一、研究背景
本代码是针对多特征分类任务的深度学习模型对比研究。在机器学习和深度学习应用中,针对不同的数据类型和任务特点,选择合适的网络架构至关重要。本研究旨在通过对比LSTM、CNN和CNN-LSTM三种主流的深度学习模型在相同数据集上的表现,为实际应用中选择合适模型提供依据。
研究意义:
- 实践指导:帮助研究人员在实际问题中快速选择合适的网络架构
- 性能评估:提供系统化的模型评估框架和可视化分析
- 教学价值:展示不同深度学习模型的特点和适用场景
二、主要功能
1. 数据预处理模块
- 支持Excel格式数据读取
- 自动划分训练集和测试集(7:3比例)
- 数据归一化处理(mapminmax,0-1标准化)
- 为不同模型准备适配的数据格式
2. 模型构建模块
- LSTM模型:处理序列数据,捕捉时间依赖关系
- CNN模型:提取局部特征,适用于空间模式识别
- CNN-LSTM混合模型:结合CNN的特征提取能力和LSTM的时序建模能力
3. 训练评估模块
- 统一的训练参数设置
- 自动化模型训练和验证
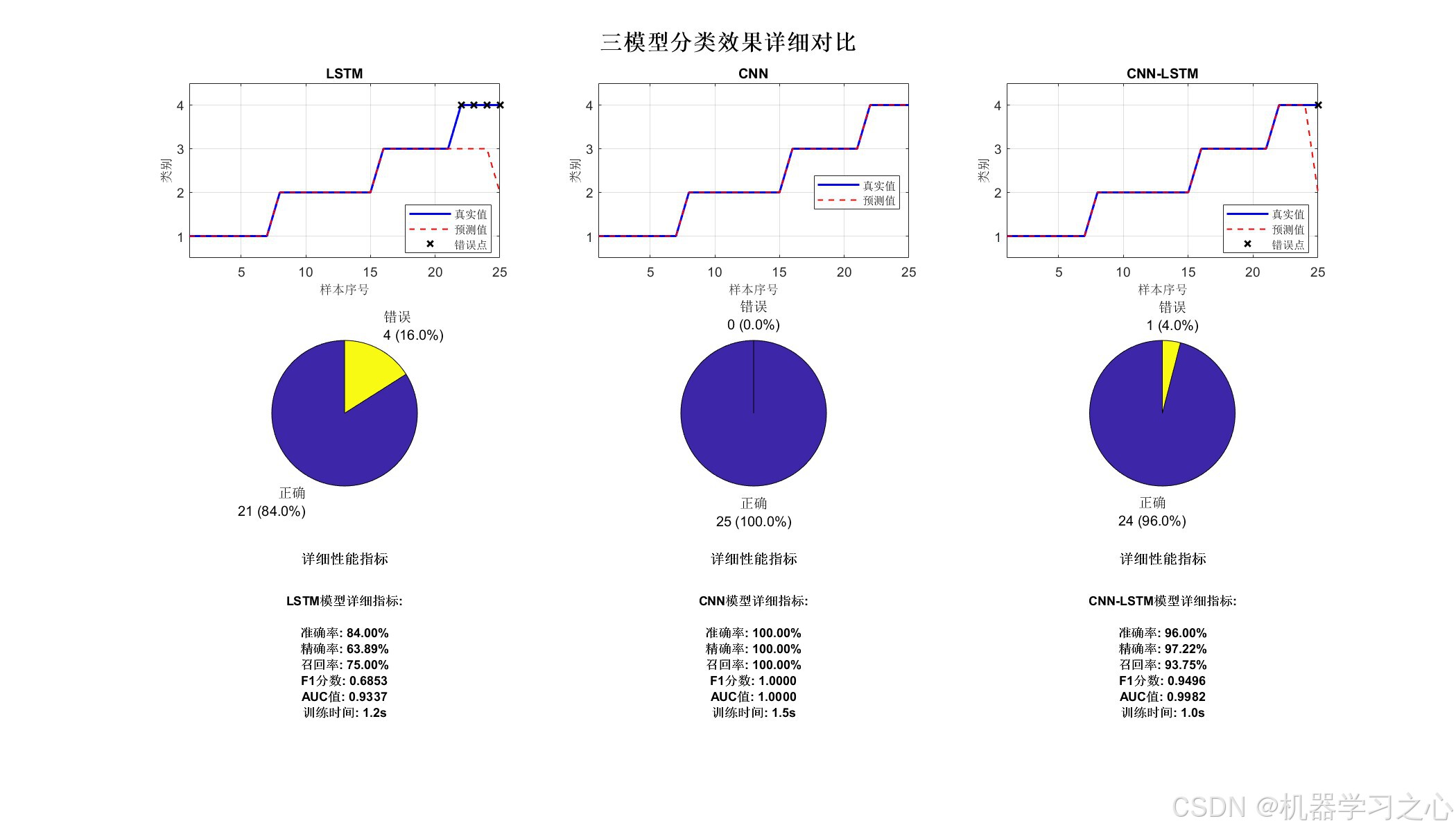
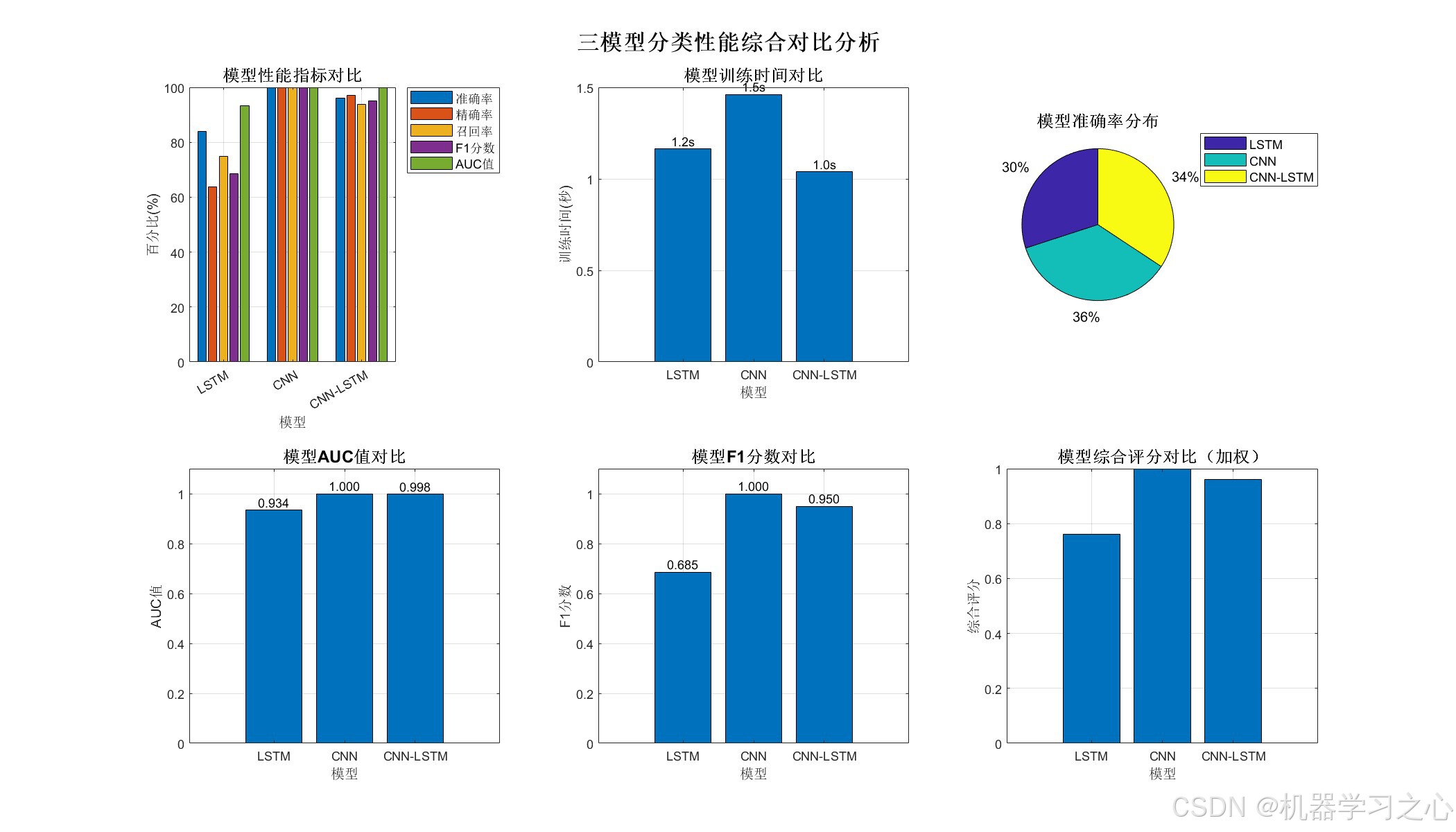
- 多维度性能评估(6个评估指标)
4. 可视化分析模块
- 指标对比柱状图
- 训练时间分析
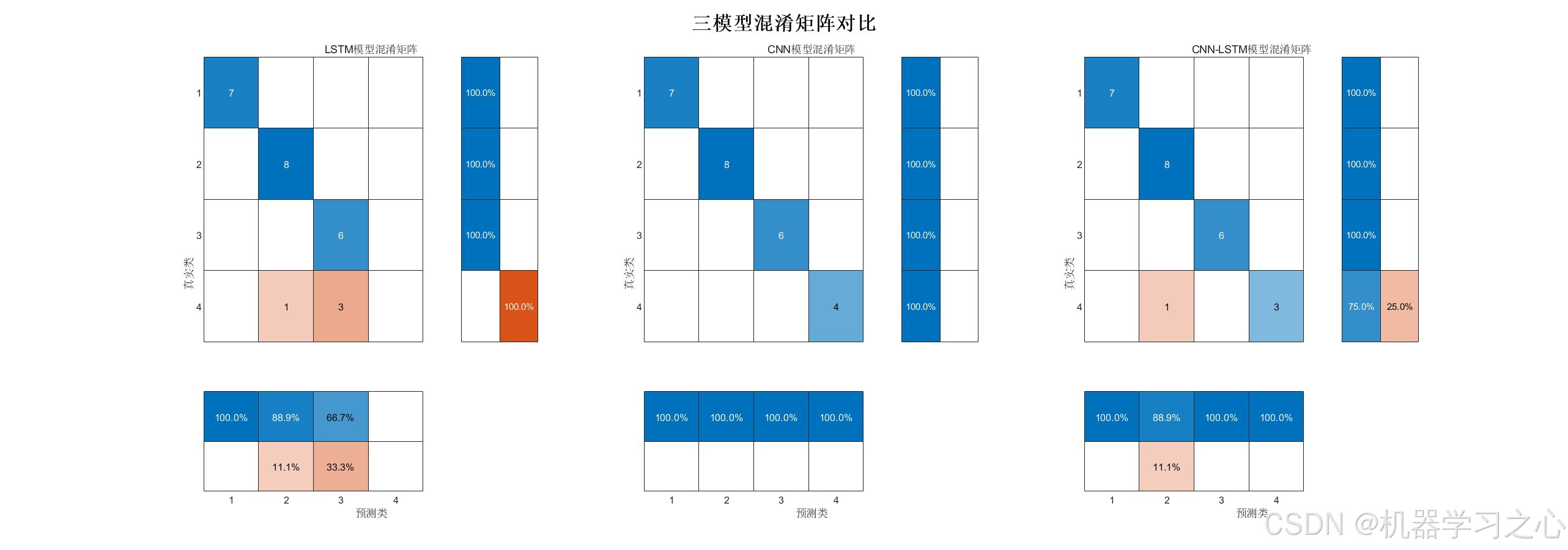
- 混淆矩阵对比
- 预测效果可视化
- 综合评分分析
三、算法步骤
整体流程:
数据读取 → 数据预处理 → 模型构建 → 模型训练 → 性能评估 → 可视化分析详细步骤:
-
数据准备阶段
读取Excel数据 → 分析数据维度 → 数据打乱 → 划分训练测试集 → 数据归一化 -
模型训练阶段
设置训练参数 → 准备数据格式 → 模型初始化 → 迭代训练 → 保存模型 -
