一、项目介绍
这是以 AI 开发实战 + 后端架构设计 为核心的项目,基于 Spring Boot 3 + LangChain4j + Vue 3 开发的企业级 AI 代码生成平台。
gitee网址:AI代码应用生成平台 最后一次提交代码为lastVersion分支。下面只讲每个模块的实现要点和设计思路
核心能力
1 )智能代码生成:用户输入需求描述, AI 自动分析并选择合适的生成策略 ,通过工具调用 生成代码文件,采用流式输出让用户实时看到 AI 的执行过程。
2 )可视化编辑:生成的应用将实时 展示,可以进入编辑模式,自由选择网页元素并且和 AI 对话来快速修改页面,直到满意为止。
3 )一键部署分享:可以将生成的应用一键部署到云端并自动截取封面图,获得可访问的地址进行分享,同时支持完整项目源码下载。
4 )企业级管理:提供用户管理、应用管理、系统监控、业务指标监控等后台功能,管理员可以设置精选应用、监控 AI 调用情况和系统性能。
二、后端项目初始化
基础项目初始化与运行环境
所属后端模块
环境准备 / 项目启动配置
核心设计目标
-
确保运行时兼容性与稳定性(JDK、Spring Boot 版本约束)。
-
提供一致的服务入口与上下文(端口、context-path、统一配置)。
-
降低开发环境差异对交付的影响,便于 CI/CD。
设计思路与关键决策
-
采用 Spring Boot 作为基础框架,统一项目启动方式与生态依赖管理;选择 Maven 保证团队熟悉度与稳定构建。
-
强制最低 JDK 要求(>=17,推荐 21),以保证语言特性、性能与长期支持。
-
将服务入口(端口、context-path)集中到
application.yml,便于环境切换与容器化部署。 -
本地开发允许热重载(DevTools)提高迭代速度,生产环境关闭以防止意外行为。
技术选型与对比分析
-
选用方案:Spring Boot 3.x + Maven + JDK21(或 17)
-
选型理由:
-
优势:成熟生态、丰富中间件支持、社区与企业级实践;开发效率高且与 Spring Security、Spring Data 等无缝集成。
-
劣势/代价:较高的运行内存与启动时间;Major 升级可能需较多兼容性工作。
-
适用场景:需要快速落地企业级微服务或单体应用并依赖 Spring 生态的团队。
-
实现要点(非代码,讲逻辑)
-
明确并文档化 JDK 与数据库版本,编写环境启动校验脚本以统一开发环境。
-
使用 profile(dev/test/prod)和外部化配置(环境变量 / 配置中心)实现环境切换。
-
启动验证:自动化检查端口、context-path 与健康接口,保证部署流水线稳定。
与其他后端模块的衔接
- 配置项为日志 、监控 、健康检查 与部署流水线提供统一入口;所有业务模块通过配置读取运行时参数。
依赖管理与工具库选型
所属后端模块
依赖管理 / 工具库(Hutool / Lombok / Knife4j / AOP)
核心设计目标
-
快速降低工程重复实现成本(常用工具函数、注解处理)。
-
提供自动化 API 文档与可视化界面,便于联调与契约管理。
设计思路与关键决策
-
选用轻量工具库(Hutool)与 Lombok 简化样板代码,提高开发效率。
-
使用 OpenAPI(springdoc)作为主文档源,并用 Knife4j 优化文档 UI 体验与调试能力。
-
在需要时使用 Spring AOP(exposeProxy 可选)满足特定代理访问需求,但限制其使用范围以减少复杂度。
技术选型与对比分析
-
选用方案:Hutool + Lombok + springdoc-openapi3 + Knife4j + Spring AOP
-
替代方案:Apache Commons / Guava(替代 Hutool);手写工具或不使用 Lombok;Swagger UI 原生界面
-
选型理由:
-
优势:工具库覆盖常见场景、减少重复代码;Knife4j 提升 OpenAPI 的可用性;AOP 提供横切逻辑的集中治理。
-
劣势/代价:引入第三方需关注版本兼容与维护;Lombok 在 IDE 上需额外插件配置;Knife4j/插件需与 Spring Boot 版本兼容。
-
适用场景:追求开发效率、希望快速生成文档并提供前端联调体验的团队。
-
实现要点(非代码,讲逻辑)
-
在构建配置中集中管理依赖版本并标注可选依赖(如 Lombok optional)。
-
OpenAPI 明确 controller 扫描包并将生成地址与网关/反向代理保持一致。
-
对 AOP 使用做好评估,必要时限制 exposeProxy 范围并说明原因。
与其他后端模块的衔接
- 接口文档为前端、测试与运维提供契约;通用工具库被业务模块复用。
通用基础代码:异常与响应统一处理
所属后端模块
异常统一处理 / 响应规范
核心设计目标
-
统一错误语义与响应结构,便于前端、监控与告警系统处理。
-
区分业务异常与系统异常,提供结构化错误码体系。
-
降低业务层异常处理的重复实现。
设计思路与关键决策
-
设计自定义错误码枚举并与 HTTP 语义对齐(例如 40100 表示未登录),便于跨团队沟通。
-
使用专门的业务异常类(BusinessException)而非直接抛 RuntimeException,清晰分层。
-
全局统一异常处理(ControllerAdvice)将异常统一映射为 BaseResponse,不向外暴露内部堆栈。
-
若与文档工具(OpenAPI/Knife4j)存在兼容性问题,可对全局处理类做文档隐藏处理。
技术选型与对比分析
-
选用方案:自定义 ErrorCode + BusinessException + 全局 ExceptionHandler + 统一 BaseResponse
-
替代方案:使用 Spring 的 ResponseStatusException / 直接依赖 HTTP 状态码驱动
-
选型理由:
-
优势:统一格式便于客户端统一处理与监控规则;错误码语义化利于告警与日志分析。
-
劣势/代价:需维护错误码表并保证跨系统一致性;初期设计需预留扩展空间。
-
适用场景:对可观测性和运维有较高要求的生产系统。
-
实现要点(非代码,讲逻辑)
-
规范错误码命名与分配策略(模块前缀、范围预留),并纳入变更流程。
-
提供抛出工具(ThrowUtils)以减少业务层模板化代码,并确保抛出信息结构一致。
-
全局异常处理器将不同异常类型映射为对应错误码,同时把完整堆栈输出到日志/追踪系统以便排查。
-
对外仅返回用户友好的 message 与 code,避免泄露实现细节。
与其他后端模块的衔接
- 该模块为所有 API 提供标准错误与响应契约,是权限管理、审计与监控的上游依赖。
请求/响应包装与通用 DTO 设计
所属后端模块
请求包装 / 分页与通用请求对象
核心设计目标
-
提供通用请求格式 (分页 、删除 、筛选),减少重复 DTO 定义。
-
保证接口参数的一致性与可文档化,便于自动生成客户端代码。
设计思路与关键决策
-
抽象分页请求、删除请求等通用 DTO,作为控制器层参数复用;将默认分页与排序约定写入通用类。
-
使用统一校验策略拦截非法参数,保证服务端输入稳定性。
技术选型与对比分析
-
选用方案:明确的 DTO 类(PageRequest、DeleteRequest 等) + 全局校验
-
替代方案:使用 Map/原始请求参数或在每个接口显式声明分页参数
-
选型理由:
-
优势:类型安全、便于生成文档与客户端代码;减少重复并利于维护。
-
劣势/代价:需要版本管理与向后兼容策略,DTO 变更需审核。
-
适用场景:常规 CRUD 型业务系统,尤其适合契约驱动开发流程。
-
实现要点(非代码,讲逻辑)
-
明确定义分页的默认值、排序字段与方向约定并在文档中说明。
-
控制器层统一使用通用请求类并配合全局校验器,尽早拒绝非法输入。
与其他后端模块的衔接
- 通用 DTO 为业务控制器、查询服务与持久层提供统一契约,影响 OpenAPI 文档与前端生成代码。
全局跨域配置与安全考量
所属后端模块
全局跨域配置(CORS) / 接口访问策略
核心设计目标
-
支持开发与联调场景下的跨域请求(包含携带 Cookie)。
-
在开发便利性与生产安全性之间找到平衡。
设计思路与关键决策
-
在全局配置中允许跨域请求并支持凭证(allowCredentials=true),但生产环境禁止使用通配符 origin 与放宽策略。
-
将生产的来源控制下沉到网关或反向代理,开发环境使用更宽松的策略以便联调。
技术选型与对比分析
-
选用方案:Spring MVC 全局 Cors 配置,allowCredentials=true,allowedOriginPatterns 配置白名单或模式
-
替代方案:在网关层或反向代理层做 CORS 控制(更安全)
-
选型理由:
-
优势:实现集中、配置简单,支持前端携带 Cookie 进行认证。
-
劣势/代价:若误用通配符 origin 与 allowCredentials 会带来安全风险;生产需严格域名白名单。
-
适用场景:中小规模项目开发阶段;安全敏感或大规模对外服务建议在网关层严格控制。
-
实现要点(非代码,讲逻辑)
-
开发环境允许放宽来源以便联调,生产环境必须使用具体域名白名单并配合 HTTPS。
-
若必须支持动态域名,可实现动态校验逻辑并记录来源审计。
与其他后端模块的衔接
- 与认证/会话管理密切相关(Cookie/Token 的跨域传递需一致);需与网关与部署脚本协同。
接口文档与自动化客户端生成
所属后端模块
接口文档 / OpenAPI 生成与客户端代码生成
核心设计目标
-
为前端、测试与 SDK 提供准确、可交互的 API 契约。
-
支持自动生成前端请求代码与类型定义,减少手工维护成本。
设计思路与关键决策
-
以 OpenAPI 3(springdoc)为主文档源,Knife4j 提升 UI;将文档生成与验证纳入 CI 构建步骤。
-
将 schemaPath、扫描包等配置化,便于在不同环境下生成与验证。
技术选型与对比分析
-
选用方案:springdoc-openapi3 + Knife4j + openapi 代码生成工具(openapi-generator / openapi2ts)
-
替代方案:Swagger2 / 手写文档 / Postman 集合
-
选型理由:
-
优势:OpenAPI 3 生态成熟,自动化生成减少前后端摩擦;Knife4j 提升文档交互体验。
-
劣势/代价:需在 CI 中增加文档校验防止实现与文档不同步;插件与 Spring 版本兼容需关注。
-
适用场景:强调契约驱动、需要自动生成客户端或类型定义的团队。
-
实现要点(非代码,讲逻辑)
-
在构建流水线中加入文档生成与校验步骤,确保接口变更需经过审查。
-
使用生成的 OpenAPI schema 自动化生成前端请求代码,形成契约驱动开发流程。
与其他后端模块的衔接
- 接口文档是前端代码生成、测试套件与 SDK 发布的上游;需与错误响应规范、权限注解保持一致。
健康检查与基础接口
所属后端模块
基础运维接口(Health Check)
核心设计目标
-
提供轻量的可用性检测端点,支持容器编排的 liveness / readiness 探针。
-
简化监控与部署平台的集成。
设计思路与关键决策
-
提供最小化的健康检查接口返回统一响应(如 OK),复杂依赖检测交给监控系统或 Actuator 扩展。
-
健康接口尽量保持轻量且权限开放或通过网关白名单控制访问。
技术选型与对比分析
-
选用方案:自定义轻量健康接口(/health)或结合 Spring Boot Actuator按需扩展
-
替代方案:仅使用 Actuator(完整健康探针)或外部监控主动探测服务
-
选型理由:
-
优势:自定义接口简单易用;Actuator 功能全面便于深入监控。
-
劣势/代价:自定义需维护依赖检测逻辑;Actuator 需控制暴露的端点安全性。
-
适用场景:初期使用轻量接口,生产环境结合 Actuator 与监控平台使用。
-
实现要点(非代码,讲逻辑)
-
健康检查返回与全局响应模型一致,便于监控端解析。
-
健康端点与权限隔离,平台可在网关层开放访问或加白名单。
与其他后端模块的衔接
- 健康检查用于部署编排(Kubernetes readiness/liveness)、CI/CD 流程与监控告警,需与部署脚本和网关配置协同。
环境准备
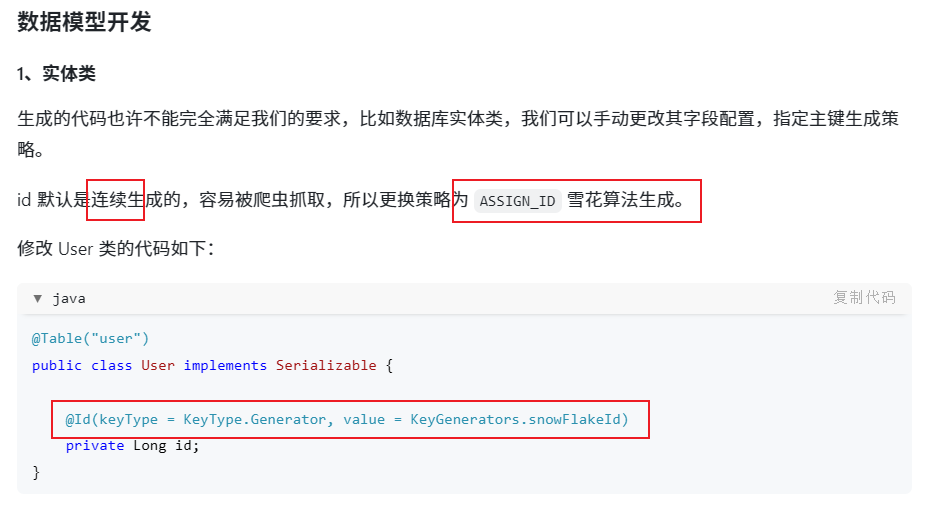
1 )安装的 JDK 版本必须 >= 17 ,推荐使用 21 版本!
可参考视频安装 JDK : https://www.bilibili.com/video/BV14SUNYREv8
2 ) MySQL 数据库最好安装 8.x 版本,或者 5.7 版本。
新建项目
在 IDEA 中新建项目,选择 Spring Boot 模板、 Maven 、 JDK 21 ,
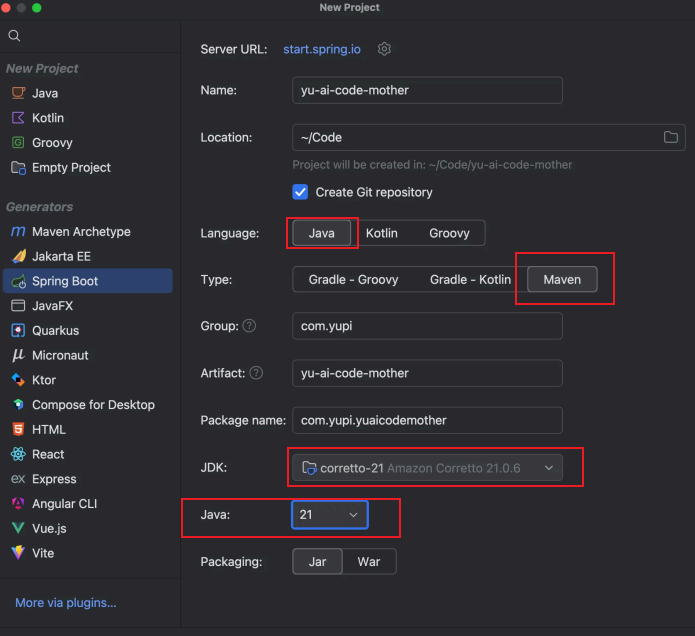
选择 Spring Boot 3.5.x 版本,必须添加的依赖包括 Spring Web 、 MySQL 、 Lombok , Spring Boot DevTools 可以按需。
整合依赖
接下来我们要整合一些开发项目常用的依赖。
Hutool 工具库
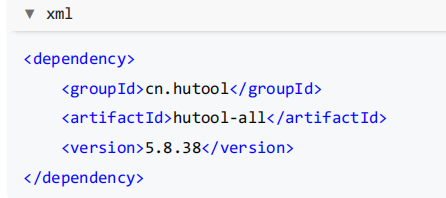
Hutool 是主流的 Java 工具类库,集合了丰富的工具类,涵盖字符串处理、日期操作、文件处理、加解密、反射、 正则匹配等常见功能。它的轻量化和无侵入性让开发者能够专注于业务逻辑而不必编写重复的工具代码。例如, DateUtil.formatDate(new Date()) 可以快速将当前日期格式化为字符串。
参考官方文档引入: https://doc.hutool.cn/pages/index/#🍊maven
在 Maven 的 pom.xml 中添加依赖:
Knife4j 接口文档
Knife4j 是基于 Swagger 接口文档的增强工具,提供了更加友好的 API 文档界面和功能扩展,例如动态参数调试、 分组文档等。它适合用于 Spring Boot 项目中,能够通过简单的配置自动生成接口文档,让开发者和前端快速了 解和调试接口,提高协作效率。
参考官方文档引入: https://doc.xiaominfo.com/docs/quick-start#spring-boot-3
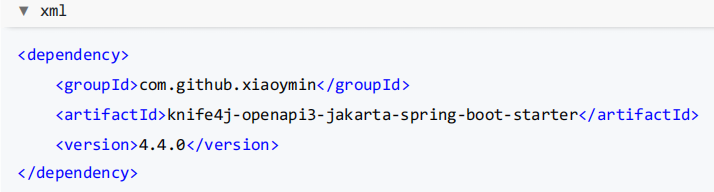
由于使用的是 Spring Boot 3.x ,注意要选择 OpenAPI 3 的版本!
