文章目录
- 一、AlexNet:点燃深度学习复兴的"导火索"
-
- [1. 激活函数:从Sigmoid到ReLU的革命](#1. 激活函数:从Sigmoid到ReLU的革命)
- [2. 防止过拟合:Dropout的智慧](#2. 防止过拟合:Dropout的智慧)
- [3. 池化层:重叠池化(Overlapping Pooling)](#3. 池化层:重叠池化(Overlapping Pooling))
- [4. 归一化](#4. 归一化)
-
- [4.1 Feature Normalization(特征归一化)](#4.1 Feature Normalization(特征归一化))
- [4.2 Batch Normalization(批量归一化)](#4.2 Batch Normalization(批量归一化))
- 二、VGGNet:极简主义的胜利
-
- [1. 设计哲学:一切皆为3x3卷积](#1. 设计哲学:一切皆为3x3卷积)
- [2. 感受野的几何级数增长](#2. 感受野的几何级数增长)
- [3. VGG的网络结构](#3. VGG的网络结构)
- 三、ResNet:解决"网络越深,性能越差"的残差革命
-
- [1. 网络退化:为什么更深的网络反而更差?](#1. 网络退化:为什么更深的网络反而更差?)
- [2. 核心创新:残差连接(Residual Connection)](#2. 核心创新:残差连接(Residual Connection))
-
- [2.1 残差块的结构](#2.1 残差块的结构)
- [2.2 为什么残差连接能解决退化问题?](#2.2 为什么残差连接能解决退化问题?)
- [3. 关键技术:1×1卷积与瓶颈结构(Bottleneck)](#3. 关键技术:1×1卷积与瓶颈结构(Bottleneck))
-
- [3.1 1×1卷积的作用:降维与升维](#3.1 1×1卷积的作用:降维与升维)
- [3.2 瓶颈结构(Bottleneck)](#3.2 瓶颈结构(Bottleneck))
- [4. 维度匹配:当输入与输出维度不一致时](#4. 维度匹配:当输入与输出维度不一致时)
-
- [4.1 方案一:对短路连接 x x x 进行卷积变换](#4.1 方案一:对短路连接 x x x 进行卷积变换)
- [4.2 方案二:对 x x x 进行池化和零填充(较少使用)](#4.2 方案二:对 x x x 进行池化和零填充(较少使用))
- [5. ResNet的网络结构](#5. ResNet的网络结构)
- 四、总结:从AlexNet到ResNet的演进
- 五、彩蛋01:残差连接多角度理解
-
- [1. 先看直观比喻:"抄近路"的智慧](#1. 先看直观比喻:“抄近路”的智慧)
- [2. 数学视角:从"学习映射"到"学习差值"](#2. 数学视角:从“学习映射”到“学习差值”)
- [3. 梯度视角:解决梯度消失的"高速公路"](#3. 梯度视角:解决梯度消失的“高速公路”)
- [4. 结构示例:两种残差块](#4. 结构示例:两种残差块)
-
