摘要
本文介绍了房屋销售价格预测的机器学习实战。首先阐述了房屋销售价格预测的背景,包括目标变量SalePrice和众多影响房屋价值的特征,如地块与分区特征、社区位置、房屋建筑特征等。接着进行了数据处理,包括特征变量数据分布分析和变量特征处理。之后进行了模型训练与测试数据切分,选择了随机森林模型进行训练和预测,并对模型进行了评价。
1. 房屋销售价格预测背景
这是房地产领域一个重要的指标,涉及到房屋买卖、投资等诸多方面。而"Advanced Regression Techniques"则表示高级回归技术,回归分析是一种统计学方法,用于研究因变量(如房屋价格)与一个或多个自变量(如房屋面积、地理位置、房间数量等)之间的关系。这里的"高级"意味着使用了较为复杂、先进的方法来进行回归分析,可能是为了更准确地预测房屋价格,或者更好地理解影响房屋价格的各种因素之间的关系。
1.1. 目标变量:SalePrice
定义:房屋的销售价格(单位:美元)。
角色 :建模分析的最终预测目标,即通过其他特征推断该变量的值。
1.2. 地块与分区特征
(影响房屋价值的基础外部环境要素)
- MSSubClass描述 :建筑类别(如单户住宅、两户住宅等)。影响:不同类别在结构、功能上存在差异,直接影响定价逻辑。
- MSZoning描述 :一般分区分类(如住宅区、商业区等)。影响:决定房屋用途与周边环境,进而显著影响价值(如住宅区溢价更高)。
- LotFrontage描述 :与街道相连的直线距离(单位:英尺)。影响:影响可访问性与视野,间接作用于价格。
- LotArea描述 :地块面积(单位:平方英尺)。影响:面积越大→户外空间与扩展性越强→房屋价值越高。
- Street描述 :道路接入类型(铺装道路/未铺装道路)。影响:铺装道路→交通便利性与维护更好→正向影响价值。
- Alley描述 :小巷接入类型(无小巷/铺装小巷/未铺装小巷)。影响:小巷的类型与存在与否,影响私密性与便利性。
- LotShape描述 :地块形状(规则/轻微不规则/中等不规则/不规则)。影响:规则形状→更易开发与利用→正面影响价值。
- LandContour描述 :地块平坦度(平坦/倾斜等)。影响:平坦地块→便于建筑与景观设计;倾斜地块→需额外工程成本。
- Utilities描述 :可用公用设施类型(如所有公共设施/无下水道等)。影响:完善设施是基本需求,直接关乎宜居性与价值。
- LotConfig描述 :地块配置(内部/角地/尽头等)。影响:不同配置改变房屋布局与周边环境体验。
- LandSlope描述 :地块坡度(平坦/温和倾斜/陡峭倾斜)。影响:坡度影响建筑成本与景观效果,平坦地块更优。
1.3. 社区位置:Neighborhood
描述 :房屋所在阿姆斯城市范围内的具体位置。
影响:不同社区的声誉、设施、安全性差异显著→房价分化明显。
1.4. 房屋建筑特征
(核心内在属性,按功能模块细分)
1.4.1. 周边环境与建筑类型
- Condition1 :与主要道路/铁路的接近程度(如相邻/靠近)。影响:交通便利性↑ vs 噪音干扰↑,需综合评估。
- Condition2:若存在第二个主要道路/铁路,其接近程度(细化周边环境)。
- BldgType :房屋类型(如单户住宅/双户住宅等)。影响:结构功能差异→价格影响不同。
- HouseStyle :房屋风格(如单层/两层等)。影响:影响外观与内部空间布局效率。
1.4.2. 质量与状况评级
- OverallQual:整体材料和完成质量评级(数值越高越好) 。影响:高质量材料与工艺→显著提升价值。
- OverallCond:整体状况评级(良好=低维护成本+高舒适度)。
- ExterQual:外部材料质量(如砖石/木材的优劣)。
- ExterCond:外部材料当前状况(影响维护成本与外观)。
- BsmtQual:地下室高度(影响可用性与舒适度,高则空间更优)。
- BsmtCond:地下室总体状况(良好=低潮湿/维护问题)。
- GarageQual:车库质量(结构设施优劣)。
- GarageCond:车库状况(影响维护成本与使用功能)。
- HeatingQC:供暖质量和状况(高=高舒适度+低能耗)。
- KitchenQual:厨房质量(设备材料优劣→影响舒适度与价值)。
- FireplaceQu:壁炉质量(性能与安全性)。
1.4.3. 建造与翻新信息
- YearBuilt :原始建造日期。影响:较新房屋→现代设计与设施;老旧房屋→需更多维护。
- YearRemodAdd :翻新日期。影响:翻新→提升现代化程度与功能→正向影响价格。
- GarageYrBlt :车库建造年份。影响:较新车库→设施更优。
1.4.4. 结构与面积特征
