目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-Transformer架构1-整体介绍、Transformer架构4-多头注意力、掩码注意力、交叉注意力,欲渐进,请循序
- 本文重点介绍Transformer架构中的残差连接与前馈网络,它们在编码器堆栈和解码器堆栈中都有用到
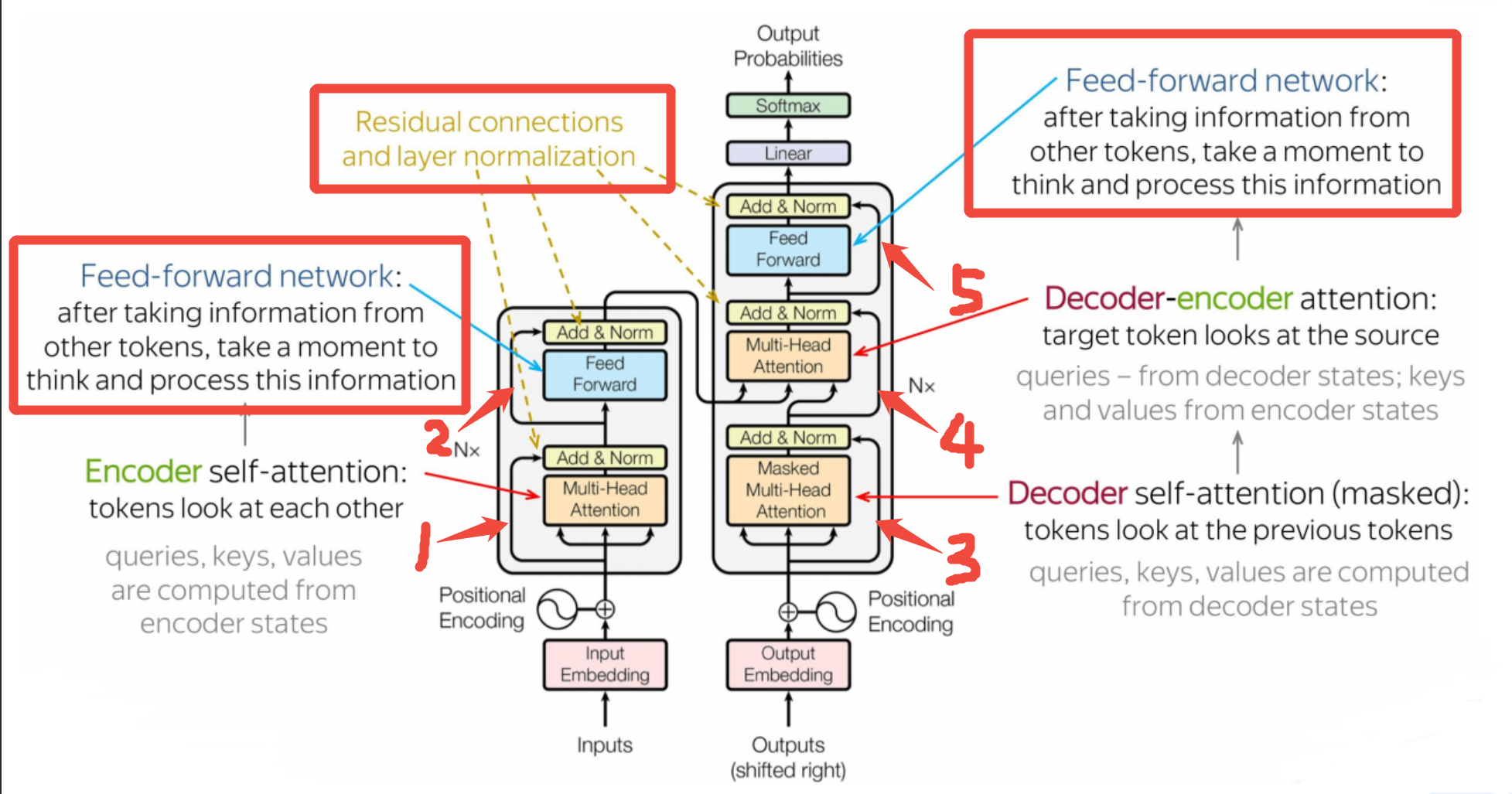
残差连接
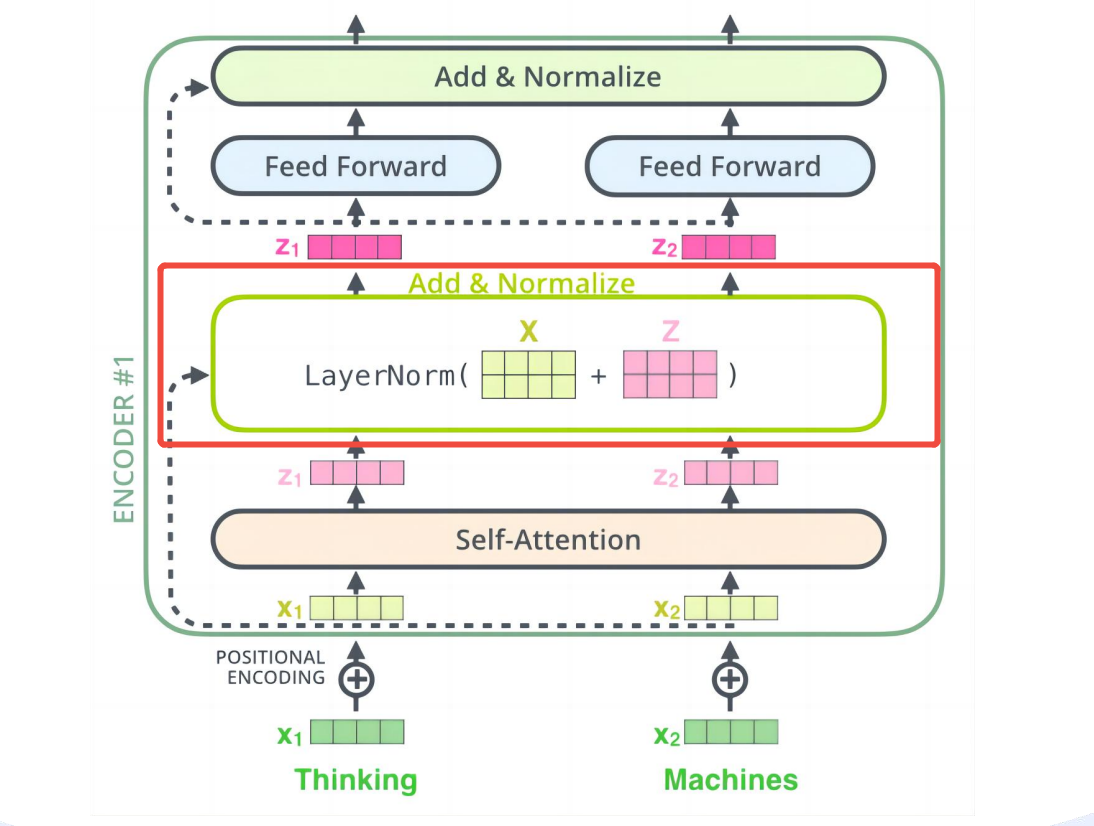
- 残差连接的详细内容,在前文-残差网络中已经提及。
- 简单讲,残差连接是一种技术手段,为了解决极深网络中的梯度消失和网络退化问题,降低优化难度,为深层网络的训练效果托底。
- 残差连接的核心,是让网络从学习完整的目标映射到学习一个残差,这样有价值的浅层信息不至于在网络的层层传递中丢失。
- 上图中,1-5号残差连接后,分别对应一个
Add & Norm模块,以1号残差连接对应的Add & Norm模块为例详细说明。
1、Add操作是残差连接的一部分,它把嵌入层的输出矩阵X 和注意力层的输出矩阵Z 相加,以确保后续层工作时,不会丢失浅层X的信息
2、Norm操作是进行层归一化,归一化的作用:- 1、提高稳定性:稳定数值范围(限制个别极端值的影响)
- 2、提升效率:加速收敛
前馈网络
- 前馈网络就是前文-神经网络中最常见的基础神经网络,也称多层感知机(MLP)、全连接网络。
- 前馈:工作时,只有前向计算,没有循环或反馈连接。与前馈神经网络并列的概念是循环神经网络如RNN
为什么要引入前馈网络
简单说:如果注意力层是让每个词"看到"其他词,那么前馈网络就是让每个词"深入思考"自己。两者结合,才能实现真正的理解。
-
注意力层的计算是加权求和,是一种线性计算,而线性能够拟合的模式有限
-
前馈网络弥注意力层的不足,使用的是非线性计算,使模型能够拟合更复杂的模式。
-
两者结合效果如下:
输入:[词1, 词2, 词3]
↓
注意力:词1←→词2←→词3(建立关系)
↓
前馈:词1→深加工,词2→深加工,词3→深加工
↓
输出:既有关系信息,又有深度特征