第 1 章 LangChain概述
前置知识: 🦜️🔗 Langchain v0.x
⛳️ 地位
- LangChain 1.0 是⼀个**⾥程碑式**的重⼤更新,标志着该框架进⼊了成熟稳定的发展阶段。此版本的核⼼⽬标是简化开发流程、统⼀API标准,并增强⽣产环境下的可控性与稳定性。
🙋♂️ 影响
- v1.0 相较于上一个版本 v0.3【v0.x系列】基本上重构了其【杂乱】的库,已经或者即将通过 Langchain 做 Agent 开发的项目,必须尽快切换 Langchain 1.0 ,重构躲不掉了!
- 企业或者开发者, 不用过度担心下一次代码重构问题 ,因为官方承诺 Langchain2.0 之前 ,不会再次做大的改动,1.0 的规范将持续保持。
1.1 大模型与大语言模型
大模型(Large Model,也称基础模型,即 Foundation Model),是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
大语言模型(Large Language Model)通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI的GPT-5 模型。这些模型通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。

1.2 大模型相关岗位介绍
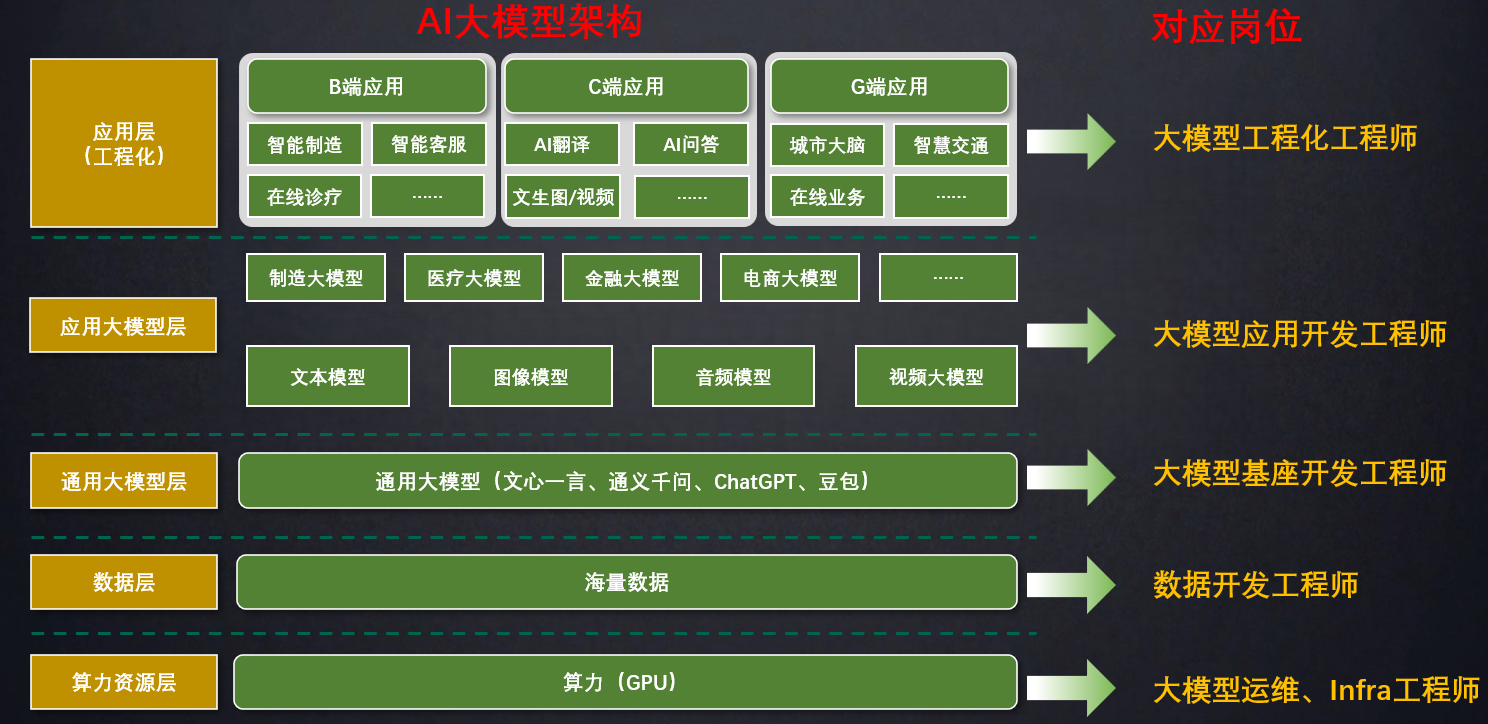
应用开发是大模型最值得关注的方向,学习LangChain框架,高效开发大模型应用。
1.3 LangChain介绍
1.3.1 什么是LangChain
- github地址:https://github.com/langchain-ai/langchain
- 官网地址:https://www.langchain.com/langchain
- 官方文档:https://docs.langchain.com/oss/python/langchain/overview
- API 文档:https://reference.langchain.com/python/langchain/
LangChain是2022年10月,由哈佛大学的Harrison Chase(哈里森·蔡斯)发起研发的一个开源框架,用于开发由大语言模型(LLMs)驱动的应用程序。
比如,搭建Agent、问答系统(QA)、对话机器人、文档搜索系统等。
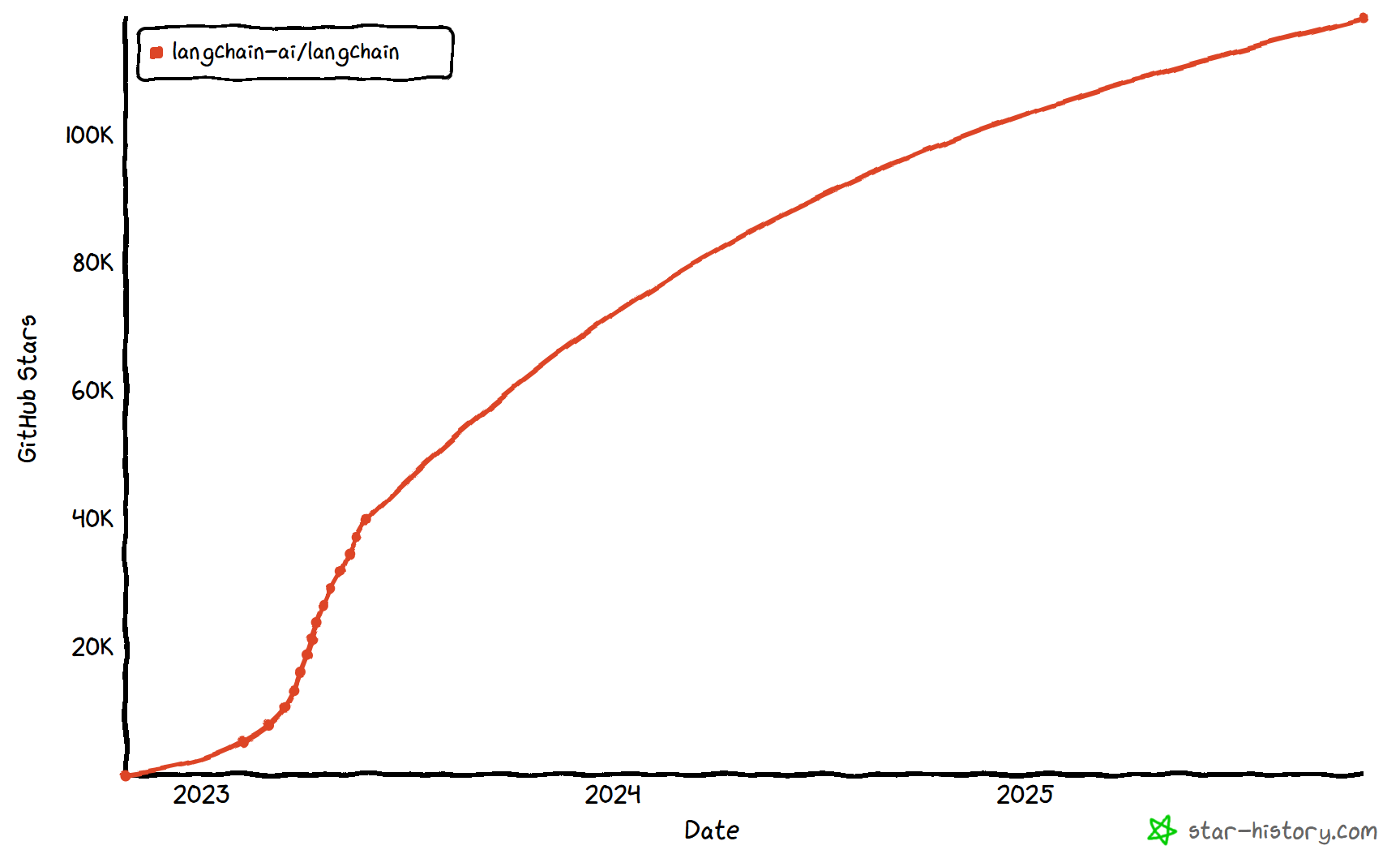
LangChain的发布比ChatGPT问世还要早一个月,从这个启动日期也可以看出创始人的眼光,占了先机的它迅速获得广泛关注和支持!
