目录
[2.1 RDD概念](#2.1 RDD概念)
[2.2 RDD算子](#2.2 RDD算子)
[2.2.1 常用转换算子](#2.2.1 常用转换算子)
[2.2.2 常用动作算子](#2.2.2 常用动作算子)
[2.3 RDD依赖](#2.3 RDD依赖)
[2.3.1 窄依赖【Narrow Dependency】](#2.3.1 窄依赖【Narrow Dependency】)
[2.3.2 宽依赖【Shuffle/Wide Dependency】](#2.3.2 宽依赖【Shuffle/Wide Dependency】)
[3.1 Spark运行模式](#3.1 Spark运行模式)
[3.1.1 Local模式](#3.1.1 Local模式)
[3.1.2 Standalone模式](#3.1.2 Standalone模式)
[3.1.3 Yarn模式](#3.1.3 Yarn模式)
[3.2 Spark执行流程](#3.2 Spark执行流程)
[3.2.1 生成逻辑查询计划](#3.2.1 生成逻辑查询计划)
[3.2.2 生成物理查询计划](#3.2.2 生成物理查询计划)
[3.2.3 任务调度与执行](#3.2.3 任务调度与执行)
[3.3 DAG任务规划与调度](#3.3 DAG任务规划与调度)
1.Spark基本概述
由于MapReduce仅支持Map、Reduce两种语义操作,执行效率低,时间开销大,主要用于大规模离线批处理,不适合迭代计算、交互式计算、实时流处理等场景,有较大的局限性。整个Spark是一个all in one的框架,它提供了多种计算场景。底层的Spark Core对标的是MapReduce, 做批处理运算,它是把数据全部拉到内存里面进行计算,解决了MapReduce计算效率慢的问题;上层提供Spark SQL接口做数仓,可以把SQL转换成底层的Spark Core代码进行运算;spark streaming是做实时流处理的,也是转换成底层的Spark Core去运行。Spark具有高吞吐、低延时、通用易扩展、高容错等特点,采用Scala语言开发,提供多种运行模式。
2.Spark编程模型
2.1 RDD概念
RDD(Resilient Distributed Datesets)是弹性分布式数据集,Spark是基于RDD进行计算的。RDD特点:
-
分布在集群中的只读对象集合
-
由多个Partition组成
-
通过转换操作构造
-
失效后自动重构(弹性)
-
存储在内存或磁盘中
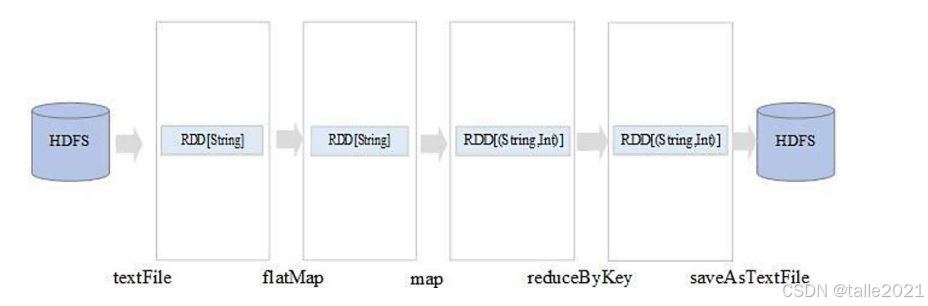
下面以WordCount的例子来理解spark是如何基于rdd来计算的。
Scala
val rdd1 = sc.textFile("hdfs://node01:9000/data/wc/in")
