对于刚接触机器学习的同学来说,感知机是绕不开的核心基础 ------ 它不仅是最简单的线性分类模型,更是神经网络、深度学习的 "雏形"。搞懂感知机的原理,就相当于打通了从传统机器学习到深度学习的第一道关。今天我们就用最通俗的语言 + 实战案例,带你彻底掌握感知机的模型、工作原理和学习规则。
一、先搞懂:感知机到底是什么?
感知机的本质是二分类的线性判别模型,核心作用是根据输入的特征,输出 "是" 或 "否"(对应数字 0 和 1)。
你可以把它类比成一个 "智能判断器":比如判断一个水果是苹果还是香蕉,输入的是水果的特征(颜色、形状等),感知机通过分析这些特征的重要性,最终给出分类结果。
从数学角度看,感知机的核心是线性函数 + 激活函数的组合:先对输入特征进行加权求和,再通过激活函数输出分类结果,完美适配 "输入→处理→输出" 的简单逻辑,特别适合入门同学理解机器学习的基本流程。
二、感知机的模型结构:拆解每一个核心部件
感知机的结构非常简单,核心由 5 个部分组成,哪怕是零基础也能一眼看懂:
1. 输入层(特征输入)
输入层是感知机的 "信息入口",对应待分类对象的特征向量。比如判断水果时,输入可以是「颜色 x₁」「形状 x₂」(特征的数量可以扩展到 n 个,即 x₁、x₂、...、xₙ)。
每个输入 xᵢ都是具体的数值(比如用 1 代表 "红色",-1 代表 "黄色";1 代表 "圆形",-1 代表 "长条形"),是模型计算的基础。
2. 权重(w₁、w₂、...、wₙ)
权重是每个输入特征的 "重要程度系数":
- 权重的绝对值越大,说明对应的特征对分类结果影响越大;
- 权重为正,说明该特征会 "推动" 模型输出 1;
- 权重为负,说明该特征会 "阻碍" 模型输出 1(推动输出 0)。
比如判断苹果时,"颜色" 的权重可能比 "形状" 大,因为红色更能区分苹果和香蕉。
3. 偏置(b)
偏置是模型的 "基础门槛",用来调整整个线性函数的输出基准,避免因特征加权和为 0 导致无法分类。你可以理解为:模型需要达到一定的 "分数" 才能输出 1,偏置就是这个分数的 "底线"。
4. 线性求和(v)
这一步是感知机的 "计算核心",将每个输入特征与对应的权重相乘,再加上偏置,得到线性组合结果 v:
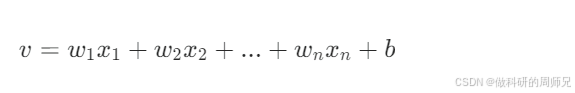
这个结果 v 是 "原始分数",还不能直接用于分类,需要经过激活函数处理。
5. 激活函数(step 函数)
激活函数的作用是将线性求和的结果 v,映射到二分类的输出(0 或 1)。感知机最常用的是阶跃函数(step 函数) ,逻辑非常简单:y=step(v)={10(v≥0)(v<0)
简单说:如果原始分数 v 达到 0(或以上),模型输出 1(属于某一类);如果低于 0,输出 0(不属于某一类)。
 图片来源于网络,仅供学习参考
图片来源于网络,仅供学习参考
三、感知机的学习规则:如何让模型 "学会" 分类?
感知机的核心优势在于 "能学习"------ 哪怕一开始权重和偏置设置得不合理,也能通过 "误差纠正" 不断调整,最终得到能正确分类的参数。
1. 学习的核心目标
感知机学习的本质是修正权重(w)和偏置(b) ,让模型的实际输出 y,无限接近我们的期望输出 y₋(比如我们明确知道 "红色圆形" 是苹果,期望输出 y₋=1)。
2. 关键公式:误差与参数更新
(1)误差计算
首先要明确 "模型错在哪里",误差 e 的定义很简单:e=y−−y
- 当模型分类正确时:y₋=y,误差 e=0,无需调整参数;
- 当模型分类错误时:e≠0,需要根据误差修正参数。
(2)参数更新规则
根据误差 e,权重和偏置的更新公式如下(核心逻辑:误差越大,参数调整幅度越大):
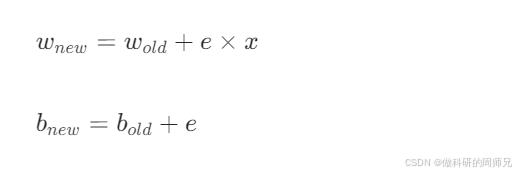
- wₙₑw:更新后的权重;wₒₗd:更新前的权重;
- bₙₑw:更新后的偏置;bₒₗd:更新前的偏置;
- x:当前输入的特征值。
这个规则的本质是 "知错就改":如果模型少输出了(e=1,期望 1 实际 0),就增大权重和偏置;如果多输出了(e=-1,期望 0 实际 1),就减小权重和偏置。
四、实战推导:用感知机分类苹果和香蕉
光看公式太抽象,我们用一个具体案例,一步步带你看感知机如何 "学会" 分类,全程计算不跳步,跟着算就能懂!
场景设定
我们要通过「颜色 x₁」和「形状 x₂」两个特征,区分苹果和香蕉:
- 特征编码:颜色(1 = 红色,-1 = 黄色);形状(1 = 圆形,-1 = 长条形);
- 期望输出:苹果→y₋=1,香蕉→y₋=0;
- 初始参数(随便选的初始值,后续会修正):w₁=1,w₂=-1,b=0。
第一步:用初始参数判断苹果(第一次尝试)

