目录
[named_struct() 函数](#named_struct() 函数)
[collect_set() 函数](#collect_set() 函数)
一、什么是维度表?
维度表就是用来描述"谁、什么、何时、何地、如何"等业务实体信息的表。 它回答了业务分析中"基于什么来看数据"的问题。
-
核心作用 :提供业务分析的"视角"和"过滤器"。
-
特点:
-
文本描述为主:大多是名称、描述、分类、状态等文本信息。
-
属性变化慢 :品牌、品类不会天天变,所以也叫 "缓慢变化维度"。
-
表相对宽而短:字段(列)很多,用来描述一个实体的各个方面;但记录(行)相对较少(比如全公司就几百个商品、几十个门店)。
-
维度表的经典例子
-
商品维度表:就像开头的牛奶标签。包含商品ID、商品名称、品牌、分类、规格、供应商等。
-
时间维度表:这是最重要的维度之一。它不单是一个日期字段,而是把日期展开成:年、季度、月、周、日、是否节假日、财年周期等。有了它,你就能轻松地分析"今年第一季度对比去年第一季度"的销售情况。
-
顾客维度表:顾客ID、姓名、性别、年龄区间、会员等级、注册城市等。用来分析不同客户群体的行为。
-
门店/区域维度表:门店ID、门店名称、所在城市、所属大区、门店等级、店长等。用来分析地域表现。
-
员工维度表:员工ID、姓名、部门、职位、入职日期等。
它和"事实表"是什么关系?(关键!)
数据仓库里另一个核心是 事实表,它俩是"黄金搭档"。我们继续用超市的例子:
-
事实表 :像是一张超级详细的购物小票。
-
记录 "发生了什么事"。
-
包含:
销售时间2023-10-01 10:05,商品ID:M001,顾客ID:C1001,门店ID:S01,销售金额:5元,销售数量:1。 -
核心是 可度量的数字(金额、数量、次数等),这些数字就是"事实"。
-
但你看这张小票,全是ID和时间戳,根本看不懂!
-
-
维度表 :就是给这些ID和时间码提供解释说明的"翻译字典"或"标签册"。
-
当把小票(事实表)和标签册(维度表)关联起来时,枯燥的数据就变成了有业务意义的信息:
-
2023-10-01(关联时间维度)-> 国庆节 -
商品ID:M001(关联商品维度)-> 蒙牛全脂纯牛奶 250ml -
顾客ID:C1001(关联顾客维度)-> 张三, 金牌会员 -
门店ID:S01(关联门店维度)-> 北京海淀店
-
现在,你就能分析了: "国庆节当天,金牌会员张三在北京海淀店购买了一盒蒙牛牛奶,花了5块钱。"
更高维的分析:
-
"国庆期间,华北地区(门店维度)的金牌会员(顾客维度)在乳制品品类(商品维度)上的消费总额(事实)是多少?"
-
这个分析过程中的每一个筛选条件(华北、金牌会员、乳制品),都来自维度表的属性。
二、维度表的建表思路
第一步:定下要贴哪些"标签种类"(确定维度表)
-
核心任务 :列出分析时所有需要的分类角度,比如:时间、地点、商品、客户、渠道等。每一种角度就对应一张可能的维度表。
-
关键原则:
-
唯一性:同一种标签只做一张表。例如,"商品"标签表全校共用,不会给销售数据和库存数据各做一个。
-
退化简化:如果某种标签信息特别简单(比如只一个"交易状态":支付成功/失败),就没必要单独建表,直接把它当作事实记录里的一个字段即可。
-
第二步:找到标签的"原始资料库"(确定主维表和相关维表)