val rdd2 = rdd1.flatMap(_.split("\t"))
val rdd3 = rdd2.map((_,1))
val rdd4 = rdd3.reduceByKey((_+_))
rdd4.saveAsTextFile("hdfs://node01:9000/data/wc/out")首先RDD是只读的,如果对RDD进行处理之后,一定要把RDD的处理结果保存成新的RDD。在spark进行处理的时候,首先用spark的一个对象spark context,简称sc对象,用textFile算子把HDFS某个目录下的数据文件读进来,然后变成rdd1;接着对rdd1进行flatMap处理,把文本拆分成多个单词,保存成新的rdd2;对rdd2进行map处理,再把结果存到了rdd3;接下来对rdd3进行reduceByKey处理,即把Key相同的数据分发到同一个reduce节点,分发到同一个reduce节点之后再把Key相同的value值做一个求和。得到最终结果之后,把这个结果保存成一个新的rdd4。最后用saveAsTextFile把rdd4保存成一个结果文件存到HDFS的out目录下。
spark是基于rdd进行运算的,它把数据读进来以后变成一个rdd,再对这个rdd进行反复的操作,最后一个rdd基本上是最终结果,把这个结果做一个输出,这是spark的一个计算流程。中间大量依赖rdd,这样的编程范式和单机编程基本上没有什么区别。spark基于rdd的运算逻辑可以绘制成一张dag有向无环图,先从目录下把数据读出来,假设这个目录下数据存了4个block块,每个block块就是rdd的一个partition分区,对每个rdd的partition进行一次操作就变成了新的rdd,得到最后结果做一个输出。
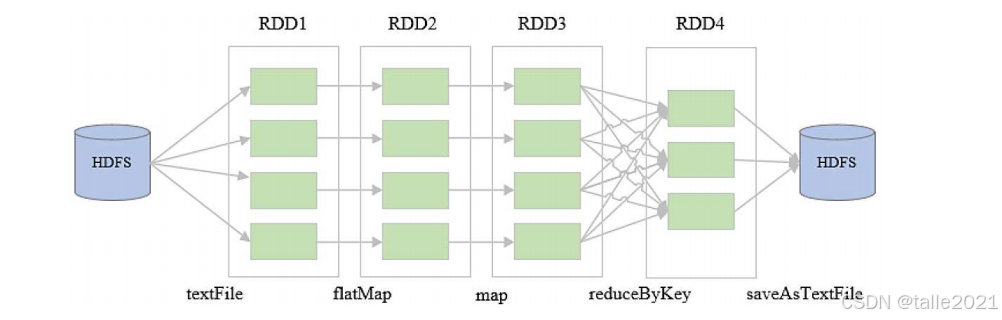
这些rdd的数据都存在内存中,一旦某个rdd的某个partition计算错误,在数据恢复的时候,不需要返回到源头让程序再从HDFS的某个节点把数据重新读出来,只需要返回到上一个阶段,上一个阶段的数据还在内存里而且是只读的,所以只需要拿到这个数据再重新执行一下就能快速恢复数据,这就是rdd的弹性。
2.2 RDD算子
RDD算子分为转换算子Transformation和动作算子Action,转换算子实际上是把RDD进行转换构造,把已有的RDD从一个RDD转换成新的一个RDD;动作算子是触发计算,触发结果的生成或结果输出。一句话总结就是:没有动作算子,所有转换算子都不会执行。
| 特性 | 转换算子 | 动作算子 |
|---|---|---|
| 定义 | 从一个RDD生成一个新的RDD的操作。 | 触发计算,将RDD的计算结果返回给Driver程序或保存到外部存储系统的操作。 |
| 本质 | 惰性的。只记录计算逻辑,不立即执行。 | 触发的。会触发整个RDD依赖链上的所有转换算子的执行。 |
