GraphRAG(图谱检索增强生成)核心技术解析
检索增强生成(Retrieval-Augmented Generation)技术是一种结合了检索和生成两个阶段的自然语言处理技术,它由 Facebook AI 团队在 2020 年提出。这种方法的核心思想是利用大规模的预训练语言模型生成技术,并结合信息检索的策略,以改善回答的准确性和相关性。
这种传统的 RAG 通过 Text2Vec 检索的方式通过将生成的响应与现实世界的数据联系起来来减少幻觉,但准确回答复杂问题是另一回事。这在于每个文本嵌入都表示非结构化数据集中的一个特定块,通过最近邻算法搜索查找表示在语义上与传入用户查询相似的块的嵌入,这也意味着搜索是语义性的,但仍然高度具体。因此,候选块的质量在很大程度上取决于查询质量。就像翻阅一本食谱书一样。使用关键字搜索"炒鸡蛋"或"西红柿鸡蛋面"并找到说明,它速度很快,对于简单的问题非常有效。但是,如果你对这些菜肴背后的文化背景或是想知道为什么某些成分能够协同作用增加风味感兴趣,仅仅关键字搜索可能就显得力不从心。例如,西红柿和鸡蛋为何能搭配得如此完美?
同时,对于已经熟悉 RAG 的小伙伴来说,可能遇到的头痛问题是:
- 上下文在文本块之间丢失
- 随着检索到的文档的增长,性能会下降
- 整合外部知识感觉就像蒙着眼睛试图解开魔方
传统RAG系统在负责合成来自各种来源的信息或理解数据集中的总体主题时却很困难。例如,如果询问传统RAG 系统:"根据该研究数据集,全球气温变暖的主要原因是什么?",它很难提供全面的答案,因为与气候相关的不同信息的分散在整个数据集中,而语义检索的方式没有办法跨整个数据集去做全局检索。这样的需求凸显了对 RAG 更加结构化和智能的方法的需求。这就是 GraphRAG(Graph Retrieval-Augmented Generation)派上用场的地方,它的核心作用是提高大模型的模型通过利用结构化知识图谱提供精确且上下文丰富的答案的能力。
