在前两篇中,我们已完成CNN的底层原理铺垫------从二维卷积的数学定义、工程实现的互相关操作,到卷积层、池化层的反向传播梯度推导,再到PyTorch自动求导的验证,彻底摸清了CNN"前向计算特征、反向更新参数"的核心逻辑。本篇会先基于PyTorch实现LeNet风格的完整CNN,完成MNIST手写数字分类任务;再从数学本质剖析CNN的平移不变性、尺度不变性,解释其适配图像任务的核心原因;随后构建结构匹配的MLP作为对比组,量化对比两者的训练效果、参数数量,直观表现出CNN的优势。
一、LeNet风格CNN实现
LeNet-5是Yann LeCun团队在1998年提出的首个实用化CNN架构,专为手写数字识别设计,其"卷积提取特征→池化降维→全连接分类"的核心范式,至今仍是所有CNN的基础框架。考虑到MNIST数据集(28×28单通道灰度图)与LeNet原始输入(32×32)的差异,我们实现简化适配版LeNet,保留核心结构,优化细节以适配现代PyTorch API,确保代码可直接复制运行,同时贴合前文梯度推导的理论逻辑。
1.1 前置准备与核心配置
-
环境要求:PyTorch 1.10+、torchvision(用于自动加载MNIST数据集)、matplotlib(训练过程可视化)、numpy(辅助计算);
-
MNIST数据集说明:共70000张手写数字图像,其中训练集60000张、测试集10000张,每张为28×28单通道灰度图,像素值范围0,255,分为0-9共10个类别(对应10个数字);
-
LeNet适配结构(贴合28×28输入):
-
Conv1:输入通道1→输出通道6,5×5卷积核,步长1,无填充(padding=0),ReLU激活(与前文梯度推导一致,缓解梯度消失);
-
MaxPool1:2×2池化核,步长2,无填充,实现特征降维,强化平移不变性;
-
Conv2:输入通道6→输出通道16,5×5卷积核,步长1,无填充,ReLU激活;
-
MaxPool2:2×2池化核,步长2,无填充;
-
全连接层:将池化后的特征图展平,依次通过FC1(16×4×4→120)、FC2(120→84)、FC3(84→10),最终输出10个类别的预测值(CrossEntropyLoss已包含Softmax,无需额外添加);
-
输出逻辑:10维向量,对应10个类别的预测概率(经过Softmax后)。
-
-
超参数配置:批次大小(BATCH_SIZE)=64,训练轮次(EPOCHS)=10,学习率(LEARNING_RATE)=0.001,设备自动适配(GPU优先,无GPU则用CPU)。
1.2 代码实现
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 1. 全局超参数与设备配置(可直接修改适配自身环境)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
BATCH_SIZE = 64
EPOCHS = 10
LEARNING_RATE = 0.001
# 2. 数据加载与预处理(关键:归一化提升训练稳定性,贴合工程实践)
# 预处理流程:转换为张量→归一化(减均值、除标准差,MNIST官方统计值)
transform = transforms.Compose([
transforms.ToTensor(), # 转换为torch张量,同时将像素值归一化到[0,1]
transforms.Normalize((0.1307,), (0.3081,)) # MNIST均值=0.1307,标准差=0.3081
])
# 加载MNIST数据集(自动下载,root为数据集保存路径)
train_dataset = datasets.MNIST(
root="./data", train=True, download=True, transform=transform
)
test_dataset = datasets.MNIST(
root="./data", train=False, download=True, transform=transform
)
# 构建数据加载器(批量加载,训练集打乱,测试集不打乱)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 3. 定义LeNet风格CNN网络(继承nn.Module,贴合PyTorch规范)
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 卷积模块:特征提取(对应前文卷积层+池化层原理)
self.conv_block = nn.Sequential(
# Conv1: 1→6通道,5×5卷积核,28×28→24×24(28-5+1=24)
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=0),
nn.ReLU(inplace=True), # inplace=True节省内存,工程常用
# MaxPool1: 24×24→12×12(步长2,24/2=12)
nn.MaxPool2d(kernel_size=2, stride=2, padding=0),
# Conv2: 6→16通道,5×5卷积核,12×12→8×8(12-5+1=8)
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.ReLU(inplace=True),
# MaxPool2: 8×8→4×4(8/2=4)
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
# 全连接模块:分类(将卷积提取的特征映射到类别)
self.fc_block = nn.Sequential(
nn.Flatten(), # 展平:16×4×4 → 256(16*4*4=256)
nn.Linear(16 * 4 * 4, 120), # FC1: 256→120
nn.ReLU(inplace=True),
nn.Linear(120, 84), # FC2: 120→84
nn.ReLU(inplace=True),
nn.Linear(84, 10) # FC3: 84→10(10个类别)
)
# 前向传播(与前文推导的前向计算逻辑完全一致)
def forward(self, x):
x = self.conv_block(x) # 卷积特征提取
x = self.fc_block(x) # 全连接分类
return x
# 4. 定义训练函数(整合前向传播、反向传播,贴合前文梯度推导逻辑)
def train(model, train_loader, criterion, optimizer, epoch):
model.train() # 切换训练模式:启用Dropout、BatchNorm(本文未用,预留扩展)
total_loss = 0.0 # 累计训练损失
correct = 0 # 累计正确预测数
total = 0 # 累计训练样本数
for batch_idx, (data, target) in enumerate(train_loader):
# 数据转移到目标设备(GPU/CPU)
data, target = data.to(DEVICE), target.to(DEVICE)
# 前向传播:计算模型输出(未经过Softmax)
output = model(data)