1 )在 Maven 的 pom.xml 中添加依赖:
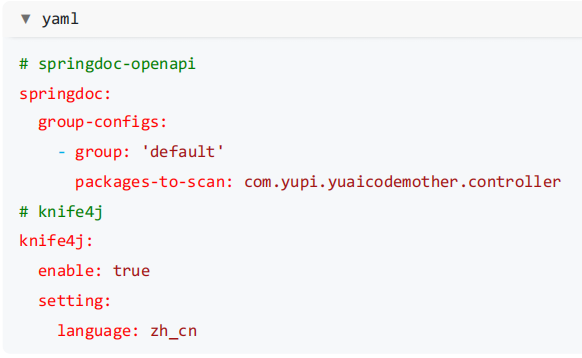
2 )在 application.yml 中追加接口文档配置,重点是指定扫描 Controller 包的路径:
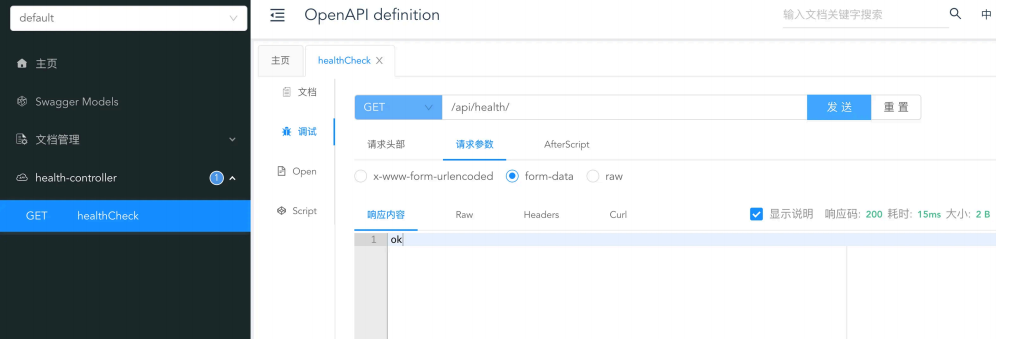
3 )在 controller 包下新建一个测试接口:
重启项目,访问 http://localhost:8123/api/doc.html 能够看到接口文档,可以测试调用接口:
通用基础代码
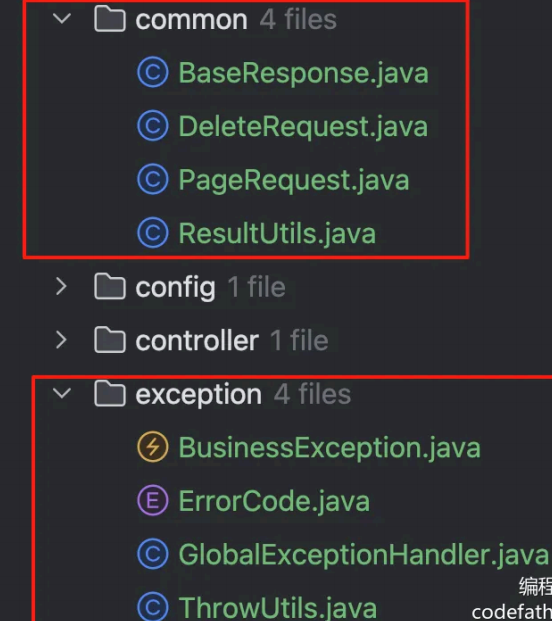
通用基础代码是指:无论在任何后端项目中,都可以复用的代码。这种代码一般 " 一辈子只用写一次 " ,了解作用 之后复制粘贴即可,无需记忆。
目录结构如下:
1**、自定义异常**
自定义错误码,对错误进行收敛,便于前端统一处理。
💡 这里有 2 个小技巧:
- 自定义错误码时,建议跟主流的错误码(比如 HTTP 错误码)的含义保持一致,比如 " 未登录 " 定义为 4010 0,和 HTTP 401 错误(用户需要进行身份认证)保持一致,会更容易理解。
- 错误码不要完全连续,预留一些间隔,便于后续扩展。
在 exception 包下新建错误码枚举类:

一般不建议直接抛出 Java 内置的 RuntimeException ,而是自定义一个业务异常,和内置的异常类区分开,便于定 制化输出错误信息:

为了更方便地根据情况抛出异常,可以封装一个 ThrowUtils ,类似断言类,简化抛异常的代码:

2 、响应包装类
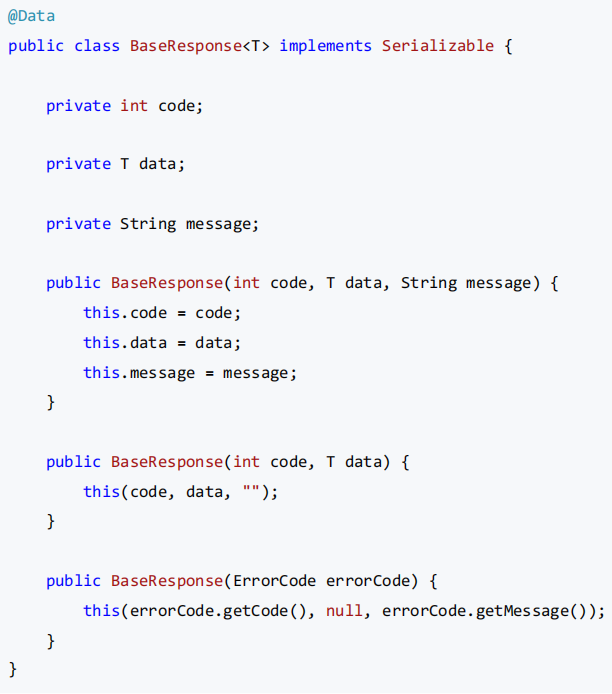
一般情况下,每个后端接口都要返回调用码、数据、调用信息等,前端可以根据这些信息进行相应的处理。 我们可以封装统一的响应结果类,便于前端统一获取这些信息。
通用响应类:
但之后每次接口返回值时,都要手动 new 一个 BaseResponse 对象并传入参数,比较麻烦,我们可以新建一个工具类,提供成功调用和失败调用的方法,支持灵活地传参,简化调用。
java
public class ResultUtils {
/**
* 成功
*
* @param data 数据
* @param <T> 数据类型
* @return 响应
*/
public static <T> BaseResponse<T> success(T data) {
return new BaseResponse<>(0, data, "ok");
}
/**
* 失败
*
* @param errorCode 错误码
* @return 响应
*/
public static BaseResponse<?> error(ErrorCode errorCode) {
return new BaseResponse<>(errorCode);
}
/**
* 失败
*
* @param code 错误码
* @param message 错误信息
* @return 响应
*/
public static BaseResponse<?> error(int code, String message) {
return new BaseResponse<>(code, null, message);
}
/**
* 失败
*
* @param errorCode 错误码
* @return 响应
*/
public static BaseResponse<?> error(ErrorCode errorCode, String message) {
return new BaseResponse<>(errorCode.getCode(), null, message);
}
}3 、全局异常处理器
为了防止意料之外的异常,利用 AOP 切面全局对业务异常和 RuntimeException 进行捕获:
java
@Hidden
@RestControllerAdvice
@Slf4j
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public BaseResponse<?> businessExceptionHandler(BusinessException e) {
log.error("BusinessException", e);
return ResultUtils.error(e.getCode(), e.getMessage());
}
@ExceptionHandler(RuntimeException.class)
public BaseResponse<?> runtimeExceptionHandler(RuntimeException e) {
log.error("RuntimeException", e);
return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统错误");
}
}注意!由于本项目使用的 Spring Boot 版本 >= 3.4 、并且是 OpenAPI 3 版本的 Knife4j ,这会导致
@RestControllerAdvice 注解不兼容,所以必须给这个类加上 @Hidden 注解,不被 Swagger 加载。虽然网上也有 其他的解决方案,但这种方法是最直接有效的。
4 、请求包装类
对于 " 分页 " 、 " 删除某条数据 " 这类通用的请求,可以封装统一的请求包装类,用于接受前端传来的参数,之后相同参数的请求就不用专门再新建一个类了。
分页请求包装类,包括当前页号、页面大小、排序字段、排序顺序参数:
java
@Data
public class PageRequest {
/**
* 当前页号
*/
private int pageNum = 1;
/**
* 页面大小
*/
private int pageSize = 10;
/**
* 排序字段
*/
private String sortField;
/**
* 排序顺序(默认降序)
*/
private String sortOrder = "descend";
}删除请求包装类,接受要删除数据的 id 作为参数:
java
@Data
public class DeleteRequest implements Serializable {
/**
* id
*/
private Long id;
private static final long serialVersionUID = 1L;
}5**、全局跨域配置**
跨域是指浏览器访问的 URL(前端地址 )和后端接口地址 的域名(或端口号)不一致导致的,浏览器为了安全,
默认禁止跨域请求访问。
后端接口:http://localhost:8123/api
这就是跨域!
为了开发调试方便,我们可以通过全局跨域配置,让整个项目所有的接口支持跨域,解决跨域报错。
新建 config 包,用于存放所有的配置相关代码。全局跨域配置代码如下:
java
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
// 覆盖所有请求
registry.addMapping("/**")
// 允许发送 Cookie
.allowCredentials(true)
// 放行哪些域名(必须用 patterns,否则 * 会和 allowCredentials 冲突)
.allowedOriginPatterns("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("*");
}
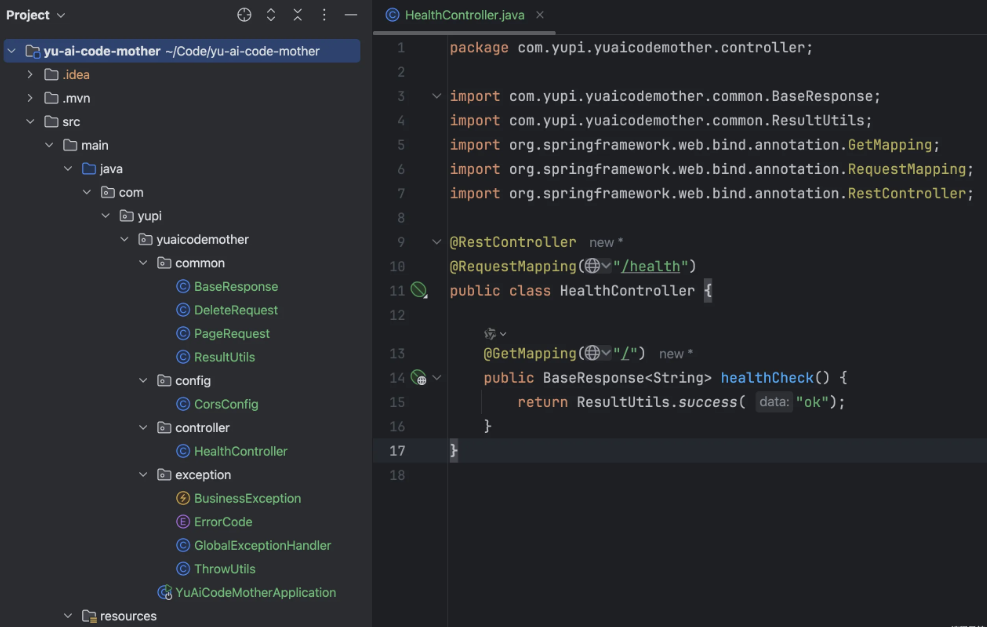
}最后初始化完的后端项目的目录结构为:
二、前端项目初始化
直接从我gitee上拉取就行,完整代码。
**三、**用户模块
本节重点
首先开发每个项目基本都具有的用户模块,本节可以当做一个 用户管理系统项目独立学习,适合新手入门, 后端和前端部分也可以按需独立学习。
本节大纲:
用户模块需求分析
用户模块方案设计
用户模块后端开发(含 MyBatis Flex + 代码生成器)
一、需求分析
对于用户模块,通常要具有下列功能:
用户注册
用户登录
获取当前登录用户
用户注销
用户权限控制
【管理员】管理用户
具体分析每个需求:
1)用户注册:用户可以通过输入账号、密码、确认密码进行注册
2)用户登录:用户可以通过输入账号和密码登录
3)获取当前登录用户:得到当前已经登录的用户信息(不用重复登录)
4)用户注销:用户可以退出登录
5)用户权限控制 :用户又分为普通用户和管理员,管理员拥有整个系统的最高权限, 比如可以管理其他用户.
6)用户管理:仅管理员可用,可以对整个系 统中的用户进行管理,比如搜索用户、删除用户
二、方案设计
实现用户模块的难度不大,方案设计阶段我们需要确认:
1 库表设计
2 用户登录流程
3 如何对用户权限进行控制?

几个注意事项:
- editTime 和updateTime 的区别:
editTime 表示用户编辑个人信息的时间(需要业务代码来更新),而 updateTime 表示这条用户记录任何字段发生修改的时间(由数据库自动更新)。
-
给唯一值添加唯一键(唯一索引),比如账号 userAccount,利用数据库天然防重复,同时可以增加查询效率.
-
给经常用于查询的字段添加索引,比如用户昵称userName,可以增加查询效率。
💡 建议养成好习惯,将库表设计SQL 保存到项目的目录中,比如新建 sql/create_table.sql 文件。
2**、扩展设计**
1)如果要实现会员功能,可以对表进行如下扩展:
-
给userRole 字段新增枚举值 vip ,表示会员用户,可根据该值判断用户权限
-
新增会员过期时间字段,可用于记录会员有效期
-
新增会员兑换码字段,可用于记录会员的开通方式
-
新增会员编号字段,可便于定位用户并提供额外服务,并增加会员归属感
用户登录流程
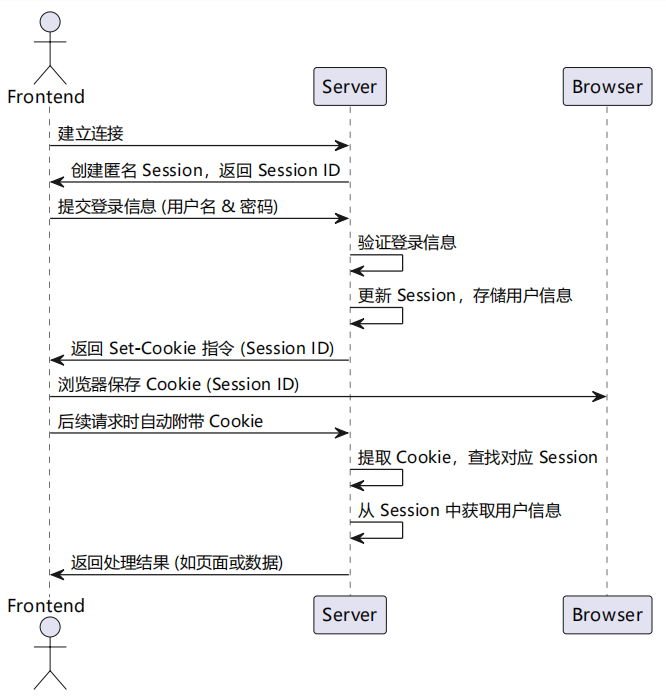
1)建立初始会话:前端与服务器建立连接后,服务器会为该客户端创建一个初始的匿名Session,并将其状态保 存下来。这个Session 的ID 会作为唯一标识,返回给前端。
2)登录成功,更新会话信息:当用户在前端输入正确的账号密码并提交到后端验证成功后,后端会更新该用户的Session,将用户的登录信息(如用户ID、用户名等)保存到与该Session 关联的存储中。同时,服务器会生成一个Set-Cookie 的响应头,指示前端保存该用户的Session ID。
3)前端保存Cookie:前端接收到后端的响应后,浏览器会自动根据Set-Cookie 指令,将SessioID
存储到浏览器的Cookie 中,与该域名绑定。
4)带Cookie的后续请求:当前端再次向相同域名的服务器发送请求时,浏览器会自动在请求头中附带之前保存的Cookie,其中包含Session ID。
5)后端验证会话:服务器接收到请求后,从请求头中提取Session ID,找到对应的Session 数据。 8
6)获取会话中存储的信息:后端通过该 Session 获取之前存储的用户信息(如登录名、权限等),从而识别用户 身份并执行相应的业务逻辑。
如何对用户权限进行控制?