LangChain在Github上的热度变化:
简单概括:
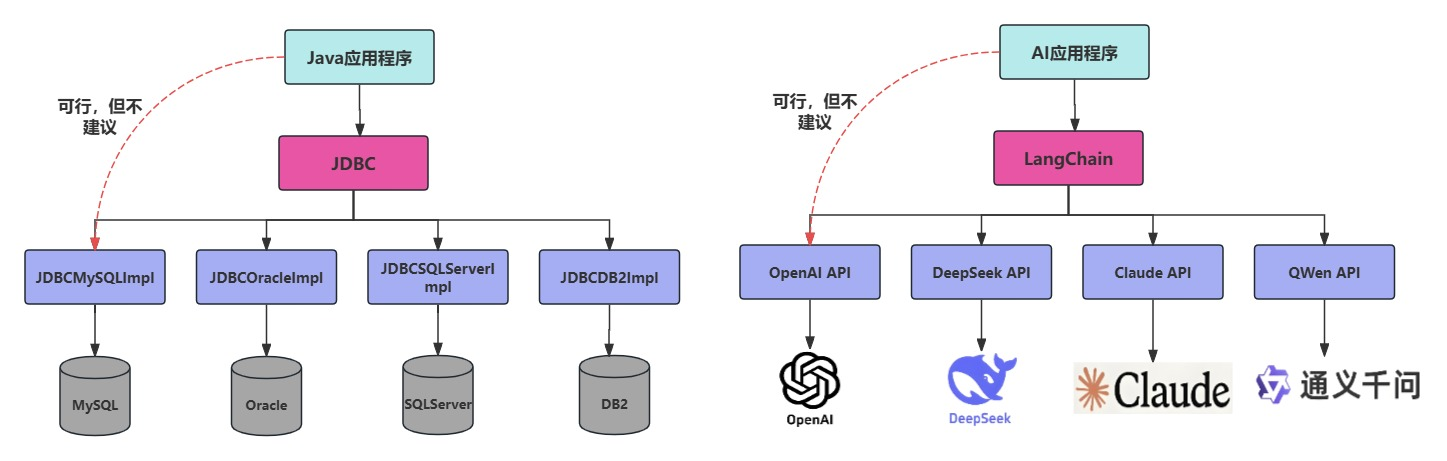
LangChain ≠ LLMs。LangChain 之于 LLMs,类似 Spring 之于 Java,Django 之于 Python。
顾名思义,LangChain中的"Lang"是指language,即大语言模型,"Chain"即"链",也就是将大模型与外部数据&各种组件连接成链,以此构建AI应用程序。
1.3.2 有哪些大模型应用开发框架
|--------------------------------------------------------------|------------------------------------------------------------------------------------------|
| 框架 | 描述 |
| LangChain ( Python ) | 出现最早、最成熟的,适合复杂任务分解和单Agent应用 |
| LlamaIndex ( Python ) | 专注于高效的索引和检索,适合 RAG 场景 |
| LangChain4J ( Java ) | LangChain出了Java、JavaScript(LangChain.js)两个语言的版本,LangChain4j的功能略少于LangChain,但是主要的核心功能都是有的 |
| SpringAI / SpringAI Alibaba ( Java ) | 有待进一步成熟,只是简单的对于一些接口进行了封装 |
| SemanticKernel ( C# ) | 微软推出的,对于C#同学来说,那就是5颗星 |
1.3.3 为什么需要 LangChain
问题1:LLMs用的好好的,为什么还需要LangChain?
在大语言模型(LLM)如 ChatGPT、Claude、DeepSeek 等快速发展的今天,开发者不仅希望能"使用"这些模型,还希望能将它们灵活集成到自己的应用中,实现更强大的对话能力、检索增强生成(RAG)、工具调用(Tool Calling)、多轮推理等功能。

问题2:我们可以使用 GPT 或 GLM4 等模型的API进行开发,为何需要LangChain这样的框架?
不使用LangChain,确实可以使用GPT 或GLM4 等模型的API进行开发。比如,搭建Agent、问答系统(QA)、对话机器人、文档搜索系统等复杂的 LLM 应用。
但使用LangChain的好处:
- 简化开发难度:更简单、更高效、效果更好。
- 开发人员可以更专注于业务逻辑,而无须花费大量时间和精力处理底层技术细节。
- 学习成本更低:不同模型的API不同,调用方式也有区别,切换模型时学习成本高。使用LangChain,可以以统一、规范的方式进行调用,有更好的移植性。
- 现成的链式组装:LangChain提供了一些现成的链式组装,用于完成特定的高级任务。让复杂的逻辑变得结构化、易组合、易扩展。
问题3:LangChain提供了哪些功能?