- [① 基本残差块(Basic Block)------用于 ResNet-18/34](#① 基本残差块(Basic Block)——用于 ResNet-18/34)
- [② 瓶颈残差块(Bottleneck Block)------用于 ResNet-50/101/152](#② 瓶颈残差块(Bottleneck Block)——用于 ResNet-50/101/152)
- [5. 维度不匹配怎么办?](#5. 维度不匹配怎么办?)
- 总结
- 六、彩蛋02:参数量计算练习
-
- 题目
- 解析(可跳过直接看答案)
-
-
- [1. 维度计算(逐阶段验证)](#1. 维度计算(逐阶段验证))
- [2. 参数量计算(卷积层)(了解即可)](#2. 参数量计算(卷积层)(了解即可))
- [3. 全连接层参数量(了解即可)](#3. 全连接层参数量(了解即可))
-
- 答案速查
在掌握了卷积、池化、全连接等核心组件后,我们来学习两个里程碑式的经典网络:AlexNet 和 VGGNet。它们不仅在图像分类任务上取得了突破性成绩,更奠定了现代卷积神经网络的设计范式。本文将从 AlexNet 的四大创新点入手,再过渡到 VGGNet 的极简设计哲学。
一、AlexNet:点燃深度学习复兴的"导火索"
2012年,AlexNet在ImageNet图像分类竞赛中以远超第二名的成绩夺冠,一举证明了深度卷积神经网络的强大能力,开启了深度学习的黄金时代。它的成功,离不开以下四大关键创新。
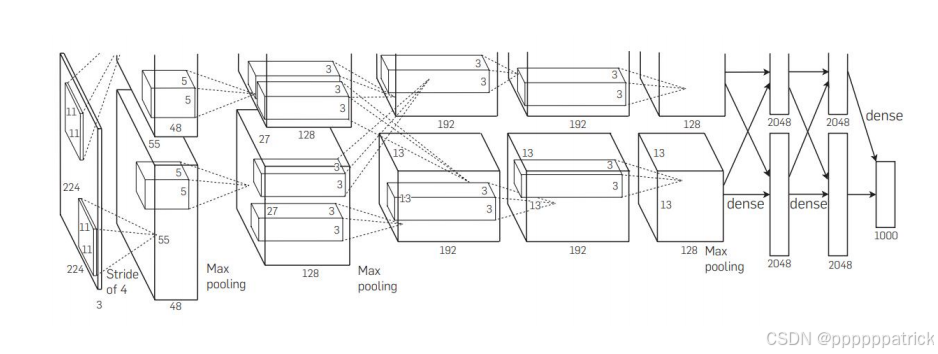
1. 激活函数:从Sigmoid到ReLU的革命
在AlexNet之前,Sigmoid是主流的激活函数,但它存在严重的梯度消失 问题,导致深层网络难以训练。AlexNet首次大规模使用了ReLU激活函数,带来了革命性的改变:
- 缓解梯度消失:在正区间,ReLU的梯度恒为1,避免了Sigmoid在输入过大或过小时梯度趋近于0的问题。
- 计算高效 :ReLU的计算仅需一个阈值判断
max(0, x),比Sigmoid的指数运算快得多。 - 加速收敛:使用ReLU的网络收敛速度比使用Sigmoid快数倍。
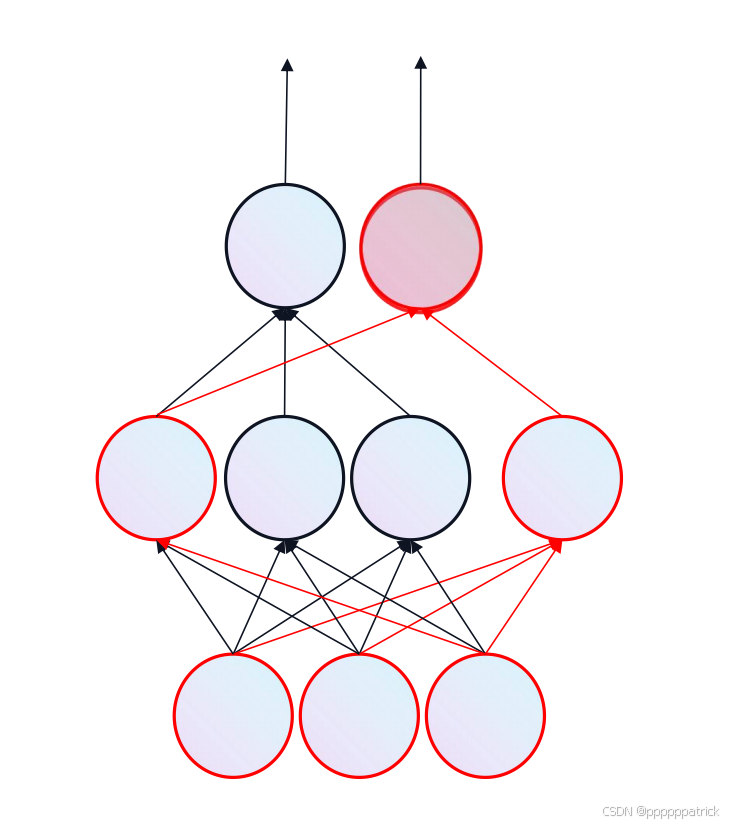
2. 防止过拟合:Dropout的智慧
深度神经网络强大的拟合能力也使其容易"死记硬背"训练数据,导致在测试集上表现糟糕,即过拟合 。AlexNet引入了Dropout技术来解决这个问题:
- 工作原理:在训练过程中,随机"丢弃"(将输出置为0)一部分隐藏层的神经元,迫使网络不能依赖于某些特定的神经元,从而学习到更鲁棒的特征。
- 效果 :显著降低了模型的过拟合风险,提升了泛化能力。在AlexNet中,Dropout被应用在全连接层。
3. 池化层:重叠池化(Overlapping Pooling)
传统的池化操作(如2x2,步长2)不会产生重叠,而AlexNet使用了重叠池化 (如3x3,步长2):
- 定义:池化核的尺寸大于步长,使得池化窗口之间产生重叠。
- 优势 :
- 减少了特征图的尺寸,同时保留了更多的细节信息。
- 增强了模型的鲁棒性,对输入的微小变化不那么敏感。
- 有助于减少过拟合。
4. 归一化
