一、模型结构
以deepseek举例:
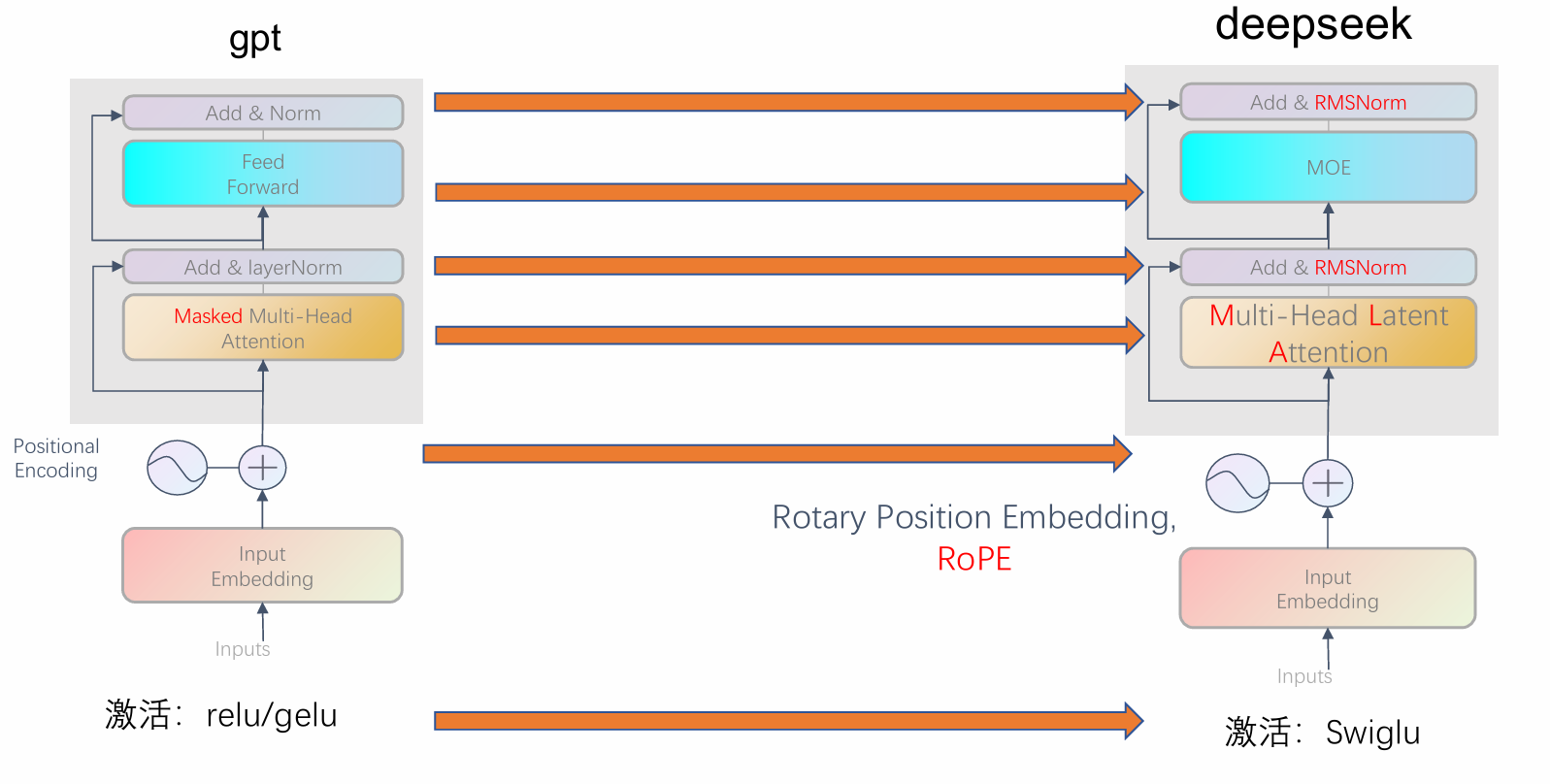
通过类比,学习LLM改进于Transformer的一些方法
二、大模型的训练步骤
1.预训练
2.有监督微调(Supervised Fine-Tuning, SFT)
3.基于人类反馈的强化学习(RLHF)
三、创新型的模型架构
1.混合专家模型(Mixture of Experts,MoE)
①什么是 MoE,为什么需要MoE?