GraphRAG通过利用大模型从原始文本数据中提取知识图谱来满足跨上下文检索的需求。该知识图将信息表示为互连实体和关系的网络,与简单的文本片段相比,提供了更丰富的数据表示。这种结构化表示使 GraphRAG 能够擅长回答需要推理和连接不同信息的复杂问题。
1.传统 RAG 的技术痛点
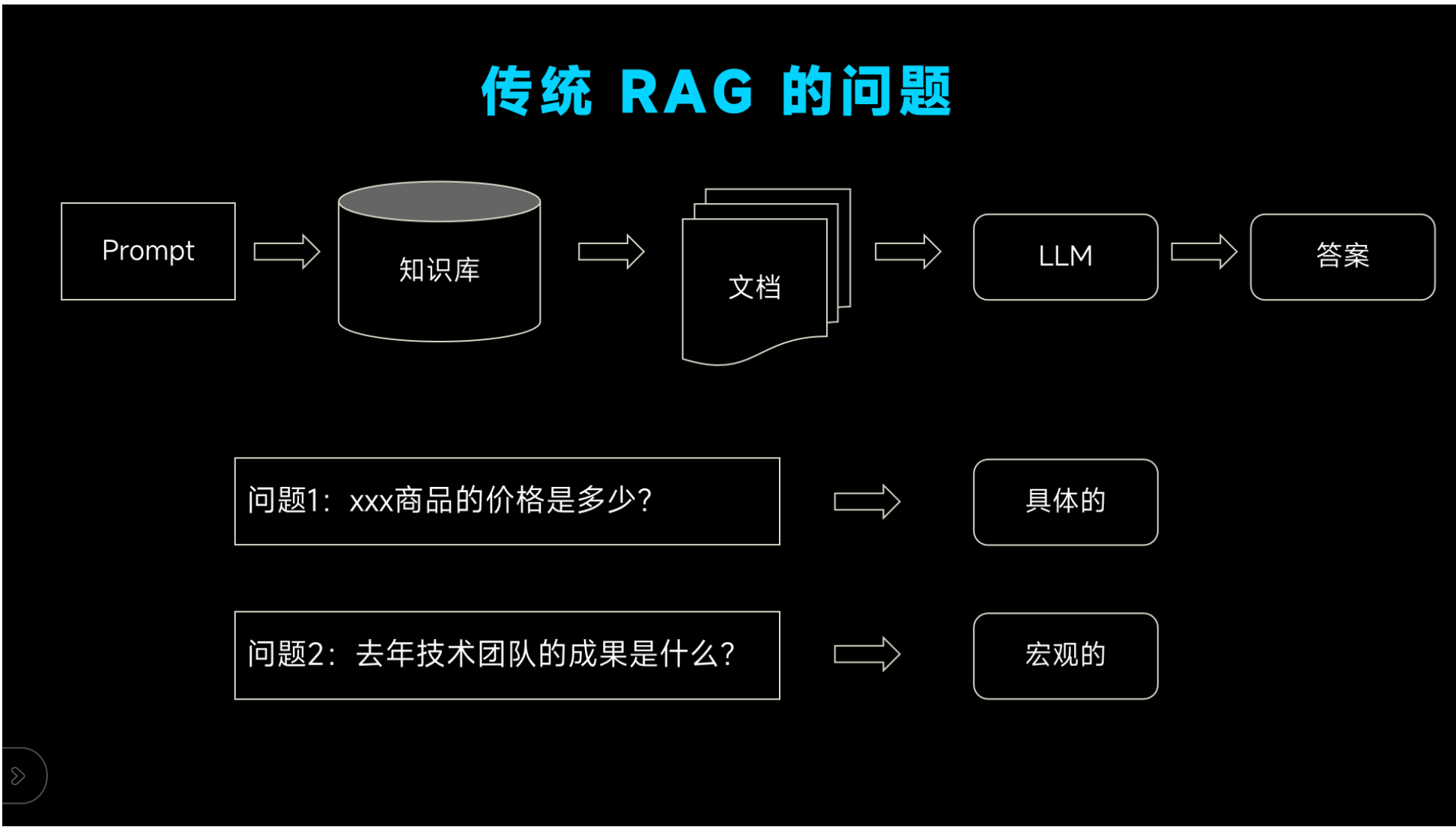
检索增强生成(RAG)由 Facebook AI 团队 2020 年提出,通过 Text2Vec 语义检索关联现实数据降低大模型幻觉,但处理复杂问题存在显著短板:
- 上下文割裂:文本分块检索导致块间关联信息丢失,无法整合分散多源知识;
- 检索依赖查询质量:语义检索高度具体,对模糊、推理类查询适配性差;
- 性能随数据量衰减:文档量增加时候选块筛选效率降低,答案全面性下降;
- 无全局推理能力:无法跨数据集做全局关联分析,难以回答多源信息整合、逻辑推理类复杂问题。
传统 RAG 本质为片段式语义匹配,仅适配简单事实性、关键字查询,复杂需求需更结构化的技术方案,GraphRAG 由此诞生。
2. GraphRAG 核心定义
GraphRAG(Graph Retrieval-Augmented Generation)是传统 RAG 的进阶形态,核心是将非结构化文本转化为结构化知识图谱,基于图谱的实体、关系、拓扑结构实现「语义 + 结构化推理检索」,结合大模型生成精准、全面、有逻辑的答案。
其将图谱构建、图谱检索推理、结构化上下文重构、大模型生成 深度融合为端到端流程,实现从 "片段式检索" 到 "结构化推理" 的升级,核心解决传统 RAG 上下文丢失、复杂推理能力弱的问题,同时提升答案可解释性、降低幻觉,简化知识更新维护流程。