| 返回值 | 返回一个新的RDD。 | 返回一个非RDD类型的值(如Scala/Java集合、具体数值)或不返回值(如保存到文件)。 |
| 例子 | map, filter, flatMap, groupByKey, reduceByKey |
count, collect, saveAsTextFile, reduce, take |
2.2.1 常用转换算子
-
map(func):对RDD中的每个元素应用func函数,返回一个新的RDD。 -
filter(func):筛选出满足func函数(返回true)的元素 -
flatMap(func):对每个元素应用func,然后将结果"扁平化"(压平)。func应返回一个序列(如列表) -
reduceByKey(func):对键值对RDD中相同键的值进行聚合。这是一个宽依赖操作(会发生Shuffle) -
groupByKey():将键值对RDD中相同键的值分组到一个迭代器中。宽依赖。 -
union(otherRdd):合并两个RDD。 -
distinct():去重。
2.2.2 常用动作算子
-
count():返回RDD中元素的个数。 -
collect():将RDD中的所有数据以数组的形式拉取到Driver程序中。但如果数据量极大,会导致Driver内存溢出。 -
take(n):取RDD中的前n个元素到Driver端。 -
first():取RDD中的第一个元素,等同于take(1)。 -
reduce(func):使用func函数(接受两个参数,返回一个同类型值)对RDD中的元素进行两两聚合。 -
saveAsTextFile(path):将RDD以文本文件形式保存到HDFS或本地文件系统。 -
foreach(func):对RDD中的每个元素应用func,通常用于将数据写入外部数据库等副作用操作。
2.3 RDD依赖
对RDD的操作会让RDD之间产生一些关系,宽依赖和窄依赖描述的是RDD中一个父RDD的分区与子RDD的分区之间的依赖关系。简单来说,就是看一个父RDD的分区的数据,会被子RDD的多少个分区所使用。
2.3.1 窄依赖【Narrow Dependency】
如下图,父RDD的每一个分区最多只能被一个子RDD的分区所依赖,子RDD如果有部分分区数据丢失或损坏,只需从对应的父RDD重新计算恢复。
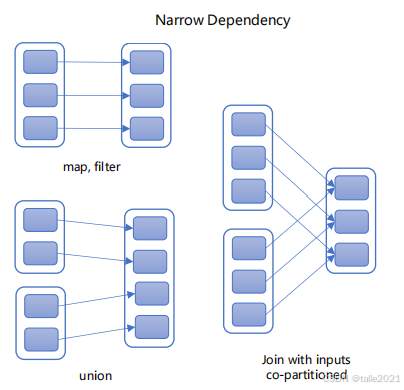
【窄依赖特点】:
-
计算可以在单个节点内独立完成,无需跨节点移动数据。
-
高效的容错:如果子RDD的某个分区丢失,只需要重新计算其对应的唯一父RDD分区即可。
-
是 "管道化" 执行的基础,支持连续多个窄依赖操作合并成一个阶段(Stage)并行执行。
【属于窄依赖的算子】:
-
map:父分区中的每个元素独立转换,输出到子分区的同一位置。 -
