分类问题
实例1,垃圾邮件检测。
任务:判断是否为垃圾邮件
输入:邮件
输出:是/不是垃圾邮件
实例2:图片分类
分类:根据已知样本的某些特征 ,判断一个新 样本属于哪个已知的 样本类。
分类任务与回归任务的区别
回归任务--
回归目标:建立函数关系
模型输出:连续型数值 如1到20000的任意数,可以是整数也可以是小数,有理数无理数。
回归(Regression) 的核心含义是:根据已知的输入数据,预测一个 连续型的输出值。
分类任务---
分类目标:判断类别
模型输出:非连续型标签 如(pass/failed;0,1,2....)

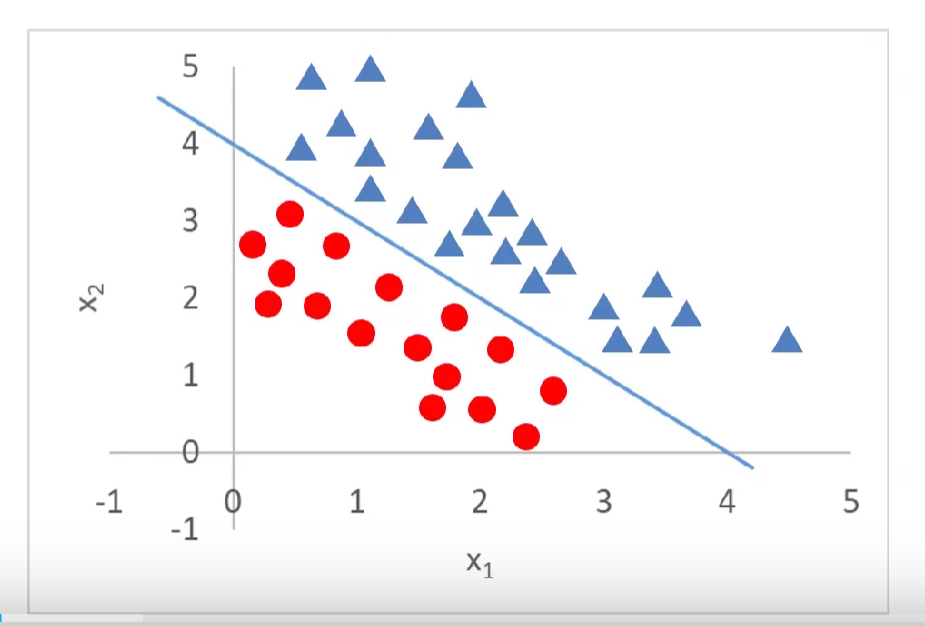
sigmoid函数的引出
(x1,x2)------>y y就是分类结果。0为红色圆球,1为蓝色三角。
如何将一个 的线性函数(函数y的取值范围是负无穷,到正无穷)转为一个取值范围在0~1之间的概率分布。
这时候就需要引入sigmoid函数了。
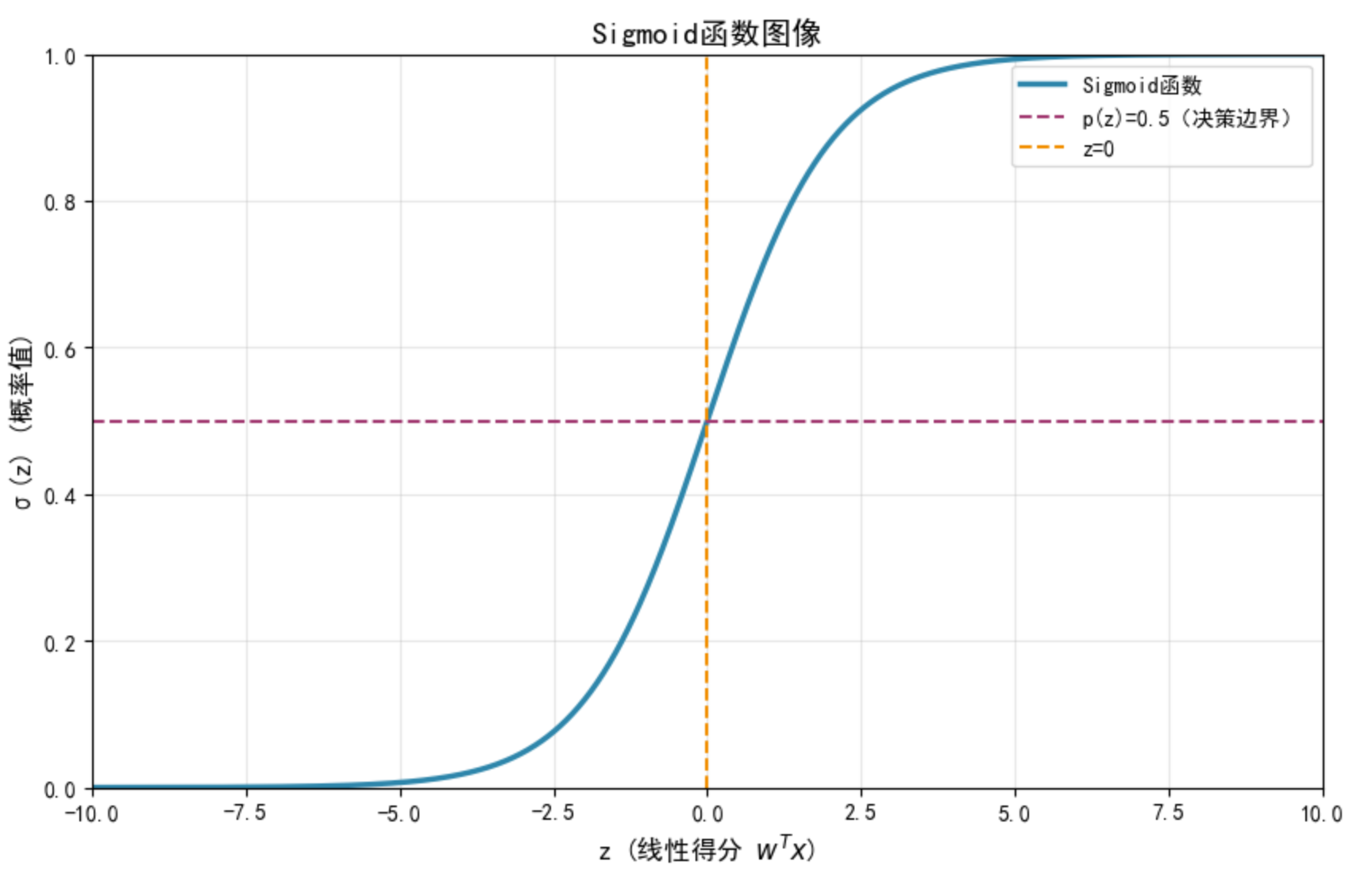
在这个图中 其中
是各参数 Z的取值范围是负无穷到正无穷
转化sigmoid函数就是
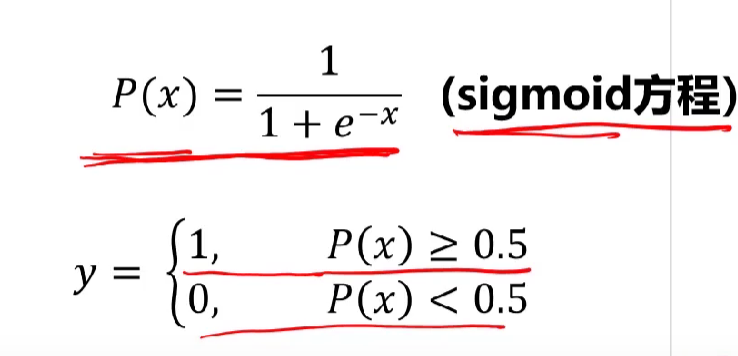
就是说当P(x)大于等于0.5时我们认为趋近于1,就是分类1
