一、语言模型
- 核心目标:估计联合概率
语言模型的本质是计算一个句子(单词序列)出现的概率,或者根据上文预测下一个词。
-
目标公式:
P(S)=P(w1,w2,...,wm)P(S)=P(w1,w2,...,wm) -
意义:判断一句话在自然语言中是否通顺(概率越高,越自然),或在生成任务中选择概率最大的下一个词。
- 实现路径:链式法则 (Chain Rule)
直接计算联合概率极其困难(数据稀疏),因此利用概率链式法则将其分解为条件概率的乘积:
P(w1,w2,...,wm)=P(w1)⋅P(w2∣w1)⋅P(w3∣w1,w2)⋅...⋅P(wm∣w1...wm−1)P(w1,w2,...,wm)=P(w1)⋅P(w2∣w1)⋅P(w3∣w1,w2)⋅...⋅P(wm∣w1...wm−1)- 简化方案:N-gram 模型
为了解决长序列参数过多的问题,引入马尔可夫假设 (Markov Assumption) :假设当前词出现的概率只与前面 的tau个词有关
-
N-gram 通用公式:
P(wi∣w1...wi−1)≈P(wi∣wi−N+1...wi−1)P(wi∣w1...wi−1)≈P(wi∣wi−N+1...wi−1) -
常见类型:
-
Unigram (N=1):词与词独立。
P(w1,w2)≈P(w1)P(w2)P(w1,w2)≈P(w1)P(w2) -
Bigram (N=2):只看前1个词。
P(wi∣wi−1)P(wi∣wi−1) -
Trigram (N=3):只看前;2个词。
P(wi∣wi−2,wi−1)P(wi∣wi−2,wi−1)
-
- 参数估计:通过统计语料库中的词频来估算概率。
二、代码
tokens=test52text_process.tokenize(test52text_process.read_time_machine())
corpus=[token for line in tokens for token in line]
vocab=test52text_process.Vocab(corpus)
print(vocab.token_freqs[:10])#查看高频词
freq=[freq for token,freq in vocab.token_freqs]
plt.figure(figsize=(10,6))
plt.xlabel('token')
plt.ylabel('frequency n(x)')
plt.xscale('log')
plt.yscale('log')
plt.grid(True)
plt.plot(freq)
plt.show()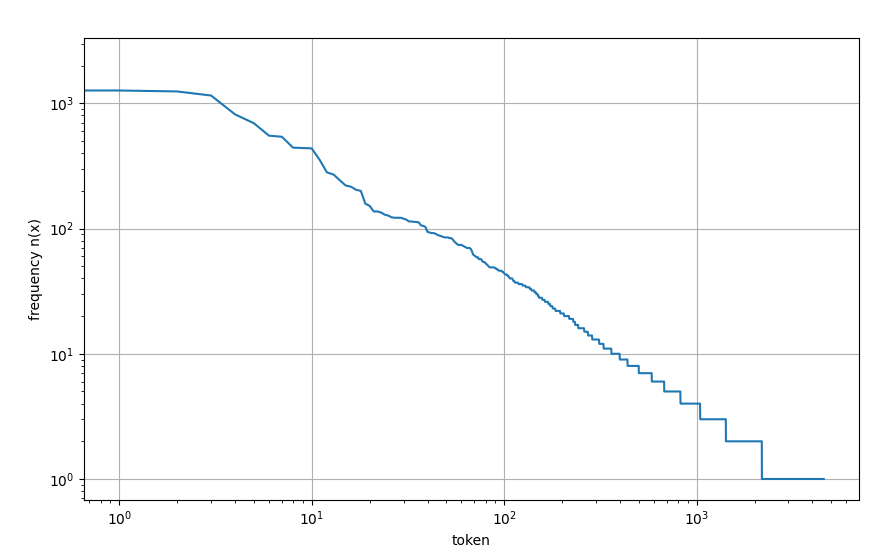
频率高于80%掌握在20%词汇里(二八定律),可以从频率图确定min_freq
gram_tokens=[pair for pair in zip(corpus[:-1],corpus[1:])]#生成二元列表
gram_vocab=test52text_process.Vocab(gram_tokens)
print(gram_vocab.token_freqs[:10])#二元很多是stopwordstrigram_tokens=[pair for pair in zip(corpus[:-2],corpus[1:-1],corpus[2:])]#生成三元列表
trigram_vocab=test52text_process.Vocab(trigram_tokens)
print(trigram_vocab.token_freqs[:10])#三元可以反映文章趋势,很少有3个停用词连在一起bigram_token=[freq for token,freq in gram_vocab.token_freqs]
trigram_token=[freq for token,freq in trigram_vocab.token_freqs]
plt.figure(figsize=(10,6))
plt.xlabel('token')
plt.ylabel('frequency n(x)')
plt.xscale('log')
plt.yscale('log')
plt.grid(True)
plt.plot(freq)
plt.plot(bigram_token)
plt.plot(trigram_token)
plt.legend(['1-gram','bi-gram','tri-gram'])
plt.show()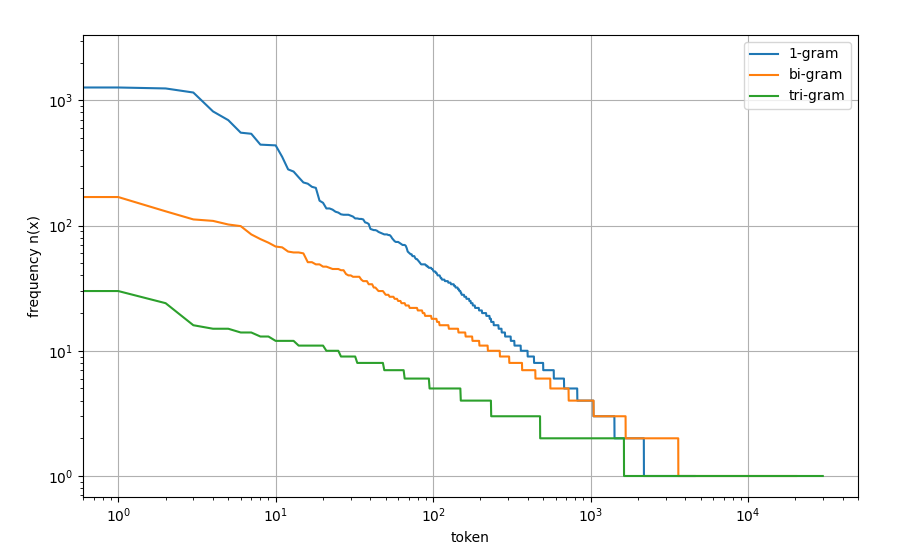