可以将接口分为4 种权限:
-
未登录也可以使用
-
登录用户才能使用
-
未登录也可以使用,但是登录用户能进行更多操作(比如登录后查看全文) 5
-
仅管理员才能使用
传统的权限控制方法是,在每个接口内单独编写逻辑 :先获取到当前登录用户信息,然后判断用户的权限是否符 合要求。
这种方法最灵活,但是会写很多重复的代码,而且其他开发者无法一眼得知接口所需要的权限。
权限校验其实是一个比较通用的业务需求,一般会通过Spring AOP切面****+****自定义权限校验注解实现统一的接口拦截和权限校验;如果有特殊的权限校验逻辑,再单独在接口中编码。
MyBatis Flex****代码生成器
1**、什么是MyBatis Flex?**

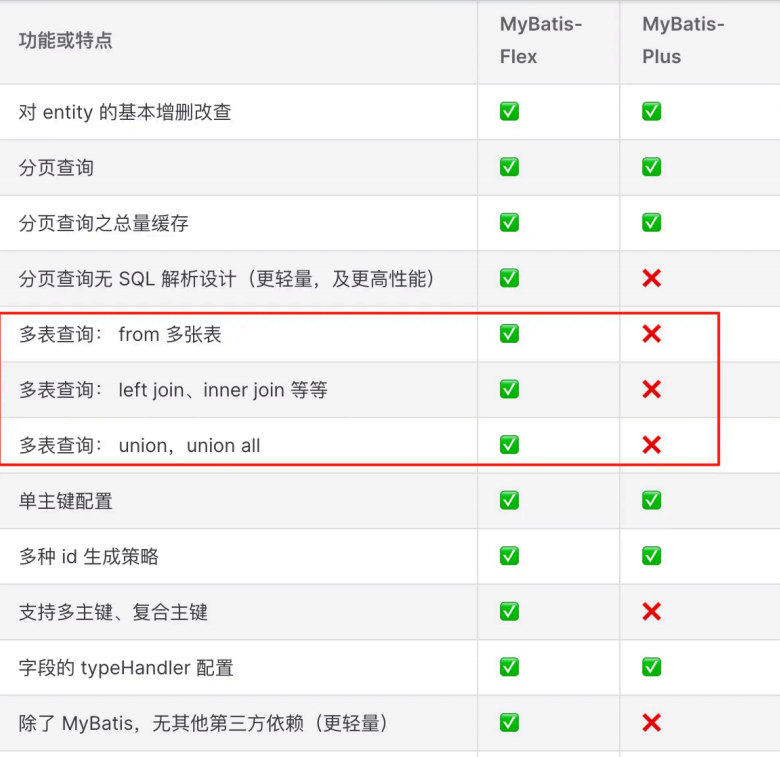
此外,在Mybatis Flex 中,有了一个名称为 mybatis-flex-codegen的模块,提供了可以通过数据库表,生成代码 的功能。当我们把数据库表设计完成后, 就可以使用其快速生成Entity、Mapper、Service、Controller 代码,能 大幅提高我们的开发效率。

代码如下:
java
public class MyBatisCodeGenerator {
// 需要生成的表名
private static final String[] TABLE_NAMES = {"user"};
public static void main(String[] args) {
// 获取数据源信息
Dict dict = YamlUtil.loadByPath("application.yml");
Map<String, Object> dataSourceConfig = dict.getByPath("spring.datasource");
String url = String.valueOf(dataSourceConfig.get("url"));
String username = String.valueOf(dataSourceConfig.get("username"));
String password = String.valueOf(dataSourceConfig.get("password"));
// 配置数据源
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
// 创建配置内容
GlobalConfig globalConfig = createGlobalConfig();
// 通过 datasource 和 globalConfig 创建代码生成器
Generator generator = new Generator(dataSource, globalConfig);
// 生成代码
generator.generate();
}
// 详细配置见:https://mybatis-flex.com/zh/others/codegen.html
public static GlobalConfig createGlobalConfig() {
// 创建配置内容
GlobalConfig globalConfig = new GlobalConfig();
// 设置根包,建议先生成到一个临时目录下,生成代码后,再移动到项目目录下
globalConfig.getPackageConfig()
.setBasePackage("com.yupi.yuaicodemother.genresult");
// 设置表前缀和只生成哪些表,setGenerateTable 未配置时,生成所有表
globalConfig.getStrategyConfig()
.setGenerateTable(TABLE_NAMES)
// 设置逻辑删除的默认字段名称
.setLogicDeleteColumn("isDelete");
// 设置生成 entity 并启用 Lombok
globalConfig.enableEntity()
.setWithLombok(true)
.setJdkVersion(21);
// 设置生成 mapper
globalConfig.enableMapper();
globalConfig.enableMapperXml();
// 设置生成 service
globalConfig.enableService();
globalConfig.enableServiceImpl();
// 设置生成 controller
globalConfig.enableController();
// 设置生成时间和字符串为空,避免多余的代码改动
globalConfig.getJavadocConfig()
.setAuthor("<a href=\"https://github.com/liyupi\">程序员鱼皮</a>")
.setSince("");
return globalConfig;
}
}
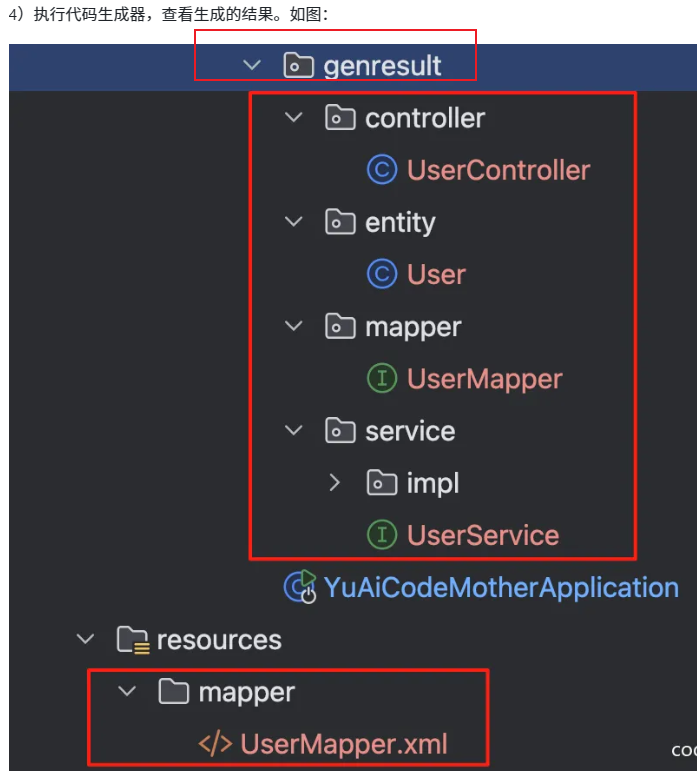
它生成的是在它的包下,后续将这些移动到相应的包下就行。

java
@Getter
public enum UserRoleEnum {
USER("用户", "user"),
ADMIN("管理员", "admin");
private final String text;
private final String value;
UserRoleEnum(String text, String value) {
this.text = text;
this.value = value;
}
/**
* 根据 value 获取枚举
*
* @param value 枚举值的value
* @return 枚举值
*/
public static UserRoleEnum getEnumByValue(String value) {
if (ObjUtil.isEmpty(value)) {
return null;
}
for (UserRoleEnum anEnum : UserRoleEnum.values()) {
if (anEnum.value.equals(value)) {
return anEnum;
}
}
return null;
}
}注意:
用户模块后端设计与实现要点
所属后端模块
用户管理 / 认证与授权 / 数据访问层 / DTO 与数据脱敏
核心设计目标
-
提供完整的用户生命周期支持(注册、登录、获取当前用户、注销)。
-
建立可维护的权限模型,支持普通用户与管理员角色的区分与控制。
-
提高开发效率与代码质量,采用代码生成与统一的数据访问框架。
设计思路与关键决策
-
采用关系型数据库持久化用户实体,设计以账号/密码为核心的
user表,包含角色、头像、简介、逻辑删除等字段;对高频查询字段建立索引。 -
使用 Session(基于 Cookie)作为默认登录态管理机制:登录成功后在 Session 中存储用户对象,后续请求从 Session 中读取登录态。
-
权限控制采用注解 + AOP 切面统一拦截(例如自定义
@AuthCheck注解),在切面中获取当前 Session 中的用户并判断角色,必要时抛出业务异常。 -
选择 MyBatis‑Flex 作为数据访问框架并使用其代码生成器:通过数据库表直接生成 Entity/Mapper/Service/Controller 等骨架代码,节省样板工作并提高一致性。
-
对外 API 返回进行脱敏处理(不返回密码等敏感字段),以及对长整型 ID 进行序列化为字符串处理以避免前端精度丢失问题。
技术选型与对比分析
-
选用方案:MySQL + MyBatis‑Flex(含 codegen) + Session(Cookie) 登录态 + AOP+自定义注解权限校验
-
替代方案:使用 MyBatis‑Plus / JPA;使用 Token/JWT 或 Sa‑Token、Spring Security 作为认证方案;使用框架自带权限(如 Spring Security)替代自定义注解+AOP。
-
优势:MyBatis‑Flex 更轻量且在 QueryWrapper、多表查询等方面灵活;代码生成器能快速产出 CRUD 框架;Session 模式实现简单、与传统 Web 应用兼容度高;注解+AOP 权限方式直观、易于理解和按需扩展。
-
劣势/代价:Session 对分布式部署需额外处理(如共享 Session 或引入 Redis);自定义权限相比成熟框架(Spring Security/Sa‑Token)需更多安全评审与功能补充(如权限粒度、权限缓存);代码生成器产出代码需人工审查与微调以符合业务规范。
-
适用场景:中小型或以传统会话为主的应用,团队希望快速搭建、并愿意在权限能力上逐步增强的项目。
-
!!!实现要点(非代码,讲逻辑)!!!
