TOFU-D与COD:两款Dialogflow聊天机器人数据集,为质量与安全研究赋能
论文信息
- 论文原标题:Assessing Task-based Chatbots: Snapshot and Curated Datasets for Dialogflow
- 主要作者及机构:Elena Masserini、Daniela Micucci、Diego Clerissi、Leonardo Mariani(意大利米兰比可卡大学)
- 引文格式(GB/T 7714):MASSERINI E, MICUCCI D, CLERISSI D, et al. Assessing task-based chatbots: snapshot and curated datasets for DialogflowC//23rd International Conference on Mining Software Repositories (MSR '26). Rio de Janeiro: ACM, 2026.
一段话总结
该研究针对任务型聊天机器人研究缺乏大规模高质量数据集的问题,提出了TOFU-D 和COD 两个基于Dialogflow平台的聊天机器人数据集,其中TOFU-D 是包含1,788个 来自GitHub的Dialogflow聊天机器人快照,COD 是从中筛选出的185个 经过验证的高质量子集;研究通过自动化方法完成数据集构建,借助Botium测试框架 和Bandit静态分析工具开展初步验证,发现聊天机器人存在测试覆盖不足、安全漏洞频发等问题,这两个数据集覆盖多领域、多语言和多开发模式,为任务型聊天机器人的质量与安全研究提供了可靠基准。
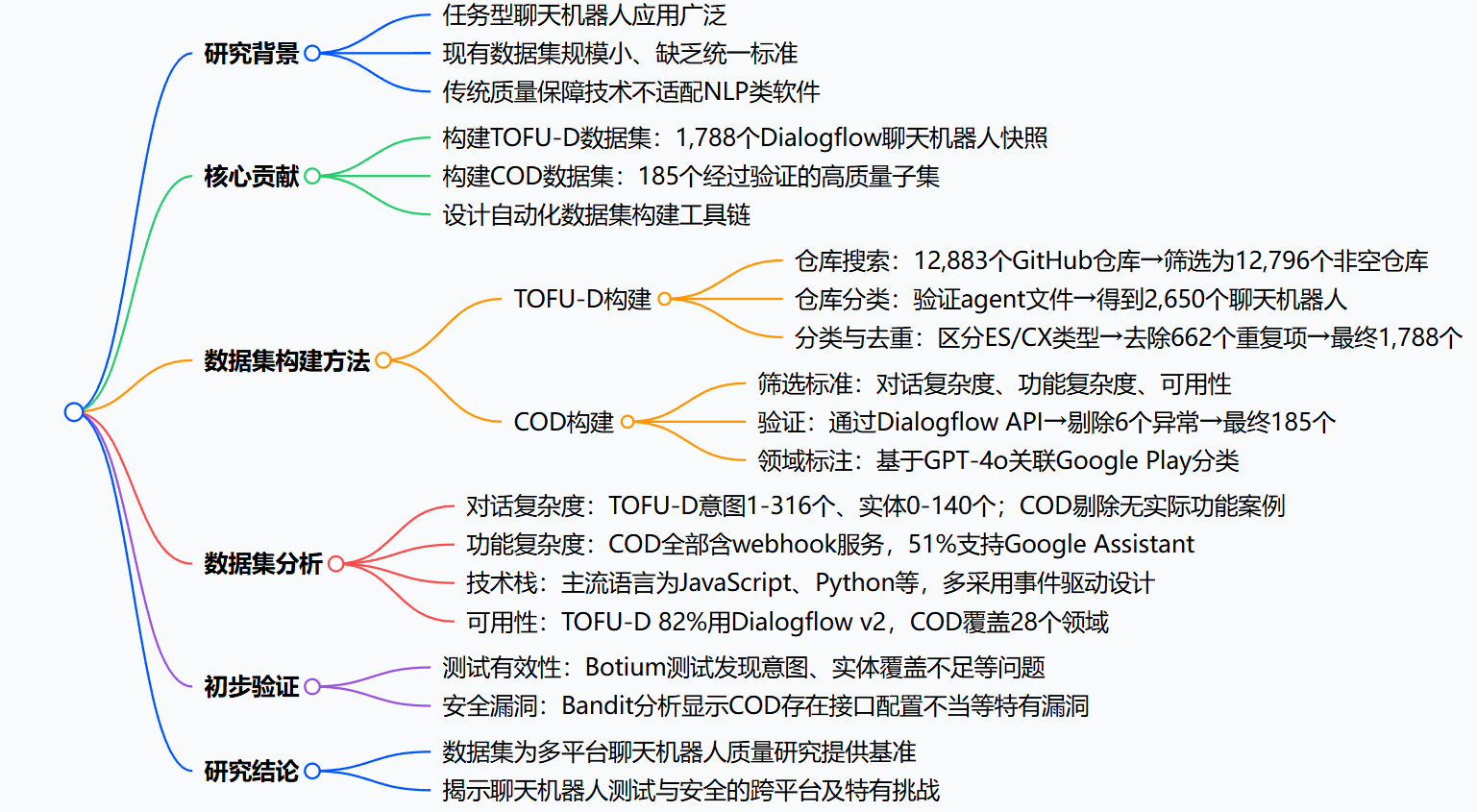
研究背景
如今,任务型聊天机器人早就渗透到医疗问诊、机票预订、个人助手等多个领域。它们和ChatGPT这类通用聊天机器人不同,专攻特定领域的具体任务,是企业里的"实干派"。
但在聊天机器人的质量和安全研究领域,一直存在一个老大难问题------缺乏大规模、高质量的标准数据集。以往的研究要么只用寥寥几个简单的聊天机器人做实验,要么选的样本没有统一标准,甚至很多都已经过时。
比如之前的ASYMOB数据集,样本是"野生"收集的,没有筛选规则;而TOFU-R和BRASATO数据集,又只覆盖了Rasa这一个开源平台。这就导致研究结果的通用性大打折扣,没法反映商业平台聊天机器人的真实情况。
简单来说,研究人员就像厨师做菜,手里只有几样不新鲜的食材,自然炒不出一桌能代表行业水平的"大餐"。
