本文档为完全分布式大数据环境(3台虚拟机:hadoop01~hadoop03)中Hive(on Spark)组件的独立测试教程,基于视频操作流程,结合完全分布式测试文档的规范要求,详细说明从环境准备、远程连接到服务启停、核心功能验证(服务状态检查、客户端连接、SQL功能)的全流程,适用于验证Hive集群的独立可用性。
一、前期准备:环境基础信息与测试前提
测试前需确认环境配置及依赖组件状态符合要求,避免因环境问题导致测试失败:
1.1 基础环境信息
- 虚拟机配置:3台虚拟机(命名为hadoop01、hadoop02、hadoop03),硬盘总配置100GB~200GB,已完成基础环境部署
- 系统账号:优先使用hertz账号(密码:hertz);特殊操作需使用root账号(密码:1)
- 工具准备:Mobaxterm远程连接工具(已安装并可正常使用)
1.2 测试前提
- 3台虚拟机(hadoop01~hadoop03)均正常启动,已到达登录页面
- 以hertz账号登录hadoop01节点(分布式脚本统一在hadoop01执行)
- 依赖组件已正常启动:Hadoop(HDFS+YARN)服务(执行命令:start-all.sh)、ZooKeeper服务(执行命令:zk start,状态为1台Leader、2台Follower)、Spark集群服务(执行命令:start-spark.sh)
- MySQL服务正常运行,确保Hive元数据存储正常(可通过命令:systemctl status mysqld 验证)
二、Hive测试详细步骤
步骤1:确认虚拟机启动状态
操作说明:分别检查3台虚拟机(hadoop01、hadoop02、hadoop03)的启动状态,确保每台虚拟机系统加载完成,均已到达登录页面。
预期结果:3台虚拟机均正常启动,无启动报错,各自显示系统登录界面。
步骤2:使用Mobaxterm连接虚拟机
操作说明:打开本地Mobaxterm工具,分别建立与3台虚拟机(hadoop01、hadoop02、hadoop03)的SSH远程连接。
核心操作要点:
- 新建远程连接,选择SSH连接类型
- 分别输入3台虚拟机对应的正确IP地址
- 默认选择普通用户登录类型,无需额外修改
预期结果:3台虚拟机的Mobaxterm连接均成功建立,各自进入等待登录状态。
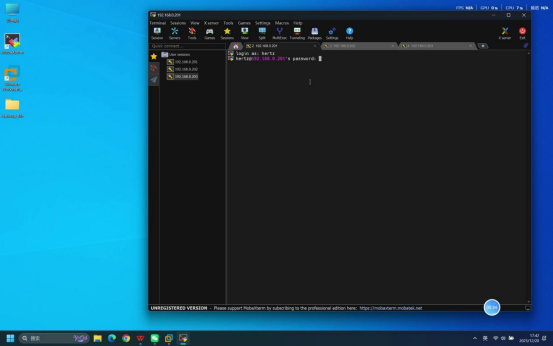
步骤3:输入账号密码完成登录
操作说明:在3台虚拟机对应的Mobaxterm连接终端中,依次完成账号和密码的输入操作。
具体操作:
- 终端提示输入账号时,输入:hertz
- 回车后,终端提示输入密码,输入:hertz(密码输入时无明文显示,直接输入后回车即可)
预期结果:3台虚拟机均登录成功,终端界面分别显示当前登录用户及主机标识,如hertz@hadoop01 \~、\[hertz@hadoop02 \~\]、hertz@hadoop03 \~$。
