一、研究背景
随着现实世界应用对大语言模型(LLMs)的需求不断升级,上下文窗口被扩展至数十万token,同时模型参数规模从数十亿激增至万亿级别。这种"长上下文+大模型"的双重扩张导致计算成本和内存消耗飙升,使得token压缩成为LLMs高效处理长文本任务的必备技术。
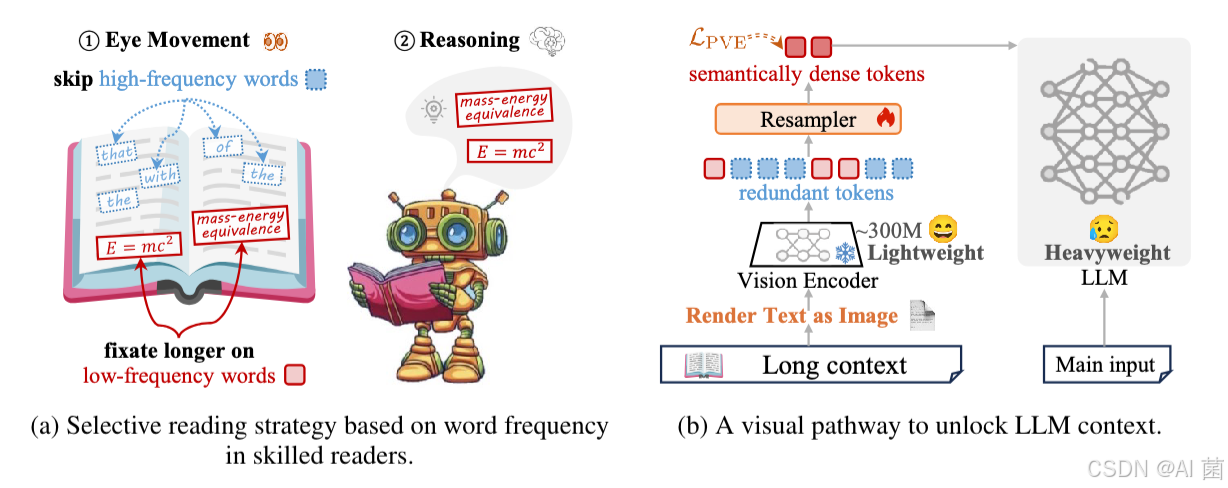
现有token压缩方法存在诸多局限:依赖LLM自身计算token信息熵的方法成本高昂;基于文本编码器的压缩方法(如CEPE)未充分解决长文本中的冗余问题,难以引导模型聚焦关键语义;传统文本分词器面临词汇瓶颈、对字符级噪声敏感、多语言处理效率低等问题。而心理语言学研究表明,人类阅读存在"选择性浏览"策略------会聚焦低频、富含语义的词汇,跳过约三分之一的高频功能词,这为设计高效压缩框架提供了灵感。
二、核心工作
提出一种名为VIST(Vision-centric Token Compression)的快慢双路径压缩框架,模拟人类阅读模式,通过轻量级视觉编码器处理长文本上下文,实现高效token压缩,同时保持甚至提升LLMs的任务性能。
核心贡献包括:
- 构建快慢双路径架构:快速路径将远距离低显著性文本转换为图像,通过冻结的轻量级视觉编码器快速浏览;慢速路径将近距离关键文本输入LLM进行细粒度推理。
- 设计概率感知视觉增强(PVE)目标:基于token频率的掩码策略,抑制高频低信息token,引导重采样器(Resampler)聚焦语义丰富区域,弥合视觉token与文本token的语义鸿沟。(配合设计了相应的损失函数)
- 验证视觉编码器在文本处理中的优势 :简化分词流程、突破词汇瓶颈、增强字符级噪声鲁棒性、提升多语言处理效率。
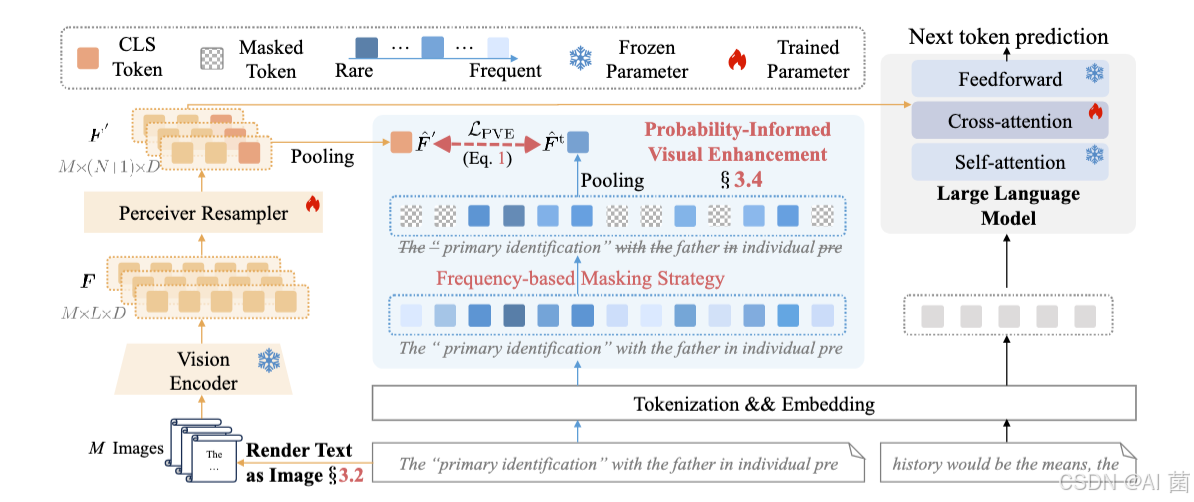
