一、学习背景
曾经,如果我们在网页上查新某些数据,在输入框中输入部分内容,后台默认可能是通过SQL的模糊查询进行操作的。
但是在现今的大数据时代,有几百万条数据,那么常规的模糊查询就非常的缓慢了,慢慢的演进出了索引,但是还是达不到大数据的要求。
那么,就有必要学习一款分布式全文搜索引擎。那么ElasticSearch主要功能就是搜索,如果在某个网站上需要用到搜索功能基本上都是用的ElasticSearch。
二、ES的起源
首先需要了解Lucene,是一套信息检索工具包,就是一个jar包,但是不包含搜索引擎。它里面有一些索引结构(相当于数据库中的表)、读写索引的工具、排序、搜索规则等等工具类。
那么我们的ES就是基于Lucene工具包做了一些增强和封装,上手十分简单!!!
三、ES概述
ES是一个开源的高扩展的分布式全文搜索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RestFul API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
现今,ES已经是全世界排名第一的搜索引擎类应用!!!
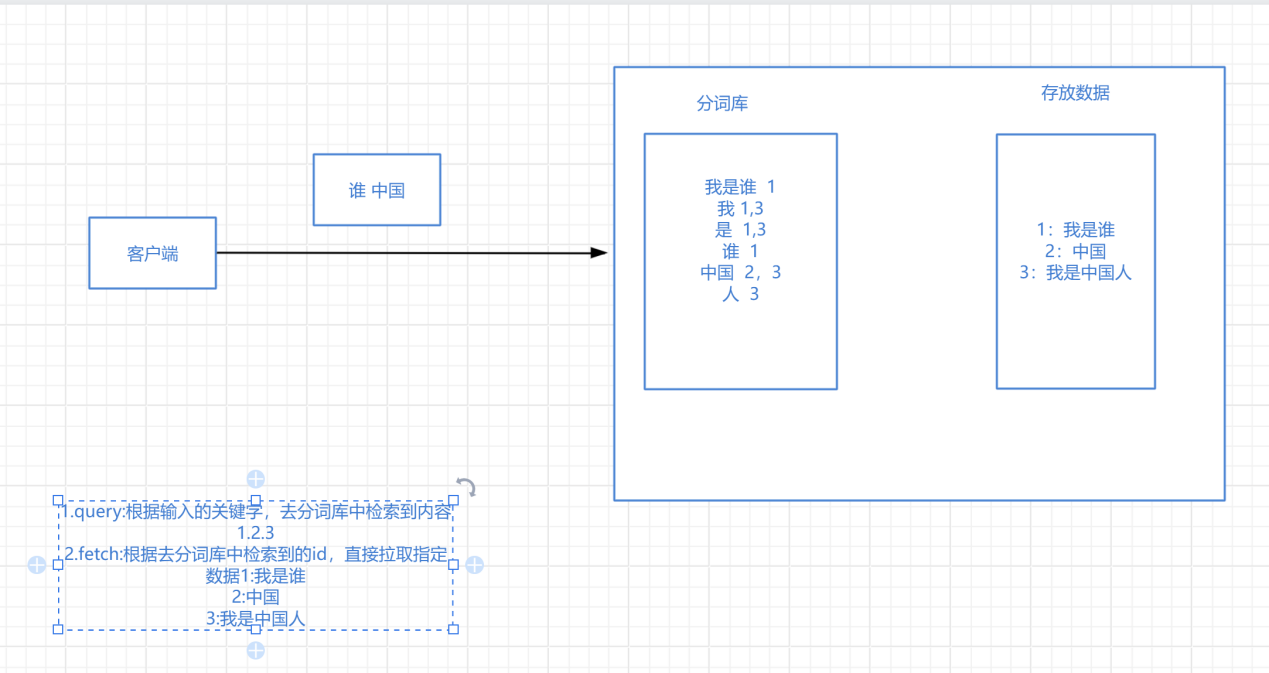
四、倒排索引
将存放的数据,以一定的方式进行分词,并且将分词的内容存放到一个单独的分词库中。当用户去查询数据时,会将用户查询关键字进行分词,然后去分词库中匹配内容,最终得到数据的id标识,根据id标识去存放数据的位置拉取到指定的数据。
画图画工具:https://www.processon.com/
五、环境准备
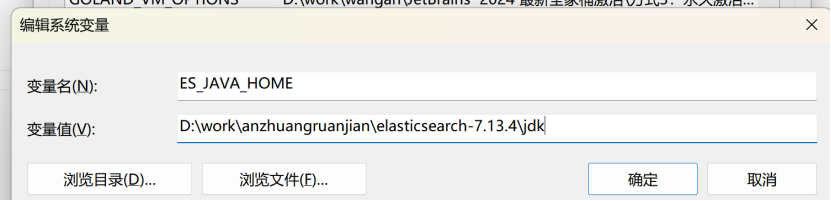