-
数据库与实体设计:为账号字段添加唯一索引,为常用查询字段(如昵称)添加普通索引;区分
editTime与updateTime的语义,保留逻辑删除字段isDelete。 -
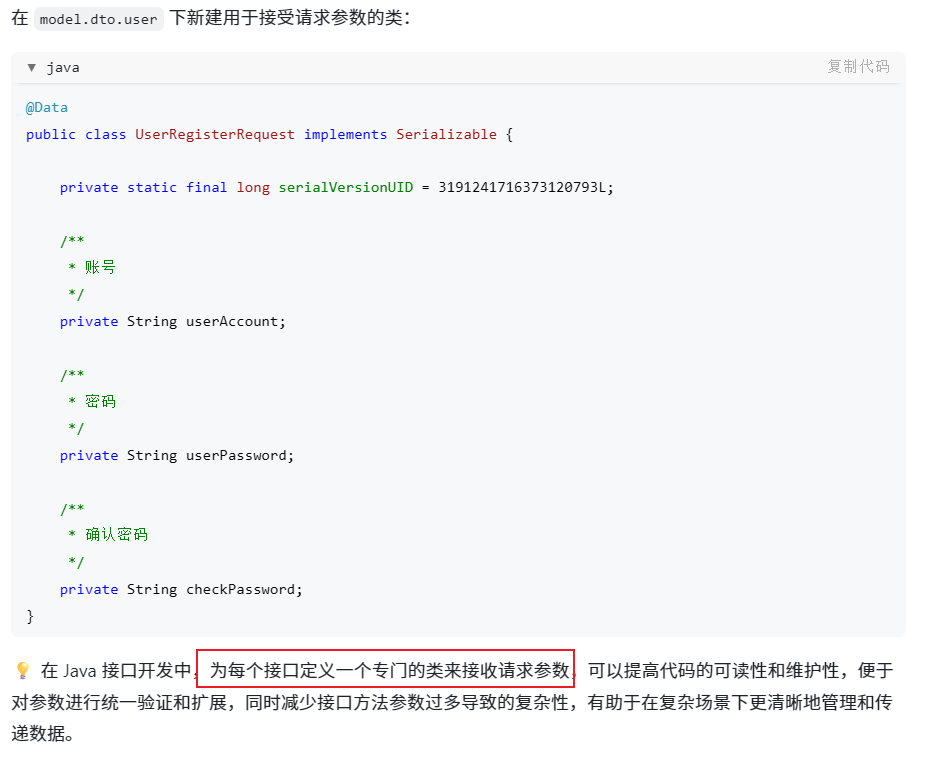
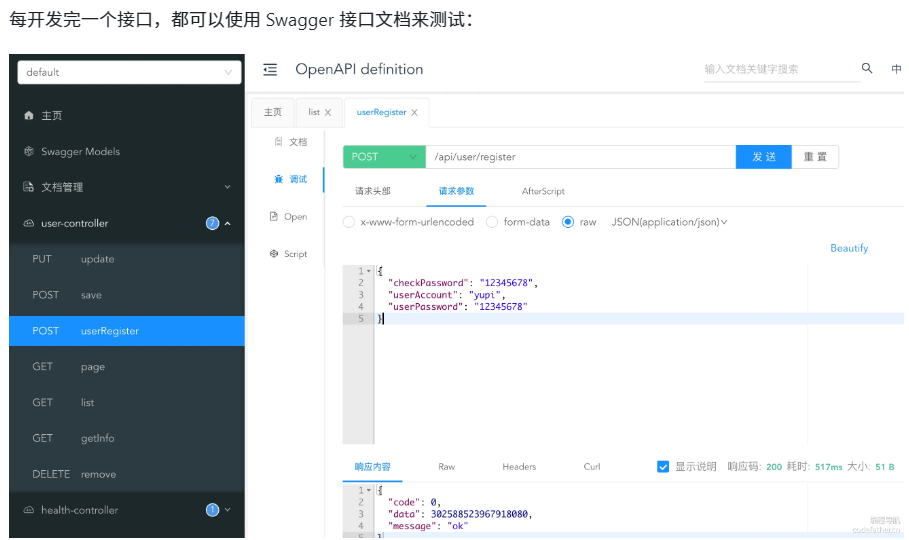
注册流程:校验参数(长度、非空、密码一致性)、账号唯一性检查、对密码按统一策略(含盐)加密后入库。
-
登录流程:接收账号/密码,按注册加密策略加密后比对数据库,登录成功写入 Session(设置统一登录态 key);后续接口通过 Session 校验用户身份。
-
会话管理注意点:Session 模式需考虑多实例场景下的 Session 同步(共享 Session/Redis 或使用粘性会话);设计统一常量(如
USER_LOGIN_STATE)便于各层读取。 -
权限控制:定义权限注解(可配置必需角色),在 AOP 环境中读取当前用户角色并比对;对常见场景采用注解声明式控制,特殊场景在业务层做精细判定。
-
数据访问与代码生成:使用 MyBatis‑Flex codegen 从数据库表生成 Entity/Mapper/Service/Controller 等初版代码,生成后进行必要的策略调整(逻辑删除字段、主键生成策略如雪花 ID)。
-
数据脱敏与返回策略:定义 VO/DTO(如
LoginUserVO、UserVO)用于接口返回,保证敏感字段(密码)不被泄露;对 Long 类型 ID 全局序列化为字符串以防前端精度丢失。 -
边界与异常处理:使用统一业务异常(BusinessException)与全局异常处理器返回标准错误码/信息,便于前端和监控处理错误场景。
与其他后端模块的衔接
-
与全局异常/响应模块衔接:用户模块使用统一的错误码与 BaseResponse 返回结构,便于前端和告警系统解析。
-
与认证/会话管理衔接:Session 登录态需与全局跨域、Cookie 策略一致;若后续改为 Token/JWT,需要调整鉴权切面与前端交互方式。
-
与数据访问层(MyBatis‑Flex)及代码生成工具衔接:生成的实体/Mapper 会被服务层和控制器直接使用,生成策略需与项目包结构和命名规范对齐。
-
与权限/审计模块衔接:权限注解与 AOP 为审计和日志模块提供切入点,可在切面中记录权限校验与用户操作日志以满足合规需求。
核心示例代码(用户模块)
以下为与本节设计对应的精简示例,直接放置在说明后以便参考和复制。
- 密码加密与用户注册/登录(推荐 BCrypt)
java
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
public long userRegister(String account, String rawPassword, String checkPassword) {
if (StrUtil.hasBlank(account, rawPassword, checkPassword) || !rawPassword.equals(checkPassword)) {
throw new BusinessException(ErrorCode.PARAMS_ERROR, "参数校验失败");
}
if (userMapper.countByAccount(account) > 0) throw new BusinessException(ErrorCode.PARAMS_ERROR, "账号已存在");
String encrypted = passwordEncoder().encode(rawPassword);
User user = new User();
user.setUserAccount(account);
user.setUserPassword(encrypted);
user.setUserRole(UserRoleEnum.USER.getValue());
userService.save(user);
return user.getId();
}
public LoginUserVO userLogin(String account, String rawPassword, HttpServletRequest request) {
User user = userMapper.findByAccount(account);
if (user == null || !passwordEncoder().matches(rawPassword, user.getUserPassword())) {
throw new BusinessException(ErrorCode.PARAMS_ERROR, "用户不存在或密码错误");
}
request.getSession().setAttribute(UserConstant.USER_LOGIN_STATE, user);
return userService.getLoginUserVO(user);
}- 权限注解 + AOP(声明式权限校验)
java
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface AuthCheck {
String mustRole() default "";
}
@Aspect
@Component
public class AuthInterceptor {
@Around("@annotation(authCheck)")
public Object doInterceptor(ProceedingJoinPoint joinPoint, AuthCheck authCheck) throws Throwable {
RequestAttributes attrs = RequestContextHolder.currentRequestAttributes();
HttpServletRequest request = ((ServletRequestAttributes) attrs).getRequest();
User loginUser = (User) request.getSession().getAttribute(UserConstant.USER_LOGIN_STATE);
if (loginUser == null) throw new BusinessException(ErrorCode.NOT_LOGIN_ERROR);
String mustRole = authCheck.mustRole();
if (StrUtil.isNotBlank(mustRole) && !mustRole.equals(loginUser.getUserRole())) {
throw new BusinessException(ErrorCode.NO_AUTH_ERROR);
}
return joinPoint.proceed();
}
}- 数据脱敏与返回 DTO(示例)
java
public LoginUserVO getLoginUserVO(User user) {
if (user == null) return null;
LoginUserVO vo = new LoginUserVO();
BeanUtil.copyProperties(user, vo);
vo.setUserPassword(null); // 确保脱敏
return vo;
}- Json 配置防止前端 Long 精度丢失(Jackson 配置示例)
java
@Configuration
public class JsonConfig {
@Bean
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
SimpleModule module = new SimpleModule();
module.addSerializer(Long.class, ToStringSerializer.instance);
module.addSerializer(Long.TYPE, ToStringSerializer.instance);
objectMapper.registerModule(module);
return objectMapper;
}
}- 全局异常处理示例
java
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public BaseResponse<?> businessExceptionHandler(BusinessException e) {
return ResultUtils.error(e.getCode(), e.getMessage());
}
@ExceptionHandler(RuntimeException.class)
public BaseResponse<?> runtimeExceptionHandler(RuntimeException e) {
log.error("RuntimeException", e);
return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统错误");
}
}四:AI 生成应用 --- 后端设计与实现要点
所属后端模块
AI 应用引擎 / 模型适配层 / 生成工作流(Workflow)/ 任务调度与存储 / 接口与流式输出
核心设计目标
-
快速、安全、可复用地把大模型能力封装为后端服务,支持从提示到产物(代码、文档、项目骨架等)的端到端生成流程。
-
支持同步体验与长时异步任务(带进度、可断点恢复、审计与回溯)。
-
可插拔模型适配(多个模型提供商、API 与本地推理),并支持流式响应以改善前端体验。
-
生成产物可持久化、版本化、可回滚,便于后续二次编辑与工程化导出。
设计思路与关键决策
-
工作流+执行器模型:将"解析输入 → 调用模型 → 后处理 → 导出保存"抽象为可编排的步骤(节点),便于复用与调试。
-
接入层(Model Adapter):统一上游模型调用接口(OpenAI、Azure、本地 LLM、LangChain4j 封装等),在适配层实现熔断、限流、重试与速率控制。
-
流式输出:对交互式/长文本生成使用 SSE 或 WebSocket 实现增量返回 ;对批量/工程级生成提供异步任务(Task ID + 轮询/回调)。
-
安全与审计:对输入进行脱敏 /归一化、对生成结果做敏感词/版权检查(可插入第三方合规检查器),并记录每次生成的上下文与模型参数用于审计和质量回溯。
-
输出工程化:对生成代码或项目,提供打包/压缩(zip)、仓库导出(Git init + commit 模板)、和多文件结果的结构化存储。
技术选型与对比
-
推荐栈:Spring Boot 3 + LangChain4j(Java 生态的链式调用与工具集)+ MySQL/Postgres(元数据)+ MinIO/对象存储(生成产物)+ Redis(缓存、任务锁、短期存储)。
-
模型接入:优先使用托管 API(OpenAI/Azure/Anthropic)以简化推理负载;需要低延迟与本地化时再接入本地推理(ONNX/TensorRT)。
-
异步任务队列:使用轻量队列(RabbitMQ / Redis Stream)实现任务调度与重试;对于高并发可接入 Kubernetes + Job 编排。
实现要点
-
输入解析与模板化:将用户输入与业务上下文映射到可复用 Prompt Template;模板支持占位、条件分支和多轮上下文注入。
-
工作流节点:每个节点定义输入/输出契约,支持并行/顺序执行、重试策略与超时控制;执行器负责节点依赖与回滚策略。
-
模型调用策略:
-
同步短文本:直接调用模型并返回最终结果(低延迟)。
-
流式长文本:使用模型流式 API(或 LangChain4j 流式封装),通过 SSE/WS 将 token 增量推送给前端。
-
异步工程化任务:提交任务后返回 Task ID,后台调度执行并把结果写入对象存储与元数据表,支持回调/通知。
-
-
结果后处理:对模型输出做格式化、语法检查、测试编译(生成代码时)、以及可信度评估(必要时触发人工复审)。
-
多文件与项目打包:生成多文件时,对每个文件元数据(路径、hash、size)建表并把文件存对象存储;提供 zip 导出与 Git 快照功能。
-
配置与可观测性:记录每次生成的模型参数(温度、top_p、tokens limit)、时间消耗、费用估算;接入指标与追踪(Prometheus + Jaeger)。
接口设计(示例)
-
同步生成(短文本)
- POST /api/v1/generate/sync --- 请求体:模板 id + 参数;返回:生成内容
-
流式生成(交互/长文本)
- GET /api/v1/generate/stream?template=... --- 使用 SSE 返回增量 token
-
异步工程任务
-
POST /api/v1/generate/task --- 提交任务,返回 taskId
-
GET /api/v1/generate/task/{taskId} --- 查询任务状态与结果元数据
-
POST /api/v1/generate/task/{taskId}/cancel --- 取消任务
-
数据模型(要点)
-
GenerationTask: id, templateId, params(json), status, submitUser, progress, modelMeta, costEstimate, createdAt, finishedAt
-
GeneratedFile: id, taskId, path, filename, objectUrl, size, hash, language, createdAt
-
PromptTemplate: id, name, description, templateBody, version, owner
持久化与存储策略
-
元数据(任务与文件)存关系型数据库;大体量产物(项目文件、日志)存对象存储并保留索引。
-
短期交互上下文(多轮对话)可存 Redis,设置 TTL;长期审计日志归档到冷存储。
示例代码片段(伪 Java / LangChain4j 风格)
java
// 简化的工作流执行示例
public GenerationResult executePipeline(Template template, Map<String,Object> params) {
// 1. 构建 prompt
String prompt = template.render(params);
// 2. 调用模型适配器(可同步或流式)
ModelResponse resp = modelAdapter.generate(prompt, ModelOptions.of("gpt-4", 0.2));
// 3. 后处理与校验
String cleaned = postProcessor.clean(resp.getText());
// 4. 持久化结果
GeneratedFile file = storage.saveTextAsFile(cleaned, "result.txt");
return GenerationResult.of(file.getUrl());
}
// SSE 流式推送示例(Spring)
@GetMapping("/api/v1/generate/stream")
public SseEmitter streamGenerate(@RequestParam String templateId) {
SseEmitter emitter = new SseEmitter(0L);
executor.submit(() -> {
modelAdapter.streamGenerate(renderedPrompt, token -> {
try { emitter.send(token); } catch (Exception ignored) {}
});
emitter.complete();
});
return emitter;
}安全、合规与质量控制
-
对用户输入做白名单/黑名单、速率限制、长度/复杂度限制,防止滥用与注入攻击。
-
生成内容做合规检查(敏感词、隐私信息、版权指纹),对高风险场景引入人工复审流程。
-
成本与配额管控:按用户/组织维度设置并发与调用配额,统计模型调用费用并预估消耗。
监控与运维要点
-
指标:请求量、平均延迟、模型调用次数、失败率、消耗 Tokens/费用。
-
日志:保存请求上下文、模型响应、后处理结果、Task 生命周期事件。
-
可观测:链路追踪每次工作流执行的节点耗时,便于定位瓶颈。
核心示例代码(Java / Spring Boot 风格)
- LangChain4j AI Service 抽象(同步/结构化与流式接口)
java
public interface AiCodeGeneratorService {
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
HtmlCodeResult generateHtmlCode(String userMessage);
@SystemMessage(fromResource = "prompt/codegen-multi-file-system-prompt.txt")
MultiFileCodeResult generateMultiFileCode(String userMessage);
@SystemMessage(fromResource = "prompt/codegen-html-system-prompt.txt")
Flux<String> generateHtmlCodeStream(String userMessage);
}- 门面(Facade)示例:接收流、实时转发并在完成后解析保存
java
public Flux<String> generateAndSaveCodeStream(String userMessage, CodeGenTypeEnum type) {
Flux<String> stream = switch (type) {
case HTML -> aiCodeGeneratorService.generateHtmlCodeStream(userMessage);
case MULTI_FILE -> aiCodeGeneratorService.generateMultiFileCodeStream(userMessage);
};
StringBuilder buf = new StringBuilder();
return stream.doOnNext(chunk -> {
// 实时转发给前端(SSE)由上层 Controller 负责
buf.append(chunk);
}).doOnComplete(() -> {
String full = buf.toString();
Object parsed = CodeParserExecutor.executeParser(full, type);
File saved = CodeFileSaverExecutor.executeSaver(parsed, type);
log.info("生成并保存到:" + saved.getAbsolutePath());
});
}- 解析器(核心正则提取策略示例)
java
public class CodeParser {
private static final Pattern HTML = Pattern.compile("```html\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern CSS = Pattern.compile("```css\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
private static final Pattern JS = Pattern.compile("```(?:js|javascript)\\s*\\n([\\s\\S]*?)```", Pattern.CASE_INSENSITIVE);
public static MultiFileCodeResult parseMultiFileCode(String input) {