LangChain 是一个帮助你构建 LLM 应用的全套工具集。这里涉及到prompt 构建、LLM 接入、记忆管理、工具调用、RAG、Agent开发等模块。
学习 LangChain 最好的方式就是做项目。
1.3.4 LangChain 使用场景
|--------------------------------------|----------------------------------|
| 项目场景 | 技术点 |
| 文档问答助手 | Prompt + Embedding + RetrievalQA |
| 智能日程规划助手 | Agent + Tool + Memory |
| LLM+ 数据库问答 | SQLDatabaseToolkit + Agent |
| 多模型路由对话系统 | RouterChain + 多 LLM |
| 互联网智能客服 | ConversationChain + RAG +Agent |
| 企业知识库助手( RAG + 本地模型) | VectorDB + LLM + Streamlit |
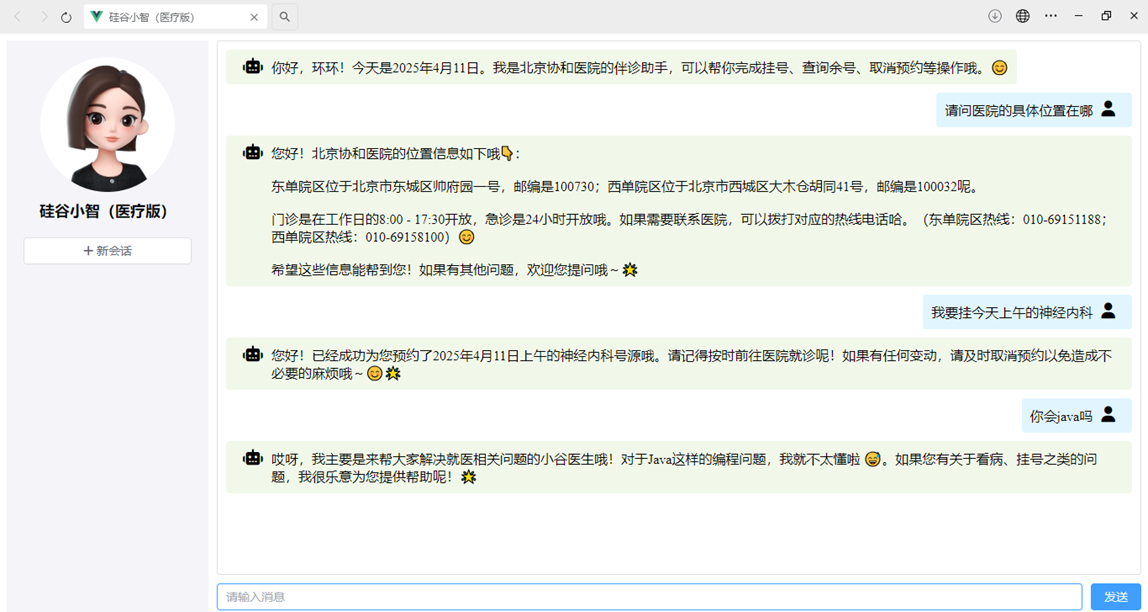
比如:医院智能助手
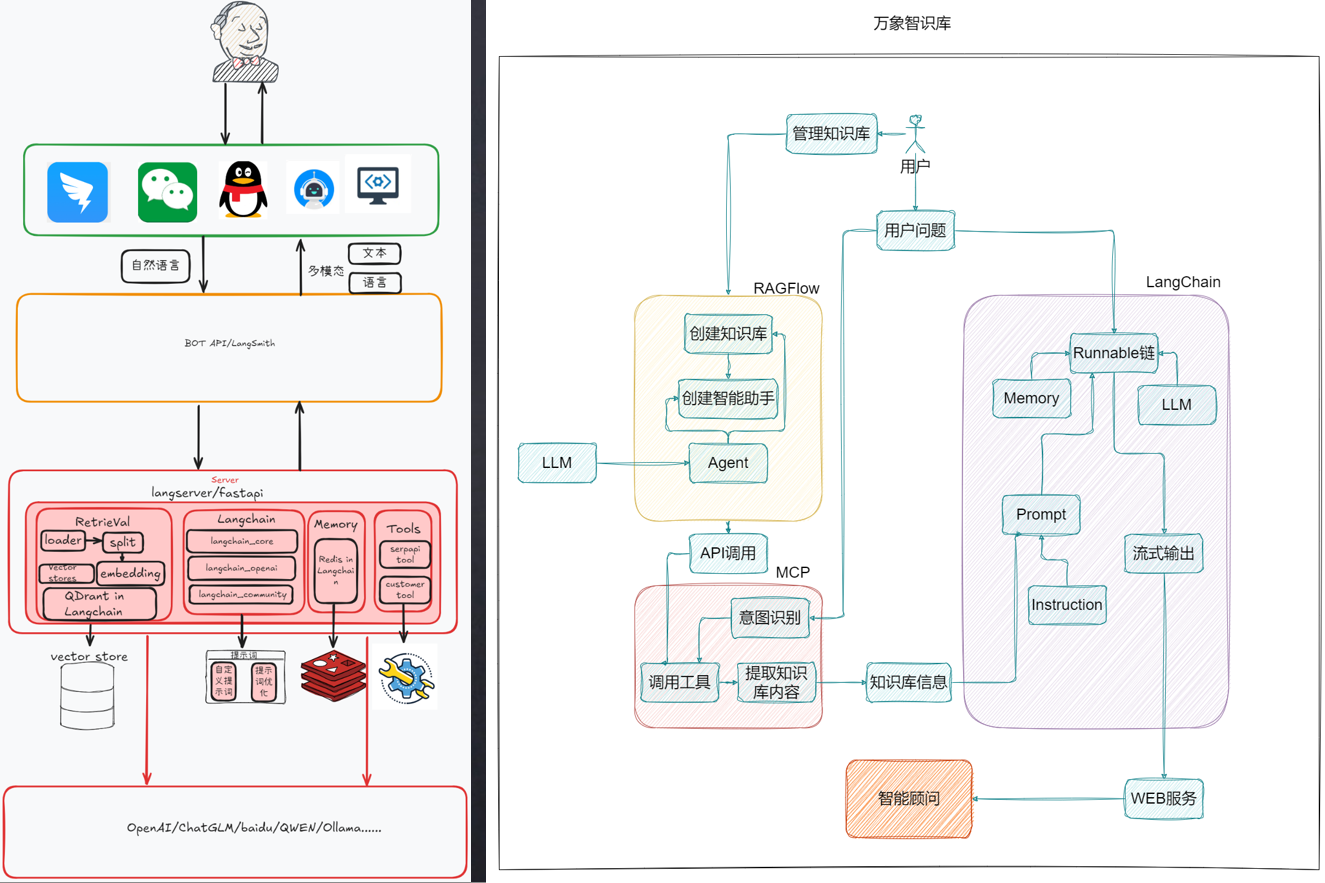
比如:万象知识库
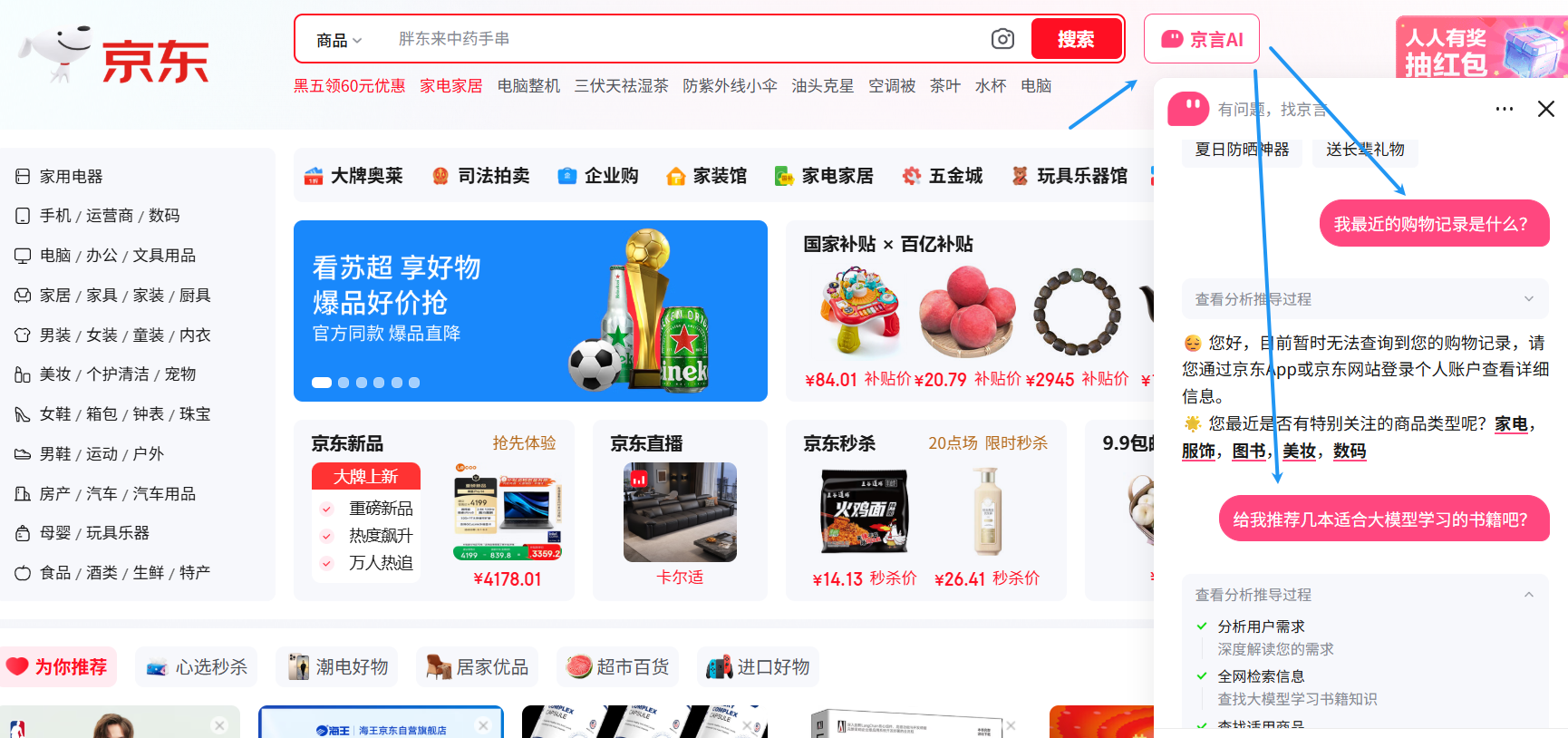
比如:京东助手
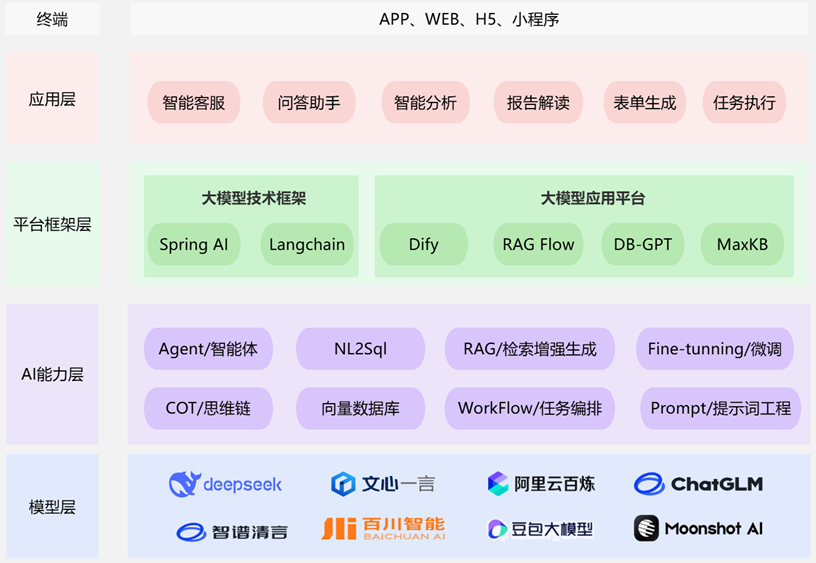
1.3.5 LangChain 生态位置
项目类型1:文档问答助手
- **案例:**企业使用 LangChain 加载内部文档(如员工手册、产品说明),结合向量存储实现语义搜索,回答员工或客户的问题。
- **示例:**新员工入职培训中,销售岗位有哪些注意事项呢?检索相关手册并生成自然语言回答。
- **场景:**基于私有或外部数据构建问答系统。
项目类型2:智能助理开发
- **案例:**LangChain 的 Agent 模块(如 ReAct Agent)结合工具,完成任务。
- 示例 1 **:**用户请求调用天气 API、计算器和日历,规划户外旅游活动。
- 示例 2 **:**结合使用Google Search、Firecrawl网页爬取工具,实现"分析某股票趋势并生成报告"的任务。