filter:父分区中过滤掉一些元素,输出到子分区的同一位置。 -
flatMap:一个父元素可能映射为0个、1个或多个子元素,但依然在同一个子分区内。 -
mapPartitions:针对整个分区进行操作,输入输出分区一一对应。 -
union:简单地将多个RDD合并,分区关系不变。 -
coalesce(N)(且N>原分区数,即减少分区):在节点内合并父分区,不产生Shuffle。例如,父分区4个 -> 子分区2个,一个父分区只贡献给一个子分区。
2.3.2 宽依赖【Shuffle/Wide Dependency】
如下图,父RDD的一个分区被多个子RDD的分区所依赖,子RDD如果部分或全部分区数据丢失或损坏,必须从所有父RDD分区重新计算。相对于窄依赖,宽依赖付出的代价要高很多,应尽量避免使用。举例:groupByKey、reduceByKey、sortByKey
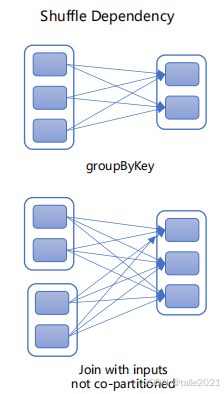
【宽依赖特点】:
-
计算必须跨节点,需要将具有相同Key的数据从所有父分区中拉取到同一个子分区进行处理。这个过程就是 Shuffle(洗牌)。
-
容错成本高:如果子RDD的某个分区丢失,由于其数据来源于多个父分区(可能在不同节点),需要重新计算所有这些父分区,并重新进行Shuffle。
-
宽依赖是划分Stage的边界。
【属于宽依赖的算子】:
-
groupByKey:相同Key的数据必须拉到同一个分区,必然Shuffle。 -
reduceByKey:聚合相同Key的数据,需要Shuffle(但比groupByKey优化,因为有Map端预聚合)。 -
join(非共同分区情况下):两个RDD中关联Key的数据需要拉到一起,必须Shuffle。 -
distinct(底层实现为reduceByKey):去重本质是相同Key的聚合,需要Shuffle。 -
repartition(N):无论增减分区,都通过Shuffle实现数据的完全重新分布。 -
coalesce(N)(且N<原分区数,即增加分区):增加分区必然需要Shuffle来打散数据。
3.Spark程序架构
-
**Driver:**负责Spark程序的解析、划分Stage、调度任务到Executor上执行,一个Spark程序有一个Driver,一个Driver创建一个Spark Context,程序的main函数在Driver中运行。
-
**SparkContext:**负责加载配置信息,初始化运行环境,创建DAGScheduler和TaskScheduler
-
**Executor:**负责执行Driver分发的任务,一个节点可以启动多个Executor,每个Executor通过多线程运行多个任务。
-