MultiFileCodeResult r = new MultiFileCodeResult();
r.setHtml(extract(input, HTML));
r.setCss(extract(input, CSS));
r.setJs(extract(input, JS));
return r;
}
private static String extract(String src, Pattern p) {
Matcher m = p.matcher(src);
return m.find() ? m.group(1).trim() : null;
}
}- 全局异常处理(统一响应契约)
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public BaseResponse<?> handleBiz(BusinessException ex) {
return ResultUtils.error(ex.getCode(), ex.getMessage());
}
@ExceptionHandler(Exception.class)
public BaseResponse<?> handleAll(Exception ex) {
log.error("Unhandled", ex);
return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统内部错误");
}
}基于 LangChain4j 的 AI 应用代码生成后端设计
所属后端模块
AI 服务接入 / 代码生成引擎 / 流式输出与文件持久化 / 结构化输出解析
核心设计目标
-
将用户自然语言描述转化为可执行的代码产物,并以可解析、可保存的结构化结果交付。
-
在保证可用性与稳定性的前提下,提升交付体验(支持 SSE 流式输出以降低等待感)。
-
构建可扩展、可测试的后端抽象层,便于替换模型、增加生成模式和拓展持久化策略。
设计思路与关键决策
-
将 AI 调用抽象为
AI Service接口(通过 LangChain4j 的注解与代理实现),并用工厂/构造器注入具体模型(普通/流式模型);系统提示词从资源文件维护,便于迭代与版本控制。 -
输出从原始字符串向结构化对象过渡:使用 LangChain4j 的结构化输出特性或自定义解析器(Regex/策略)将模型响应转为
HtmlCodeResult/MultiFileCodeResult等 DTO。 -
为兼顾实时体验及后处理可靠性,采用"流式接收 + 最终解析"流程:流式(Flux)将片段实时推送前端并在完成后进行拼接与解析保存。
-
使用门面模式(Facade)提供统一的生成与保存入口(AiCodeGeneratorFacade),内部组合解析器、保存器与执行器,隐藏复杂实现并便于单元测试。
-
在工程实现上优先选用 LangChain4j(跨模型与 Java 生态友好),但保留与 Spring AI 等替代框架的迁移可能性。
技术选型与对比分析
-
选用方案:LangChain4j + DeepSeek/OpenAI 兼容模型(chat/streaming) + Reactor(Flux) 流式处理 + 结构化 DTO + 本地/临时文件保存器(可扩展为云存储)
-
替代方案:Spring AI(更深 Spring 原生支持)/ 直接调用 OpenAI SDK;Token/JWT 或外部任务队列结合模型调用;不同流式实现(原生 TokenStream)
-
选型理由:
-
优势:LangChain4j 提供声明式 AI Service、结构化输出与对多家模型良好兼容性;Flux/Reactor 与 SSE 集成便捷,能显著提升前端体验;门面 + 模式化设计提升可维护性。
-
劣势/代价:部分模型对严格 JSON 输出的支持不完全(需在提示与配置上做兼容处理);流式时无法直接获得结构化类型,需额外拼接与解析工作;引入 Reactor 需管理反应式依赖与测试复杂度。
-
适用场景:需要在后端快速集成大模型并对生成内容做解析保存、同时追求在线流式体验的产品级项目。
-
实现要点(非代码,讲逻辑)
-
系统提示词管理:将不同生成模式的系统提示(单文件/多文件)以资源文件维护,提示词内包含严格输出格式与约束,增强模型输出可解析性。
-
AI Service 抽象:为每种生成模式定义接口方法(同步字符串/结构化对象、流式 Flux),通过工厂注入相应的 chatModel/streamingChatModel。
-
结构化输出策略:尽量优先使用 LangChain4j 的结构化输出特性;当模型返回非严格 JSON 时,采用提示词 + 字段描述 + max_tokens 配置提升成功率,并准备解析降级方案(正则/策略解析器)。
-
流式处理策略:采用 Reactor Flux 收集分片并实时转发给前端(SSE),在流结束时对拼接结果进行一次完整解析并保存,既保证实时性又保留最终一致性。
-
解析与保存分离:解析职责由 CodeParser(可策略化)承担,保存职责由 CodeFileSaver/模板保存器承担,二者通过执行器/门面统一协调,便于扩展不同保存后端(本地、对象存储、数据库)。
-
唯一性与临时目录:生成文件使用业务类型 + 雪花 ID 等策略创建唯一临时目录,避免并发冲突并便于清理;临时目录加入 .gitignore。
-
容错与重试:对模型输出进行重试与最大 token 控制;对结构化输出不稳定情况,记录完整日志并在解析失败时提供人工/自动补救路径(重试或回退到全文解析)。
-
单元测试与自动化:对 AI Service(mock 模型)、CodeParser、保存器与 Facade 进行单元测试,保证在模型返回多种变体时解析器的健壮性。
与其他后端模块的衔接
-
与配置管理:模型 API Key、base-url、模型名与流式开关等集中在配置文件(支持 profile/local)并加入 .gitignore 管理本地敏感配置。
-
与日志与可观测性:在 AI 调用、流式分片、解析与保存节点增加链路日志(请求/响应/解析状态)与指标(耗时、失败率),便于监控与回溯。
-
与接口文档/契约:结构化 DTO(HtmlCodeResult、MultiFileCodeResult)应纳入后端 API 文档,确保前端/测试能稳定消费返回结果。
-
与权限与限流:AI 生成功能通常是高成本操作,应与鉴权、频率限制、配额管理模块集成,避免滥用与成本暴涨。
-
与存储与部署:保存器可切换为对象存储(如 OSS/S3)或持久化数据库,部署时需考虑临时目录的清理策略与存储成本。
五:应用模块 --- 设计、生成、流式与部署
了解应用生命周期、AI 生成集成、流式 SSE 优化、代码保存与部署方案的实现要点。
目录
-
概述
-
需求与目标
-
后端总体设计
-
数据模型与 DTO
-
核心流程与关键类
-
SSE 流式生成与优化
-
生成结果解析与持久化
-
应用部署方案(3 种)
-
接口与示例请求
-
测试与运维注意事项
-
总结与后续扩展
概述
将单机代码生成能力升级为平台化应用:支持应用管理(增删改查)、AI 驱动的代码生成(流式或异步)、生成结果持久化与在线部署。后台负责鉴权、限流、存储、索引和下载。
需求与目标
-
支持多用户、应用生命周期管理与部署。
-
提供稳定的 REST 与 SSE 流式接口,支持异步任务(taskId)与流式分片转发。
-
结果以结构化 DTO(
HtmlCodeResult/MultiFileCodeResult)解析并可靠持久化,支持下载(zip)。
后端总体设计
-
分层:
Controller(API+SSE)→Service(业务)→AiCodeGeneratorFacade(AI 门面)→Parser/Saver(解析/持久化)→ Adapter(存储/队列/Auth)。 -
关键约定:长耗时操作异步化;流式以最终解析后的 DTO 为准并做一次可靠保存;生成目录以
codeGenType_appId命名,部署目录以deployKey命名。
数据模型与 DTO(要点)
-
app表:包含id, appName, cover, initPrompt, codeGenType, deployKey, priority, userId, createTime, updateTime, isDelete等字段;deployKey采用 6 位英数标识以支持短路径访问。 -
Java DTO 示例:
GenerateRequest,HtmlCodeResult,MultiFileCodeResult,AppVO(包含UserVO以便返回关联用户信息)。
示例(简化):
sql
create table app (
id bigint auto_increment primary key,
appName varchar(256),
initPrompt text,
codeGenType varchar(64),
deployKey varchar(64),
priority int default 0,
userId bigint,
createTime datetime,
updateTime datetime
);核心流程与关键类
-
请求接收(
AiApplicationController/AppController)→ 参数校验→ 权限校验→ 同步/异步/流式调用AiCodeGeneratorFacade。 -
AiCodeGeneratorFacade:封装AIService(模型调用)和CodeParser,提供generateCode,generateCodeStream,parseFinal等方法。 -
CodeParser:优先尝试 JSON 结构化解析,回退到基于分隔符(如 ```file:PATH)或正则的解析。 -
CodeFileSaver:把解析后的多文件结果保存到磁盘(或 S3),并打包为 zip,返回可供下载的路径。
关键设计要点:
-
生成结果目录:
FILE_SAVE_ROOT_DIR/{codeGenType}_{appId},部署目录:CODE_DEPLOY_ROOT_DIR/{deployKey}。 -
对流式结果,服务端应实时缓存分片,流结束后统一解析并持久化,避免前端看到不完整或错位的文件结构。
SSE 流式生成与优化
问题与优化策略:
-
空格丢失问题:在 SSE 中封装返回数据为 JSON(例如 {"d":"chunk"}),避免浏览器或网络层对空格的意外处理。
-
明确结束事件:在流末尾发送一个特定事件(如
event: done),便于前端区分正常结束与异常断开。
示例(Spring WebFlux):
java
@GetMapping(value = "/chat/gen/code", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<String>> chatToGenCode(@RequestParam Long appId,
@RequestParam String message,
HttpServletRequest request) {
Flux<String> contentFlux = appService.chatToGenCode(appId, message, user);
return contentFlux.map(chunk -> {
String json = JSONUtil.toJsonStr(Map.of("d", chunk));
return ServerSentEvent.<String>builder().data(json).build();
}).concatWith(Mono.just(ServerSentEvent.<String>builder().event("done").data("").build()));
}前端提示:使用 EventSource 监听 message,并用 event == 'done' 判断流结束;从 data.d 字段取出原始内容并拼接。
生成结果解析与持久化
解析流程:
-
AiCodeGeneratorFacade获取原始文本或流。 -
CodeParser尝试 JSON → 回退正则/分隔符解析,产出MultiFileCodeResult。 -
CodeFileSaverExecutor根据codeGenType选择HtmlCodeFileSaver或MultiFileCodeFileSaver,使用appId构建唯一目录并保存文件。
示例保存(关键点):
java
String uniqueDir = FILE_SAVE_ROOT_DIR + File.separator + codeGenType + "_" + appId;
FileUtil.mkdir(uniqueDir);
// 遍历 result.files 写入磁盘并打包 zip注意:不要把大量代码直接写入数据库字段;文件系统或对象存储更适合多文件结构与静态托管。
应用部署方案(后端实现)
-
使用
serve(Node.js):快速启动静态服务器,适合开发/预览。缺点:需要 Node 环境、进程管理。- 可通过
ProcessBuilder在启动时运行npx serve并管理其生命周期。
- 可通过
-
Spring Boot 静态资源接口:将生成目录映射到
/static/{deployKey}/,通过后端返回FileSystemResource,无需额外进程,便于集成测试与预览。 -
Nginx 映射:生产推荐方案,性能与稳定性最好,使用
try_files实现 SPA 支持并通过deployKey做路径隔离。
部署流程(后端实现要点):
-
参数校验与权限:只有应用所有者可部署(或管理员)。
-
deployKey:若不存在则生成 6 位英数字串并保证唯一(可加 DB 查重重试)。 -
复制目录:把
code_output/{codeGenType}_{appId}内容复制到code_deploy/{deployKey}。 -
更新应用记录:写入
deployKey与deployedTime,返回访问 URL(例如http://{HOST}/{deployKey}/)。
接口与示例请求
-
提交生成:
POST /api/v1/applications/generate(返回taskId或同步结果)。 -
查询状态:
GET /api/v1/applications/{taskId}/status。 -
SSE 流式生成:
GET /api/app/chat/gen/code?appId=...&message=...(Accept: text/event-stream)。 -
部署:
POST /api/app/deploy(body:appId),返回部署 URL。
Curl 流式示例:
# 登录(保存 cookie)
curl -X POST "http://localhost:8123/api/user/login" -H "Content-Type: application/json" -d '{"userAccount":"yupi","userPassword":"12345678"}' -c cookies.txt
# 调用流式接口
curl -G "http://localhost:8123/api/app/chat/gen/code" --data-urlencode "appId=123456" --data-urlencode "message=我需要一个简单的任务记录工具网站" -H "Accept: text/event-stream" -b cookies.txt测试与运维注意事项
-
单元测试:Mock
AIService,覆盖AiCodeGeneratorFacade的不同输出(JSON、分隔符、异常)以验证CodeParser的稳健性。 -
集成测试:验证从生成 → 解析 → 保存 → 部署 的完整链路;测试 SSE 的空格/编码问题与
done事件。 -
可观测性:记录 requestId、耗时、失败率、解析命中率与流式分片日志,便于重解析与故障排查。
-
安全与限流:生成操作成本高,必须与鉴权/限流/计费打通,防止滥用。
总结与后续扩展
本文梳理了将 AI 代码生成功能整合为平台化应用模块的后端实现要点,包括数据模型、流式生成优化、解析与保存策略、以及三种部署方案。后续可扩展方向:
-
应用版本化与多版本部署管理。
-
将静态文件存储迁移至对象存储(COS/S3)并结合 CDN 部署。
-
更完善的
deployKey生成策略与灰度/回滚机制。 -
为高并发场景引入队列(Rabbit/Kafka/Redis)和更细粒度的资源配额控制。
如果需要,我可以将文中示例的 Java 类拆成可直接运行的项目样板(含单元测试、README 与启动脚本),或生成发布到 CSDN 的 HTML/FrontMatter 模板。
🧠🛠️
模块引入(Hook) 搞定了环境配置,接下来我们进入核心:实现"将用户的生成请求交给 AI,引擎渲染结果并可靠落盘"的功能------也就是应用模块的后端职责:接收请求、调度模型(同步/流式)、解析模型输出、持久化并对外提供下载与状态查询。
核心代码解析(The "Meat")⚡
下面只保留含业务逻辑或 AI 交互的关键片段,去掉常规 DTO、Getter/Setter 与框架样板。每段关键行都带中文注释,并在代码块下方解释设计思路。
1) 异步生成与流式生成入口(业务层)
java
// AiAppService.java - 关键方法
public String startAsyncGeneration(GenerateRequest req) {
String taskId = IdUtil.simpleUUID();
taskRepo.createPending(taskId, req); // 保存初始任务元信息
// 异步提交到线程池或消息队列
CompletableFuture.runAsync(() -> {
try {
var result = facade.generateCode(req); // 调用门面,同步生成
var saved = saver.save(result, taskId); // 持久化生成结果
taskRepo.markDone(taskId, saved); // 标记完成并写结果元信息
} catch (Exception e) {
taskRepo.markFailed(taskId, e.getMessage()); // 失败处理
}
});
return taskId;
}
public String startStreamGeneration(GenerateRequest req) {
String taskId = IdUtil.simpleUUID();
taskRepo.createPending(taskId, req);
// 启动流式处理:门面按 chunk 回调,最终聚合解析并保存
facade.generateCodeStream(req, chunk -> {
taskRepo.appendStreamChunk(taskId, chunk); // 实时写入分片(便于 SSE 推送或恢复)
}, finalText -> {
var parsed = facade.parseFinal(finalText); // 对完整文本进行结构化解析
var saved = saver.save(parsed, taskId); // 保存解析后的多文件结果
taskRepo.markDone(taskId, saved);
});
return taskId;
}设计思路:
-
使用
CompletableFuture.runAsync把重任务放到异步执行器或队列,做到 API 快速返回 taskId,避免请求阻塞。 -
对流式生成,实时把分片写入任务仓库(
taskRepo.appendStreamChunk),以支持 SSE 推送、进度查询和失败重试时的重解析。最终再触发结构化解析与持久化,保证"最终一致"的结果状态。
2) AI 调用门面(封装模型交互与解析)
java
// AiCodeGeneratorFacade.java - 门面职责
public MultiFileCodeResult generateCode(GenerateRequest req) {
String raw = aiService.generate(req.prompt, req.options); // 同步拉模型结果
return parser.parseMultiFile(raw); // 统一走解析器
}
public void generateCodeStream(GenerateRequest req, Consumer<String> onChunk, Consumer<String> onComplete) {