ElasticSearch是使用Java开发的,且7.8版本的ES需要JDK版本1.8以上,默认安装包带有jdk环境,如果系统配置JAVA_HOME,那么使用系统默认的JDK,如果没有配置使用自带的JDK,一般建议使用系统配置的JDK。
怎么使用Elasticsearch自带的jdk呢?
我们看一下下载之后的Elasticsearch包下bin目录下的elasticsearch-env.bat文件
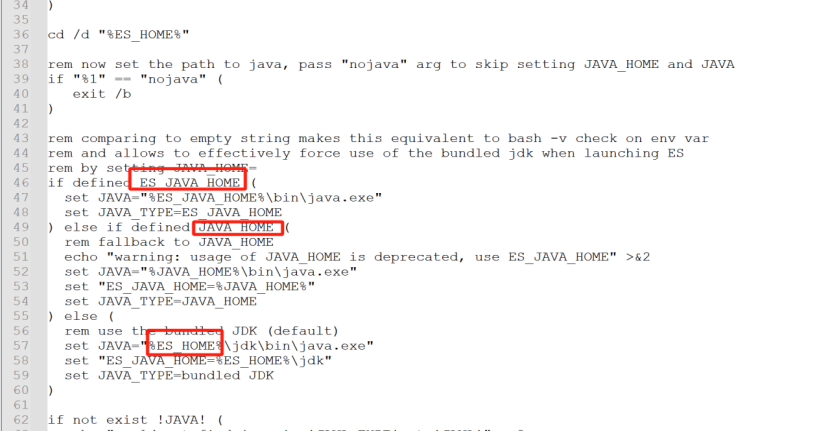
JAVA_HOME是我们配置的jdk的环境变量,假如我们配置了ES_JAVA_HOME就会优先使用我们下载的Elasticsearch自带的jdk。
六、下载Elasticsearch
6.1:Elasticsearch:下载:
下载地址:https://www.elastic.co/downloads/past-releases/elasticsearch-7-13-4
JDK兼容查看:https://www.elastic.co/cn/support/matrix#matrix_jvm
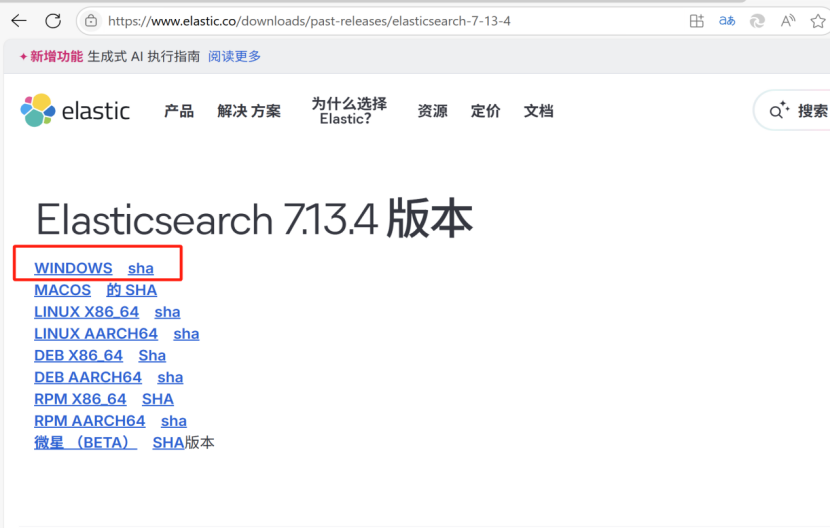
下载之后是一个压缩包,只需要解压即可
解压后的目录:
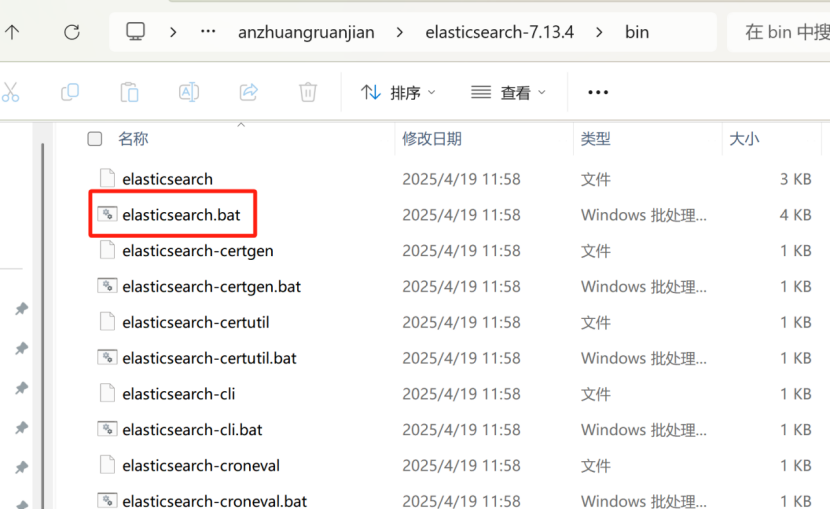
bin目录下有启动类
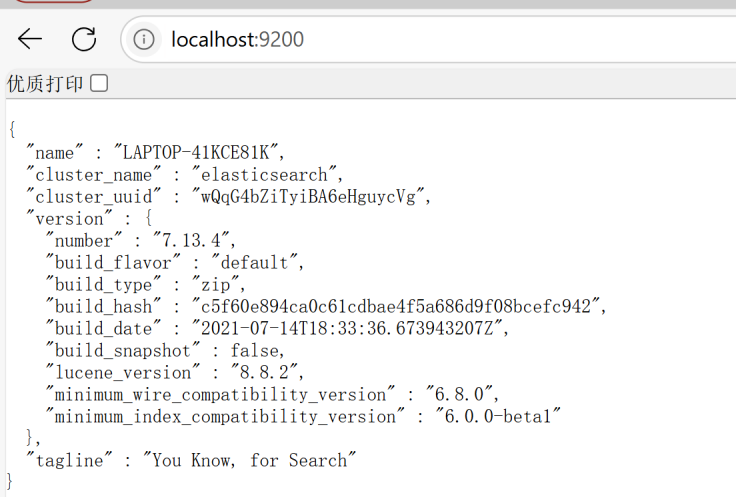
启动后在浏览器输入:http://localhost:9200
6.2:安装ElasticSearch-head插件
Elasticsearch-head是一个轻量级的Elasticsearch管理工具,主要用于集群的可视化管理。其主要功能包括:
实时监控集群健康状态:Elasticsearch-head可以实时显示集群的健康状况,包括节点的状态、分片分布等信息,帮助用户了解集群的整体运行情况。