- RoofStyle :屋顶类型(平屋顶/坡屋顶等)。影响:美观性、排水性、维护成本差异。
- RoofMatl :屋顶材料(沥青瓦/金属等)。影响:质量与耐用性→影响维护成本与寿命。
- Exterior1st:外部覆盖材料(如砖石/木材)。
- Exterior2nd:第二种外部覆盖材料(丰富外观与材料特性)。
- MasVnrType:石砌饰面类型(无/砖石等)。
- MasVnrArea:石砌饰面面积(平方英尺,影响外观与成本)。
- Foundation :基础类型(混凝土/砖石等)。影响:关乎稳定性与耐久性。
- 1stFlrSF:第一层面积(平方英尺,影响居住空间与布局)。
- 2ndFlrSF:第二层面积(多层住宅中重要性高)。
- GrLivArea:地上居住面积(平方英尺,核心空间指标)。
- TotalBsmtSF:地下室总面积(平方英尺,整体空间指标)。
- BsmtFinSF1/BsmtFinSF2:类型1/2完成区域面积(决定可用空间)。
- BsmtUnfSF:地下室未完成区域面积(可用于存储)。
- LowQualFinSF:低质量完成区域面积(需更多维护更新)。
1.4.5. 地下室细节
- BsmtExposure:地下室暴露程度(如无/良好,影响采光通风)。
- BsmtFinType1/BsmtFinType2:地下室完成区域质量(如无/良好,影响使用功能)。
1.4.6. 设施与功能
- Heating:供暖类型(燃气/电等,影响舒适度与能效)。
- CentralAir:是否安装中央空调(提升温控舒适度)。
- Electrical:电气系统(标准电路/无等,关乎安全性与功能)。
- Functional:房屋功能评级(典型/损坏等,反映实用性)。
- Fireplaces:壁炉数量(增加舒适性与美观性)。
1.4.7. 空间与房间配置
- Bedroom:地下室以上楼层卧室数量(基本居住功能指标)。
- Kitchen:厨房数量(通常1个,特殊情况多厨房)。
- TotRmsAbvGrd:地上总房间数(不含浴室,衡量规模)。
- FullBath/HalfBath:地上全浴室/半浴室数量(便利性指标)。
- BsmtFullBath/BsmtHalfBath:地下室全浴室/半浴室数量(额外便利)。
1.4.8. 车库特征
- GarageType:车库位置(无/附着等,影响便利性)。
- GarageFinish:车库内部完成情况(如无/粗糙,影响使用功能)。
- GarageCars:车库容量(汽车数量单位,决定停车能力)。
- GarageArea:车库面积(平方英尺,衡量大小)。
- PavedDrive:是否铺设车道(提升进出便利性与房屋整洁度)。
2. 数据处理
2.1. 特征变量数据分布情况
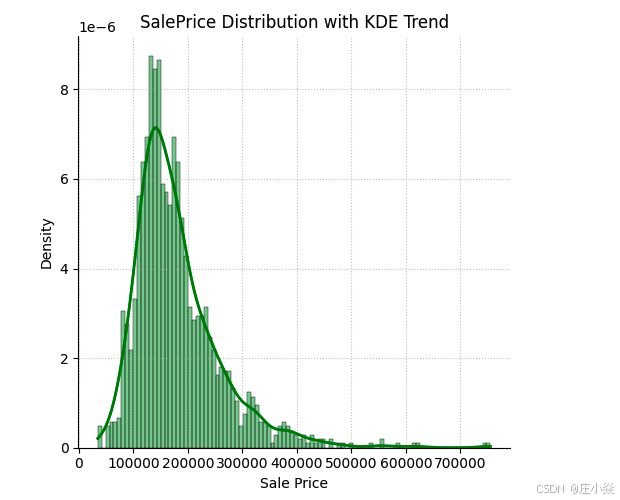
2.2. 特征变量中所有数字类型变量分布
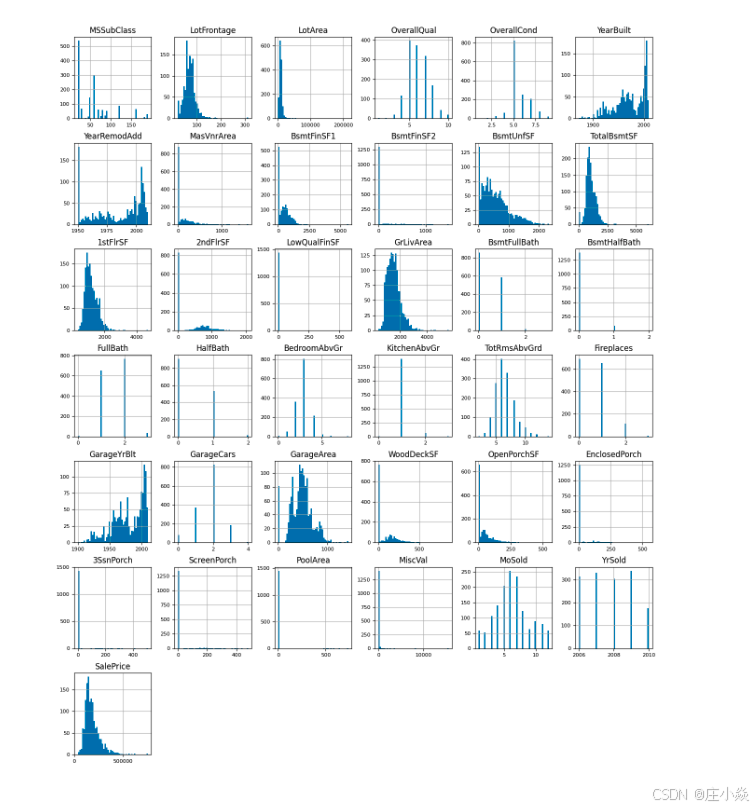
2.3. 变量特征处理
当前只有删除无效列id数据
# 删除第一列 id
dataset_df = dataset_df.drop('Id', axis=1)
dataset_df.head(3)
import matplotlib
import numpy as np
import tensorflow as tf
import tensorflow_decision_forests as tfdf
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# tf 当前版本
# print("TensorFlow v" + tf.__version__)
# print("TensorFlow Decision Forests v" + tfdf.__version__)
#
# print("----------"*5+"\n")
# 读取测试数据,
train_file_path = "./data/train.csv"
dataset_df = pd.read_csv(train_file_path)
# 查询矩阵行列
# print("Full train dataset shape is {}".format(dataset_df.shape))
# 显示所有列(前 3 行)
# dataset_df_3 = dataset_df.head(3)
# print(dataset_df_3.to_string())
# 删除第一列 id
dataset_df = dataset_df.drop('Id', axis=1)
dataset_df.head(3)