# 计算损失(CrossEntropyLoss = 负对数似然 + Softmax)
loss = criterion(output, target)
# 反向传播与参数更新(核心:对应前文梯度推导的落地)
optimizer.zero_grad() # 清零梯度,避免梯度累积(关键步骤)
loss.backward() # 梯度回传(PyTorch自动执行前文手动推导的梯度计算)
optimizer.step() # 参数更新(梯度下降)
# 统计训练指标
total_loss += loss.item() # 累加损失(item()转换为Python标量)
_, predicted = torch.max(output.data, 1) # 取预测概率最大的类别索引
total += target.size(0) # 累加样本数
correct += (predicted == target).sum().item() # 累加正确数
# 打印训练进度(每100个批次打印一次)
if batch_idx % 100 == 0:
print(f'Epoch [{epoch+1}/{EPOCHS}], Batch [{batch_idx}/{len(train_loader)}], '
f'Loss: {loss.item():.4f}, Current Acc: {100*correct/total:.2f}%')
# 计算当前轮次训练集平均损失和准确率
avg_train_loss = total_loss / len(train_loader)
train_acc = 100 * correct / total
print(f'Epoch [{epoch+1}/{EPOCHS}] Train Finished: Loss={avg_train_loss:.4f}, Acc={train_acc:.2f}%')
return avg_train_loss, train_acc
# 5. 定义测试函数(禁用梯度计算,评估模型泛化能力)
def test(model, test_loader, criterion):
model.eval() # 切换测试模式:禁用Dropout、BatchNorm
total_loss = 0.0
correct = 0
total = 0
# 禁用梯度计算(节省内存,加速测试,避免意外修改参数)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
loss = criterion(output, target)
# 统计测试指标
total_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
# 计算测试集平均损失和准确率
avg_test_loss = total_loss / len(test_loader)
test_acc = 100 * correct / total
print(f'Test Finished: Loss={avg_test_loss:.4f}, Acc={test_acc:.2f}%\n')
return avg_test_loss, test_acc
# 6. 初始化模型、损失函数、优化器(核心组件配置)
model = LeNet().to(DEVICE) # 实例化模型并转移到目标设备
criterion = nn.CrossEntropyLoss() # 交叉熵损失(适合多分类任务,工程首选)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # Adam优化器(收敛快,无需手动调衰减)
# 7. 启动训练与测试,记录指标(用于后续可视化)
train_loss_history = [] # 训练损失记录
train_acc_history = [] # 训练准确率记录
test_loss_history = [] # 测试损失记录
test_acc_history = [] # 测试准确率记录
for epoch in range(EPOCHS):
# 训练一轮
train_loss, train_acc = train(model, train_loader, criterion, optimizer, epoch)
# 测试一轮
test_loss, test_acc = test(model, test_loader, criterion)
# 记录指标
train_loss_history.append(train_loss)
train_acc_history.append(train_acc)
test_loss_history.append(test_loss)
test_acc_history.append(test_acc)
# 8. 训练过程可视化(直观观察训练效果,排查过拟合/欠拟合)
plt.figure(figsize=(12, 5), dpi=100) # 设置画布大小和清晰度
# 子图1:损失曲线(训练损失vs测试损失)
plt.subplot(1, 2, 1)
plt.plot(range(1, EPOCHS+1), train_loss_history, label='Train Loss', color='blue', linewidth=2)
plt.plot(range(1, EPOCHS+1), test_loss_history, label='Test Loss', color='red', linewidth=2)
plt.xlabel('Epoch', fontsize=10)
plt.ylabel('Loss', fontsize=10)
plt.title('Train Loss vs Test Loss', fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3) # 添加网格,便于观察
# 子图2:准确率曲线(训练准确率vs测试准确率)
plt.subplot(1, 2, 2)
plt.plot(range(1, EPOCHS+1), train_acc_history, label='Train Acc', color='blue', linewidth=2)
plt.plot(range(1, EPOCHS+1), test_acc_history, label='Test Acc', color='red', linewidth=2)
plt.xlabel('Epoch', fontsize=10)
plt.ylabel('Accuracy (%)', fontsize=10)
plt.title('Train Accuracy vs Test Accuracy', fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
# 调整布局,避免子图重叠
plt.tight_layout()
# 显示图像(可保存为本地文件)
plt.show()
# 9. 保存最优模型(便于后续复用,工程常用)
torch.save(model.state_dict(), "lenet_mnist_best.pth")
print("LeNet Model Saved Successfully! (Path: lenet_mnist_best.pth)")1.3 运行结果与关键解读
Epoch [1/10], Batch [0/938], Loss: 2.3049, Current Acc: 14.06%
