首先是预训练得到一个模型,但这个模型不懂人类的指令,所以要进行后训练,先是分两路,
一路是进行SFT,目的是让模型学会遵循指令和对话格式,训练数据是(prompt, completion)对
一路是进行RM奖励建模,和sft并列,建模主要是进行一个打分/排序模型,
然后进行RL强化学习
里面有一个问题值得注意,
奖励模型(RM)不能在 SFT 的基础上"顺着做",
因为 SFT 学的是「怎么生成」,
RM 学的是「怎么判断好坏」,
两者在目标函数、数据形式、梯度方向上是冲突的。
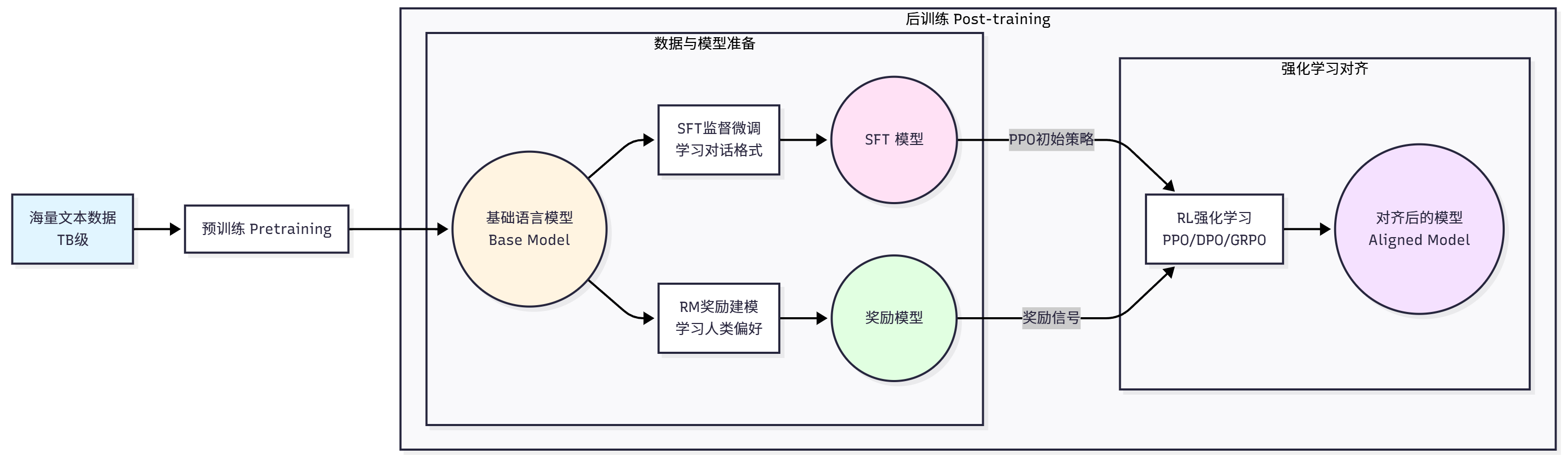
==预训练阶段 ==是 LLM 训练的第一阶段,目标是让模型学习语言的基本规律和世界知识。这个阶段使用海量的文本数据(通常是数 TB 级别),通过自监督学习的方式训练模型。最常见的预训练任务是因果语言建模(Causal Language Modeling),也称为下一个词预测(Next Token Prediction)。
==后训练阶段==则是要解决预训练模型的不足。预训练后的模型虽然具备了强大的语言能力,但它只是一个"预测下一个词"的模型,并不知道如何遵循人类的指令、生成有帮助无害诚实的回答、拒绝不当的请求,以及以对话的方式与人交互。后训练阶段就是要解决这些问题,让模型对齐人类的偏好和价值观。
后训练通常包含三个步骤。
第一步是==监督微调(SFT) ==15,目标是让模型学会遵循指令和对话格式。训练数据是(prompt, completion)对,训练目标与预训练类似,仍然是最大化正确输出的概率:
第二步是奖励建模(RM) 。SFT 后的模型虽然能遵循指令,但生成的回答质量参差不齐。我们需要一种方式来评估回答的质量,这就是奖励模型的作用13,14。
第三步是强化学习微调。有了奖励模型后,我们就可以用强化学习来优化语言模型,让它生成更高质量的回答。最经典的算法是 PPO(Proximal Policy Optimization)
传统的 ==人类反馈强化学习RLHF( ==Reinforcement Learning from Human Feedback)5需要大量人工标注偏好数据,成本高昂。为了降低成本,研究者提出了 AI 反馈强化学习RLAIF(Reinforcement Learning from AI Feedback)7,用强大的 AI 模型(如 GPT-4)来替代人类标注员。RLAIF 的工作流程是:用 SFT 模型生成多个候选回答,用强大的 AI 模型对回答进行评分和排序,用 AI 的评分训练奖励模型,用奖励模型进行强化学习。实验表明,RLAIF 的效果接近甚至超过 RLHF,同时成本大幅降低11。