-
核心任务:去公司的业务系统(比如ERP、CRM)里,找到记录这些标签最详细、最核心的原始数据表。
-
如何找:
-
主维表 :是记录该维度最基础、最细粒度信息的核心表。例如,"商品"维度里,记录每个具体货品(SKU)的表就是主维表。
-
相关维表 :是存放与主维表信息相关的补充描述的表。例如,商品的品牌表、分类表就是相关维表。
-
-
粒度一致:最终做出来的维度表,其详细程度(粒度)要和主维表保持一致。
第三步:加工并填写"标签说明书"(确定维度属性)
-
核心任务:决定维度表里具体要放哪些描述性字段。这些字段就是未来用来筛选、分组数据的条件。
-
字段来源:
-
直接来自主维表和相关维表(如商品名称、品牌名、分类名)。
-
通过对原有字段加工得到(如从生日算出年龄,从日期算出星期、季度)。
-
-
核心要求:
-
越丰富越好:标签越详细,分析角度就越灵活。比如"客户"维度,除了姓名ID,还可以有年龄、性别、城市、会员等级等。
-
通俗易懂:尽量用"北京"、"华东区"这样的文字,而不是只用"BJ"、"001"这种编码。可以编码和文字同时存在。
-
提前加工,一劳永逸:把那些需要复杂计算或拼接才能得到的属性(比如"完整地址"由省市区街道拼接),提前算好并存入维度表。这样每次分析时直接调用即可,无需重复计算。
-
通俗比喻
想象你在整理一个全球销售记录本(事实表),每条记录只写了:"某时,某产品,卖了X元给某客户"。
为了让这本记录本变得有用,你需要做几本独立的 "标签手册"(维度表):
-
决定做哪些手册 :你需要一本产品手册 、一本客户手册 、一本时间手册。
-
收集原始资料:
-
做产品手册,就以公司的《产品详细清单》为蓝本,再去参考《品牌大全》和《产品分类指南》。
-
做客户手册,就以《客户信息登记表》为蓝本。
-
-
编写手册内容:
-
在产品手册里,不仅抄录产品ID和名称,还把品牌、分类、颜色、尺寸等都写进去,甚至把产品全称(品牌+系列+名称)这样的信息也提前拼写好。
-
在客户手册里,把客户的地址、等级、年龄段等都整理好。
-
在时间手册里,把日期对应的年、月、周、季度、节假日标志都标注清楚。
-
以后,当你分析销售记录时,就可以随时翻阅这些"标签手册",轻松地回答诸如 "华东区的VIP客户在第三季度购买了哪些高端品牌的产品?" 这类复杂问题了。这就是维度表设计的核心价值。
三、维度设计要点(采用星型模型)
核心概念:拆与合
-
规范化 (拆开) :就像管理一个公司,把员工信息、部门信息、工资单分别放在不同的Excel表里。好处是 数据整齐,修改一个地方,所有相关数据都自动更新(比如改部门名,只改一处)。缺点是查一个人的完整信息(带部门、工资)得同时打开三个表,对来对去,很麻烦。
-
反规范化 (合并) :就是把员工、他的部门、工资都写在同一张表里。好处是 查起来一目了然,速度飞快。缺点是数据有重复(比如同一个部门的所有员工,部门名都重复写),如果部门改名,需要改很多行。
对应到数据仓库模型
-
雪花模型:就是"规范化"的设计。一个商品维度表,可能只存"品牌ID",你需要再关联一张"品牌表"才能看到品牌名。表像雪花一样散开。
-
星型模型:就是"反规范化"的设计。商品维度表里直接把"品牌名"、"分类名"等都写进去,一张大宽表。所有维度表都直接围绕着事实表,像星星。
结论:为什么常用星型模型?
