宇树 Go2 + NaVILA 全栈导航系统详解 (新手入门版)
文章目录
- [宇树 Go2 + NaVILA 全栈导航系统详解 (新手入门版)](#宇树 Go2 + NaVILA 全栈导航系统详解 (新手入门版))
-
- 第一部分:你的工作空间结构 (ROS 2 Workspace)
-
- [1. 机器人的躯体 (仿真与描述)](#1. 机器人的躯体 (仿真与描述))
- [2. 机器人的四肢 (导航与定位)](#2. 机器人的四肢 (导航与定位))
- [3. 机器人的大脑 (VLA - 本次核心)](#3. 机器人的大脑 (VLA - 本次核心))
- [第二部分:详细对比 ------ 官方 NaVILA vs. 我们魔改的 VLA](#第二部分:详细对比 —— 官方 NaVILA vs. 我们魔改的 VLA)
-
- [方案一:官方建议的 NaVILA 方案(不仅要用 Python,还要用最好的显卡)](#方案一:官方建议的 NaVILA 方案(不仅要用 Python,还要用最好的显卡))
- [方案二:我们为你部署的轻量化 VLA 方案 (Client-Server)](#方案二:我们为你部署的轻量化 VLA 方案 (Client-Server))
-
- [1. 后台大脑 (The Brain - Server)](#1. 后台大脑 (The Brain - Server))
- [2. 眼睛与传令兵 (The Vision Client - Upper Layer)](#2. 眼睛与传令兵 (The Vision Client - Upper Layer))
- [3. 四肢执行者 (The Executor - Lower Layer)](#3. 四肢执行者 (The Executor - Lower Layer))
- [第三部分:强化学习 (RL) 与 NaVILA (VLA) 的技术双雄](#第三部分:强化学习 (RL) 与 NaVILA (VLA) 的技术双雄)
-
- [1. NaVILA (VLA) ------ 机器人的"通感大脑"](#1. NaVILA (VLA) —— 机器人的“通感大脑”)
- [2. 强化学习 (RL) ------ 像训狗一样的"试错学习"](#2. 强化学习 (RL) —— 像训狗一样的“试错学习”)
-
- 核心原理:巴甫洛夫的狗
- [RL 如何部署?(Sim-to-Real)](#RL 如何部署?(Sim-to-Real))
- [3. 总结:NaVILA vs. RL ------ 都在哪儿用?](#3. 总结:NaVILA vs. RL —— 都在哪儿用?)
- [第四部分:1km 级全局自动导航的秘密](#第四部分:1km 级全局自动导航的秘密)
- [第五部分:终极形态 ------ 分层导航组队 (The Team)](#第五部分:终极形态 —— 分层导航组队 (The Team))
- [第六部分:进阶玩法 ------ 特定领域微调 (Domain Adaptation)](#第六部分:进阶玩法 —— 特定领域微调 (Domain Adaptation))
第一部分:你的工作空间结构 (ROS 2 Workspace)
想象你的 ROS2-Gazebo-GO2 文件夹是一个机器人工厂。
1. 机器人的躯体 (仿真与描述)
这些包负责在电脑里"画"出机器人,并模拟物理环境。