步骤4:启动Hive相关服务
操作说明:在登录成功的hadoop01节点终端中,先确认依赖的Hadoop、ZooKeeper、Spark服务已正常运行,再执行Hive集群启动命令。
具体操作:
- 确认依赖服务状态(可选):通过jps命令验证Hadoop、ZooKeeper、Spark进程正常;ZooKeeper状态可执行zkServer.sh status验证
- 启动Hive服务:执行命令:hive-all.sh start
说明:hive-all.sh为封装的集群脚本,执行后可一键启动Hive元数据服务(metastore)和HiveServer2服务,两者均启动后Hive才能正常使用。
预期结果:终端逐步输出Hive服务的启动日志,无报错提示。
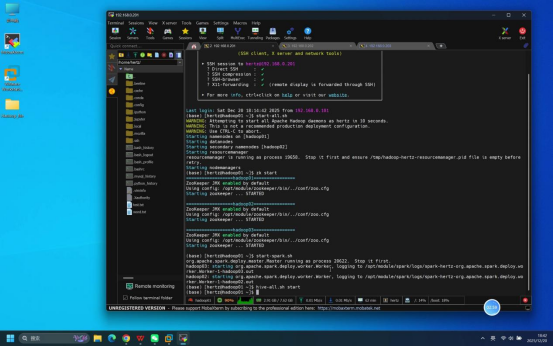
步骤5:执行hive-all.sh status检查服务状态
操作说明:在hadoop01节点终端中,分两次执行Hive服务状态查询命令,观察服务启动过程中的状态变化。
具体操作:
- 第一次执行命令:hive-all.sh status
- 等待片刻(约30秒~1分钟,给服务启动缓冲时间),第二次执行命令:hive-all.sh status
预期结果:
- 第一次执行后,终端显示metastore、hiveserver2服务状态异常(如"not running")
- 第二次执行后,终端显示metastore、hiveserver2服务状态均为正常(如"running")
说明:若第二次仍异常,可通过命令systemctl status mysqld检查MySQL服务状态,若未启动则执行systemctl start mysqld(输入root密码1)启动MySQL后重新尝试。
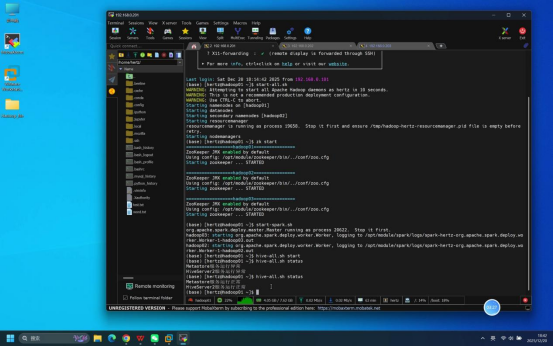
步骤6:Hive客户端模式验证
操作说明:在hadoop01节点终端中,启动Hive客户端,执行数据库列表查询命令后退出。
具体操作:
- 启动Hive客户端:执行命令:hive
- 查询数据库:在客户端交互界面输入命令:show databases;
- 退出客户端:输入命令:exit;
预期结果:
- Hive客户端启动无报错,进入交互界面(显示hive> 提示符)
- show databases;命令执行无报错,可列出默认数据库(如default)
- exit;命令执行后,正常退出客户端,返回终端命令行界面。
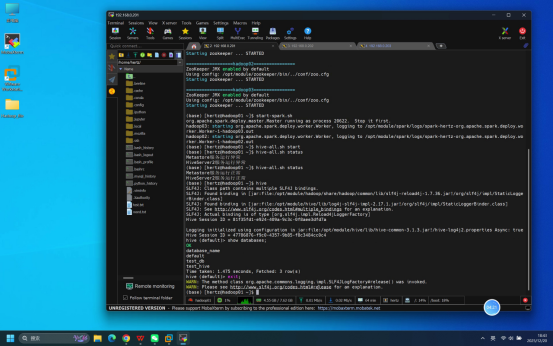
步骤7:Beeline远程连接Hive验证
操作说明:在hadoop01节点终端中,启动Beeline工具并远程连接HiveServer2服务。