神经网络对输入数据的尺度非常敏感。如果不同特征的取值范围差异巨大,会导致训练困难、收敛缓慢。AlexNet引入了局部响应归一化(LRN, Local Response Normalization),虽然现在更多被Batch Norm取代,但其背后的归一化思想至关重要。
4.1 Feature Normalization(特征归一化)
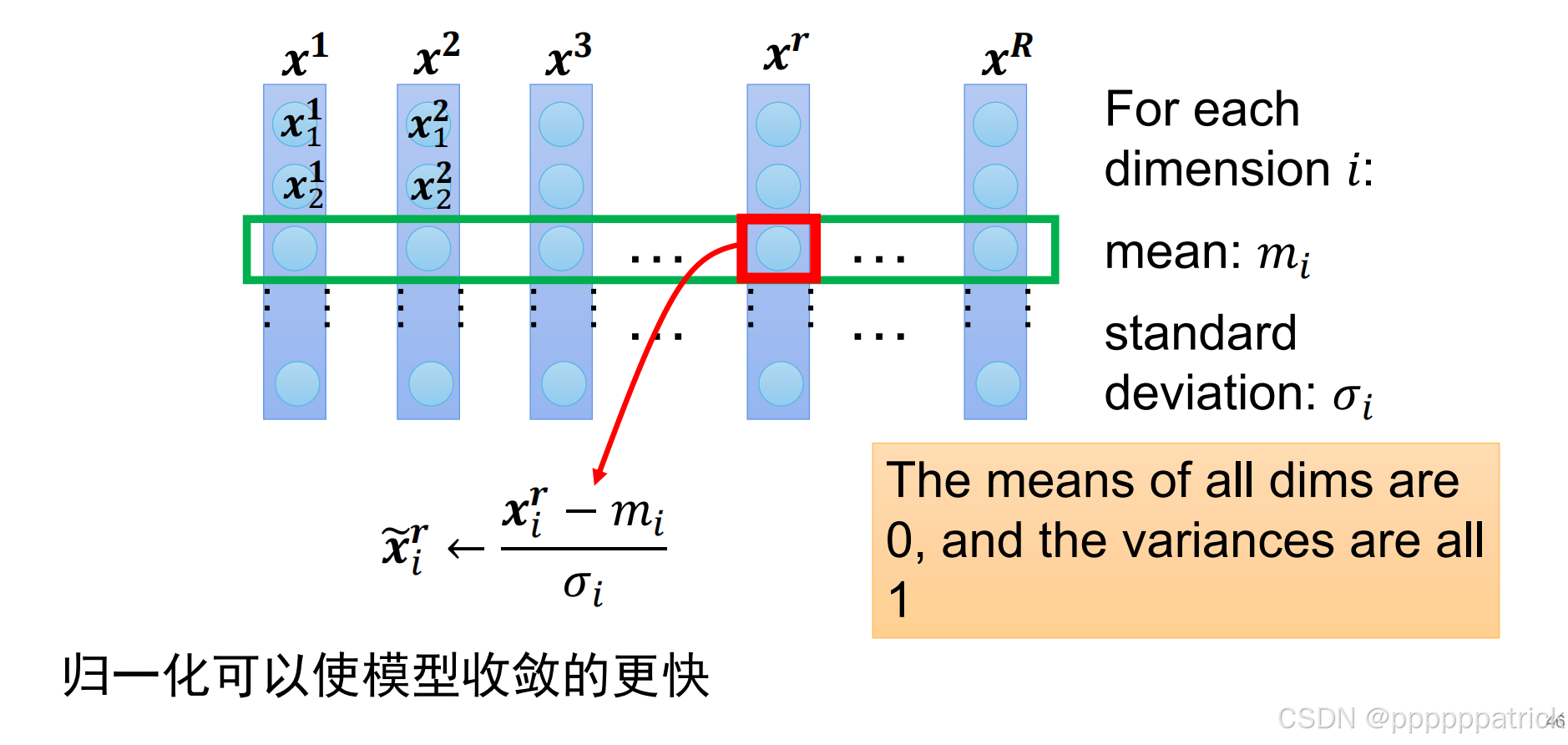
这是对输入数据或特征进行的预处理,核心思想是让数据分布更"规矩"。
- 公式 :对每个特征维度 i i i,计算其在整个数据集上的均值 m i m_i mi 和标准差 σ i \sigma_i σi,然后进行标准化:
x ~ i r = x i r − m i σ i \widetilde{x}_i^r = \frac{x_i^r - m_i}{\sigma_i} x ir=σixir−mi - 效果:处理后,所有特征的均值为0,方差为1。这消除了不同特征尺度不一的影响,让梯度下降更平稳,模型收敛更快。
4.2 Batch Normalization(批量归一化)
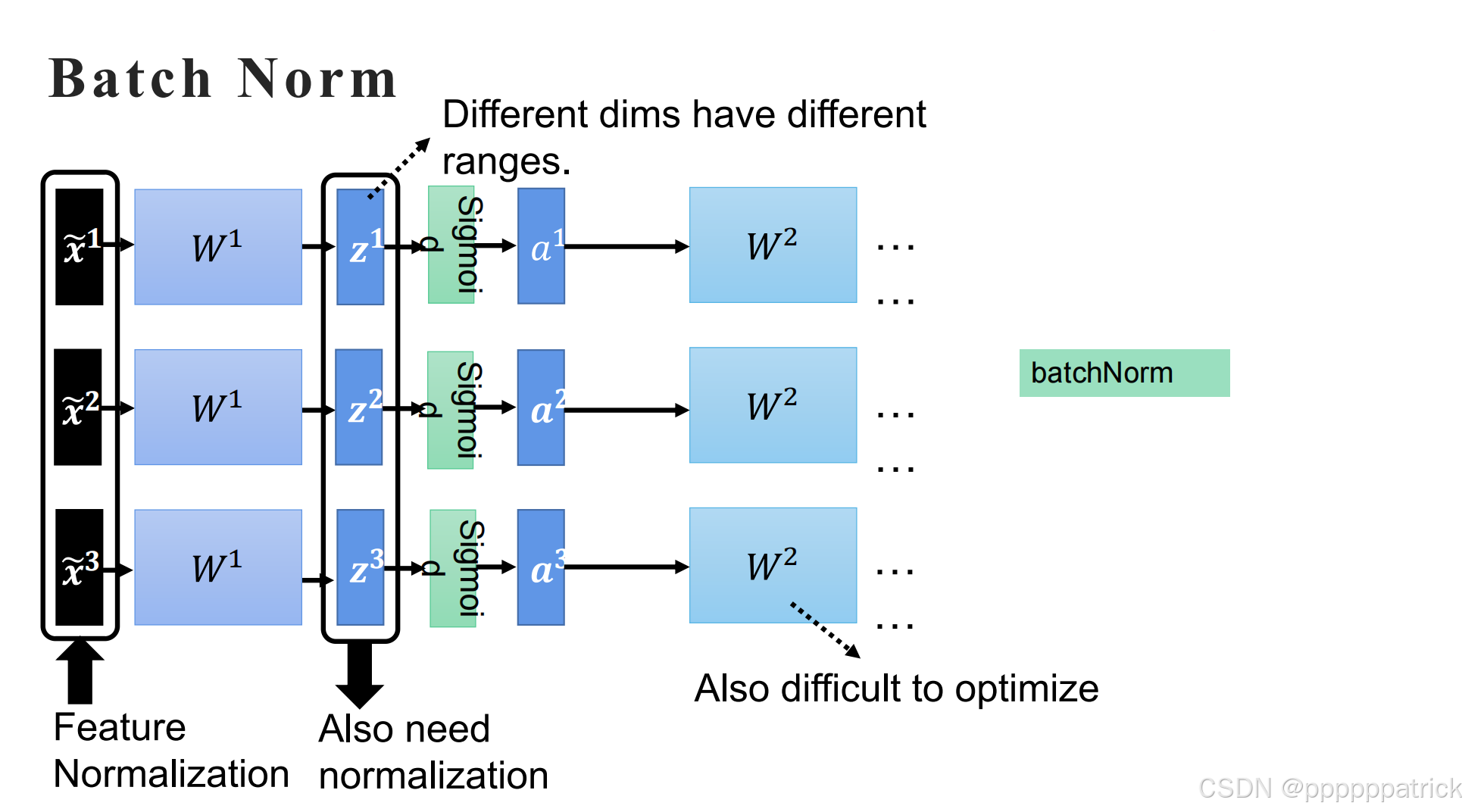
在AlexNet之后,人们发现,即使对输入做了归一化,经过多层线性变换和激活后,数据分布又会变得混乱,这被称为"内部协变量偏移"(Internal Covariate Shift)。Batch Norm 应运而生:
- 工作原理 :在每一层的激活函数之前,对该层的输出在一个Batch内进行归一化,然后再通过两个可学习的参数 γ \gamma γ 和 β \beta β 进行缩放和偏移,以保留网络的表达能力。
- 核心优势 :
- 极大地加速了网络的收敛速度。
- 降低了模型对初始化和学习率的敏感度。
- 起到了一定的正则化作用,减少了对Dropout的依赖。
二、VGGNet:极简主义的胜利
在AlexNet之后,涌现了大量改进的网络结构,而VGGNet (由牛津大学视觉几何组提出)以其极致简洁的设计脱颖而出,成为了卷积神经网络设计的"教科书"。
1. 设计哲学:一切皆为3x3卷积
VGGNet的核心创新在于它的极简主义:
- 统一卷积核 :所有的卷积层都使用
3x3的卷积核,步长为1,填充为1。这使得卷积操作不会改变特征图的空间尺寸。 - 统一池化 :所有的池化层都使用
2x2的最大池化,步长为2。这使得特征图的尺寸每次池化都精确地减半。 - 深度堆叠 :通过不断堆叠
3x3卷积层来加深网络,而不是使用更大的卷积核。
2. 感受野的几何级数增长
VGGNet的设计巧妙地利用了感受野 的概念。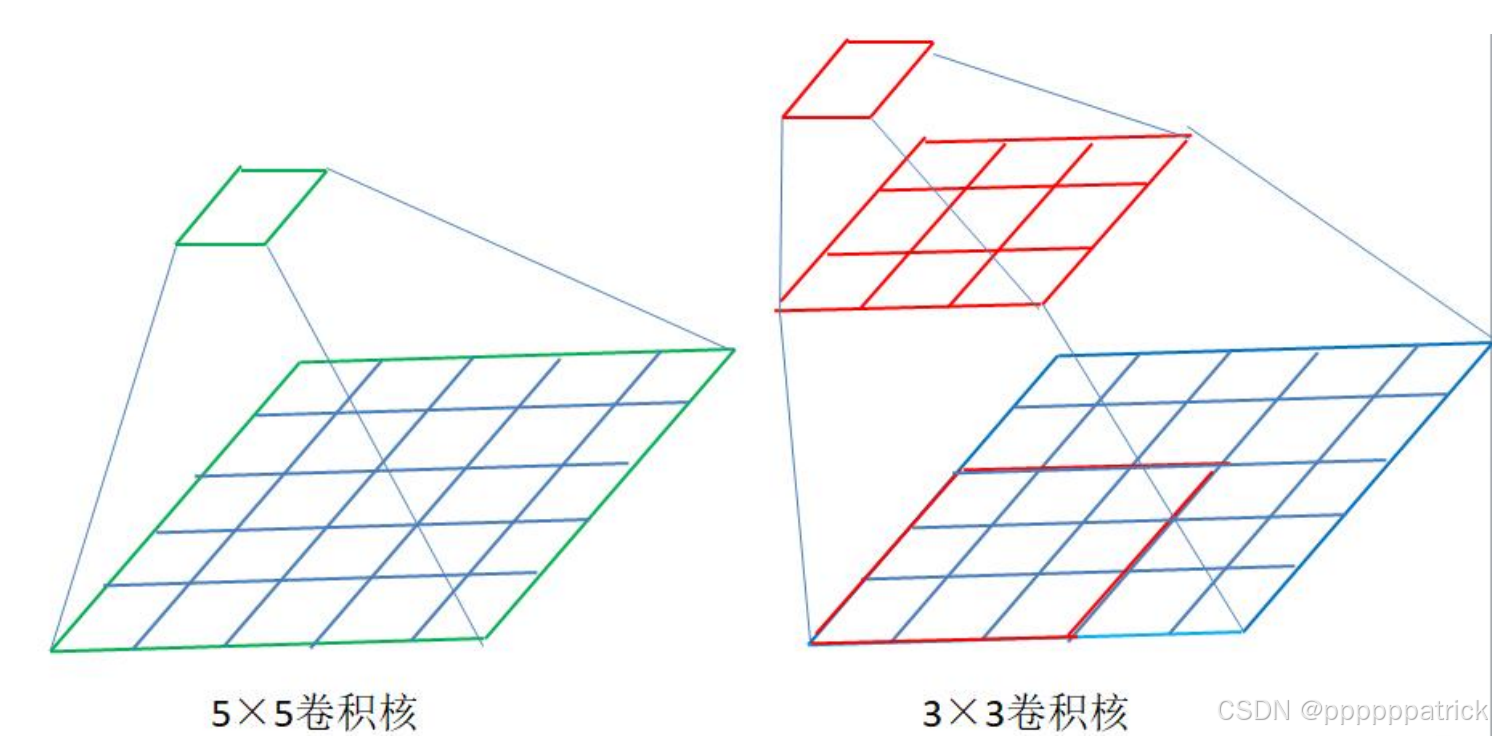
- 感受野:指特征图上的一个像素,在原始输入图像上对应的区域大小。
- 堆叠的威力 :两个连续的
3x3卷积层,其等效的感受野是5x5;三个连续的3x3卷积层,其等效的感受野是7x7。 - 优势 :
- 使用多个小卷积核堆叠,既达到了大卷积核的感受野,又减少了参数量。例如,3个
