机器学习-决策树
决策树(Decision Tree)是机器学习中最直观、最易于理解 的监督学习算法之一,兼具分类与回归能力。其"树形结构"与人类"if-then"决策逻辑高度一致,使得模型不仅在预测时效率极高,更具备天然的可解释性 。从核心思想 → 数学原理 → 算法变种 → 应用场景的路径理解决策树,是掌握树模型(如随机森林、GBDT)乃至整个集成学习理论的基石。
通俗地说,决策树模仿了人类在面对复杂决策时逐步拆解问题的过程。例如,要判断"明天是否适合打网球",我们可能会先看"天气",若是晴天,再考虑"湿度"是否小于70%;若是雨天,则看"风力"是否过大。这种层层递进的判断逻辑,正是决策树的核心。
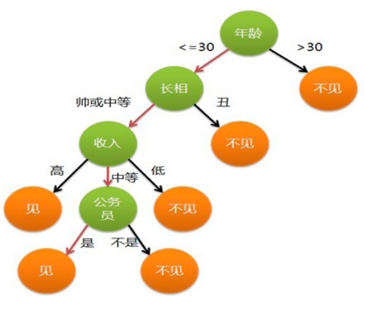
上图是一个经典的分类决策树,每个内部节点代表对一个特征的判断,每个分支代表判断的结果,而每个叶子节点则代表最终的分类或回归输出。决策树的学习目标,就是基于已知数据,自动构建出这样一棵"最合适"的树,即确定在哪些节点用哪些特征做判断,以及判断的阈值如何设定。
ID3树
ID3(Iterative Dichotomiser 3)是决策树最经典的算法之一,由Ross Quinlan于1986年提出。它采用信息增益 (Information Gain)作为特征选择的标准,以递归地构建决策树。
熵(Entropy)
熵是信息论中度量系统不确定性的核心概念。一个系统越混乱、越不确定,其熵值就越高。在决策树中,我们用熵来衡量数据集的"不纯度"。
假设当前数据集 DDD 中,样本属于第 kkk 类的概率为 pkp_kpk,则数据集 DDD 的熵定义为:
H(D)=−∑k=1Kpklog2pk H(D) = -\sum_{k=1}^{K} p_k \log_2 p_k H(D)=−k=1∑Kpklog2pk
其中 KKK 为类别总数。当所有样本属于同一类别时(最"纯"),熵为0;当样本均匀分布在所有类别时(最"乱"),熵取得最大值 log2K\log_2 Klog2K。
信息熵与条件熵
信息熵 H(D)H(D)H(D) 衡量了数据集 DDD 本身的不确定性。而当我们引入某个特征 A 对数据集进行划分后,我们可以计算划分后各子集的不确定性,并求其加权平均,这就是条件熵(Conditional Entropy)。
假设特征 AAA 有 VVV 个可能的取值 {a1,a2,...,aV}\{a1,a2,...,aV\}{a1,a2,...,aV},根据 AAA 的取值将 DDD 划分为 VVV 个子集 {D1,D2,...,DV}\{D1,D2,...,DV\}{D1,D2,...,DV}。条件熵 H(D∣A)H(D∣A)H(D∣A) 表示在已知特征 AAA 的条件下,数据集 DDD 的不确定性:
H(D∣A)=∑v=1V∣Dv∣∣D∣H(Dv) H(D|A) = \sum_{v=1}^{V} \frac{|D_v|}{|D|} H(D_v) H(D∣A)=v=1∑V∣D∣∣Dv∣H(Dv)
其中∣Dv∣|D_v|∣Dv∣是子集 DvD_vDv 的样本数,∣D∣|D|∣D∣ 是总样本数。
信息增益(Information Gain)
信息增益衡量了引入特征 A 进行划分后,数据集不确定性减少的程度。它定义为数据集原始的信息熵与划分后的条件熵之差:
Gain(D,A)=H(D)−H(D∣A) Gain(D,A) = H(D) - H(D|A) Gain(D,A)=H(D)−H(D∣A)
ID3算法的核心 :在构建树的每一个节点,算法会遍历所有可用特征,计算每个特征的信息增益,然后选择信息增益最大的那个特征作为当前节点的划分特征。因为信息增益越大,意味着使用该特征划分后,数据的"纯度"提升得越多。
举例说明
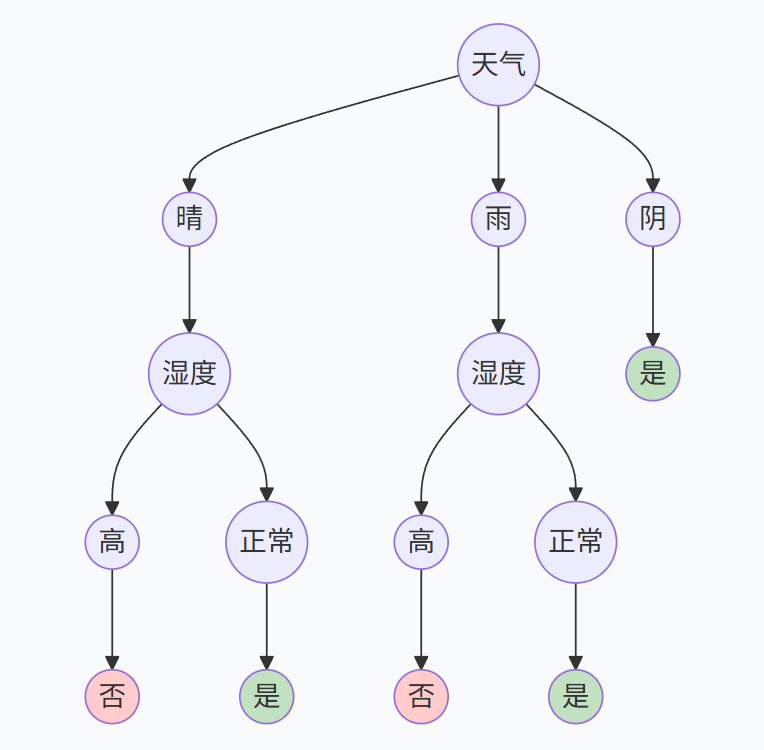
