喂饭级教程:如何在 ROS 2 仿真中实现四足机器人的 VLA(视觉-语言-动作)控制链路
文章目录
- [喂饭级教程:如何在 ROS 2 仿真中实现四足机器人的 VLA(视觉-语言-动作)控制链路](#喂饭级教程:如何在 ROS 2 仿真中实现四足机器人的 VLA(视觉-语言-动作)控制链路)
-
- 前言:我们在做什么?
- [1. 第一步:解决"腿软"问题(关键!)](#1. 第一步:解决“腿软”问题(关键!))
- [2. 第二步:搭建 VLA 桥接包](#2. 第二步:搭建 VLA 桥接包)
- [3. 第三步:启动流程(严格按照顺序!)](#3. 第三步:启动流程(严格按照顺序!))
-
- [终端 1:世界生成器](#终端 1:世界生成器)
- [终端 2:运动小脑](#终端 2:运动小脑)
- [终端 3:唤醒法师 (重要!)](#终端 3:唤醒法师 (重要!))
- [终端 4:VLA 大脑(我们的桥接节点)](#终端 4:VLA 大脑(我们的桥接节点))
- [4. 第四步:见证奇迹](#4. 第四步:见证奇迹)
- [5. 总结](#5. 总结)
前言:我们在做什么?
在这个教程里,我们将带你手把手在 Gazebo 仿真环境中,用自然语言(比如"向前走")控制一只 Unitree GO2 四足机器人。
⚠️ 诚实预警 :
为了聚焦于系统架构 和控制链路的跑通,本教程中的"大模型节点"目前是**模拟(Mock)**的。
- 现在的状态:节点接收到包含 "forward" 的指令,就会假装自己听懂了,并发出控制命令。
- 未来的扩展 :你只需要把这个 Python 文件里的
if "forward" in text:换成调用 OpenAI/Gemini 的 API 代码,它就变成真正的 AI 机器人了。
1. 第一步:解决"腿软"问题(关键!)
很多同学根据我上一篇文章下载了 GO2 的代码包,发现仿真里机器人要么不动,要么像面条一样瘫在地上。这是因为官方配置里缺少了 Gazebo 物理引擎需要的 PID 参数。
操作步骤 :
找到这个文件:src/go2_description/config/ros_control.yaml
在文件末尾(或其他合适位置),确保加入以下 gazebo_ros2_control 配置块。这一步是让狗能站起来的关键!
yaml
# src/go2_description/config/ros_control.yaml 修改示例
controller_manager:
# ... (原有的内容保持不变)
# === 请务必添加以下内容 ===
gazebo_ros2_control:
ros__parameters:
pid_gains:
# 把12个关节的 PID 都加上,让电机这股劲儿能使出来
rf_hip_joint: {p: 100.0, i: 0.05, d: 2.5}
rf_upper_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
rf_lower_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
lf_hip_joint: {p: 100.0, i: 0.05, d: 2.5}
lf_upper_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
lf_lower_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
rh_hip_joint: {p: 100.0, i: 0.05, d: 2.5}
rh_upper_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
rh_lower_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
lh_hip_joint: {p: 100.0, i: 0.05, d: 2.5}
lh_upper_leg_joint: {p: 100.0, i: 0.05, d: 2.5}
lh_lower_leg_joint: {p: 100.0, i: 0.05, d: 2.5}2. 第二步:搭建 VLA 桥接包
我们需要一个翻译官,把自然语言变成机器人的速度指令。
-
创建包 :
在
src目录下新建一个包叫vla_bridge。我把文件夹放这里了通过网盘分享的文件:vla_bridge.zip链接: https://pan.baidu.com/s/1FibvO3gqAD_cHvOLeqCjFA 提取码: luck
-
核心代码 (
src/vla_bridge/vla_bridge/vla_node.py):这是我们的模拟 VLA 节点。
python# 简化逻辑展示 def instruction_callback(self, msg): command = msg.data.lower() if "move forward" in command: self.get_logger().info("【VLA模拟】理解指令:请求向前移动") # 发送结构化指令给下层 self.action_pub.publish(String(data="move forward 1.0m")) -
执行代码 (
src/vla_bridge/vla_bridge/action_parser_node.py):这是动作执行器,它把 "move forward 1.0m" 翻译成
cmd_vel速度话题。python# 简化逻辑展示 def execute_move(self): # 发布线速度 0.5 m/s msg = Twist() msg.linear.x = 0.5 self.cmd_vel_pub.publish(msg) -
终端编译
colcon build 之后source
3. 第三步:启动流程(严格按照顺序!)
玩机器人就像开飞机,启动顺序乱了就飞不起来。请打开 4个终端。
终端 1:世界生成器
加载仿真环境和机器人模型。
bash
ros2 launch gazebo_sim launch.py sensors:=true world:=warehouse.sdf现象:Gazebo 窗口弹出,狗出现在里面,但是此时它是瘫软的。
终端 2:运动小脑
启动机器人的运动控制器,负责控制那12个电机怎么动。
bash
ros2 launch quadropted_controller robot_controller.launch.py现象:终端里会疯狂刷屏,这是正常的。
终端 3:唤醒法师 (重要!)
机器人默认是趴着的(阻尼模式),我们需要发服务指令把它叫醒。
先发这个(站起来):
bash
ros2 service call /robot1/robot_behavior_command quadropted_msgs/srv/RobotBehaviorCommand "{command: 'up'}"现象:你会看到狗在 Gazebo 里猛地站了起来!
