【计算】Ray框架介绍,AI基础设施之"通用"分布式计算(跨场景,门槛低,大规模生产,单机->集群->推理一站式)
文章目录
-
- 1、分布式计算框架的演进
-
- [1.1 分布式计算框架演进时间线(理论->批处理/磁盘->内存->流处理->AI/云原生)](#1.1 分布式计算框架演进时间线(理论->批处理/磁盘->内存->流处理->AI/云原生))
- [1.2 演进背后的驱动因素(硬件迭代,业务变化)](#1.2 演进背后的驱动因素(硬件迭代,业务变化))
- [1.3 分布式计算框架共同特征(现代,未来)](#1.3 分布式计算框架共同特征(现代,未来))
- 2、Ray与AI生态
-
- [2.1 "通用" 分布式(支持跨场景复用)](#2.1 “通用” 分布式(支持跨场景复用))
- [2.2 研发体验,AI分布式基础设施标准化(门槛低)](#2.2 研发体验,AI分布式基础设施标准化(门槛低))
- [2.3 融合计算、AI生态化(大规模生产使用)](#2.3 融合计算、AI生态化(大规模生产使用))
- 3、Ray用法介绍
-
- [3.1 Ray 基础示例(单机,并行,调参,训练,数据处理)](#3.1 Ray 基础示例(单机,并行,调参,训练,数据处理))
- [3.2 Ray实现对比原生torch(数据并行,模型并行,自由组合)](#3.2 Ray实现对比原生torch(数据并行,模型并行,自由组合))
- [3.3 Ray 框架全流程使用方式(单机->集群->推理)](#3.3 Ray 框架全流程使用方式(单机->集群->推理))
1、分布式计算框架的演进
分布式计算框架是一种软件工具,旨在通过将大型计算任务分解为多个子任务,并调度多台计算机节点(集群)协同并行处理,以解决单机无法承载的大规模数据处理和高并发任务。它通过网络连接节点、资源管理、任务调度和通信机制,实现了资源共享、高扩展性和高可靠性。
核心要素与特性
- 并行处理与数据拆分:将海量数据拆分成小块,在多台机器上同时计算。
- 高扩展性与灵活性:可根据任务量需求动态增加或减少计算节点。
- 容错能力:当部分节点发生故障时,框架能自动重试或将任务分配给其他节点,保证任务完成。
- 移动数据而非计算:通常遵循"计算向数据靠拢"原则,在数据存储节点本地执行计算,减少网络开销。
1.1 分布式计算框架演进时间线(理论->批处理/磁盘->内存->流处理->AI/云原生)
txt
┌─────────────────────────────────────────────────────────────────────┐
│ 2000之前:理论奠基期 │
│ • 分布式系统理论 (Lamport, Chandy-Lamport) │
│ • MPI标准 (1994) - 高性能计算 │
│ • CORBA, RPC - 远程调用基础 │
│ │
│ 2003-2006:第一代:批处理时代 │
│ • Google MapReduce论文 (2004) │
│ • Hadoop实现 (2006) │
│ • 核心思想:分而治之,磁盘计算 │
│ │
│ 2009-2013:第二代:内存计算时代 │
│ • Spark (2009) - RDD,内存计算 │
│ • Storm (2011) - 流处理 │
│ • 核心突破:减少磁盘IO,提高性能 │
│ │
│ 2014-2017:第三代:流批一体时代 │
│ • Flink (2014) - 真正的流处理,流批一体 │
│ • Beam (2016) - 统一编程模型 │
│ • 核心思想:实时性,统一API │
│ │
│ 2017-2020:第四代:AI/ML驱动时代 │
│ • Ray (2017) - AI原生,统一训练/服务 │
│ • Horovod (2017) - 分布式深度学习 │
│ • 核心特征:支持AI/ML特殊需求 │
│ │
│ 2020至今:第五代:云原生时代 │
│ • Dask (更成熟) - Python原生分布式 │
│ • Materialize (2020) - 流式数据库 │
│ • Arroyo (2022) - Rust实现的高性能流引擎 │
│ • 核心趋势:云原生,Serverless,硬件加速 │
└─────────────────────────────────────────────────────────────────────┘1.2 演进背后的驱动因素(硬件迭代,业务变化)
1、硬件演进如何驱动框架演进
txt
hardware_evolution = {
"2000年代": {
"CPU": "单核 → 多核",
"内存": "昂贵,GB级",
"磁盘": "机械硬盘,慢但便宜",
"网络": "千兆以太网",
"影响框架": "MapReduce面向磁盘,避免内存使用"
},
"2010年代": {
