目录
备注:没有特别说明就在atguigu执行下面命令
一、模拟数据说明及前期准备
1.模拟数据说明:数据仓库上线时间假定为2022-06-08,为了符合真实的业务情况,所以要保证模拟数据包括2022-06-04、2022-06-05、2022-06-06、2022-06-07的历史数据(历史数据不含日志数据只有业务数据)和2022-06-08的全量数据(因为是从这天开始的所以要将这天的日志数据和业务数据都上传到HDFS),所以整个模拟数据包括2022-06-04、2022-06-05、2022-06-06、2022-06-07、2022-06-08的业务数据和2022-06-08的日志数据,且在HDFS上/origin_data/gmall/db路径下的所有增量表和全量表记录的2022-06-04、2022-06-05、2022-06-06、2022-06-07、2022-06-08的业务数据且都归为2022-06-08这一天的数据。
2.启动HDFS服务,删除以前采集项目时的遗留数据(在hadoop102执行下面命令)
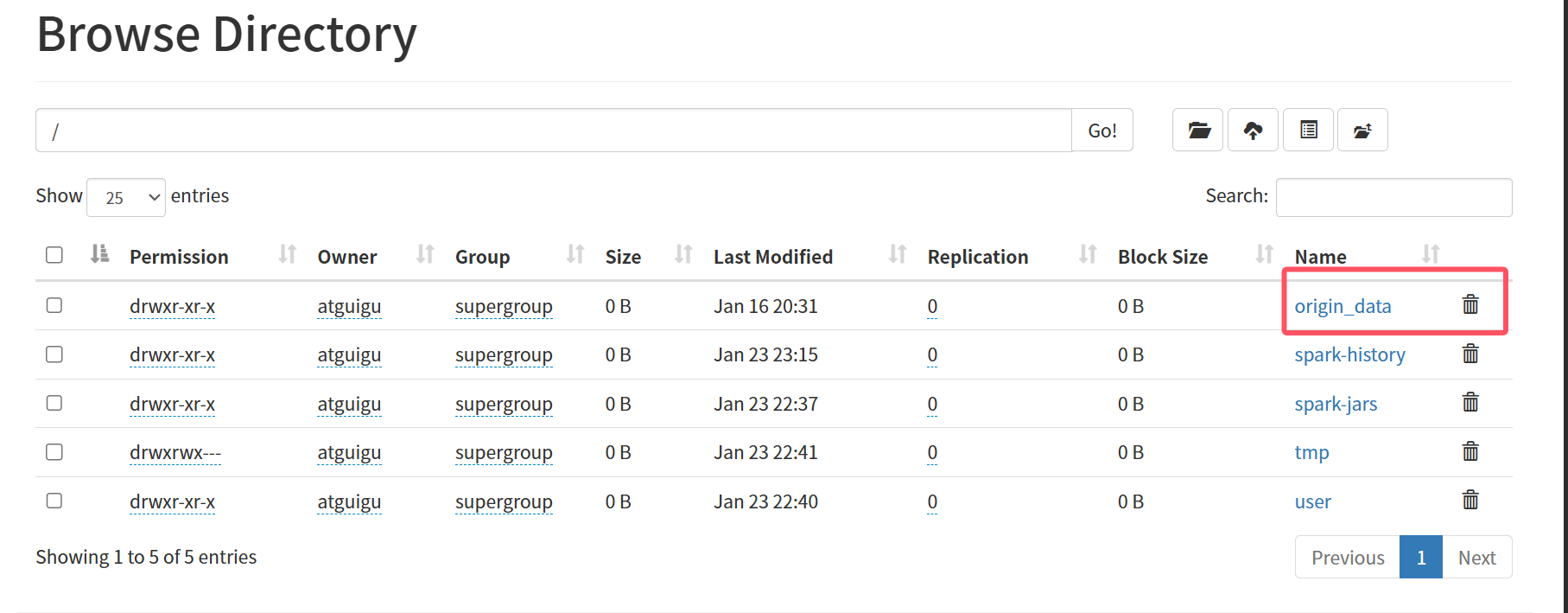
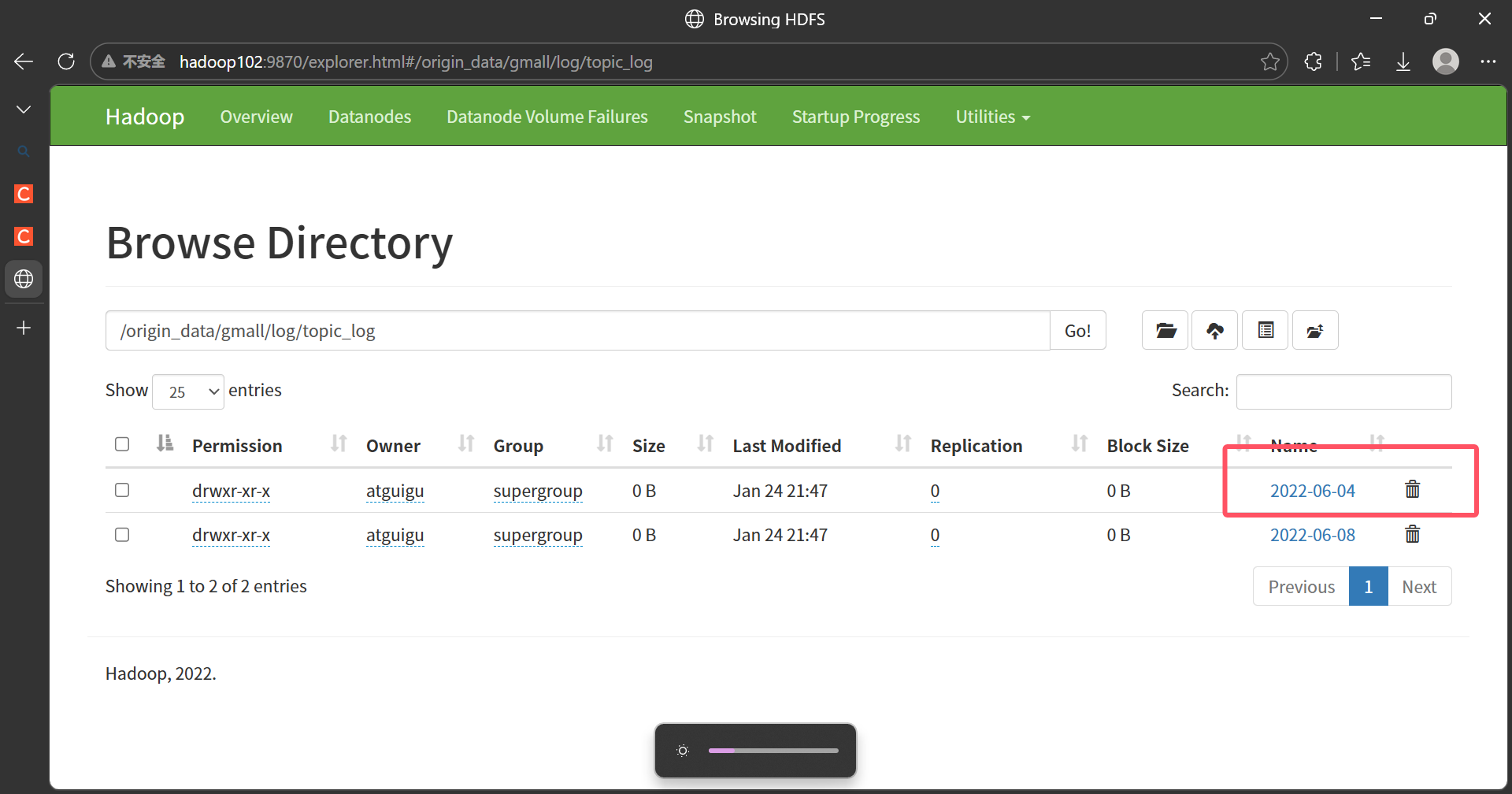
hdp.sh start访问http://hadoop102:9870,删除下图框选的文件origin_data
3.启动采集项目服务,并关闭Maxwell服务,因为我们后面要生成的模拟数据要先将全量数据同步到HDFS(就是HDFS以full结尾的表------全量表),然后再开启Maxwell就行首日增量全量同步(就是HDFS以inc结尾的表------增量表),先关闭Maxwell避免全是增量表没有全量表了。(在hadoop102执行下面命令)