eda_dataset_df_3 = dataset_df.head(3)
# print(eda_dataset_df_3.to_string())
# 显示所有数据的类型
# print(dataset_df.info())
# 查询当前数据最小值、最大值、平均值、方差值
# print(dataset_df['SalePrice'].describe())
# plt.figure(figsize=(9, 8))
# sns.displot(
# data=dataset_df,
# x='SalePrice',
# kind='hist', # 直方图类型
# bins=100,
# color='g',
# alpha=0.4,
# kde=True, # 添加KDE曲线
# line_kws={'color': 'red', 'lw': 2}, # KDE曲线样式
# stat='density' # 标准化为密度
# )
# plt.title('SalePrice Distribution with KDE Trend')
# plt.xlabel('Sale Price')
# plt.ylabel('Density')
# plt.grid(True, linestyle=':', alpha=0.7)
# plt.show()
list(set(dataset_df.dtypes.tolist()))
# 原始数据集 dataset_df中仅保留数值类型的列(排除字符串列 object、日期列 datetime、分类列 category等)。
df_num = dataset_df.select_dtypes(include = ['float64', 'int64'])
df_num.head()
# print(df_num_result.describe())
# 目的是快速可视化所有数值列的分布特征(如集中趋势、离散程度、异常值等)。
df_num.hist(figsize=(16, 20), bins=50, xlabelsize=8, ylabelsize=8)
# plt.show()3. 模型训练与测试数据切分
import numpy as np
import pandas as pd
# 读取测试数据,
train_file_path = "./data/train.csv"
dataset_df = pd.read_csv(train_file_path)
# 切分测试数据
def split_dataset(dataset, test_ratio=0.30):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples in testing.".format(len(train_ds_pd), len(valid_ds_pd)))4. 模型选择/训练/导出/预测
使用随机森林模型来实现
# tfdf.keras.get_all_models()
rf = tfdf.keras.RandomForestModel(task = tfdf.keras.Task.REGRESSION)模型训练
import matplotlib
import numpy as np
import tensorflow as tf
import tensorflow_decision_forests as tfdf
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取测试数据,
train_file_path = "./data/train.csv"
dataset_df = pd.read_csv(train_file_path)
# 切分测试数据
def split_dataset(dataset, test_ratio=0.30):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples in testing.".format(len(train_ds_pd), len(valid_ds_pd)))
label = 'SalePrice'
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label, task = tfdf.keras.Task.REGRESSION)
valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(valid_ds_pd, label=label, task = tfdf.keras.Task.REGRESSION)