- **场景:**构建自主决策的Agent,执行复杂任务。
项目类型3:对话聊天机器人
- **案例:**电商平台使用 LangChain 的 ConversationChain,结合 ConversationBufferMemory,记录用户历史对话,提供个性化客服。
- **示例:**用户问"推荐一款跑鞋",机器人根据之前提到的偏好(如"喜欢轻量鞋")推荐合适产品。
- **场景:**开发上下文感知的聊天机器人,支持多轮对话。
项目类型4:数据分析与洞察生成
- **案例:**金融分析师使用 LangChain 加载 CSV 数据,结合 LLM 分析销售趋势,生成自然语言报告。
- **示例:**从销售数据中提取"哪些产品在特定地区销量最高"并生成可视化描述。
- **场景:**处理结构化或非结构化数据,生成报告或洞察。
项目类型5:多模态应用
- **案例:**平台使用 LangChain 结合 CLIP 模型,分析产品图片、视频等,生成高质量回复。
- 示例 1 **:**教育平台分析教学视频和讲义,生成互动式学习内容。
- 示例 2 **:**零售平台结合产品图片和描述,回答"哪些产品适合户外使用?"。
- **场景:**结合文本、图像、语音等多模态数据。
项目类型6:教育与学习助手
- **案例:**在线教育平台使用 LangChain 构建数学助手,结合 Wolfram Alpha 工具解答复杂公式。
- **示例:**学生提问"积分的定义",LangChain 检索教材并生成逐步讲解。
- **场景:**开发个性化教育工具,支持学习和练习。
项目类型7:自动化工作流
- **案例:**营销团队使用 LangChain 整合市场数据,自动生成社交媒体帖子。
- **示例:**从 CRM 数据生成客户跟进邮件,结合日历安排发送时间。
- **场景:**自动化复杂业务流程,如报告生成、任务调度。
项目类型8:研究与创新
- **案例:**研究者使用 LangChain 分析文献,结合知识图谱提取跨领域的概念关系。
- **示例:**从气候变化文献中提取关键趋势,生成研究报告。
- **场景:**支持学术或行业研究,挖掘数据关联。
1.3.6 LangChain 架构
1) 总体架构
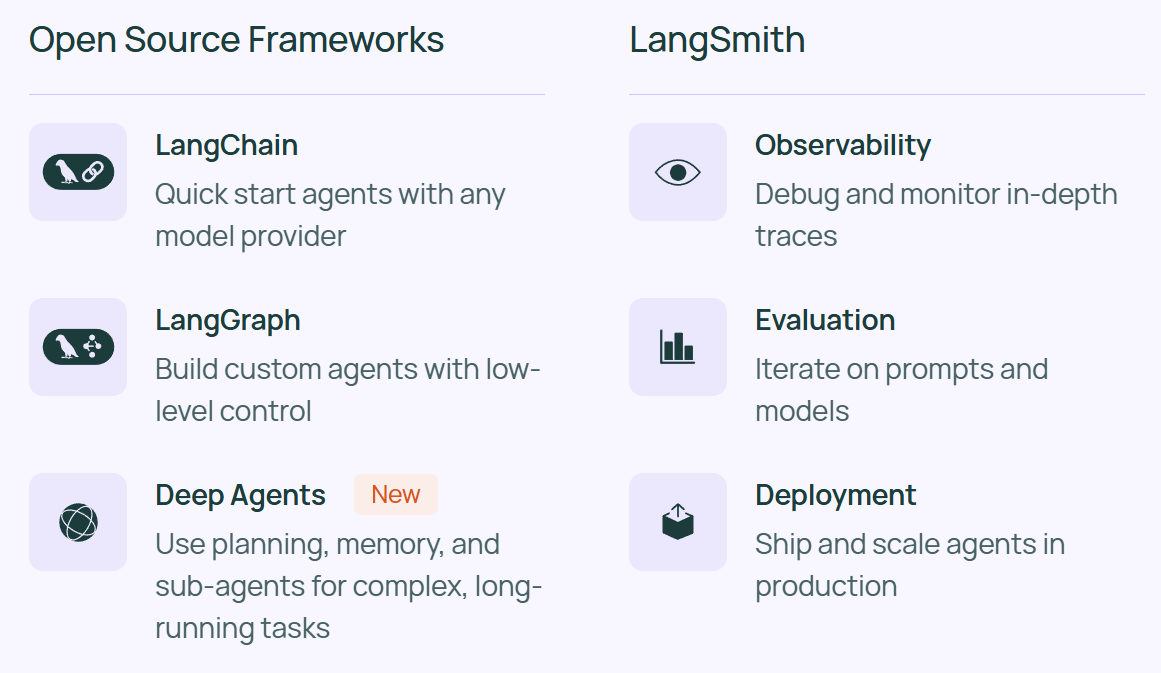