**Task:**Spark运行的基本单位,一个Task负责处理一个RDD分区的计算逻辑。
spark集群的主节点是Master,从节点是Worker,也是主从架构。客户端向Master主节点发起提交任务请求,Master就会在所有的worker节点里分配一个运行资源,第一个运行资源运行作业自己的管理进程Driver,Driver运行起来后就开始解析作业,解析完以后发现需要4个task的资源,于是Driver向Master申请分配4个task的资源,Master就会在所有的Worker节点里面分配资源,把资源分装成Executor,Driver拿到新分配的资源后就把解析出来的task分发到Executor执行,执行过程中task会实时向Driver汇报,Driver发现所有的task运行完成之后,就向Master申请资源释放,Master就把所有的Executor资源全部释放掉。
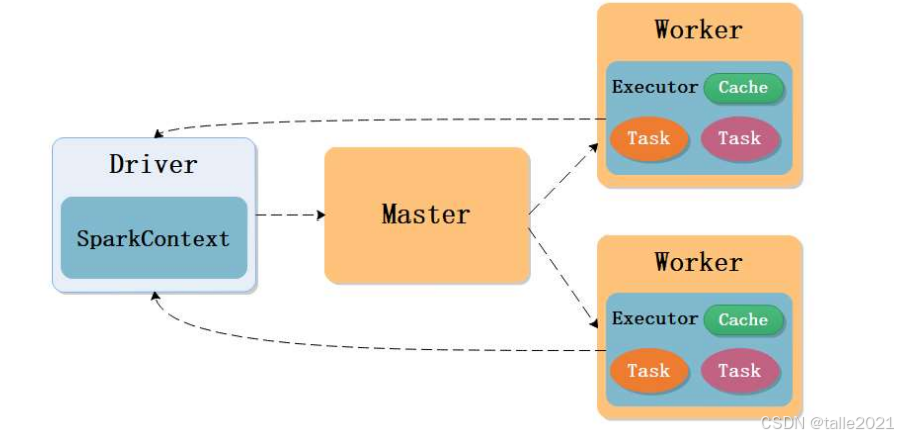
Spark程序架构原理跟Yarn很相似,在Yarn中,作业的管理进程叫Application Master,申请出来的资源叫Container,Container里只能运行一个 task;在Spark中,作业的管理进程叫Driver,申请出来的资源叫Executor,Executor里可以运行多个task。
3.1 Spark运行模式
Spark运行模式指的是Spark应用程序的Driver进程、Executor进程、以及集群管理器这三者之间的组织和管理方式。简单说,就是Spark程序在哪里、以什么方式运行。
3.1.1 Local模式
local模式是单机执行,通常用于测试。比如本地写好spark代码之后,在本地测试,就用local模式跑一下,如果跑通了,说明代码没有问题。
3.1.2 Standalone模式
Standalone模式是已经装了spark集群,不依赖于第三方资源管理系统(如:YARN、Mesos),就可以把代码,以Standalone模式提交到spark集群里面运行。它的运行机制首先是客户端向Master主节点发起提交任务请求,Master就会在所有的worker节点里分配一个运行资源,第一个运行资源运行作业自己的管理进程Driver,Driver运行起来后就开始解析作业,解析完以后发现需要4个task的资源,于是Driver向Master申请分配4个task的资源,Master就会在所有的Worker节点里面分配资源,把资源分装成Executor,Driver拿到新分配的资源后就把解析出来的task分发到Executor执行,执行过程中task会实时向Driver汇报,Driver发现所有的task运行完成之后,就向Master申请资源释放,Master就把所有的Executor资源全部释放掉。
3.1.3 Yarn模式
如果没有单独的spark集群,只有Hadoop集群,就用Yarn模式。其本质是将Spark作为Yarn上的一个应用程序来运行。Yarn负责整体的集群资源管理和调度。
Yarn-Cluster模式