"CPU": "多核普及",
"内存": "价格下降,TB级可行",
"磁盘": "SSD开始普及",
"网络": "万兆以太网",
"GPU": "开始用于计算",
"影响框架": "Spark内存计算,Flink低延迟"
},
"2020年代": {
"CPU": "异构计算(CPU+GPU+TPU)",
"内存": "非易失内存,TB级常见",
"存储": "NVMe SSD,超低延迟",
"网络": "RDMA,超低延迟高吞吐",
"影响框架": "Ray细粒度调度,硬件感知"
}
}2、业务需求如何塑造框架
txt
application_demand_evolution = {
"早期(2000s)": {
"主要需求": "批量数据处理(ETL,报表)",
"特点": "T+1处理,准确性最重要",
"典型应用": "搜索引擎索引,日志分析",
"对应框架": "MapReduce"
},
"中期(2010s)": {
"主要需求": "实时分析 + 交互查询",
"特点": "秒级响应,准实时",
"典型应用": "推荐系统,实时监控",
"对应框架": "Spark,Storm"
},
"近期(2010s末)": {
"主要需求": "AI/ML全流程",
"特点": "从训练到服务的全链路",
"典型应用": "智能客服,自动驾驶",
"对应框架": "Ray,Flink ML"
},
"当前(2020s)": {
"主要需求": "实时决策 + 个性化",
"特点": "毫秒级响应,个性化",
"典型应用": "实时风控,个性化推荐",
"对应框架": "Materialize,Flink CEP"
}
}1.3 分布式计算框架共同特征(现代,未来)
1、现代优秀框架的共同特征
txt
modern_framework_features = {
"云原生": {
"容器化部署": "Docker/Kubernetes原生支持",
"声明式API": "YAML/JSON定义,系统自动维护",
"弹性伸缩": "根据负载自动调整资源",
"多租户安全": "RBAC,网络策略,资源隔离"
},
"性能优化": {
"向量化执行": "SIMD指令优化",
"列式存储": "更好的压缩,更快的分析",
"编译执行": "JIT编译查询计划",
"硬件加速": "GPU,TPU,FPGA支持"
},
"开发者体验": {
"统一API": "流批统一,多语言支持",
"交互式开发": "Notebook集成,实时反馈",
"可观察性": "完整Metrics,Tracing,Logging",
"生态集成": "与主流工具链无缝集成"
},
"智能化": {
"自动优化": "基于成本的优化器",
"自适应执行": "运行时动态调整",
"预测性伸缩": "基于历史预测资源需求",
"自治运维": "自动故障诊断和修复"
}
}2、分布式计算框架的未来方向
txt
future_trends = {
"更深入AI集成": {
"预测": "框架内置AI优化,自动模型选择",
"示例": "自动选择最优算法,自动特征工程"
},
"完全Serverless": {
"预测": "用户完全不用关心基础设施",
"示例": "按查询付费,无限弹性伸缩"
},
"边缘计算融合": {
"预测": "云边端协同计算框架",
"示例": "边缘设备预处理,云端聚合分析"
},
"量子计算准备": {
"预测": "经典-量子混合计算框架",
"示例": "量子算法作为特殊算子集成"
},
"隐私计算": {
"预测": "数据不出域的联合计算",
"示例": "多方安全计算,联邦学习原生支持"
},
"可持续发展": {
"预测": "能耗感知的调度算法",
"示例": "优先使用绿色能源节点"
}
}参考资料:1
2、Ray与AI生态
- Ray 是一个通用的分布式计算引擎,2016年开源于加州大学伯克利分校 RISELab。RISELab是大数据和AI领域顶尖的实验室,另外几个出自这个实验室的知名项目有Spark、Alluxio和最近炙手可热的vLLM等。Ray 的初创团队于2019年成立了一家公司 Anyscale,目前主要围绕Ray 做 AI Infra 平台和开源社区的运营。
- 2023年初,随着大模型的爆发,OpenAI曾揭露其 GPT-4系列模型基于 Ray 进行分布式训练,Ray随即得到业内广泛关注。在国内,蚂蚁公司早于2017年就开始与RISELab进行合作,将 Ray广泛应用于生产环境,并于2023年达到100W核心的生产规模。近年来 Ray 在国内应用越来越广泛,字节、华为、小红书、B站、滴滴等公司纷纷投入其中。
2.1 "通用" 分布式(支持跨场景复用)
Ray和其他分布式框架的区别
-
Ray 的通用性,不是靠 "堆功能",而是靠底层设计解决了分布式系统的本质问题,提供了一组最小、通用、可组合的分布式原语。