❌ 分类错误!需要用学习规则更新参数。
第二步:更新权重和偏置
根据更新公式代入 e=1、x₁=1、x₂=1:
- 新权重 w₁:w₁ₙₑw = 1 + 1×1 = 2;
- 新权重 w₂:w₂ₙₑw = -1 + 1×1 = 0;
- 新偏置 b:bₙₑw = 0 + 1 = 1。
更新后参数:w₁=2,w₂=0,b=1。
第三步:用新参数重新判断苹果

✅ 期望输出 1,实际输出 1,苹果分类正确!
第四步:验证香蕉分类(测试泛化能力)

✅ 期望输出 0,实际输出 0,香蕉分类正确!
到这里,感知机通过一次误差修正,就学会了正确分类苹果和香蕉 ------ 这就是 "有监督学习" 的核心:用已知答案(期望输出)修正模型,直到模型能准确判断。
五、延伸:感知机的全连接与局限性
1. 全连接的含义
当感知机的输入特征有 n 个(x₁到 xₙ),每个输入都对应一个权重(w₁到 wₙ),这种 "每个输入都与权重一一对应、无遗漏关联" 的结构,就是全连接。全连接是神经网络的基础结构,后续的多层感知机(MLP)、CNN 等,都基于这个核心思想扩展。
2. 感知机的局限性
感知机只能处理线性可分的问题(比如用一条直线就能把两类数据分开)。如果遇到非线性问题(比如 "异或" 逻辑),单个感知机无法解决 ------ 这也是为什么后来会发展出多层感知机(增加隐藏层)和深度学习。
但对于入门同学来说,先掌握单个感知机的原理,是理解后续复杂模型的关键。
六、学习总结:感知机的核心要点
- 感知机是线性二分类模型,结构 = 输入层 + 权重 + 偏置 + 线性求和 + 激活函数;
- 学习规则的核心是误差驱动的参数更新,通过 e=y₋-y 修正 w 和 b,直到分类正确;
- 实战是理解的关键:一定要亲手复现参数更新的过程,才能真正掌握;
- 感知机是神经网络的 "地基",后续的复杂模型都是在它的基础上增加层数、优化激活函数而来。
对于刚入门的同学,建议先用 Python 实现这个苹果香蕉分类的感知机(用 numpy 就能写,几行代码搞定),亲手调整参数、观察误差变化,比单纯看公式更有收获。
机器学习的入门之路,核心是 "理解原理 + 动手实践"。感知机的知识虽然基础,但却是构建后续知识体系的关键 ------ 吃透它,你就已经迈出了机器学习的坚实一步!