当P(x)小于0.5时,认为趋近0,就是分类0
所以我们的目标就是根据训练集,找出sigmoid函数中合适的这些个参数
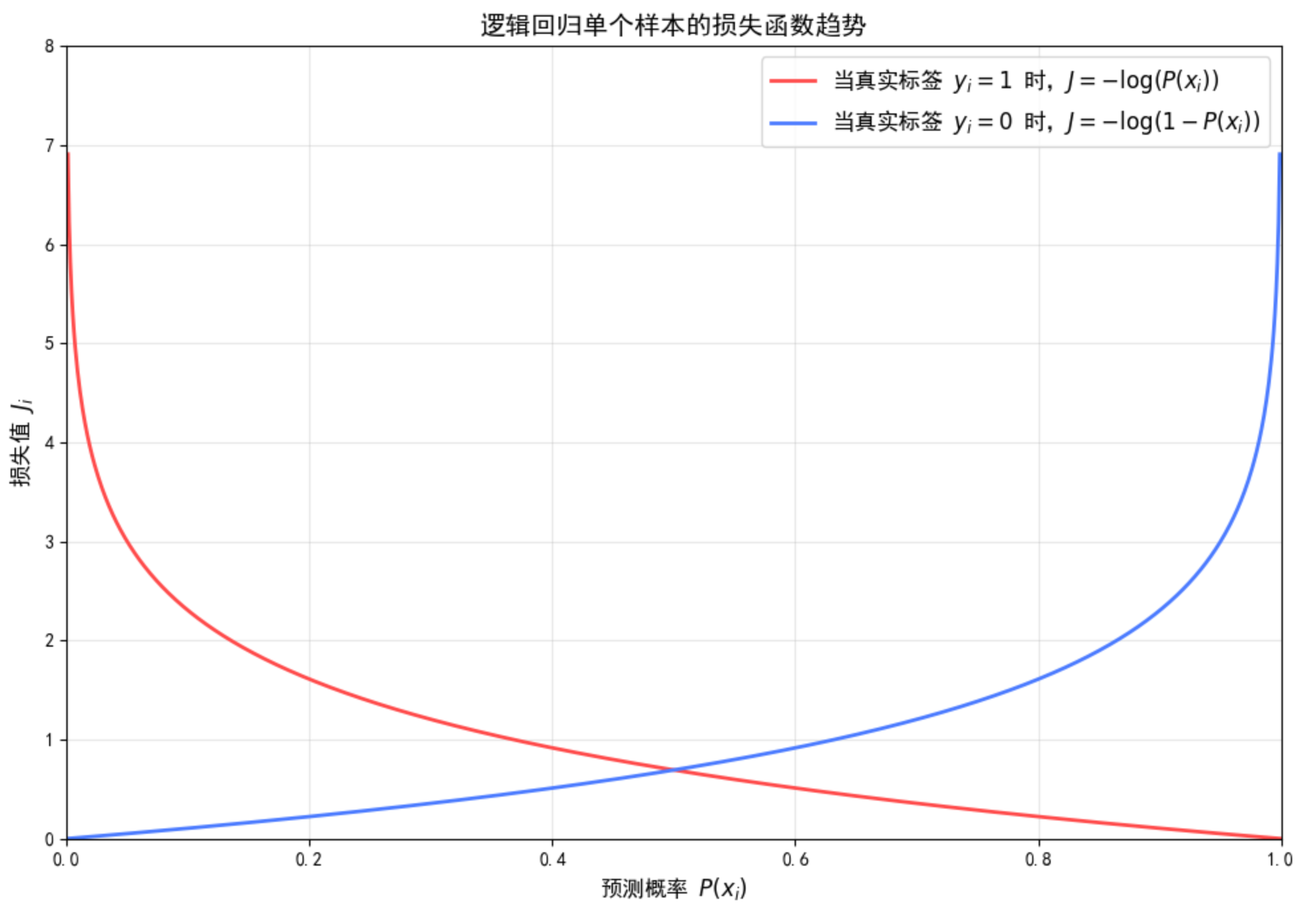
sigmoid函数对应的损失函数
当然sigmoid函数也是损失函数,找寻最优参数的过程也是依托损失函数来根据数据集逐渐收敛找出的。
你想知道的 sigmoid 函数对应的损失函数,其实就是逻辑回归的对数似然损失(也叫交叉熵损失) ------ 这是专门为二分类场景、适配 sigmoid 输出(概率值)设计的损失函数,核心是惩罚模型对样本类别的错误预测。