cluster.sh start
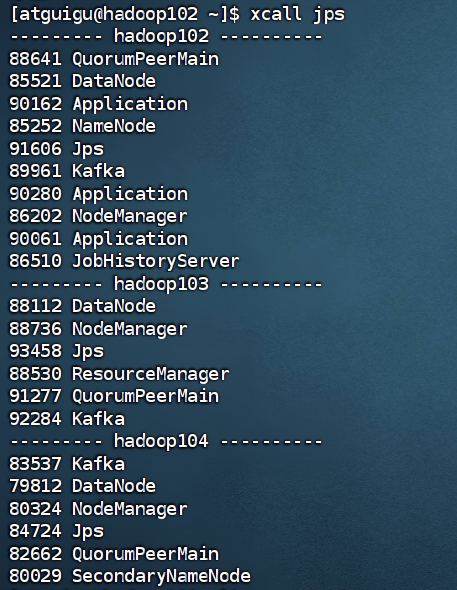
mxw.sh stop服务启动后保证只有下面的进程
二、生成模拟数据
1.更改后续需要修改文件的权限(在hadoop102执行下面命令)
su root
chmod 777 application.yml
su - atguigu2.修改hadoop102节点的/opt/module/applog/application.yml文件(在hadoop102执行下面命令)
cd /opt/module/applog
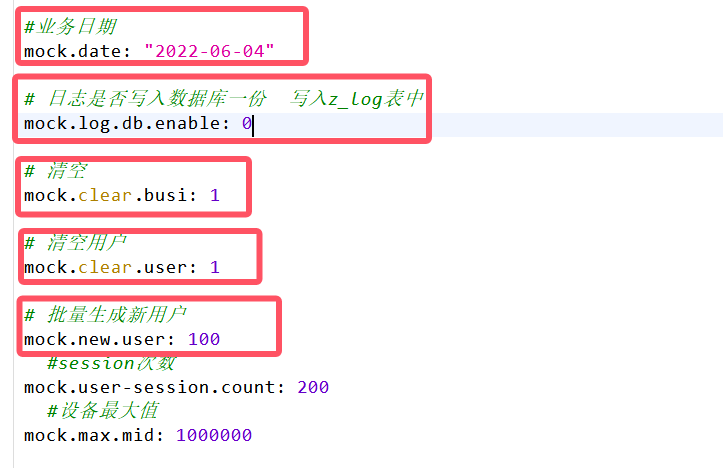
vim application.yml将5个参数修改为图中的值