Yarn-Cluster模式是Driver运行在Yarn集群的一个容器中(由Yarn的ApplicationMaster兼任),Executor运行在其他容器中,适用于生产环境。
如下图,首先客户端向Resource Manager提交作业申请,Resource Manager在所有的Node Manager里面分配一个container出来,第一个container运行application master,前面提到spark的管理进程是driver,yarn的管理进程是application master,两者的协调只需要在driver外面套一个application master的壳子,application master运行起来后,负责解析作业的还是driver,driver把spark作业解析完以后,发现spark作业解析成了8个task,需要8个task的资源,但是driver没办法申请Hadoop的资源,这个时候driver就通知application master需要8个task的资源,application master再向resource manager申请资源,resource manager就给application maste分配container,application maste拿到资源之后就通知driver已申请到作业资源,于是driver就把解析好的task分发到这些container里运行,执行过程中,task会实时向driver进行汇报,driver发现所有的task运行完成之后,再通知application master释放资源,于是resource manager就把所有的资源给释放掉了。
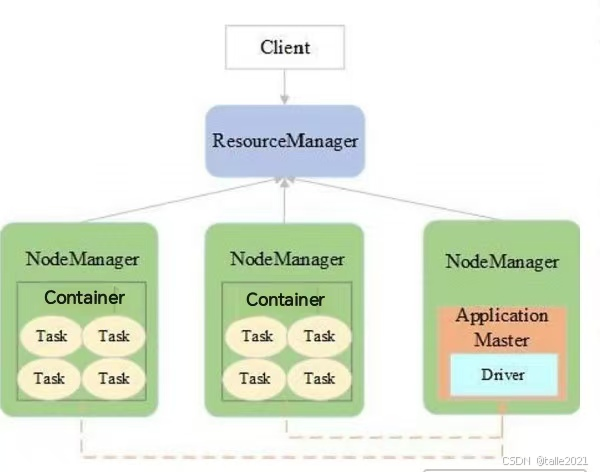
Yarn-Cluster模式的driver在某一个从节点上,客户端看不到返回来的信息,所以为了便于调试,希望客户端这一块也能看到driver,实时收集到task的运行信息,观察作业情况,这个时候就可以用Yarn-Client模式。
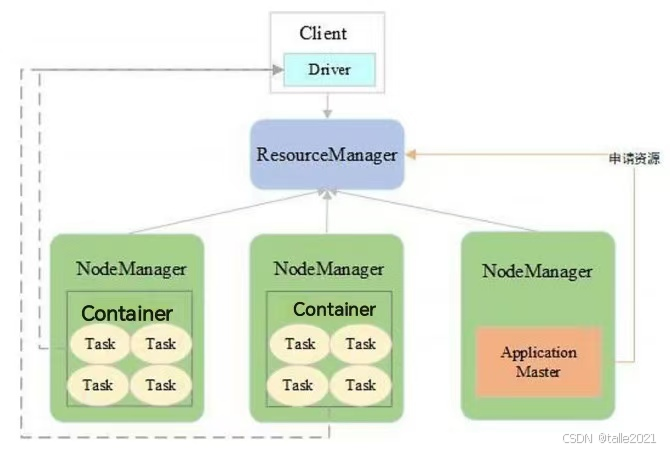
Yarn-Client模式
Yarn-Client模式是Driver运行在提交任务的客户端机器上,Executor运行在Yarn的容器中,适用于交互和调试。Client模式和Cluster模式的区别在于Client模式的driver放到了客户端里,把driver放到了客户端里,这样driver会实时监控task返回来的信息,这种方式更适合调试。
3.2 Spark执行流程
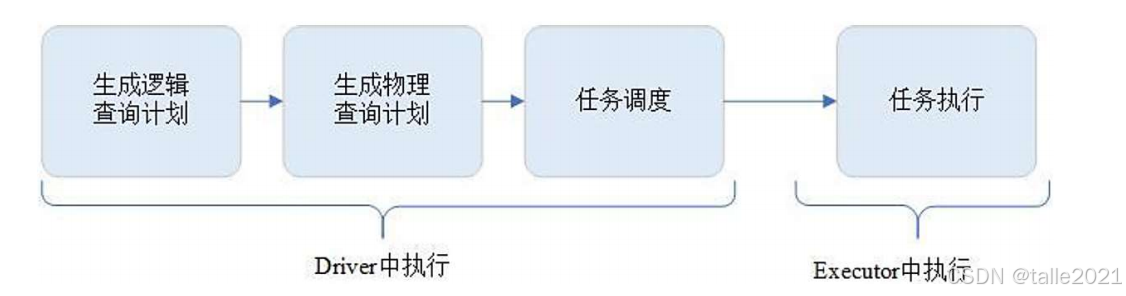
整体的spark程序执行流程首先是Driver解析代码,先生成逻辑查询计划,再生成物理查询计划,最后打包成任务,即task的集合,打包成task集合之后,就把task集合调度到executor里去执行,执行过程中driver还会实时监控task的运行信息,进行相应的调度。