MoE 是一种稀疏激活的神经网络架构设计。在现代大语言模型(LLM)中,MoE 被用于在不显著增加计算成本的前提下大幅提升模型容量。
这里和之前用的Feed Forward Net(FFN)对比一下:
在 Transformer 中,每个 FFN 层通常由两个线性变换 + 激活函数组成,
这两个全连接的参数量在大模型下太大了
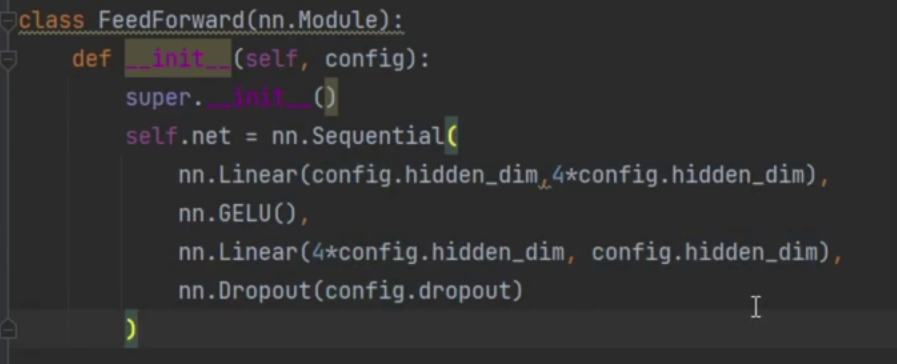
假如有2048的参数量,几乎有20482048 2的参数量(忽略b),忒多了
所有 token 都要完整走一遍这个 FFN,100% 参数被激活。
而MoE 层用 多个专家(Experts) + 门控(Gating) 替代单个 FFN。
②三类MoE架构
- 全加型MoE
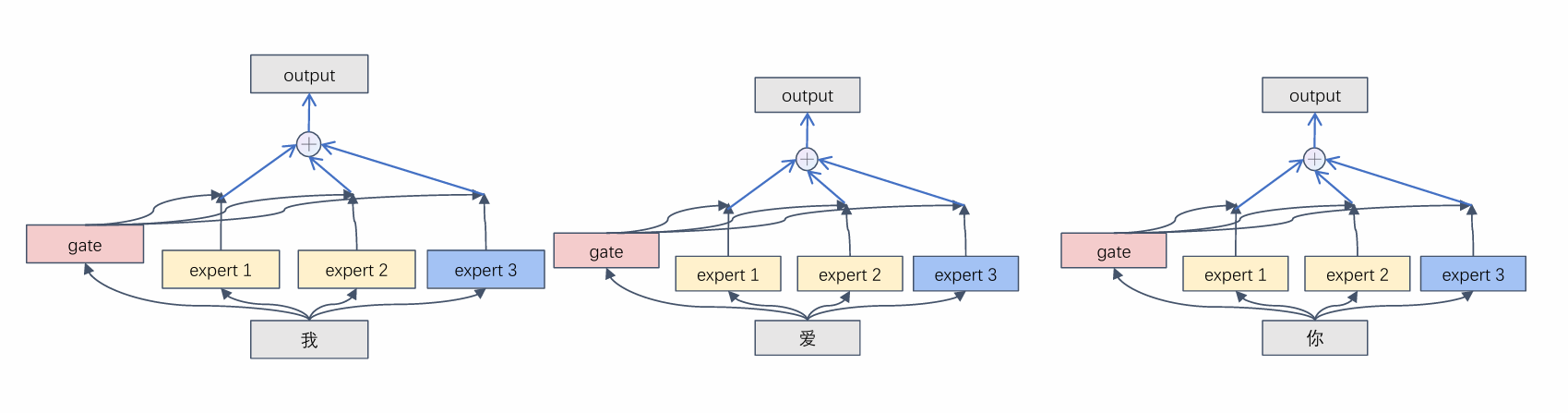
所有专家都参与计算,每个专家对最终输出都有贡献。
门控网络为每个专家分配一个连续权重(如 softmax 概率),输出是所有专家输出的加权和。
依然需要大量计算,违背初衷。 - 挑选型MoE(Sparse MoE)
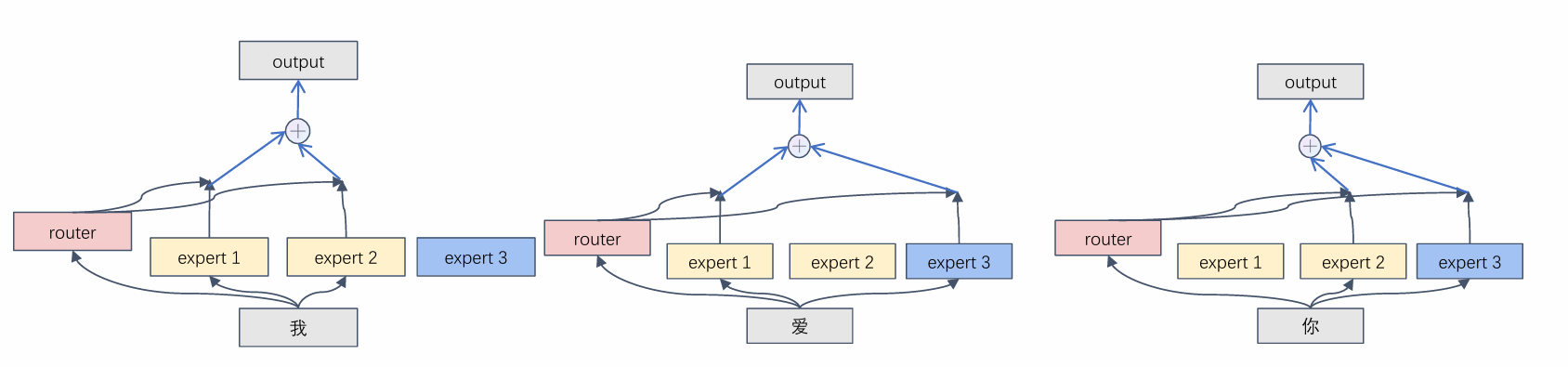
只激活 top-k 个专家(通常 k=1 或 2),其余专家完全不参与计算。
输出是被选中专家的加权和