# tfdf.keras.get_all_models()
rf = tfdf.keras.RandomForestModel(task = tfdf.keras.Task.REGRESSION)
rf.compile(metrics=["mse"])
rf.fit(x=train_ds)
# 模型导出
tfdf.model_plotter.plot_model(rf, tree_idx=0, max_depth=3)模型预测
import matplotlib
import numpy as np
import tensorflow as tf
import tensorflow_decision_forests as tfdf
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取测试数据,
train_file_path = "./data/train.csv"
dataset_df = pd.read_csv(train_file_path)
# 移除 Id 列(关键步骤!)
if 'Id' in dataset_df.columns:
dataset_df = dataset_df.drop(columns=['Id']) # 删除 Id 列
# 切分测试数据
def split_dataset(dataset, test_ratio=0.30):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples in testing.".format(len(train_ds_pd), len(valid_ds_pd)))
label = 'SalePrice'
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label, task = tfdf.keras.Task.REGRESSION)
valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(valid_ds_pd, label=label, task = tfdf.keras.Task.REGRESSION)
rf = tfdf.keras.RandomForestModel(task = tfdf.keras.Task.REGRESSION)
rf.compile(metrics=["mse"])
rf.fit(x=train_ds)
test_file_path = "./data/test.csv"
test_data = pd.read_csv(test_file_path)
ids = test_data.pop('Id')
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_data,task = tfdf.keras.Task.REGRESSION)
preds = rf.predict(test_ds)
output = pd.DataFrame({'Id': ids,'SalePrice': preds.squeeze()})
# 保存结果到CSV
output.to_csv('submission.csv', index=False)
print("预测结果已保存到 submission.csv")
print(output.to_string())5. 模型评价
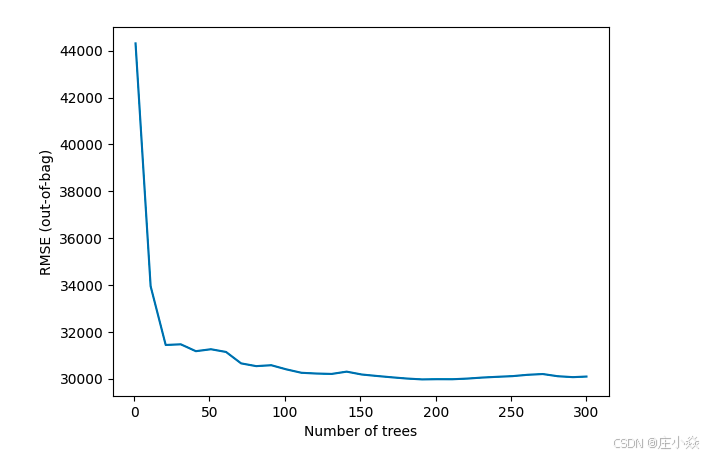
# logs = rf.make_inspector().training_logs()
# plt.plot([log.num_trees for log in logs], [log.evaluation.rmse for log in logs])
# plt.xlabel("Number of trees")
# plt.ylabel("RMSE (out-of-bag)")
# plt.show()
inspector = rf.make_inspector()
inspector.evaluation()
# evaluation = rf.evaluate(x=valid_ds,return_dict=True)
# for name, value in evaluation.items():
# print(f"{name}: {value:.4f}")
#
#
# print(f"Available variable importances:")
# for importance in inspector.variable_importances().keys():
# print("\t", importance)
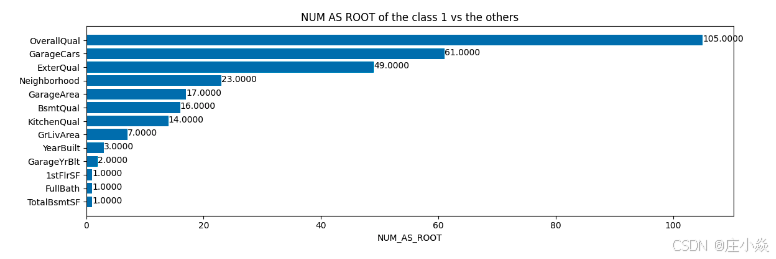
