应达宇1,2,0009−0001-9080-316X,宣嘉琪1,2,0009−0009-4375-0104,史书慧1,2,009−0007-4786-2635,滕宣宇1,2,0009−0004-8602-7016,徐舒扬1,2,0000-0002-0409-8928,童冠超1,2,*0000-0002-3503--2745
1温州肯恩大学,中国浙江温州325060,大学路88号
2美国肯恩大学,美国新泽西州尤宁市07083,莫里斯大道1000号
{yuying,xuanji,shishu,tengx,shuxu,tguancha}@kean.edu
https://arxiv.org/pdf/2601.11640
摘要
边缘设备上的农业杂草检测受限于严格的模型容量、计算资源和实时推理延迟约束,这使得通过模型扩展或集成来提升性能变得不可行。本文提出模型驱动数据校正(MDDC),一种以数据为中心的框架,通过迭代诊断和校正数据质量缺陷来提升检测性能。一个自动化错误分析流程将检测失败分为四种类型:假阴性、假阳性、类别混淆和定位错误。这些错误模式通过一个结构化的训练-修复-再训练流程以及版本控制的数据管理得到系统性的解决。在多个杂草检测数据集上的实验结果表明,使用一个固定的轻量级检测器(YOLOv8n),mAP@0.5能够持续提升5%-25%,这表明在固定的模型容量约束下,系统性的数据质量优化能够有效缓解性能瓶颈。
关键词: 数据清洗 · 目标检测 · 置信学习
1 引言
精准杂草管理(PWM)已成为现代农业的关键发展方向,旨在通过精确、实时的田间感知实现定点杂草控制,从而减少除草剂使用和环境影响1,5,8,11,18。随着深度学习的快速发展,卷积神经网络通过提升特征表示能力、鲁棒性和部署效率,显著推动了目标检测技术在农业场景中的应用6,8,13,15。在现有的检测器中,YOLO系列因其在精度、推理速度和计算效率之间良好的权衡而成为田间杂草检测的主流解决方案,特别适合在资源受限环境下实时部署16,19。尽管取得了这些进展,实际的农业环境------具有复杂背景、有限标记样本和跨区域多样性等特点------仍然对模型的鲁棒性和泛化能力构成重大挑战。
在现实世界的农业应用中,严格的硬件约束和实时性要求通常需要使用轻量级单阶段检测器,这限制了增加模型容量或替换已部署架构的可行性2,3,14,22。越来越多的研究和实证证据表明,在模型容量受限的情况下,性能瓶颈往往源于数据质量而非模型本身,这促使研究焦点从以模型为中心的优化转向系统性的以数据为中心的改进策略。然而,当前提升数据质量的方法面临几个关键局限。首先,识别预测错误的根本原因(例如标签噪声、样本偏差、分布不平衡或边缘情况覆盖不足)通常是临时的、依赖经验的,且高度依赖人工检查(即,通过修复数据集来修复模型)。其次,没有系统的数据管理和版本控制,很难追踪数据发生了哪些变化,以及这些变化如何影响不同训练迭代中的模型性能4。第三,现有的数据集优化工作流程通常缺乏可重复性和标准化,这阻碍了团队协作和大规模部署17,21。
为了克服上述局限性,本文提出一种在模型改进受限条件下的主动目标检测方法------特别是在基于边缘设备的农业部署中------采用结构化、以数据为中心、模型驱动的优化工作流程,而非仅仅扩大模型规模或调整超参数,代表了提升检测精度、鲁棒性和真实世界泛化性能更有前景的方法7,23,24。
本研究的主要贡献总结如下:
(1)我们提出一个名为模型驱动数据校正(MDDC)的集成化以数据为中心的目标检测框架,它将基于YOLO的检测器与聚类级离群点检测相结合,以系统性地识别和校正杂草检测数据集中的标注噪声。
(2)我们通过多个数据集和分析验证了所提框架的有效性和泛化能力,为其未来在更多目标识别任务中的应用做好准备。