生成2022-06-04的数据,输入下面命令(在hadoop102执行下面命令)
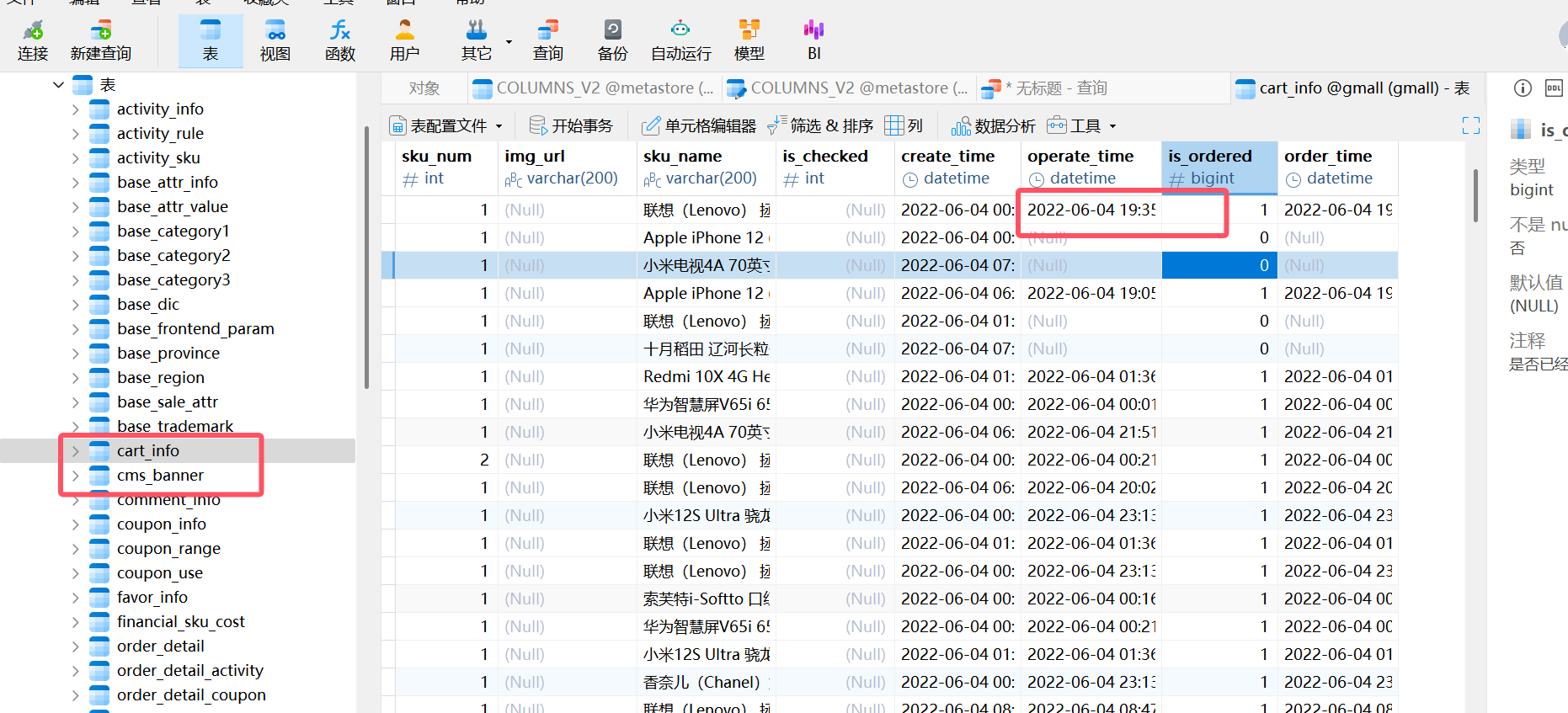
lg.sh去navicat查看是否正确生成了对应日期的数据
去HDFS看是否有对应日期的日志数据(后面会删,下面哪个8号的不用管)
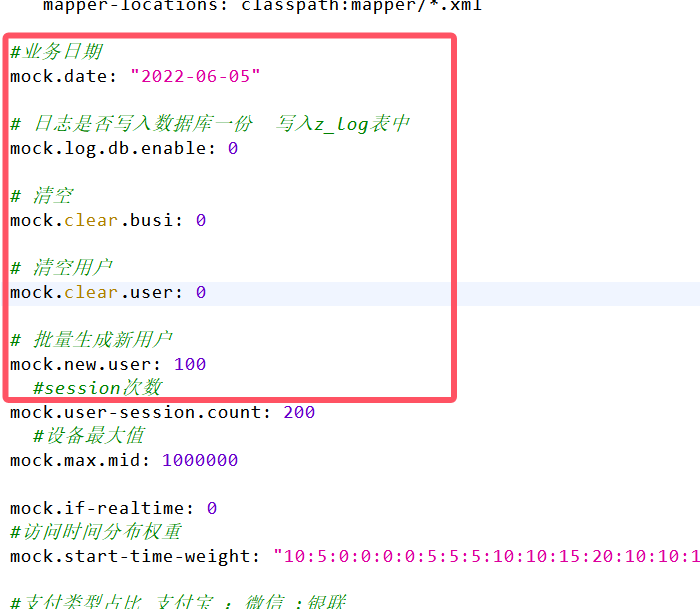
同理修改配置生成5号的数据(在hadoop102执行下面命令)
cd /opt/module/applog
vim application.yml参数如图
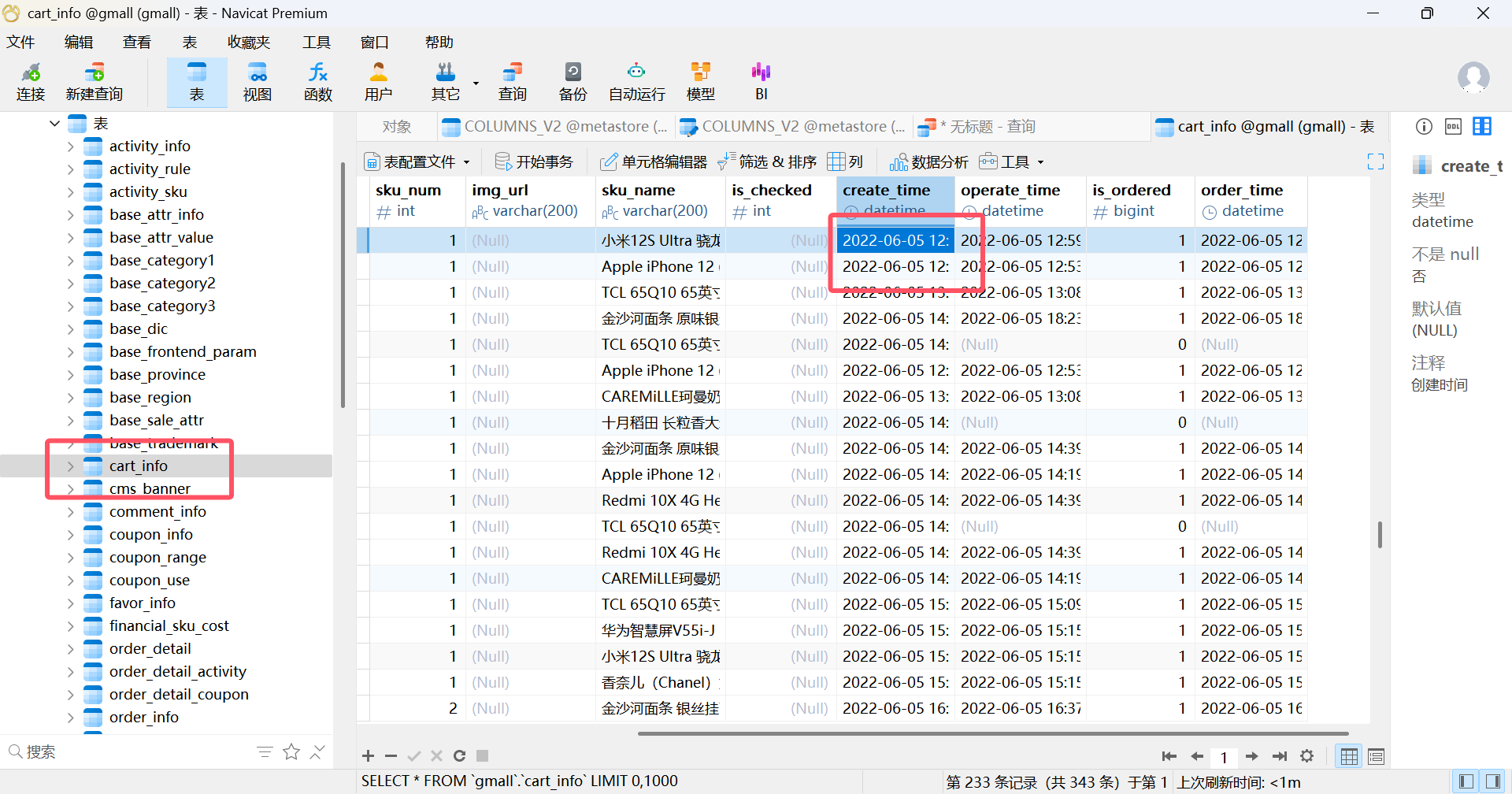
生成5号数据(在hadoop102执行下面命令)
lg.sh去navicat查看,往下滑就找到5号的数据。
同理生成6、7号数据(在hadoop102执行下面命令)