可视化展示节点和分片分布:通过图像化的方式展示集群中的节点和分片分布情况,使用户能够直观地了解数据地存储和分布情况。
索引管理和数据浏览:用户可以直接在Elasticsearch-head中管理索引,浏览数据,而无需通过其他工具或命令行操作。
执行REST API命令:Elasticsearch-head提供了一个接口,允许用户通过选择和输入方式执行REST API命令,简化了API的使用过程。
跨域访问配置:为了在Elasticsearch中正常使用Elasticsearch-head,需要配置Elasticsearch的跨域访问设置,允许从不同的域名或端口访问Elasticsearch服务。
此外,Elasticsearch-head相比Kibana,具有更轻量的特点,适合快速部署和日常运维使用。
下载安装:
1:使用NPM安装
2:安装grunt Grunt 是基于 Node.js 的前端自动化工具
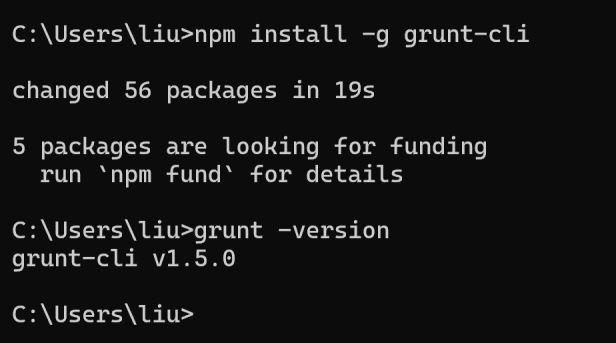
CMD中执行 npm install -g grunt-cli
输入:grunt -version 命令检查是否安装成功
3:Head插件下载
方法一:https://gitcode.com/gh_mirrors/el/elasticsearch-head?utm_source=csdn_github_accelerator,直接去github镜像地址下载压缩包
方法二:
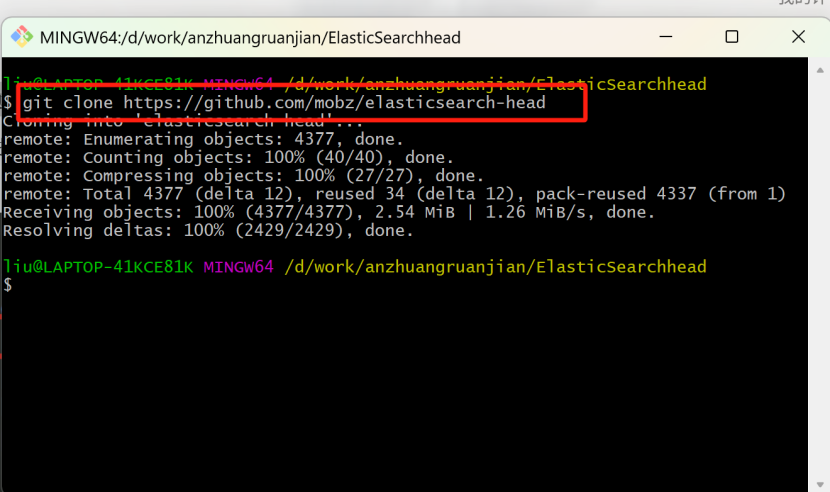
下载地址:https://github.com/mobz/elasticsearch-head,该地址需要在git下载