#随机取小批量,方法:每次在长序列最前面随即丢弃一定数量的值,从头来是切
def seq_data_iter_random(corpus,batch_size,num_steps):#num_steps小片段的数据长度
corpus=corpus[random.randint(0,num_steps-1):]
num_subseqs=(len(corpus)-1)//num_steps#防止切到最后一个片段,导致没有标签y,提前预留,一共可以产生num_subseqs个小片段
initial_indices=list(range(0,num_subseqs*num_steps,num_steps))
random.shuffle(initial_indices)
def data(pos):#给定起点 pos,就切一段长度 num_steps 的子序列
return corpus[pos:pos+num_steps]
num_batches=num_subseqs//batch_size#计算一共能组成多少个 batch
for i in range(0,batch_size*num_batches,batch_size):#划分n个batch
initial_indices_per_batch=initial_indices[i:i+batch_size]#逐个取batch
X=[data(j) for j in initial_indices_per_batch]
Y=[data(j+1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
my_seq=list(range(35))
for X,Y in seq_data_iter_random(my_seq,2,5):
print('X',X,'y',Y)
保证相邻2个小批量的子序列在原始序列是相邻的
def seq_data_iter_sequential(corpus,batch_size,num_steps):
offset=random.randint(0,num_steps)
num_tokens=((len(corpus)-offset-1)//batch_size)*batch_size
Xs=torch.tensor(corpus[offset:offset+num_tokens])
Ys=torch.tensor(corpus[offset+1:offset+num_tokens+1])
Xs,Ys=Xs.reshape(batch_size,-1),Ys.reshape(batch_size,-1)
num_batches=Xs.shape[1]//num_steps#获取一个batch里有几个minibatch
for i in range(0,num_steps*num_batches,num_steps):
X=Xs[:,i:i+num_steps]
Y=Ys[:,i:i+num_steps]
yield X,Y
for X,Y in seq_data_iter_sequential(my_seq,2,5):
print('X',X,'\n','y',Y)
class SeqDataLoader:#合并在一起
def __init__(self,batch_size,num_steps,use_random_iter,max_tokens):
if use_random_iter:
self.data_iter_fn=seq_data_iter_random
else:
self.data_iter_fn=seq_data_iter_sequential
self.corpus,self.vocab=test52text_process.load_crops_time_machine(max_tokens)
self.batch_size=batch_size
self.num_steps=num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus,self.batch_size,self.num_steps)
def load_data_time_machine(batch_size,num_steps,use_random_iter=False,max_tokens=10000):#定义函数,同时返回数据迭代器和词汇表
data_iter=SeqDataLoader(batch_size,num_steps,use_random_iter,max_tokens)
return data_iter,data_iter.vocab