- LangChain 帮助快速开始构建 Agent ,支持选择的任何模型提供商。
- LangGraph 允许通过低级编排、记忆和人工参与支持来控制自定义 Agent 的每一步。可以管理具有持久执行能力的长时间运行任务。
- LangSmith 是一个帮助 AI 团队使用实时生产数据进行持续测试和改进的平台。提供观测、评估与部署功能。
- Deep Agents 用于构建能够规划、使用子 Agent 并利用文件系统处理复杂任务的 Agent,受 Claude Code、Deep Research 和 Manus 等应用的启发。
2) LangChain 架构
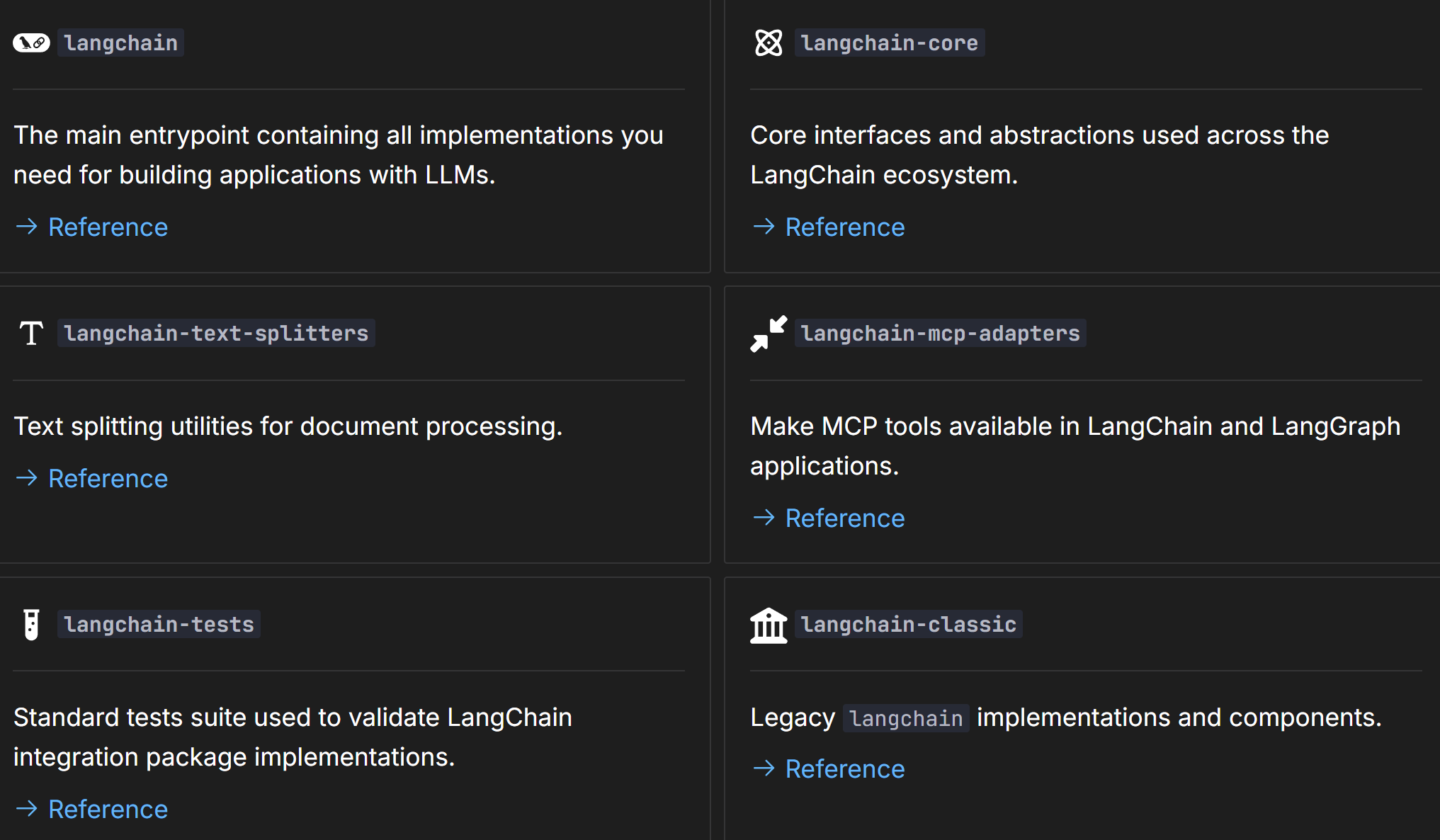
|------------------------------|--------------------------------------|
| 包 | 描述 |
| langchain | 包含构建使用 LLM 的应用所需的所有实现的主入口点 |
| langchain-core | LangChain 生态系统中的核心接口和抽象 |
| langchain-text-splitters | 用于文档处理的文本分割工具 |
| langchain-mcp-adapters | 在 LangChain 和 LangGraph 应用中提供 MCP 工具 |
| langchain-tests | 用于验证 LangChain 集成包实现的标准化测试套件 |
| langchain-classic | 遗留的 angchain 实现和组件 |
1.4 开发架构与开发场景介绍
1.4.1 RAG开发
1)背景
大模型的知识冻结:随着 LLM 规模扩大,训练成本与周期相应增加,模型无法实时学习到最新的信息或动态变化。导致 LLM 难以应对诸如"请推荐现在的热门影片"等时间敏感的问题。
大模型幻觉:涉及到大模型从未在训练过程中学习过的信息时,大模型无法给出准确的答复,转而开始臆想和编造答案。
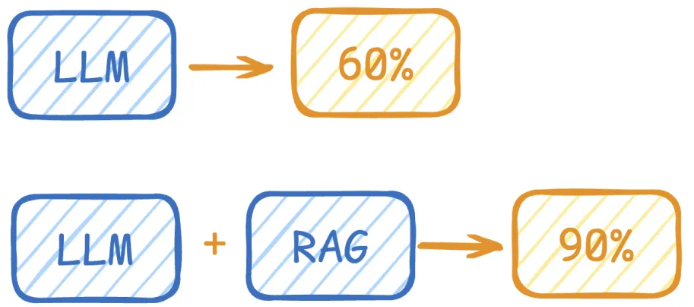
2)RAG举例
LLM在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了,而此时RAG给了一些提示和参考,让LLM根据参考回答,最终考试的正确率从60%到了90%!
