构建传统 RAG Agent:从文档到知识库的完整之旅
1. 前言
在大模型应用中,检索增强生成(RAG,Retrieval-Augmented Generation) 是一种强大的技术,它通过将外部知识库与大模型结合,使得模型能够基于真实数据生成更准确的回答。本文将详细讲解如何使用 LangChain + LangGraph + DashScope + Milvus 的技术栈,从零开始构建一个完整的传统 RAG Agent。
2. 项目架构概览
┌─────────────────┐
│ 原始文档 │
│ (company.txt) │
└────────┬────────┘
│
▼
┌──────────────────────────┐
│ 文本分割器 │
│ (RecursiveCharacterTS) │
└────────┬─────────────────┘
│
▼
┌──────────────────────────┐
│ 向量化 (Embeddings) │
│ (DashScope Embeddings) │
└────────┬─────────────────┘
│
▼
┌──────────────────────────┐
│ 向量数据库 (Milvus) │
│ 存储与检索向量索引 │
└────────┬─────────────────┘
│
▼
┌──────────────────────────┐
│ RAG Chain │
│ 检索 + 提示词 + LLM │
└────────┬─────────────────┘
│
▼
┌──────────────────────────┐
│ LangGraph Agent │
│ (集成多代理系统) │
└──────────────────────────┘3. 代码详解
3.1 第一阶段:环境初始化与依赖导入
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.documents import Document
from langchain_core.messages import HumanMessage
from langgraph.graph import StateGraph, MessagesState, START, END
load_dotenv()
key = os.getenv("DASHSCOPE_API_KEY")
base_url = os.getenv("DASHSCOPE_API_BASE")3.1.1 关键点说明
- dotenv 环境配置 :通过
.env文件安全地存储 API 密钥,避免硬编码敏感信息 - 模块迁移 :注意使用
langchain_text_splitters而非langchain.text_splitter(LangChain 0.2+ 的变化) - 通义千问集成 :使用
DashScopeEmbeddings而非 OpenAI Embeddings
3.2 第二阶段:大模型初始化
python
graph_llm = ChatOpenAI(temperature=0, model_name="qwen-plus-2025-12-01",
api_key=key, base_url=base_url)
llm = ChatOpenAI(temperature=0, model_name="qwen-plus",
api_key=key, base_url=base_url)3.2.1 参数解析
| 参数 | 含义 | 取值 |
|---|---|---|
temperature |
输出随机性 | 0 = 确定性(适合RAG), 1 = 创意性 |
model_name |
模型版本 | qwen-plus(基础)/ qwen-plus-2025-12-01(增强) |
api_key |
身份认证 | 从 .env 读取(不显示实际密钥) |
base_url |
API 端点 | 通义千问 API 基址(从 .env 读取) |
3.3 第三阶段:文档加载与文本分割
python
# Step 1: 加载文档
with open('../doc/company.txt', 'r', encoding="utf-8") as file:
content = file.read()
documents = [Document(page_content=content)]
# Step 2: 文本分割
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(documents)
3.3.1 核心原理
- chunk_size = 250:每个文本块的大小,平衡上下文完整性与检索精度
- chunk_overlap = 30:相邻块的重叠部分,避免重要信息被截断
- RecursiveCharacterTextSplitter:递归按层级分割(段落 → 句子 → 词),保持文本逻辑连贯
3.3.2 为什么要分割?
- 直接存储完整文档会导致向量检索结果过冗长
- 分割后可精准定位用户查询相关的信息片段
- 大模型的上下文窗口有限,分割能提高效率
3.4 第四阶段:向量化与向量库构建
python
# Step 3: 初始化 Embeddings
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=key # 从环境变量读取