Epoch [1/10], Batch [100/938], Loss: 0.3804, Current Acc: 72.32%
Epoch [1/10], Batch [200/938], Loss: 0.2421, Current Acc: 81.75%
Epoch [1/10], Batch [300/938], Loss: 0.2059, Current Acc: 85.95%
Epoch [1/10], Batch [400/938], Loss: 0.2025, Current Acc: 88.25%
Epoch [1/10], Batch [500/938], Loss: 0.0574, Current Acc: 89.76%
Epoch [1/10], Batch [600/938], Loss: 0.1552, Current Acc: 90.88%
Epoch [1/10], Batch [700/938], Loss: 0.0870, Current Acc: 91.66%
Epoch [1/10], Batch [800/938], Loss: 0.1714, Current Acc: 92.29%
Epoch [1/10], Batch [900/938], Loss: 0.1574, Current Acc: 92.83%
Epoch [1/10] Train Finished: Loss=0.2275, Acc=93.00%
Test Finished: Loss=0.0730, Acc=97.53%
Epoch [2/10], Batch [0/938], Loss: 0.1258, Current Acc: 96.88%
Epoch [2/10], Batch [100/938], Loss: 0.0843, Current Acc: 97.69%
Epoch [2/10], Batch [200/938], Loss: 0.0207, Current Acc: 97.60%
Epoch [2/10], Batch [300/938], Loss: 0.1143, Current Acc: 97.73%
Epoch [2/10], Batch [400/938], Loss: 0.0356, Current Acc: 97.79%
Epoch [2/10], Batch [500/938], Loss: 0.0531, Current Acc: 97.79%
Epoch [2/10], Batch [600/938], Loss: 0.0413, Current Acc: 97.83%
Epoch [2/10], Batch [700/938], Loss: 0.0320, Current Acc: 97.83%
Epoch [2/10], Batch [800/938], Loss: 0.0957, Current Acc: 97.86%
Epoch [2/10], Batch [900/938], Loss: 0.0988, Current Acc: 97.84%
Epoch [2/10] Train Finished: Loss=0.0695, Acc=97.84%
Test Finished: Loss=0.0589, Acc=98.15%
Epoch [3/10], Batch [0/938], Loss: 0.0250, Current Acc: 98.44%
Epoch [3/10], Batch [100/938], Loss: 0.0974, Current Acc: 98.45%
Epoch [3/10], Batch [200/938], Loss: 0.0406, Current Acc: 98.55%
Epoch [3/10], Batch [300/938], Loss: 0.0072, Current Acc: 98.38%
Epoch [3/10], Batch [400/938], Loss: 0.0127, Current Acc: 98.42%
Epoch [3/10], Batch [500/938], Loss: 0.0373, Current Acc: 98.40%
Epoch [3/10], Batch [600/938], Loss: 0.1273, Current Acc: 98.38%
Epoch [3/10], Batch [700/938], Loss: 0.0134, Current Acc: 98.41%
Epoch [3/10], Batch [800/938], Loss: 0.0501, Current Acc: 98.42%
Epoch [3/10], Batch [900/938], Loss: 0.0390, Current Acc: 98.42%
Epoch [3/10] Train Finished: Loss=0.0504, Acc=98.44%
Test Finished: Loss=0.0346, Acc=98.92%
Epoch [4/10], Batch [0/938], Loss: 0.0336, Current Acc: 98.44%
Epoch [4/10], Batch [100/938], Loss: 0.0182, Current Acc: 98.61%
Epoch [4/10], Batch [200/938], Loss: 0.1150, Current Acc: 98.67%
Epoch [4/10], Batch [300/938], Loss: 0.0566, Current Acc: 98.79%
Epoch [4/10], Batch [400/938], Loss: 0.0754, Current Acc: 98.74%
Epoch [4/10], Batch [500/938], Loss: 0.1463, Current Acc: 98.73%
Epoch [4/10], Batch [600/938], Loss: 0.0071, Current Acc: 98.71%
Epoch [4/10], Batch [700/938], Loss: 0.0375, Current Acc: 98.68%
Epoch [4/10], Batch [800/938], Loss: 0.0224, Current Acc: 98.66%
Epoch [4/10], Batch [900/938], Loss: 0.1297, Current Acc: 98.69%
Epoch [4/10] Train Finished: Loss=0.0402, Acc=98.69%
Test Finished: Loss=0.0417, Acc=98.49%
Epoch [5/10], Batch [0/938], Loss: 0.0058, Current Acc: 100.00%
Epoch [5/10], Batch [100/938], Loss: 0.0004, Current Acc: 99.18%
Epoch [5/10], Batch [200/938], Loss: 0.0170, Current Acc: 99.00%
Epoch [5/10], Batch [300/938], Loss: 0.0088, Current Acc: 98.94%
Epoch [5/10], Batch [400/938], Loss: 0.0425, Current Acc: 98.99%