3x3卷积的参数量( 3 × 3 2 = 27 3 \times 3^2 = 27 3×32=27)远少于1个7x7卷积的参数量( 7 2 = 49 7^2 = 49 72=49)。 - 增加了网络的深度和非线性,提升了特征提取能力。
- 使用多个小卷积核堆叠,既达到了大卷积核的感受野,又减少了参数量。例如,3个
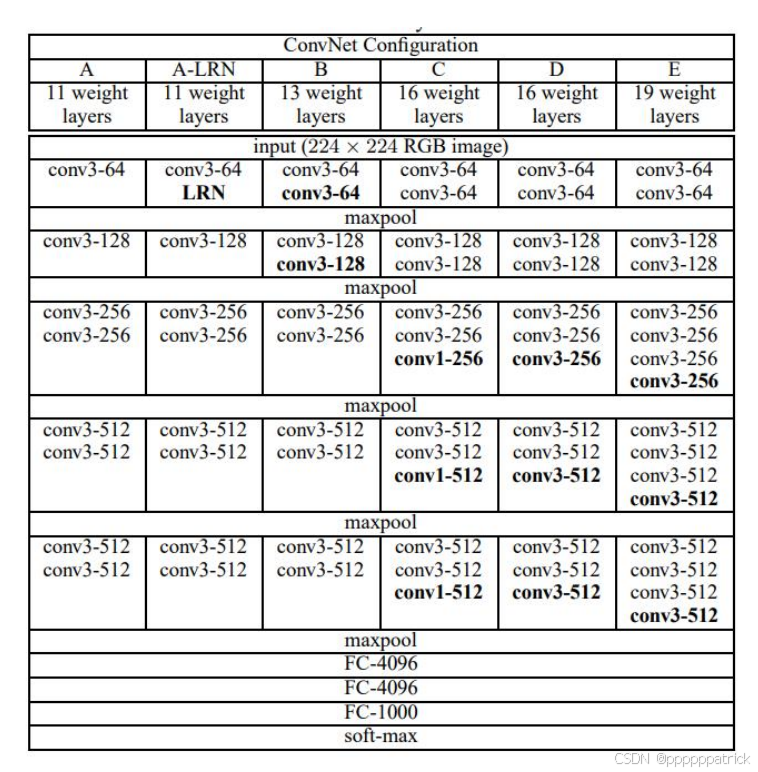
3. VGG的网络结构
VGGNet有多个版本(如VGG11, VGG16, VGG19),其中VGG16最为流行。其结构可以清晰地分为5个阶段:
- 阶段1 :2个
3x3卷积(64通道)+ 1个2x2池化 - 阶段2 :2个
3x3卷积(128通道)+ 1个2x2池化 - 阶段3 :3个
3x3卷积(256通道)+ 1个2x2池化 - 阶段4 :3个
3x3卷积(512通道)+ 1个2x2池化 - 阶段5 :3个
3x3卷积(512通道)+ 1个2x2池化 - 全连接层:3个全连接层(4096, 4096, 1000)
这种高度规整的结构,使得VGGNet非常易于理解和复现,也为后续的网络设计提供了重要的参考。
三、ResNet:解决"网络越深,性能越差"的残差革命
在AlexNet和VGGNet证明了"网络越深,特征提取能力越强"之后,研究者们却遇到了一个反直觉的问题:当网络层数增加到一定程度后,训练误差和测试误差反而会上升 ,这就是"网络退化"(Degradation)问题。何凯明团队提出的ResNet(残差网络),通过引入残差连接(Residual Connection) ,一举解决了这一难题,让训练上百层甚至上千层的深度网络成为可能。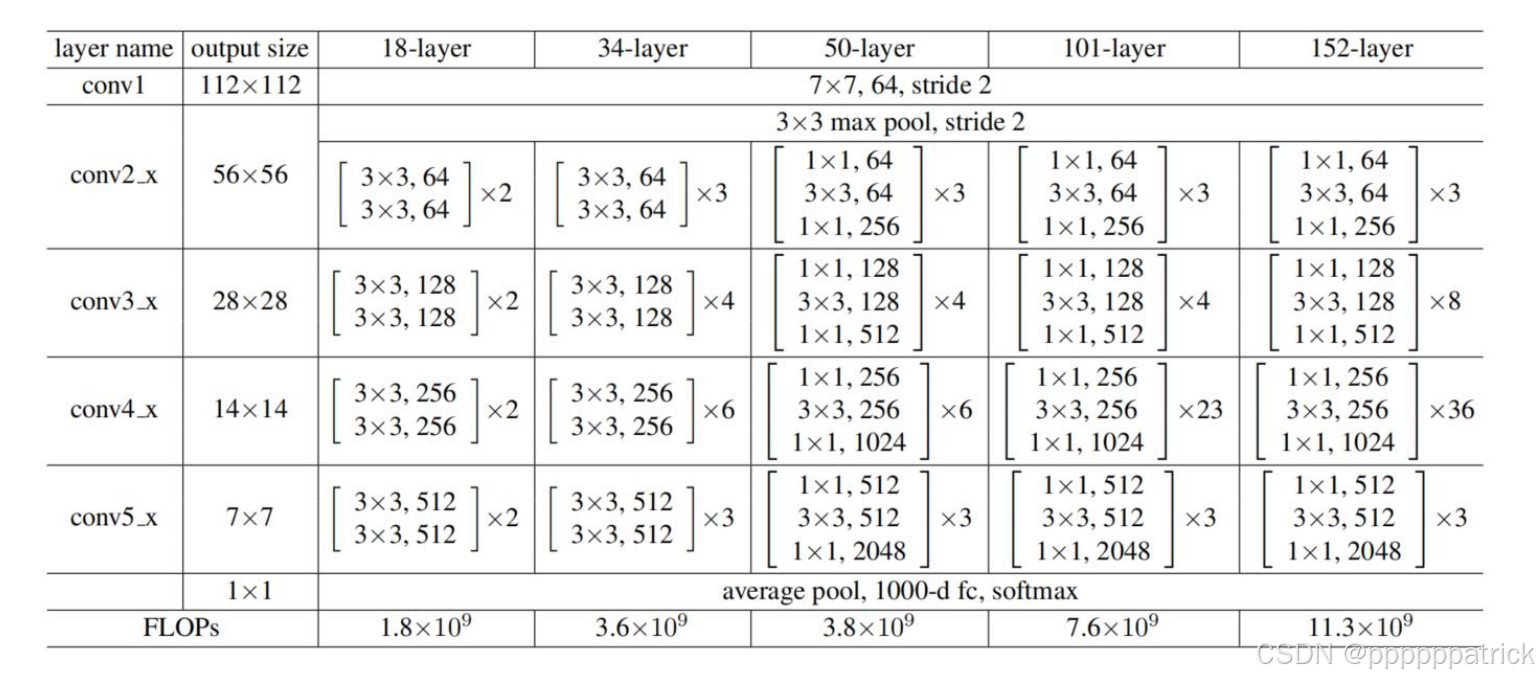
1. 网络退化:为什么更深的网络反而更差?
在ResNet之前,人们普遍认为"更深的网络应该有更强的表达能力",但实验结果却恰恰相反。如下图所示,在CIFAR-10数据集上,56层的"Plain Network"(无残差连接)的训练误差和测试误差,都明显高于20层的网络。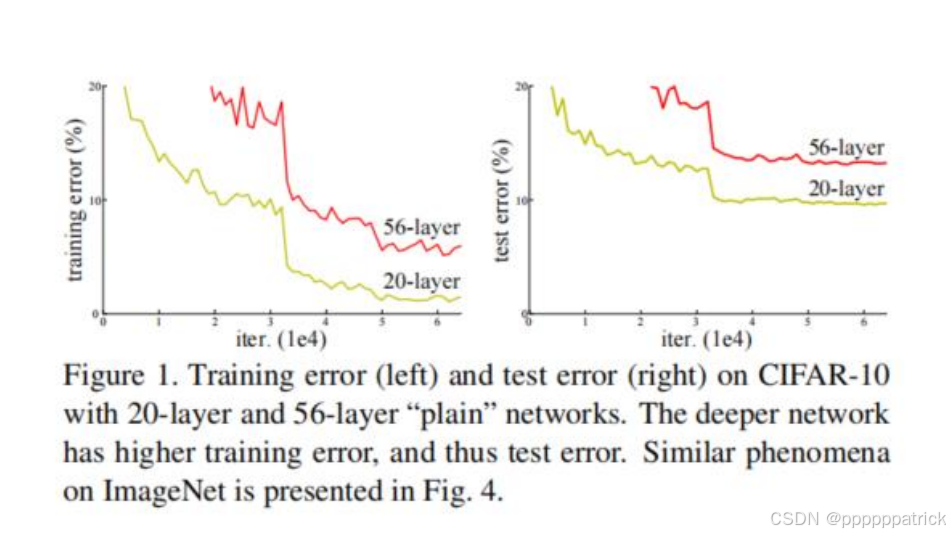
这说明,网络层数的增加,并不一定带来性能的提升,反而可能因为梯度消失/爆炸等问题,导致网络难以优化。
2. 核心创新:残差连接(Residual Connection)
ResNet的核心思想非常简洁:与其让堆叠的层直接学习一个复杂的映射 H ( x ) H(x) H(x),不如让它们学习残差映射 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x,然后通过一个"短路"连接(Shortcut)将原始输入 x x x 直接加到输出上。
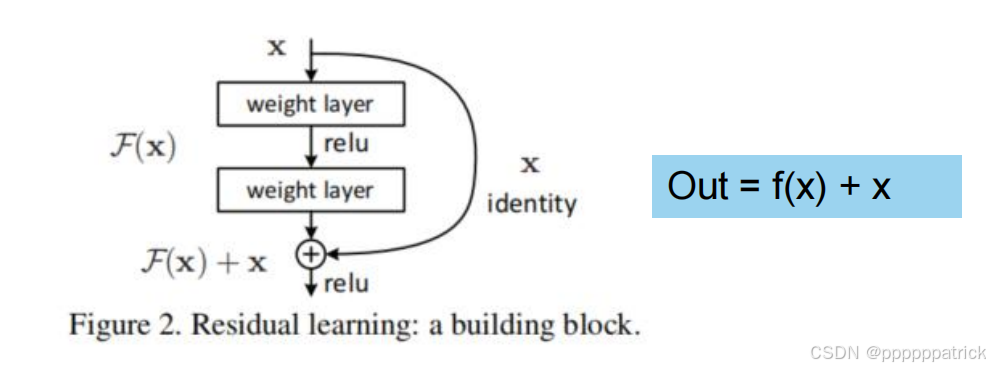
2.1 残差块的结构
一个基本的残差块可以表示为:
Out = F ( x ) + x \text{Out} = F(x) + x Out=F(x)+x
- F ( x ) F(x) F(x):由两个(或更多)卷积层和激活函数组成的残差映射。
- x x x:原始输入,通过短路连接直接加到残差映射的输出上。
- 最后再经过一个ReLU激活函数。
2.2 为什么残差连接能解决退化问题?