1.4.2 Agent开发
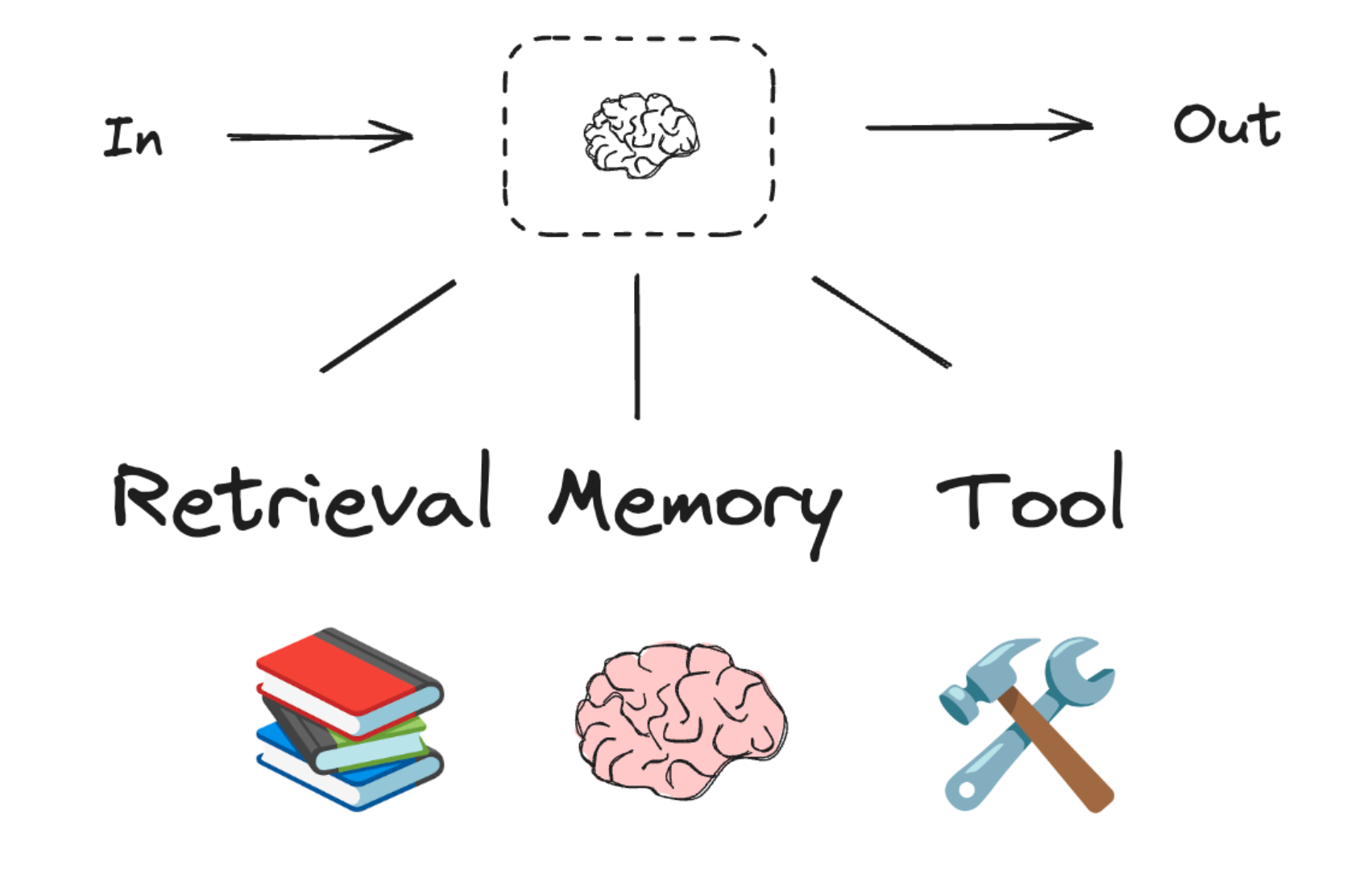
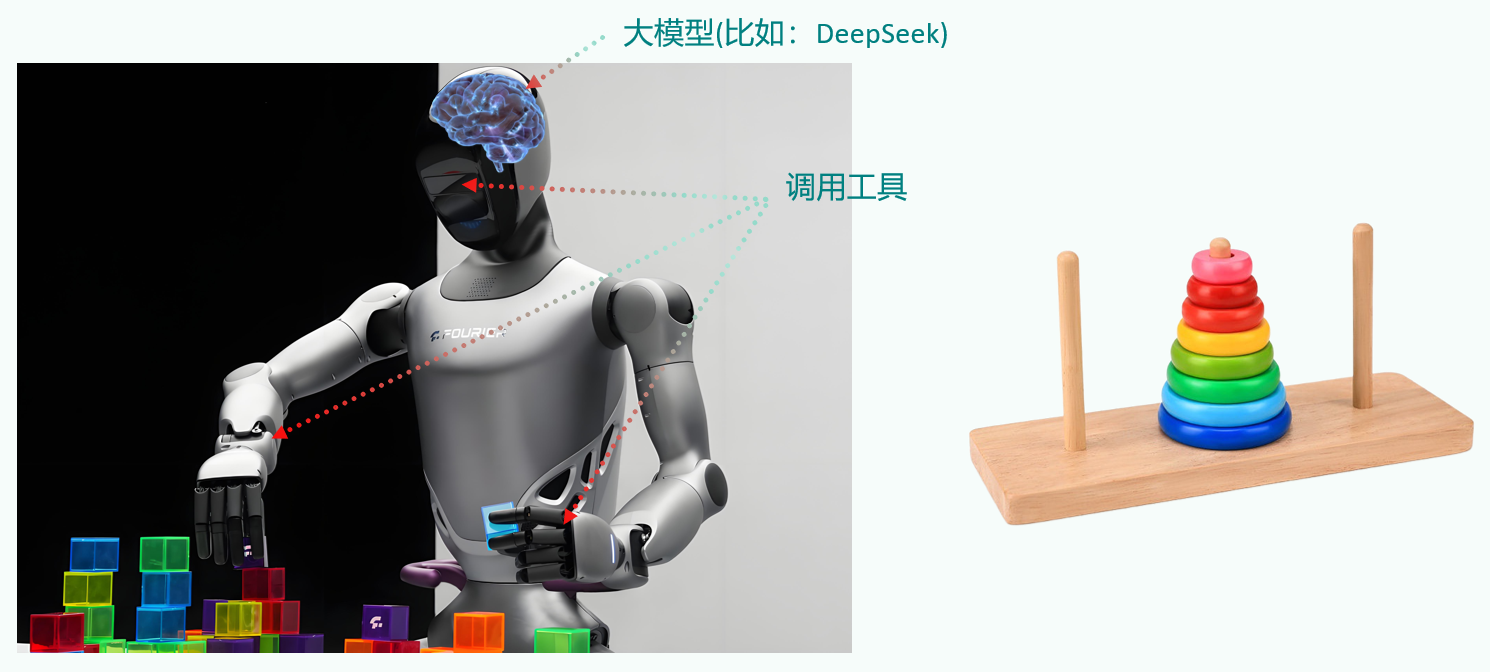
充分利用 LLM 的推理决策能力,通过增加规划、记忆和工具调用的能力,构造一个能够独立思考、逐步完成给定目标的Agent。
OpenAI的元老翁丽莲(Lilian Weng)于2023年6月在个人博客(https://lilianweng.github.io/posts/2023-06-23-agent/)首次提出了现代AI Agent架构。
一个数学公式来表示:
Agent = LLM + Memory + Tools + Planning + Action
比如,打车到西藏玩。
- 大脑中枢:规划行程的你
- 规划:步骤1:规划打车路线,步骤2:订饭店、酒店,。。。
- 调用工具:调用MCP或FunctionCalling等API,滴滴打车、携程、美团订酒店饭店
- 记忆能力:沟通时,要知道上下文。比如订酒店得知道是西藏路上的酒店,不能聊着聊着忘了最初的目的
- 能够执行上述操作。说走就走,不能纸上谈兵。
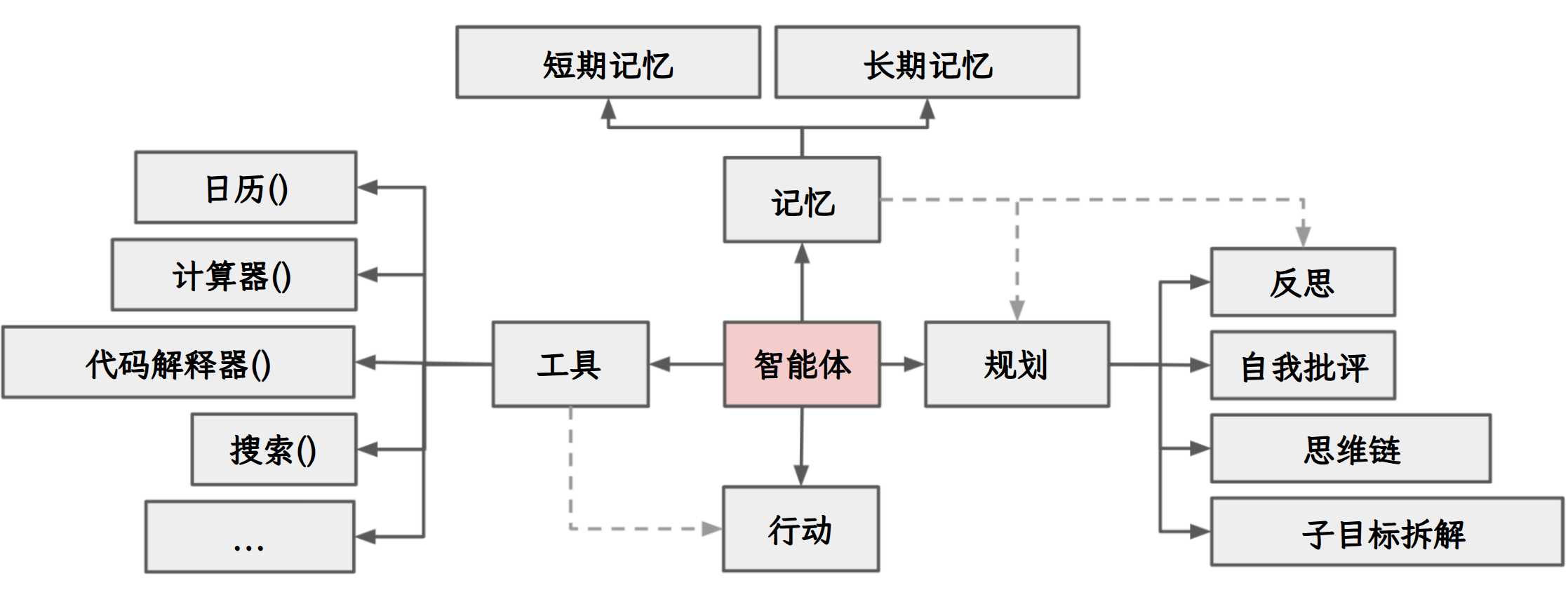
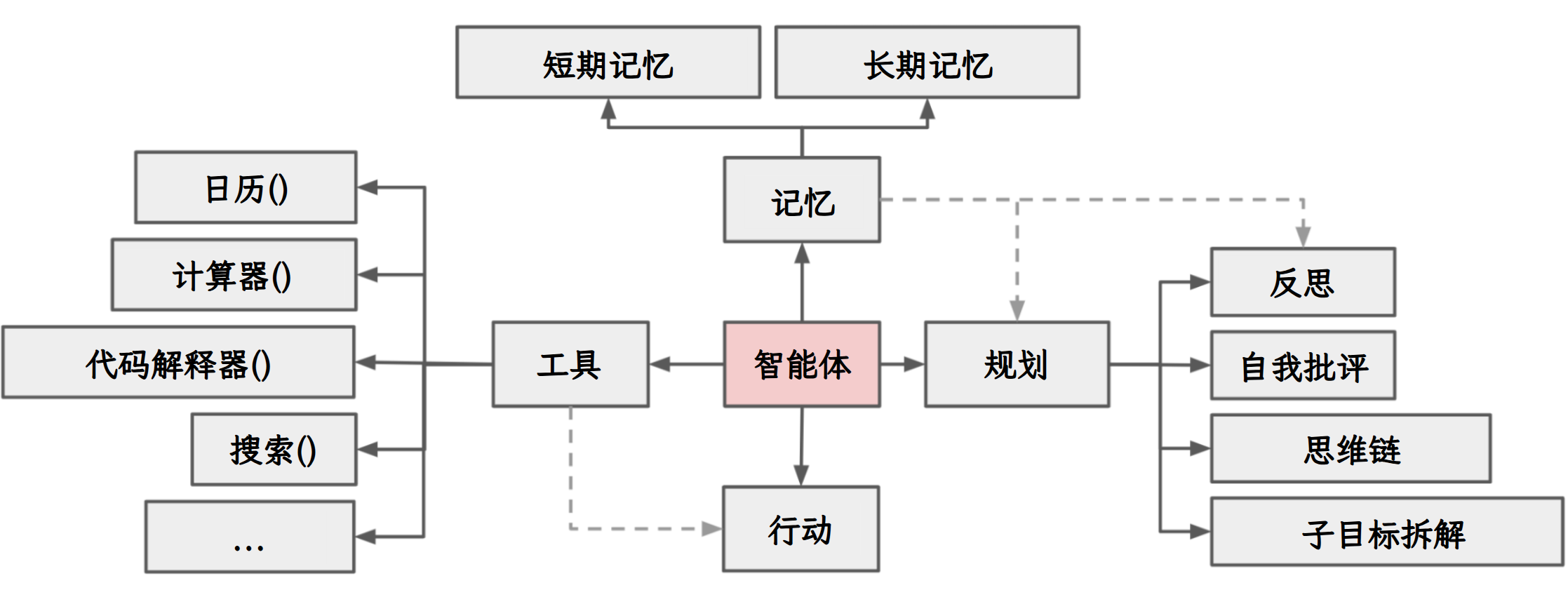
Agent核心要素被细化为以下模块:
1) 大模型( LLM )作为"大脑"