-
Ray 的 "通用分布式" 能力来源于 Ray 独特的计算引擎抽象。计算引擎的抽象往往反映在其 API 的设计上。
-
Ray Core既没有围绕数据进行抽象 (对比 Spark 的 RDD ),也没有围绕模型进行抽象 (对比 Pytorch 的 Tensor ),而是从最基本的面向对象编程语言进行抽象和设计。
-
绝大多数分布式框架都是面向特定场景设计 DSL 或 API,比如 Spark 面向批处理、MPI 面向 HPC 科学计算、TensorFlow Distributed 面向深度学习训练。它们的 API 和执行模型都是为单一任务优化,很难跨场景复用。
-
Ray 只抽象出两个核心原语 ,并且完全兼容原生 Python:
Remote Task(远程任务) :无状态函数,分布式异步执行 ,自动调度、负载均衡、容错。用来做:数据处理、批量推理、超参搜索、数据预处理等无状态工作。
Remote Actor(远程演员) :有状态的分布式对象 ,支持状态持久化、并发调用、消息通信。用来做:模型副本、参数服务器、推理服务实例、模拟器、多智能体、在线服务等有状态服务。
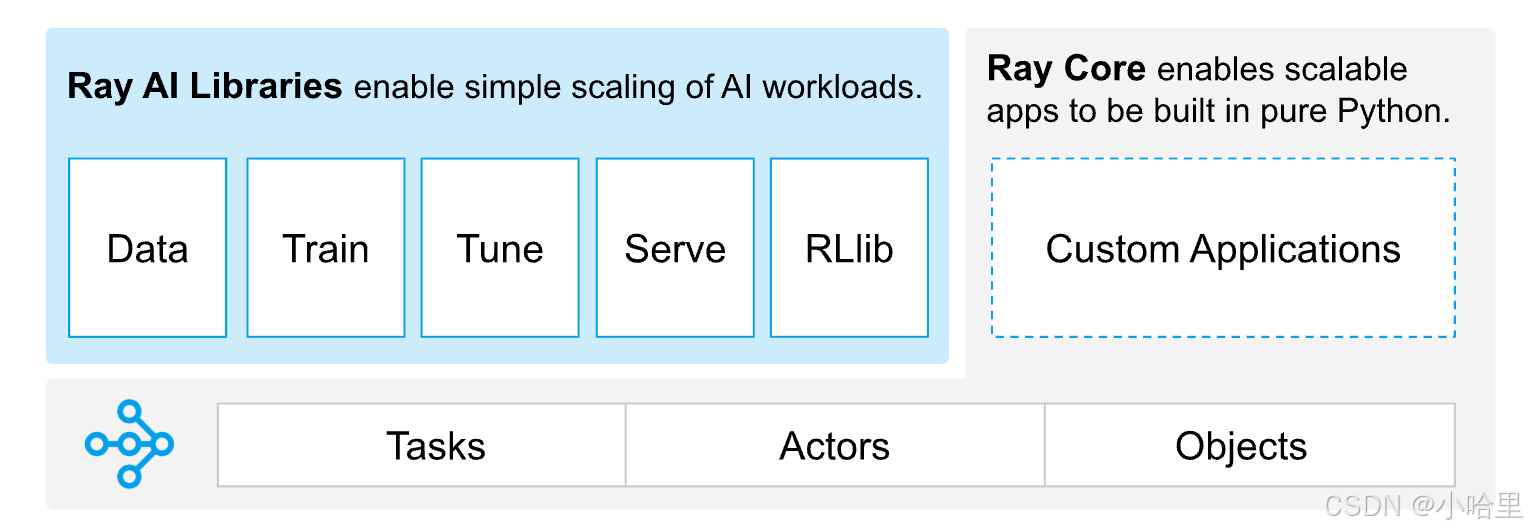
-
这两个原语是图灵完备的组合 :
无状态任务可以构建任何批处理、数据并行工作流;
有状态 Actor 可以构建参数服务、在线服务、状态机、强化学习环境;
两者混合,就能覆盖从离线训练到在线推理、从数据 ETL 到服务部署的全流程。
所以用ray的好处
-
开发者不需要为 "训练" 学一套 API、为 "推理" 再学一套、为 "数据处理" 再学一套,同一套 Python 语法,注解式改造,就能适配所有分布式场景。这是通用性的核心基础。
-
在 Ray 出现之前,AI 工程面临严重的碎片化问题 :
数据处理用 Spark;
训练用 PyTorch DDP / Horovod;
超参搜索自己写分布式脚本;
推理部署用 Flask/Tornado + K8s;
强化学习自己封装分布式环境。
每一层都要适配不同的分布式系统、不同的编程模型、不同的部署方式,链路长、运维复杂、迁移成本极高。 -
Ray 从底层设计就支持:
Task 无状态,失败自动重试;
Actor 有状态,支持状态快照、恢复、迁移;
集群支持动态扩缩容,节点上下线不中断业务;
同一套容错机制,同时适用于离线批处理、训练、超参搜索、在线服务。
-
这种设计让 Ray 既能用于科研实验(不稳定小集群),也能用于生产环境(高可用服务),通用性进一步放大。
-
Ray 第一次实现了:
统一编程模型:原生 Python,一套抽象适配全场景 ;
全链路一体化:数据、训练、调优、推理、强化学习在同一分布式 runtime 上运行 ;
从原型到生产无缝迁移:笔记本代码,不加修改或极少修改,直接扩到大规模 GPU 集群。 -
它解决的是 AI 分布式基础设施标准化的问题,让分布式不再是深度学习专家、大数据专家的专属能力,普通算法工程师也能规模化使用分布式资源。从整个 AI 工程演进来看,这是里程碑级的进步。
客观看待:ray不是 "万能",也不是 "不可替代"
- 极致性能的超大规模 HPC 训练,MPI + 专用集合通信依然有优势;
纯离线数仓、SQL 分析场景,Spark 生态更成熟、工具链更完善;
纯微服务、无状态 API 服务,K8s 生态更专业。 - Ray 的核心价值是AI 全链路的通用性,而不是在所有单一领域碾压所有专用框架。它的强大在于 "通吃",而不是 "单项第一"。
为什么其他框架做不到?(spark对比)
- 不是技术上 "绝对做不到",而是设计目标和演进路径决定了它们无法走向通用:
- 大部分框架诞生时,就是为了解决某一个痛点 (批处理、训练、服务编排),底层架构和 API 都做了场景绑定,后期很难重构为通用内核。
- 例如spark,极致成熟的 SQL & 数仓生态,是企业大数据的事实标准 ,Spark 从诞生起就是为海量离线批处理、数据仓库、ETL、SQL 分析设计的,经过十几年迭代,已经形成完整的企业级数据生态,这是 Ray 完全无法比拟的。
- Ray 虽然有 Ray Data 可以做批处理,也能对接数据湖,但Ray 没有成熟的 SQL 优化器、没有成熟的数仓建模能力、没有完善的数据治理体系 。Ray Data 定位是 "AI 场景下的数据预处理",而不是 "通用企业数仓引擎"。在 PB 级离线数仓、常规报表、批量 ETL 场景,Spark 依然是首选。
- Spark 针对长时、大吞吐、高容错的批处理作业做了极致工程化优化。
- Spark 擅长的是 "把数据洗好、算好、存好",是数据层的基础设施。
- Ray 擅长的是 "把数据变成模型,再把模型服务化",是 AI 层的基础设施。
2.2 研发体验,AI分布式基础设施标准化(门槛低)
为什么Ray会火起来?