但是:如果router根据token生成一个打分表,即每个专家得分,选择最高的top_k个,然后让这个token经过这几个专家,得到向量,再加起来,难道要循环token数量的次数?
做法:反过来,让专家选择token,让专家看看哪些token选了我
一次性处理整个 batch + sequence 的所有 token,将它们"分发"给对应的专家,每个专家一次性处理属于它的所有 token。
批量计算所有 token 的专家得分->对每个 token 选 top-k 专家->
构建 token到专家 的分配映射->按专家分组 token,形成大 batch 输入->
每个专家一次性处理其所有 token->将输出按原 token 位置加权合并
-
共享型MoE(Shared MoE)
在部分参数共享的基础上引入专家机制,平衡表达能力与效率。
常见形式:一个共享的"骨干"FFN + 多个轻量级专家
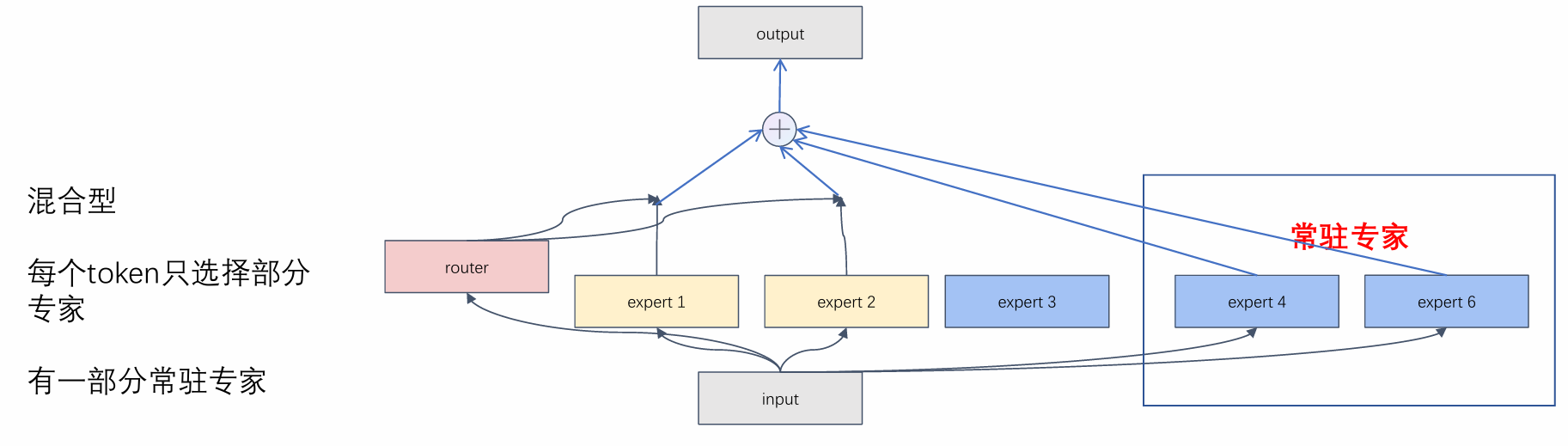
-
负载均衡
目的:确保每个专家被分配到大致相同数量的 token,让每个专家都得到充分利用,避免router"偷懒",某些专家"过劳"而其他专家"闲置"的现象。
做法:主流是在损失函数中加入辅助损失(Auxiliary Loss),显式鼓励 router 均匀分配 token。

-
moe并不能减少参数量(还增加), 只是减少了激活的单元,减少计算量
1.为什么增加了参数量?