提供推理、规划和知识理解能力,是AI Agent的决策中枢。
大脑主要由一个大型语言模型 LLM 组成,承担着信息处理和决策等功能, 并可以呈现推理和规划的过程,能很好地应对未知任务。
2) 记忆( Memory )
Agent 像人类一样,能留存学到的知识以及交互习惯等,这样的机制能让 Agent 在处理重复工作时调用以前的经验,从而避免用户进行大量重复交互。
- 短期记忆:存储单次对话周期的上下文信息,属于临时信息存储机制。受限于模型的上下文窗口长度。
- 长期记忆:可以横跨多个任务或时间周期,可存储并调用核心知识,非即时任务。长期记忆可以通过模型参数微调(固化知识)、知识图谱(结构化语义网络)或向量数据库(相似性检索)方式实现。
以人作类比:
- 短期记忆:在进行心算时临时记住几个数字
- 长期记忆:学会骑自行车后,多年后再次骑起来时仍能掌握这项技能
3) 工具使用( Tool Use ):调用外部工具(如 API 、数据库)扩展能力边界。
4) 规划决策( Planning ):通过任务分解、反思与自省框架实现复杂任务处理。
例如,利用思维链(Chain of Thought)将目标拆解为子任务,并通过反馈优化策略。
5) 行动( Action ):实际执行决策的模块,涵盖软件接口操作(如自动订票)和物理交互(如机器人执行搬运)。
Agent 会形成完整的计划流程。例如先读取以前工作的经验和记忆,之后规划子目标并使用相应工具去处理问题,最后输出给用户并完成反思。