aiService.streamGenerate(req.prompt, chunk -> onChunk.accept(chunk), finalText -> onComplete.accept(finalText)); // 将模型流回调透传给业务
}
public MultiFileCodeResult parseFinal(String finalText) {
return parser.parseMultiFile(finalText); // 将完整文本交给解析器做结构化
}设计思路:
-
门面把模型层与解析/持久化完全解耦,便于替换不同 AI 适配器(例如 LangChain4j、OpenAI SDK、私有模型接入)。
-
流式方法保持极简:只负责转发分片和最终文本,业务侧(或
taskRepo)负责缓存与事件广播(SSE/Webhook)。
3) 解析器:优先 JSON -> 回退分隔符解析(鲁棒性)
java
// CodeParser.java - 解析策略
public MultiFileCodeResult parseMultiFile(String raw) {
try {
return JsonUtil.fromJson(raw, MultiFileCodeResult.class); // 尝试严格结构化解析
} catch (Exception e) {
return fallbackParse(raw); // 解析失败再回退
}
}
private MultiFileCodeResult fallbackParse(String raw) {
Map<String,String> files = new LinkedHashMap<>();
String[] parts = raw.split("(?m)^```file:"); // 按约定分隔符拆分多文件
for (String p : parts) {
if (p.isBlank()) continue;
int nl = p.indexOf('\n');
String path = p.substring(0, nl).trim();
String content = p.substring(nl+1);
files.put(path, content);
}
MultiFileCodeResult res = new MultiFileCodeResult();
res.files = files;
res.mainFile = files.keySet().stream().findFirst().orElse(null); // 选第一个作为入口
return res;
}设计思路:
-
解析器采用"宽容优先"的策略:先尝试严格 JSON(便于精确多文件结构),失败则按常见约定(例如 ```file:PATH)回退解析,极大提高对模型输出多样性的容错能力。
-
将解析策略集中在一处,方便扩展:可加入更多策略(正则+语言感知解析、前缀提示词校验等)。
4) 结果持久化(本地示例)
java
// CodeFileSaver.java - 保存逻辑
public String save(MultiFileCodeResult result, String taskId) throws IOException {
Path base = Paths.get("/tmp/ai-gen/" + taskId); // 使用 taskId 生成隔离目录
Files.createDirectories(base);
for (Map.Entry<String,String> e : result.files.entrySet()) {
Path p = base.resolve(e.getKey());
Files.createDirectories(p.getParent()); // 确保目录存在
Files.writeString(p, e.getValue(), StandardOpenOption.CREATE, StandardOpenOption.TRUNCATE_EXISTING); // 写文件
}
Path zip = base.resolveSibling(base.getFileName() + ".zip");
ZipUtil.pack(base.toFile(), zip.toFile()); // 打包供下载
return zip.toString(); // 返回可下载路径或 URL
}设计思路:
-
以
taskId为隔离目录保证并发安全,并使用原子更新(覆盖写)保证幂等性。 -
持久化后返回"可下载的 artifact(zip)",便于前端或下载接口直接提供文件。
技术难点 / 亮点(Highlights)🔍
异步与流式的边界管理:把"分片即时转发"和"最终结构化解析后持久化"分离,可以避免中途失败导致不一致。
CompletableFuture与线程池的使用:必须明确线程池大小与限流策略,否则在高并发下可能导致 OOM 或队列积压。解析鲁棒性:模型输出格式不稳定,优先 JSON 再回退分隔符/正则的策略能显著降低解析错误率。
SSE/回调的容错:流式分片需保留原始日志以便重建最终文本或二次解析(建议将分片持久化到可重放的存储)。
文件落盘并打包:注意目录权限、并发创建父目录的竞态,以及大文件的内存/流式打包实现(避免一次性加载全部内容)。
安全与成本控制:必须和鉴权/限流/计费系统联通,防止被滥用造成费用暴涨或资源耗尽。
技术提示(快捷清单):
-
使用固定线程池并配置拒绝策略,或优先走消息队列(Rabbit/Kafka)做缓冲。
-
流式分片写入时写入有序存储并保留序号,避免乱序导致的错误拼接。
-
为解析器增加观测指标:解析成功率、平均耗时、回退次数。
-
将模型密钥与敏感配置放到配置中心或环境变量中,不要硬编码。
六: 对话历史模块(后端)实战:游标分页、持久化与对话记忆
理解对话历史存储、游标分页、对话记忆(Redis + LangChain4j)和多项工程化实践。
目录
-
目标与背景
-
分页策略:为什么用游标而非 offset
-
数据模型与索引设计
-
后端核心实现要点
-
对话记忆:Redis + LangChain4j 实践
-
AI 服务隔离与缓存优化
-
API 设计与前端对接要点
-
测试、运维与扩展思路
目标与背景
在此前的章节中,AI 生成应用已能产出网站代码,但每次对话互不关联,无法支持基于历史的迭代优化。本模块目标是:
-
持久化保存每次用户/AI 消息(包含失败信息),保证对话完整性;
-
按应用隔离对话数据,删除应用时一并清理历史;
-
提供高性能的分页查询(游标方案),支持"加载更多"滚动历史;
-
提供对话记忆能力(Redis 持久化),使 AI 能基于历史上下文进行多轮优化。
分页策略:为什么用游标
传统 offset 分页在聊天场景会导致两类问题:数据重复/漏取 (因新消息插入)与严重的性能下降 (大偏移量需要跳过大量记录)。因此采用游标分页(使用 createTime 或主键)按时间向前读取更高效且稳定。
示例查询:
java
SELECT * FROM chat_history
WHERE appId = 123 AND createTime < '2025-07-29 10:30:00'
ORDER BY createTime DESC
LIMIT 10;结合复合索引 idx_appId_createTime 可将查询成本压缩到 O(pageSize)。
数据模型与索引设计
推荐表结构(简化):
sql
CREATE TABLE chat_history (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
message TEXT NOT NULL,
messageType VARCHAR(32) NOT NULL, -- 'user'|'ai'
appId BIGINT NOT NULL,
userId BIGINT NOT NULL,
createTime DATETIME DEFAULT CURRENT_TIMESTAMP,
isDelete TINYINT DEFAULT 0,
INDEX idx_appId_createTime (appId, createTime)
);扩展字段建议:parentId(关联用户消息与 AI 回复),fileList(若需保存代码版本,存 JSON 引用)。注意:大文件不要直接存入数据库。
后端核心实现要点
-
消息保存:在用户发送时保存
user消息 ;在AI 流式或最终返回时保存ai消息 ;AI 失败时也需记录错误信息以保持对话完整。 -
关联删除:删除应用时需先删除对应
chat_history(容错处理,删除失败记录日志但不阻塞业务)。 -
游标查询 API:后端提供按
lastCreateTime查询早于该时间的记录 ,限制pageSize(建议 10),返回降序数据,前端反转为升序展示。
Java/伪码要点:
java
// 保存消息
chatHistoryService.addChatMessage(appId, message, ChatHistoryMessageTypeEnum.USER.getValue(), userId);
// 游标查询
Page<ChatHistory> page = chatHistoryService.listAppChatHistoryByPage(appId, pageSize, lastCreateTime, loginUser);前端注意:后端返回按 createTime 降序,前端需要 reverse() 并将老消息置顶。
对话记忆:Redis + LangChain4j 实践
为何使用 Redis:
- Redis 读写延迟低,适合实时对话记忆;内存存储便于 LangChain4j 的 memory 管理;避免频繁访问 MySQL 导致性能瓶颈。
关键实现步骤:
- 引入 LangChain4j 的 Redis 集成依赖(示例):
XML
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>- 在配置中添加 Redis 信息并设置合理 TTL(例如 3600 秒),避免内存无限增长:
XML
spring:
data:
redis:
host: localhost
port: 6379
ttl: 3600- 提供
RedisChatMemoryStore的 Bean 并在 AiService 创建时注入为chatMemoryProvider,为每个appId分配独立的MessageWindowChatMemory(确保 memoryId 唯一):
java
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.id(appId)
.chatMemoryStore(redisChatMemoryStore)
.maxMessages(20)
.build();- 加载历史到 Redis:当需要构造对话记忆时,从数据库加载最近的历史消息并写入 Redis,保证 AI 在内存丢失或过期前能访问到足够上下文。
注意:Redis 存储需要设置过期策略,且敏感信息要审慎存储。
AI 服务隔离与缓存优化
两种隔离策略:
-
方案 A(内置隔离):同一 AI Service 实例,通过
chatMemoryProvider(memoryId)为不同memoryId(即appId)提供独立记忆。 -
方案 B(实例隔离):为每个
appId构建独立的 AI Service(更强隔离),并用 Caffeine 做本地缓存以降低构建成本。
Caffeine 缓存示例策略:最大 1000 条,写入后 30 分钟过期,访问后 10 分钟过期。
API 设计与前端对接要点
-
加入消息:
POST /api/chat/add或在chatToGenCode流式逻辑内自动保存用户与 AI 消息。 -
游标查询:
GET /api/chat/app/{appId}?pageSize=10&lastCreateTime=...返回 Page 数据结构(records 按降序)。 -
管理员接口:分页查询所有对话
POST /api/chat/admin/list/page/vo(需权限)。
前端对接要点:
-
初次进入应用页面:先调用游标查询最新 10 条;若为空且为应用所有者,则自动发送
initPrompt。 -
在流式生成后(SSE 的
done事件),前端应延迟 500ms-1s 再拉取最新历史以确保后端写入完成并可预览生成结果。
测试、运维与扩展思路
-
单元测试:Mock
chatMemoryStore与AiService,验证addChatMessage、游标查询与异常写入逻辑;测试删除应用时的关联清理行为。 -
集成测试:验证完整链路:生成请求 → SSE/流式返回 → 持久化(DB)→ Redis 会话记忆 → 后续调用能读取历史上下文。
-
监控指标:对话写入失败率、游标查询延迟、Redis hit/miss、对话记忆回退次数。
扩展建议:
-
对话历史导出(导出为 JSON/ZIP);
-
智能记忆管理:基于规则或模型自动裁剪记忆(保留关键轮次);
-
多人协作场景:实现多用户参与的对话合并与权限控制;
-
对话版本化并关联生成代码版本。
七: 工程项目生成(后端)实战:从工具调用到可运行工程
介绍如何把 AI 输出升级为可运行的前端工程项目(以 Vue + Vite 为例),涵盖方案选择、工具调用流式处理、文件写入工具、TokenStream 流处理、构建与部署要点。
目录
-
背景与目标
-
方案选型:Markdown / 工具调用 / Agent
-
最终方案与系统提示词设计
-
工具调用与文件写入工具实现
-
流式工具调用的解析(TokenStream / onPartialToolExecution)
-
构建、浏览与部署流程
-
缓存、记忆与多模型策略
-
测试与质量检验
-
实践建议与扩展方向
背景与目标
目标:让平台能生成更复杂的前端工程化项目(如 Vue3 + Vite),并支持流式展示、文件写入、构建与子路径部署,从而提高生成结果的可用性与企业适配度。
挑战点:工程文件数量多、文件层级复杂、AI 流式输出断片、工具调用参数需拼接、需要保证生成后可通过 npm install / npm run build 成功构建。
方案选型
-
直接输出 Markdown:让 AI 在 Markdown 中输出多个代码块并解析为文件。实现简单,但对大文件/多文件场景容错差,易缺失。
-
工具调用(选中方案):为 AI 提供写文件等工具,AI 调用工具写入文件,后端实现工具调用流式回显与保存逻辑,兼顾实时性与可靠性。
-
Agent 模式:先规划再分步执行,步骤清晰、容错好,但架构更复杂,调用次数多,成本高。
由于 LangChain4j 已支持工具调用能力且实现成本较低,最终选择"工具调用 + 流式回显"的方案,并在必要处采用 Agent 风格分步执行。
系统提示词与生成约束
-
定义新的生成模式(例如
VUE_PROJECT),为该模式指定推理流式模型与系统提示词,明确项目结构、依赖版本、Vite base 配置与路由 hash 模式等约束。 -
约束输出文件数与 token 总量,提供 package.json、vite.config.js 范例以降低生成不确定性。
文件写入工具(核心实现)
实现要点:
-
使用 LangChain4j 的 @Tool 注解创建
FileWriteTool,提供writeFile(relativePath, content, @ToolMemoryId appId)方法; -
后端根据
appId构建项目根目录 (例如vue_project_{appId}),把相对路径解析到该目录并写入; -
工具返回相对路径结果,禁止返回服务器绝对路径以避免泄露;写入要创建父目录并以原子方式覆盖文件。
示例(核心片段):
java
@Tool("写入文件到指定路径")
public String writeFile(String relativeFilePath, String content, @ToolMemoryId Long appId) {
Path projectRoot = Paths.get(AppConstant.CODE_OUTPUT_ROOT_DIR, "vue_project_" + appId);
Path target = projectRoot.resolve(relativeFilePath);
Files.createDirectories(target.getParent());
Files.write(target, content.getBytes(), StandardOpenOption.CREATE, StandardOpenOption.TRUNCATE_EXISTING);
return relativeFilePath; // 仅返回相对路径
}流式工具调用的解析与 TokenStream
问题:AI 会将工具调用的 JSON 在流中分片输出(relativePath 与 content 可能被拆开),需要能实时拼接并展示工具调用进度。
解决方案:
-
使用 LangChain4j 的 TokenStream / ChatModel 的流式事件扩展:监听
onPartialToolExecutionRequest、onToolExecuted、onPartialResponse等事件; -
实现一个 Flux/TokenStream 适配器,按工具调用 id 聚合分片,实时构建当前工具调用的参数并推送给前端;
-
在工具真正执行完成(onToolExecuted)时输出最终的写文件结果并在后端持久化为对话历史的一部分。
代码思路(伪):
java
tokenStream.onPartialToolExecutionRequest((index, reqPart) -> aggregateToolCall(reqPart))
.onToolExecuted(toolExec -> persistToolResult(toolExec))
.onCompleteResponse(...)
.start();注意:若 LangChain4j 版本不支持所需事件,可临时覆盖相关源码或使用本地补丁实现回调(教程中有实践案例)。
工程构建、浏览与部署
生成完成后的流程:
-
在项目目录(
vue_project_{appId})执行npm install、npm run build,得到dist目录; -
为了在子路径(
/{deployKey}/)下部署,需在vite.config.js设置base: './',路由使用 hash 模式; -
部署方案同前:Serve(开发预览)、Spring Boot 静态资源代理、或 Nginx 映射(生产首选)。
自动化建议:将安装与构建步骤封装为后端工具或异步任务,记录日志并提供构建状态查询接口。
缓存、记忆与多模型策略
-
对于复杂推理(带工具调用),建议使用专门的"推理流式模型 "(推理模型)以提升准确性;同时保留普通流式/对话模型用于快速调试;
-
AI 服务实例应以
appId + codeGenType为缓存键,通过 Caffeine 缓存避免重复构造,降低开销; -
在创建 AI 服务实例时,为该
appId加载最近对话到MessageWindowChatMemory,保证工具调用时语境一致。
测试与质量检验标准
必须确保:
-
npm install能成功安装依赖; -
npm run dev能启动开发服务器(或npm run build能构建生产版本); -
构建后的
dist能在子路径下正常访问; -
工具调用的写文件操作在流式过程中能被正确聚合与回显。
建议:为 FileWriteTool 与 AiCodeGeneratorFacade.generateVueProjectCodeStream 编写单元/集成测试,模拟工具调用并断言文件写入与流式事件顺序。
实践建议与扩展方向
-
使用项目模板:提供可复用的工程模板,AI 只需在模板上修改与增量写入,能显著提升成功率;
-
对工具调用输出定义标签(如
mc-write,mc-add-dependency)以便前端可视化展示并减少解析复杂度; -
引入 TokenStream 事件监控与日志聚合,便于故障排查与重放;
-
为构建任务提供异步队列与限流,避免主服务阻塞或被滥用。
8: 功能扩展(后端)实战:可插拔架构、插件系统与集成策略