所有专家的权重都必须完整保存在内存/显存中。
即使某个专家当前没被激活,它的参数依然存在,占用存储空间。
训练时,虽然只更新被激活专家的梯度,但所有参数都要加载到 GPU 内存
2.为什么减少计算的参数量?
计算发生在"激活的路径"上。
在 MoE 层中,只有被选中的 top-k 专家执行矩阵乘法等运算。
3.传统FFN: 100B参数
MoE: 总参数236B,但每个token只激活21B参数
传统FFN: 每个token计算量: 100B FLOPs
MoE: 每个token计算量: 21B FLOPs (减少79%!)
2.旋转位置编码(Rotary Position Embedding,RoPE)
之前在bert,及原始transformer中中,位置信息与词嵌入直接相加,泛化能力差
核心思想:
将位置信息编码为"旋转变换",通过旋转 query 和 key 向量来隐式注入位置信息。
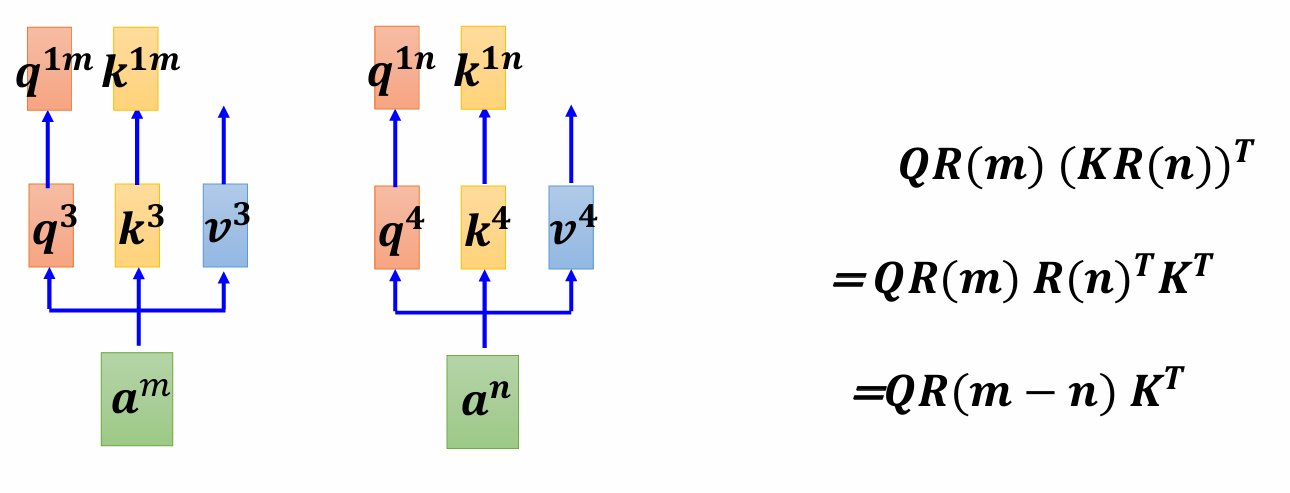
旋转矩阵是一个正交矩阵
3.多头潜在注意力(Multi-head Latent Attention,MLA)
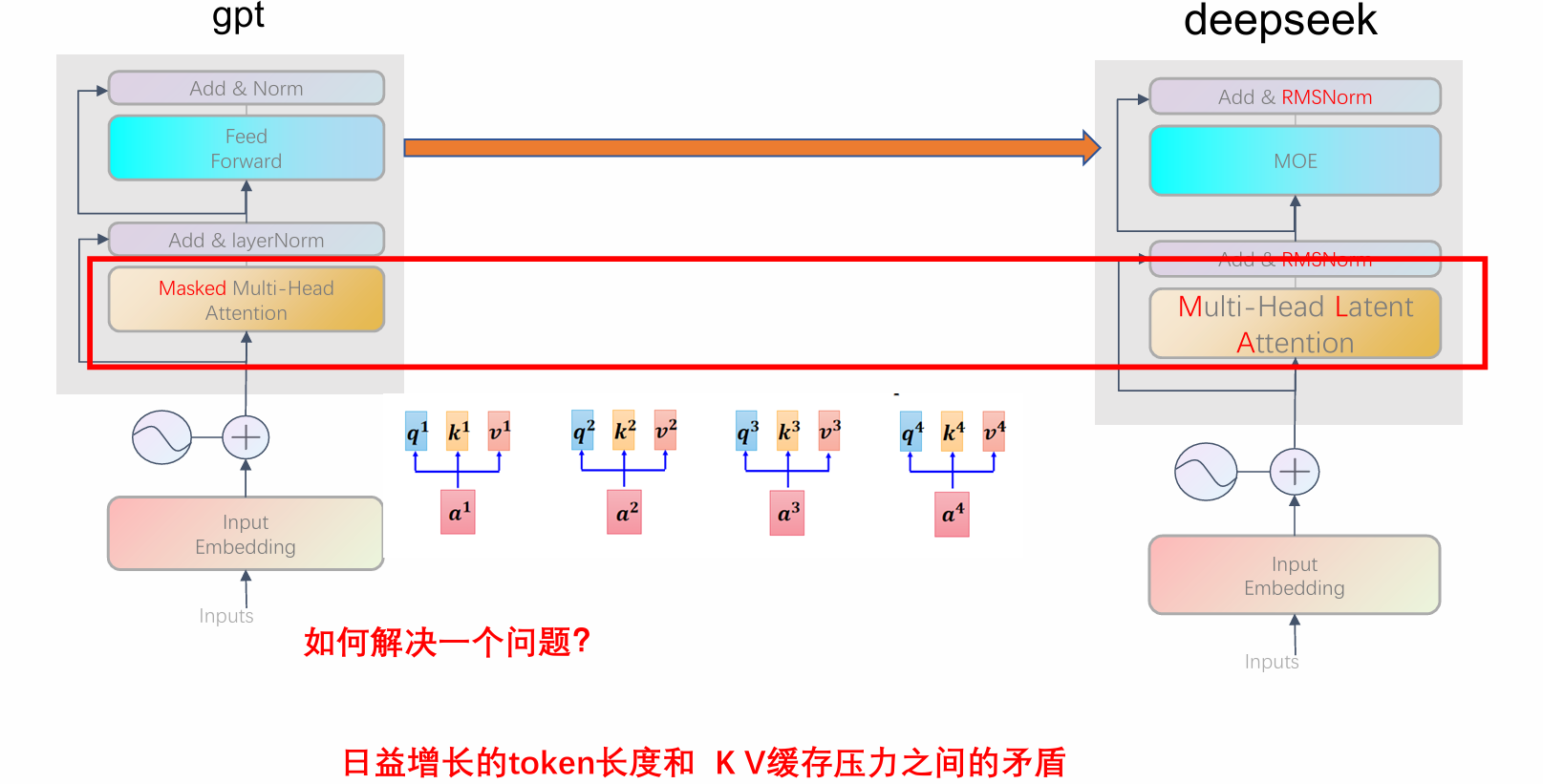
K,V被重复计算了
可以使用KVcache把他们存起来,但是最后KVcache也会很大!!