3. GraphRAG 核心技术原理
GraphRAG 工作流程分为离线知识图谱构建层 和在线推理生成层,大模型贯穿全流程,图数据库为核心基础设施,形成 "数据结构化→图谱推理检索→结构化生成" 闭环。
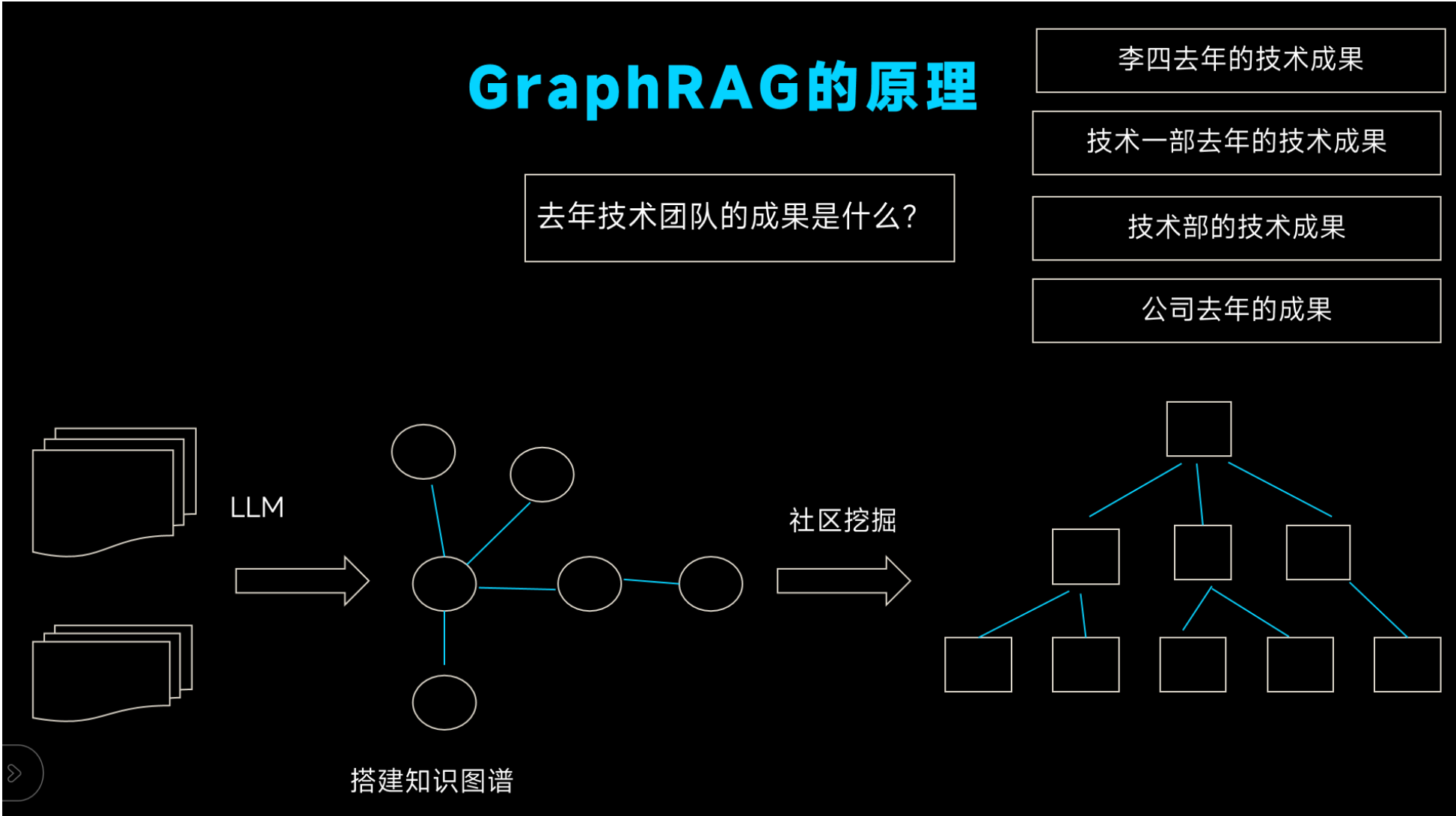
(一)离线构建层:非结构化文本→结构化知识图谱
从原始文本提取结构化知识并构建可推理知识图谱,为在线检索提供基础,包含 4 个核心环节:
- 文本预处理与细粒度分块:对原始文本做清洗、分词,按语义单元 / 句子细粒度分块,贴合实体边界,避免实体和关系割裂;
- 实体 / 关系 / 属性抽取:通过大模型 / 领域微调抽取模型,提取核心实体、实体属性、实体间语义关系,解决传统规则抽取低泛化性问题;
- 知识图谱构建与融合 :将 "实体 - 关系 - 实体" 三元组、实体属性整合为属性图,完成知识去重、实体对齐、关系补全,形成 "节点(实体)- 边(关系)- 属性" 互连网络;
- 图谱嵌入(可选):通过 TransE、GraphSAGE、Node2Vec 等算法,将实体、关系转化为低维稠密向量,实现结构化 + 语义双重检索,解决查询与图谱实体表述不一致问题。
(二)在线推理生成层:用户查询→结构化推理→答案生成
基于知识图谱做逻辑推理检索,将结构化知识转化为自然语言答案,包含 4 个核心环节:
-
用户查询结构化解析:大模型解析查询,提取核心实体、查询意图、逻辑关系,对多跳推理查询解析出具体推理路径;
-
图谱检索与逻辑推理
:结合两种方式实现精准检索,支持组合使用:
- 结构化检索:从核心实体出发,按拓扑结构遍历直接 / 间接关系实体,多跳查询按推理路径做多跳遍历;
- 语义 + 结构化混合检索:将查询嵌入向量与图谱嵌入向量做语义匹配,结合拓扑结构推理提升鲁棒性;