创建一个文件夹,ElasticSearchhead,进入到该文件夹下
在该文件夹下,右键,找到 git bash here
下载完成之后,打开elasticsearch-head文件夹,修改Gruntfile.js文件,添加hostname*,详情如下: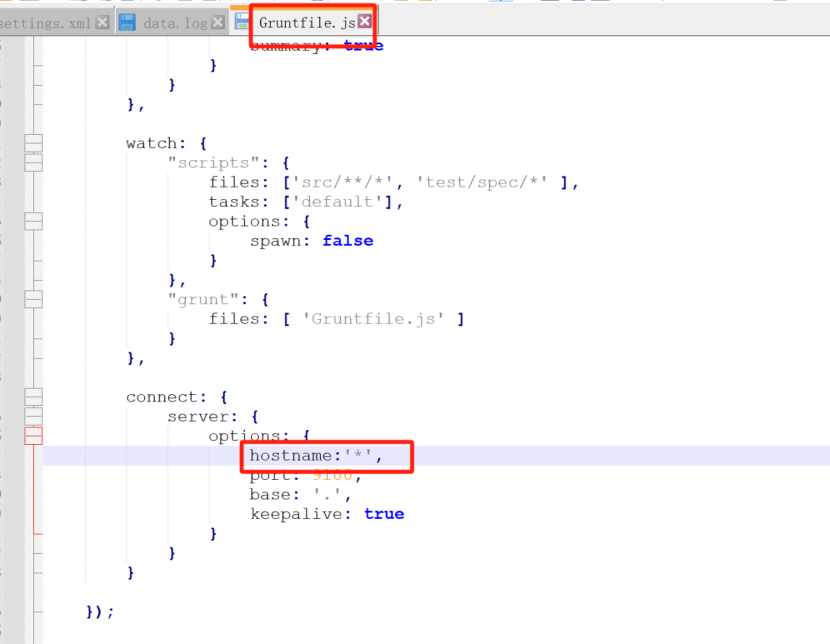
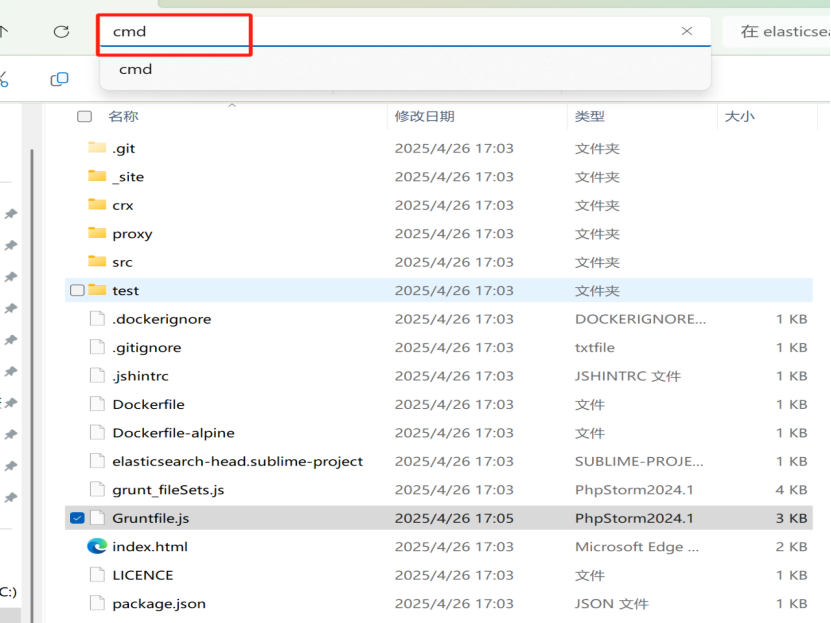
在elasticsearch-head文件下,上方的地址栏输入cmd,回车打开命令窗口
如下图:
打开后:
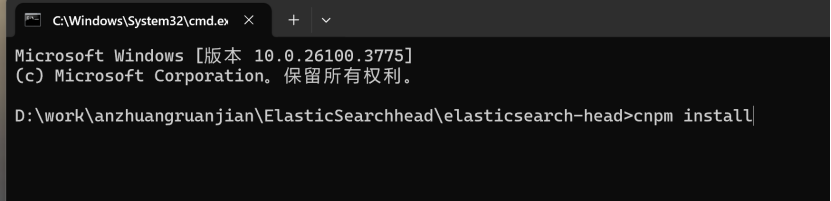
执行cnpm install 安装依赖
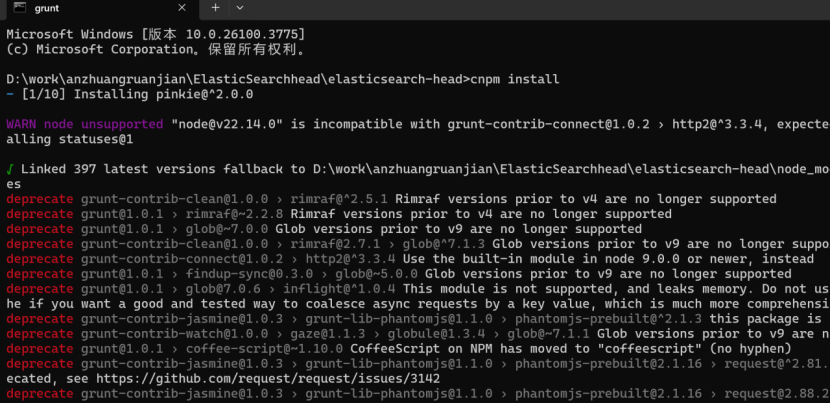
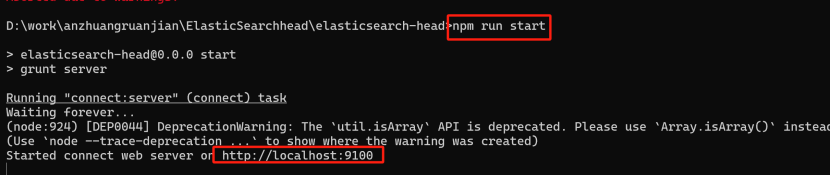
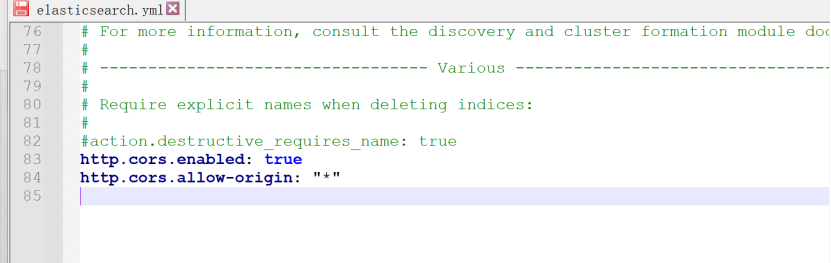
下方是启动地址打开之后效果如下:
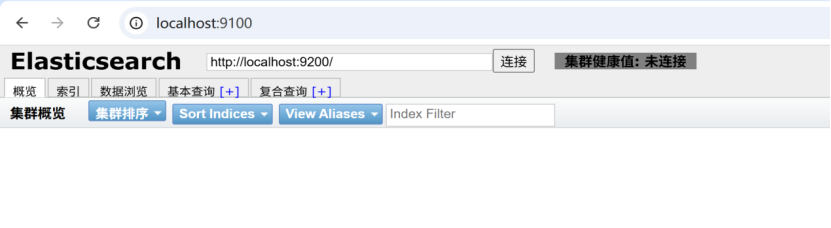
上图中集群健康值:未连接,这个有个跨域问题
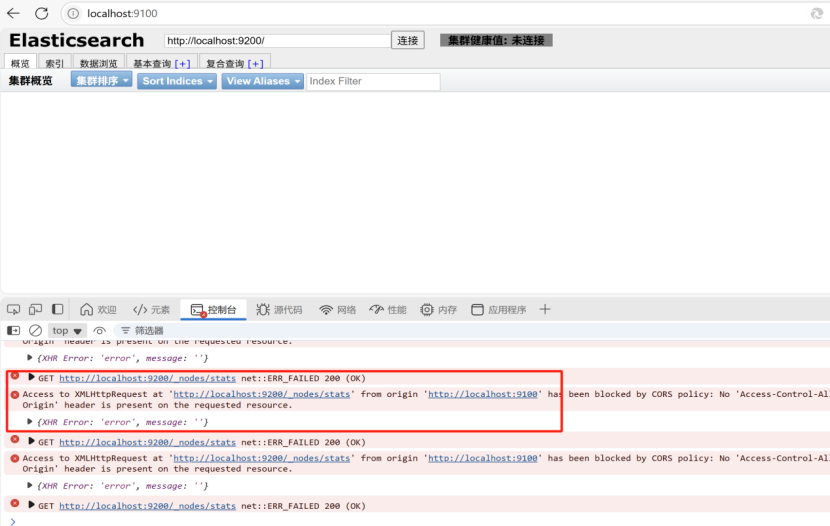
这里我们需要在Elasticsearch下找到下图文件,然后在里面添加以下两行
http.cors.enabled: true
http.cors.allow-origin: "*"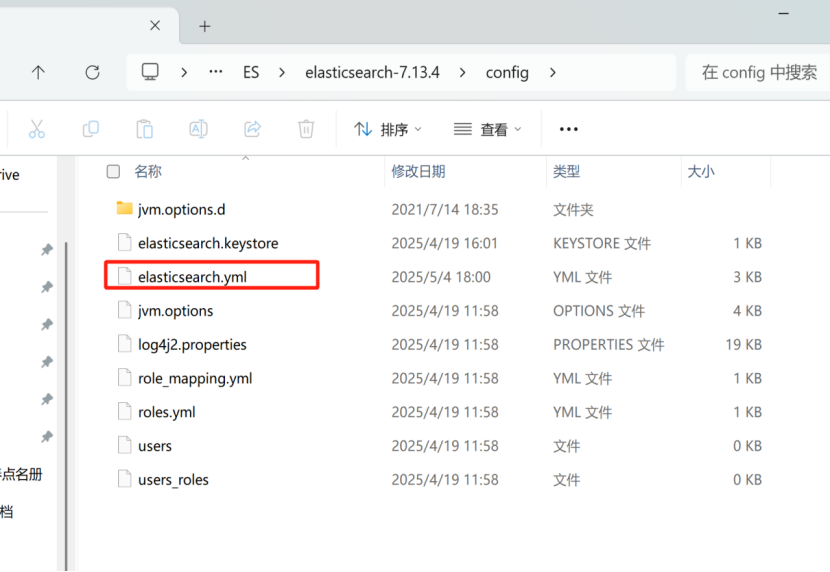
添加后重启Elasticsearch服务
再次链接
七、了解ELK
7.1:ELK