2. 思维导图
详细总结
该研究聚焦任务型聊天机器人质量与安全研究的数据集缺口,围绕Dialogflow平台构建并分析了两个专用数据集,具体内容如下:
-
研究背景与动机
- 任务型聊天机器人在医疗、预订等领域应用广泛,与通用聊天机器人不同,它可完成特定领域任务,主流开发平台包括Dialogflow、Amazon Lex、Rasa等。
- 现有研究存在实证样本规模小、选择无标准的问题,且已有的数据集多基于单一开源平台(如Rasa),缺乏商业平台的覆盖,限制了研究的通用性。
- 传统质量保障技术难以适配NLP类软件,需要专用数据集支撑相关研究。
-
数据集构建方法
数据集 构建步骤 关键操作 关键数字 TOFU-D 仓库搜索 基于GitHub API检索含"Dialogflow""chatbot"等关键词的仓库 初始12,883个仓库→剔除87个空仓库→12,796个非空仓库 仓库分类 验证仓库中是否存在Dialogflow必需的agent文件 剔除11,086个无效仓库→得到2,650个聊天机器人 分类与去重 区分ES(免费版)和CX(企业版)类型,剔除结构异常的55个聊天机器人;通过代码相似度(≤95%)去重 剔除662个重复项→最终1,788个唯一聊天机器人 COD 筛选 依据3个标准:最小对话复杂度(至少1个意图+1个实体)、功能复杂度(含webhook服务)、可用性(支持英语+Dialogflow v2+星标仓库) 1,788个→筛选为191个候选 验证 通过Dialogflow REST API验证部署可行性 剔除6个实体配置异常的聊天机器人→最终185个 领域标注 基于GPT-4o,结合仓库信息将聊天机器人关联到Google Play分类 覆盖28个不同领域 -
数据集特征分析
- 对话复杂度:TOFU-D的意图数量范围为1-316个,实体数量范围为0-140个,其中15%的聊天机器人无实际信息处理能力;COD剔除了这类无功能案例,仅保留具备实际服务能力的聊天机器人。
- 功能复杂度:COD中所有聊天机器人均含webhook服务,62%的聊天机器人超半数意图依赖webhook实现;51%的COD聊天机器人支持Google Assistant,29%实现了云函数,远高于TOFU-D的平均水平(32%、16%)。
- 技术栈分布:Dialogflow聊天机器人开发语言多样,主流为JavaScript、Python、Java、TypeScript,其中JavaScript因平台原生支持占比最高;这与Rasa聊天机器人全部基于Python的特点形成对比。