加显卡并不行。 因为卡内通信带宽> 卡间通信带宽> 机间通信带宽
过多的机器和显卡会导致通信消耗太高
于是引入MLA
LORA(Low Rank Adaptation,低秩适配器)
一种高效微调大语言模型(LLM)的技术,不直接更新原始大模型的全部参数,而是通过引入少量可训练的低秩矩阵来"近似"权重更新,从而大幅减少训练所需的显存、计算量和存储成本。
向前传播公式中:
W𝟏=𝑾𝟎 +△W(△W:权重更新)
权重更新(ΔW)在微调过程中具有低秩特性,即可以用两个小矩阵的乘积近似:
比如,一个1000010000的矩阵,ΔW可表示为
(10000, 10000) = (10000, x) @ (x, 10000)x是很小的数
h=Wx+ΔWx=Wx+B(Ax),训练时只更新 A 和 B;推理时可将 W+BA 合并为一个矩阵,无额外计算开销。
以前更新矩阵需要:10000 10000+10000的参数
假设x=1,现在只需要:10000*1+10000的参数
MLA
核心思想:不直接缓存原始的 K 和 V,而是学习一组低维"潜在表示"(Latent Tokens),用它们来重建近似的 K/V
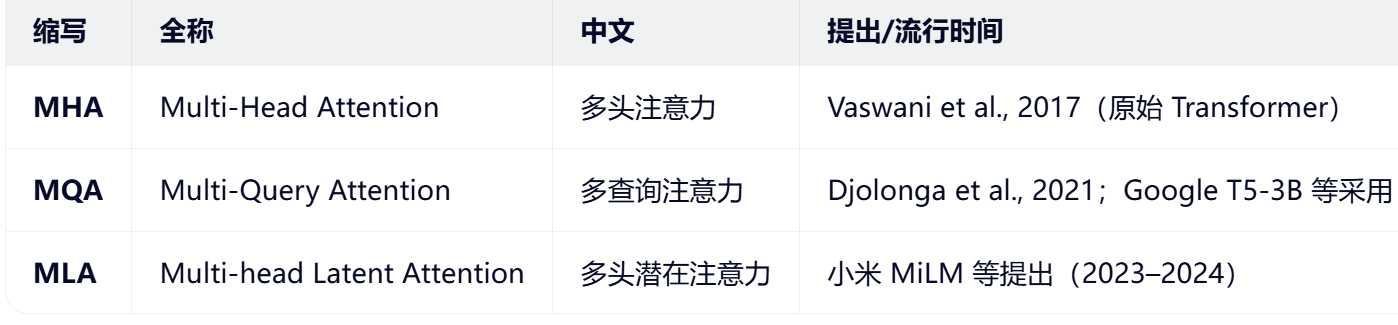

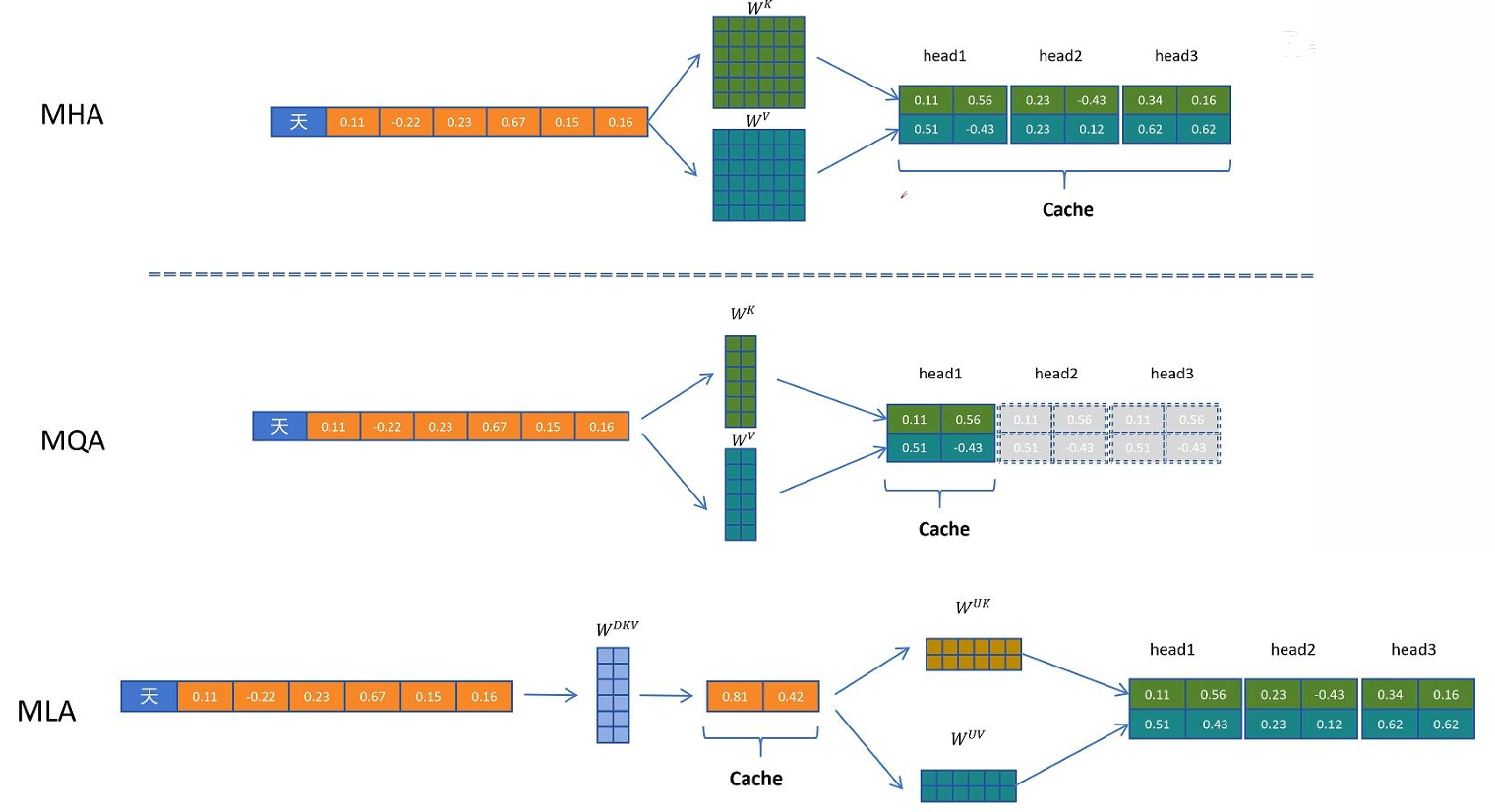
具体:
引入一个小型可学习的 潜在记忆池(Latent Memory Bank),包含 L 个 latent tokens(如L=256 )所有历史 K/V 信息被压缩编码到这 L 个 latent 向量中,推理时,只缓存这 L 个 latent 向量(而非全部历史 K/V)
计算当前 query 的注意力时,从 latent memory 中动态重建 K/V

对于MLA:W_dkv是一个低秩矩阵,只需要存C_kv,需要求K,V的时候就拿C_kv做计算得到K,V
由此,减少计算量:
①维度低,计算更少
②回到公式,其实不用算K了,直接X @ W_q @ W_uk转置 @ C_kv转置,矩阵吸收