三、研究方法
1. 整体框架
VIST将输入长文本分为两部分(T=Tc+TdT=T_c+T_dT=Tc+Td):TcT_cTc个文本token通过视觉路径处理,TdT_dTd个原始文本token直接输入LLM。具体流程为:
- 文本渲染 :将TcT_cTc个token均匀渲染为M张RGB图像(分辨率224×224),采用10px字体和Google Noto Sans字体,空白区域掩码处理。
- 视觉编码:冻结的视觉编码器(ViT-L/14)提取图像特征,输入可训练的Perceiver Resampler,生成固定数量的视觉token(含CLS token)。
- 跨注意力融合:视觉token通过跨注意力层与LLM输入融合,共同参与下一个token预测,Resampler与LLM跨注意力层端到端联合训练。
2. 概率感知视觉增强(PVE)
- 文本锚定语义一致性:通过对比损失函数,使Resampler输出的视觉特征与LLM分词器提取的文本token嵌入对齐,构建共享嵌入空间。
- 频率基于掩码策略 :基于香农信息论,低频token被视为高信息token,计算token重要性得分sw=log∣S∣1+count(w)s_w=log\frac{|\mathcal{S}|}{1+count(w)}sw=log1+count(w)∣S∣,对50%低重要性token进行掩码,提升文本嵌入的信息密度。其中S表示样本数,count(w)表示该词汇的统计数量。
3. 关键参数配置
- 图像尺寸:H=14、W=3584、C=3,对应224×224分辨率;
- 压缩比例:每1024个文本token渲染为7张图像,生成448个视觉token,压缩比达2.3×;
- 训练设置:采用float16精度和DeepSpeed Zero-2优化,训练序列长度4608(前4096个token走视觉路径,后512个token直接输入LLM)。