ELK是Elasticsearch 、Logstash 、Kibana 三大开源框架首字母大写简称。市面上也被称为Elastic Stack,其中Elasticsearch 是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候,我们简Elasticsearch为es;Logstash 是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过波后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等);Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性,并非唯一性。
7.2:安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据,使用Kibana可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表盘(dashboard)实时显示Elasticsearch查询动态,设置Kibana非常简单,无需编码或者额外的基础框架,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
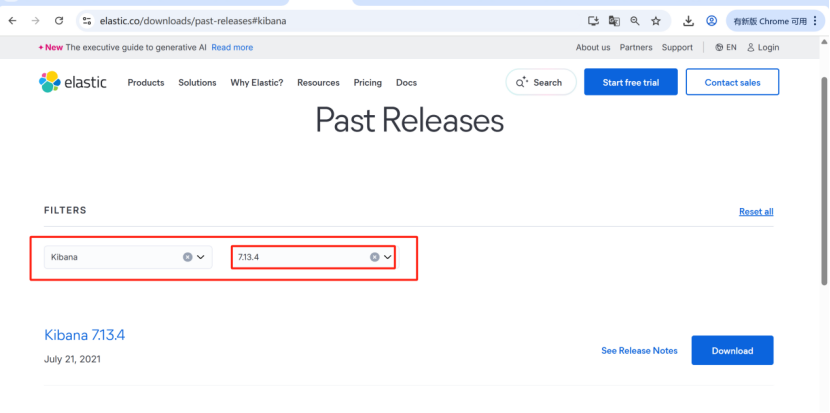
官网下载地址:https://www.elastic.co/downloads/past-releases#kibana
跟之前es对应的版本地址:https://www.elastic.co/downloads/past-releases/kibana-7-13-4
需要注意:Kibana的版本需要跟我们前面下载的Elasticsearch版本保持一致,比如Elasticsearch是7.xx版本,Kibana也需要是7.xx版本。