本文其余部分组织如下。第2节回顾相关工作。第3节介绍我们的方法。第4节描述实验设置和结果。第6节总结全文。我们框架的一个拟议用例示意图如下。
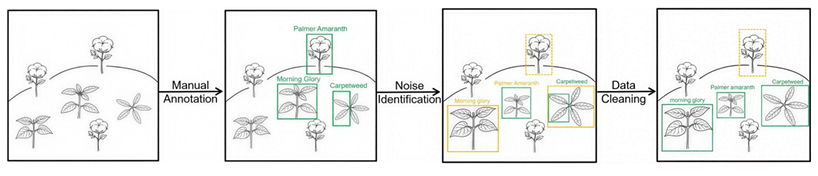
图1. 我们框架的拟议用例
2 相关工作
在目标检测任务中,标注噪声是限制模型性能的主要因素,其影响通常超过架构改进。这种噪声源于多种原因,包括遗漏目标、边界框定位不准确、类别标签错误以及模糊的小目标或被遮挡目标。为了缓解这些问题,先前在以数据为中心的人工智能领域提出了多种策略,作用于数据和训练流程的不同阶段。
2.1 基于规则和人在回路的数据清洗
基于规则和人在回路的数据清洗方法利用领域知识、启发式规则和人工检查来校正标注错误。在农业目标检测中,这通常涉及验证遗漏目标、约束边界框几何形状以及有选择地重新标注模糊样本。例如,Li等人20提出了一个用于无人机影像的基于规则的杂草检测框架,利用植被结构先验过滤不可信的检测结果并指导手动校正。类似的大规模基准测试中也存在标注不一致和人为偏差问题12,28。虽然精确,但这些方法劳动密集,难以扩展,并且依赖专家知识,限制了其普适性。
2.2 噪声感知样本过滤
噪声感知样本过滤方法旨在识别并移除潜在的错误标注。Han等人14在目标检测中使用一种框级别的协同教学策略,通过比较两个网络的损失来识别噪声框,并且只使用低损失框进行训练。这种方法过滤的是单个框而非整个图像,额外的稳定性检查通过跟踪不同检查点的预测一致性来识别不可靠的框。基于置信度的方法,如置信学习,提供了一种无需改变训练过程即可检测潜在标注错误的原则性方法。
该策略自动过滤极端噪声,减少人工检查,同时部分噪声图像仍能提供有用信息。然而,丢弃样本可能会移除稀有但有效的实例,需要仔细的保留比例以避免过度数据丢失。
2.3 损失重加权和样本加权
诸如自助法27、S-模型13和MentorNet18等方法在训练过程中减少了噪声标签的影响。自助法将真实标签与模型预测混合以创建软标签,S-模型对噪声转移矩阵建模,而MentorNet学习每个样本的权重以降低低置信度样本的权重。例如,Reed等人27证明了自助法能够在标注错误下稳定训练。
在目标检测中,模型预测与原始边界框之间的差异可以产生软标签或样本特定权重,从而在不进行人工干预的情况下降低高差异框的影响。虽然这些方法在缓解噪声方面有效,但它们并不校正错误,因此系统的错误标注或遗漏标注仍然可能限制性能。
2.4 自动标注校正
自动校正技术,例如两步的类别无关框校正和随后的标签调整21,使用模型预测来更新噪声标注。伪边界框替换定位不佳的真实标注框,类别标签根据模型共识进行校正,低置信度的更改可选择由人工验证。师生框架利用教师模型的伪标签迭代优化数据集。Chachula等人9提出了目标检测置信学习算法,该算法自动识别缺失、多余、错标和定位错误的边界框,以提升标签质量。
该策略直接改进了训练标签并减少了系统偏差,但其有效性依赖于初始模型的可靠性,且不恰当的校正可能引入确认偏误或放大现有错误。
3 方法
本研究提出了一种用于农业目标检测的以数据为中心的工作流程,称为模型驱动数据校正(MDDC)。该框架将基于YOLO的目标检测器与置信学习原则相结合,以自动评估模型预测与训练标注之间的一致性。通过利用预测置信度和空间一致性,该工作流程系统地识别和校正训练数据中的标注噪声,从而提高数据质量和检测性能。如图2所示,MDDC框架包含六个顺序阶段:数据集准备、基线模型训练、空间聚类与约简、噪声分析、标签校正和数据集再训练。
3.1 数据集准备
按照标准做法,数据集被划分为训练集和验证集。验证集在整个工作流程中保持固定,不参与任何数据清洗或校正过程。该协议确保在数据集精炼后观察到的任何性能提升反映了模型泛化能力的真实增益,而非标签校正引起的记忆效应。
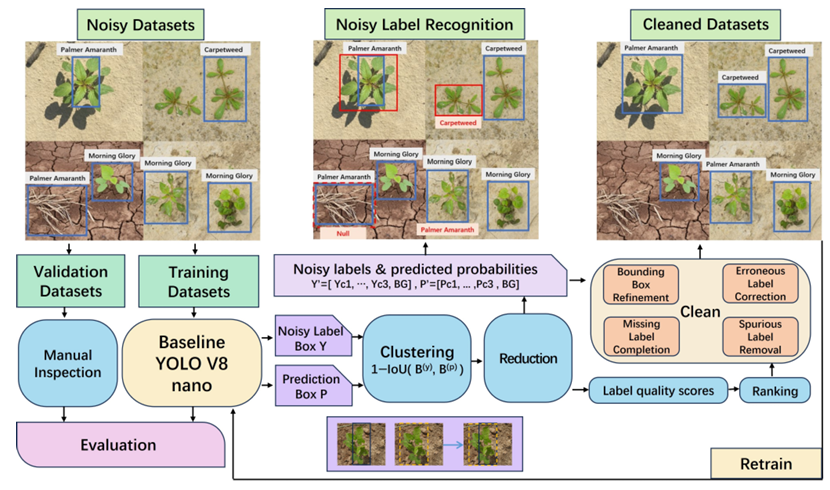