- 可用性特征:TOFU-D中82%的聊天机器人采用Dialogflow v2版本,1,557个支持英语,159个支持多语言(最多达12种);COD的仓库星标数范围为1-289,覆盖领域以教育(18%)、商业(13%)、医疗(11%)为主。
-
初步验证实验
- 测试有效性验证:使用Botium框架对COD中10个随机聊天机器人测试,发现100%存在回退行为意图测试缺失,30%存在问候意图、前置条件依赖意图测试缺失,30%存在实体完全未覆盖,70%存在实体部分覆盖,10%存在测试用例失效问题。
- 安全漏洞验证:使用Bandit工具分析COD中69个含Python代码的聊天机器人,并与BRASATO数据集(193个Rasa聊天机器人)对比,发现两者存在共性漏洞(如请求无超时、伪随机数生成器不安全),同时COD存在特有漏洞(如41%的聊天机器人存在全接口绑定问题,32%存在任意代码执行风险)。
-
研究结论
- TOFU-D和COD数据集填补了商业平台任务型聊天机器人数据集的空白,提升了研究的通用性和异质性。
- 初步验证揭示了任务型聊天机器人在测试覆盖和安全防护方面的共性与特有问题,证明多平台研究的必要性。
4. 关键问题
-
侧重数据集价值 :TOFU-D和COD两个数据集相较于现有聊天机器人数据集,核心优势是什么?
答案:一是平台多样性 ,现有数据集多基于开源平台Rasa,这两个数据集聚焦商业平台Dialogflow,弥补了商业平台研究样本的缺口;二是质量与规模平衡 ,TOFU-D包含1,788个聊天机器人快照,覆盖真实开发场景,COD筛选出185个高质量验证样本,可支撑大规模实证研究;三是技术栈异质性,Dialogflow聊天机器人采用多语言开发,不同于Rasa的单一Python技术栈,能更好地反映实际开发的技术多样性。
-
侧重构建方法 :研究在构建COD数据集时,采用了哪些筛选标准,这些标准的制定依据是什么?
答案:筛选标准包括三个方面,分别是最小对话复杂度 (至少1个意图+1个实体)、功能复杂度 (必须包含webhook服务)、可用性(支持英语、基于Dialogflow v2版本、存储在星标仓库)。制定依据是为了确保数据集样本具备研究价值,最小对话复杂度可剔除无实际交互能力的玩具示例,功能复杂度可保证样本包含后端逻辑,可用性标准则能提升数据集的通用性和时效性,便于不同研究团队复现实验。
-
侧重实践意义 :通过对COD数据集的初步验证,研究发现了任务型聊天机器人在质量保障方面的哪些核心问题?