评估分析阶段
测试集预测 → 计算评估指标 → 性能对比 → 可视化展示
四、技术路线
1. 数据处理技术
- 特征工程:自动识别特征维度和类别数
- 数据标准化:使用min-max归一化方法
- 类别平衡:按类别比例划分训练测试集
2. 模型架构技术
matlab
% LSTM模型架构
sequenceInputLayer → lstmLayer → dropoutLayer → fullyConnectedLayer → softmaxLayer
% CNN模型架构
imageInputLayer → convolution2dLayer → batchNormalizationLayer → reluLayer → poolingLayer
% CNN-LSTM混合架构
sequenceInputLayer → CNN层 → flattenLayer → lstmLayer → 全连接层3. 训练优化技术
- 优化算法:Adam优化器
- 学习率调度:分段式学习率衰减
- 正则化:Dropout层防止过拟合
五、公式原理
1. LSTM单元公式
遗忘门:f_t = σ(W_f·[h_{t-1}, x_t] + b_f)
输入门:i_t = σ(W_i·[h_{t-1}, x_t] + b_i)
候选值:C̃_t = tanh(W_C·[h_{t-1}, x_t] + b_C)
细胞状态:C_t = f_t ⊙ C_{t-1} + i_t ⊙ C̃_t
输出门:o_t = σ(W_o·[h_{t-1}, x_t] + b_o)
隐状态:h_t = o_t ⊙ tanh(C_t)2. 卷积运算公式
输出特征图:Y[i,j,k] = Σ_{m} Σ_{n} X[i+m-1, j+n-1, l] · W[m, n, l, k] + b[k]