cd /opt/module/applog
vim application.yml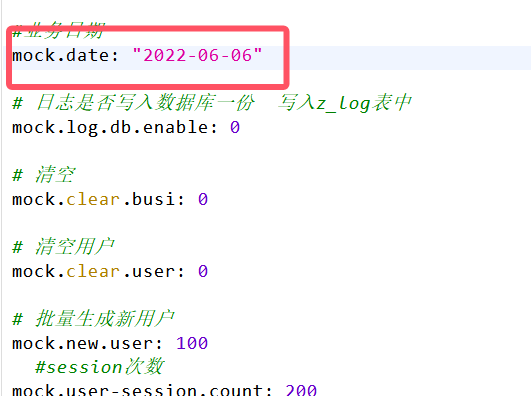
生成6号数据(在hadoop102执行下面命令)
lg.sh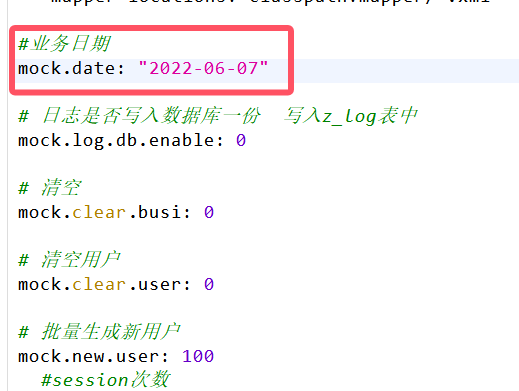
生成7号数据(在hadoop102执行下面命令)
lg.sh!!!生成数据完成后还是要去navicat和HDFS查看数据是否成功生成
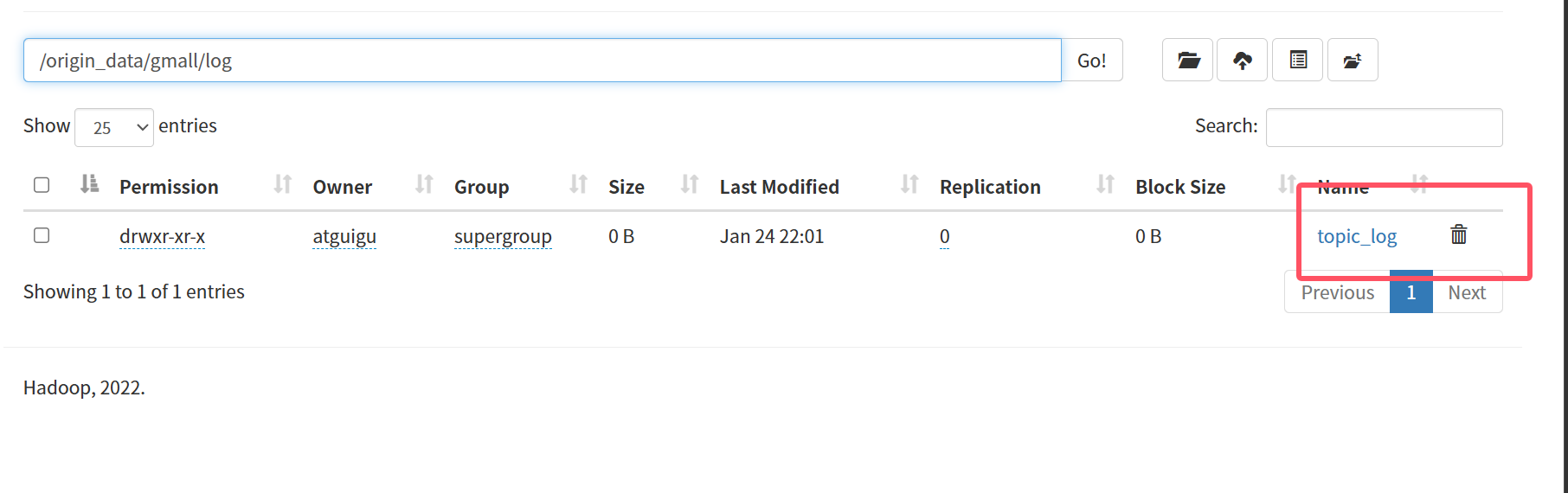
因为lg.sh脚本生成数据默认会生成日志数据,所以生成数据完成后就需要将4、5、6、7号的日志数据删除,前面说了它们不需要日志数据,找到如图的路径删除topic_log
同理生成数仓搭建开始日期的数据(在hadoop102执行下面命令)