如果我们假设在理想情况下,某几层网络是"多余"的,即最优映射 H ( x ) = x H(x) = x H(x)=x。在传统网络中,这需要这些层的权重全部学习为0,这在深层网络中非常困难;而在残差网络中,只需让残差映射 F ( x ) = 0 F(x) = 0 F(x)=0,就能轻松实现恒等映射 H ( x ) = x H(x) = x H(x)=x。这大大降低了网络优化的难度,让深层网络至少不会比浅层网络更差。
从梯度传播的角度看,残差连接提供了一条梯度可以直接无损传播的"高速公路",有效缓解了深层网络中的梯度消失问题,这与ReLU激活函数的作用异曲同工。
3. 关键技术:1×1卷积与瓶颈结构(Bottleneck)
为了在加深网络的同时控制参数量和计算量,ResNet引入了1×1卷积 和瓶颈结构 。
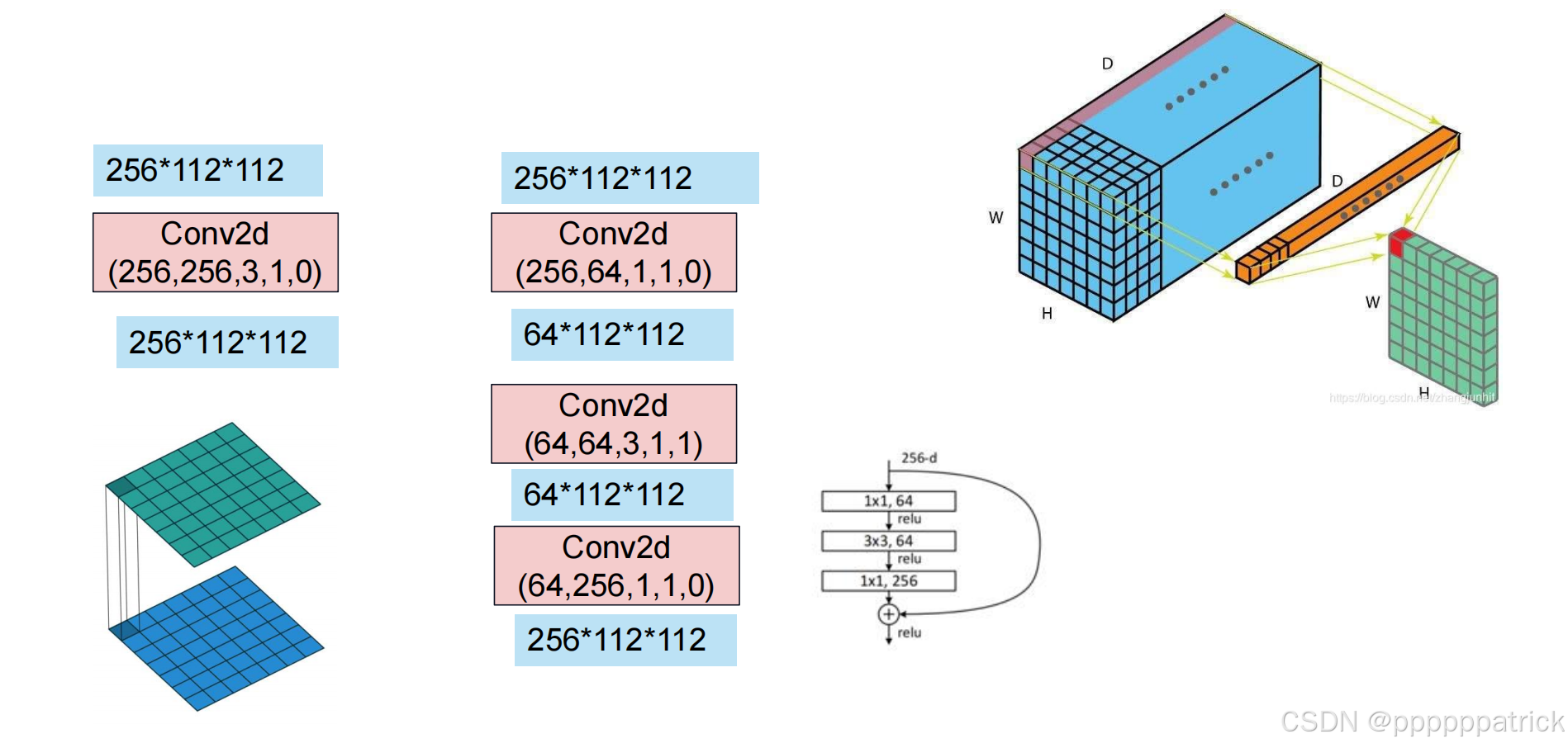
3.1 1×1卷积的作用:降维与升维
1×1卷积是一种特殊的卷积,它不改变特征图的空间尺寸,只改变通道数,主要作用是:
- 降维:减少通道数,降低后续3×3卷积的计算量。
- 升维:在瓶颈结构的末尾恢复通道数,保证特征表达能力。
3.2 瓶颈结构(Bottleneck)
对于ResNet-50及更深的版本,残差块采用了瓶颈结构,用三个连续的卷积层(1×1 → 3×3 → 1×1)替代了原来的两个3×3卷积:
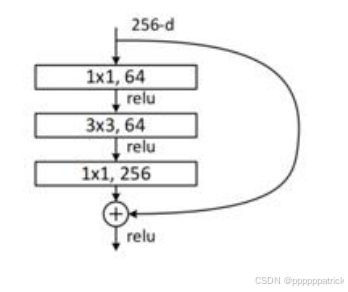
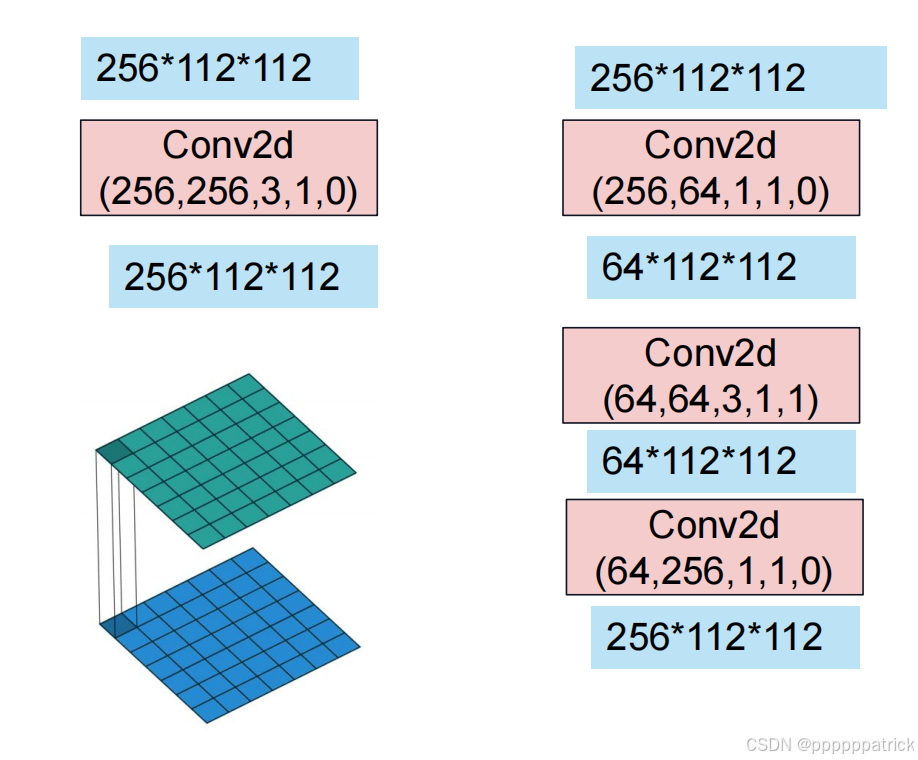
以输入通道为256的特征图为例:
- 先用1×1卷积将通道数从256降到64。
- 再用3×3卷积在64个通道上提取特征。
- 最后用1×1卷积将通道数从64恢复到256。
参数对比:
- 直接使用两个3×3卷积:参数量为 256 × 256 × 3 × 3 × 2 = 1 , 179 , 648 256 \times 256 \times 3 \times 3 \times 2 = 1,179,648 256×256×3×3×2=1,179,648。
- 使用瓶颈结构:参数量为 ( 256 × 64 × 1 × 1 ) + ( 64 × 64 × 3 × 3 ) + ( 64 × 256 × 1 × 1 ) = 69 , 632 (256 \times 64 \times 1 \times 1) + (64 \times 64 \times 3 \times 3) + (64 \times 256 \times 1 \times 1) = 69,632 (256×64×1×1)+(64×64×3×3)+(64×256×1×1)=69,632。
可以看到,瓶颈结构在保持感受野和表达能力的同时,参数量减少了约17倍,极大地提升了训练效率。
4. 维度匹配:当输入与输出维度不一致时
残差连接要求 F ( x ) F(x) F(x) 和 x x x 的维度(通道数和空间尺寸)必须完全一致才能相加。当需要通过步长为2的卷积来下采样时,维度就会不匹配,此时有两种解决方案:
4.1 方案一:对短路连接 x x x 进行卷积变换
在短路连接上使用一个1×1卷积,步长为2,来调整 x x x 的通道数和空间尺寸,使其与 F ( x ) F(x) F(x) 匹配。
例如,当输入为 64 × 56 × 56 64 \times 56 \times 56 64×56×56,需要输出为 128 × 28 × 28 128 \times 28 \times 28 128×28×28 时:
- 残差路径 F ( x ) F(x) F(x):通过步长为2的卷积层,输出 128 × 28 × 28 128 \times 28 \times 28 128×28×28。
- 短路路径 x x x:通过一个步长为2的1×1卷积,输出 128 × 28 × 28 128 \times 28 \times 28 128×28×28。
- 两者维度一致,即可相加。
4.2 方案二:对 x x x 进行池化和零填充(较少使用)
也可以通过池化来下采样空间尺寸,并用零填充来增加通道数,但这种方式会丢失信息,因此在ResNet中主要采用方案一。
5. ResNet的网络结构
ResNet有多个版本(ResNet-18, 34, 50, 101, 152),它们的核心结构相似,只是残差块的堆叠次数不同。
以ResNet-50为例,其结构可以分为以下几个阶段:
- conv1 :一个7×7卷积(步长2)+ 3×3最大池化(步长2),将输入从 3 × 224 × 224 3 \times 224 \times 224 3×224×224 转换为 64 × 56 × 56 64 \times 56 \times 56 64×56×56。
- conv2_x :3个瓶颈残差块,输出 256 × 56 × 56 256 \times 56 \times 56 256×56×56。
- conv3_x :4个瓶颈残差块,输出 512 × 28 × 28 512 \times 28 \times 28 512×28×28。
- conv4_x :6个瓶颈残差块,输出 1024 × 14 × 14 1024 \times 14 \times 14 1024×14×14。
- conv5_x :3个瓶颈残差块,输出 2048 × 7 × 7 2048 \times 7 \times 7 2048×7×7。
- 分类头:全局平均池化 + 1000维全连接层 + Softmax。
四、总结:从AlexNet到ResNet的演进
- AlexNet 证明了深度卷积神经网络的可行性,其ReLU、Dropout、归一化等创新至今仍是深度学习的基石。
- VGGNet 则将这种可行性推向了极致,用极简的设计证明了"深度"和"规整性"的力量,其对感受野的深刻理解,影响了后续几乎所有的CNN架构。