- 优秀的研发体验(或者说"易用性")是Ray能吸引大量国内外开发者来使用的重要原因。在 AI领域,基础设施的易用性对于 M L工程师或算法工程师来说显得尤为重要,特别是在大模型时代,一个能够屏蔽底层复杂性、帮助用户快速开发和验证算法或模型的框架会受到追捧。
- 基于 Task 和 Actor 的设计,Ray 可以在不改变用户单机编程习惯的前提下,无缝地扩展面向对象编程语言的能力 ,不同于Spark需适配专属数据结构、MPI需手动编写并行逻辑,Ray仅靠
@ray.remote轻量装饰器,就能将普通Python函数、类转化为分布式任务与有状态实例。无需重构代码、学习新API,完美兼容单机编程习惯,实现"单机编码、分布式运行",大幅降低分布式开发门槛。 - "Ray Cluster is all your need",如果你已经拥有了一个 Ray集群,你可以通过编写很少的 Python 代码实现复杂的分布式应用,并且可以非常容易地从本地研发切换到集群化运行。
2.3 融合计算、AI生态化(大规模生产使用)
计算范式与融合计算
-
计算范式:你可以理解为「不同场景下的计算套路」,每种计算范式都是为解决一类特定问题设计的固定计算逻辑、执行模式。
-
批处理:一次性处理海量静态数据 (如 Spark 洗数、Ray Data 预处理),适合离线任务 ;
流处理:实时处理持续产生的数据流 (如 Flink/Kafka Stream),适合低延迟场景 ;
深度学习训练:模型并行 / 数据并行计算 (如 PyTorch DDP、Ray Train),依赖 GPU 异构资源 ;
在线推理:长生命周期有状态服务(如 API 接口、Ray Serve ),需高并发低延迟 ;
超参搜索:动态调度多任务并行试参 (如 Ray Tune),需弹性资源分配 ;
强化学习:智能体与环境持续交互的状态化计算 (如 Ray RLlib),需多智能体协同。
-
融合计算就是把多种计算范式,整合到同一个分布式引擎(如 Ray)里协同工作,不用在多个系统间切换、传数据,靠一个「底盘」完成复杂任务 。
流批一体:把「批处理」和「流处理」整合到一个引擎 (如 Flink/Spark);
湖仓一体:把「数据湖」和「数据仓」的能力整合到一个存储层 ;
融合计算:范围更广,整合「批、流、训练、推理、调参、强化学习」等多种范式,是更全面的「一体化计算」。
-
Ray 的底层设计(Task+Actor+Plasma 存储)天然支持多范式融合,这是「通用分布式」能力的延伸 ------ 它不是为单一范式设计,而是用通用原语承接所有范式 ,具体怎么承接:
1、用「Remote Task」承接无状态范式:批处理、流处理(轻量流)、超参搜索任务,自动调度并行执行;
2、用「Remote Actor」承接有状态范式:在线推理服务、强化学习智能体、参数服务器,维护长生命周期状态;
3、用「Plasma 分布式对象存储」打通数据链路:所有范式的输入输出都存在这里,跨范式数据不用落盘、不用格式转换,直接通过引用共享。
-
解决系统孤岛:告别「多系统串联的麻烦」
传统模式(非融合):在线学习场景,需 Flink 做流处理→Kafka 存中间数据→PyTorch DDP 做训练→K8s 做推理,每个环节要适配接口、传数据,不仅复杂,还容易出故障。
Ray 融合模式:流处理任务(Task)处理完数据,直接通过 Plasma 存储传给训练任务(Task/Actor),训练好的模型直接交给推理 Actor 部署,全程在 Ray 一个系统内完成,没有中间件串联,减少链路复杂度和故障点。
-
提升性能:靠「本地协同 + 零拷贝」省时间
传统模式:跨系统传数据要经过网络 IO、磁盘 IO(如 Flink 写 Kafka,PyTorch 再读 Kafka),延迟高、开销大。
Ray 融合模式:通过「亲和性调度」,把流处理的输出节点和训练的数据加载节点,调度到同一台物理机;再通过 Plasma 的 Shared Memory(共享内存)传数据,不用拷贝、不用走网络,速度大幅提升,尤其适合大模型训练的海量数据输入场景。
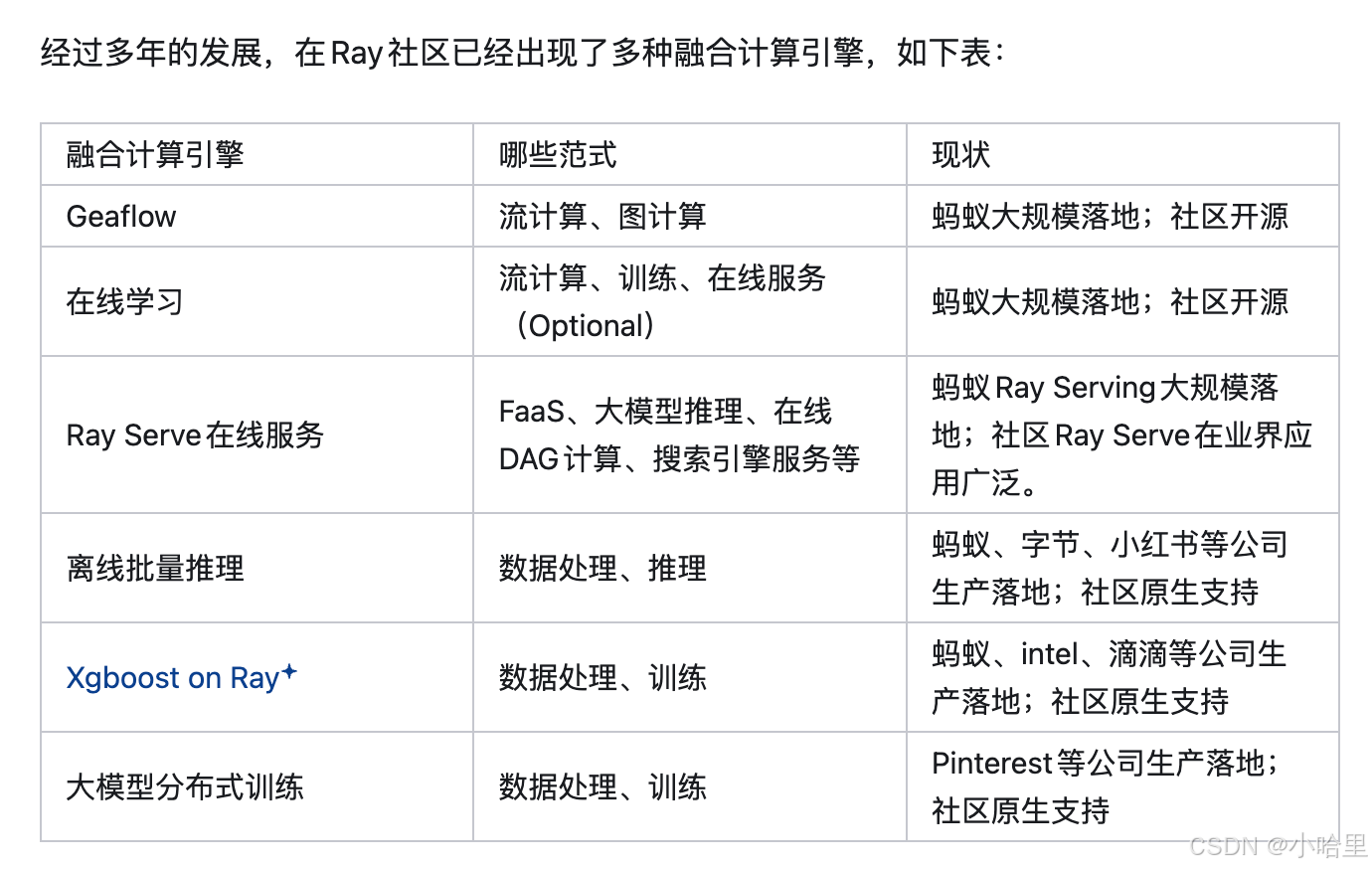
AI生态化
- 如果将 Ray Core 定义为底层通用分布式引擎,将运行在引擎之上、面向垂直场景的上层功能库定义为场景化框架,二者相互支撑,就构成了一套完整且可扩展的 AI 分布式生态,为开发者提供开箱即用、全流程覆盖的标准化能力。
- Ray 构建 AI 生态具备一项天然核心优势,就是 与框架无关(Framework Agnostic) 的底层设计。从 AI 研发全链路 Pipeline 视角来看,Ray 上层的各类核心库 ------ 包括数据处理、分布式训练、超参优化、模型推理与服务部署等模块,均采用中立、无绑定的设计思路,不强制依赖任何单一深度学习或机器学习框架。
以分布式训练场景为例,开发者可以在 Ray 之上无缝使用 PyTorch、TensorFlow、XGBoost 等主流训练框架,保留框架原生 API 与编程习惯;对于尚未提供原生封装的小众或自研框架,也可以基于 Ray Core 提供的 Task、Actor 等基础原语,快速完成分布式能力扩展与集成。 - 经过持续迭代与社区共建,Ray 目前已原生兼容行业内绝大多数主流 AI 框架,形成了稳定、开放的生态格局。同时,Ray 的研发体验与工程化设计高度贴合 AI 全生命周期研发流程,进一步夯实了其作为标准化基础设施的地位。从本地单机快速完成算法原型验证,到接入集群实现规模化分布式训练,依托引擎自动完成任务调度、并行策略管理与 CPU/GPU 等异构资源的细粒度分配,再到通过 Ray Serve 快速部署高可用、可弹性扩缩的在线推理服务,整套流程实现代码低改造、环境无缝切换、链路全程贯通。
Ray 从底层消除了单机开发与集群生产之间的技术壁垒,让数据预处理、模型训练、参数调优、服务上线等全环节工作,都能运行在统一的分布式底座之上,真正实现 AI 研发基础设施的标准化、易用化与工程化落地。
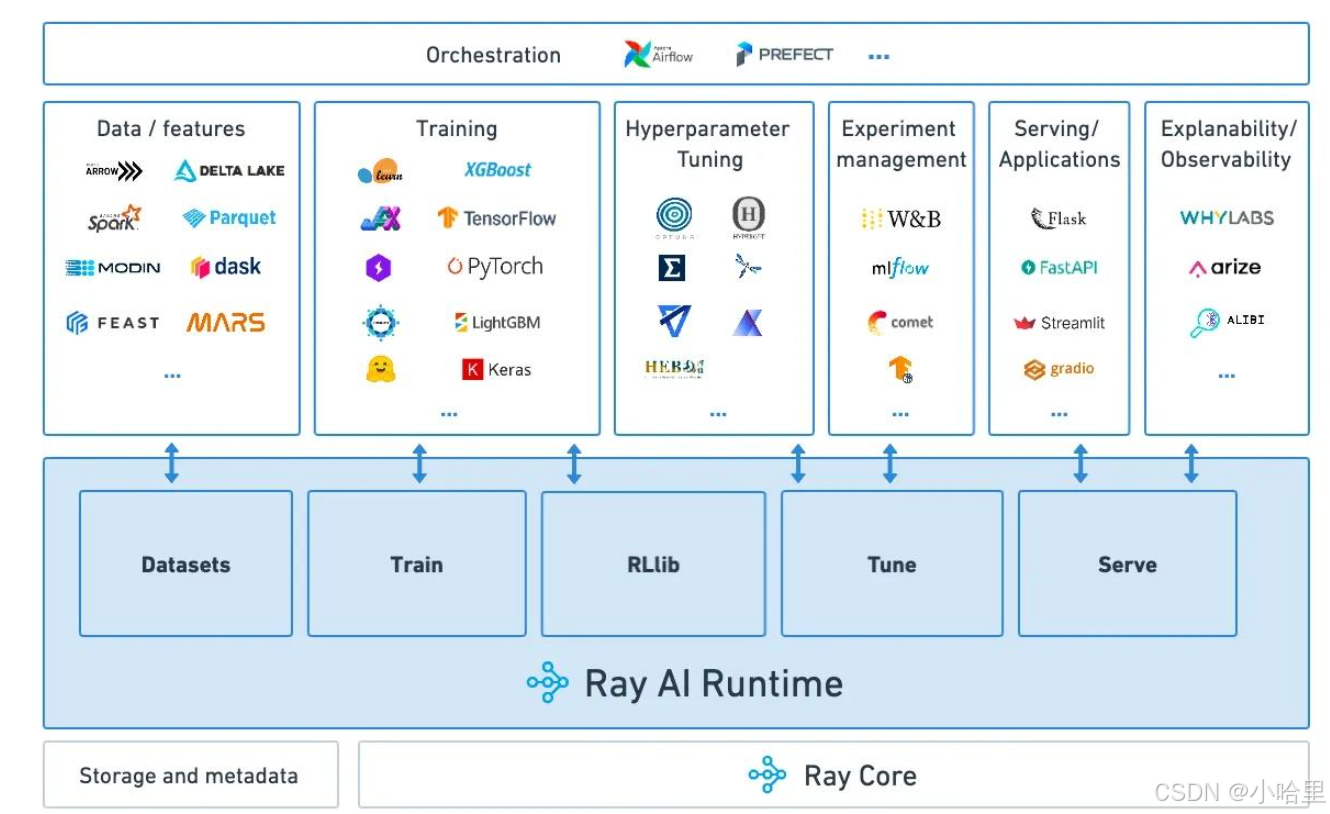
