2026年1月24日学习总结:
在之前已经结束了C语言初阶的学习,将进入C语言进阶的学习。在进入学习下一节之前补充一个知识点:
数组的越界访问代码的debug环境和release环境中运行的区别(X86环境下)
代码如下:
cs
#include<stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int i = 0;
for (i = 0; i <= 12; i++)
{
printf("hehe\n");
}
return 0;
}在debug环境下为死循环(一直打印hehe),因为arr(低)的内存地址在i(高)地址后面,且包含一定间隔,就会出现地址冲突的情况。
而在release环境下只是打印了13个hehe,并没有陷入死循环。这是因为release环境下对该程序进行了优化,此时arr(高)的内存地址在i(低)地址的前面,从低到高进行访问时就不会出现地址冲突情况。
然后进入C语音进阶的学习,首先进入第一章的学习------数据在内存中的存储,本次学习主要分为以下两个部分:
1.数据类型介绍
基本数据类型:
char 字符数据类型 1字节
short 短整型 2字节
int 整型 4字节
long 长整型 32位机:4字节/64位机:8字节(C语音中:sizeof(long)>=sizeof(int))
long long 更长整型 8字节(C99中使用)
float 单精度浮点数 4字节
double 双精度浮点数 8字节
类型的意义:① 使用这个类型开辟空间的大小(大小决定使用范围);② 如何看待内存空间的视角。
1.1类型的基本归类
(1)整型家族:
char unsigned char signed char
short unsigned short int signed short int
int unsigned int signed int
long unsigned long int signed long int
long long unsigned long long int signed long long int
①为什么将char归纳到整型?
char本质是ASCLL码,是整型,所以划分到整型家族。
②char更详细的划分应该有3种类型:char,unsigned char,signed char。因为在使用cahr时并为定义是有符号还是无符号,这取决于编译器的实现。其余的都只有两种无符号和有符号,单独的类型相当于有符号(如int相当于signed int)
③可以根据实际情况判断使用的参数有符号还是无符号,一般最高位为符合位,0为正,1为负。
(2)浮点数家族:只要是表示小数就可以使用浮点数。
float 单精度 精度低 存储的数据范围小。
double 双精度 精度高 储存的数据范围大。
(3)构造类型:自定义类型
①数组类型(创建不同数据类型和不同个数的数组)
②结构体类型 struct
③枚举类型 enum
④联合类型 union
(4)指针类型 int* char* float* void*
(5)空类型 void 表示空类型(无类型)
通常用于函数的返回类型、函数的参数、指针类型。
例如: void teat(void) 第一个void表示函数不会返回值,第二个void表示函数不需要任何参数(只能起到提示作用,不能防止)
2.整型在内存中的存储
之前我们了解过数据有不同的表示形式,二进制、十进制、八进制、十六进制等。例如在十进制的21 二进制:10101 八进制:25 十六进制:15。
2.1整数的二进制也有三种表示形式:原码、反码、补码
三种表示形式的规则:①正数的原码、反码、补码相同;②负数需要通过计算得出。
计算规则:
原码:直接通过正正负形式写出二进制序列。
反码:原码符号位不变,其他按位取反得到的二进制序列。
补码:在反码的基础上加1。
以下面的代码为例:
cs
#include<stdio.h>
int main()
{
int a = 20;
//原码、补码、反码:00000000 00000000 00000000 00010100
//转为十六进制: 0x 00 00 00 14
int b = -10;
//原码:10000000 00000000 00000000 00001010
//十六进制:0x 80 00 00 0a
//反码:11111111 11111111 11111111 11110101
//十六进制:0x ff ff ff f5
//补码:11111111 11111111 11111111 11110110
//十六进制:0x ff ff ff f6
return 0;
}在调试下查看内存存储的信息:
变量a在内存中的存储:
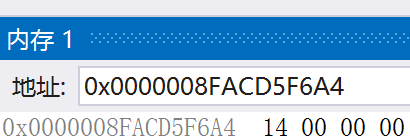
变量b在内存中的存储:
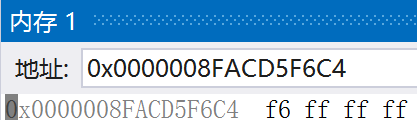
根据上面可以看出,在计算机系统中,整型数值一律用补码来表示和存储。
原因:使用补码可以将符号位和数值域统一处理,这可以使加、减法可以统一处理(补码的加减分都可以统一使用加分完成,CPU只有加法器),此外,补码与原码互相转换,其运算过程是相同的,不需要额外的硬件电路(原码和补码之间的相互转换都可以通过取反加1得到)
数据存储的顺序不对劲,为什么?
2.2 大小端介绍(大小端取决于硬件)
大端(字节序)储存:是指数据的低位保存在内存的高地址中,而数据的高位保存在内存的低地址中(补码正着存)。
小端(字节序)存储:是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中(补码倒着存,如上数据存储)。
相关试题:百度2015试题:解释大小端的区别,并用一个程序判断用的是大端还是小端存储?
版本一:将int*类型的指针强制转换成char*类型指针
cs
#include<stdio.h>
int main()
{
int a = 0;
if (*(char*)&a == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}版本二:封装成一个函数
cs
#include<stdio.h>
int test_dxd(void)
{
int a = 1;
return *(char*)&a;
}
int main()
{
int ret = test_dxd();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}