图2. 完整工作流程包含六个顺序阶段:数据集准备、基线训练、空间聚类与约简、噪声分析、标签校正、数据集再训练。
3.2 基线训练
使用原始的、未精炼的训练集训练一个基线YOLO目标检测模型。基线检测器并非为达到最高检测精度而优化,而是作为一个概率诊断机制,用于识别模型预测与数据集标注之间的不一致性。
对于每个预测的边界框,检测器输出(1)针对所有杂草类别和背景的类别概率分布,以及(2)相对于真实标注的空间对齐信息。这些输出构成了后续聚类和噪声检测阶段的基础。
3.3 空间聚类与约简
在目标检测中,单个目标往往会被预测出多个高度重叠的边界框,导致冗余和不稳定的置信度估计。为解决此问题,我们采用目标检测置信学习来进行空间聚类和标注精炼。具体地,预测框和真实框基于交并比(IoU)距离进行聚类:
d(a,b)=1−IoU(a,b),d(a,b)=1-\mathrm{IoU}(a,b),d(a,b)=1−IoU(a,b),
使得每个聚类包含对应于同一目标或空间区域的框。在每个聚类内,通过建议框约简移除冗余预测,以保留代表性框并提高计算效率。
对于每个聚类 CkC_{k}Ck,CLOD构建一个伪标签向量 Yk′Y_{k}^{\prime}Yk′ 和一个伪概率向量 P^k′\hat{P}{k}^{\prime}P^k′。对于每个类别 m∈{1,...,M}m\in\{1,\ldots,M\}m∈{1,...,M}:
Yk,m′={1,if a ground−truth box of class m exists in the cluster,0,otherwise,Y{k,m}^{\prime}=\left\{\begin{aligned}{1,\quad}&{{}\mathrm{if~a~ground-truth~box~of~class~}m\mathrm{~exists~in~the~cluster},}\\ {0,\quad}&{{}\mathrm{otherwise},}\end{aligned}\right.Yk,m′={1,0,if a ground−truth box of class m exists in the cluster,otherwise,
如果没有标注框存在,则分配一个背景标签:
Yk,M+1′={1,∑m=1MYk,m′=0,0,otherwise.Y_{k,M+1}^{\prime}=\begin{cases}{1,}&{\sum_{m=1}^{M}Y_{k,m}^{\prime}=0,}\\ {0,}&{\mathrm{otherwise}.}\end{cases}Yk,M+1′={1,0,∑m=1MYk,m′=0,otherwise.
伪概率向量定义为每个类别的最大预测置信度:
P^k,m′=max{score(b)∣b∈CkP^,label(b)=m},\hat{P}{k,m}^{\prime}=\operatorname*{max}\{\mathrm{score}(b)\mid b\in C{k}^{\hat{P}},\mathrm{label}(b)=m\},P^k,m′=max{score(b)∣b∈CkP^,label(b)=m},
背景分数类似地定义为:
P^k,M+1′={1,∑m=1MP^k,m′=0,0,otherwise.\begin{array}{r}{\hat{P}{k,M+1}^{\prime}=\left\{\begin{aligned}{}&{{}1,}&{}&{{}\sum{m=1}^{M}\hat{P}_{k,m}^{\prime}=0,}\\ {}&{{}0,}&{}&{{}\mathrm{otherwise}.}\end{aligned}\right.}\end{array}P^k,M+1′=⎩ ⎨ ⎧1,0,m=1∑MP^k,m′=0,otherwise.