)
# Step 4: 构建向量索引
vectorstore = Milvus.from_documents(
documents=splits,
collection_name="company_milvus",
embedding=embeddings,
connection_args={
"uri": os.getenv("MILVUS_URI"), # 从环境变量读取
"user": os.getenv("MILVUS_USER"), # 从环境变量读取
"password": os.getenv("MILVUS_PASSWORD"), # 从环境变量读取
}
)这里向量库可以考虑在线。
这里我们同样使用免费的在线milvus实例,地址如下:https://cloud.zilliz.com/login?redirect=/orgs , 先注册登录
创建索引:
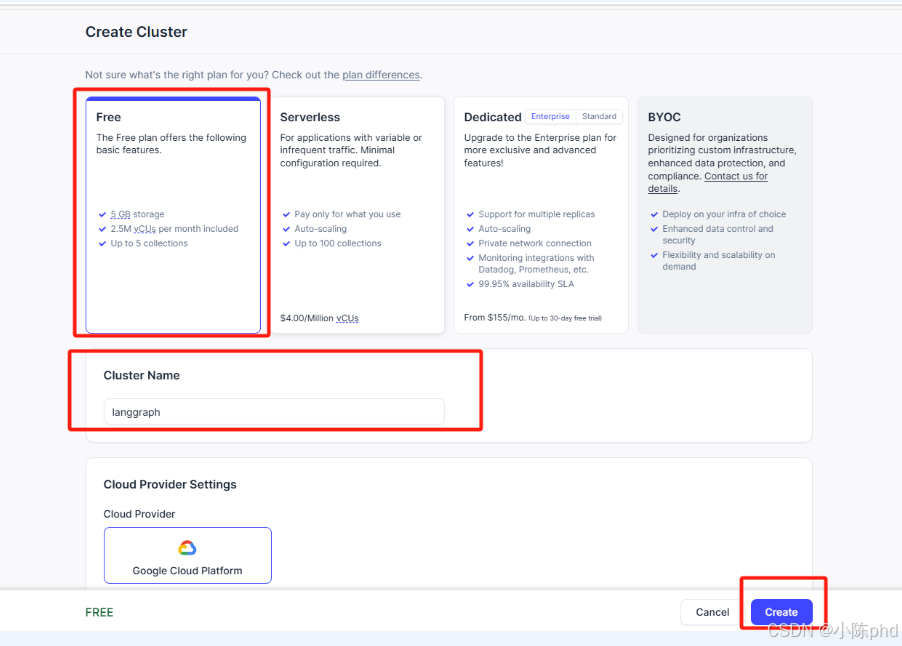
选择免费实例:
 保存好用户密码:
保存好用户密码:
3.4.1 工作流程
文本块
↓
DashScope Embeddings (文本向量化)
↓
向量 (1024 维)
↓
Milvus (向量存储与索引)
↓
HNSW/IVF 索引结构
↓
支持快速相似度检索3.4.2 Milvus 的作用
- 向量存储:以向量形式存储文本块
- 快速检索:使用 HNSW 算法,时间复杂度 O(log n)
- 云端部署:无需本地安装,直接使用云实例,连接信息从环境变量读取
3.5 第五阶段:RAG Chain 构建
python
# Step 5: 创建 RAG Chain
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "context"],
)
rag_chain = prompt | graph_llm | StrOutputParser()3.5.1 LCEL 管道解析
用户问题 + 检索上下文
↓
PromptTemplate (格式化)
↓
ChatOpenAI (推理)
↓
StrOutputParser (解析输出)
↓
最终回答3.5.2 提示词设计的三个要点
- 角色定义:明确告知模型是问答助手
- 约束条件:最多三句话,简洁表达
- 容错机制:不知道的情况下说"不知道",避免幻觉
3.6 第六阶段:RAG Chain 测试
python
# Step 6: 测试
question = "我的知识库中都有哪些公司信息"
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": docs, "question": question})
print(f"生成的答案: {generation}")3.6.1 检索流程
| 步骤 | 操作 | 输出 |
|---|---|---|
| 1 | 问题向量化 | 1024 维向量 |
| 2 | Milvus 相似度搜索 | Top-k 最相关文本块 |
| 3 | 构建提示词 | 格式化后的完整提示 |
| 4 | 调用大模型 | 结构化回答 |
| 5 | 解析输出 | 纯文本答案 |
3.7 第七阶段:LangGraph Agent 节点定义
python
# Step 7: 定义 AgentState
class AgentState(MessagesState):
next: str
# Step 8: 创建 vec_kg Agent 节点
def vec_kg(state: AgentState):
messages = state["messages"][-1]
question = messages.content
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "context"],
)
rag_chain = prompt | graph_llm | StrOutputParser()
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": docs, "question": question})
final_response = [HumanMessage(content=generation, name="vec_kg")]
return {"messages": final_response}3.7.1 Agent 节点的核心逻辑
状态输入 (消息列表)
↓
提取最后一条消息作为问题
↓
执行 RAG Chain (检索 + 推理)
↓
包装为 HumanMessage (带 vec_kg 标识)
↓
返回更新后的状态3.7.2 为什么需要 AgentState?
- 消息管理:维护对话历史
- 多代理协作:标识消息来源(vec_kg, graph_kg, chat 等)
- 状态转移 :通过
next字段控制代理流向
3.8 第八阶段:测试与验证
python
# Step 9: 测试 vec_kg 节点
if __name__ == "__main__":
test_state = AgentState(
messages=[HumanMessage(content="我的知识库中都有哪些公司信息")]
)
result = vec_kg(test_state)
print(f"RAG Agent 响应: {result}")
4. 核心概念理解
4.1 什么是 RAG?