go2_description/: 这里面放着 Go2 机器人的"图纸"(模型文件、关节定义)。它告诉 ROS:哪里是腿、哪里是头。gazebo_sim/: 这是一个由 Gazebo 软件驱动的"虚拟世界"。机器人就在这里面跑。quadropted_controller/: 这是机器人的"小脑"。它负责把"向前走 1 米"这种高级指令,拆解成四条腿 12 个电机每毫秒该怎么转的微操指令。
2. 机器人的四肢 (导航与定位)
navigation2/: 这是一个成熟的导航系统(Nav2),负责规划路径、避障。cartographer/: 这是一个绘图师(SLAM),负责边走边画地图。
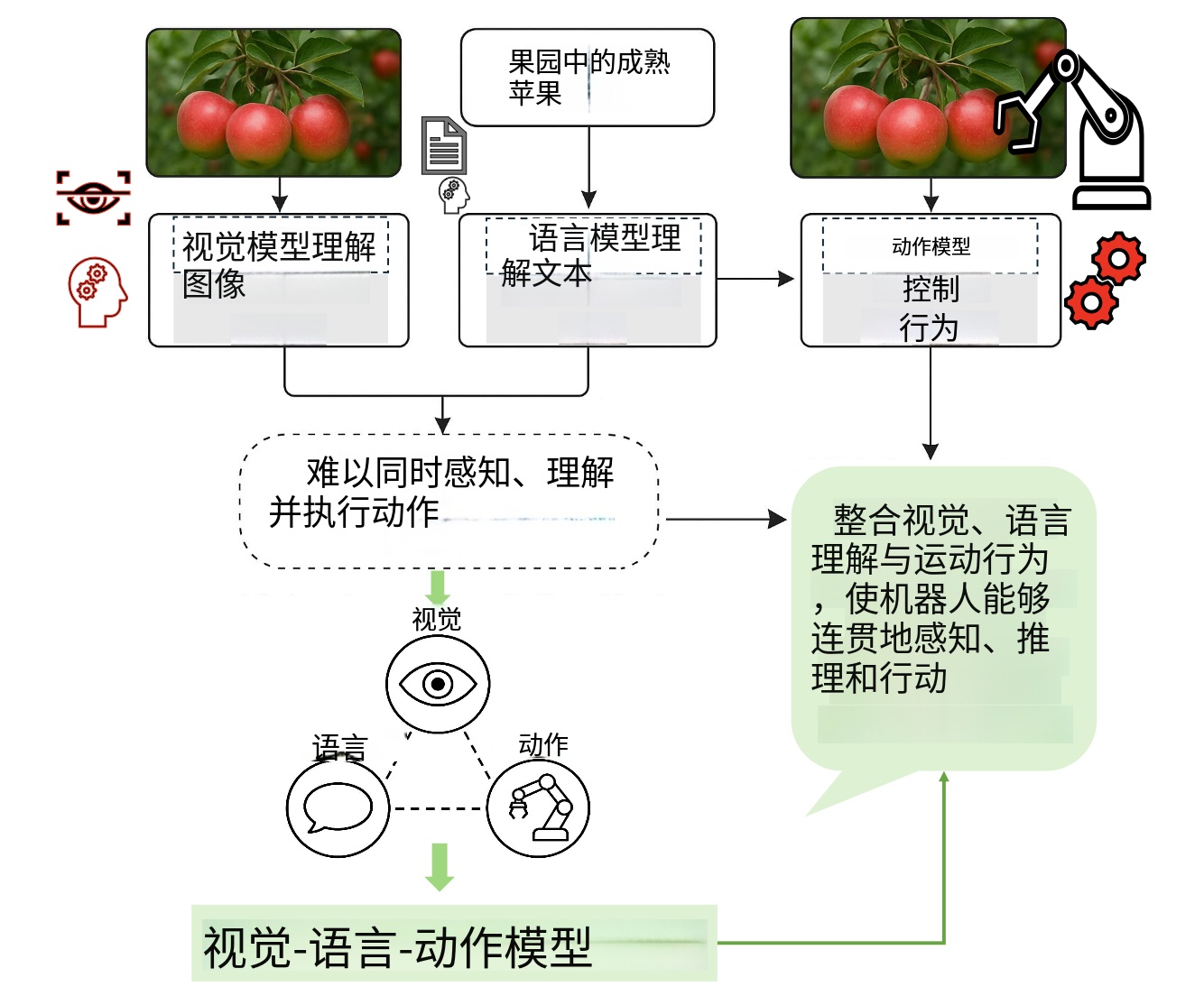
3. 机器人的大脑 (VLA - 本次核心)
vla_bridge/: 这是我们重点关注的包。VLA 是 Visual-Language-Action 的缩写,意思是"视觉-语言-动作"。它的作用是让机器人像人一样思考:"看到红灯 -> 知道要停 -> 踩刹车"。

第二部分:详细对比 ------ 官方 NaVILA vs. 我们魔改的 VLA
这就是从"只会听死命令的机器"进化到"能看懂图的智能体"的关键。
方案一:官方建议的 NaVILA 方案(不仅要用 Python,还要用最好的显卡)
官方 NaVILA (Navigation with Video Language Agents) 是一个庞大的神经网络系统。如果你有一台带 RTX 4090 的电脑,流程是这样的:
- 文件位置 :
NaVILA-main文件夹。 - 核心代码 :
llava/model/: 这里是模型的核心架构。它把图像编码器(Vision Encoder)和语言模型(LLM)拼接在一起。llava/eval/run_navigation.py: 这是官方的运行脚本。它会加载 PyTorch 库,把好几个 G 的模型一股脑塞进显存。
- 运行逻辑 :
- 第一步: 摄像头拍下一张照片 -> Python 代码用 PyTorch 读取。
- 第二步 (最重): 整个 PyTorch 模型 (7B 或更多参数) 在显卡上全速运转,进行数亿次计算。
- 第三步: 模型直接输出文本 "move forward"。
- 与 ROS 的联系 :
- 官方代码本身只是跑 AI 的,它不认识 ROS。所以你之前提供的
na_vila_node.py(原始版) 其实是一个胶水代码。它一边引用庞大的 NaVILA 库,一边连着 ROS。
- 官方代码本身只是跑 AI 的,它不认识 ROS。所以你之前提供的
- 为什么 Jetson 跑不动 :
- 它需要加载的库太多 (Transformers, Accelerator, DeepSpeed...)。
- 它需要的显存太大 (跑起来可能要 16GB+ 纯显存)。
- Jetson 只有共享内存,很容易就把内存撑爆(OOM),然后程序直接崩溃。
方案二:我们为你部署的轻量化 VLA 方案 (Client-Server)
我们做的所有努力,都是为了让大象能在钢丝上跳舞。我们抛弃了臃肿的 PyTorch,换上了精简的 C++ 引擎。
核心思想:脑体分离(Client-Server 架构)
1. 后台大脑 (The Brain - Server)
- 使用的是什么 :
llama.cpp的llama-server。 - 作用 :
- 这是最占资源的部分。它在后台默默运行,霸占了 Jetson 大部分的内存和算力。
- 它不关心你是机器人还是聊天软件,它只提供一个像网址一样的接口 (HTTP API)。
- 关键关联 : 它加载了那两个 GGUF 模型文件(你看到的
navila-llm...gguf和mmproj...gguf)。这俩文件就是先把 NaVILA 模型"压缩"(量化)后的产物。
