本文档为完全分布式大数据环境(3台虚拟机:hadoop01~hadoop03)中Spark组件的独立测试教程,基于视频操作流程,结合完全分布式测试文档的规范要求,详细说明从环境准备、远程连接到服务启停、核心功能验证(Web页面验证、Python交互模式验证)的全流程,适用于验证Spark集群的独立可用性。
一、前期准备:环境基础信息与测试前提
测试前需确认环境配置及依赖组件状态符合要求,避免因环境问题导致测试失败:
1.1 基础环境信息
- 虚拟机配置:3台虚拟机(命名为hadoop01、hadoop02、hadoop03),硬盘总配置100GB~200GB,已完成基础环境部署
- 系统账号:优先使用hertz账号(密码:hertz);特殊操作需使用root账号(密码:1)
- 工具准备:Mobaxterm远程连接工具(已安装并可正常使用)、本地浏览器
1.2 测试前提
- 3台虚拟机(hadoop01~hadoop03)均正常启动,已到达登录页面
- 以hertz账号登录hadoop01节点(分布式脚本统一在hadoop01执行)
- Hadoop(HDFS+YARN)服务已正常启动(执行命令:start-all.sh)
- ZooKeeper服务已正常启动(执行命令:zk start),且状态正常(1台Leader、2台Follower)
二、Spark测试详细步骤
步骤1:确认虚拟机启动状态
操作说明:分别检查3台虚拟机(hadoop01、hadoop02、hadoop03)的启动状态,确保每台虚拟机系统加载完成,均已到达登录页面。
预期结果:3台虚拟机均正常启动,无启动报错,各自显示系统登录界面。
步骤2:使用Mobaxterm连接虚拟机
操作说明:打开本地Mobaxterm工具,分别建立与3台虚拟机(hadoop01、hadoop02、hadoop03)的SSH远程连接。
核心操作要点:
- 新建远程连接,选择SSH连接类型
- 分别输入3台虚拟机对应的正确IP地址
- 默认选择普通用户登录类型,无需额外修改
预期结果:3台虚拟机的Mobaxterm连接均成功建立,各自进入等待登录状态。
步骤3:输入账号密码完成登录
操作说明:在3台虚拟机对应的Mobaxterm连接终端中,依次完成账号和密码的输入操作。
具体操作:
- 终端提示输入账号时,输入:hertz
- 回车后,终端提示输入密码,输入:hertz(密码输入时无明文显示,直接输入后回车即可)
预期结果:3台虚拟机均登录成功,终端界面分别显示当前登录用户及主机标识,如hertz@hadoop01 \~、\[hertz@hadoop02 \~\]、hertz@hadoop03 \~$。
步骤4:启动Spark相关服务
操作说明:在登录成功的hadoop01节点终端中,先确认依赖的Hadoop和ZooKeeper服务已正常运行,再执行Spark集群启动命令。
具体操作:
- 确认依赖服务状态(可选):通过jps命令验证Hadoop、ZooKeeper进程正常;ZooKeeper状态可执行zkServer.sh status验证
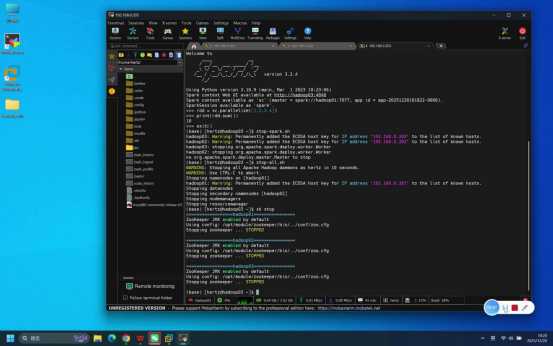
