note
- 提出了绝对零范式,并通过绝对零推理器(AZR)展示了其在不需要外部数据的情况下,通过自我对弈实现强大推理能力的潜力。AZR在编码和数学推理任务上均达到了最先进的性能,并显示出显著的跨域泛化能力和模型规模效应。未来的研究方向包括探索不同的环境反馈源、扩展到多模态推理、定义或让模型动态学习如何定义任务分布、以及设计探索和多样性奖励。
- AZR整个流程就是标准On-Policy逻辑------当前策略模型生成任务→当前策略解题→环境(代码执行器)给奖励→用这批同策略样本更新模型→迭代新一轮策略生成更优任务,全程策略与样本同步迭代,无离线异策略样本介入
文章目录
一、研究背景
- 研究问题:这篇文章要解决的问题是如何在不依赖外部数据的情况下,通过自我对弈来增强大型语言模型的推理能力。现有的零样本强化学习(RLVR)方法虽然避免了监督学习,但仍然依赖于手工策划的问题和答案集,这限制了长期的可扩展性。
- 研究难点:该问题的研究难点包括:高质量人类生成例子的稀缺性、依赖手工策划数据集的长期可扩展性问题、以及在未来AI可能超越人类智能的情况下,人类设计的任务可能提供的学习潜力有限。
- 相关工作:该问题的研究相关工作有:使用可验证奖励的强化学习(RLVR)来增强大型语言模型的推理能力、零样本RLVR方法、以及自我对弈在AlphaGo和AlphaZero中的应用。
二、Absolute Zero

这篇论文提出了绝对零(Absolute Zero)范式,用于解决不依赖外部数据的推理模型训练问题。具体来说,
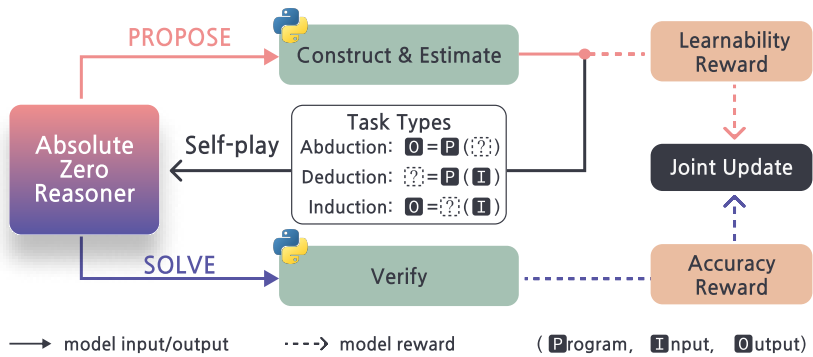
- 绝对零范式:在该范式中,模型同时学习提出任务并解决它们,从而在没有外部数据的情况下通过自我对弈进行学习和进化。模型通过代码执行器验证自我提出的代码推理任务并提供可验证的反馈,作为指导开放式但实际的学习的统一来源。
- 绝对零推理器(AZR):AZR通过自我对弈来提出和解决代码推理任务。它将代码执行器作为一个开放式但实际的环境,足以验证任务完整性并提供稳定的训练反馈。AZR学习三种基本的推理模式:归纳、推导和假设。
- 多任务学习优势估计器:为了适应多任务学习,提出了一个新的优势估计器,用于计算每个任务的相对优势。
三、实验设计
- 数据收集:实验使用了多个预训练的大型语言模型,包括Qwen2.5-7B、Qwen2.5-7B-Coder、Qwen2.5-Coder-3B、Qwen2.5-Coder-14B、Qwen2.5-14B和Llama-3.1-8B。
- 实验设置:所有实验均在A800 GPU集群上进行,每个实验持续约3-5天。使用恒定的学习率1e-6和AdamW优化器。训练批量大小为64×6(2个角色 × 3个任务类型)。
- 任务构建:AZR通过自我对弈提出和解决代码推理任务。任务类型包括归纳、推导和假设。具体任务包括生成代码、验证代码的正确性、从输入输出三元组中推理等。
- 评估协议:评估分为分布内(ID)和分布外(OOD)两类。对于OOD基准,进一步分为编码和数学推理基准。使用Evalplus、HumanEval+、MBPP+和LiveCodeBench Generation等评估工具。