2. 眼睛与传令兵 (The Vision Client - Upper Layer)
- 使用的是什么 :
na_vila_node.py(修改版)。 - 作用 :
- 它极度轻量,只用很少的内存。
- 输入 : 订阅
/robot1/color/image_raw(机器人的眼睛)。 - 处理 : 它不思考,它只是把图片打包,通过网络发给后台那个
llama-server(大脑)。 - 修正 (Hack): 当大脑有时候犯傻(在那瞎描述"这是个冰淇淋")时,这个传令兵会根据很多规则(if-else),强行把这些话翻译成"前进"。
- 输出 : 发布
/vla/action话题,内容是一句简单的文本指令,比如 "move forward 1m"。
3. 四肢执行者 (The Executor - Lower Layer)
- 使用的是什么 :
action_parser_node.py。 - 作用 :
- 这就好比是一个不懂大道理,只知道干活的司机。
- 输入 : 监听
/vla/action。 - 处理: 它收到 "move forward 1m" 这种文本。它会用正则表达式(Regex)去解析数字。
- 输出 : 它算出发了持续时间和速度,然后发布
/robot1/cmd_vel。 - 物理联系 :
/cmd_vel是 ROS 里的标准控制指令,quadropted_controller(小脑)听到这个指令后,就会真的去驱动电机,让狗腿子动起来。
第三部分:强化学习 (RL) 与 NaVILA (VLA) 的技术双雄
我们用通俗易懂的比喻来拆解这两个当下最火的技术方向。
1. NaVILA (VLA) ------ 机器人的"通感大脑"
模型原理:它是怎么被"组装"出来的?
这就好比造一个"贾维斯",由三个核心部件拼装而成:
- 眼睛(Vision Encoder):像视神经,把图片(光信号)转成电脑能懂的数字(电信号)。
- 桥梁(Projector):像翻译官,把视觉信号翻译成大脑能懂的语言信号。
- 大脑(LLM):像决策中心,结合图片和指令思考,吐出"向前走"的文字。
它是如何训练出来的?(三步走)
- 第1阶段:预训练(Pre-training):学会"看图说话"。给它看几亿张图,让翻译官和大脑磨合。如果不走路只描述图片,就是停留在这个阶段。
- 第2阶段:指令微调(Instruction Tuning) :学会"听话照做"。喂给它导航教材:
输入:走廊图+去厨房 -> 输出:前进1米。这是 NaVILA 的核心。 - 第3阶段:微调(Fine-tuning) :变成"特种兵"。在特定办公室收集数据训练,适应环境 (Domain Adaptation)。
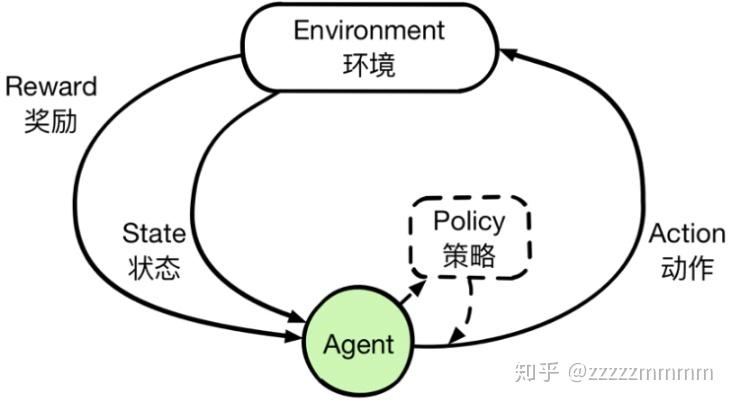
2. 强化学习 (RL) ------ 像训狗一样的"试错学习"
核心原理:巴甫洛夫的狗
强化学习不告诉机器"迈多大步",而是让它试:
- 走得稳 -> 给饼干 (Reward +1)。
- 摔倒了 -> 打屁股 (Reward -10) 。
经过几亿次试错,它就练成了完美的平衡和步态。
RL 如何部署?(Sim-to-Real)
- 仿真中训练 : 在 Isaac Gym 里让几千只狗同时跑,训练出一个策略网络 (Policy Network)(几百 KB)。
- 部署到真机: 把这个小文件拷贝到 Jetson 上。
- 实际运行 : 接收电机角度和 IMU 数据,高频输出电机扭矩,保证平衡。
3. 总结:NaVILA vs. RL ------ 都在哪儿用?