数据仓库的核心任务是快速查询和分析,而不是频繁地修改数据。
-
性能快:星型模型把所有需要的信息挤在一张表里,查询时几乎不用关联其他表,速度自然快。
-
简单易懂:业务人员或分析师很容易理解,他们就想看"某商品在某地区某时间的销售额",星型模型直接给结果,而雪花模型需要他们自己理解好几张表的关系。
-
优化方向 :虽然它会重复存储数据(占用更多空间),但在现代数据仓库中,存储成本通常远低于计算(查询)成本和时间成本。用空间换时间和易用性,是更划算的交易。
一句话记住:
做数据仓库设计维度表时,为了让人用着方便、让查询跑得快 ,我们通常选择反规范化 的星型模型,把数据冗余在一起。那种高度规范化的雪花模型,虽然理论完美,但在实际分析场景中并不讨好。
四、商品维度表建表及数据装载
1.这里先给出完整的建表SQL文,然后根据SQL文进行一步步解析
sql
DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(
`id` STRING COMMENT 'SKU_ID',
`price` DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'SPU编号',
`spu_name` STRING COMMENT 'SPU名称',
`category3_id` STRING COMMENT '三级品类ID',
`category3_name` STRING COMMENT '三级品类名称',
`category2_id` STRING COMMENT '二级品类id',
`category2_name` STRING COMMENT '二级品类名称',
`category1_id` STRING COMMENT '一级品类ID',
`category1_name` STRING COMMENT '一级品类名称',
`tm_id` STRING COMMENT '品牌ID',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,
value_id :STRING,
attr_name :STRING,
value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,
sale_attr_value_id :STRING,
sale_attr_name :STRING,
sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_sku_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');2.数据装载
sql
with
sku as
(
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
category3_id,
tm_id,
create_time
from ods_sku_info_full
where dt='2022-06-08'
),
spu as
(
select
id,
spu_name
from ods_spu_info_full
where dt='2022-06-08'
),
c3 as
(
select
id,
name,
category2_id
from ods_base_category3_full
where dt='2022-06-08'
),
c2 as
(
select
id,
name,
category1_id
from ods_base_category2_full
where dt='2022-06-08'
),
c1 as
(
select
id,
name
from ods_base_category1_full