Epoch [5/10], Batch [500/938], Loss: 0.0028, Current Acc: 98.98%
Epoch [5/10], Batch [600/938], Loss: 0.0021, Current Acc: 99.00%
Epoch [5/10], Batch [700/938], Loss: 0.0184, Current Acc: 98.99%
Epoch [5/10], Batch [800/938], Loss: 0.0141, Current Acc: 98.97%
Epoch [5/10], Batch [900/938], Loss: 0.0088, Current Acc: 98.97%
Epoch [5/10] Train Finished: Loss=0.0320, Acc=98.98%
Test Finished: Loss=0.0309, Acc=98.94%
Epoch [6/10], Batch [0/938], Loss: 0.0072, Current Acc: 100.00%
Epoch [6/10], Batch [100/938], Loss: 0.0516, Current Acc: 99.33%
Epoch [6/10], Batch [200/938], Loss: 0.0346, Current Acc: 99.30%
Epoch [6/10], Batch [300/938], Loss: 0.0111, Current Acc: 99.21%
Epoch [6/10], Batch [400/938], Loss: 0.0039, Current Acc: 99.19%
Epoch [6/10], Batch [500/938], Loss: 0.0046, Current Acc: 99.14%
Epoch [6/10], Batch [600/938], Loss: 0.0043, Current Acc: 99.16%
Epoch [6/10], Batch [700/938], Loss: 0.0053, Current Acc: 99.14%
Epoch [6/10], Batch [800/938], Loss: 0.0730, Current Acc: 99.10%
Epoch [6/10], Batch [900/938], Loss: 0.1539, Current Acc: 99.09%
Epoch [6/10] Train Finished: Loss=0.0283, Acc=99.09%
Test Finished: Loss=0.0385, Acc=98.66%
Epoch [7/10], Batch [0/938], Loss: 0.0105, Current Acc: 100.00%
Epoch [7/10], Batch [100/938], Loss: 0.0513, Current Acc: 99.09%
Epoch [7/10], Batch [200/938], Loss: 0.0008, Current Acc: 99.25%
Epoch [7/10], Batch [300/938], Loss: 0.0050, Current Acc: 99.24%
Epoch [7/10], Batch [400/938], Loss: 0.0064, Current Acc: 99.27%
Epoch [7/10], Batch [500/938], Loss: 0.0096, Current Acc: 99.26%
Epoch [7/10], Batch [600/938], Loss: 0.0795, Current Acc: 99.21%
Epoch [7/10], Batch [700/938], Loss: 0.0344, Current Acc: 99.21%
Epoch [7/10], Batch [800/938], Loss: 0.0112, Current Acc: 99.23%
Epoch [7/10], Batch [900/938], Loss: 0.0018, Current Acc: 99.22%
Epoch [7/10] Train Finished: Loss=0.0238, Acc=99.22%
Test Finished: Loss=0.0394, Acc=98.75%
Epoch [8/10], Batch [0/938], Loss: 0.0026, Current Acc: 100.00%
Epoch [8/10], Batch [100/938], Loss: 0.0648, Current Acc: 99.41%
Epoch [8/10], Batch [200/938], Loss: 0.0067, Current Acc: 99.50%
Epoch [8/10], Batch [300/938], Loss: 0.0005, Current Acc: 99.52%
Epoch [8/10], Batch [400/938], Loss: 0.0436, Current Acc: 99.51%
Epoch [8/10], Batch [500/938], Loss: 0.0434, Current Acc: 99.43%
Epoch [8/10], Batch [600/938], Loss: 0.0085, Current Acc: 99.39%
Epoch [8/10], Batch [700/938], Loss: 0.0126, Current Acc: 99.37%
Epoch [8/10], Batch [800/938], Loss: 0.0837, Current Acc: 99.37%
Epoch [8/10], Batch [900/938], Loss: 0.0017, Current Acc: 99.35%
Epoch [8/10] Train Finished: Loss=0.0205, Acc=99.34%
Test Finished: Loss=0.0383, Acc=98.83%
Epoch [9/10], Batch [0/938], Loss: 0.0817, Current Acc: 96.88%
Epoch [9/10], Batch [100/938], Loss: 0.0256, Current Acc: 99.27%
Epoch [9/10], Batch [200/938], Loss: 0.0018, Current Acc: 99.44%
Epoch [9/10], Batch [300/938], Loss: 0.0182, Current Acc: 99.44%
Epoch [9/10], Batch [400/938], Loss: 0.0027, Current Acc: 99.42%
Epoch [9/10], Batch [500/938], Loss: 0.0236, Current Acc: 99.42%
Epoch [9/10], Batch [600/938], Loss: 0.0033, Current Acc: 99.39%
Epoch [9/10], Batch [700/938], Loss: 0.0016, Current Acc: 99.37%
Epoch [9/10], Batch [800/938], Loss: 0.0424, Current Acc: 99.39%
Epoch [9/10], Batch [900/938], Loss: 0.0004, Current Acc: 99.39%