下面以一段用scala语言编写好的一个spark词频统计代码来理解spark程序是如何解析成task的。这段代码的逻辑首先是spark context用textFile把文本文件读进来,然后把文本文件拆分成单词,再给每个单词标数字"1",再按照Key值进行reduce,也就是把相同的单词聚合到同一个节点里面,再把对应的value值累加,得到最终的词频统计结果,然后输出到一个数据目录里保存。
Scala
sc.textFile(inputArg)
.flatMap(_.split("\t"))
.map((_,1))
.reduceByKey((_+_))
.saveAsTextFile(outArg)3.2.1 生成逻辑查询计划
逻辑查询计划仅仅关注RDD的状态,首先driver把这段代码生成逻辑查询计划,从Hdfs把文本读出来时,RDD里的数据是string类型的,对这个string类型的数据进行flatMap处理成单词形式,每个单词也是属于string类型的,接着进行map处理,给每个单词标数字"1",这个时候RDD的数据类型就变成了key-value的类型,key是string类型的单词,value是int类型的,最后reduceByKey按照Key值聚合,统计出词频结果并输出,这个就是逻辑查询计划,把RDD的状态解析出来。
3.2.2 生成物理查询计划
接下来做物理查询计划,物理查询关注底层数据的状态,比方说底层数据是由4个block块,这个时候就要根据4个block块来划分DAG图。如下图,从HDFS里面读出来4个block块,这样第一个RDD里面就有4个partition,每个block块对应一个partition,接下来进行一系列处理,第一次处理的时候是一对一的转换,把文本拆成单词,partition变成了一个新的partition,生成新的RDD;接着给每个单词标数字"1",转换完以后,reduceByKey按照Key值聚合到reduce节点处理,生成最后一个RDD并输出。
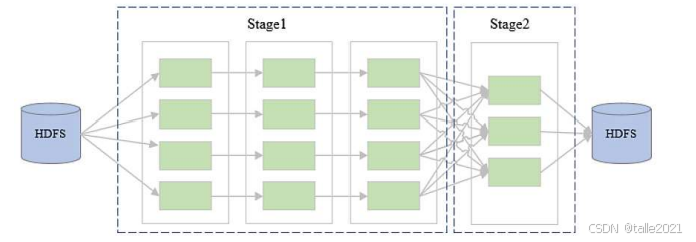
3.2.3 任务调度与执行
整个DAG图出来之后就要根据DAG图是否有宽窄依赖进行stage的切分,如下图前面都是一对一转换,一对一都是窄依赖啊,于是窄依赖的放在stage1里面。中间一旦走过宽依赖,在宽依赖处就切一刀,把剩下的这个rdd变成了新的stage2。可以理解为它是按照宽窄依赖进行拆分的,或者说是根据是否有shuffle进行拆分的,因为一旦有shuffle,实际上就是形成了一个宽依赖,前面是窄依赖,前后不是一个stage的。