where dt='2022-06-08'
),
tm as
(
select
id,
tm_name
from ods_base_trademark_full
where dt='2022-06-08'
),
attr as
(
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ods_sku_attr_value_full
where dt='2022-06-08'
group by sku_id
),
sale_attr as
(
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrs
from ods_sku_sale_attr_value_full
where dt='2022-06-08'
group by sku_id
)
insert overwrite table dim_sku_full partition(dt='2022-06-08')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;五、商品维度表建表解析
1.第一步因为是商品维度表,所有确定维度很简单就是关于商品的各种信息
2.确定商品的主维度表和相关维度表
首先就是将业务数据库中与商品相关的表找出来
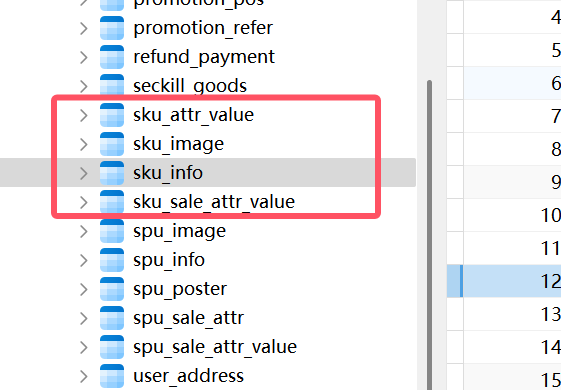
如图的4张表就是与商品(sku)相关的表,现在就是确定哪个是主维表
首先4张表分别记录了商品的平台属性、图片、详细信息、销售属性,因为我们分析的是商品维度,所以主维表就确定了为sku_info,其它的则为相关表
在确定字段前,我们要先了解什么是sku什么是spu
以一个简单的例子来说明,如果spu代表手机的一个类型,比如小米15,而sku就代表小米15下不同内存、颜色的商品
3.确定表的字段
要确定表的字段首先是要以主维表为基础,其它相关表为辅
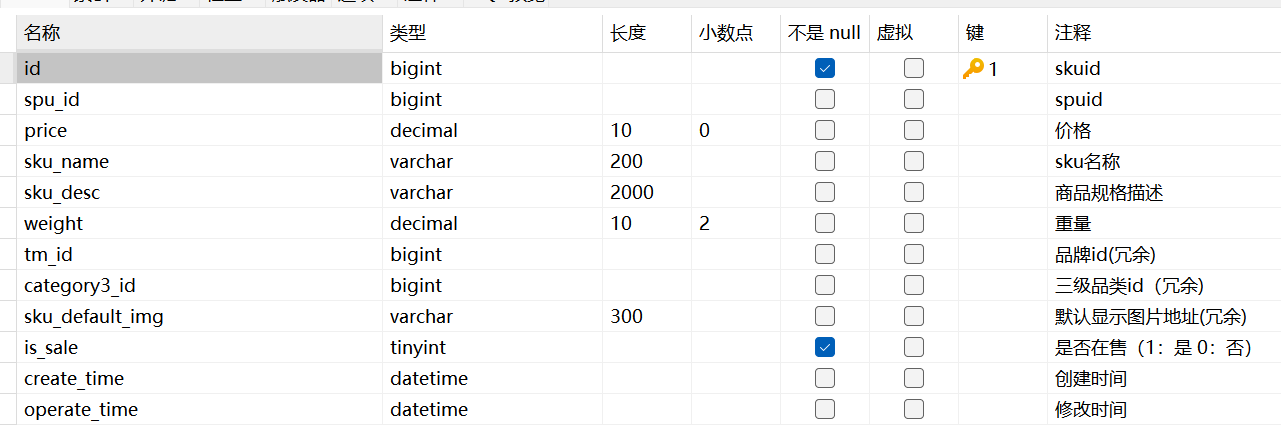
如图是主维表的字段及注释
首先商品id肯定是需要的,它用于区分不同的商品
然后是spu_id,它是指该商品所属的类别,它也可以作为分类标准,比如统计哪个类别卖的商品数量最多等等,但我们不能只要一个spu_id就行了,因为它只是一个编码,在后面分析的时候我们并不知道它具体代表什么,所以我们找到下面的spu_info表
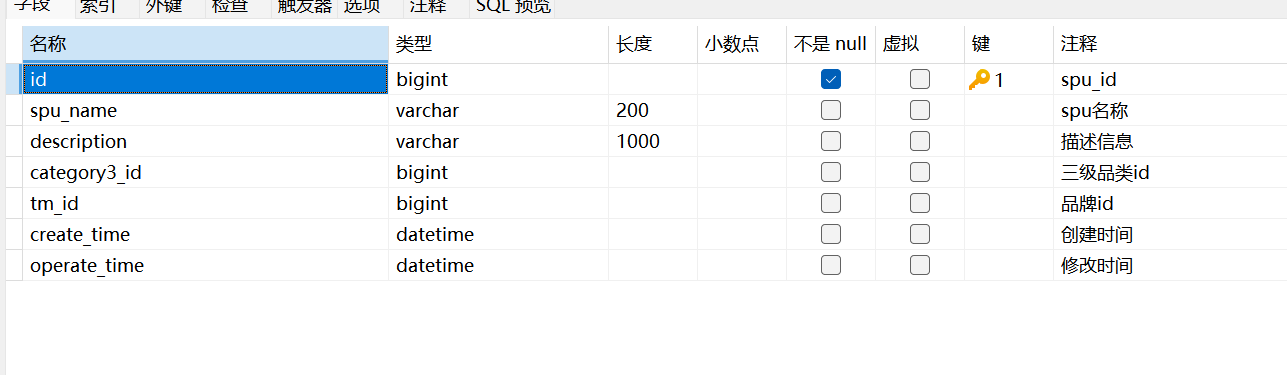
可以看到其中有一个spu_name字段记录了类别的具体名称所以我们也需要这个表spu_name字段,而且还需要这个表的id字段,这样才能与sku_info表的spu_id关联起来
然后我们返回继续看sku_info表下面的几个字段


这7个字段肯定是需要的,属于商品的基本信息
然后我们继续看下面的两个字段,是不是与spu_id类似,所以我们也要找到相关字段的具体名称
所以我们找到base_trademark表,表中就有tm_id的具体名称,所以我们需要这张表的id、tm_name字段,其它字段与商品无关所以不需要
接着我们找到的base_category3表,同理找到category3_id的具体名称,我们需要id、name字段

但是我们注意到这里有一个category2_id,那我们需要吗?
答案是需要,因为与商品有关,我们在分析数据的时候不仅要从三类品级分析排名等等,还要从二级、一级品级分类
所以我们找到base_category2、base_category1表,分别获取id、name、category1_id和id、name


然后哪些创建时间与修改时间就不需要了,对于商品分析没有用
最后一个字段图片地址我们需不需要?