| 特性 | NaVILA (VLA) | 强化学习 (RL) |
|---|---|---|
| 角色 | 大脑 (决策层) | 小脑 (控制层) |
| 输入 | 图像、自然语言 ("去厨房") | 传感器数据 (角度、速度、重力) |
| 输出 | 高级指令 ("向前走") | 低级指令 (关节扭矩) |
| 思考速度 | 慢 (每秒 1-5 次) | 极快 (每秒 50-500 次) |
| 能力 | 理解世界,规划路径 | 保持平衡,走梅花桩 |
第四部分:1km 级全局自动导航的秘密
视频里机器狗狂奔一公里,靠的不是 VLA(路痴),而是 SLAM + 导航栈。
第一步:建图 (Mapping)
- 工具 :
Cartographer。 - 过程: 遥控机器人走一遍,雷达疯狂扫描,画出一张巨型地图。
第二步:定位 (Localization)
- 问题: 我在哪?
- 方案: 室内用 AMCL(看墙角对比地图);室外用 GPS/RTK(看卫星定位)。
第三步:规划与控制 (Planning & Control)
- 工具 :
navigation2(Nav2)。 - 全局规划: 战略家。在地图上画出从起点到终点的绿线 (A* 算法)。
- 局部规划: 战术家。躲避突然出现的障碍物,绕回绿线。
第五部分:终极形态 ------ 分层导航组队 (The Team)
如何结合以上所有技术?我们组建一个"车队":
第一层:战略官 (Global Planner - GPS/Nav2)
- 任务: 宏观导航。
- 指令: "去 800米 外的便利店"。不管细节,只管带路到附近。
第二层:战术官 (VLA - NaVILA)
- 任务: 语义导航与微操。
- 场景: 到便利店门口了,GPS 精度不够。
- 指令: "看到自动门了吗?往中间走,别撞玻璃"。VLA 接管,理解环境语义。
第三层:安全官 (Safety Filter - Nav2)
- 任务: 避障保底。
- 工作: VLA 说往前走,但雷达发现地上有快递盒。安全官强行修改指令,绕过去。
第四层:执行官 (Controller - RL)
- 任务: 运动控制。
- 工作 : 无论上层谁发令,RL 永远在线。它负责控制 12 个电机瞬间出力,保证机器人保持平衡,把腿迈出去。

第六部分:进阶玩法 ------ 特定领域微调 (Domain Adaptation)
想让机器人在你的办公室里表现得像"特种兵"?
步骤一:数据收集 (Data Collection)
- 当"教练"。遥控机器人在办公室走,录制
ros bag:- 图像 (Image)
- 任务 (Text): "Go to the printer"
- 操作 (Action): "前进0.5, 左转0.2..."
步骤二:数据处理 (Data Processing)
- 把数据切成一对一对的训练样本:
- Input :
<Image> + "Target: Go to the printer" - Label :
<nav>_forward_0.5_left_0.2
- Input :
步骤三:高效微调 (LoRA Training)
- 原理: 冻结大脑,外挂"补丁"。
- 训练: 只训练 LoRA 补丁,让它记住"在这个光线下的灰地毯上,去打印机要直走"。单张 4090 显卡即可完成。
步骤四:部署 (Deployment)
- 启动
llama-server时,加载 基础模型 + 你的LoRA补丁。 - 现在,你的机器人就是你办公室的"地头蛇"了。