面向希望把 AI 生成功能扩展为可插拔、可集成平台的后端工程师。内容覆盖插件架构、工具/事件体系、安全沙箱、模板与扩展点、监控与运维建议等。
目录
-
目标与动机
-
可插拔架构总览
-
插件契约与清单(manifest)
-
事件总线与扩展点(Hooks)
-
工具/操作调用与沙箱运行
-
扩展的配置、权限与安全
-
模板/脚手架与自定义模板策略
-
集成点:Webhooks、第三方服务与 SDK
-
测试、版本与迁移策略
-
观测、限流与治理
-
总结与实践建议
目标与动机
功能扩展旨在让平台支持第三方或内部按需增加能力(如自定义代码生成器、格式化器、部署器、外部适配器),最小化核心代码改动、提高可维护性与演进速度。
可插拔架构总览
-
内置核心(Runtime):负责鉴权、模型调用、流式转发、持久化与调度;
-
插件层(可热加载/按需启用):实现具体扩展能力(写文件、部署、检测、分析);
-
通信契约:插件通过定义清晰的输入/输出 DTO、事件订阅以及工具调用接口与核心通信。
架构要点:使用基于事件的解耦(Event Bus)与插件注册表(Plugin Registry),插件以声明式 manifest 注册自己的能力与权限。
插件契约与清单(manifest)
每个插件应包含清晰的 manifest.json:
{
"id": "com.example.vue-deployer",
"name": "Vue Deployer",
"version": "1.0.0",
"entry": "com.example.plugins.VueDeployer",
"permissions": ["deploy", "read_project_files"],
"config": { "defaultPort": 8080 }
}清单用于权限审查、配置面板展示与运行时隔离。
事件总线与扩展点(Hooks)
定义平台级事件(例如 onProjectGenerated, onFileWritten, onDeployRequested),插件订阅感兴趣事件并异步处理。事件消息 建议携带 contextId (如 appId / taskId)和可追溯的 requestId,便于审计和重放。
示例事件流程:生成完成 → 发布 onProjectGenerated → 插件 A(自动部署)与插件 B(触发代码扫描)并行处理 → 返回事件结果。
工具/操作调用与沙箱运行
当允许插件执行文件写入、命令或外部部署操作时,必须限制能力范围:
-
以
Tool接口封装敏感操作(写文件、执行 shell、网络访问),核心对工具调用进行权限校验并在受控环境执行; -
对可能暴露的路径做严格映射(只能写入
workspace/{appId}子目录); -
可通过容器/进程隔离或 JVM SecurityManager(或自定义策略)做运行时沙箱。
扩展的配置、权限与安全
-
权限模型:基于最小权限原则,为插件声明
scopes并在安装/启用时审核; -
签名与审计:插件包建议签名,平台保留插件操作日志并支持回滚;
-
配置管理:集中配置中心(或数据库)保存插件配置,并支持按租户/应用覆盖。
模板/脚手架与自定义模板策略
提供可复用的项目模板能大幅提高工程生成成功率。策略:
-
官方模板库+版本管理:维护多个模板(Vue、React、Node CLI),并在生成时选择或作为基线;
-
增量写入:让 AI 修改模板而不是全量生成,减少不确定性;
-
模板参数化:通过占位符与渲染引擎(如 Mustache)注入用户变量。
集成点:Webhooks、第三方服务与 SDK
-
Webhooks:插件或核心在关键事件触发后可推送 webhook,供 CI/CD 或外部系统消费;
-
第三方适配器:为常见服务(S3/COS、Nginx、Serve、云函数)提供官方适配器插件;
-
SDK:提供简洁的插件 SDK(Java/TypeScript),封装事件订阅、工具调用、日志与度量接口,降低插件开发门槛。
测试、版本与迁移策略
-
插件测试:单元测试工具行为、集成测试事件交互与端到端模拟(包括权限/沙箱场景);
-
版本策略:遵循 SemVer,并在 manifest 中声明兼容的核心平台版本;
-
迁移支持:核心在升级时提供兼容层或迁移工具,插件可声明迁移脚本。
观测、限流与治理
-
指标:记录每个插件的调用次数、平均耗时、失败率、资源消耗;
-
限流与配额:为高成本插件(模型调用/构建)设置并发与速率限制,结合队列进行流量削峰;
-
异常隔离:插件异常应被捕获并降级,不影响核心服务可用性(使用 Circuit Breaker/隔离线程池)。
总结与实践建议
-
从最小插件能力开始(例如只读、写入受限目录),逐步放开权限并增强审核;
-
优先提供模板与官方适配器,降低第三方插件失败率;
-
在设计时把安全、审计与限流作为核心需求,不可折中;
-
提供良好的 SDK、示例与单元测试框架,让插件生态健康发展。
九: 可视化修改(后端实现)实战:选择元素、工具链与增量修改策略
基于第9章"可视化修改"提取内容,聚焦可视化编辑功能的后端实现要点、工具设计、提示词与安全策略。面向希望把 AI 生成的网站支持"点击选中元素 → 精确修改"能力的后端工程师。
目录
-
背景与目标
-
需求摘要
-
总体方案与权衡
-
前端与后端的边界(通信与注入策略,后端准备工作)
-
后端能力设计:工具集合与 ToolManager
-
提示词与 AI 流程要点(避免幻觉与保持稳定)
-
流式生成 / SSE 与修改流程示例
-
安全、审计与回滚策略
-
测试与上线注意事项
-
小结与实践建议
背景与目标
目标:为 AI 零代码应用生成平台增加"可视化修改"能力,用户可在预览页面上直接选中元素并通过提示词指导 AI 对指定位置做精确修改,降低文字歧义导致的误改。
核心思路:前端负责通过 postMessage 将选中元素的最小语义信息(selector、tag、text、bounding rect、pagePath)上报给后端;后端在收到用户提示词时,把选中元素信息拼接进提示词/上下文,驱动 AI 调用后端工具对项目源码做增量修改或全量替换。
需求摘要
-
支持点击选中单个元素并把最小定位信息发送到后端;
-
对原生 HTML 小型站点允许全量替换式修改(通过更严格的提示词控制解析规则);
-
对大型 Vue 等工程采用"工具链"做增量修改(读文件、遍历目录、修改/写入/删除单文件);
-
输出要便于前端展示:工具调用结果应包含文件路径、旧内容、替换后内容等结构化信息;
-
强调安全:只允许操作
workspace/{appId}子目录,禁止删除重要文件。
总体方案与权衡
竞品启发:美团 NoCode 与百度秒哒分别采取了"完整文件提交后端整体修改"和"只传选中容器片段并让后端处理"的策略。权衡后推荐:
-
对小型原生站点可使用全量替换,但必须在提示词中强制解析规则;
-
对工程化项目(Vue)采用工具化增量修改,减少网络与计算开销并提升修改准确度;
-
不建议将整个项目源文件全部发送给后端以避免传输/隐私/效率问题。
前端与后端的边界(后端准备工作)
后端需要提供:
-
接受前端发送的"选中元素元数据 + 用户提示词"的 API(或通过现有 chat/gen 接口在发送消息时一起传参);
-
一套可被 AI 驱动的工具接口(见下文),工具调用应可被 AI 以 JSON 方式请求;
-
工具执行结果的结构化输出(便于前端按照文件/差异展示);
-
适配 SSE/流式响应的能力,确保前端能实时看到 AI 的修改建议与工具调用进度。
实现要点(后端):
-
校验并白名单 化可操作目录(
workspace/{appId}); -
对工具操作做权限与速率限制;
-
将工具调用记录到审计日志(便于回滚)。
后端能力设计:工具集合与 ToolManager
建议按单一职责将工具拆分为独立类,并通过 ToolManager 统一注册与分发:
-
FileReadTool:读取单文件内容(返回文件相对路径 + 内容); -
FileDirReadTool:列出某目录下文件结构(便于 AI 了解工程组织); -
FileWriteTool:创建/写入文件; -
FileModifyTool:基于旧内容做精确替换(返回旧/新内容对比); -
FileDeleteTool:删除文件(需严格保护名单);
工具基类示例(伪代码):
public abstract class BaseTool {
public abstract String getToolName();
public abstract String generateToolExecutedResult(JSONObject arguments);
}ToolManager 要点:在 Spring 环境中自动注入所有工具 Bean,初始化时将工具按名字注册到 Map,以便根据 AI 的工具调用请求调度对应工具实例。
提示词与 AI 流程要点(避免幻觉)
-
提醒 AI 使用工具接口而非凭空生成文件路径/行号;
-
对于原生 HTML,需要在提示词底部加入"特别注意:如何解析代码块/保持不修改的区域"等规则;
-
对于工程化项目,提供工具使用示例到提示词(例如如何调用
readFile、modifyFile); -
对工具调用结果要求结构化输出(例如 JSON 包含
toolName、relativeFilePath、oldContent、newContent),并在后端做格式校验。
提示词安全建议:在提示词中明确禁止 AI 执行高风险文件操作(例如删除重要配置文件),并在后端做二次校验。
流式生成 / SSE 与修改流程示例
后端可沿用已有的 SSE 流式接口(项目中已有示例:/app/chat/gen/code?appId=...&message=...),示例流程:
-
前端构建消息:包含
message(用户输入)和可选selectedElementInfo(selector/text/pagePath); -
后端 AI 服务在流式会话中解析消息并根据需要发起工具调用请求;
-
每次工具执行,后端将工具执行结果以特定事件或 JSON 片段返回给前端,前端据此展示文件/差异;
-
当工具链执行结束,后端触发
done事件,前端可在短延时后刷新预览(如静态预览 URL)。
示例:EventSource 连接(前端)会接收 onmessage 的 JSON 包含 d 字段流式拼接文本,以及 done 事件用于标识完成。
安全、审计与回滚策略
-
目录限制:任何写/改/删操作必须把路径映射到
workspace/{appId}下; -
白名单与黑名单:实现不可删除的"重要文件"名单(例如 package.json、vite.config.js、index.html 等);
-
操作审计:记录每次工具调用参数与结果,支持回滚脚本(基于旧内容恢复);
-
权限控制:对高权限操作(deploy、网络访问)要求人工授权或管理员审计。
测试与上线注意事项
-
工具单元测试:为每个工具编写单元测试(正常/边界/异常路径);
-
集成测试:模拟 AI 调用工具的完整交互,校验工具输出格式,测试多轮工具调用场景;
-
回归测试:保证提示词优化后不会导致全站被替换的回归;
-
负载与限流:对高并发场景(大量 model 调用、文件 I/O)做并发限制与队列化处理。
示例后端代码片段(关键要素)
FileModifyTool(核心逻辑简要):
java
public String modifyFile(String relativeFilePath, String oldContent, String newContent, Long appId) {
Path path = resolveAppPath(relativeFilePath, appId);
if (!Files.exists(path)) return "错误:文件不存在";
String original = Files.readString(path, StandardCharsets.UTF_8);
if (!original.contains(oldContent)) return "警告:未找到要替换的旧内容";
String modified = original.replace(oldContent, newContent);
Files.writeString(path, modified, StandardOpenOption.TRUNCATE_EXISTING);
return "文件修改成功: " + relativeFilePath;
}ToolManager 注册示例:
java
@PostConstruct
public void init() {
for (BaseTool tool : tools) {
toolMap.put(tool.getToolName(), tool);
}
}AI Service 构建(注入工具):
java
AiServices.builder(AiCodeGeneratorService.class)
.tools(new FileWriteTool(), new FileReadTool(), new FileModifyTool(), new FileDirReadTool(), new FileDeleteTool())
.build();扩展思路
-
将"创建"和"修改"两个流程拆分不同的 AI Service,以减小工具集合并减少幻觉风险;
-
优化工具流式输出格式,使前端能以 Tab 展示多文件差异(同美团示例);
-
支持用户上传媒体并把链接一并作为修改上下文发给后端;
-
在未来可探索更细粒度的流式代码写入,但需后端/前端共同约定解析规范。
小结与实践建议
-
对于可视化修改,首选方案是"前端上报最小元素信息 + 后端工具化增量修改";
-
对工程化项目必须依赖工具集合(读/写/改/删/列目录),并把工具的能力以结构化结果返回给前端;
-
安全(路径限制、重要文件黑名单)、审计与回滚是上线前必须保障的要素;
-
在提示词中清晰约束 AI 的修改行为,结合后端二次校验,能显著降低错误修改概率。
第10章:AI 工作流(后端实现要点)
摘要:本章介绍基于 LangGraph4j 的 AI 工作流实现思路,聚焦后端架构、状态管理、节点实现、工具集成、并发与质量检查、流式输出(Flux/SSE)以及在 Spring Boot 中的集成与测试要点。
一、为什么用工作流
-
对于可标准化的生成步骤(如图片收集、提示词增强、代码生成、质检、构建),把流程写成工作流可以降低随机性、提升可维护性和可视化能力。
-
相比低代码平台,编程框架(LangGraph4j)更利于与现有 Spring Boot 服务深度集成,支持复杂条件、循环与并发,便于长期演进。
二、核心概念速览(后端关心的点)
-
StateGraph:工作流的有向图抽象,编译后得到不可变的 CompiledGraph,可流式执行。
-
AgentState / WorkflowContext:状态载体,业务侧建议定义自己的
WorkflowContext类并作为 AgentState 的一个字段来管理复杂状态。 -
Nodes:每个节点实现具体业务(可同步或异步),输入为当前状态,输出为对状态的更新。
-
Edges(普通/条件/并发边):边负责流程控制 ,条件边用于路由决策 ,Parallel/子图用于并发和复用。
-
Checkpoints:持久化检查点支持"人在环路"和恢复执行,生产环境需使用持久化存储(如 PostgreSQL)。
三、后端实现要点
1) WorkflowContext 结构
-
包含原始提示词
originalPrompt、增强提示enhancedPrompt、图片资源集合imageList、生成类型generationType、生成目录generatedCodeDir、构建结果buildResultDir、质检结果qualityResult等字段。 -
以 POJO/Serializable 形式存放,且在 MessagesState 中以固定 key 保存,便于 LangGraph4j 节点读取/更新。
2) 节点设计原则(可复用的后端节点)
-
单一职责:每个节点只做一件事(图片收集 / 提示词增强 / 路由 / 代码生成 / 质检 / 构建)。
-
可测试:先用 Mock 数据实现节点,编写单元测试验证状态流转,再替换为真实实现。
-
Spring 集成:节点内部通过静态工具获取 Spring Bean(例如
SpringContextUtil.getBean(...)),避免对框架强耦合。
3) 条件路由与循环
-
条件边用于流程决策 (例如根据
generationType决定是否进入构建节点)。 -
质检失败时通过条件边回到代码生成节点,实现自动修复循环(代码生成 → 质检 → 失败→ 重新生成)。
4) 并发实现选型
-
方案 A(推荐简单):节点内部使用
CompletableFuture并发调用多个工具(实现成本低、易测试)。 -
方案 B:使用 LangGraph4j 的 Parallel Branch(框架级并发,适用于需要可视化并发分支的场景,需配置线程池)。
-
方案 C:将重复逻辑拆成子图(子图可复用、便于模块化),适合大型项目。
5) 图片收集与外部工具集成(后端实现细节)
-
工具举例:Pexels(内容图)、Undraw(插画)、Mermaid CLI(架构图)、DashScope/百炼(Logo/生成图)。
-
图片收集流程:先用 AI 规划图片任务(ImageCollectionPlan),再并发执行各类工具,最后聚合为
imageList。 -
注意:外部 SDK/API 的速率限制、超时与重试策略需在工具层实现。
6) 代码生成与流式输出
-
代码生成节点调用
AiCodeGeneratorFacade,获取Flux<String>的流式输出并blockLast/或在流中处理保存操作。 -
若要给前端实时推送生成进度,后端可实现两个接口:Flux(返回
MediaType.TEXT_EVENT_STREAM_VALUE)或 SSE(SseEmitter)。Flux 推荐在响应式栈或 WebFlux 中使用;SseEmitter 在传统 Spring MVC 中可用。
7) 代码质量检查(QualityResult)
-
读取生成目录,拼接关键代码文件内容交给 AI 进行检查,返回结构化
QualityResult{isValid, errors, suggestions}。 -
工作流中将质量检查设为独立节点,之后通过条件边决定是进入构建还是回到代码生成并附带修复提示词。
四、运行与调度建议
-
WorkFlow 编译时需做结构校验(检查孤立节点、循环错误等),生成
CompiledGraph后再执行。 -
执行上下文中尽量传入
appId/threadId等信息,便于多用户并发和后续恢复。 -
如果需要人工审核环节,启用 Checkpoint + Breakpoint,并通过 UI 提供 resume 接口(GraphInput.resume)。
五、测试覆盖策略(后端)
-
单元测试:每个工具类(图片搜索、Mermaid 转图、Logo 生成)和节点(ImageCollectorNode、PromptEnhancerNode 等)均要有 mock 测试。
-
集成测试:以
CodeGenWorkflowTest、CodeGenConcurrentWorkflowTest验证工作流端到端状态流转与并发逻辑。 -
性能测试:对图片并发收集、代码生成流式输出进行耗时对比(可用
StopWatch采样)。
六、运维与监控要点
-
日志:节点级别日志记录输入/输出与失败信息,必要时保存节点执行快照以便回溯。
-
指标:记录每次工作流执行耗时、各节点耗时、图片收集数量、质检失败率等;上报 Prometheus/Grafana。
-
错误处理:工具层实现幂等、限流与重试(指数退避),对外部服务错误进行降级策略(例如图片失败时回退占位图)。
七、配置与依赖(实用信息)
-
推荐 LangGraph4j 版本:
1.6.0-rc2(示例中用于并发/Studio 支持)。 -
关键依赖:
langgraph4j-core、langgraph4j-studio-springboot(可选)、AI SDK(如百炼/DashScope)、HTTP 客户端工具库(Hutool/OkHttp)。 -
本地工具:
mermaid-cli用于生成架构图,建议在 CI/CD 环境预装。
八、代码示例(后端要点示例)
-
建议实现小而清晰的节点工厂,例如:
ImageCollectorNode.create()、PromptEnhancerNode.create(),节点内部通过SpringContextUtil.getBean(...)获取服务。
java
流式接口示例(概念性):