下载完成之后,解压即可 解压后启动服务
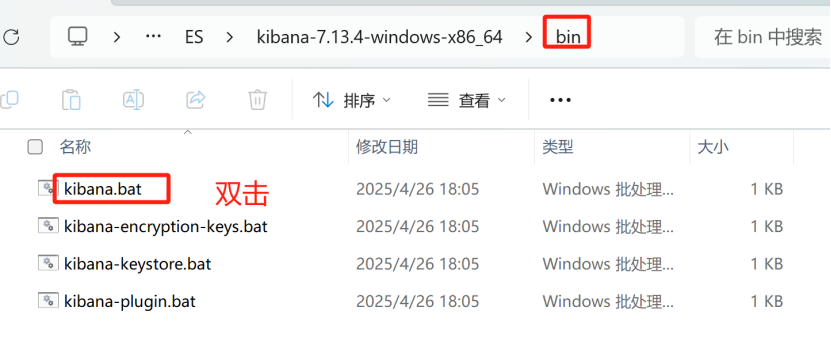
如果双击没有反应使用命令行启动服务,在上图的地址栏输入cmd,进入命令窗口kibana.bat
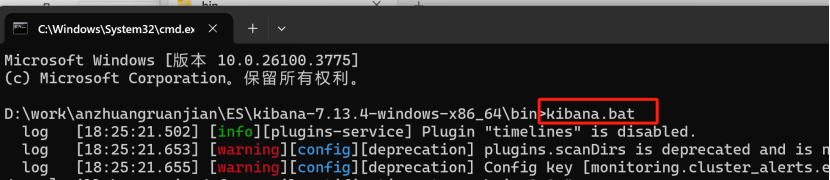
启动成功之后,在浏览器输入:http://localhost:5601
八、索引操作
8.1:创建索引
对比于关系型数据库,创建索引就相当于创建数据库。
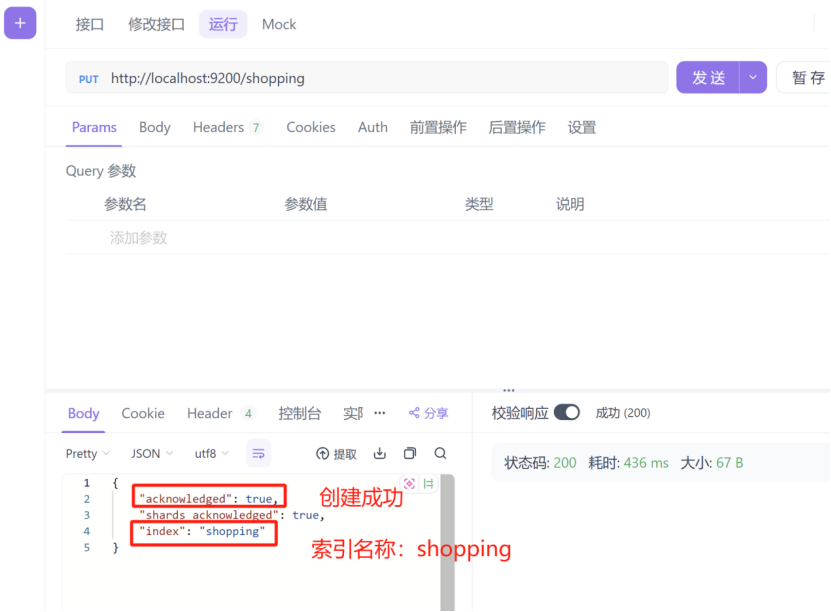
在psotman或者apifox中,向ES服务器,发送put请求,比如:http://localhost:9200/shopping
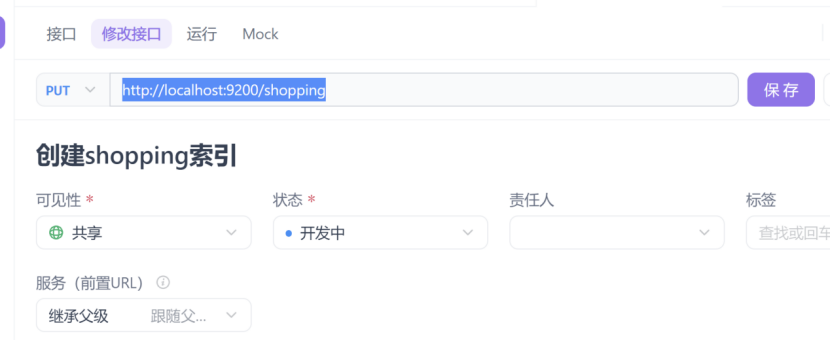
注意,这里要使用put请求
查看运行结果:
8.2:查询索引
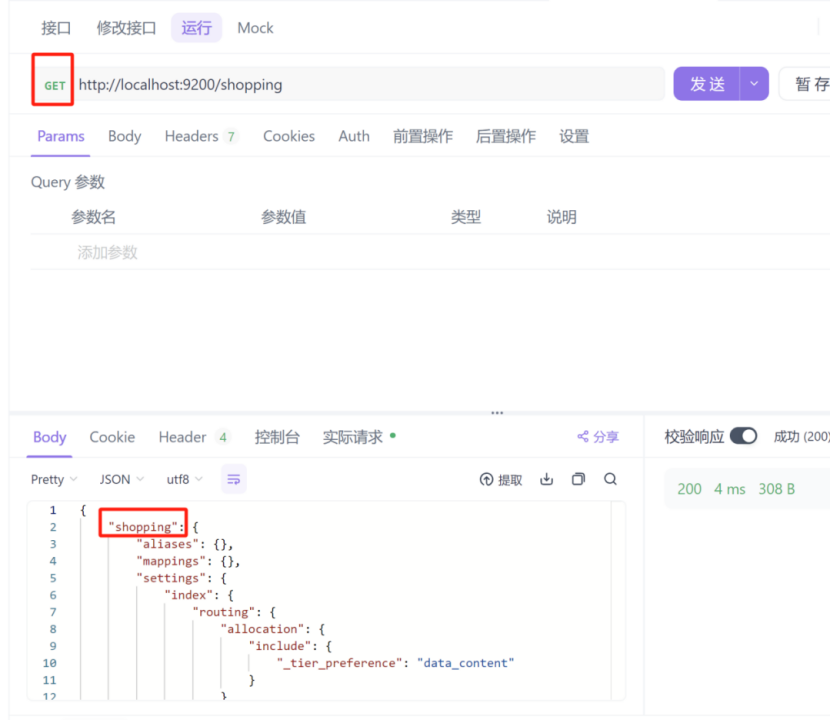
查询单个索引:
假如我们查询我们刚刚创建的shopping索引,我们只需要将我们的请求,从put改为get即可,如下图:
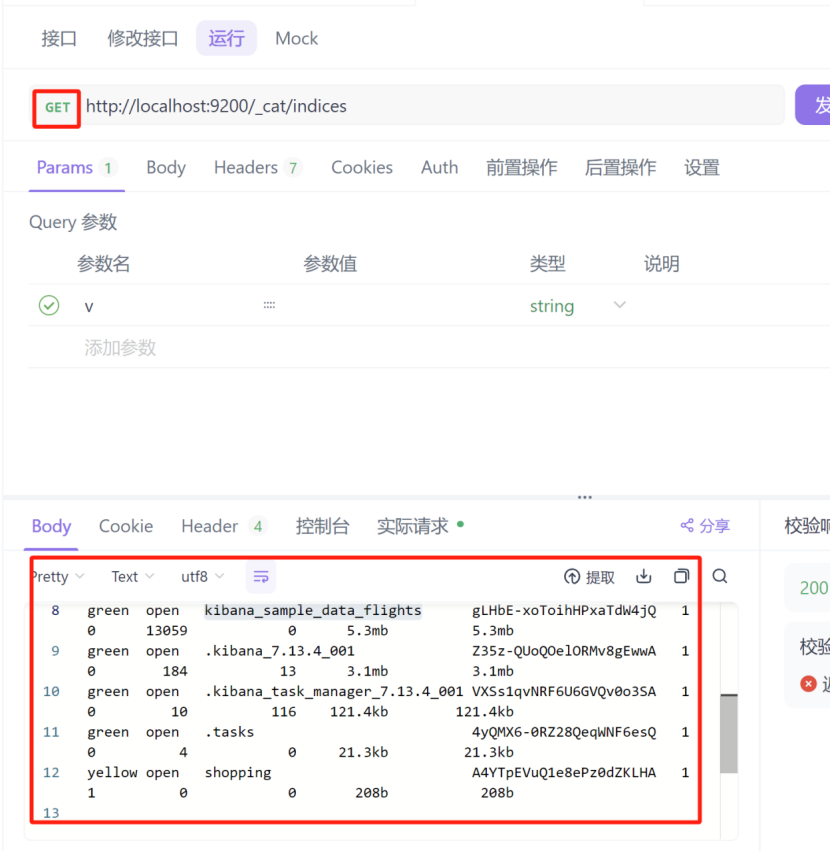
查看所有索引,这里是使用的固定的写法,请求方式还是get,请求路径如下http://localhost:9200/_cat/indices?v
8.3:删除索引
删除索引和单个查询,以及新增是一样的,只不过我们的请求方式要改为delete,如下图
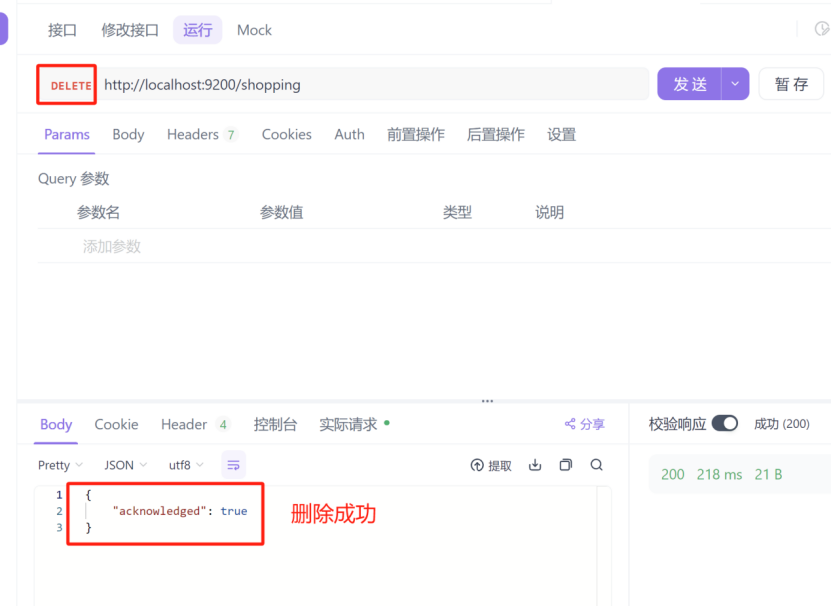
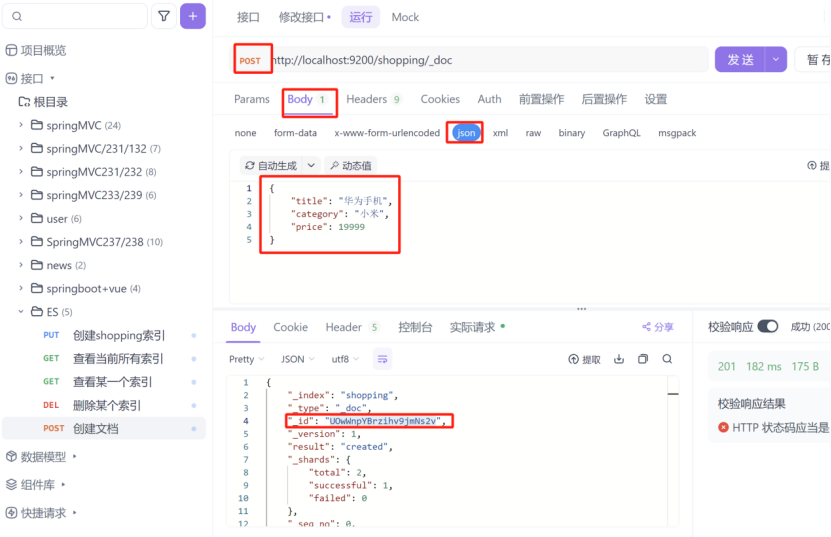
8.4:创建文档