具体操作:
- 启动Beeline:执行命令:beeline
- 连接Hive:在Beeline交互界面输入命令:!connect jdbc:hive2://hadoop01:10000(注:"hadoop"需替换为hadoop01节点的IP或主机名,确保可正常解析)
- 输入登录账号:hertz,输入密码:hertz(均为hertz),按回车确认登录
预期结果:连接成功,无"Connection refused"错误,进入Beeline交互界面(显示0: jdbc:hive2://hadoop01:10000> 提示符)。
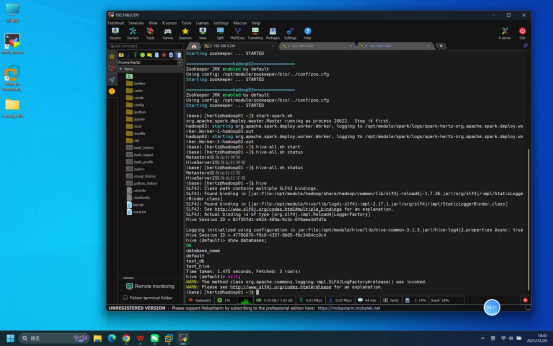
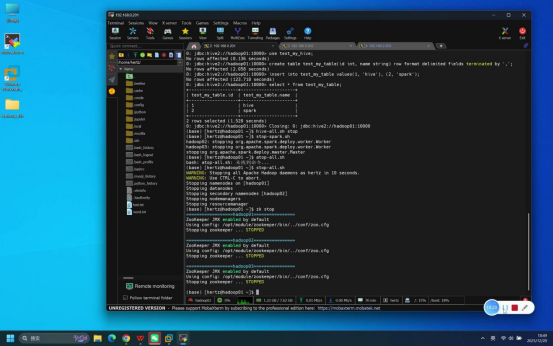
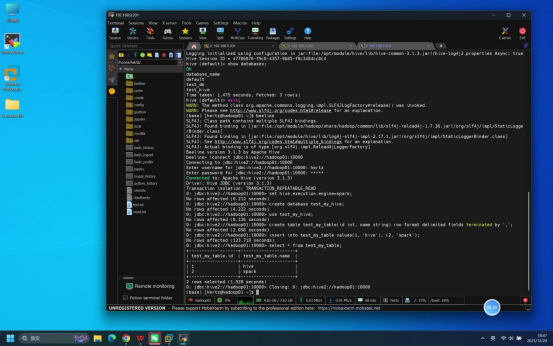
步骤8:SQL功能验证(Spark引擎)
操作说明:在Beeline连接成功后的交互界面中,执行与完全分布式测试文档一致的SQL命令,验证Hive(on Spark)的核心数据操作功能。
具体操作(依次执行以下SQL命令):
- 设置Spark为执行引擎:set hive.execution.engine=spark;
- 创建测试数据库:create database test_my_hive;
- 使用测试数据库:use test_my_hive;
- 创建测试表:create table test_my_table(id int, name string) row format delimited fields terminated by ',';
- 插入测试数据:insert into test_my_table values(1, 'hive'), (2, 'spark');
- 查询测试数据:select * from test_my_table;
预期结果:所有SQL命令执行无报错,查询结果显示两行数据:1 hive、2 spark,与插入的测试数据一致。
步骤9:关闭Hive相关服务
操作说明:功能验证完成后,先退出Beeline交互界面,再在hadoop01节点执行Hive服务停止命令,最后根据需求停止依赖服务。
具体操作:
- 退出Beeline:在Beeline交互界面按Ctrl+C组合键终止进程,返回终端命令行
- 停止Hive服务:执行命令:hive-all.sh stop
- 停止依赖服务(可选):若后续无需使用其他组件,依次执行stop-spark.sh(停止Spark)、stop-all.sh(停止Hadoop)、zk stop(停止ZooKeeper)
预期结果:
- Beeline正常退出,无进程残留
- Hive服务停止命令执行无报错,终端输出metastore、hiveserver2服务停止日志。