使用 (Yk′,P^k′)(Y_{k}^{\prime},\hat{P}{k}^{\prime})(Yk′,P^k′),计算聚类级别的质量分数 sk∗s{k}^{*}sk∗,并将其分配给聚类中的所有标注。基于聚类模式和IoU,识别出四种主要的标注错误类型:
- 缺失:存在预测框但没有真实框的聚类;
- 多余:只有真实框存在的聚类;
- 标签错误:预测和标注类别不一致的聚类;
- 定位错误:类别匹配但IoU较低的聚类,表明框未对齐。
聚类内的模型预测也可作为自动校正建议,以提升标注质量和训练效率。算法1如下所示。

3.4 噪声分析
在空间聚类和建议框约简之后,每个剩余的边界框被视为一个独立分析单元。对于每个框,从真实标注构建一个伪标签向量 Yk′Y_{k}^{\prime}Yk′,从模型预测推导出一个伪概率向量 P^k′\hat{P}_{k}^{\prime}P^k′。两个向量都包含所有杂草类别以及一个显式的背景类别。应用参数 α=0.8\alpha=0.8α=0.8 的指数移动平均(EMA)来计算聚类级别的自置信度分数,从而对标注和预测进行细粒度比较。
基于聚类组成和IoU阈值 δ=0.5\delta=0.5δ=0.5,每个聚类 CkC_{k}Ck 被归类为四种标注错误类型之一:
Ek={缺失标签,多余标签,标签错误,定位错误,E_{k}=\left\{\begin{aligned}&缺失标签,\\ &多余标签,\\ &标签错误,\\ &定位错误,\end{aligned}\right.Ek=⎩ ⎨ ⎧缺失标签,多余标签,标签错误,定位错误, 如果存在预测框但没有真实框,如果仅存在真实框,如果预测和标注具有不同类别,如果类别匹配但IoU < δ。
3.5 标签校正
针对每种错误类型,应用有针对性的校正策略。使用置信度高于 τ=0.9\tau=0.9τ=0.9 的高置信度预测来添加缺失标注:
- 多余标签:从数据集中移除相应的真实框。
- 标签错误:保留框的坐标,但将类别标签更新为匹配最高置信度预测。
- 定位错误:保留类别标签,但使用预测结果精炼边界框坐标。
- 缺失标签:添加一个对应于高置信度预测框 (score>τ)(\mathrm{score}>\tau)(score>τ) 并带有预测类别的新标注。

3.6 数据集再训练
应用这些校正后,使用精炼的标注更新训练数据集。然后使用相同的网络架构和超参数重新训练YOLO检测器,以确保性能提升仅源于数据质量的改善。在固定的验证集上进行最终评估,以定量比较数据集精炼前后的检测性能。
4 实验与结果
4.1 实验设置
数据集 在本工作中,我们在四个农业数据集上进行了杂草和作物检测实验(表1)。
表1. 本研究中使用的数据集摘要。
| 数据集 | 类别 图像 实例数 | ||
|---|---|---|---|
| 作物和杂草检测数据 25 | 2 | 1,300 | 2072 |
| 训练集 | 2 | 910 | 1469 |
| 验证集 | 2 | 390 | 603 |
| 杂草作物图像数据集 29 | 2 | 2,822 | 14,919 |
| 训练集 | 2 | 2,469 | 12533 |
| 验证集 | 2 | 353 | 2386 |
| 3LC棉花杂草检测挑战赛 26 | 3 | 848 | 1532 |
| 训练集 | 3 | 593 | 1061 |
| 验证集 | 3 | 255 | 471 |
| 杂草玉米数据集 10 | 18 | 7862 | 122,315 |
| 训练集 | 18 | 4368 | 54541 |
| 验证集 | 12 | 3494 | 67774 |
总的来说,这些数据集涵盖了二分类和多分类检测任务、无人机和地面水平成像、多种作物类型以及多样的环境条件,为评估精准农业中的检测算法提供了一个稳健的基准。
实验环境 所有实验均在一台配备NVIDIA RTX 4090 GPU和CUDA 12.8的云端工作站上进行。软件环境包括Python 3.9、PyTorch 2.0+和Ultralytics YOLOv8框架。
对于模型训练,我们使用 YOLOv8n\mathrm{YOLOv8n}YOLOv8n 架构(3M参数,6MB),固定输入分辨率为 640×640640\times640640×640。批量大小设置为16。
4.2 噪声识别性能