-
结构化上下文重构:将检索到的实体、关系、推理路径,转化为大模型可理解的自然语言,同时保留因果 / 包含等逻辑结构;
-
大模型生成答案:将重构后的结构化上下文与用户查询输入大模型,基于结构化知识生成答案,替代传统文本片段拼接方式。
4. GraphRAG 核心技术架构
采用五层解耦架构,各层职责明确、可灵活扩展,主流支撑工具以开源为主,降低落地成本:
| 架构层级 | 核心功能 | 主流技术 / 工具支撑 |
|---|---|---|
| 数据层 | 存储原始非结构化文本数据,为图谱构建提供数据源 | 本地文件、MinIO、HDFS、MySQL/PostgreSQL |
| 图谱构建层 | 文本分块、实体 / 关系 / 属性抽取、图谱融合、图谱嵌入 | LLM、spaCy、HanLP、GraphSAGE |
| 图谱存储层 | 存储知识图谱,支持高效图遍历、多跳推理、结构化查询 | Neo4j 社区版、Nebula Graph、NetworkX |
| 检索推理层 | 查询解析、图谱结构化检索、语义匹配、推理路径优化、结构化上下文重构 | LLM、Cypher/nGQL、Sentence-BERT |
| 生成层 | 接收结构化上下文,生成自然流畅、准确的自然语言答案 | GPT-3.5/4、通义千问、Llama 3、文心一言 |
核心基础设施:图数据库,针对 "节点 - 边" 拓扑结构做专项优化,实现高效多跳推理和全局检索,区别于传统 RAG 的向量数据库(仅支持语义相似性匹配)。
5. GraphRAG 与传统 RAG、KGQA 的核心差异
(一)GraphRAG vs 传统 RAG
二者为互补关系,非替代关系,核心差异如下:
| 对比维度 | 传统 RAG | GraphRAG |
|---|---|---|