- 启动Spark集群:执行命令:start-spark.sh
说明:start-spark.sh为封装的集群脚本,执行后可一键启动hadoop01的Master节点和3台节点的Worker节点,无需在各节点单独启动。
预期结果:终端逐步输出各节点Spark服务的启动日志,无报错提示。
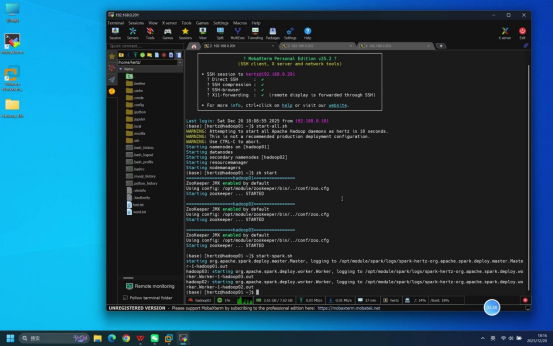
步骤5:执行jps命令验证进程状态
操作说明:启动命令执行完成后,分别在hadoop01、hadoop02、hadoop03节点的终端中输入jps命令,查看各节点Java进程运行情况。
具体命令:jps
预期结果:各节点进程符合以下要求,说明Spark服务启动正常:
- hadoop01节点:包含Master进程
- hadoop02~hadoop03节点:均包含Worker进程
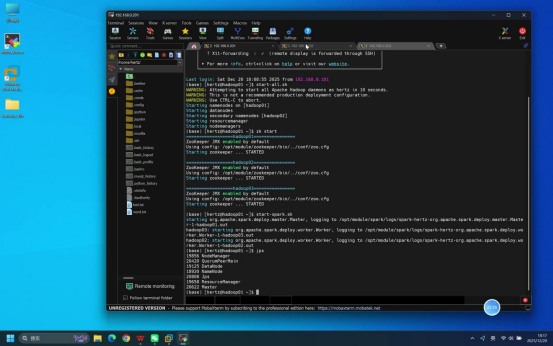
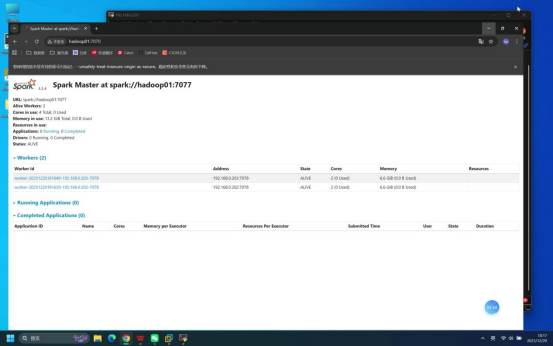
步骤6:打开浏览器访问Spark Web页面
操作说明:在本地打开浏览器,访问Spark Master节点的Web管理页面,验证集群状态。
具体操作:在浏览器地址栏输入:hadoop01:7070(注:"hadoop01"可替换为对应节点的IP地址,确保本地可正常解析)
预期结果:浏览器可正常打开Spark Web页面,无访问失败提示;页面"Workers"栏目中显示2台节点,状态均为"ALIVE"。
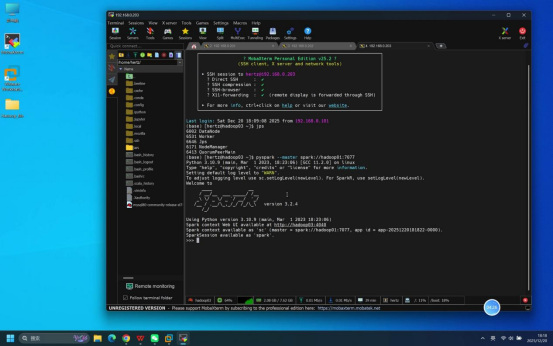
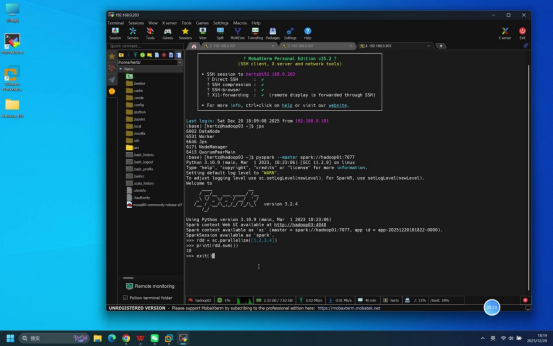
步骤7:执行Python交互模式验证命令
操作说明:在hadoop01节点终端中,启动Spark Python交互模式,执行测试代码验证核心计算功能。
具体操作:
- 启动Python交互模式:执行命令:pyspark --master spark://hadoop01:7077
- 输入测试代码:
- 创建RDD数据集:rdd = sc.parallelize(1,2,3,4)
- 计算数据集总和:print(rdd.sum())
- 退出交互模式(可选,可后续步骤完成后执行):exit()
预期结果:Python交互模式启动无报错;测试代码执行正常,终端输出结果"10",说明Spark计算功能正常。
步骤8:关闭Spark相关服务
操作说明:功能验证完成后,先退出Python交互模式(若未退出),再在hadoop01节点执行Spark集群停止命令,最后根据需求停止依赖服务。
具体操作:
- 退出Python交互模式:在交互模式终端输入exit(),或按Ctrl+C组合键终止进程
- 停止Spark集群:在hadoop01节点终端执行命令:stop-spark.sh(一键停止所有节点的Spark服务)
- 停止依赖服务(可选):若后续无需使用其他组件,依次执行stop-all.sh(停止Hadoop)、zk stop(停止ZooKeeper)
预期结果:Python交互模式正常退出;Spark集群停止命令执行无报错,终端输出各节点Spark服务停止日志。