参考资料:1
3、Ray用法介绍
3.1 Ray 基础示例(单机,并行,调参,训练,数据处理)
(1) 单机并行计算
python
import ray
import time
# 初始化 Ray(单机模式)
ray.init(num_cpus=4) # 使用4个CPU核心
@ray.remote
def slow_function(x):
time.sleep(1) # 模拟耗时任务
return x * x
# 并行执行4个任务
futures = [slow_function.remote(i) for i in range(4)]
results = ray.get(futures) # 获取结果 [0, 1, 4, 9]
print(results)
# 输出
# [0, 1, 4, 9] # 4个任务并行完成,总耗时约1秒(串行需4秒)(2) 跨机器集群计算
bash
# 步骤1:启动 Head 节点(机器1)
ray start --head --port=6379 --num-cpus=4
# 步骤2:启动 Worker 节点(机器2)
ray start --address='<head-node-ip>:6379' --num-cpus=4
# 步骤3:提交分布式任务
python
import ray
# 连接到集群(任意节点运行)
ray.init(address='auto')
@ray.remote
def distributed_task(x):
return x ** 2
# 在集群所有节点上并行计算
futures = [distributed_task.remote(i) for i in range(8)]
print(ray.get(futures)) # [0, 1, 4, 9, 16, 25, 36, 49](3) 分布式超参数调优
python
import ray
from ray import tune
def train(config):
lr = config["lr"]
# 模拟训练过程
accuracy = 1.0 / (lr + 0.1)
tune.report(accuracy=accuracy)
ray.init(num_cpus=4)
analysis = tune.run(
train,
config={"lr": tune.grid_search([0.01, 0.1, 1.0])},
)
print(analysis.best_config) # 输出最佳学习率(4) 分布式 PyTorch 训练
python
import ray
import torch
from torchvision import datasets
@ray.remote(num_gpus=1)
class Trainer:
def __init__(self):
self.model = torch.nn.Linear(10, 1).cuda()
def train(self, data):
loss = torch.mean((self.model(data) - data) ** 2)
loss.backward()
return loss.item()
# 启动两个训练器(使用两台机器的GPU)
trainers = [Trainer.remote() for _ in range(2)]
data = torch.randn(100, 10).cuda()
results = ray.get([t.train.remote(data) for t in trainers])
print(results) # 打印两台机器的损失值(5) 实时数据处理(Actor 模型)
python
import ray
@ray.remote
class StreamingProcessor:
def __init__(self):
self.count = 0
def add_data(self, x):
self.count += x
return self.count
# 创建两个处理器
processor1 = StreamingProcessor.remote()
processor2 = StreamingProcessor.remote()
# 异步更新状态
print(ray.get(processor1.add_data.remote(1))) # 输出 1
print(ray.get(processor2.add_data.remote(2))) # 输出 23.2 Ray实现对比原生torch(数据并行,模型并行,自由组合)
在分布式训练中,任务如何在多台机器上运行取决于具体的并行策略和框架设计。
(1) 数据并行(Data Parallelism)
- 核心思想 :同一任务 (同一模型)在两台机器上运行,但处理不同的数据批次。
- 适用场景:单模型过大无法放入单机GPU,或需要加速训练。
- 技术实现 :
- PyTorch :
torch.nn.parallel.DistributedDataParallel(DDP)+ NCCL。 - TensorFlow :
tf.distribute.MirroredStrategy或MultiWorkerMirroredStrategy。
- PyTorch :
- 通信需求:需同步梯度(高频通信,依赖NCCL/MPI)。
示例代码(PyTorch DDP):
python
# 机器1(rank=0)和机器2(rank=1)运行相同代码
import torch
import torch.distributed as dist
dist.init_process_group(
backend='nccl',
init_method='tcp://主节点IP:23456',
rank=0, # 机器1为0,机器2为1
world_size=2
)
model = torch.nn.Linear(10, 10).cuda()
model = torch.nn.parallel.DistributedDataParallel(model)
