https://www.apache.org/dyn/closer.lua/spark/spark-3.4.4/spark-3.4.4-bin-hadoop3.tgz
https://repo.anaconda.com/archive/Anaconda3-2024.10-1-Linux-x86_64.sh
1.安装vmworkstation 15.5
2. 安装linux-centos7
3.配置网络,ip静态化
ip静态化:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
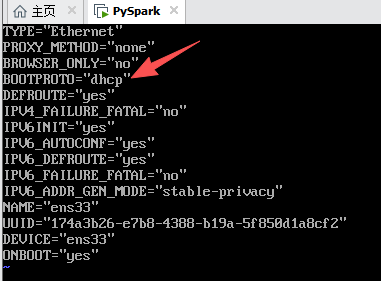
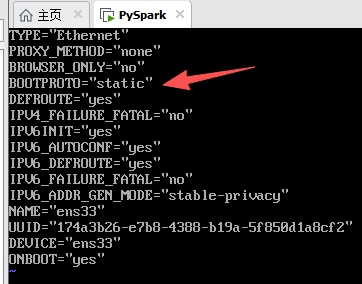
配置网络ip
对本机ip进行修改.
这里一定要改,不然moba连接不上
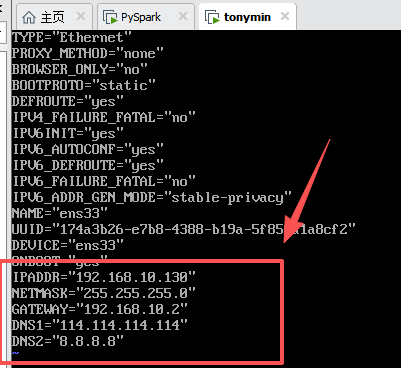
配置开机激活网络
vim /etc/sysconfig/network

重启网络服务即可生效
systemctl restart network service
4.配置主机,修改主机名
更改主机名

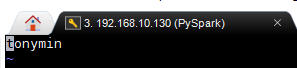
配置主机 ip及名字


5.配置主机与ip映射关系
这里暂时做伪分布式,就不配了
6.关闭虚拟机防火墙
systemctl status firewalld.service
状态已关闭,不必继续关了

7. 安装jdk配置环境变量
export JAVA_HOME=/root/meituan/jdk1.8.0_121
export PATH=JAVA_HOME/bin:PATH
查看环境变量配置
vim /etc/profile
8.配置免秘钥登录
ssh-keygen -t rsa
把当前密钥追加到
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
设置权限
chmod 600 ~/.ssh/authorized_keys
600 6=4+2 自己可读可写,不可执行
此时重启一下电脑
9.上传hadoop3.1.3
tar -zxvf hadoop-3.1.3.tar.gz
mv hadoop-3.1.3 hadoop
10. 配置Hadoop环境变量
- 配置环境变量
vi /etc/profile
export HADOOP_HOME=/root/soft/hadoop
export PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置完,刷新一下
source /etc/profile
检查一下环境变量是否配置成功
hadoop version
11.需要修改 Hadoop 的核心配置文件 包括: 共7个
配置文件所在位置/root/soft/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/root/meituan/jdk1.8.0_121
export JAVA_HOME=/root/meituan/jdk1.8.0_121
3.core-site.xml、
添加内容如下:
<configuration>
<!-- 设置namenode内部通信端口 hdfs://主机名:端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://tonymin:9820</value>
</property>
<!-- 设置hadoop数据存储的临时文件夹 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/soft/hadoop/tmp</value>
</property>
</configuration>
4.hdfs-site.xml、
<configuration>
<!--设置hdfs的副本数-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置namenode文件存储路径-->
<property>
<name>dfs.name.dir</name>
<value>/root/soft/hadoop/tmp/hdfs/name</value>
</property>
<!--设置datanode文件存储路径-->
<property>
<name>dfs.data.dir</name>
<value>/root/soft/hadoop/tmp/hdfs/data</value>
</property>
<!-- namenode的web端访问地址:主机名:端⼝号 -->
<property>
<name>dfs.namenode.http-address</name>
<value>tonymin:9870</value>
</property>
<!-- secondarynamenode的web端访问地址:主机名:端⼝号-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>tonymin:9868</value>
</property>
</configuration>