其中:(m,n)为卷积核尺寸,l为输入通道,k为输出通道3. 评估指标公式
准确率:Accuracy = (TP+TN)/(TP+TN+FP+FN)
精确率:Precision = TP/(TP+FP)
召回率:Recall = TP/(TP+FN)
F1分数:F1 = 2·Precision·Recall/(Precision+Recall)
AUC:ROC曲线下的面积4. 损失函数
交叉熵损失:L = -Σ_{c=1}^M y_{o,c} log(p_{o,c})
其中:M为类别数,y为真实标签,p为预测概率六、参数设定
1. 数据参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
| data_file | 'data.xlsx' | 数据文件路径 |
| train_ratio | 0.7 | 训练集比例 |
| shuffle_data | 1 | 是否打乱数据 |
2. 模型结构参数
| 模型 | LSTM单元数 | CNN卷积核 | 全连接层 |
|---|---|---|---|
| LSTM | 32 | - | num_class |
| CNN | - | 8, 16 | num_class |
| CNN-LSTM | 32 | 8, 16 | num_class |
3. 训练参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
| max_epochs | 100 | 最大训练轮数 |
| mini_batch_size | 64 | 批处理大小 |
| initial_learn_rate | 0.001 | 初始学习率 |
| LearnRateDropFactor | 0.5 | 学习率衰减因子 |
| LearnRateDropPeriod | 50 | 学习率衰减周期 |
