---关注作者,送A/B实验实战工具包
在前面十篇中,我们聊了 P 值、MDE、分层分流等各种"术"。但所有这些技术都有一个共同的前提假设:我们的实验平台是公正的。
如果分流算法本身有 Bug,导致进入 A 组的都是高消费用户,进入 B 组的都是低消费用户,那你无论怎么优化策略,B 组永远跑不赢 A 组。这把"尺子"本身就是弯的,量出来的结果自然也是歪的。
为了校准这把尺子,我们需要进行 A/A 实验。
简单来说,就是给 A 组和 B 组都下发完全一样的策略,然后看指标有没有显著差异。
- 理想结果:P 值 > 0.05,指标无显著差异。说明分流均匀,系统公正。
- 糟糕结果 :P 值 < 0.05,指标显著。说明发生了第一类错误 (Type I Error),系统自带偏见,必须排查。
在实战中,A/A 实验主要有三种玩法,分别对应不同的业务节奏和严谨度需求。
1. A/A 实验的三种流派
| 方案类型 | 核心操作 | 优点 | 缺点/风险 | 建议场景 |
|---|---|---|---|---|
| 实验前 A/A (Pre-experiment) | 在上新策略前,先跑 7 天空跑实验,确认无误后再加载策略。 | 最严谨。直接验证了即将进入实验的那批人的同质性。 | 耗时。业务方通常等不及,多等一周像过一年。 | 适用于 DAU 稳定、对严谨性要求极高的核心算法改动。 |
| 实验中 A/A (In-experiment) | 分三个组:A 组(对照)、A' 组(对照镜像)、B 组(实验)。 | 实时性。可以同步观察分流系统的稳定性。 | 浪费流量。A' 组占用了宝贵的样本。且 A vs A' 不显著,不能严格推导出 A vs B 也不显著(样本不同)。 | 不推荐。科学性论证不足,且挤占实验资源。 |
| 回溯 A/A (Post-hoc / Retrospective) | 实验开始后,拉取 A/B 两组用户在过去 N 天的历史数据进行对比。 | 零成本。不需要占用额外的实验时间,想查就查。 | 马后炮。如果发现历史数据有差异,实验只能推翻重做,还得换随机种子。 | 最常用。适合快速迭代的互联网业务,是效率与质量的妥协。 |
2. 进阶玩法:实验前 A/A 与灰度放量的"无缝衔接"
实验前 A/A 虽然严谨,但有一个巨大的落地难题:如何与灰度放量 (SQR) 结合?
通常我们跑 A/A 时是 50% vs 50% (为了验证最大统计功效下的均匀性)。但实验开始时,我们是从 1% 开始灰度的。
如果跑完 A/A 重新打散分流,那之前的 A/A 就白跑了(因为人群变了)。如果不重新打散,如何从 50% 缩回到 1%?
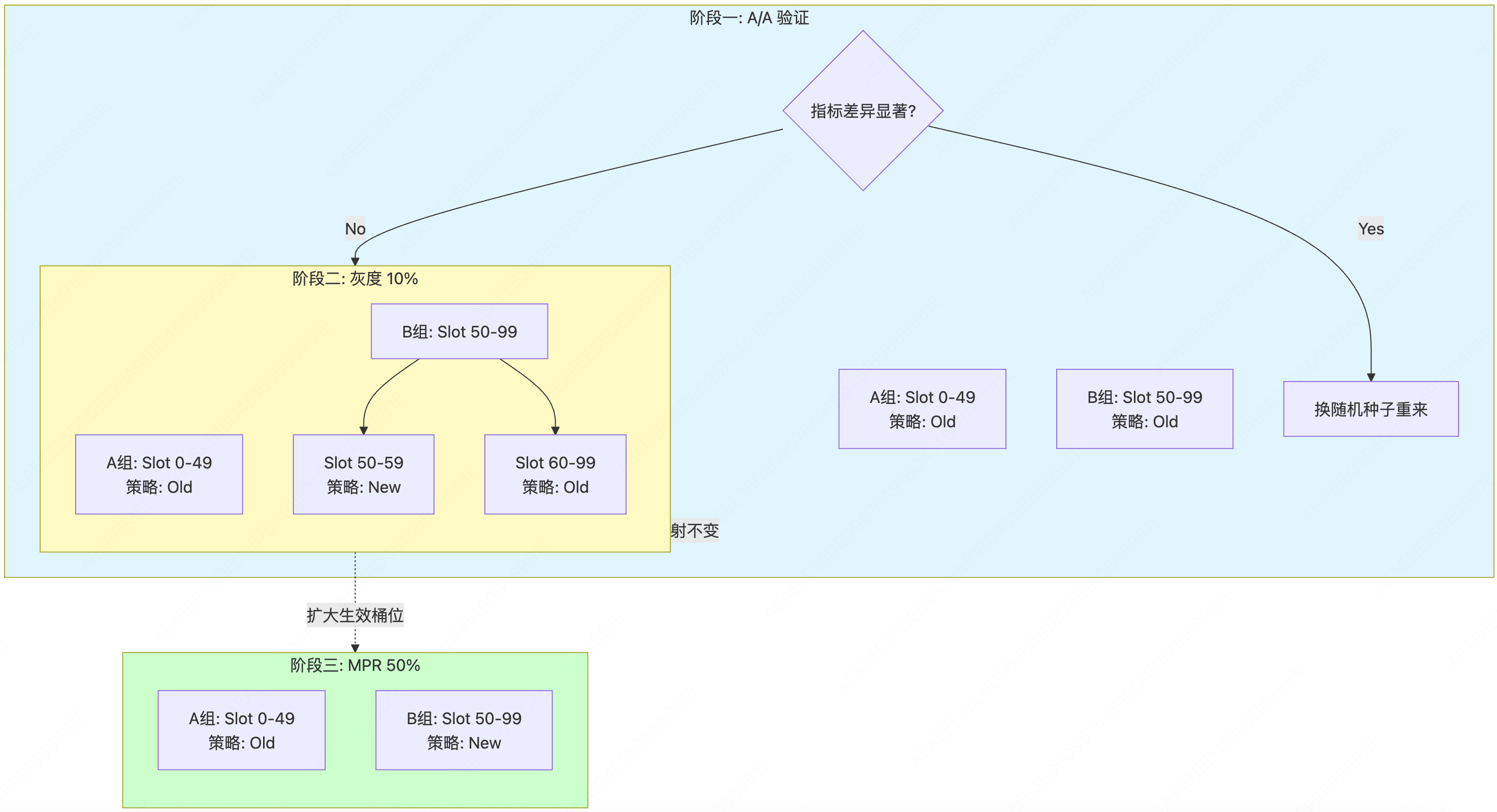
这就需要实验平台具备**"精细化桶位控制 (Bucket/Slot Control)"**的能力。
巧妙的"锁桶"策略
我们不操作"人",我们操作"桶"。假设流量被切分为 100 个固定的桶(Slot 0-99)。
-
阶段一:A/A 验证期
- 配置:Group A (Slot 0-49) vs Group B (Slot 50-99)。