划分stage的作用在于,同一个stage里的rdd可以放在同一个节点处理,一对一的转换可以打包成一个task,只需要把数据拿过来,在task里一对一的转换,并不需要其他的数据,这样stage1可以画成4个task,右边stage2可以画成3个task,一共打包成7个task,再把7个task放到一个set集合里,然后打包发送到executor里执行,执行过程中这些task会实时向driver汇报,这是整个调度流程。
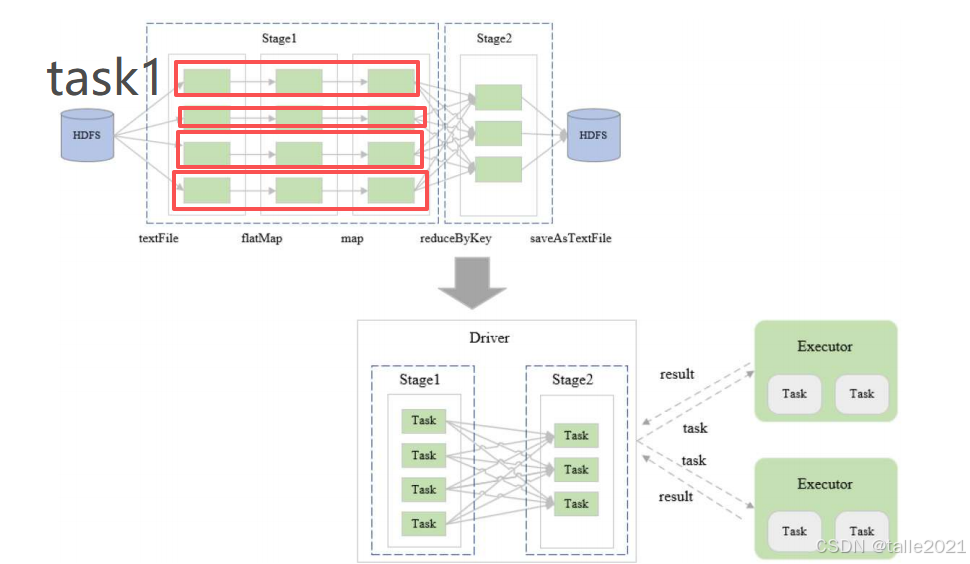
3.3 DAG任务规划与调度
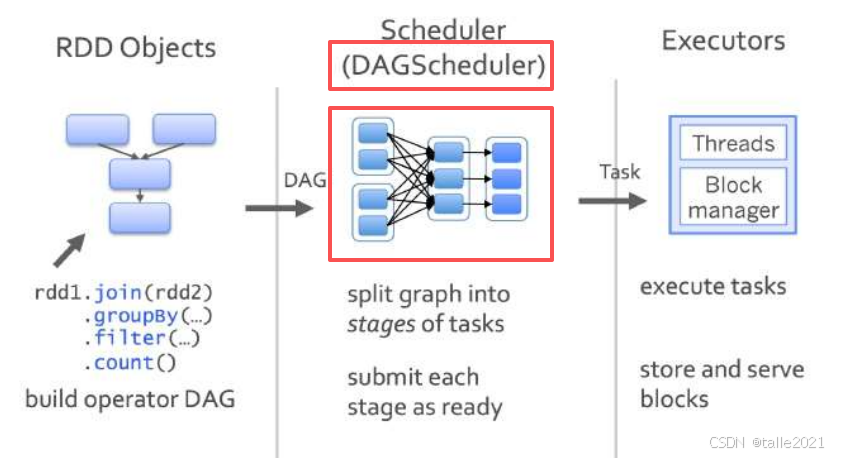
DAG(Directed Acyclic Graph)有向无环图:受制于某些任务必须比另一些任务较早执行的约束,可排序为一个队列的任务集合,该队列可由一个DAG图呈现,一个有向图无法从任意顶点出发经过若干条边回到该点。Spark程序的内部执行逻辑可由DAG描述,顶点代表任务,边代表任务间的依赖约束。
DAGScheduler:根据任务的依赖关系建立DAG,根据依赖关系是否为宽依赖,即是否存在Shuffle,将DAG划分为不同的阶段(Stage),将各阶段中的Task组成的TaskSet提交到TaskScheduler
TaskScheduler:负责Application的任务调度;重新提交失败的Task;为执行速度慢的Task启动备用Task。
 下面以一个DAG图来展示stage是如何去切分的。首先是根据宽窄依赖去切分的,宽窄依赖是针对RDD与RDD之间来说的,图中有ABCDEF总共有6个RDD,rdd-A和rdd-B之间是宽依赖,中间走了一次shuffle,那么在rdd-A和rdd-B之间切一刀,左边变成Stage1;rdd-C、rdd-D和rdd-E之间是一对一的窄依赖,可以放在一个stage里;rdd-E和rdd-F之间是宽依赖,中间走了一次shuffle,那么在rdd-E和rdd-F之间切一刀,左边rdd-CDE变成Stage2;剩下的rdd-B和rdd-F之间是一对一的窄依赖,形成Stage3。
下面以一个DAG图来展示stage是如何去切分的。首先是根据宽窄依赖去切分的,宽窄依赖是针对RDD与RDD之间来说的,图中有ABCDEF总共有6个RDD,rdd-A和rdd-B之间是宽依赖,中间走了一次shuffle,那么在rdd-A和rdd-B之间切一刀,左边变成Stage1;rdd-C、rdd-D和rdd-E之间是一对一的窄依赖,可以放在一个stage里;rdd-E和rdd-F之间是宽依赖,中间走了一次shuffle,那么在rdd-E和rdd-F之间切一刀,左边rdd-CDE变成Stage2;剩下的rdd-B和rdd-F之间是一对一的窄依赖,形成Stage3。
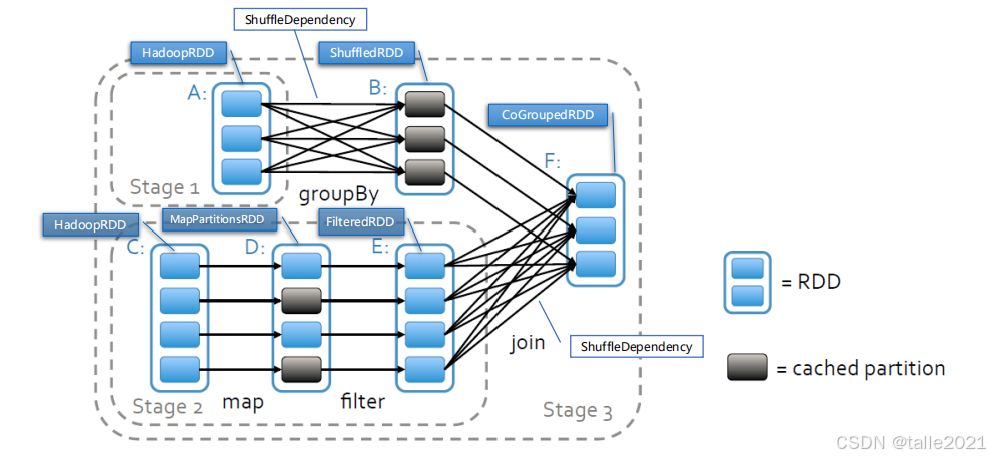
stage数量越多,shuffle越多,性能越慢,所以在调优过程中,重点关注整个spark任务的stage个数。