data = torch.randn(100, 10).cuda() # 每台机器分到不同数据分片
output = model(data)(2) 模型并行(Model Parallelism)
- 核心思想 :不同机器运行同一模型的不同部分(如不同层)。
- 适用场景:模型过大无法放入单机GPU(如LLM训练)。
- 技术实现 :
- 手动拆分:将模型层分配到不同设备(需框架支持)。
- 框架集成 :PyTorch的
pipe = PipelineParallel(model, chunks=8)。
示例代码(PyTorch 模型拆分):
python
# 机器1运行前半部分模型
class Layer1(torch.nn.Module):
def forward(self, x):
return x * 2
# 机器2运行后半部分模型
class Layer2(torch.nn.Module):
def forward(self, x):
return x + 1
# 通过RPC通信(需配置)(3)通过 Ray 实现灵活任务分配
Ray 支持更通用的任务分发模式,可自由组合数据/模型并行:
python
# 两机器跑不同任务
import ray
ray.init(address='auto')
@ray.remote(num_gpus=1)
def task_a(data):
return train_model_a(data)
@ray.remote(num_gpus=1)
def task_b(data):
return train_model_b(data)
# 机器1跑task_a,机器2跑task_b
result_a = task_a.remote(data1)
result_b = task_b.remote(data2)
python
# 两机器协作跑同一任务(数据并行)
@ray.remote(num_gpus=1)
class Trainer:
def __init__(self, rank):
self.rank = rank
self.model = build_model().cuda()
def train(self, data_shard):
loss = self.model(data_shard).mean()
return loss
# 启动两个训练器
trainers = [Trainer.remote(rank=i) for i in range(2)]
data_shards = [data[:100], data[100:]] # 数据分片
ray.get([t.train.remote(d) for t, d in zip(trainers, data_shards)])| 维度 | 数据并行 | 模型并行 | Ray自由任务 |
|---|---|---|---|
| 机器协作 | 同步梯度(强耦合) | 流水线式协作(松耦合) | 完全独立或自定义协作 |
| 适用场景 | 数据量大、模型可单机加载 | 超大模型(如GPT-3) | 异构任务、灵活调度 |
| 实现复杂度 | 中(需框架支持) | 高(需手动拆分模型) | 低(仅需装饰器) |
| 通信开销 | 高(频繁同步梯度) | 中(层间传递张量) | 可自定义(零通信) |
3.3 Ray 框架全流程使用方式(单机->集群->推理)
结合 AI 研发本地单机原型验证→集群规模化训练→Ray Serve 高可用推理部署全链路
Ray 集群常用操作
shell
查看集群状态:ray status(查看节点数、资源使用情况)
停止服务:serve shutdown(停止推理服务)
停止集群:主节点执行 ray stop --force(关闭整个集群)
监控集群:访问 http://主节点IP:8265(Ray 原生 Dashboard,查看任务、资源、服务监控)1、本地单机原型验证(基础版,无 Ray 依赖)
py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 1. 定义简单模型(MNIST 分类,简化版)
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
def forward(self, x):
return self.fc(x.view(x.size(0), -1)) # 展平图片
# 2. 生成模拟数据(替代真实MNIST,方便快速运行)
def generate_data(batch_size=32):
X = torch.randn(1000, 1, 28, 28) # 1000张28*28灰度图
y = torch.randint(0, 10, (1000,)) # 随机标签0-9
dataset = TensorDataset(X, y)
return DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 3. 单机训练函数
def train_model():
model = SimpleModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
dataloader = generate_data()
# 训练5个epoch
for epoch in range(5):
loss_sum = 0.0
for X, y in dataloader:
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
loss_sum += loss.item()
print(f"单机训练 Epoch {epoch+1}, 平均损失: {loss_sum/len(dataloader):.4f}")
return model # 返回训练好的模型
# 4. 单机推理函数
def infer_model(model, X):
model.eval()
with torch.no_grad():