第一个实验评估了所提出的MDDC框架在四个农业目标检测数据集上,在5%、10%和20%受控标注噪声水平下的鲁棒性。如表2所示,MDDC在所有噪声水平和所有数据集上都持续优于基线。在低噪声(5%)下,MDDC将平均检测精度提高了大约6-8个百分点,这主要由对缺失和多余标注的有效校正驱动,其识别性能通常超过90%。在中等噪声水平10%下,性能差距进一步扩大,MDDC通过可靠地识别错标类别并部分缓解定位错误,实现了比基线高7-9个点的精度。当噪声水平上升到20%时,两种方法的整体性能都下降;然而,MDDC仍保持明显优势,实现了比基线高10-12个百分点的精度。这些结果表明,所提出的框架在现实的标注噪声条件下有效提升了数据质量和模型鲁棒性,并且在不同农业数据集上具有良好的泛化能力。
结果显示,MDDC有效识别了大部分的标注错误,识别率随着噪声水平增加而略有下降。缺失和多余标注的检测精度最高,而定位错误的框由于边界框位置存在中度偏差而更具挑战性。这些发现表明MDDC可以可靠地优先选择需要人工复核的标注,从而实现有针对性的校正和数据集精炼。
4.3 数据清洗的有效性
第二个实验从标签修改的角度评估MDDC的有效性。对于每个数据集,将10%的合成标注噪声注入到训练标签中,包括缺失框、多余框、定位错误框和错标类别。应用MDDC后,将修改后的标注与经过人工完整验证的参考标注进行比较,并分类为四种结果:(i)修改的标注总数,(ii)与真实情况一致的正确修改标注,(iii)偏离真实情况的不正确修改标注,以及(iv)原始正确标注保持不变的无效修改。这种分类明确区分了有益、有害和冗余的校正,提供了对校正可靠性的直接和细粒度度量。
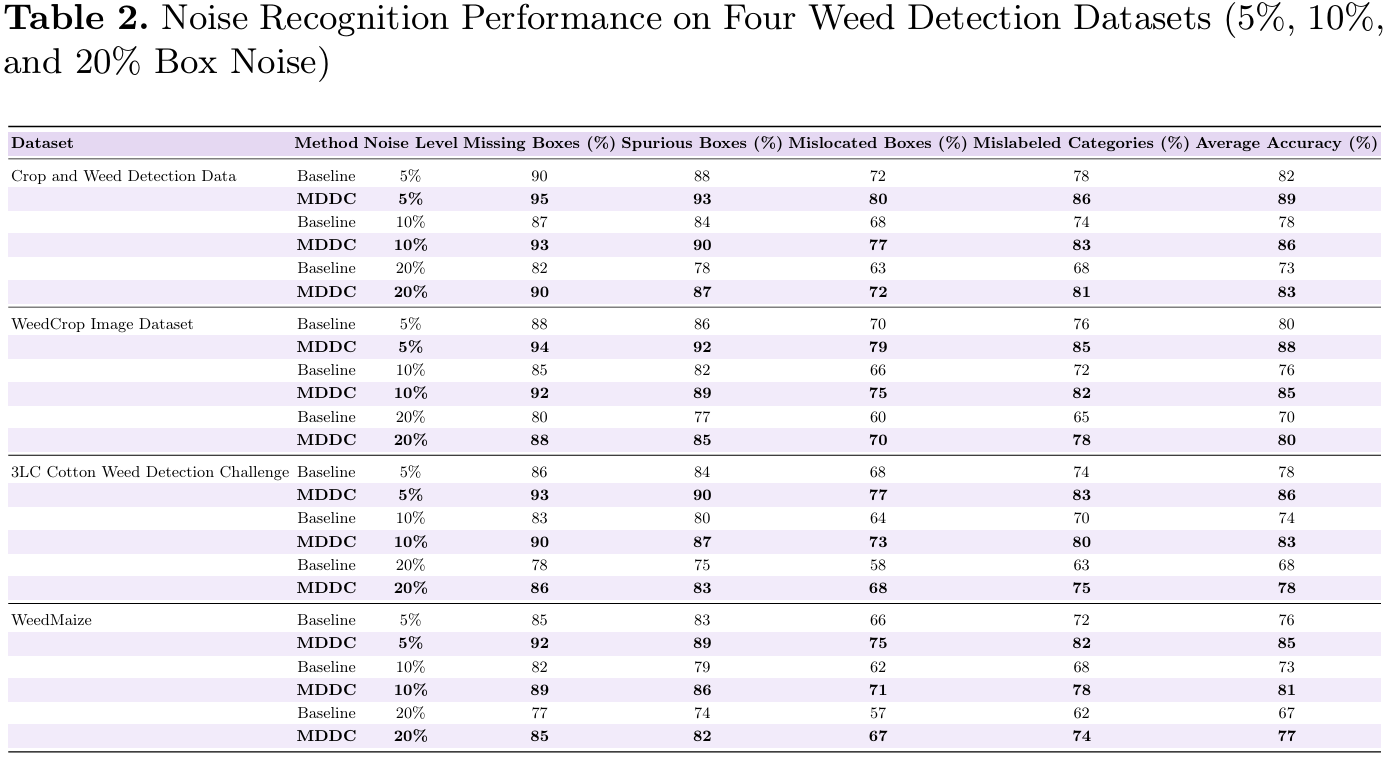
图3展示了典型标注清洗结果的定性示例,说明了MDDC如何在不同噪声条件下移除多余框、校正定位错误的标注以及修正错标类别。同时,通过在噪声数据集、MDDC精炼数据集和人工完整验证的数据集上训练目标检测器进行了定量评估。表3总结的检测性能结果表明,MDDC精炼的标签持续优于噪声标签,并且达到了接近人工完整验证数据的性能。
总的来说,虽然MDDC引入的自动标签修改偶尔会产生错误或次优的校正,但大多数修改提升了标注质量,并转化为下游检测性能的可衡量增益。鉴于其与详尽的人工验证相比显著更低的成本,这些结果表明MDDC为目标检测任务中的迭代数据清洗提供了一个实用且有效的解决方案。

图3. 典型标注清洗结果示例
表3. 不同标签条件下四个杂草检测数据集的检测性能
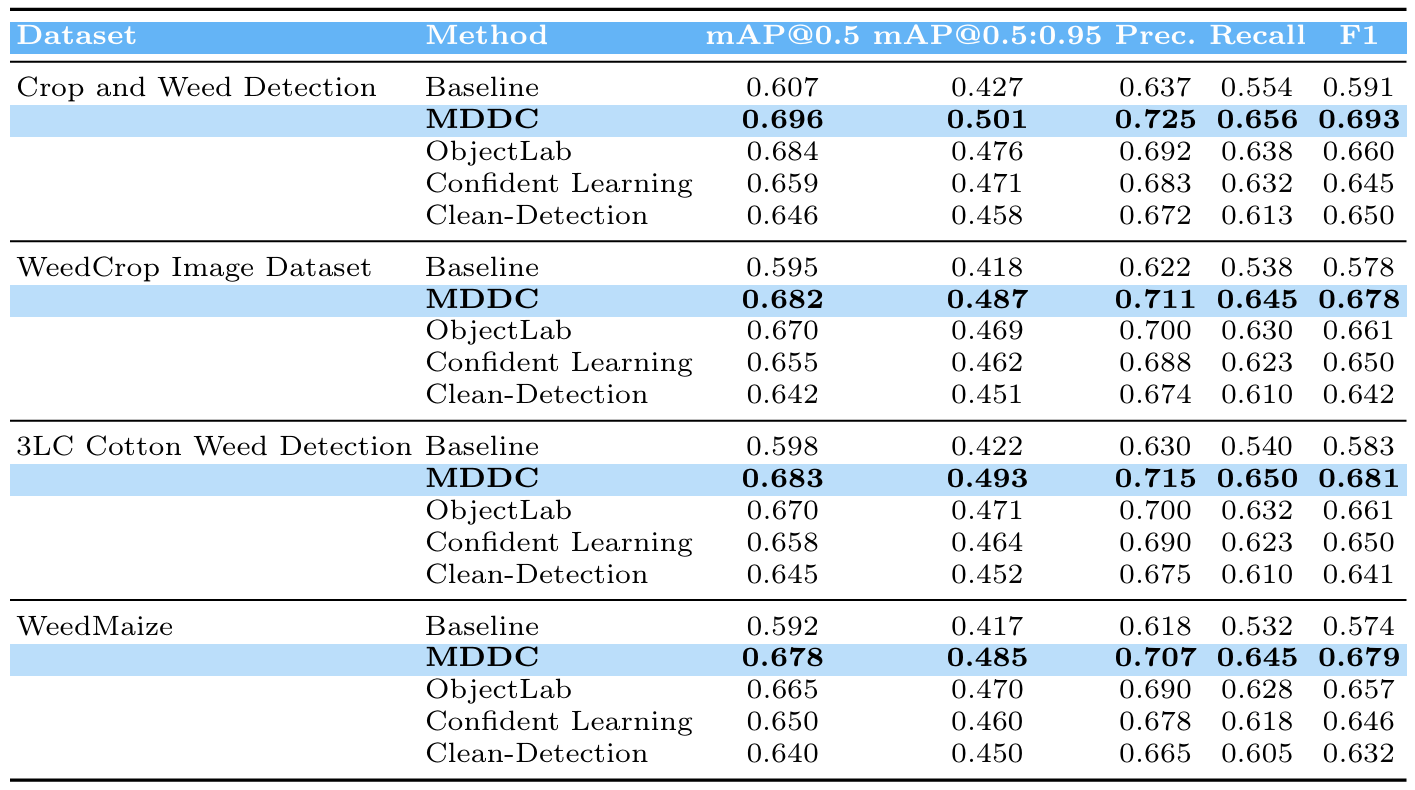
4.4 与其他方法的比较
第三个实验评估了所提出的MDDC框架与几种目标检测中最先进的噪声处理方法相比的有效性,这些方法包括Object Lab、置信学习、自助法/标签平滑和Clean-Detection。所有方法都应用于相同的数据集,并使用YOLOv8n骨干在相同设置下训练模型,以确保公平比较。
在四个广泛使用的农业杂草检测数据集上评估性能:作物和杂草检测数据、杂草作物图像数据集、3LC棉花杂草检测挑战赛和杂草玉米数据集。评估指标包括mAP@0.5、mAP@0.5:0.95、精确率、召回率和F1分数,提供了对检测精度、定位精确度和类别分配正确性的全面评估。
表4总结了结果。在所有数据集上,MDDC在mAP@0.5方面持续优于其他方法,相比基线和替代方法实现了5-25%的提升。该框架在mAP@0.5:0.95方面也显示出优越性能,表明了对具有挑战性或模糊目标具有更精确的定位和更稳健的处理能力。精确率和召回率同时得到提升,导致更高的F1分数,这突显了MDDC对于现实世界杂草检测任务的实用优势。
值得注意的是,MDDC在不同图像质量、目标密度和杂草类型的数据集上表现出强大的泛化能力,这表明其模型驱动的数据校正策略在各种农业场景中有效地缓解了标注噪声并提升了数据集质量。这些结果强调了在模型容量受限的条件下,系统性的数据精炼比纯粹的以模型为中心的改进能产生更实质性的性能提升。
5 结论
在这项工作中,我们提出了MDDC,一个在模型容量受限条件下改进目标检测的以数据为中心的框架。通过系统地识别和校正标注错误,MDDC通过一个迭代的训练-修复-再训练过程提升了数据集质量,并显著提高了检测性能。在四个不同杂草检测数据集上的广泛实验表明,我们的方法始终优于最先进的噪声处理方法,在mAP@0.5上实现了5--25%的增益。这些结果凸显了提升数据质量可能比增加模型复杂度更有效,为现实世界的农业应用提供了一个实用且可重复的解决方案。
表4. 在四个杂草数据集上MDDC与最先进方法的比较
致谢
您可以在我们的GitHub仓库中找到我们的代码。(https://github.com/YingdaYu/Cotton-Weed-Detection)
参考文献