| 检索本质 | 文本片段的语义相似性匹配 | 知识图谱的结构化逻辑推理 |
| 上下文形态 | 独立文本片段,上下文割裂 | 实体 - 关系 + 推理路径,全局关联 |
| 复杂推理能力 | 弱,不支持多跳 / 分析类查询 | 强,支持多跳推理、因果分析、多源整合 |
| 数据量对性能影响 | 性能显著衰减 | 性能稳定,可扩展性强 |
| 答案可解释性 | 弱,无法追溯答案依据 | 强,可追溯至图谱三元组 |
| 知识更新成本 | 高,需重新分块、嵌入、入库 | 低,仅增删改单个实体 / 关系 |
| 幻觉控制 | 中等,依赖文本片段完整性 | 低,基于结构化知识,依据明确 |
(二)GraphRAG vs KGQA(知识图谱问答)
GraphRAG 是 KGQA 与传统 RAG 的最优结合,核心差异如下:
| 对比维度 | KGQA | GraphRAG |
|---|---|---|
| 生成逻辑 | 基于三元组直接生成,无大模型深度融合 | 结构化知识重构 + 大模型生成,深度融合二者优势 |
| 答案形态 | 简洁碎片化,缺乏自然流畅性 | 自然流畅,符合人类语言习惯 |
| 复杂查询适配 | 仅支持简单图谱查询,多跳能力弱 | 支持多跳推理、模糊查询、分析类查询 |
| 非结构化数据处理 | 不支持,仅适配结构化图谱数据 | 支持,可直接从非结构化文本构建图谱 |
| 落地复杂度 | 低,仅需图谱 + 简单查询引擎 | 中等,需图谱 + 大模型 + 检索推理层融合 |
6. GraphRAG 核心适用场景
聚焦复杂推理、多源信息整合场景,与传统 RAG 形成场景互补,核心适用场景:
- 行业智能问答:金融、医疗、法律等领域的关联分析类查询;
- 科研 / 数据分析:研究数据集、企业业务数据的多因素关联分析;
- 多跳推理查询:教育、地理等领域的多环节逻辑推理类问题;