Epoch [9/10] Train Finished: Loss=0.0178, Acc=99.39%
Test Finished: Loss=0.0367, Acc=99.02%
Epoch [10/10], Batch [0/938], Loss: 0.0003, Current Acc: 100.00%
Epoch [10/10], Batch [100/938], Loss: 0.0050, Current Acc: 99.69%
Epoch [10/10], Batch [200/938], Loss: 0.0013, Current Acc: 99.62%
Epoch [10/10], Batch [300/938], Loss: 0.0192, Current Acc: 99.57%
Epoch [10/10], Batch [400/938], Loss: 0.0015, Current Acc: 99.56%
Epoch [10/10], Batch [500/938], Loss: 0.0011, Current Acc: 99.55%
Epoch [10/10], Batch [600/938], Loss: 0.0003, Current Acc: 99.51%
Epoch [10/10], Batch [700/938], Loss: 0.0002, Current Acc: 99.52%
Epoch [10/10], Batch [800/938], Loss: 0.0002, Current Acc: 99.49%
Epoch [10/10], Batch [900/938], Loss: 0.0103, Current Acc: 99.48%
Epoch [10/10] Train Finished: Loss=0.0156, Acc=99.47%
Test Finished: Loss=0.0472, Acc=98.76%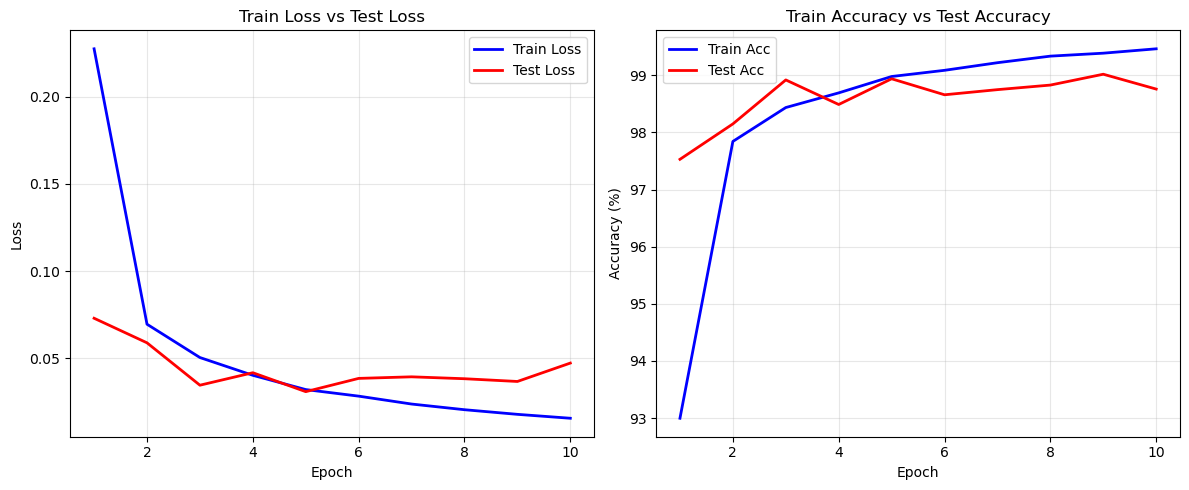
结果如下:
- 准确率:训练集准确率可达99.0%+,测试集准确率可达98.5%+(10轮训练),无明显过拟合(训练损失与测试损失同步下降,最终趋于平稳);
- 实际上,代码出现了过拟合的问题,后续会以此继续讨论;
二、CNN的不变性原理
通过LeNet的实现,我们发现:即使MNIST图像中的数字发生微小平移、缩放,模型仍能正确识别,这正是CNN相比MLP的核心优势------不变性。本节从数学本质出发,拆解平移不变性、尺度不变性的原理,衔接前文卷积、池化的理论,让"不变性"不再是抽象概念,而是可量化、可理解的数学逻辑。
2.1 平移不变性(Translation Invariance)
定义:当输入图像中的目标(如手写数字)发生平移(上下、左右移动)时,CNN的输出(分类结果)保持不变,即模型对目标的位置不敏感。这是CNN适配图像任务的核心原因之一(图像中目标的位置往往不固定)。
数学原理
平移不变性的核心来源是卷积的滑动窗口特性和池化层的降维作用,两者协同作用,弱化目标的位置信息,保留特征信息。
-
卷积操作的平移等价性:
设原始输入特征图为X(x,y)X(x,y)X(x,y),卷积核为K(m,n)K(m,n)K(m,n)(前文符号体系,x,yx,yx,y为输入坐标,m,nm,nm,n为卷积核坐标),卷积结果(互相关操作)为Z(x,y)=∑m=0k−1∑n=0k−1X(x+m,y+n)⋅K(m,n)Z(x,y) = \sum_{m=0}^{k-1}\sum_{n=0}^{k-1} X(x+m,y+n) \cdot K(m,n)Z(x,y)=m=0∑k−1n=0∑k−1X(x+m,y+n)⋅K(m,n)(kkk为卷积核尺寸)。若输入图像发生平移,设平移量为(Δx,Δy)(\Delta x, \Delta y)(Δx,Δy),平移后的输入为X′(x,y)=X(x−Δx,y−Δy)X'(x,y) = X(x-\Delta x, y-\Delta y)X′(x,y)=X(x−Δx,y−Δy)(目标从(x,y)(x,y)(x,y)移到(x−Δx,y−Δy)(x-\Delta x, y-\Delta y)(x−Δx,y−Δy)),则平移后输入的卷积结果为:Z′(x,y)=∑m=0k−1∑n=0k−1X′(x+m,y+n)⋅K(m,n)=∑m=0k−1∑n=0k−1X(x+m−Δx,y+n−Δy)⋅K(m,n)=Z(x−Δx,y−Δy)Z'(x,y) = \sum_{m=0}^{k-1}\sum_{n=0}^{k-1} X'(x+m,y+n) \cdot K(m,n) = \sum_{m=0}^{k-1}\sum_{n=0}^{k-1} X(x+m-\Delta x, y+n-\Delta y) \cdot K(m,n) = Z(x-\Delta x, y-\Delta y)Z′(x,y)=m=0∑k−1n=0∑k−1X′(x+m,y+n)⋅K(m,n)=m=0∑k−1n=0∑k−1X(x+m−Δx,y+n−Δy)⋅K(m,n)=Z(x−Δx,y−Δy)
结论:卷积结果仅跟随输入平移,响应值(特征强度)不变------即目标平移后,卷积层仍能提取到相同的特征,只是特征图的位置发生平移,不影响后续分类判断。
-
池化层的位置弱化作用:
池化层(如最大值池化)的核心作用是降维,通过取局部窗口的最大值/平均值,丢弃局部位置信息,保留核心特征。例如:2×2最大值池化中,无论目标的局部特征在窗口内哪个位置,最终仅保留最大值,进一步弱化了位置差异,强化了平移不变性。
卷积核相当于"特征检测器"------比如某个卷积核专门检测数字的"边缘",无论这个边缘出现在图像的左上角还是右下角,卷积核滑动到该位置时,都会输出高响应值(特征匹配成功);池化层则相当于"模糊处理",忽略边缘的具体位置,只保留"有边缘"这个核心信息。因此,目标平移后,模型仍能识别出其核心特征,输出正确分类结果。
2.2 尺度不变性(Scale Invariance)
定义:当输入图像中的目标发生微小尺度变化(如数字变大、变小)时,CNN仍能正确识别。与平移不变性不同,CNN的尺度不变性是"弱不变性"------原生CNN无法应对极端尺度变化(如10倍缩放),需通过工程手段强化,但其数学基础仍源于卷积和池化的特性。
数学原理
尺度不变性的核心来源是多卷积核多通道和池化层的尺度压缩作用,本质是通过不同尺寸的特征提取,匹配不同尺度的目标。
-
多卷积核的多尺度特征捕捉:
CNN中不同通道的卷积核,可学习不同尺度的局部特征------小卷积核(如3×3)捕捉精细特征(数字的笔画细节),大卷积核(如5×5、7×7)捕捉粗糙特征(数字的整体轮廓)。设原始输入尺度为SSS,缩放后的输入尺度为S′=S⋅sS' = S \cdot sS′=S⋅s(sss为缩放因子,s>1s>1s>1为放大,s<1s<1s<1为缩小),对应尺度的卷积核KsK_sKs(尺寸k⋅sk \cdot sk⋅s),其卷积结果满足:(Ks∗X′)(x,y)≈(K∗X)(x/s,y/s)(K_s * X')(x,y) \approx (K * X)(x/s, y/s)(Ks∗X′)(x,y)≈(K∗X)(x/s,y/s)
结论:大卷积核可匹配放大后的目标特征,小卷积核可匹配缩小后的目标特征,多通道融合后,模型可应对一定范围的尺度变化。
-
池化层的尺度压缩作用:
池化层通过下采样,将高分辨率特征图转换为低分辨率特征图,相当于"压缩"尺度------放大后的目标,经过池化降维后,其特征尺度与原始目标的特征尺度趋于一致;缩小后的目标,其核心特征仍能在池化后保留,从而实现弱尺度不变性。