- Active label cleaning for improved dataset quality under resource constraints | Nature Communications. https://www.nature.com/articles/s41467-022-28818-32. Deep Neural Networks for Weed Detections Towards Precision Weeding 3. "Everyone wants to do the model work, not the data work: Data Cascades in High-Stakes AI" Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems. https://dl.acm.org/doi/abs/10.1145/3411764.34455184. Archana, R., Jeevaraj, P.S.E.: Deep learning models for digital image processing: A review. Artificial Intelligence Review 57(1), 11 (Jan 2024). https://doi.org/10.1007/s10462-023-10631-z
- Bernhardt, M., Castro, D.C., Tanno, R., Schwaighofer, A., Tezcan, K.C., Monteiro, M., Bannur, S., Lungren, M.P., Nori, A., Glocker, B., Alvarez-Valle, J., Oktay, O.: Active label cleaning for improved dataset quality under resource constraints. Nature Communications 13(1), 1161 (Mar 2022). https://doi.org/10.1038/s41467-022-28818-3
- Bernhardt, M., Castro, D.C., Tanno, R., Schwaighofer, A., Tezcan, K.C., Monteiro, M., Bannur, S., Lungren, M.P., Nori, A., Glocker, B., Alvarez-Valle, J., Oktay, O.: Active label cleaning for improved dataset quality under resource constraints. Nature Communications 13(1), 1161 (Mar 2022). https://doi.org/10.1038/s41467-022-28818-3
- Bernhardt, M., Castro, D.C., Tanno, R., Schwaighofer, A., Tezcan, K.C., Monteiro, M., Bannur, S., Lungren, M.P., Nori, A., Glocker, B., Alvarez-Valle, J., Oktay, O.: Active label cleaning for improved dataset quality under resource constraints. Nature Communications 13(1), 1161 (Mar 2022). https://doi.org/10.1038/s41467-022-28818-3
- Cai, Z., Vasconcelos, N.: Cascade R-CNN: Delving Into High Quality Object Detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6154-6162 (2018)
- Chachula, K., Lyskawa, J., Olber, B., Fratczak, P., Popowicz, A., Radlak, K.: Combating noisy labels in object detection datasets (2022), https://arxiv.org/abs/2211.13993
- Correa, J.L., D. Andújar, M., Todeschini, J.K., Begochea, J., A, R.: Weedmaize (2021), https://doi.org/10.5281/zenodo.510679511. Dai, J., Li, Y., He, K., Sun, J.: R-FCN: Object Detection via Region-based Fully Convolutional Networks. In: Advances in Neural Information Processing Systems. vol. 29. Curran Associates, Inc. (2016)