在创建文档时,使用的请求为post请求,请求路径为
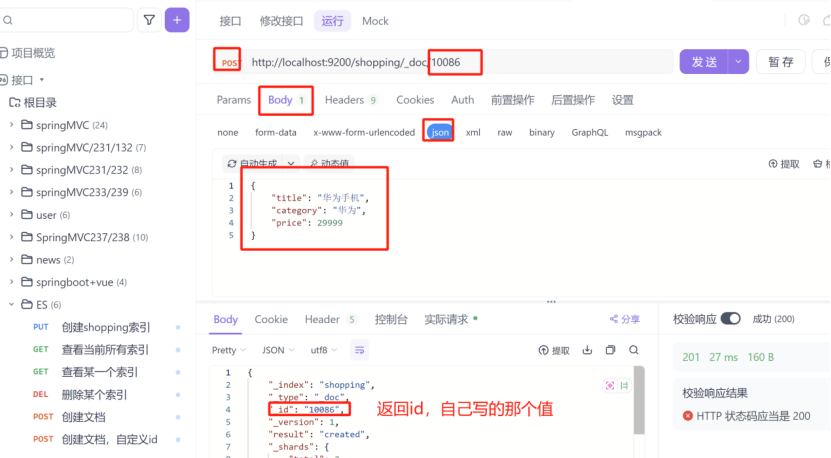
自定义id,在上图中,创建文档之后生成了一个id,这个id很长,我们给他自定义一个好记的id,请求路径 http://localhost:9200/shopping/_doc/10086
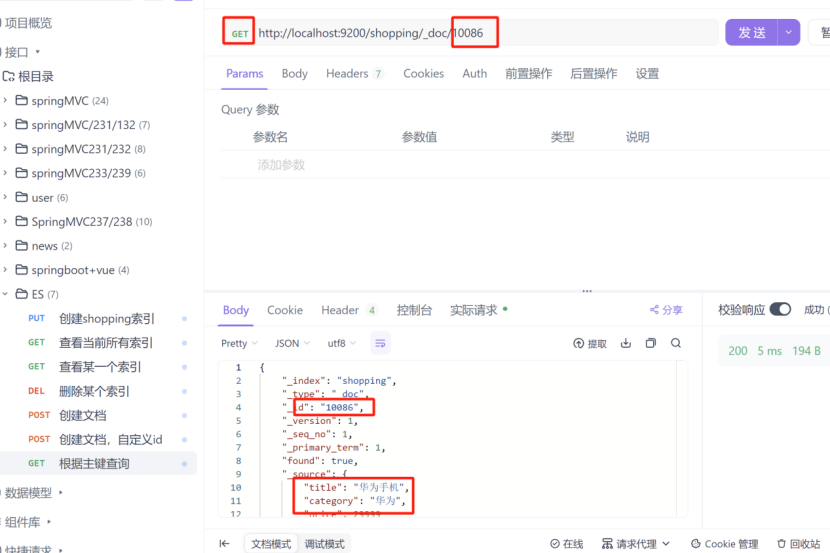
8.5:根据主键查询
在上图中,我们在返回值中,看到id为10086,那么我们根据这个id去查询看看返回结果,使用的请求方式为get
8.6:查询所有
8.7:全量修改,局部修改
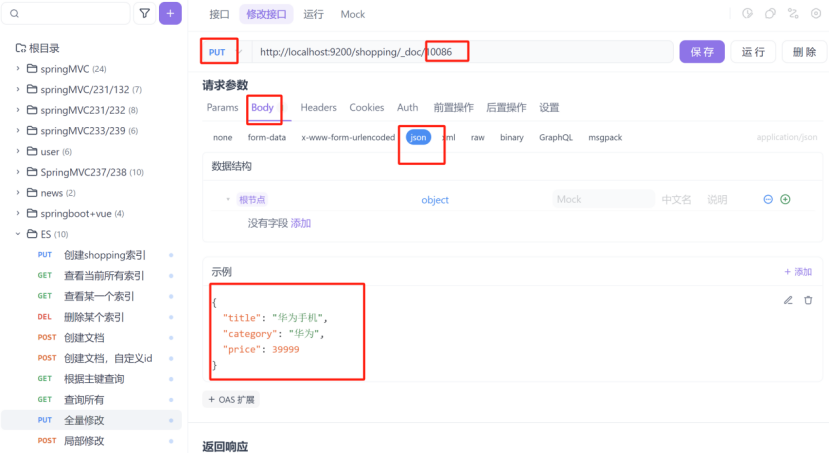
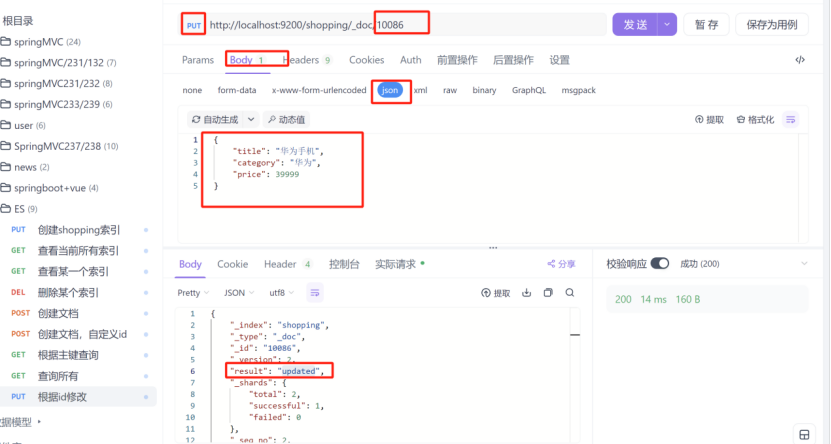
1:全量修改
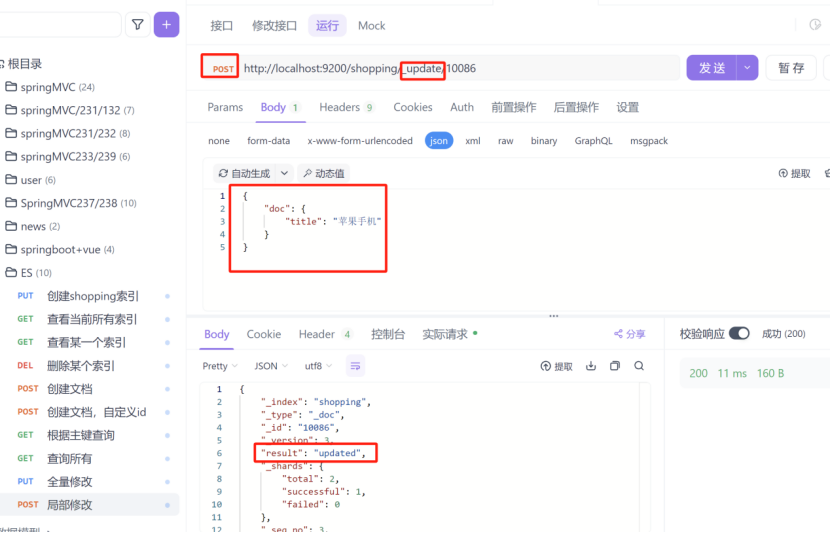
2:局部修改
8.8:条件查询,分页查询
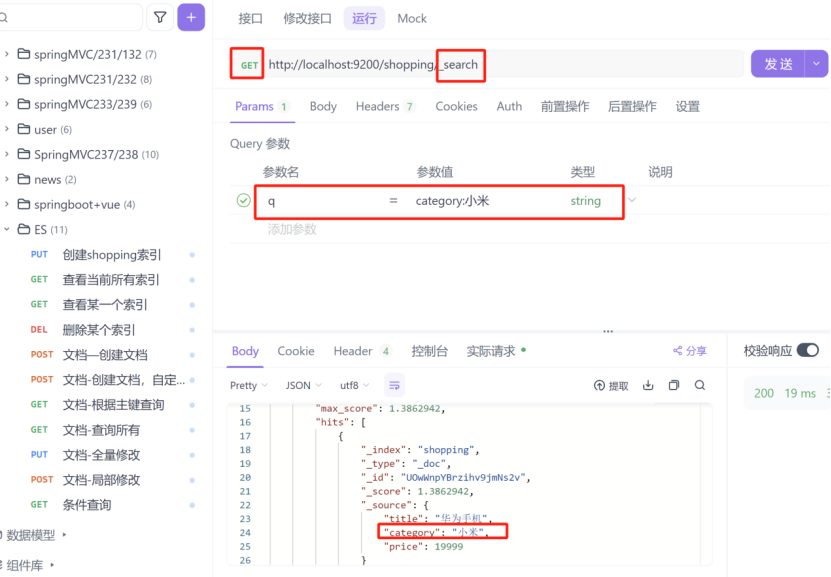
1:条件查询,在请求路径中添加参数
2:条件查询,在请求体中添加查询参数
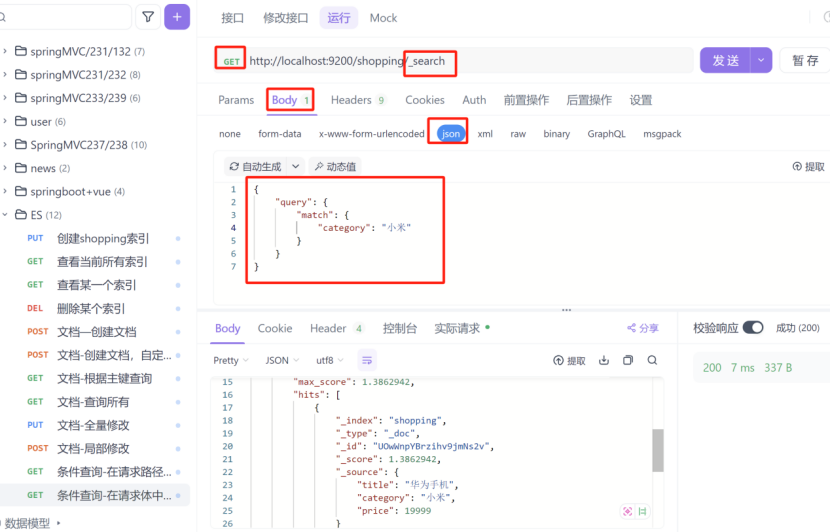
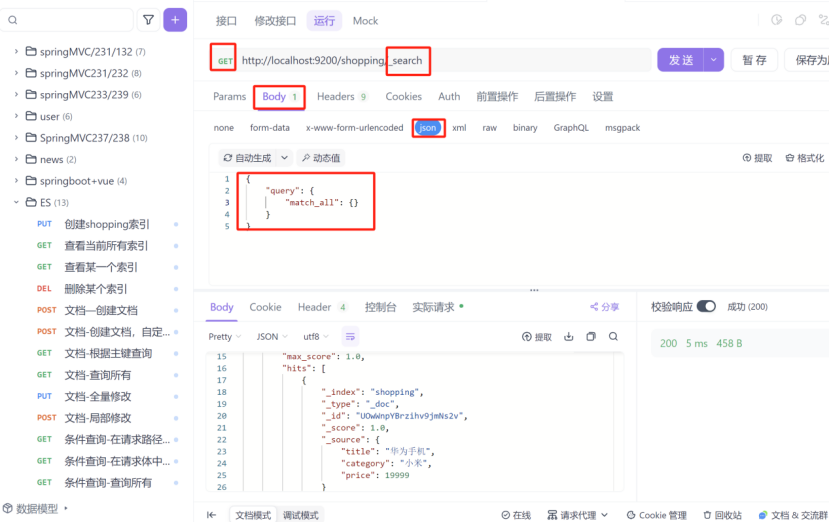
3:条件查询,查询所有
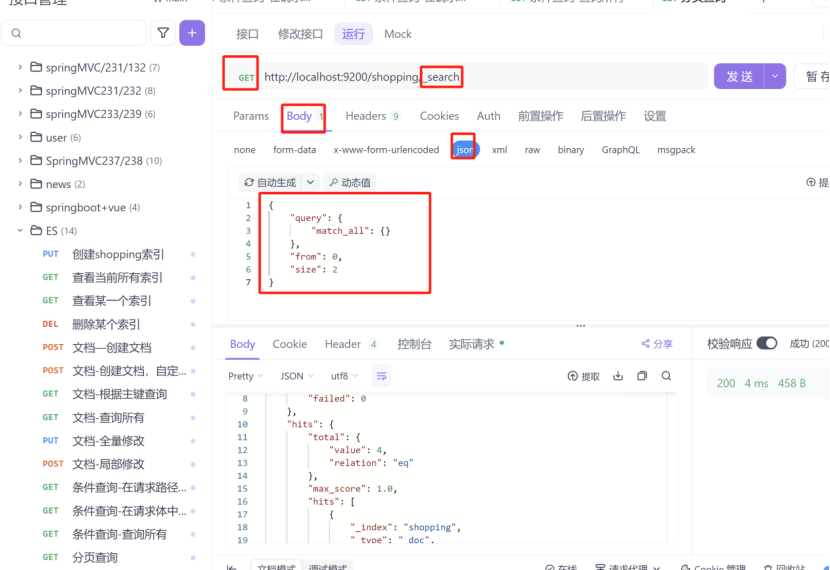
4:分页查询
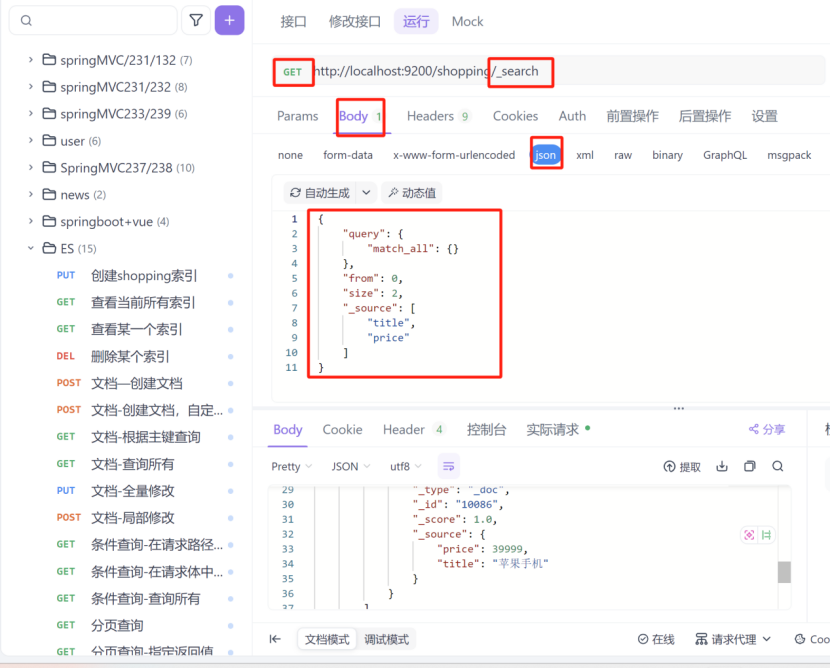
5:分页查询,指定返回结果
8.9:多条件查询,范围查询
1:多条件查询,多个条件同时符合
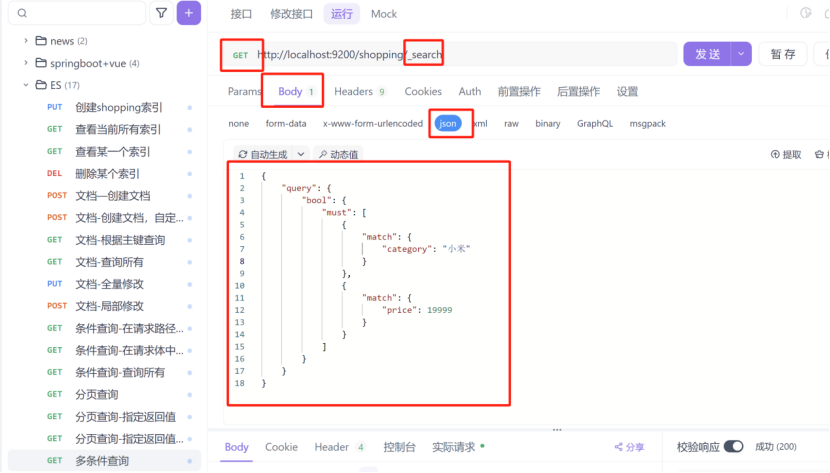