outputs = model(X)
return torch.argmax(outputs, dim=1) # 返回预测标签
# 本地运行:纯单机原型验证
if __name__ == "__main__":
model = train_model()
test_X = torch.randn(5, 1, 28, 28) # 5个测试样本
pred = infer_model(model, test_X)
print(f"单机推理结果: {pred.numpy()}")
# 运行结果:输出 5 个 epoch 的训练损失,以及 5 个测试样本的预测标签,完成纯单机原型验证。2、集群规模化分布式训练(基于 Ray Train,无缝升级)
基于上述单机代码,通过 Ray Train 实现分布式训练,自动完成数据并行、异构资源调度(CPU/GPU)、集群任务分发,核心代码仅少量修改,保留 PyTorch 原生逻辑。
- 代码最小改造:模型、损失函数、优化器完全复用单机代码,仅通过 ray.train.torch.prepare_model 实现分布式封装;
- 资源自动调度:通过 ScalingConfig 配置节点数、GPU 数,Ray 自动在集群中调度资源,无需手动分配节点;
- 单机 / 集群无缝切换:注释 ray.init(address="auto") 即可本地运行,开启则对接集群,代码无其他修改;
- 异构资源适配:无 GPU 时仅需将 num_gpus_per_worker 设为 0,Ray 自动切换为 CPU 训练,无需修改训练逻辑。
py
import ray
from ray.train import Trainer, TorchTrainer
from ray.train.torch import TorchCheckpoint
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# -------------------------- 关键:集群连接(单机运行可注释这行) --------------------------
ray.init(address="auto") # 自动连接Ray集群,本地运行注释后不影响
# ----------------------------------------------------------------------------------------
# 1. 复用单机的模型定义(完全无修改)
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
def forward(self, x):
return self.fc(x.view(x.size(0), -1))
# 2. 数据加载函数(Ray Train要求:返回train/val DataLoader)
def data_config():
def generate_data(batch_size=32):
X = torch.randn(1000, 1, 28, 28)
y = torch.randint(0, 10, (1000,))
return DataLoader(TensorDataset(X, y), batch_size=batch_size, shuffle=True)
return {"train_dataloader": generate_data(), "val_dataloader": generate_data(batch_size=32)}
# 3. 训练循环函数(Ray Train封装,保留PyTorch原生逻辑)
def train_loop_per_worker(config):
# Ray Train自动初始化分布式环境,加载数据
dataloaders = ray.train.get_dataloaders()
model = SimpleModel()
# 关键:Ray Train封装分布式模型,自动处理数据并行
model = ray.train.torch.prepare_model(model)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 原生训练逻辑(完全复用单机代码)
for epoch in range(5):
model.train()
loss_sum = 0.0
for X, y in dataloaders["train_dataloader"]:
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
loss_sum += loss.item()
# 关键:Ray Train记录指标,支持集群监控
ray.train.report({"epoch": epoch+1, "train_loss": loss_sum/len(dataloaders["train_dataloader"])})
# 返回训练好的模型(Ray Train自动保存为Checkpoint)
return TorchCheckpoint.from_model(model)
# 4. 启动分布式训练(核心:配置资源,Ray自动调度)
def ray_distributed_train():
# 配置:2个工作节点,每个节点1块GPU(无GPU则设num_gpus=0,自动适配CPU)
trainer = TorchTrainer(
train_loop_per_worker,
train_loop_config={},
data_config=data_config(),
scaling_config=ray.train.ScalingConfig(
num_workers=2, # 分布式工作节点数,集群中自动调度到不同机器
num_gpus_per_worker=1, # 每节点GPU数,细粒度资源分配
use_gpu=True
)
)
# 启动训练(单机/集群统一接口,Ray自动处理调度)
result = trainer.fit()