cd /opt/module/applog
vim application.yml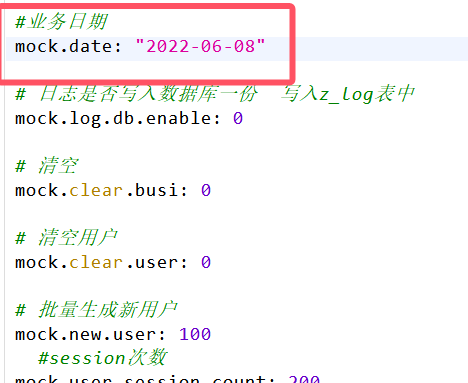
生成8号数据(在hadoop102执行下面命令)
lg.sh去HDFS查看保证只有8号的日志数据
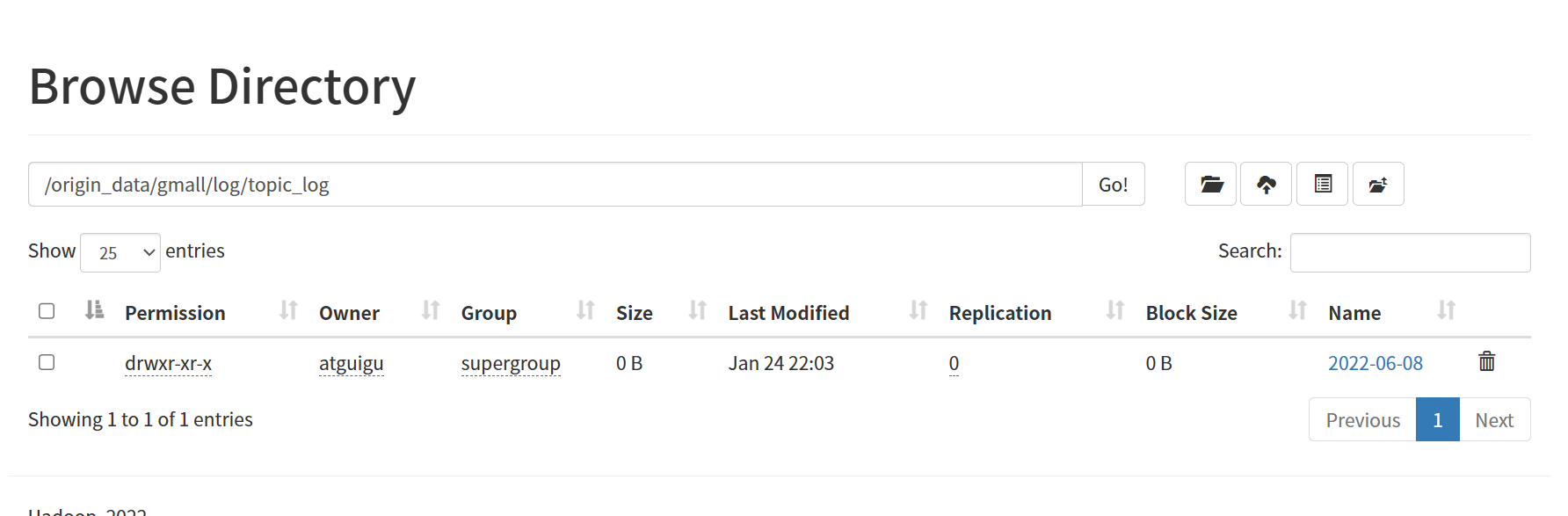
三、数据同步到HDFS
1.执行全量表同步脚本(在hadoop102执行下面命令)
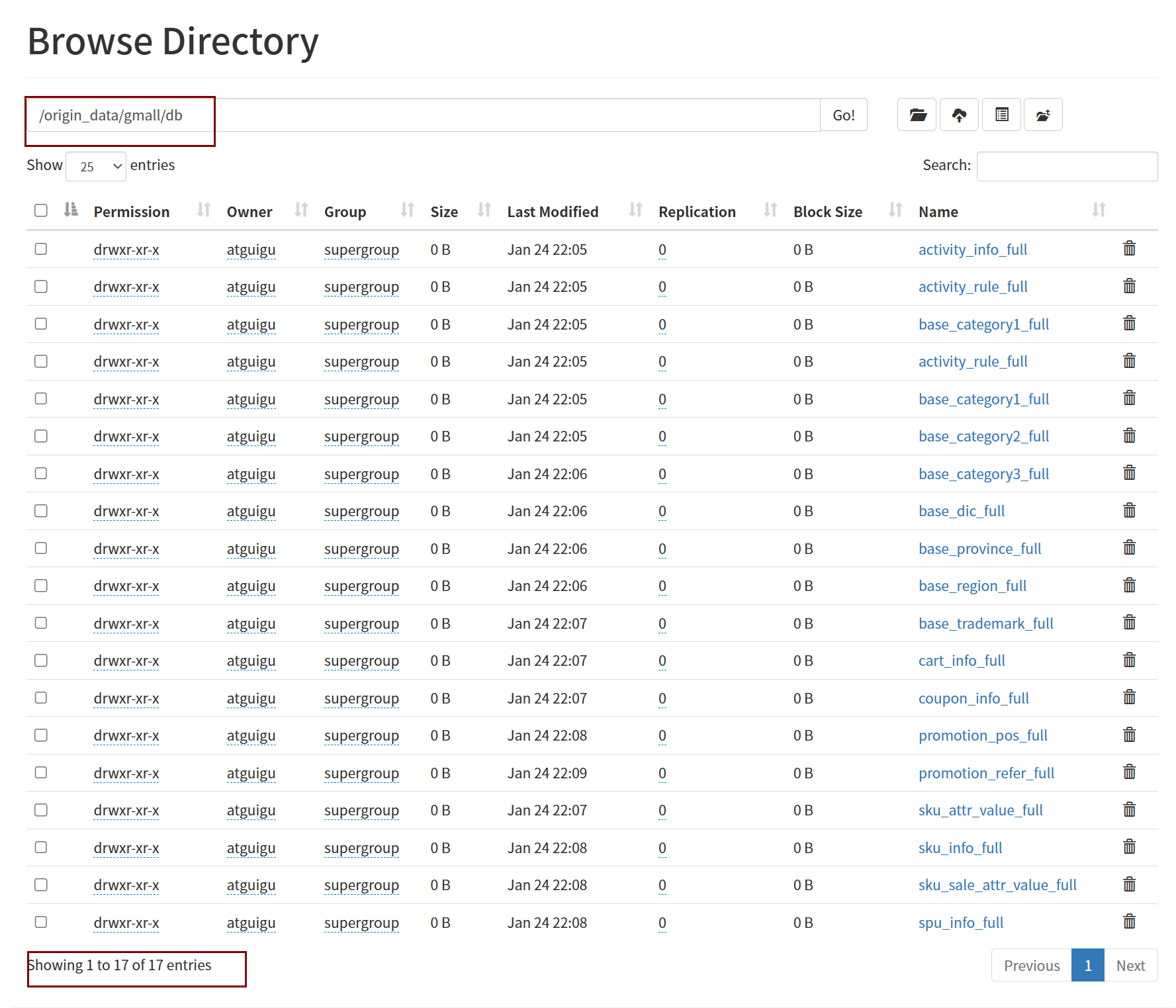
mysql_to_hdfs_full.sh all 2022-06-08同步完成查看可以发现有17张full结尾的表
2.清除Maxwell断点记录
由于Maxwell支持断点续传,而上述重新生成业务数据的过程,会产生大量的binlog操作日志,这些日志我们并不需要。故此处需清除Maxwell的断点记录,令其从binlog最新的位置开始采集。