- 策略:两边都用老策略。
- 目的:验证 Slot 0-49 的人群和 Slot 50-99 的人群是同质的。
-
阶段二:灰度放量期 (如 10%)
- 关键点 :不要重新洗牌。保持 Slot 0-49 依然属于 A 组,Slot 50-99 依然属于 B 组。
- 操作 :
- Group A (Slot 0-49):全量保持老策略。
- Group B (Slot 50-99):
- 在 B 组内部进行逻辑判断:只让 Slot 50-59 (占总流量 10%) 生效新策略。
- Slot 60-99 (占总流量 40%) 依然保持老策略(作为陪跑)。
- 分析:此时分析 Slot 0-9 vs Slot 50-59(小流量对比),或者等待放量。
-
阶段三:MPR 黄金期 (50%)
- 操作:Group B 的新策略覆盖范围扩大到 Slot 50-99。
- 价值 :此时对比的 Group A (0-49) 和 Group B (50-99),正是我们在阶段一里千辛万苦验证过的那两波人!完美闭环。
3. 效率妥协:回溯 A/A (Post-hoc A/A)
对于大多数追求速度的业务线,"实验前 A/A"太奢侈了。这时候,回溯 A/A 是标准动作。
操作方法
- 正常开启 A/B 实验,分流产生。
- 实验平台自动记录 A 组和 B 组命中的用户 ID。
- 穿越回去 :去数仓里捞这批用户在实验开启前 7 天的行为数据。
- 对比:计算这两波人在 7 天前的转化率、人均时长等指标。
优缺点分析
- 优点 :
- 快:不需要空跑,上线即实验。
- 省:不浪费流量。
- 缺点 :
- 赌博性质:如果回溯发现差异显著(比如 A 组历史表现本来就比 B 组好),那当前的实验结果就不可信了。
- 补救成本 :一旦未通过,只能更换随机种子 (Salt) 重新分流,之前的实验数据全部作废。这实际上比实验前 A/A 损失更大。
- 局限性 :依赖用户 ID 的稳定性。如果是新用户注册实验(New User),这些人在 7 天前根本不存在,无法使用回溯 A/A。
补正办法:预验证种子库
为了降低"赌输"的概率,平台方可以在后台通过离线数据跑脚本,预先筛选出一批**"也是均匀的随机种子"**。
当业务方开实验时,直接分配这些经过验证的种子,从而把回溯 A/A 的通过率从 95% 提升到 99.9%。
总结
A/A 实验是数据科学家的**"验钞机"**。
- 不要裸奔 :无论你用哪种方案,必须做 A/A 验证。不做 A/A 的实验结论,就像没有校准的天平,毫无公信力。
- 分场景选择 :
- 核心算法/重大改版 → \rightarrow → 实验前 A/A + 锁桶(求稳)。
- 日常运营/UI微调 → \rightarrow → 回溯 A/A(求快)。
- 新用户实验 → \rightarrow → 实验中 A/A(没得选)。
信任很难建立,但很容易崩塌。一次错误的实验结论,可能让你失去业务方所有的信任。A/A 实验,就是守护这份信任的最后一道防线。
如果这篇文章帮你理清了思路,不妨点个关注,我会持续分享 AB 实验干货文章。