4.Swiglu
一种高性能前馈网络(FFN)激活函数 结构
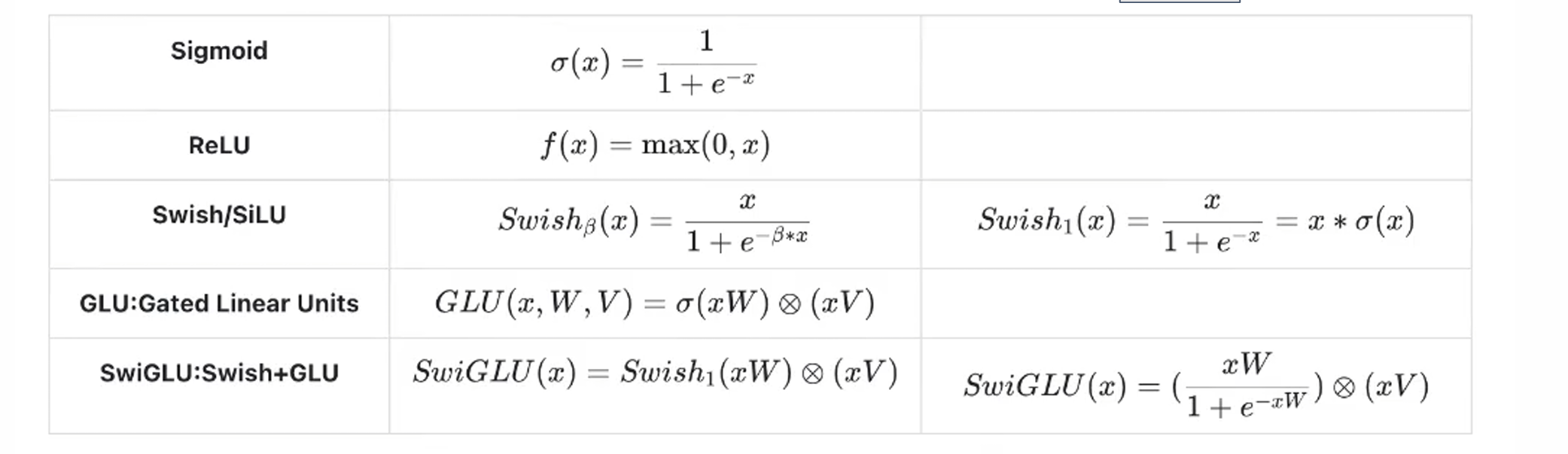
x:输入向量; W: 主线性变换的权重 ;V: 门控线性变换的权重
5.RMSNorm
RMSNorm是一种对标准 LayerNorm 的简化与改进
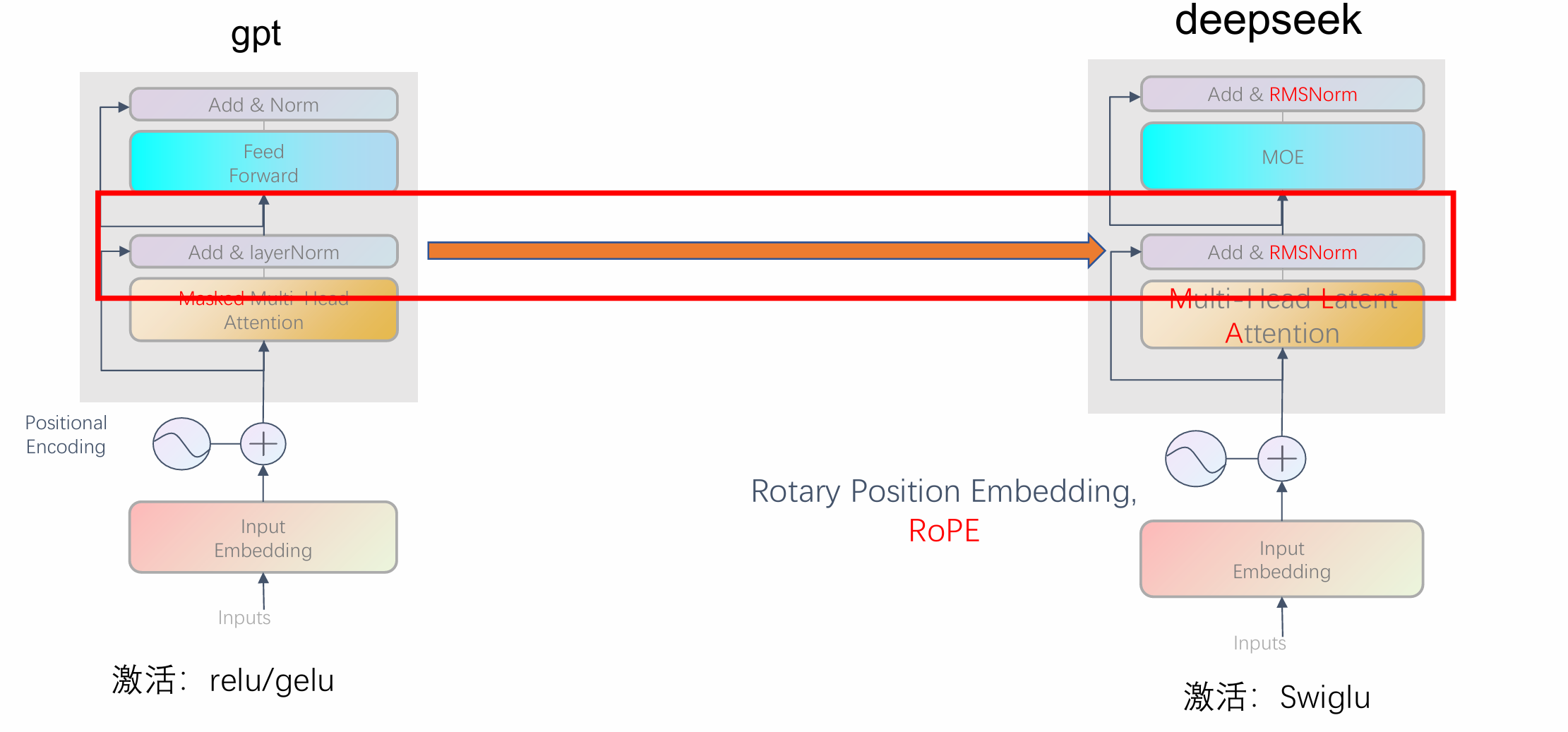
RMSNorm,LayerNorm都适用于语言任务NLP。RMS的更加简化一点
由于自注意力输出天然近零均值 ,所以RMS就把冗余的均值部分给去除掉了
批归一化:在批次维度上归一化,更适合图像网络
层归一化:对单个样本归一化。(求出该样本各个token均值方差,适合transformer)
Rms:简化的层归一化,不减去均值,仅缩放

为什么NLP不适用BatchNorm?
①NLP输入长度是可变的,而BatchNorm需要固定输入尺寸
②大模型使用的batch都很小,所以BatchNorm效率有限