在navicat执行下面的查询语句,注意数据库是maxwell
sql
drop table maxwell.bootstrap;
drop table maxwell.columns;
drop table maxwell.databases;
drop table maxwell.heartbeats;
drop table maxwell.positions;
drop table maxwell.schemas;
drop table maxwell.tables;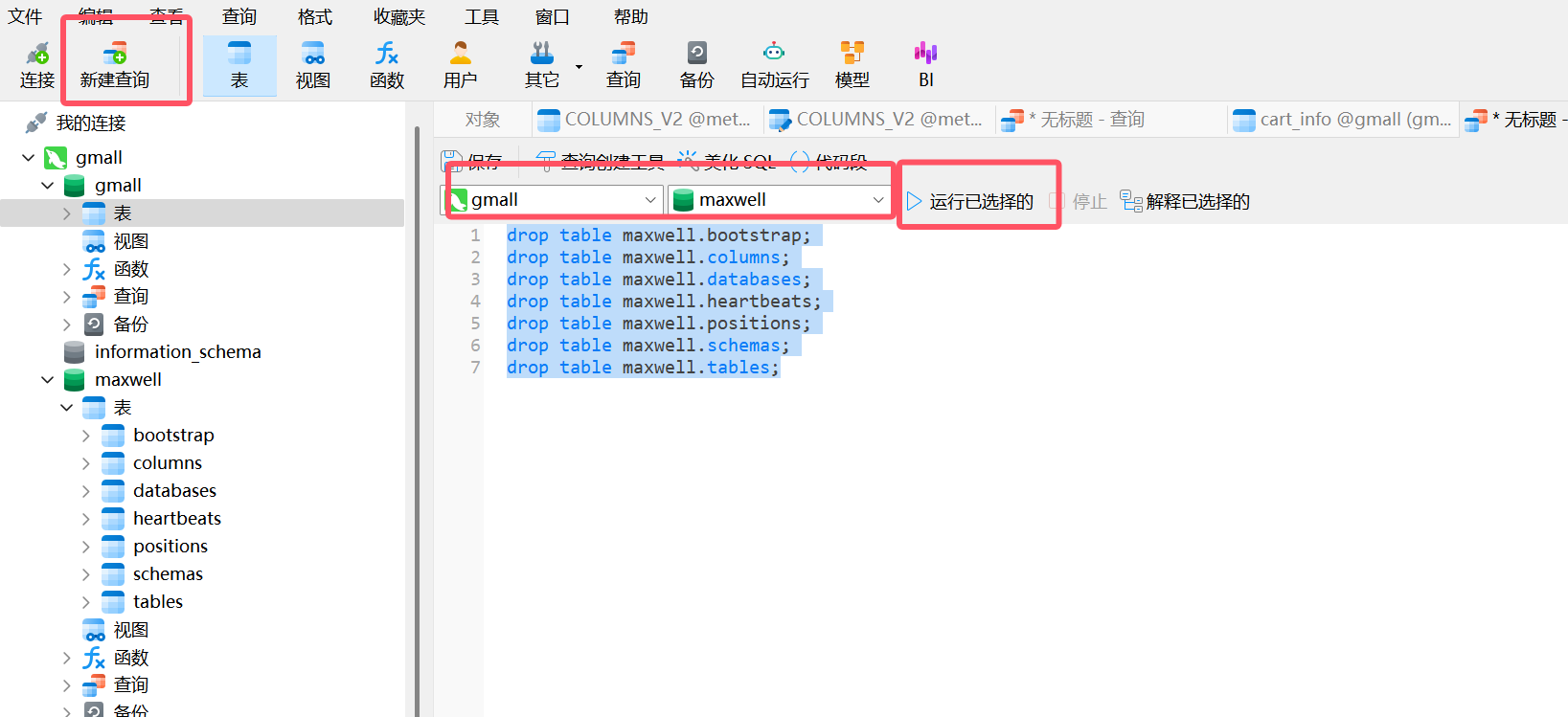
3.启动Maxwell服务(在hadoop102执行下面命令)
sql