- Everingham, M., Van Gool, L., Williams, C., Winn, J., Zisserman, A.: The pascal visual object classes challenge: A retrospective. International Journal of Computer Vision 111(1), 98-136 (2015). https://doi.org/10.1007/s11263-014-0733-513. Goldberger, J., Ben-Reuven, E.: Training deep neural-networks using a noise adaptation layer. In: International Conference on Learning Representations (Feb 2017)14. Han, B., Yao, Q., Yu, X., Niu, G., Xu, M., Hu, W., Tsang, I., Sugiyama, M.: Co-teaching: Robust training of deep neural networks with extremely noisy labels. In: Advances in Neural Information Processing Systems. vol. 31. Curran Associates, Inc. (2018)
- Heo, D.H., Park, S.H., Kang, S.J.: Resource-constrained edge-based deep learning for real-time person-identification using foot-pad. Engineering Applications of Artificial Intelligence 138, 109290 (Dec 2024). https://doi.org/10.1016/j.engappai.2024.10929016. Hu, J., Gong, H., Li, S., Mu, Y., Guo, Y., Sun, Y., Hu, T., Bao, Y., Hu, J., Gong, H., Li, S., Mu, Y., Guo, Y., Sun, Y., Hu, T., Bao, Y.: CottonWeed-YOLO:A Lightweight and Highly Accurate Cotton Weed Identification Modelfor Precision Agriculture. Agronomy 14(12) (Dec 2024). https://doi.org/10.3390/agronomy1412291117. Jiang, D., Shen, Z., Zheng, Q., Zhang, T., Xiang, W., Jin, J.: Farm-LightSeek: An Edge-centric Multimodal Agricultural IoT Data Analytics Framework with Lightweight LLMs (May 2025). https://doi.org/10.48550/arXiv.2506.0316818. Jiang, L., Zhou, Z., Leung, T., Li, L.J., Fei-Fei, L.: MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels. In: Proceedings of the 35th International Conference on Machine Learning. pp. 2304--2313. PMLR (Jul 2018)
- Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. Commun. ACM 60(6), 84-90 (May 2017). https://doi.org/10.1145/3065386
- Li, X., Zhang, Y., Wang, H.: Rule-based weed detection in uav images for precision agriculture. Remote Sensing 12(10), 1654 (2020). https://doi.org/10.3390/rs12101654
- Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollar, P.: Focal Loss for Dense Object Detection. In: Proceedings of the IEEE International Conference on Computer Vision. pp. 2980-2988 (2017)
- Luo, Z., Yeung, S.H., Zhang, M., Zheng, K., Zhu, L., Chen, G., Fan, F., Lin, Q., Ngiam, K.Y., Ooi, B.C.: MLCask: Efficient Management of Component Evolution in Collaborative Data Analytics Pipelines (Mar 2021). https://doi.org/10.48550/arXiv.2010.1024623. Manalil, S., Coast, O., Werth, J., Chauhan, B.S.: Weed management in cotton (Gossypium hirsutum L.) through weed-crop competition: A review. Crop Protection 95, 53--59 (May 2017). https://doi.org/10.1016/j.cropro.2016.08.00824. Murad, N.Y., Mahmood, T., Forkan, A.R.M., Morshed, A., Jayaraman, P.P., Siddiqui, M.S., Murad, N.Y., Mahmood, T., Forkan, A.R.M., Morshed, A., Jayaraman, P.P., Siddiqui, M.S.: Weed Detection Using Deep Learning: A Systematic Literature Review. Sensors 23(7)(Mar 2023). https://doi.org/10.3390/s2307367025. Panara, U., Pandya, R., Rayja, M.: Crop and weed detection data with bounding boxes (2020), https://www.kaggle.com/datasets/ravirajsinh45/crop-and-weeddetection-data-with-bounding-boxes
- Rahman, A., Lu, Y., Wang, H.: Cottonweeddet3::A 3-class weed detection dataset for cotton cropping systems (2022), https://www.kaggle.com/datasets/yuzhenlu/cottonweeddet3/27. Reed, S., Lee, H., Anguelov, D., Szegedy, C., Erhan, D., Rabinovich, A.: Training Deep Neural Networks on Noisy Labels with Bootstrapping (Apr 2015). https://doi.org/10.48550/arXiv.1412.659628. Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A., Fei-Fei, L.: Imagenet large scale visual recognition challenge. International Journal of Computer Vision 115(3), 211--252 (2015). https://doi.org/10.1007/s11263-015-0816-y 29. Sudars, K., Jasko, J., Namatevs, I., Ozola, L., Badaukis, N.: Weedcrop image dataset (2020), https://www.kaggle.com/datasets/vinayakshanawad/weedcropimage-dataset