四、实验设计
1. 实验环境
- 基础模型:TinyLlama(主要验证)、Mistral 7B(通用性验证);
- 视觉编码器:冻结的ViT-L/14(来自OpenCLIP);
- 预训练数据集:RedPajama数据集的1B token样本,涵盖7个领域(ArXiv、Book、C4等);
- 对比方法:长上下文模型(Replug、Stream)、文本编码器压缩方法(CEPE∗)、视觉中心压缩方法(ToMe†、FastV†)。
2. 评估任务与指标
- 长上下文语言建模(LCM):在ArXiv、Book、PG19等数据集上,以困惑度(PPL)为指标,评估最后256个token的预测性能;
- 上下文学习(ICL):11个文本分类数据集(SST2、MR、AGN等),评估平均准确率(3个随机种子);
- 开放域问答(QA):TriviaQA、NQ、PopQA数据集,以精确匹配(EM)为指标;
- 消融实验:验证掩码策略、编码器输入长度、图像token数量、模型通用性的影响。
五、实验分析
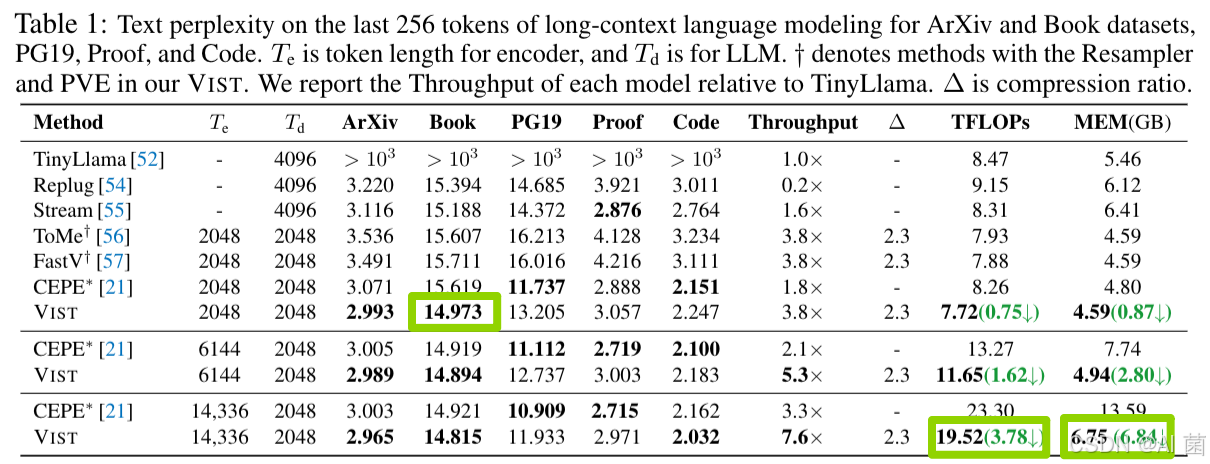
1. 长上下文语言建模
- VIST随输入长度增加,困惑度持续下降,在Book数据集上达到最低PPL(14.973),而TinyLlama超过2048token后性能骤降(PPL>10³);
- 与CEPE∗相比,VIST处理14336个token时,TFLOPs减少3.78,内存占用减少6.84GB,吞吐量提升2.3×。
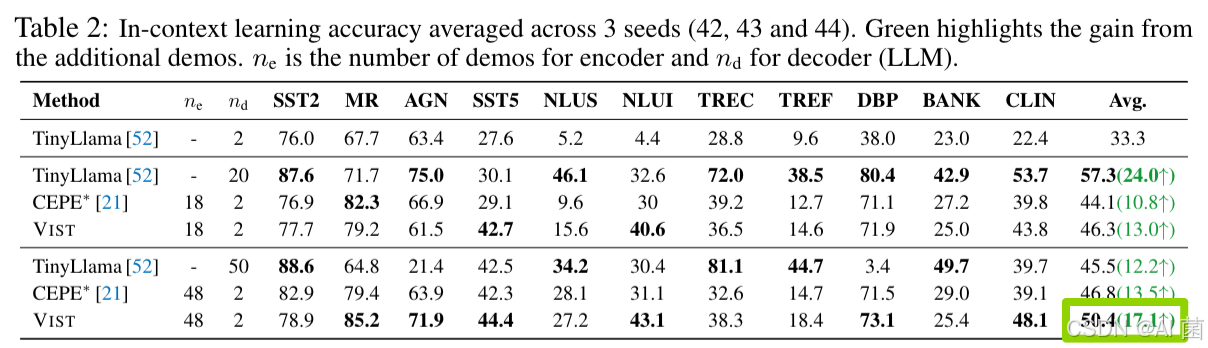
2. 上下文学习
- VIST在11个数据集上平均准确率达50.4%,较CEPE∗提升3.6%,且随着演示样本数量增加,性能稳步提升(+17.1%);