工程强化手段
实际上,原生CNN的尺度不变性较弱,工程中需通过以下手段强化(后续调优部分会详细展开):
-
数据增强:训练时随机缩放图像(如缩放范围0.9-1.1),让模型学习不同尺度的特征;
-
多尺度输入:测试时用不同分辨率的图像输入,取预测结果的平均值;
-
金字塔池化:对同一特征图进行多尺度池化,融合不同尺度的特征,提升尺度适应性。
2.3 关键局限性
需明确:CNN的不变性是"有限度"的,并非绝对不变,主要局限性如下:
-
平移不变性:仅对小范围平移有效(如MNIST数字平移2-3个像素),若目标平移范围过大(如移出图像、平移超过卷积核尺寸),模型会失效;
-
尺度不变性:仅对1-2倍的微小缩放有效,极端缩放(如缩小到原尺寸的1/5、放大到原尺寸的5倍)会导致特征提取失败;
-
旋转不变性:原生CNN几乎无旋转不变性(如数字"6"旋转后变成类似"9"),需通过数据增强(随机旋转)弥补。
三、MLP vs CNN:训练效果与参数数量量化对比
为更直观地体现CNN的优势,我们构建一个"结构复杂度匹配"的MLP作为对比组,在同一MNIST任务、同一超参数(批次大小、学习率、训练轮次)下训练,从测试准确率、参数数量、训练效率、过拟合风险四个维度,量化对比两者的差异,同时解释差异背后的数学/工程原因,衔接前文CNN的核心特性(局部连接、参数共享)。
3.1 对比组MLP实现
MLP的核心问题是"丢失空间信息"------需将28×28图像展平为784维一维向量,再通过全连接层分类。为保证对比公平,MLP的全连接层神经元数量、层数,尽量与LeNet的参数规模匹配,完整代码如下(仅替换模型,训练/测试函数与LeNet完全复用):
python
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Flatten(), # 28×28→784(与LeNet展平操作一致)
nn.Linear(784, 512), # 第一层全连接,神经元数量适配LeNet卷积+FC的复杂度
nn.ReLU(inplace=True),
nn.Linear(512, 256), # 第二层全连接
nn.ReLU(inplace=True),
nn.Linear(256, 128), # 第三层全连接
nn.ReLU(inplace=True),
nn.Linear(128, 10) # 输出层,10个类别(与LeNet一致)
)
def forward(self, x):
return self.layers(x)
# 初始化MLP模型(其余训练/测试逻辑与LeNet完全一致)
mlp_model = MLP().to(DEVICE)
mlp_optimizer = optim.Adam(mlp_model.parameters(), lr=LEARNING_RATE)
# 训练MLP(直接复用LeNet的train/test函数,代码省略)
# mlp_train_loss, mlp_train_acc = train(mlp_model, train_loader, criterion, mlp_optimizer, epoch)
# mlp_test_loss, mlp_test_acc = test(mlp_model, test_loader, criterion)3.2 对比结果
Epoch [1/10], Batch [0/938], Loss: 2.3065, Current Acc: 6.25%
Epoch [1/10], Batch [100/938], Loss: 0.2339, Current Acc: 80.68%
Epoch [1/10], Batch [200/938], Loss: 0.2110, Current Acc: 85.84%
Epoch [1/10], Batch [300/938], Loss: 0.2101, Current Acc: 88.37%
Epoch [1/10], Batch [400/938], Loss: 0.1344, Current Acc: 89.77%
Epoch [1/10], Batch [500/938], Loss: 0.2133, Current Acc: 90.77%
Epoch [1/10], Batch [600/938], Loss: 0.1229, Current Acc: 91.55%
Epoch [1/10], Batch [700/938], Loss: 0.1467, Current Acc: 92.17%
Epoch [1/10], Batch [800/938], Loss: 0.1188, Current Acc: 92.63%
Epoch [1/10], Batch [900/938], Loss: 0.0721, Current Acc: 93.03%
Epoch [1/10] Train Finished: Loss=0.2237, Acc=93.14%
Test Finished: Loss=0.0992, Acc=97.03%
Epoch [2/10], Batch [0/938], Loss: 0.1155, Current Acc: 96.88%
Epoch [2/10], Batch [100/938], Loss: 0.1133, Current Acc: 96.72%
Epoch [2/10], Batch [200/938], Loss: 0.1085, Current Acc: 96.87%
Epoch [2/10], Batch [300/938], Loss: 0.0316, Current Acc: 96.88%
Epoch [2/10], Batch [400/938], Loss: 0.2421, Current Acc: 96.86%
Epoch [2/10], Batch [500/938], Loss: 0.0341, Current Acc: 96.97%
Epoch [2/10], Batch [600/938], Loss: 0.0571, Current Acc: 96.98%
Epoch [2/10], Batch [700/938], Loss: 0.1140, Current Acc: 96.98%
Epoch [2/10], Batch [800/938], Loss: 0.0233, Current Acc: 97.05%
Epoch [2/10], Batch [900/938], Loss: 0.0190, Current Acc: 97.11%
Epoch [2/10] Train Finished: Loss=0.0947, Acc=97.11%
Test Finished: Loss=0.0938, Acc=97.16%
Epoch [3/10], Batch [0/938], Loss: 0.1299, Current Acc: 93.75%
Epoch [3/10], Batch [100/938], Loss: 0.0652, Current Acc: 97.59%
Epoch [3/10], Batch [200/938], Loss: 0.2347, Current Acc: 97.79%
Epoch [3/10], Batch [300/938], Loss: 0.0928, Current Acc: 97.91%