4.1.1 传统 LLM 的局限
- 知识截止日期固定(训练数据年份)
- 无法访问私密数据
- 容易产生幻觉(编造答案)
4.1.2 RAG 的解决方案
用户问题 → [检索] 相关文档 → [融合] 上下文 → [生成] 准确答案4.2 为什么使用向量数据库?
| 方案 | 检索方式 | 优点 | 缺点 |
|---|---|---|---|
| 全文搜索 | 关键词匹配 | 速度快 | 语义理解差 |
| 向量相似度 | 语义匹配 | 准确度高 | 需要计算成本 |
本项目选择向量方案:基于语义理解,适合复杂问题
4.3 DashScope vs OpenAI Embeddings
| 特性 | DashScope | OpenAI |
|---|---|---|
| 成本 | 更便宜 | 较贵 |
| 语言 | 中文优化 | 英文优先 |
| 维度 | 1024 维 | 1536 维 |
| 部署 | 国内快速 | 需科学上网 |
5. 应用扩展方向
5.1 混合检索(Hybrid Retrieval)
python
# 结合向量检索 + BM25 关键词检索
results = vectorstore.similarity_search_with_score(question, k=5)
bm25_results = bm25_retriever.get_relevant_documents(question)
combined = merge_and_rerank(results, bm25_results)5.2 多知识库联合
python
# 组合图数据库 + 向量数据库 + 传统数据库
supervisor_agent.route_to([graph_kg, vec_kg, db_agent])5.3 逐步优化提示词
python
# 使用少样本学习 (Few-shot)
template = """
示例 1:...
示例 2:...
用户问题:{question}
"""6. 常见问题排查
6.1 向量检索结果不相关
原因 :chunk_size 过大或过小
解决:调整分割参数 (推荐 200-500)
6.2 回答包含幻觉信息
原因 :检索文档不足或提示词不强制
解决:
python
# 强制模型只基于上下文回答
template += "If the context is not helpful, just say you don't know."6.3 响应速度慢
原因 :Milvus 索引未优化或网络延迟
解决:
python
# 增加 batch 处理或缓存
cache_layer = caching_decorator(rag_chain)7. 总结
本文展示了构建一个完整的传统 RAG Agent 的全过程:
- 文档处理:加载 → 分割 → 向量化
- 知识存储:向量数据库集成
- 检索增强:基于语义的精准匹配
- 智能生成:RAG Chain 组合
- 多代理集成:LangGraph 框架应用
这个系统可以立即用于:
- 📚 企业知识库问答
- 💼 产品信息快速查询
- 📖 文档智能总结
- 🔍 复杂问题推理
下一步可以考虑引入 GraphRAG(图知识库)以处理更复杂的关系推理任务,构建混合知识库系统!
8. 参考资源
完整代码贴上:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.documents import Document
from langchain_core.messages import HumanMessage
from langgraph.graph import StateGraph, MessagesState, START, END
# 加载环境变量
load_dotenv()
key = os.getenv("DASHSCOPE_API_KEY")
base_url = os.getenv("DASHSCOPE_API_BASE")
# 初始化 LLM
graph_llm = ChatOpenAI(temperature=0, model_name="qwen-plus-2025-12-01", api_key=key, base_url=base_url)
llm = ChatOpenAI(temperature=0, model_name="qwen-plus", api_key=key, base_url=base_url)
# 3.4 创建传统 RAG Agent
# Step 1: 加载文档并分割
with open('../doc/company.txt', 'r', encoding="utf-8") as file:
content = file.read()
documents = [Document(page_content=content)]
# Step 2: 文本分割
chunk_size = 250
chunk_overlap = 30
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(documents)
# Step 3: 初始化 Embeddings
embeddings = DashScopeEmbeddings(
model="text-embedding-v4",
dashscope_api_key=key
)
# Step 4: 构建向量索引并存储到 Milvus
vectorstore = Milvus.from_documents(
documents=splits,
collection_name="company_milvus",
embedding=embeddings,
connection_args={
"uri": "https://xxxxxxxxxxxxxxx.serverless.gcp-us-west1.cloud.zilliz.com",
"user": "xxxxxxxxx", # 替换为自己的
"password": "xxxxxx",
}
)
# Step 5: 创建 RAG Chain
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "context"],
)
rag_chain = prompt | graph_llm | StrOutputParser()
# Step 6: 测试 RAG Chain
question = "我的知识库中都有哪些公司信息"
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": docs, "question": question})
print(f"生成的答案: {generation}")
# Step 7: 定义 AgentState
class AgentState(MessagesState):
next: str
# Step 8: 创建传统 RAG 的 Agent 节点
def vec_kg(state: AgentState):
messages = state["messages"][-1]
question = messages.content
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise:
Question: {question}
Context: {context}
Answer:
""",
input_variables=["question", "context"],
)
# 构建传统的RAG Chain
rag_chain = prompt | graph_llm | StrOutputParser()
# 构建检索器
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
# 执行检索
docs = retriever.invoke(question)
generation = rag_chain.invoke({"context": docs, "question": question})
final_response = [HumanMessage(content=generation, name="vec_kg")]
return {"messages": final_response}
# Step 9: 测试 vec_kg 节点
if __name__ == "__main__":
test_state = AgentState(
messages=[HumanMessage(content="我的知识库中都有哪些公司信息")]
)
result = vec_kg(test_state)
print(f"RAG Agent 响应: {result}")