目录
背景:
从上文可以知道我们在修改短链接的时候是分情况而定的,根据是否修改gid进行分情况而定。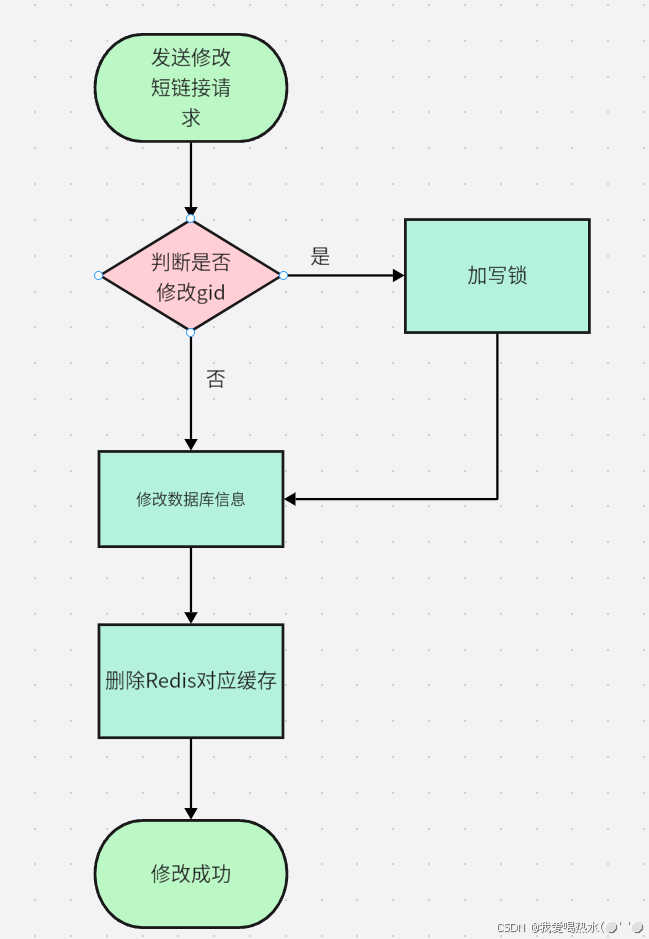
为什么要进行判断是否改变了gid?为什么修改gid的时候我们要加锁那?而且加的是读写锁,为什么不是分布式锁那?
为什么进行判断是否改变了gid?
我们短链接表是采用了分表的,分片键就是gid,一旦该短链接的信息中的gid发生了改变,那么相当于所属单位就发生了改变,因为我们查找短链接是根据gid进行查找到对应的分表,gid发生改变则对应存储的分表可能发生了改变,当需要访问该短链接的信息的时候,根据gid查找,在新改的gid对应的表下是找不到的,就会引起读扩散,遍历全表。
为什么修改gid的时候我们要加锁?
从上段可知,当我们gid发生了修改的时候,要对数据进行先删除后新增操作。
java
baseMapper.update(delShortLink, updateWrapper);//更新操作---更新就相当于逻辑删除
//添加新元素
baseMapper.insert(linkDO);但是因为是在并发系统中,在修改的时候可能会有用户正在访问,这样会导致监控数据失真,本该访问的是新的短链接,监控统计也该加在新的短链接上。所以在修改的时候要加锁进行保障监控数据的真实性。
为什么不是分布式锁而是读写锁?
首先是锁的特性,加分布式锁就把系统变成了串行化,降低了系统的性能,这是舍弃分布式锁的一个重要原因,另一个原因就是用户体验上,如果你使用分布式锁,是只要你有人发出修改短链接就会上锁,只你自己可以进行访问,那别人正在访问该短连接,会导致延迟,体验感差,如果使用读写锁,有用户正在访问,就会上读锁,而且读者是共享的,可以共享读,更符合业务要求。
读写锁的使用:
先获取读写锁在获取写锁进行尝试上锁
java
//防止并发的修改---写锁
RReadWriteLock readWriteLock = redissonClient.getReadWriteLock(String.format(LOCK_GID_UPDATE_KEY, shortLinkUpdateReqDTO.getFullShortUrl()));
RLock rLock = readWriteLock.writeLock();
if (!rLock.tryLock()){//尝试上锁
throw new ClientException("短链接正在被访问");
}//无论无何要释放锁---final---使用try-catch
try {}
final{//释放锁
rLock.unlock();
}读锁使用在监控部分进行说明。