假设我们有一个关于"是否打网球"的数据集,特征包括天气(晴、雨、阴)、湿度(高、正常)等。标签为"是"或"否"。
- 首先,计算整个数据集的熵 H(D)H(D)H(D)。
- 然后,分别计算按"天气"划分后的条件熵 H(D∣天气)H(D∣天气)H(D∣天气),以及按"湿度"划分后的条件熵 H(D∣湿度)H(D∣湿度)H(D∣湿度)。
- 接着,计算信息增益:Gain(D,天气)=H(D)−H(D∣天气),Gain(D,湿度)=H(D)−H(D∣湿度)Gain(D,天气)=H(D)−H(D∣天气),Gain(D,湿度)=H(D)−H(D∣湿度)Gain(D,天气)=H(D)−H(D∣天气),Gain(D,湿度)=H(D)−H(D∣湿度)。
- 最后,比较哪个特征的信息增益更大,就选择哪个特征作为根节点。
ID3的局限性 :信息增益倾向于选择取值数目较多的特征(例如"ID编号"这种特征,每个样本取值都不同,划分后每个子集纯度极高,信息增益极大,但这种划分毫无泛化能力)。同时,ID3只能处理离散特征,不能处理连续值和缺失值。
C4.5树
C4.5是ID3的改进算法,由同一作者提出。它针对ID3的缺陷,主要引入了信息增益率(Gain Ratio)作为特征选择标准,并增加了对连续特征和缺失值的处理能力。
信息增益率
为了克服信息增益对多值特征的偏好,C4.5引入了内在信息 (Intrinsic Information)或称分裂信息 (Split Information),用来衡量特征 AAA 本身取值的分散程度:
SplitInfoA(D)=−∑v=1V∣Dv∣∣D∣log2∣Dv∣∣D∣ SplitInfo_A(D) = -\sum_{v=1}^{V} \frac{|D_v|}{|D|} \log_2 \frac{|D_v|}{|D|} SplitInfoA(D)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
这本质上就是以特征 AAA 的取值分布计算的熵。当一个特征取值非常多(非常分散)时,其分裂信息值会很大。
信息增益率定义为信息增益与分裂信息的比值:
GainRatio(D,A)=Gain(D,A)SplitInfoA(D) GainRatio(D,A) = \frac{Gain(D,A)}{SplitInfo_A(D)} GainRatio(D,A)=SplitInfoA(D)Gain(D,A)
这样,即使某个特征的信息增益很大,但如果其内在分裂信息也很大(即取值很分散),那么其增益率就会被调低,从而抑制了对多值特征的过度偏好。
C4.5在特征选择时,并非直接选择增益率最大的特征,而是先找出信息增益高于平均水平的特征,再从这些特征中选择增益率最高的,这是一种启发式策略。
对连续特征的处理
C4.5可以将连续特征离散化。对于一个连续特征 AAA,算法会将数据集 DDD 中 AAA 的所有取值排序 ,然后考察每两个相邻取值的中点作为潜在的分裂阈值。
对于每一个候选阈值 t,可以将数据集划分为 Dleft={x∣A≤t}Dleft=\{x∣A≤t\}Dleft={x∣A≤t} 和 Dright={x∣A>t}Dright=\{x∣A>t\}Dright={x∣A>t}两部分,然后计算以该点划分的信息增益或增益率。最终,选择使划分标准最优的那个阈值点,将连续特征转化为二分支的离散判断。
对缺失值的处理
C4.5处理缺失值的主要思想是权重分配。
- 在计算信息增益(率)时 :对于特征 A,仅使用在 A 上无缺失的样本子集来计算信息增益和分裂信息。同时,在计算条件熵的加权平均时,权重 ∣Dv∣/∣D∣|D_v| / |D|∣Dv∣/∣D∣ 调整为无缺失样本中属于该取值的比例。
- 在划分样本时 :对于一个在划分特征 A 上取值缺失的样本,它不会只进入一个子节点,而是以不同的概率(权重)进入所有子节点。这个概率等于当前节点中,无缺失样本在各个取值上的分布比例。这使得同一个样本可以同时"存在"于多个分支中,但其权重被稀释。