inspector.variable_importances()["NUM_AS_ROOT"]
plt.figure(figsize=(12, 4))
# Mean decrease in AUC of the class 1 vs the others.
variable_importance_metric = "NUM_AS_ROOT"
variable_importances = inspector.variable_importances()[variable_importance_metric]
# Extract the feature name and importance values.
#
# `variable_importances` is a list of <feature, importance> tuples.
feature_names = [vi[0].name for vi in variable_importances]
feature_importances = [vi[1] for vi in variable_importances]
# The feature are ordered in decreasing importance value.
feature_ranks = range(len(feature_names))
bar = plt.barh(feature_ranks, feature_importances, label=[str(x) for x in feature_ranks])
plt.yticks(feature_ranks, feature_names)
plt.gca().invert_yaxis()
# TODO: Replace with "plt.bar_label()" when available.
# Label each bar with values
for importance, patch in zip(feature_importances, bar.patches):
plt.text(patch.get_x() + patch.get_width(), patch.get_y(), f"{importance:.4f}", va="top")
plt.xlabel(variable_importance_metric)
plt.title("NUM AS ROOT of the class 1 vs the others")
plt.tight_layout()
plt.show()6. 模型总结
6.1. 数据预处理:严重缺失,直接影响模型性能
代码仅做了"移除Id列"的操作,完全忽略了房屋数据常见的预处理步骤,导致模型输入质量差、无法学习有效规律。
6.1.1. 缺失值未处理
房屋数据(如Ames Housing数据集)普遍存在大量缺失值(例如LotFrontage、Alley、BsmtQual、GarageYrBlt等)。直接输入模型会导致:
- 树模型(如随机森林)虽能处理部分缺失值,但会默认用特定规则(如"忽略该特征"或"归为单独类别"),可能扭曲特征分布;
- 若缺失值比例过高(如
Alley缺失率>90%),该特征实际无效,应直接删除而非保留。
改进:
- 统计各特征缺失率,删除缺失率>50%的特征(如
Alley、PoolQC); - 对剩余缺失值,按特征类型填充:
-
- 数值特征(如
LotFrontage):用同Neighborhood的中位数填充(考虑社区相关性); - 类别特征(如
BsmtQual):用"None"填充(表示"无地下室")。
- 数值特征(如
6.1.2. 类别特征未编码
代码中大量类别特征(如MSZoning、Street、LotShape、Neighborhood等)为字符串类型,直接输入模型会导致:
- TensorFlow Decision Forests(TFDF)虽支持自动识别类别特征,但需显式标记(
categorical=True),否则可能被误判为数值特征(如MSSubClass是类别却用数字编码,易被当作有序变量); - 高基数类别(如
Neighborhood有25个取值)可能导致模型过拟合。
改进:
- 用
pd.Categorical标记类别特征,或转换为独热编码(低基数)、目标编码(高基数,如Neighborhood用该社区平均房价编码); - 对TFDF,需在
pd_dataframe_to_tf_dataset中指定categorical_columns参数。
6.1.3. 目标变量(SalePrice)未变换