- 企业智能知识库:产品、政务知识库的关联化问答与信息检索;
- 内容深度分析:热点事件、行业趋势的主体、脉络、因果关系分析。
7.GraphRAG 技术挑战与优化方向
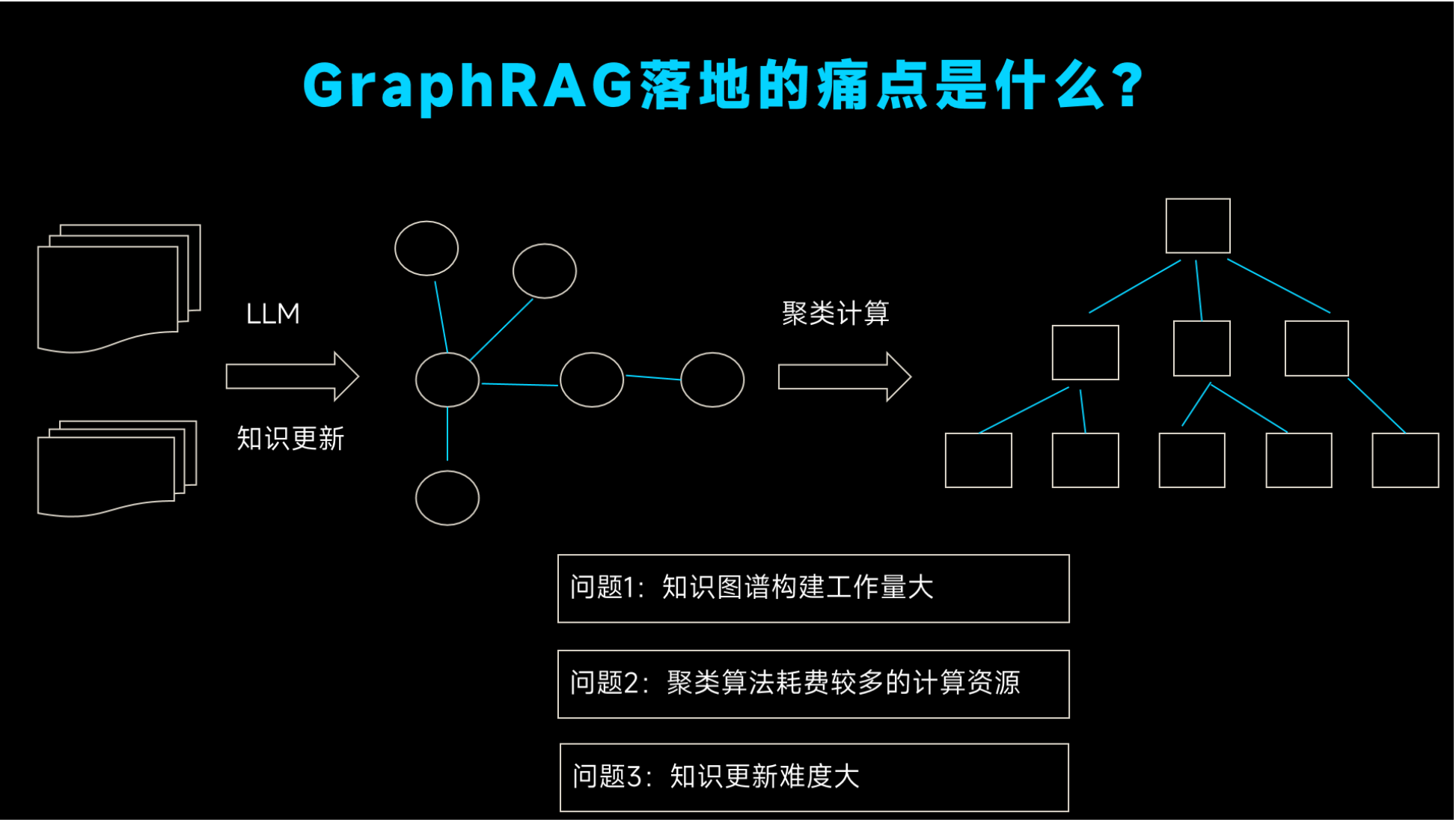
(一)核心技术挑战
- 知识抽取精度:跨领域、模糊语义文本易出现实体漏抽、关系误判,影响图谱质量;
- 图数据库性能与成本:超大规模图谱多跳遍历效率下降,商用图数据库成本较高;
- 复杂查询解析:极复杂多跳、模糊、多意图查询,推理路径解析易出现偏差;
- 部署复杂度:多组件协同,轻量化、边缘设备部署难度大;
- 图谱迭代维护:长期运行易出现知识冗余、冲突,缺乏自动化优化机制。
(二)主流优化方向
- 提升抽取精度:结合领域微调大模型 + 人工校验 + 知识图谱补全算法;
- 平衡性能与成本:开源图数据库分布式部署 +"图谱 + 向量" 混合检索;
- 优化查询解析:Prompt Engineering + 思维链(CoT)+ 工具调用提升解析能力;
- 轻量化部署:轻量图数据库 + 开源小模型搭建极简落地方案;
- 自动化图谱维护:加入知识冲突检测、冗余清理、实体消歧自动化算法。
8. GraphRAG 技术总结
- 技术定位:大模型时代 RAG 技术的重要发展方向,实现结构化推理 + 自然语言生成的双重能力,弥补传统 RAG 和纯 KGQA 的技术缺陷;
- 落地原则:简单事实性查询用传统 RAG,复杂推理分析类查询用 GraphRAG,避免过度设计;
- 落地路径:中小场景采用开源轻量组件快速落地,大型企业场景结合分布式图数据库 + 大模型私有化部署;
- 发展趋势:向端到端轻量化、多模态融合、自动化图谱构建维护发展,与 Agent 技术结合实现 "检索 - 推理 - 行动" 全流程智能化。