@GetMapping(value = "/workflow/execute-flux", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> executeWorkflowWithFlux(@RequestParam String prompt) {
return new CodeGenWorkflow().executeWorkflowWithFlux(prompt);
}九、常见坑与实践建议
-
避免把所有逻辑"交给 AI 决定":对可标准化的步骤(图片收集计划、构建流程)最好显式写入工作流,减少随机性。
-
并发实现需关注版本与线程池配置:早期 LangGraph4j 版本并发支持不完整,务必按示例配置
RunnableConfig与线程池。 -
结构化输出并非万能:不同模型对 JSON Schema 支持差异较大,实际工程中可选择"非结构化文本 + 解析"作为兼容方案。
第11章:系统优化(后端要点)
摘要:本章把已经能跑的 AI 零代码平台,推进到生产级别的优化实践,覆盖性能(并发、缓存)、实时性(预览/构建)、安全(限流、Prompt 审查)、稳定性(重试/护轨/工具调用保护)和成本控制等后端关注点与实现细节。
一、性能优化
1. AI 并发调用 --- 问题与解决
-
问题:ChatModel 单例 + 底层同步解析导致多个用户请求串行化,出现第一个请求占用资源、后续阻塞的现象。
-
方案:采用多例(prototype)或工厂模式为每次 AI 调用创建独立的 ChatModel/StreamingChatModel 实例。
-
在配置类中使用
@Scope("prototype")创建模型 Bean(如streamingChatModelPrototype、reasoningStreamingChatModelPrototype)。 -
在工厂/Service 创建处通过
SpringContextUtil.getBean("xxxPrototype", StreamingChatModel.class)动态获取新实例注入到 AiServices。
-
-
测试:使用虚拟线程(Java 21)或并发单元测试验证路由与生成服务并行执行。
2. Redis 缓存优化
-
场景:缓存主页前 N 页的精选应用,采用旁路缓存(先查缓存,未命中查 DB 并写缓存)。
-
实现要点:
-
缓存键统一由工具类生成 ,避免过长:
CacheKeyUtils.generateKey(obj)(JSON -> MD5)。 -
配置
RedisCacheManager:设置 key 序列化(String)、value 使用 JSON 序列化(GenericJackson2JsonRedisSerializer)并为特定缓存区域设定差异化 ttl(如good_app_page5分钟)。 -
在接口上使用
@Cacheable(value = "good_app_page", key = "T(...).generateKey(#req)", condition = "#req.pageNum <= 10")。
-
-
注意:合理设置 TTL、处理缓存穿透/击穿/雪崩,以及在复杂对象序列化时保证可反序列化类型信息。
二、实时性优化(网站预览)
-
问题:Vue 工程生成需安装依赖并构建,导致用户看到 AI 输出时页面仍不可用(时间差)。
-
方案对比:同步构建、前端轮询、SSE/ WebSocket 推送构建进度、集成 Vite Dev Server。
-
推荐:对于生产可接受的延迟,直接把 Vue 项目构建改为同步步骤(在流式响应结束前执行构建),或使用 SSE/Flux 推送构建进度并在构建完成后通知前端刷新。
-
补充:提供
GET /build/status/{appId}接口查询构建状态;或用 SSE 推送business-error/step_completed等自定义事件。
三、安全性优化
1. 流量保护(分布式限流)
-
使用 Redisson 的分布式限流器(令牌桶
RRateLimiter)实现多维度限流(API / USER / IP)。 -
设计:自定义
@RateLimit注解 +RateLimitAspect切面,运行时生成限流 key(如rate_limit:user:{userId}或rate_limit:api:Class.method)。 -
失败处理:抛出业务异常(如 429),并在 SSE 场景通过全局异常处理器把限流信息以 SSE 事件格式返回给前端。
2. Prompt 审查(输入护轨)
-
在把用户 prompt 交给 LLM 前,使用 Input Guardrail 检查:长度、敏感词、注入模式(如
ignore previous)等。示例:PromptSafetyInputGuardrail返回fatal(...)拒绝或success()。 -
可扩展:接入内容安全服务(阿里云/其他)或用 AI 模型做更智能的检测;使用配置中心(Nacos)动态热更敏感词。
四、稳定性优化
1. 重试策略与输出护轨
-
LangChain4j 支持模型层面的
maxRetries配置;也可用 Output Guardrail 检查响应并决定retry()、reprompt()或fatal()。 -
注意:输出护轨的重试会影响流式输出体验(通常会等待最终结果才返回),因此在需要实时流式展示时谨慎使用。
2. 防止工具调用无限循环
-
方案 A(简单):设置
maxSequentialToolsInvocations(20)限制单次对话工具连续调用次数。 -
方案 B(优雅):实现一个
ExitTool,由 AI 在合适时机主动调用以结束工具调用流程。
五、成本优化
-
通过分层模型策略降低成本:为轻量任务(智能路由/分类)选择低成本模型(如
qwen-turbo),为复杂推理/代码生成使用高质量模型。 -
针对热点 Prompt 或相似输入进行缓存,减少重复调用;统计用户调用量、token 消耗,按用户/项目做配额与限额。
-
定期清理 COS 临时文件、对长期不访问的文件做归档或删除以节约存储成本。
六、运维与监控要点(简要)
-
日志:节点级别日志、工具调用与错误堆栈;记录护轨拦截/限流事件以便审计。
-
指标:工作流执行耗时、各节点耗时、并发数、质检失败率、AI 调用次数和 token 用量(上报到 Prometheus/Grafana)。
-
安全:对限流、异常信息做告警;对异常率/失败模式做自动打点和报警策略。
七、示例代码片段(关键位置)
@Scope("prototype")的模型配置示例(略)------用于避免 ChatModel 单例导致的并发阻塞。
CacheKeyUtils.generateKey(obj):JSON -> MD5 保证 key 唯一且长度可控。
@Cacheable(...)与RedisCacheManager的差异化 ttl 配置。
@RateLimit(...)注解 +RateLimitAspect:RedissonRRateLimiter的令牌获取逻辑。
PromptSafetyInputGuardrail:输入长度/敏感词/注入模式检测。
12 部署上线(后端方向)
摘自"12 - 部署上线"节,聚焦后端部署与上线实践,省略前端细节。目标:快速把后端服务稳定、安全地推向线上。
本节要点
-
服务器初始化与权限、面板(示例:1Panel)使用
-
环境依赖:JDK、Maven、Node、MySQL、Redis、Chrome(Selenium)
-
后端部署:Jar 包运行、进程管理、Nginx 反向代理、生产配置
-
数据库与缓存:建库、配置、密码与远程访问
-
部署验证、日志与回滚思路
-
扩展:Docker / Docker Compose(项目场景下为扩展知识)
一、部署前的规划(必须)
-
明确部署组件:后端服务(Jar)、数据库(MySQL)、缓存(Redis)、反向代理(Nginx)、对象存储(COS)等。
-
端口与路径规划:后端实际运行端口(例:8123),通过 Nginx 统一对外暴露并以
/api前缀转发。 -
配置与密钥清单:所有生产密钥、数据库账号、对象存储 Key 等必须列入清单,并准备好安全存储方式(详见配置节)。
二、服务器与环境初始化
-
选型建议:轻量云服务器(≥2 核、≥2G 内存),使用熟悉的运维面板加速配置(示例:1Panel)。
-
基本安装:开启必要防火墙端口(HTTP/80、数据库/3306、Redis/6379 等仅在需要时开放)、安装 OpenResty/Nginx、MySQL、Redis。
-
运行环境:安装 JDK 21、Maven(可选,用于服务器端构建)、Node.js/NPM(后端需能执行 npm 命令用于构建/截图等)、Chrome(Selenium 截图)。
-
注意:在服务器上手动安装 JDK/Node 能保证后端进程可以从 Java 中调用终端命令(避免面板内受限环境)。
三、后端部署流程(推荐步骤)
-
生产配置:准备
application-prod.yml/application-prod.properties,包含数据库、Redis、对象存储与模型服务 Key;把该文件加入.gitignore。 -
本地或 CI 打包:在本地或 CI 中执行
mvn -DskipTests package得到可运行的*.jar。 -
上传与运行:将 jar 上传到服务器指定目录(例如
/project/yu-ai-code-mother-backend),先在前台验证java -jar app.jar --spring.profiles.active=prod,再用后台启动命令运行(或使用系统服务管理)。-
简易后台启动:
nohup java -jar app.jar --spring.profiles.active=prod > app.log 2>&1 & -
更稳健:建议使用
systemd单元或进程守护工具(例:supervisord、pm2-like 进程管理)来管理启动/重启与日志。
-
-
日志与持久化:确保日志文件写在持久目录并按需切割,避免容器/临时目录丢失日志。
四、Nginx 反向代理与 SSE 配置
-
Nginx 负责:静态文件托管、反向代理
/api至后端、处理跨域与同源问题。 -
反向代理示例(关键点):
-
转发
/api到http://127.0.0.1:8123 -
对 SSE(长连接)需要调整 proxy 超时和缓冲:
proxy_read_timeout、proxy_buffering off等以避免流式超时。
-
-
在面板中创建站点并设置反向代理或在 Nginx 配置内手动增加对应
location。部署后用curl/浏览器测试http://{域名}/api/doc.html。
五、数据库与缓存(MySQL / Redis)
-
数据库:安装 MySQL 8.x、创建生产库(如
yu_ai_code_mother)并执行初始化 SQL;限制对外访问并只在需要时开放端口。 -
Redis:安装并设置密码,后端配置中提供密码与(必要时)默认用户名映射。
-
迁移策略:在生产部署前运行数据迁移工具(Flyway / Liquibase)或使用 SQL 脚本在 CI 中自动执行。
六、应用生成文件的部署(AI 生成内容)
-
文件路径约定:后端需要将 AI 生成的网站文件写入可被 Nginx 访问的目录(示例:
/www/sites/yu-ai-code-mother/tmp),或通过上传到对象存储后返回可访问 URL。 -
权限与隔离:避免将敏感写入目录暴露到公共目录,使用合适权限与定期清理策略。
七、测试验证(上线检查清单)
-
基本功能:用户注册/登录、API 文档可达、核心接口返回正常。
-
运行时检查:查看后端日志无异常、应用能正确读取数据库与 Redis。
-
生成流程:AI 生成网站 -> 保存到部署目录 -> Nginx 能访问生成页面。
-
性能烟雾测试:简单并发请求(数十并发)验证无明显内存泄露或阻塞。
八、回滚与发布策略
-
简单策略:保留最近若干个 jar 包与数据库备份;出现问题时快速替换 jar 并重启服务。
-
进阶策略:蓝绿/金丝雀发布(若使用容器编排或负载均衡器),结合 feature flag 实现逐步放量。
九、监控、告警与日志聚合
-
监控:推荐引入 Prometheus + Grafana 监控 JVM、请求 QPS、延迟、错误率、内存与线程数。
-
日志:集中化日志(ELK / Loki / 云日志)以便查询与告警。
-
链路追踪:可接入 Jaeger/Zipkin 做请求链路追踪,便于排查分布式调用问题。
十、安全与运维要点
-
配置与密钥:不要在源码库提交生产配置或 Key,使用 Vault / 云 KMS / 环境变量管理敏感信息。
-
最小权限:数据库与对象存储账号只授予必要权限。
-
防火墙与 WAF:关闭不必要端口,必要时接入 WAF 做应用层防护。
十一、扩展知识:Docker / Docker Compose(可选)
-
本项目场景下:制作完整 Docker 镜像成本较高且可能引起资源问题,故不推荐作为默认方式;
-
若需容器化:推荐采用多阶段构建(先在构建阶段打包 jar,再在运行阶段仅拷贝 jar),或使用 CI 构建镜像并推送到镜像仓库,生产环境使用容器编排以支持滚动升级与副本伸缩。
十二、常用命令速查
-
后台运行:
nohup java -jar app.jar --spring.profiles.active=prod > app.log 2>&1 & -
查看日志:
tail -f app.log -
重启服务:
pkill -f 'app.jar' && nohup java -jar app.jar ... & -
Nginx 重载:
nginx -s reload(或面板中的重载按钮)
13 可观测性(后端方向)
聚焦后端可观测性实践:日志、指标、追踪、告警与可视化(Prometheus + Grafana / ARMS)。
本节要点
-
可观测性三大支柱:日志(Logs)、指标(Metrics)、追踪(Traces)。
-
指标分层:系统指标、应用指标、业务指标;关注百分位(P50/P90/P99)。
-
推荐方案:ARMS(探针无侵入接入)用于系统级监控;Prometheus + Grafana 用于自定义业务监控。
-
关键实践:Micrometer + Spring Boot Actuator、/actuator/prometheus、PromQL 指标聚合与告警。
一、为什么需要可观测性
-
通过外部输出(日志/指标/追踪)推断系统内部状态,定位性能瓶颈与异常。
-
对 AI 平台,还需关注模型调用次数、Token 消耗、模型响应时间与失败率等业务指标。
二、可观测性数据分类
-
系统指标:CPU、内存、磁盘、网络等基础资源。
-
应用指标:接口响应时间、QPS、错误率、JVM 指标(堆、GC、线程)。
-
业务指标:模型调用量、Token 消耗、用户活跃度、应用/模型维度的统计。
-
调用链(Trace):完整请求链路与各 Span 的耗时,有助于查找分布式调用瓶颈。
三、常用概念简要(快速参考)
-
维度(Dimension):用于切分和筛选的数据标签(如 user_id、app_id、model_name)。
-
指标(Metric):可量化的数值 ,如
requests_total、response_time_seconds、tokens_used。 -
百分位:P50/P75/P90/P95/P99,关注尾延迟时需看 P95/P99。
四、ARMS(阿里云监控)接入要点
-
优点:无侵入式(Java Agent 探针)接入,开箱即用,快速获得调用链、异常分析、SQL 慢查询等能力。
-
缺点:云服务有费用,按需开启采样与高级功能以控制成本。
-
使用步骤(概要):下载 Java Agent、在 JVM 启动参数中添加
-javaagent与 license、设置-Darms.appName等,然后启动应用并在控制台查看指标与调用链。
五、Prometheus + Grafana(自研/开源方案)
-
适合自定义业务指标、灵活查询与可移植性强的场景。
-
核心组件:Prometheus Server(拉取 /metrics)、Exporter(如 node_exporter、mysql_exporter)、Alertmanager、Grafana。
-
指标类型:Counter(累加)、Gauge(可波动)、Histogram / Summary(分布/百分位)。
-
推荐在 Spring Boot 中引入:
spring-boot-starter-actuator、micrometer-core、micrometer-registry-prometheus,并暴露/actuator/prometheus。
六、指标设计(针对 AI 平台的建议)
-
必备业务维度:
app_id、user_id、model_name、request_id、generation_type。 -
核心业务指标示例:
-
ai_model_requests_total{model="deepseek"}(Counter) -
ai_model_response_seconds(Histogram) -
ai_model_tokens_input_total,ai_model_tokens_output_total(Counter) -
ai_model_failures_total{reason="timeout"}(Counter)
-
-
注意:在设计时既要覆盖聚合场景(趋势/排行),也要保留足够的维度以便下钻分析。
七、埋点与上下文传递
-
在业务层埋点收集原始事件(最细粒度),后端用 Listener/Interceptor 将上下文(如
appId/userId/requestId)通过 ThreadLocal 传递给监控逻辑。 -
建议实现一个
MonitorContext+MonitorContextHolder来集中管理监控上下文,执行请求结束后务必清除 ThreadLocal。
八、调用链追踪与日志关联
-
使用 Trace ID (或 requestId)把日志、指标、追踪串联起来,保证日志能通过 Trace ID 快速定位到对应的 Span 与请求。
-
分布式追踪工具:Jaeger / Zipkin / ARMS Trace。对 AI 工作流类场景,追踪每个模型调用和工具调用的 Span 有利于定位长尾延迟。
九、告警与分级
-
常见告警规则:接口 P95/P99 超阈值、错误率大于阈值、慢 SQL 次数异常、JVM 内存/GC 警报。
-
告警配置应分级(紧急/高/中/低),避免告警疲劳。告警通知支持邮件、钉钉/企业微信、Webhook 等。
十、可视化与仪表盘构建
-
常见仪表盘模块:服务概览、请求性能、模型调用概览、Token 消耗排行、错误与异常跟踪、实例资源监控。
-
Grafana 支持 JSON 导入/导出,可在多个环境复用看板模板。
十一、运维实践与成本控制
-
采样率管理:对追踪与日志设置合理采样,保留完整指标同时控制存储成本。
-
指标保留与聚合:对长期趋势数据做下采样与归档(Prometheus 可结合 Thanos / Cortex 做长期存储)。
-
监控等级策略:开发环境与生产环境的采集粒度不同,生产环境优先保障关键业务指标。
十二、快速接入示例(Spring Boot)
- 依赖(pom.xml):
- 配置(application.yml):
management:
endpoints:
web:
exposure:
include: health,info,prometheus- 自定义指标示例(伪代码):
Counter requests = Counter.builder("ai_model_requests_total")
.description("Total AI model requests")
.tag("model", modelName)
.register(meterRegistry);
requests.increment();- 暴露指标:
http://{host}:{port}/actuator/prometheus,然后在 Prometheus 配置中加入该目标。
十三、总结与建议
-
对于快速落地:若使用云服务(如 ARMS),可以最快获得全套监控能力;若追求可控与可移植,采用 Prometheus + Grafana + Micrometer。
-
监控设计要把业务场景放在首位:设计关键业务指标、合理划分维度、并保证日志与追踪能串联起来。
-
注重成本控制:合理采样、分级告警、指标下采样与归档策略。
文件位置:e:\pdf\13-可观测性-博客章节.md