print(f"分布式训练完成,最后一轮损失: {result.metrics['train_loss']:.4f}")
return result.checkpoint # 返回模型检查点,用于后续推理部署
# 运行分布式训练
if __name__ == "__main__":
model_checkpoint = ray_distributed_train()
# 保存检查点到本地(可选,用于推理部署)
model_checkpoint.to_directory("./ray_model_checkpoint")3、Ray Serve 部署高可用推理服务(无缝衔接训练结果)
基于上述分布式训练生成的模型检查点,通过 Ray Serve 快速部署高可用、可弹性扩缩的推理服务,支持HTTP 接口调用、动态扩缩容、多实例负载均衡,全程复用模型定义,无框架切换
Ray Serve 核心优势(高可用 + 标准化)
- 无缝衔接训练:直接加载 Ray Train 生成的模型检查点,无需模型格式转换、无需重新训练;
- 弹性扩缩容:通过 num_replicas 动态调整服务实例数,集群中自动调度到不同节点,支持流量峰值自动扩容;
- 细粒度资源分配:支持「分片 GPU(如 0.5 块)」,提升 GPU 资源利用率,适合小模型推理;
- 高可用:服务实例故障时,Ray 自动重启并重新调度,无需人工干预;
- 统一接口:部署代码与训练代码基于同一 Ray 引擎,无需学习 K8s、FastAPI 等额外框架,保持 Python 原生编程习惯。
推理服务部署代码(兼容单机 / 集群)
py
import ray
from ray import serve
import torch
import json
from starlette.requests import Request
# 复用训练阶段的模型定义(完全无修改)
from train_code import SimpleModel # 假设训练代码在train_code.py,直接导入即可
# -------------------------- 集群连接(单机运行可注释) --------------------------
ray.init(address="auto")
serve.start(detached=True) # 以守护进程启动服务,集群中持久运行
# --------------------------------------------------------------------------------
# 1. 定义Ray Serve服务类(核心:封装模型加载与推理)
@serve.deployment(
num_replicas=2, # 服务实例数,支持动态扩缩容(集群中自动调度)
ray_actor_options={"num_gpus": 0.5} # 每个实例分配0.5块GPU(细粒度资源切分)
)
class ModelInferenceService:
def __init__(self, checkpoint_dir: str):
# 从训练检查点加载模型(无缝衔接训练结果)
self.model = SimpleModel()
checkpoint = torch.load(f"{checkpoint_dir}/model.pt")
self.model.load_state_dict(checkpoint["model_state_dict"])
self.model.eval() # 推理模式
# 推理函数:支持HTTP POST请求,处理JSON数据
async def __call__(self, request: Request):
try:
# 解析请求数据
data = await request.json()
X = torch.tensor(data["image"]).unsqueeze(0) # 增加batch维度
# 原生推理逻辑(复用单机代码)
with torch.no_grad():
output = self.model(X)
pred_label = torch.argmax(output, dim=1).item()
# 返回JSON结果
return {"code": 200, "pred_label": pred_label, "msg": "推理成功"}
except Exception as e:
return {"code": 500, "msg": f"推理失败:{str(e)}"}
# 2. 部署服务(加载训练好的模型检查点)
ModelInferenceService.deploy(checkpoint_dir="./ray_model_checkpoint")
print("Ray Serve推理服务部署成功!")
print("服务访问地址:http://<节点IP>:8000/ModelInferenceService")推理服务调用(HTTP 接口,支持本地 / 远程调用)
py
import requests
import numpy as np
# 构造测试数据(28*28灰度图,随机生成)
test_image = np.random.randn(1, 28, 28).tolist()
# 发送POST请求
response = requests.post(
"http://localhost:8000/ModelInferenceService",
json={"image": test_image}
)
# 解析结果
print(response.json())
# 预期输出:{"code": 200, "pred_label": 某数字, "msg": "推理成功"}
# Curl命令
curl -X POST http://localhost:8000/ModelInferenceService \
-H "Content-Type: application/json" \
-d '{"image": [[[0.1, 0.2, ..., 0.3]]]}' # 28*28的二维数组