mxw.sh start4.执行增量表首日全量同步脚本(在hadoop102执行下面命令)
sql
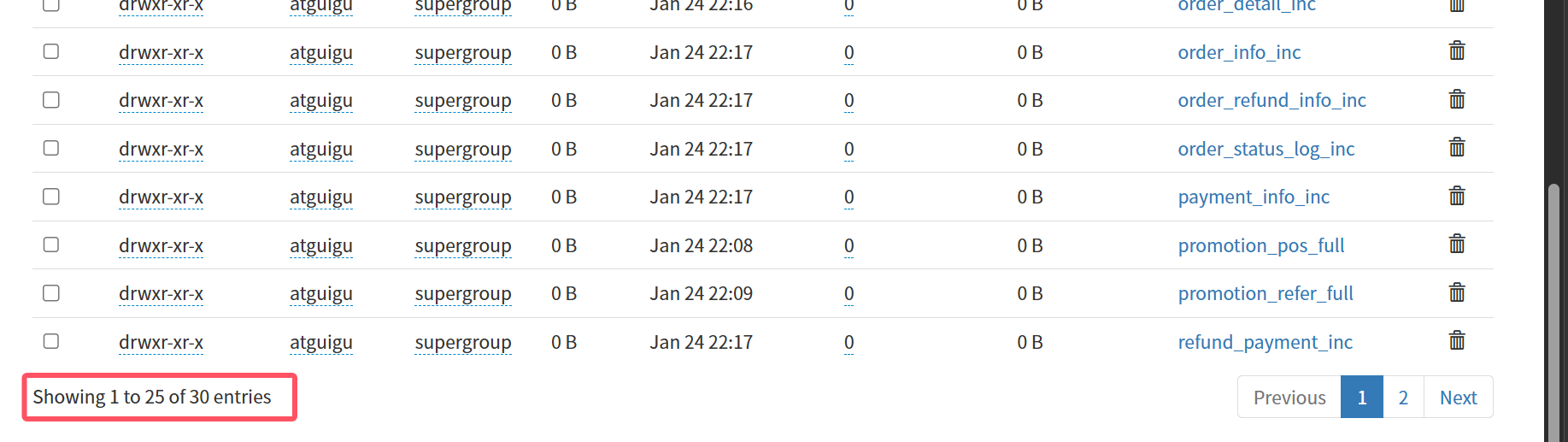
mysql_to_kafka_inc_init.sh all同步完成查看可以发现有17张full结尾的全量表,13张inc结尾的增量表,一共30张

四、查看表数据
1.查看全量表数据(随便选一个查看)(在hadoop102执行下面命令)
sql
hadoop fs -cat /origin_data/gmall/db/cart_info_full/2022-06-08/* | zcat
2.查看增量表数据(随便选一个查看)(在hadoop102执行下面命令)
sql
hadoop fs -cat /origin_data/gmall/db/cart_info_inc/2022-06-08/* | zcat