四、实验结果
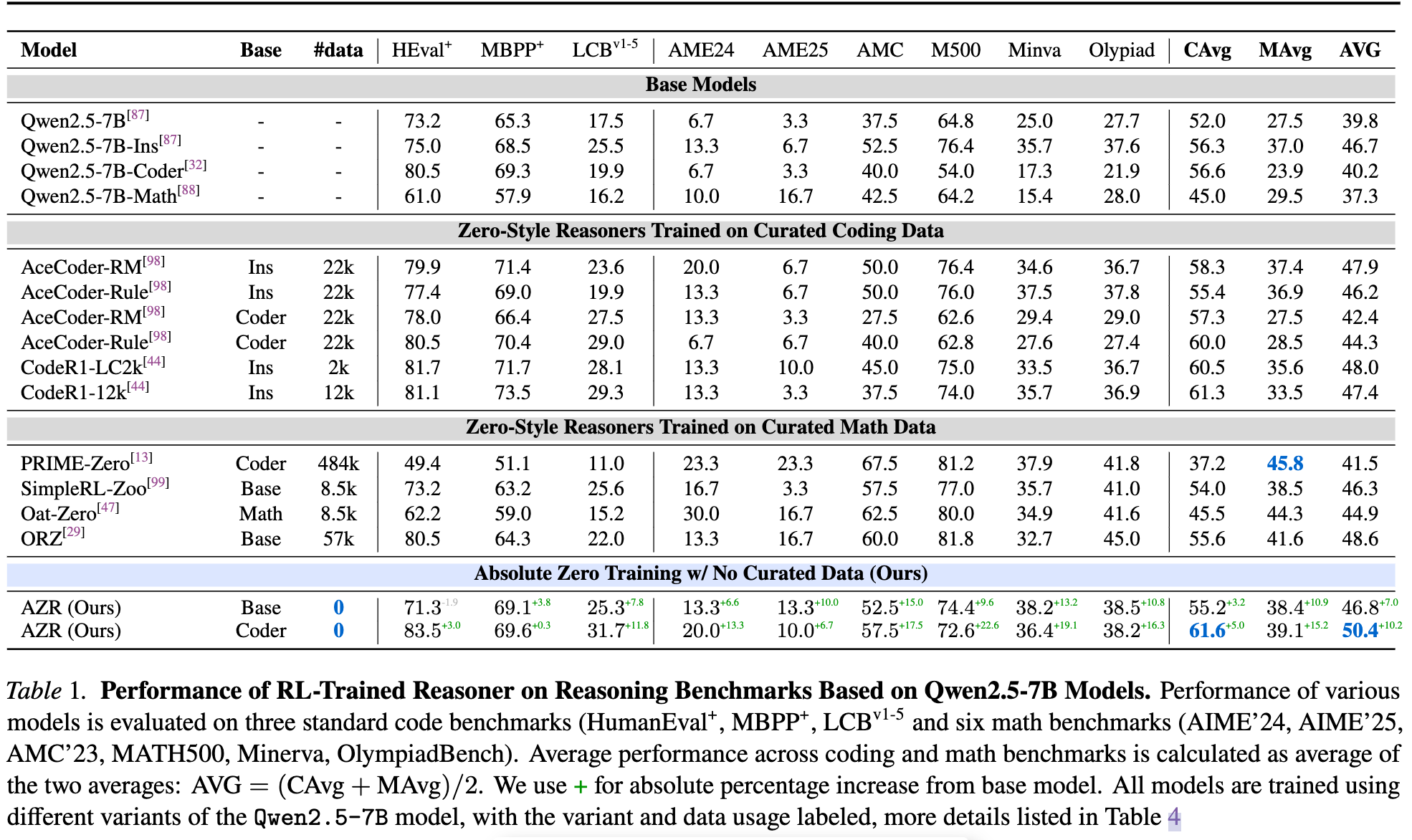
- 与现有零样本模型的比较:AZR在编码和数学推理任务上均达到了最先进的性能,尤其是在没有领域特定监督的情况下,编码任务的平均性能提高了0.3个百分点。
跨域泛化能力:经过RLVR训练后,AZR在数学任务上的性能提升显著,平均提高了10.9个百分点,而专家代码模型的平均提升仅为0.65个百分点。 - 模型规模的影响:较大的模型(如7B、14B)在分布内外任务上的性能提升更大,表明扩展模型规模对AZR的有效性有积极影响。
- 不同模型类的效果:即使在相对较弱的Llama-3.1-8B模型上,AZR也实现了适度的性能提升,表明AZR在不同模型类上均有效。
- 训练过程中的行为观察:AZR在提出任务阶段表现出多样化的编程任务,如字符串操作、动态规划问题和实际案例。在解决代码归纳任务时,AZR经常以注释和代码的形式交错中间计划。
五、论文评价
1、优点与创新
无监督自我对弈推理:提出了"绝对零度"(Absolute Zero)范式,使模型能够在没有外部数据的情况下,通过自我对弈来提出任务并解决问题,从而提高推理能力。
自演化训练课程:引入了"绝对零度推理器"(AZR),该系统能够自我演化其训练课程和推理能力,使用代码执行器验证自我提出的代码推理任务并验证答案。
跨领域泛化能力:AZR在数学和编程任务上展示了强大的跨领域泛化能力,尤其是在没有直接训练数据的情况下,仍能超越依赖领域特定监督的模型。
多任务学习优势估计器:提出了一种新的强化学习优势估计器,专门针对所提出方法的多任务特性进行优化。
代码先验放大推理:发现代码先验可以放大整体推理改进,特别是在AZR训练后,基础模型的数学性能提升了0.7个百分点。
更大的模型带来更大的增益:性能提升随着模型规模的增加而扩展,表明AZR在更大规模模型上具有更强的潜力。
中间计划自然出现:在解决代码归纳任务时,AZR经常会在代码中交错步骤计划作为注释,类似于ReAct提示框架。
安全性警报:观察到AZR偶尔会产生令人担忧的思维链,强调了未来工作需要关注安全性训练。
2、不足与反思
安全性问题:尽管AZR在没有人类监督的情况下取得了显著进展,但仍需关注潜在的安全性问题,如生成的思维链可能带来的意外行为。
探索组件的局限:当前的研究主要集中在推理任务的生成和解决上,未来可以进一步探索如何在学习任务空间内进行更高级的探索,即定义和精炼学习任务本身。
初始种子缓冲区的策略:虽然使用了统一的均匀采样策略,但基于时间序列的采样或其他策略可能会减少性能下降。
额外奖励的探索:虽然尝试了复杂性奖励和多样性奖励,但未观察到显著的性能提升,未来需要进一步研究这些方向。
环境转换的影响:移除注释和全局变量的实验表明,这些转换可能会影响模型的性能,未来需要更好地理解和控制这些转换。
Reference
1 Absolute Zero: Reinforced Self-play Reasoning with Zero Data