CART树
CART(Classification and Regression Trees)是另一种广泛使用的决策树算法,由Breiman等人于1984年提出。它与ID3/C4.5的主要区别在于:
- 二叉树结构:无论特征有多少个取值,CART每次只产生两个分支("是"或"否"),形成一棵二叉树。这简化了模型结构,也便于处理连续特征。
- 可以同时处理分类和回归任务:这是CART名称的由来。
- 使用不同的不纯度度量 :分类任务使用基尼指数 ,回归任务使用平方误差。
分类树:基尼指数(Gini Index)
基尼指数同样用于度量数据集的"不纯度"。对于数据集 DDD,其基尼指数定义为:
Gini(D)=1−∑k=1Kpk2 Gini(D) = 1 - \sum_{k=1}^{K} p_k^2 Gini(D)=1−k=1∑Kpk2
直观理解:从数据集中随机抽取两个样本,它们属于不同类别的概率。基尼指数越小,数据集的纯度越高。
对于一个特征 A 和一个候选划分点(对于连续特征)或取值子集(对于离散特征,CART通过遍历所有可能的二元分组来寻找最优划分),可以将 D 划分为 D1 和 D2 两部分。划分后的基尼指数为两部分基尼指数的加权和:
Gini(D,A)=∣D1∣∣D∣Gini(D1)+∣D2∣∣D∣Gini(D2) Gini(D,A) = \frac{|D_1|}{|D|} Gini(D_1) + \frac{|D_2|}{|D|} Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
CART分类树的构建过程 :在每个节点,遍历每个特征的所有可能划分方案,选择使得划分后基尼指数最小的特征和划分点。这与信息增益(率)的"最大化"思路相反,但本质相同,都是寻找让子节点更"纯"的划分。
回归树:最小化平方误差
对于回归任务,CART树预测的是连续值。每个叶子节点的输出值,通常是落到该叶子所有样本的标签平均值。
在构建回归树时,CART的目标是最小化样本的预测误差平方和 。对于特征 AAA 和一个划分点 t,将数据划分为 D1D1D1 和 D2D2D2,该划分的误差为:
E(D,A,t)=∑xi∈D1(yi−c1)2+∑xi∈D2(yi−c2)2 E(D,A,t) = \sum_{x_i \in D_1} (y_i - c_1)^2 + \sum_{x_i \in D_2} (y_i - c_2)^2 E(D,A,t)=xi∈D1∑(yi−c1)2+xi∈D2∑(yi−c2)2
其中,c1 和 c2 分别是 D1D1D1 和 D2D2D2 中样本标签的均值,即该区域的预测值。
总结与对比
| 算法 | 特征选择标准 | 树结构 | 任务类型 | 连续值处理 | 缺失值处理 | 主要特点 |
|---|---|---|---|---|---|---|
| ID3 | 信息增益 | 多叉树 | 分类 | 不支持 | 不支持 | 基础算法,易偏向多值特征 |
| C4.5 | 信息增益率 | 多叉树 | 分类 | 支持(二分) | 支持(权重分配) | ID3的全面改进,工业常用 |
| CART | 基尼指数(分类) 平方误差(回归) | 二叉树 | 分类与回归 | 支持(二分) | 支持(替代值/概率分配) | 应用最广,集成学习基础 |
如何选择?
- 理解基本概念:从ID3入手,搞懂熵和信息增益。
- 学习经典改进:通过C4.5理解如何改进指标、处理复杂数据。
- 掌握当前主流:CART 是实践中最常用的决策树算法,也是学习高级树模型的起点。
决策树的魅力在于其白盒模型的透明性。下一棵树将从哪里开始生长,取决于我们如何定义"最优"的划分。理解这些定义背后的数学与思想,便是掌握了开启树模型世界大门的钥匙。