4. 评估参数
| 参数名 | 默认值 | 说明 |
|---|---|---|
| flag_confusion | 1 | 是否绘制混淆矩阵 |
| flag_all_plots | 1 | 是否绘制所有图表 |
七、运行环境
软件要求
- 操作系统:Windows
- MATLAB版本:R2020b及以上
依赖文件
- 数据文件:data.xlsx(需包含特征数据和标签列)
扩展应用
1. 自定义模型
用户可以根据需要修改模型结构:
matlab
% 示例:增加LSTM层数
lstm_layers = [
sequenceInputLayer(num_dim)
lstmLayer(64, 'OutputMode', 'sequence')
lstmLayer(32, 'OutputMode', 'last')
dropoutLayer(0.3)
fullyConnectedLayer(num_class)
softmaxLayer
classificationLayer];2. 添加新评估指标
可以在calculate_metrics函数中添加更多评估指标,如:
- Kappa系数
- Matthews相关系数
- 对数损失
3. 支持其他数据格式
修改数据读取部分以支持CSV、MAT等格式:
matlab
% 支持CSV格式
res = readtable('data.csv');
res = table2array(res);注意事项
-
数据格式要求:
- 最后一列为标签列
- 前N-1列为特征列
- 标签应为整数(1,2,3,...)
-
类别数量限制:
- 混淆矩阵在类别数≤10时自动生成
- 类别过多时可手动调整
flag_confusion参数
-
训练时间预估:
- CNN模型训练通常最快
- LSTM模型训练时间中等
- CNN-LSTM模型训练时间最长