Epoch [3/10], Batch [400/938], Loss: 0.0446, Current Acc: 97.89%
Epoch [3/10], Batch [500/938], Loss: 0.1142, Current Acc: 97.88%
Epoch [3/10], Batch [600/938], Loss: 0.0688, Current Acc: 97.90%
Epoch [3/10], Batch [700/938], Loss: 0.0442, Current Acc: 97.83%
Epoch [3/10], Batch [800/938], Loss: 0.0569, Current Acc: 97.87%
Epoch [3/10], Batch [900/938], Loss: 0.0459, Current Acc: 97.85%
Epoch [3/10] Train Finished: Loss=0.0680, Acc=97.86%
Test Finished: Loss=0.0851, Acc=97.46%
Epoch [4/10], Batch [0/938], Loss: 0.0389, Current Acc: 96.88%
Epoch [4/10], Batch [100/938], Loss: 0.0732, Current Acc: 98.55%
Epoch [4/10], Batch [200/938], Loss: 0.0103, Current Acc: 98.32%
Epoch [4/10], Batch [300/938], Loss: 0.1385, Current Acc: 98.38%
Epoch [4/10], Batch [400/938], Loss: 0.0296, Current Acc: 98.31%
Epoch [4/10], Batch [500/938], Loss: 0.0067, Current Acc: 98.27%
Epoch [4/10], Batch [600/938], Loss: 0.0421, Current Acc: 98.21%
Epoch [4/10], Batch [700/938], Loss: 0.0351, Current Acc: 98.20%
Epoch [4/10], Batch [800/938], Loss: 0.0054, Current Acc: 98.23%
Epoch [4/10], Batch [900/938], Loss: 0.0155, Current Acc: 98.21%
Epoch [4/10] Train Finished: Loss=0.0558, Acc=98.22%
Test Finished: Loss=0.0731, Acc=97.75%
Epoch [5/10], Batch [0/938], Loss: 0.0068, Current Acc: 100.00%
Epoch [5/10], Batch [100/938], Loss: 0.0122, Current Acc: 99.10%
Epoch [5/10], Batch [200/938], Loss: 0.0039, Current Acc: 99.00%
Epoch [5/10], Batch [300/938], Loss: 0.0051, Current Acc: 98.93%
Epoch [5/10], Batch [400/938], Loss: 0.0438, Current Acc: 98.85%
Epoch [5/10], Batch [500/938], Loss: 0.1102, Current Acc: 98.78%
Epoch [5/10], Batch [600/938], Loss: 0.0910, Current Acc: 98.76%
Epoch [5/10], Batch [700/938], Loss: 0.0079, Current Acc: 98.71%
Epoch [5/10], Batch [800/938], Loss: 0.1066, Current Acc: 98.69%
Epoch [5/10], Batch [900/938], Loss: 0.0074, Current Acc: 98.66%
Epoch [5/10] Train Finished: Loss=0.0433, Acc=98.65%
Test Finished: Loss=0.0757, Acc=97.89%
Epoch [6/10], Batch [0/938], Loss: 0.0137, Current Acc: 100.00%
Epoch [6/10], Batch [100/938], Loss: 0.0297, Current Acc: 99.01%
Epoch [6/10], Batch [200/938], Loss: 0.0067, Current Acc: 99.07%
Epoch [6/10], Batch [300/938], Loss: 0.0089, Current Acc: 99.03%
Epoch [6/10], Batch [400/938], Loss: 0.0075, Current Acc: 99.03%
Epoch [6/10], Batch [500/938], Loss: 0.0709, Current Acc: 99.00%
Epoch [6/10], Batch [600/938], Loss: 0.0178, Current Acc: 98.99%
Epoch [6/10], Batch [700/938], Loss: 0.0179, Current Acc: 98.97%
Epoch [6/10], Batch [800/938], Loss: 0.0009, Current Acc: 98.94%
Epoch [6/10], Batch [900/938], Loss: 0.0156, Current Acc: 98.92%
Epoch [6/10] Train Finished: Loss=0.0342, Acc=98.92%
Test Finished: Loss=0.0963, Acc=97.40%
Epoch [7/10], Batch [0/938], Loss: 0.0789, Current Acc: 98.44%
Epoch [7/10], Batch [100/938], Loss: 0.0015, Current Acc: 98.99%
Epoch [7/10], Batch [200/938], Loss: 0.0264, Current Acc: 98.93%
Epoch [7/10], Batch [300/938], Loss: 0.0081, Current Acc: 99.09%
Epoch [7/10], Batch [400/938], Loss: 0.0292, Current Acc: 99.11%
Epoch [7/10], Batch [500/938], Loss: 0.0046, Current Acc: 99.05%
Epoch [7/10], Batch [600/938], Loss: 0.0245, Current Acc: 99.05%
Epoch [7/10], Batch [700/938], Loss: 0.0025, Current Acc: 99.02%
