1. 核心动机:为什么要引入"门"?
标准 RNN(Recurrent Neural Network)存在一个致命缺陷:无法捕捉长距离依赖(Long-term Dependencies)。
-
梯度消失/爆炸: 在反向传播中,梯度需要连乘经过每一个时间步。如果序列过长,梯度会呈指数级衰减(消失)或增加(爆炸),导致网络"忘记"了早期的信息。
-
记忆不可控: 标准 RNN 对每个输入都无差别地进行处理,没有机制来决定"保留什么"或"遗忘什么"。
GRU 通过引入门控机制来解决这个问题。它赋予了网络两种能力:
-
选择性关注: 决定当前的输入有多重要。
-
选择性遗忘: 决定之前的记忆应当保留多少。
2. 宏观结构:两个"门"
GRU 的核心在于它有两个门,它们都是神经网络层(全连接层 + Sigmoid激活函数),输出值都在 0,1之间。
-
重置门 (Reset Gate ):
-
直觉: "我应该在多大程度上忽略过去的知识?"
-
作用: 专门用于计算候选隐状态。如果趋近于 0,说明之前的记忆对于当前预测没有帮助,应该被重置(相当于从当前词重新开始阅读)。
-
-
更新门 (Update Gate ):
-
直觉: "我应该保留多少旧记忆,又应该写入多少新记忆?"
-
作用: 控制最终隐状态的更新。它决定了信息是直接从上一步"复制"过来,还是用新的计算结果覆盖。这是解决梯度消失的关键。
-
3. 数学推导与微观实现
假设当前时间步的输入为 xt,上一时间步的隐藏状态为Ht-1,隐藏单元数 h
第一步:计算门控信号
重置门 Rt和更新门 Zt的计算方式完全相同,只是权重不同。它们都使用 Sigmoid 函数,将值映射到 0,1区间。
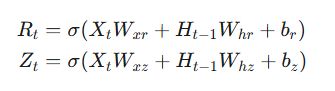
- 当门的值接近 1 时,表示"通过/保留";接近 0 时,表示"阻断/忽略"。
第二步:计算候选隐状态 (Candidate Hidden State)
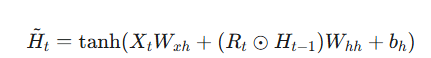
第三步:计算最终隐状态 (Final Hidden State)
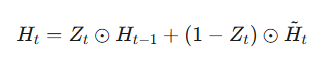
4. 物理意义图解
我们可以把 GRU 想象成一个水流控制系统:
-
输入与上一步状态进入。
-
Reset Gate (阀门1) 决定:在混合新旧水流之前,要先倒掉多少脏水(旧状态)。
- 场景举例: 正在阅读一篇影评。前一段是在讲剧情,后一段开始讲特效。当遇到"剧情讲完了"这个信号时,重置门关闭,不再让剧情的记忆干扰特效的评价。
-
计算候选水流(新的混合物)。
-
Update Gate (阀门2) 决定:最终输出的水流中,含有多少纯净的老水(直接旁路过来),含有多少新混合的水。
- 场景举例: 句子中出现了"The cat...",后面跟了很多定语从句,最后是谓语 "...sat"。在处理中间定语时,更新门可能一直保持为 1(保留记忆),直到遇到 "sat",将 "cat" 的主语信息传递给它。
5. GRU 与 LSTM 的对比
虽然 LSTM (Long Short-Term Memory) 和 GRU 都能解决长距离依赖问题,但它们有以下区别:
|-----------|----------------------------|-------------------------------|
| 特性 | GRU (Gated Recurrent Unit) | LSTM (Long Short-Term Memory) |
| 结构复杂度 | 简单,只有 2 个门 | 复杂,有 3 个门 (遗忘、输入、输出) |
| 状态变量 | 只有隐状态 | 分离了 记忆元 和 隐状态 |
| 参数量 | 较少 (训练速度稍快) | 较多 |
| 表现 | 在小数据集上表现往往更好 | 在大数据集和极长序列上可能略强 |
| 核心差异 | 将"遗忘"和"输入"耦合在一个更新门 中 | 遗忘门和输入门是独立的 |
6. 总结
GRU 是对标准 RNN 的一种优雅的修正。它不需要额外的记忆单元(Cell State),完全依靠门控机制在隐藏状态(Hidden State)内部调节信息流。