query:表示查询条件
bool:表示条件
must:表示多个条件同时成立
match:表示匹配的条件
2:多条件查询,或查询
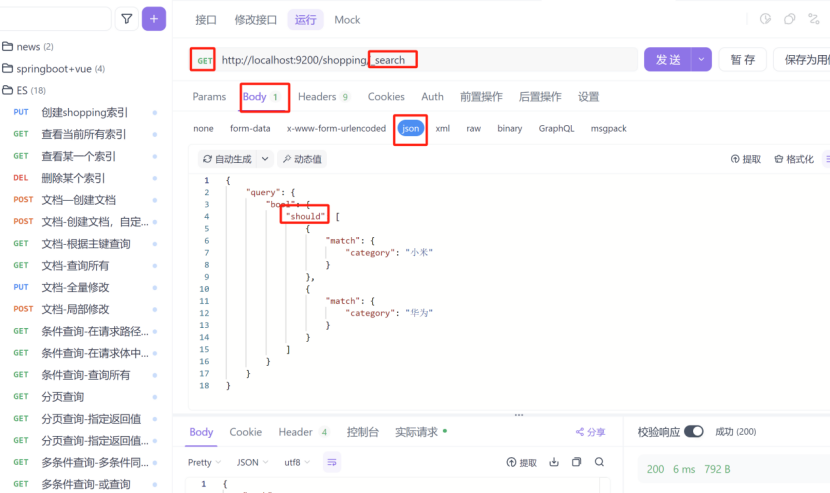
should:表示或
3:范围查询
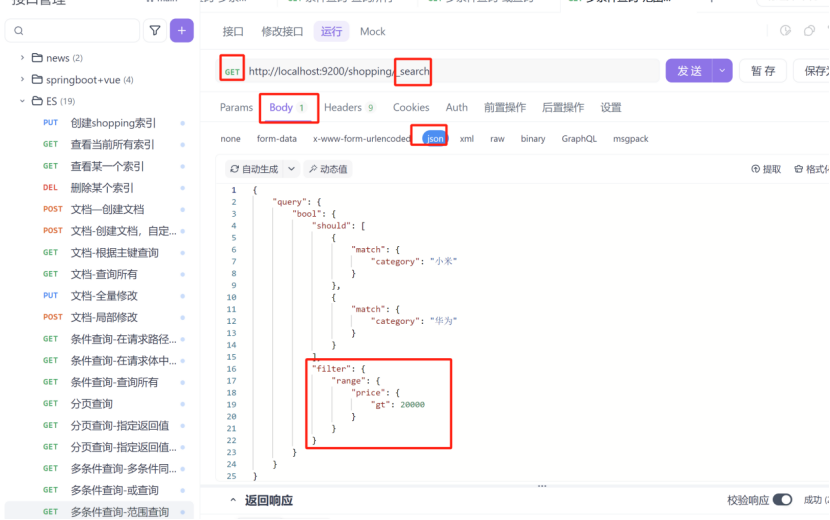
filter:表示过滤
range:表示范围
gt:相当于大于号,lt表示小于号,ge表示大于等于,le表示小于等于
8.10:完全匹配,高亮查询
1:完全匹配
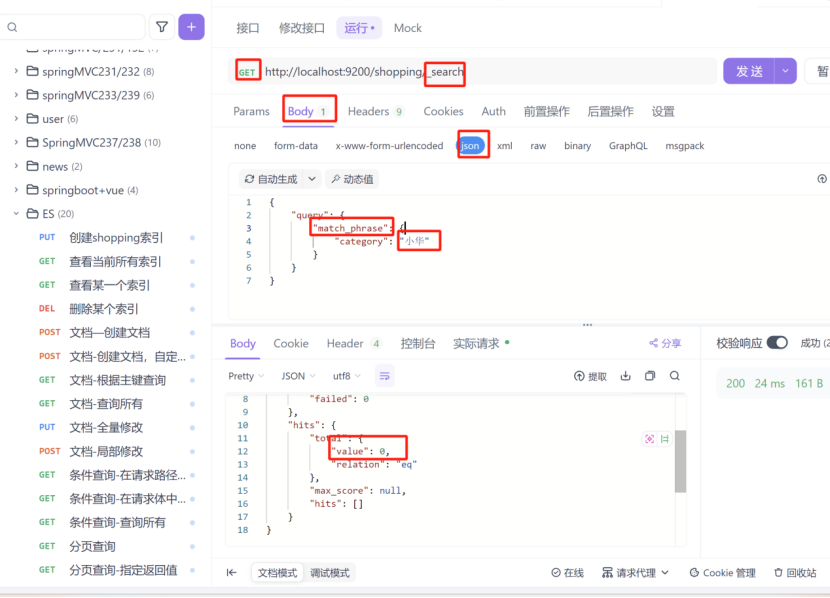
match_phrase:完全匹配
2:高亮查询
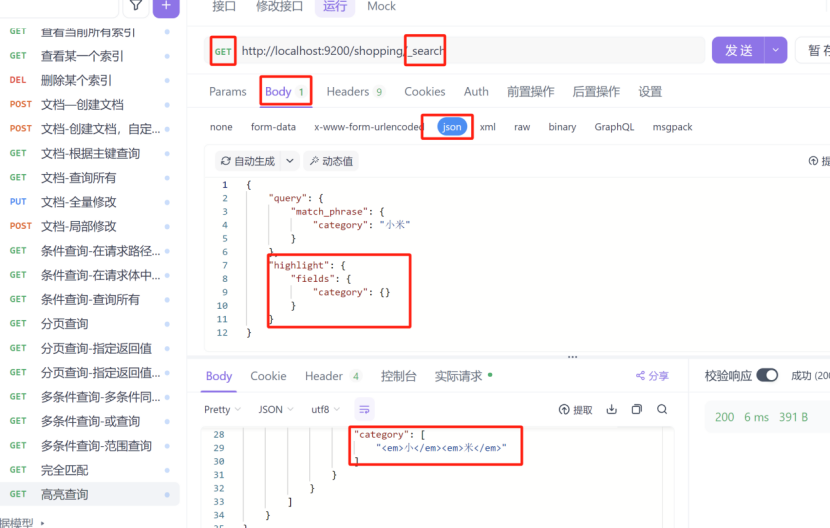
highlight:高亮
fields:表示对某个字段
8.11:聚合查询
1:分组查询
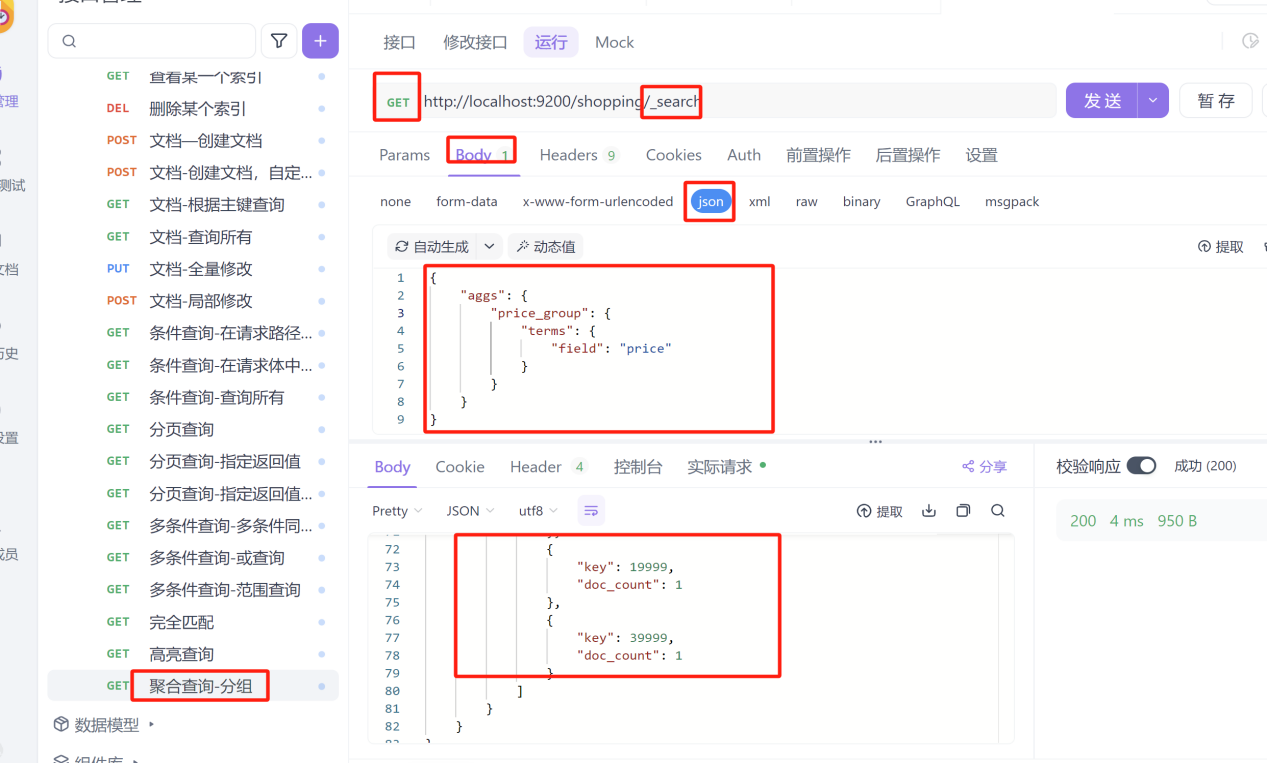
aggs:聚合操作
price_group:这个是自己分组起的名字,名字自定义
term:分组
field:分组字段
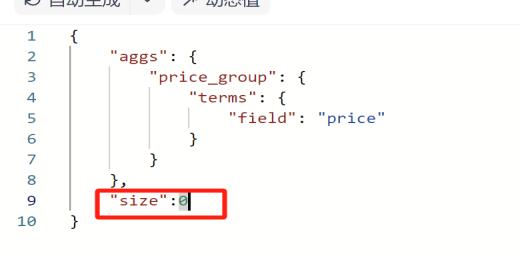
添加"size:0"隐藏原始字段
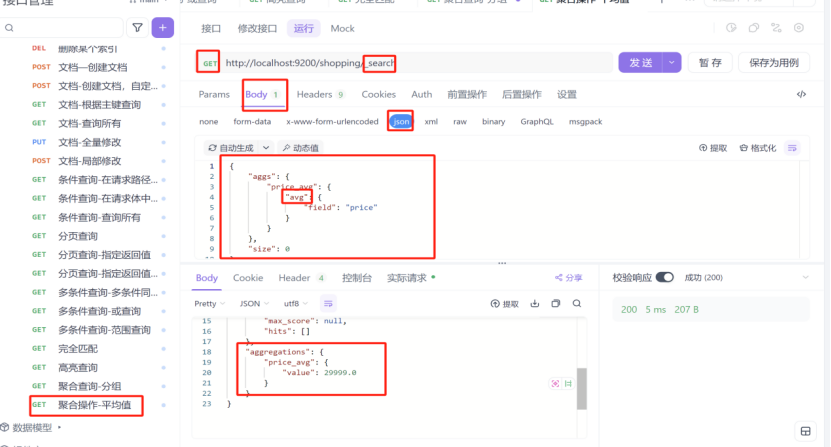
2:求平均值
九、映射关系
1:先创建一个user索引
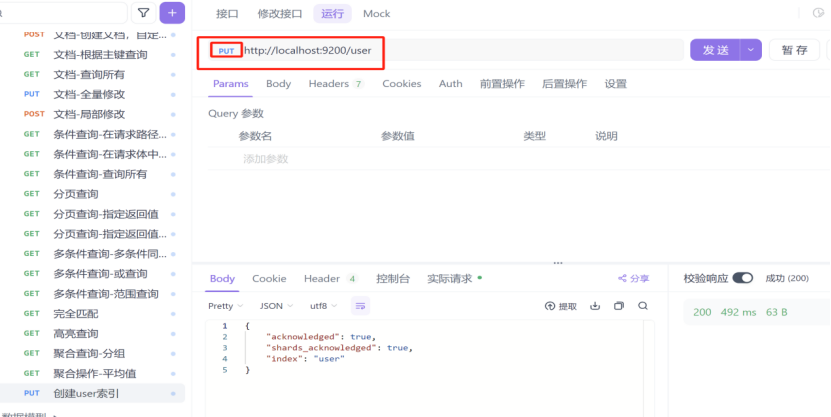
2:创建映射条件
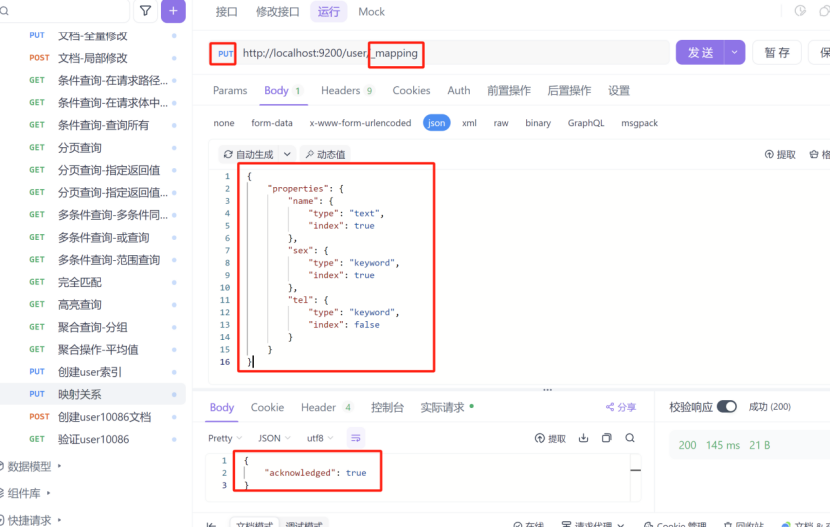
3:创建测试的user文档
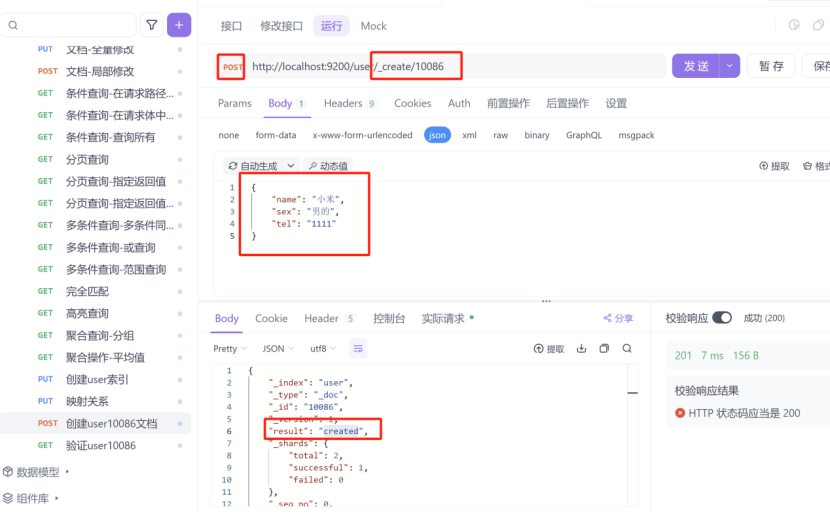
4:验证映射条件