再发这个(切换到行走模式):
bash
ros2 service call /robot1/robot_behavior_command quadropted_msgs/srv/RobotBehaviorCommand "{command: 'walk'}"现象:狗会稍微调整一下姿态,准备好走路。如果没有这一步,发速度指令它只会原地踏步。
终端 4:VLA 大脑(我们的桥接节点)
启动我们写的 Python 节点。
bash
ros2 launch vla_bridge vla_bridge.launch.py现象:显示 Ready to receive instructions...
4. 第四步:见证奇迹
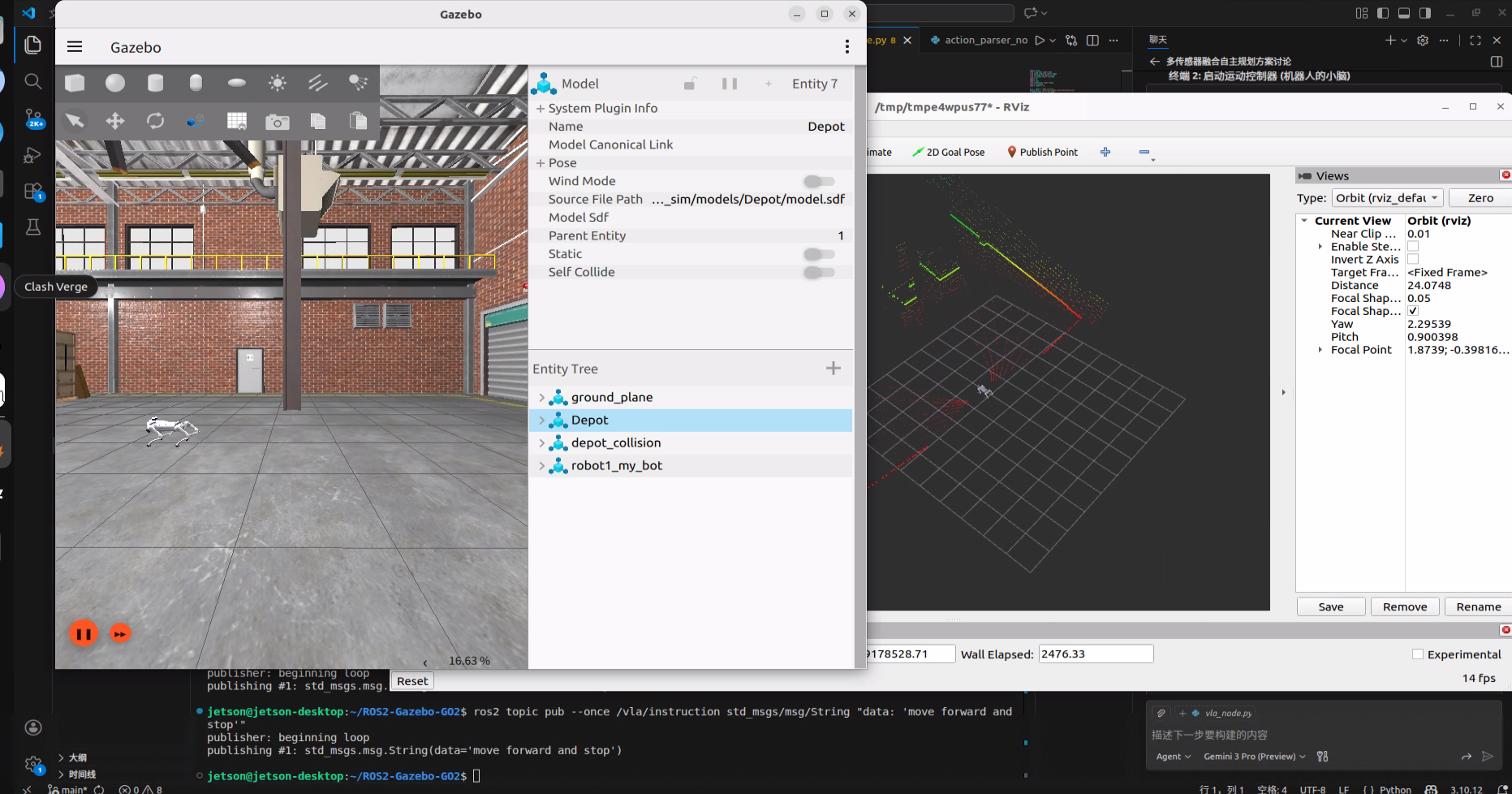
现在万事俱备,我们在任意终端里扮演"用户",发送一条自然语言指令:
bash
ros2 topic pub --once /vla/instruction std_msgs/msg/String "data: 'move forward and stop'"预期的快乐:
- 终端 4 会打印:
[ActionParser] Executing: move forward ... - Gazebo 里的狗开始走了!
- 走了一段距离后,它会自动停下来。
5. 总结
虽然我们的 VLA 现在是"人工智障"(Mock 的),但这套链路是真实可用的:
- 感知层 :摄像头图像 (
Image) 已接入。 - 决策层 :指令接收 (
String) 已打通。 - 执行层 :物理仿真 (
Gazebo) 和运动控制 (Controller) 已修复并完美配合。
如果你想在这个基础上做真 AI,只需要修改 vla_node.py,把 if 语句换成大模型 API 调用即可。恭喜你,迈出了具身智能的第一步!