- TinyLlama在50个演示样本时因上下文窗口限制性能下降,而VIST保持稳定,验证了长上下文处理能力。
3. 开放域问答
- 当输入20个相关段落(10个走视觉路径,10个直接输入LLM)时,VIST在TriviaQA上的EM分数达25.67,较CEPE∗提升9.11个百分点;
- 仅使用视觉路径(10个段落)时,VIST性能与TinyLlama(全量处理10个段落)相当,证明快速路径的信息蒸馏能力;
- CEPE∗随输入段落增加性能下降,而VIST因PVE的降噪机制保持稳定。
4. 消融实验
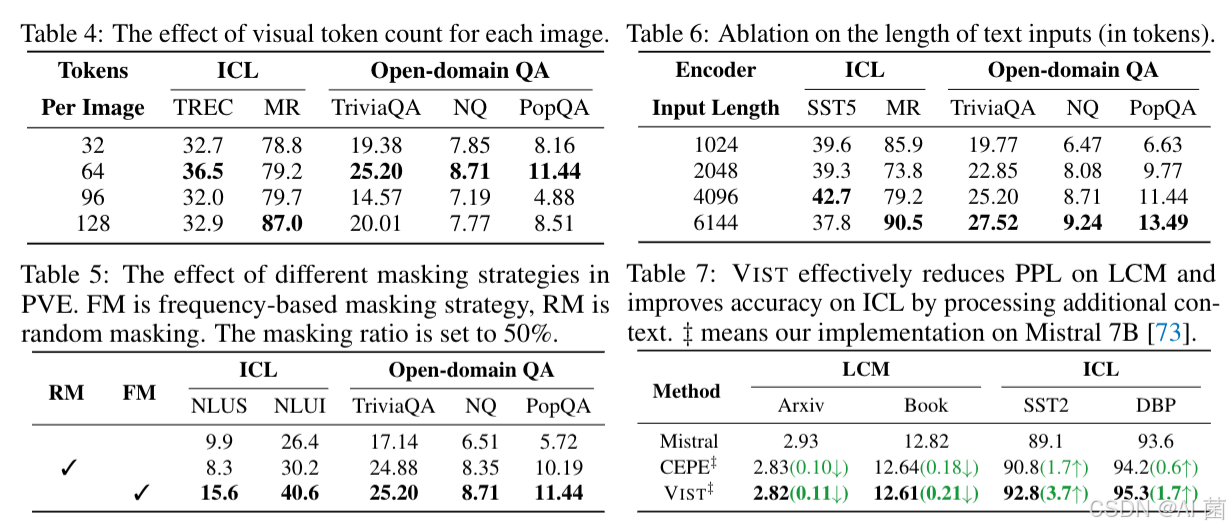
- 图像token数量:64个token时性能最优,过多或过少均会导致性能下降(平衡信息保留与噪声引入);
- 掩码策略:移除频率基于掩码后,ICL和QA性能显著下降,验证了高信息密度文本嵌入的引导作用;
- 编码器输入长度:6144个token时QA任务EM分数最高, longer训练文本有助于模型提取长上下文关键信息;
- 通用性:在Mistral 7B上,VIST较CEPE‡在LCM任务上PPL降低0.21,ICL任务准确率提升3.7个百分点,证明跨模型适用性。
六、总结
VIST创新性地将视觉编码引入LLM长文本token压缩,通过模拟人类选择性阅读的快慢双路径架构,结合概率感知视觉增强目标,在大幅降低计算成本(减少16% FLOPs、50%内存)和提升token效率(2.3×压缩比)的同时,在长上下文建模、上下文学习、开放域问答等任务中超越传统文本编码器压缩方法。
研究还验证了文本token中存在显著冗余,低频token是语义完整性的核心载体,为后续长文本处理研究提供了新视角。未来方向包括扩展更多下游任务评估、深入探索文本token冗余特性、优化多语言场景下的文本渲染与编码策略。