房屋价格SalePrice通常呈右偏分布(少数高价房拉高均值),直接预测会导致模型对高值样本误差大。
改进 :对SalePrice做对数变换 (log(1 + SalePrice)),使其接近正态分布,预测后用exp(pred) - 1还原。
6.1.4. 异常值未处理
数据中存在极端值(如GrLivArea极大但SalePrice极低的"异常交易"),会干扰模型对正常规律的学习。
改进 :用箱线图或Z-score检测异常值,结合业务逻辑删除(如GrLivArea > 4000且SalePrice < 200000的样本)。
6.2. 模型训练流程:逻辑混乱,缺乏科学评估
6.2.1. 数据划分与命名错误
- 函数
split_dataset注释写"切分测试数据",实际是将train.csv划分为训练集(70%)和验证集(30%) ,但变量名valid_ds_pd易误解为"测试集"; - 未设置随机种子 (
np.random.seed(42)),导致每次运行划分结果不同,实验无法复现。
改进:
- 明确划分"训练集(60%)-验证集(20%)-测试集(20%)",用
sklearn.model_selection.train_test_split并设置random_state=42; - 变量名改为
train_df, val_df, test_df,避免歧义。
6.2.2. 未使用验证集评估模型
代码仅用训练集拟合模型(rf.fit(x=train_ds)),完全忽略验证集 (valid_ds_pd转成的valid_ds未参与训练监控),导致:
- 无法判断模型是否过拟合(训练集误差小、验证集误差大);
- 无法根据验证集性能调参(如树的数量、深度)。
改进:
-
训练时用验证集监控:
rf.fit(x=train_ds, validation_data=valid_ds); -
训练后计算验证集指标(MSE、RMSE、MAE),例如:
val_preds = rf.predict(valid_ds)
mse = tf.keras.metrics.mean_squared_error(valid_ds_pd[label], val_preds)
print(f"验证集MSE: {mse.numpy().mean()}")
6.2.3. 模型选择单一,无超参数调优
仅用随机森林(RandomForestModel),未对比其他更适合表格数据的模型(如梯度提升树GBDT),且未调参:
- 随机森林对高维稀疏特征(如独热编码后的类别特征)效果不如GBDT;
- 默认参数(如树数量=300、最大深度=16)可能非最优,需通过网格搜索/贝叶斯优化调参(如
num_trees=500、max_depth=10)。
改进:
- 尝试TFDF的
GradientBoostedTreesModel(梯度提升树,表格数据SOTA之一),或对比XGBoost/LightGBM; - 用
tfdf.keras.RandomForestModel的hyperparameter参数调优,或用Keras Tuner自动搜索。
6.2.4. 缺乏交叉验证
仅用单次随机划分验证集,结果受样本划分影响大,稳定性差。
改进 :用5折交叉验证(sklearn.model_selection.KFold)评估模型泛化能力,取平均性能。
6.3. 工程实践:冗余代码与潜在风险
6.3.1. 导入冗余库
代码导入matplotlib/seaborn/sns/plt但未使用,增加内存占用。
改进 :删除无用导入,仅保留必要库(pandas/numpy/tensorflow/tensorflow_decision_forests)。
6.3.2. 测试集处理与训练集不一致
- 测试集
test.csv仅pop('Id'),未做与训练集相同的预处理(如缺失值填充、类别编码),导致预测时因特征分布不一致报错或结果失真。
改进:
- 将预处理步骤封装为函数(如
preprocess(df, is_train=True, fill_values=None)),对训练集/验证集/测试集统一处理; - 用训练集的统计量(如填充值、编码映射)处理测试集,避免数据泄露。
6.3.3. 未保存模型与结果校验
- 训练好的模型未保存(
rf.save("model")),下次预测需重新训练; - 预测结果
preds.squeeze()未校验合理性(如是否存在负房价、极端值是否超过历史范围)。
改进:
- 用
rf.save("/path/to/model")保存模型,预测时加载; - 对预测结果做后处理:
output['SalePrice'] = output['SalePrice'].clip(lower=0)(确保非负),并对比训练集价格分布。