- ResNet 则解决了"网络越深,性能越差"的退化问题,通过残差连接让训练超深网络成为可能,重塑了深度学习的架构设计范式。
五、彩蛋01:残差连接多角度理解
残差连接(Residual Connection)是 ResNet 的核心创新,我们可以用通俗比喻 + 数学推导 + 梯度视角三层来理解,
1. 先看直观比喻:"抄近路"的智慧
想象你要从 A 地走到 B 地,中间要经过很多复杂的街道(对应多层卷积)。
- 传统网络:必须走完所有街道,才能到达 B 地。如果街道太多(网络太深),你很容易迷路(梯度消失),甚至越走越远(网络退化)。
- 残差网络 :在 A 和 B 之间修了一条"高速公路"(短路连接)。你可以选择:
- 走复杂街道(学习复杂映射 F ( x ) F(x) F(x));
- 或者直接走高速公路(直接传递输入 x x x);
- 也可以两者结合:先在街道上走一段,再上高速,最终到达 B 地( F ( x ) + x F(x) + x F(x)+x)。
这条"高速公路"就是残差连接,它让网络在加深的同时,至少不会比原来更差。
2. 数学视角:从"学习映射"到"学习差值"
在传统的卷积层中,我们希望堆叠的层学习一个复杂的映射:
H ( x ) = 一些卷积和激活 H(x) = \text{一些卷积和激活} H(x)=一些卷积和激活
这个映射 H ( x ) H(x) H(x) 可能非常复杂,很难学习。
ResNet 的思路是:与其直接学习 H ( x ) H(x) H(x),不如学习 H ( x ) H(x) H(x) 和 x x x 之间的差值(残差)。
我们定义残差映射:
F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x
那么,最终的输出就变成了:
H ( x ) = F ( x ) + x H(x) = F(x) + x H(x)=F(x)+x
这就是残差连接的数学表达:输出 = 残差 + 原始输入。
为什么这样更好?
假设在理想情况下,某几层网络是"多余"的,即最优的映射就是 H ( x ) = x H(x) = x H(x)=x(输入什么就输出什么)。
- 传统网络 :要学习 H ( x ) = x H(x) = x H(x)=x,需要让所有卷积层的权重都精确地学习为 0,这在深层网络中几乎不可能。
- 残差网络 :要学习 H ( x ) = x H(x) = x H(x)=x,只需要让残差映射 F ( x ) = 0 F(x) = 0 F(x)=0 即可。这意味着卷积层的权重可以全部初始化为 0,网络就能轻松实现恒等映射。
这大大降低了网络优化的难度,让深层网络至少不会比浅层网络更差。
3. 梯度视角:解决梯度消失的"高速公路"
深层网络训练困难的核心原因是梯度消失。在反向传播时,梯度需要从输出层逐层乘以前向传播的权重和激活函数的导数。如果这些值都小于 1,经过几十层的连乘后,梯度会变得无限小,导致前面的层几乎无法更新。
残差连接的出现,彻底改变了这一点。
我们来看残差块的输出:
y = F ( x ) + x y = F(x) + x y=F(x)+x
在反向传播时,损失 L L L 对输入 x x x 的梯度为:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ x = ∂ L ∂ y ⋅ ( ∂ F ( x ) ∂ x + 1 ) \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial x} = \frac{\partial L}{\partial y} \cdot \left( \frac{\partial F(x)}{\partial x} + 1 \right) ∂x∂L=∂y∂L⋅∂x∂y=∂y∂L⋅(∂x∂F(x)+1)
这里的关键是那个 +1。它意味着:
- 即使 ∂ F ( x ) ∂ x \frac{\partial F(x)}{\partial x} ∂x∂F(x) 这部分的梯度很小(趋近于 0),整个梯度 ∂ L ∂ x \frac{\partial L}{\partial x} ∂x∂L 也至少等于 ∂ L ∂ y \frac{\partial L}{\partial y} ∂y∂L,不会消失。
- 梯度可以通过这条"+1"的高速公路,直接无损地传播到前面的层,让深层网络的训练变得和浅层网络一样容易。
这和 ReLU 激活函数的作用异曲同工,都是为了缓解梯度消失问题。
4. 结构示例:两种残差块
在 ResNet 中,主要有两种残差块结构:
① 基本残差块(Basic Block)------用于 ResNet-18/34
由两个 3×3 卷积层组成,短路连接是直接的恒等映射。
y = Conv(3×3) -> ReLU -> Conv(3×3) ⏟ F ( x ) + x y = \underbrace{\text{Conv(3×3) -> ReLU -> Conv(3×3)}}_{F(x)} + x y=F(x) Conv(3×3) -> ReLU -> Conv(3×3)+x
② 瓶颈残差块(Bottleneck Block)------用于 ResNet-50/101/152
为了减少参数量和计算量,使用了 1×1 卷积来降维和升维,形成"瓶颈"结构。
y = Conv(1×1) -> ReLU -> Conv(3×3) -> ReLU -> Conv(1×1) ⏟ F ( x ) + x y = \underbrace{\text{Conv(1×1) -> ReLU -> Conv(3×3) -> ReLU -> Conv(1×1)}}_{F(x)} + x y=F(x) Conv(1×1) -> ReLU -> Conv(3×3) -> ReLU -> Conv(1×1)+x
5. 维度不匹配怎么办?