答案:一是测试覆盖不足 ,自动测试工具难以覆盖回退行为、依赖前置交互的意图,同时存在实体覆盖不全、测试用例失效等问题;二是安全漏洞突出 ,存在共性漏洞(如外部API请求无超时、伪随机数生成器不安全)和特有漏洞(如全接口绑定、任意代码执行风险);三是跨平台挑战显著,无论是测试还是安全问题,都存在通用共性问题和平台特有问题,证明任务型聊天机器人的质量保障需要采用多平台视角。
创新点
- 填补商业平台数据集空白:首次针对谷歌商业平台Dialogflow,构建了大规模快照数据集TOFU-D和高质量精选数据集COD,弥补了以往研究集中于开源平台的缺陷。
- 自动化+高可复用的构建流程:设计了一套全自动化的数据集构建工具链,从GitHub仓库搜索、分类到去重、验证,步骤清晰且可复现,还能适配其他任务型聊天机器人框架的数据集构建。
- 兼顾规模与质量的双重属性:TOFU-D追求广度,囊括1788个真实的Dialogflow聊天机器人;COD追求精度,筛选出185个具备实际功能的高质量样本,满足不同研究场景的需求。
研究方法和思路
整个研究围绕**"构建数据集---分析数据集---验证数据集价值"**三步展开,具体拆解如下:
一、 TOFU-D数据集构建:从GitHub"大海捞针"
- 仓库搜索:用GitHub API检索名称、说明里包含"Dialogflow"和"chatbot/agent"的仓库,初筛出12883个仓库,剔除87个空仓库后剩12796个。
- 仓库分类:下载仓库并检查是否有Dialogflow必备的agent配置文件,剔除11086个无效仓库,得到2650个包含聊天机器人的仓库。
- 分类与分析:区分免费版(ES)和企业版(CX)聊天机器人,剔除55个结构错误的样本;再提取聊天机器人的意图、实体、支持语言等信息,剔除51个实现异常的样本。
- 去重处理:用代码相似度(低于95%才算不同)判断重复样本,优先保留新版本、高星标的聊天机器人,最终得到1788个唯一样本。
二、 COD数据集构建:从"海量"到"精选"
- 筛选:设定3个硬标准------至少1个意图+1个实体、包含webhook后端服务、支持英语+基于Dialogflow v2+存储在星标仓库,从TOFU-D中筛选出191个候选。
- 验证:通过Dialogflow REST API测试部署可行性,剔除6个实体配置异常的样本,最终得到185个高质量样本。
- 领域标注:用GPT-4o结合仓库信息,将COD样本关联到Google Play分类,覆盖28个领域,确保样本多样性。
三、 数据集验证:测试+安全分析
- 测试有效性验证:用Botium框架测试COD中10个样本,检查测试覆盖情况。
- 安全漏洞验证:用Bandit工具分析COD中69个含Python代码的样本,并和Rasa平台的BRASATO数据集对比,找出共性和特有漏洞。
主要成果和贡献
一、 核心成果:两款高质量数据集
| 数据集 | 规模 | 特点 | 适用场景 |
|---|---|---|---|
| TOFU-D | 1788个 | 覆盖GitHub上Dialogflow聊天机器人全貌,包含玩具示例、实用工具等各类样本 | 大规模场景化研究,如行业现状分析 |
| COD | 185个 | 全功能、可部署、多领域,51%支持Google Assistant,29%实现云函数 | 质量保障、安全漏洞等精细化研究 |
| 开源地址:https://gitlab.com/securitychatbot/dialogflow-chatbot-dataset |
二、 关键发现:聊天机器人的"通病"与"特有病"
- 测试覆盖不足:100%的样本缺失回退行为意图测试,30%缺失问候意图测试,30%的实体完全未被覆盖。
- 安全漏洞突出 :
- 共性漏洞:外部API请求无超时、伪随机数生成器不安全、异常处理不当,这是所有平台聊天机器人的"通病"。
- 特有漏洞:41%的样本存在全接口绑定问题,32%存在任意代码执行风险,这是Dialogflow平台webhook架构的"特有病"。
三、 领域贡献
- 解决数据匮乏问题:为Dialogflow平台提供了首个大规模标准数据集,让研究不再依赖小样本。
- 推动多平台研究:填补了商业平台和开源平台研究的鸿沟,证明聊天机器人质量保障需要"跨平台视角"。
- 提供工具链支持:自动化构建流程可复现、可扩展,为其他聊天机器人框架的数据集构建提供参考。
总结
本文针对任务型聊天机器人研究缺乏大规模高质量数据集的痛点,构建了Dialogflow平台的TOFU-D快照数据集和COD精选数据集。研究通过自动化流程完成从GitHub仓库筛选到样本验证的全链路工作,并用测试和安全工具验证了数据集的价值。这两款数据集不仅填补了商业平台研究的空白,还揭示了聊天机器人在测试覆盖和安全防护方面的共性与特有问题,为后续质量保障研究提供了坚实的基准。