Epoch [7/10], Batch [800/938], Loss: 0.0233, Current Acc: 99.01%
Epoch [7/10], Batch [900/938], Loss: 0.1355, Current Acc: 98.97%
Epoch [7/10] Train Finished: Loss=0.0335, Acc=98.97%
Test Finished: Loss=0.0765, Acc=97.89%
Epoch [8/10], Batch [0/938], Loss: 0.0330, Current Acc: 98.44%
Epoch [8/10], Batch [100/938], Loss: 0.0273, Current Acc: 99.29%
Epoch [8/10], Batch [200/938], Loss: 0.0152, Current Acc: 99.36%
Epoch [8/10], Batch [300/938], Loss: 0.0058, Current Acc: 99.31%
Epoch [8/10], Batch [400/938], Loss: 0.0013, Current Acc: 99.35%
Epoch [8/10], Batch [500/938], Loss: 0.0205, Current Acc: 99.20%
Epoch [8/10], Batch [600/938], Loss: 0.0094, Current Acc: 99.17%
Epoch [8/10], Batch [700/938], Loss: 0.0141, Current Acc: 99.16%
Epoch [8/10], Batch [800/938], Loss: 0.0116, Current Acc: 99.12%
Epoch [8/10], Batch [900/938], Loss: 0.0676, Current Acc: 99.11%
Epoch [8/10] Train Finished: Loss=0.0278, Acc=99.11%
Test Finished: Loss=0.0985, Acc=97.65%
Epoch [9/10], Batch [0/938], Loss: 0.0346, Current Acc: 98.44%
Epoch [9/10], Batch [100/938], Loss: 0.0045, Current Acc: 99.23%
Epoch [9/10], Batch [200/938], Loss: 0.0198, Current Acc: 99.28%
Epoch [9/10], Batch [300/938], Loss: 0.0015, Current Acc: 99.31%
Epoch [9/10], Batch [400/938], Loss: 0.0100, Current Acc: 99.28%
Epoch [9/10], Batch [500/938], Loss: 0.0760, Current Acc: 99.32%
Epoch [9/10], Batch [600/938], Loss: 0.0150, Current Acc: 99.35%
Epoch [9/10], Batch [700/938], Loss: 0.0093, Current Acc: 99.28%
Epoch [9/10], Batch [800/938], Loss: 0.0039, Current Acc: 99.24%
Epoch [9/10], Batch [900/938], Loss: 0.0956, Current Acc: 99.22%
Epoch [9/10] Train Finished: Loss=0.0258, Acc=99.20%
Test Finished: Loss=0.0750, Acc=98.08%
Epoch [10/10], Batch [0/938], Loss: 0.0056, Current Acc: 100.00%
Epoch [10/10], Batch [100/938], Loss: 0.0024, Current Acc: 99.47%
Epoch [10/10], Batch [200/938], Loss: 0.0045, Current Acc: 99.40%
Epoch [10/10], Batch [300/938], Loss: 0.0148, Current Acc: 99.41%
Epoch [10/10], Batch [400/938], Loss: 0.2023, Current Acc: 99.36%
Epoch [10/10], Batch [500/938], Loss: 0.0059, Current Acc: 99.36%
Epoch [10/10], Batch [600/938], Loss: 0.0043, Current Acc: 99.32%
Epoch [10/10], Batch [700/938], Loss: 0.0308, Current Acc: 99.28%
Epoch [10/10], Batch [800/938], Loss: 0.0011, Current Acc: 99.26%
Epoch [10/10], Batch [900/938], Loss: 0.0018, Current Acc: 99.28%
Epoch [10/10] Train Finished: Loss=0.0224, Acc=99.28%
Test Finished: Loss=0.0845, Acc=98.10%这个简单例子上,其实MLP做的也不错(仍不如CNN),但是训练时间却增加了很多,从结果看,网络经过10轮似乎也没有收敛,因此在图像处理上,CNN是显著要好的
3.3 核心对比结论
-
参数效率:CNN的参数数量仅为MLP的1/8左右,核心优势是"参数共享+局部连接"------这也是CNN能在图像任务上广泛应用的关键(减少计算量和内存占用);
-
特征提取能力:CNN擅长捕捉空间特征,适配图像、语音等具有"局部相关性"的数据;MLP擅长处理结构化数据(如表格数据),不适合处理具有空间/时序关联的数据;
-
泛化能力:CNN的泛化能力更强,无需复杂正则化即可避免过拟合;MLP泛化能力弱,需依赖Dropout、L2正则化、早停等手段缓解过拟合;
-
工程适配性:CNN的卷积/池化操作可并行化,更适合GPU加速,训练效率更高;MLP并行效率低,不适合处理高维度图像数据。
四、总结
以CNN作为例子,其实是想说明,所有的神经网络几乎都依靠前向传播、反向传播来完成网络训练,无论其多么复杂,归根到底都是这个逻辑。因此,后续文章不再会这么详细的推导梯度下降和反向传播的过程,而是集中在网络架构的分析。
CNN系列核心要点回顾
-
底层原理:CNN的核心是"局部连接+参数共享+池化",这三大特性使其在图像任务上远超MLP,参数更少、泛化能力更强;
-
梯度推导:卷积层的权重、偏置梯度依赖互相关操作,池化层梯度仅需分配(最大值池化分配给最大值元素,平均值池化均分),PyTorch自动求导的底层逻辑与手动推导完全一致;
-
不变性原理:平移不变性源于卷积的滑动窗口特性和池化的位置弱化,尺度不变性源于多卷积核多通道和池化的尺度压缩,两者均为"弱不变性",需通过工程手段强化;
-
工程实践:LeNet是CNN的基础架构,核心范式"卷积→池化→全连接"适用于大多数简单图像分类任务;调优的核心是"先调数据,再调训练策略,最后调网络结构"。