残差连接要求 F ( x ) F(x) F(x) 和 x x x 的维度(通道数和空间尺寸)必须完全一致才能相加。当需要通过步长为 2 的卷积来下采样时,维度就会不匹配,此时我们需要在短路连接上也加一个卷积层来调整维度:
y = F ( x ) + W s x y = F(x) + W_s x y=F(x)+Wsx
- W s W_s Ws 是一个 1×1 的卷积层,步长为 2,用来将 x x x 的维度调整到和 F ( x ) F(x) F(x) 一致。
总结
残差连接就是在网络层之间加了一条"短路",让输出等于"卷积学到的东西"加上"原始输入"。它的核心作用是:
- 让深层网络更容易优化,解决了网络退化问题;
- 提供了一条梯度传播的"高速公路",有效缓解了梯度消失。
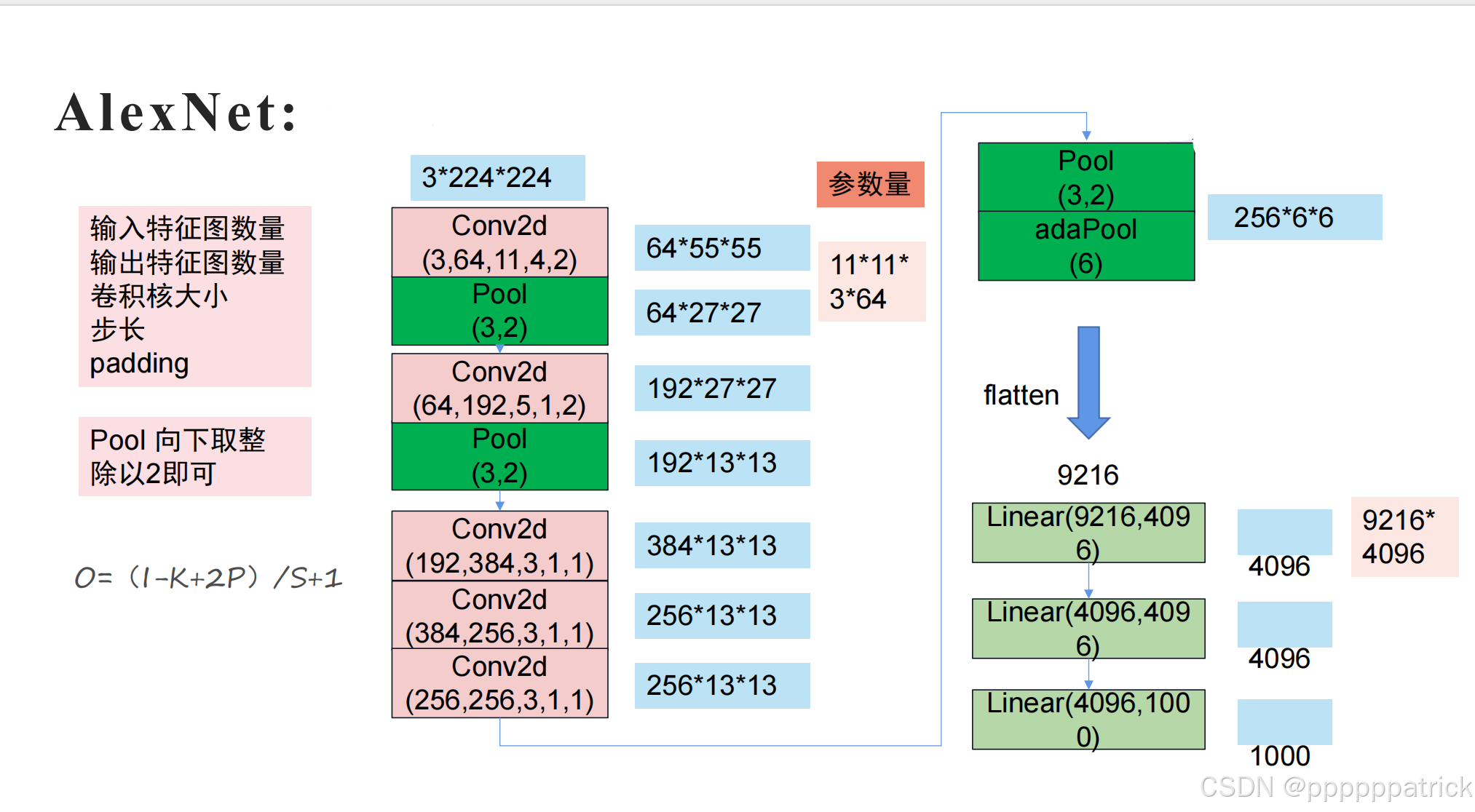
六、彩蛋02:参数量计算练习
题目
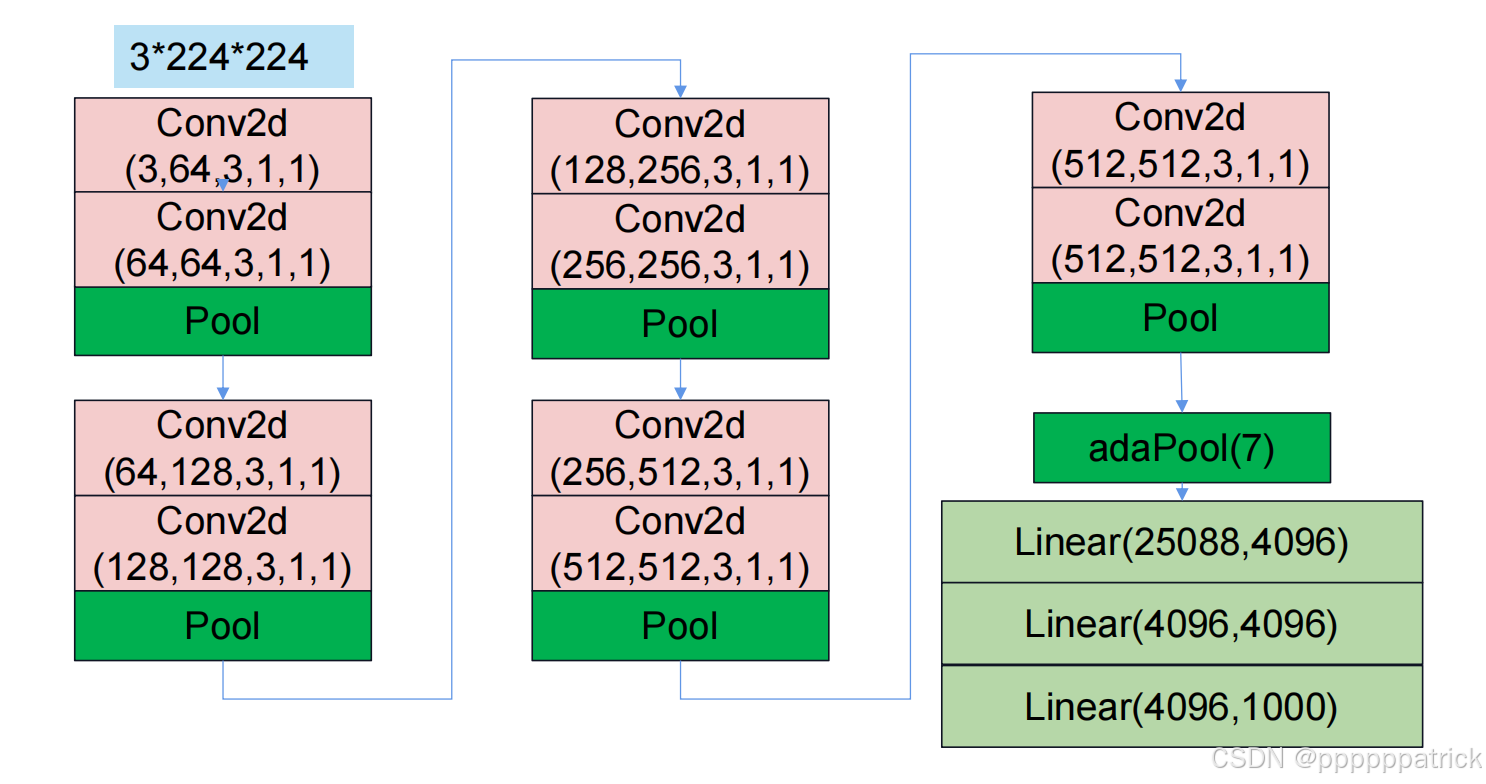
请计算出图中各个步骤的维度变化
解析(可跳过直接看答案)
1. 维度计算(逐阶段验证)
输入: 3 × 224 × 224 3 \times 224 \times 224 3×224×224
阶段1(Conv2d 3→64, 64→64, Pool 2×2)
- 卷积: K = 3 , S = 1 , P = 1 K=3, S=1, P=1 K=3,S=1,P=1,输出尺寸 O = 224 − 3 + 2 × 1 1 + 1 = 224 O = \frac{224-3+2 \times 1}{1}+1 = 224 O=1224−3+2×1+1=224
→ 输出: 64 × 224 × 224 64 \times 224 \times 224 64×224×224 - 池化: K = 2 , S = 2 K=2, S=2 K=2,S=2,输出尺寸 O = 224 2 = 112 O = \frac{224}{2} = 112 O=2224=112
→ 输出: 64 × 112 × 112 64 \times 112 \times 112 64×112×112
阶段2(Conv2d 64→128, 128→128, Pool 2×2)
- 卷积: O = 112 − 3 + 2 × 1 1 + 1 = 112 O = \frac{112-3+2 \times 1}{1}+1 = 112 O=1112−3+2×1+1=112
→ 输出: 128 × 112 × 112 128 \times 112 \times 112 128×112×112 - 池化: O = 112 2 = 56 O = \frac{112}{2} = 56 O=2112=56
→ 输出: 128 × 56 × 56 128 \times 56 \times 56 128×56×56
阶段3(Conv2d 128→256, 256→256, Pool 2×2)
- 卷积: O = 56 − 3 + 2 × 1 1 + 1 = 56 O = \frac{56-3+2 \times 1}{1}+1 = 56 O=156−3+2×1+1=56
→ 输出: 256 × 56 × 56 256 \times 56 \times 56 256×56×56 - 池化: O = 56 2 = 28 O = \frac{56}{2} = 28 O=256=28
→ 输出: 256 × 28 × 28 256 \times 28 \times 28 256×28×28
阶段4(Conv2d 256→512, 512→512, Pool 2×2)
- 卷积: O = 28 − 3 + 2 × 1 1 + 1 = 28 O = \frac{28-3+2 \times 1}{1}+1 = 28 O=128−3+2×1+1=28
→ 输出: 512 × 28 × 28 512 \times 28 \times 28 512×28×28 - 池化: O = 28 2 = 14 O = \frac{28}{2} = 14 O=228=14
→ 输出: 512 × 14 × 14 512 \times 14 \times 14 512×14×14
阶段5(Conv2d 512→512, 512→512, Pool 2×2)
- 卷积: O = 14 − 3 + 2 × 1 1 + 1 = 14 O = \frac{14-3+2 \times 1}{1}+1 = 14 O=114−3+2×1+1=14
→ 输出: 512 × 14 × 14 512 \times 14 \times 14 512×14×14 - 池化: O = 14 2 = 7 O = \frac{14}{2} = 7 O=214=7
→ 输出: 512 × 7 × 7 512 \times 7 \times 7 512×7×7
AdaPool(7)
- 自适应池化输出尺寸固定为 7 × 7 7 \times 7 7×7
→ 输出: 512 × 7 × 7 512 \times 7 \times 7 512×7×7 - 展平: 512 × 7 × 7 = 25088 512 \times 7 \times 7 = 25088 512×7×7=25088,与图中
Linear(25088, 4096)一致
2. 参数量计算(卷积层)(了解即可)
卷积层参数量公式:
Params = ( 输入通道数 × K × K + 1 ) × 输出通道数 \text{Params} = (\text{输入通道数} \times K \times K + 1) \times \text{输出通道数} Params=(输入通道数×K×K+1)×输出通道数
( + 1 +1 +1 为偏置项,若 bias=False 则不加)
| 层 | 输入C | 输出C | K×K | 参数量计算 | 参数量 |
|---|---|---|---|---|---|
| Conv1 | 3 | 64 | 3×3 | ( 3 × 3 × 3 + 1 ) × 64 (3 \times 3 \times 3 + 1) \times 64 (3×3×3+1)×64 | 1792 |
| Conv2 | 64 | 64 | 3×3 | ( 64 × 3 × 3 + 1 ) × 64 (64 \times 3 \times 3 + 1) \times 64 (64×3×3+1)×64 | 36928 |
| Conv3 | 64 | 128 | 3×3 | ( 64 × 3 × 3 + 1 ) × 128 (64 \times 3 \times 3 + 1) \times 128 (64×3×3+1)×128 | 73856 |
| Conv4 | 128 | 128 | 3×3 | ( 128 × 3 × 3 + 1 ) × 128 (128 \times 3 \times 3 + 1) \times 128 (128×3×3+1)×128 | 147584 |
| Conv5 | 128 | 256 | 3×3 | ( 128 × 3 × 3 + 1 ) × 256 (128 \times 3 \times 3 + 1) \times 256 (128×3×3+1)×256 | 295168 |
| Conv6 | 256 | 256 | 3×3 | ( 256 × 3 × 3 + 1 ) × 256 (256 \times 3 \times 3 + 1) \times 256 (256×3×3+1)×256 | 590080 |
| Conv7 | 256 | 512 | 3×3 | ( 256 × 3 × 3 + 1 ) × 512 (256 \times 3 \times 3 + 1) \times 512 (256×3×3+1)×512 | 1180160 |
| Conv8 | 512 | 512 | 3×3 | ( 512 × 3 × 3 + 1 ) × 512 (512 \times 3 \times 3 + 1) \times 512 (512×3×3+1)×512 | 2359808 |
| Conv9 | 512 | 512 | 3×3 | ( 512 × 3 × 3 + 1 ) × 512 (512 \times 3 \times 3 + 1) \times 512 (512×3×3+1)×512 | 2359808 |
| Conv10 | 512 | 512 | 3×3 | ( 512 × 3 × 3 + 1 ) × 512 (512 \times 3 \times 3 + 1) \times 512 (512×3×3+1)×512 | 2359808 |
卷积层总参数量 :
1792 + 36928 + 73856 + 147584 + 295168 + 590080 + 1180160 + 2359808 + 2359808 + 2359808 = 9404992 1792 + 36928 + 73856 + 147584 + 295168 + 590080 + 1180160 + 2359808 + 2359808 + 2359808 = 9404992 1792+36928+73856+147584+295168+590080+1180160+2359808+2359808+2359808=9404992
3. 全连接层参数量(了解即可)
全连接层参数量公式:
Params = ( 输入维度 + 1 ) × 输出维度 \text{Params} = (\text{输入维度} + 1) \times \text{输出维度} Params=(输入维度+1)×输出维度
| 层 | 输入维度 | 输出维度 | 参数量计算 | 参数量 |
|---|---|---|---|---|
| FC1 | 25088 | 4096 | ( 25088 + 1 ) × 4096 (25088 + 1) \times 4096 (25088+1)×4096 | 102764544 |
| FC2 | 4096 | 4096 | ( 4096 + 1 ) × 4096 (4096 + 1) \times 4096 (4096+1)×4096 | 16781312 |
| FC3 | 4096 | 1000 | ( 4096 + 1 ) × 1000 (4096 + 1) \times 1000 (4096+1)×1000 | 4097000 |
全连接层总参数量 :
102764544 + 16781312 + 4097000 = 123642856 102764544 + 16781312 + 4097000 = 123642856 102764544+16781312+4097000=123642856
答案速查
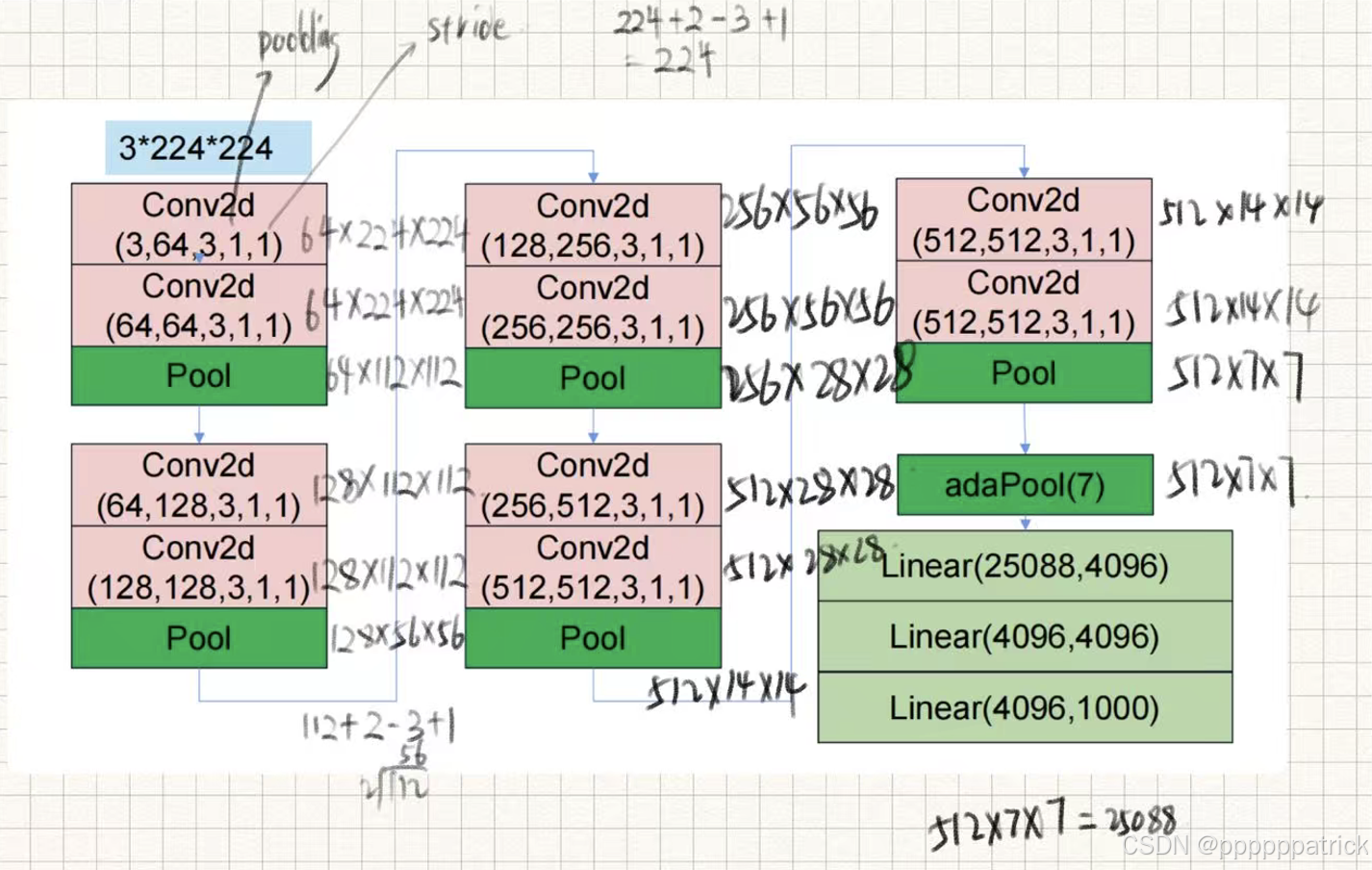
会做到这一步就可以了!