答案是不需要,因为通过一个图片地址在电商分析中,并不能得到有价值的信息,同时很多商品图片都不是真实的,只是吸引眼球罢了。

最后根据上面的分析我们得到商品维度表的字段如下
sql
`id` STRING COMMENT 'SKU_ID',
`price` DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'SPU编号',
`spu_name` STRING COMMENT 'SPU名称',
`category3_id` STRING COMMENT '三级品类ID',
`category3_name` STRING COMMENT '三级品类名称',
`category2_id` STRING COMMENT '二级品类id',
`category2_name` STRING COMMENT '二级品类名称',
`category1_id` STRING COMMENT '一级品类ID',
`category1_name` STRING COMMENT '一级品类名称',
`tm_id` STRING COMMENT '品牌ID',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,
value_id :STRING,
attr_name :STRING,
value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,
sale_attr_value_id :STRING,
sale_attr_name :STRING,
sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'在这里需要注意平台属性和销售属性使用array加struct,因为一个商品可以有多个平台属性和商品属性。
六、商品维度表数据装载解析
1.首先是with as 语法(也称为公共表表达式,Common Table Expression,CTE)是一种临时命名结果集的方法,可以在查询中多次引用。
一、基本语法
sql
WITH
cte_name1 AS (
SELECT column1, column2 FROM table1 WHERE condition
),
cte_name2 AS (
SELECT column3, column4 FROM table2 WHERE condition
)
SELECT
a.*, b.*
FROM cte_name1 a
JOIN cte_name2 b ON a.id = b.id;二、主要作用
- 提高查询可读性
sql
-- 不使用CTE
SELECT * FROM (
SELECT user_id, SUM(amount) as total_amount
FROM orders
WHERE order_date >= '2024-01-01'
GROUP BY user_id
) t1 JOIN (
SELECT user_id, user_name FROM users
) t2 ON t1.user_id = t2.user_id;
-- 使用CTE(更清晰)
WITH
order_summary AS (
SELECT user_id, SUM(amount) as total_amount
FROM orders
WHERE order_date >= '2024-01-01'
GROUP BY user_id
),
user_info AS (
SELECT user_id, user_name FROM users
)
SELECT
o.total_amount,
u.user_name
FROM order_summary o
JOIN user_info u ON o.user_id = u.user_id;- 避免重复子查询
sql
-- 同一个子查询被多次使用
WITH product_stats AS (
SELECT
product_id,
AVG(price) as avg_price,
COUNT(*) as sales_count
FROM sales
GROUP BY product_id
)
SELECT
p1.product_id,
p1.avg_price,
p1.sales_count,
(SELECT COUNT(*) FROM product_stats p2
WHERE p2.avg_price > p1.avg_price) as higher_price_count
FROM product_stats p1;- 支持递归查询(Hive 3.0+)
sql
-- 层次结构数据查询
WITH RECURSIVE org_hierarchy AS (
-- 初始查询(根节点)
SELECT employee_id, manager_id, employee_name, 1 as level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 递归查询
SELECT e.employee_id, e.manager_id, e.employee_name, oh.level + 1
FROM employees e
JOIN org_hierarchy oh ON e.manager_id = oh.employee_id
)
SELECT * FROM org_hierarchy;2.怎样构建array嵌套struct
sql
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrsnamed_struct() 函数
-
作用:创建一个结构体(struct),给每个字段指定名称和值
-
语法 :
named_struct('field_name1', value1, 'field_name2', value2, ...) -
返回值:一个结构体对象
collect_set() 函数
-
作用 :将多个值收集到一个集合(Set)中,并自动去重
-
与
collect_list()的区别:-
collect_set():去重,无序 -
collect_list():保留重复,保持顺序
-
-
返回值:一个数组(Array)
-
与它相似的还有一个collect_list()函数------不去重返回一个数组
3.插入数据时为什么采用覆盖(overwrite)而不是into直接插入
sql
insert overwrite table dim_sku_full partition(dt='2022-06-08')因为在后续像这种批量插入数据的过程肯定要封装为一个脚本(因为实际业务中需要每天将前一天的数据在凌晨进行装载分析,不可能天天一个个执行每个表的数据装载),在脚本中万一有一个sql因为网络或资源的问题不能正确执行时,应该使整个脚本有重复执行的能力,如果用into可能会导致数据重复插入。
4.为什么表采用左连接
sql
left join spu on sku.spu_id=spu.id因为这些相关表,在数据传输中可能会丢失。如果用其它的连接方式不能避免这种情况,最终导致SQL执行失败。