1.4.3 大模型应用开发的4个场景
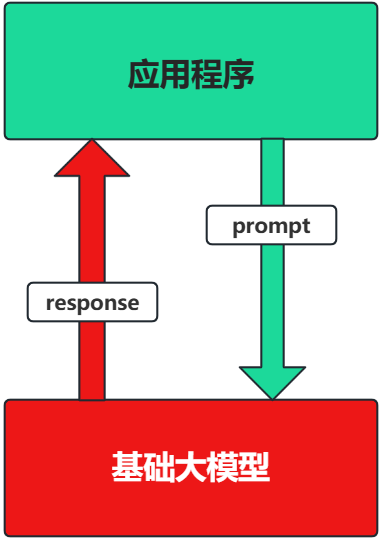
1.4.3.1 场景1:纯 Prompt
Prompt是操作大模型的唯一接口
当人看:你说一句,ta回一句,你再说一句,ta再回一句...
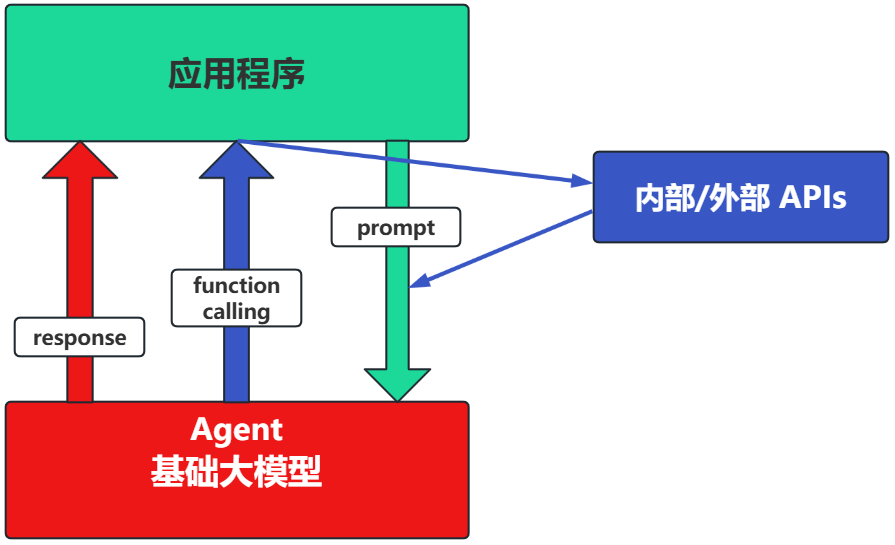
1.4.3.2 场景2:Agent + Function Calling
- Agent:AI 主动提要求
- Function Calling:需要对接外部系统时,AI 要求执行某个函数
当人看:你问 ta「我明天去杭州出差,要带伞吗?」,ta 让你先看天气预报,你看了告诉ta,ta 再告诉你要不要带伞
1.4.3.3 场景3:RAG (Retrieval-Augmented Generation)
- RAG:需要补充领域知识时使用
- Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
- 向量数据库:把向量存起来,方便查找
- 向量搜索:根据输入向量,找到最相似的向量
举例:考试答题时,到书上找相关内容,再结合题目组成答案
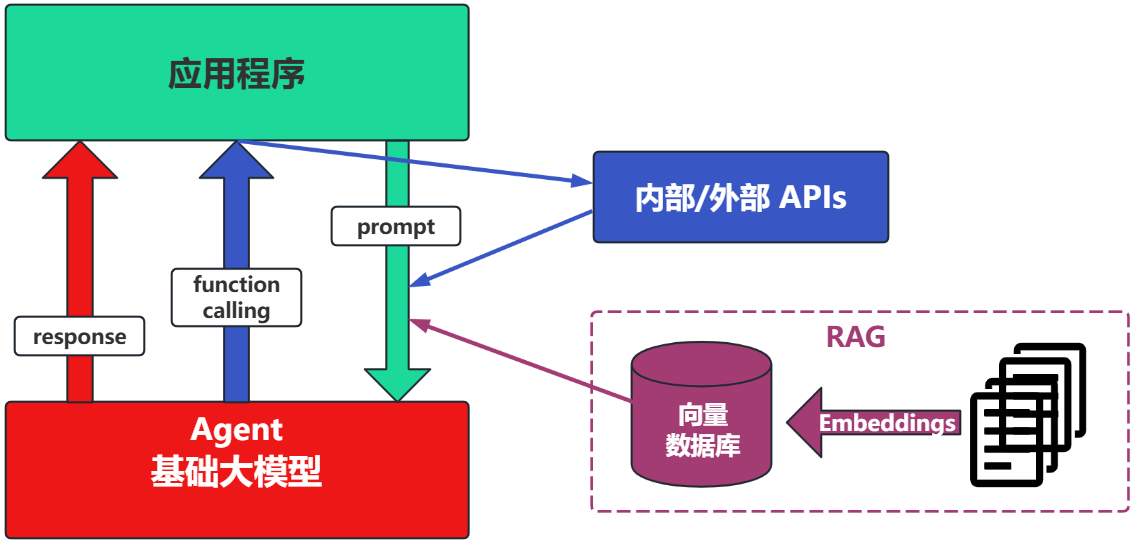
这个在智能客服上用的最广泛。
1.4.3.4 场景4:Fine-tuning(精调/微调)
举例:努力学习考试内容,长期记住,活学活用。
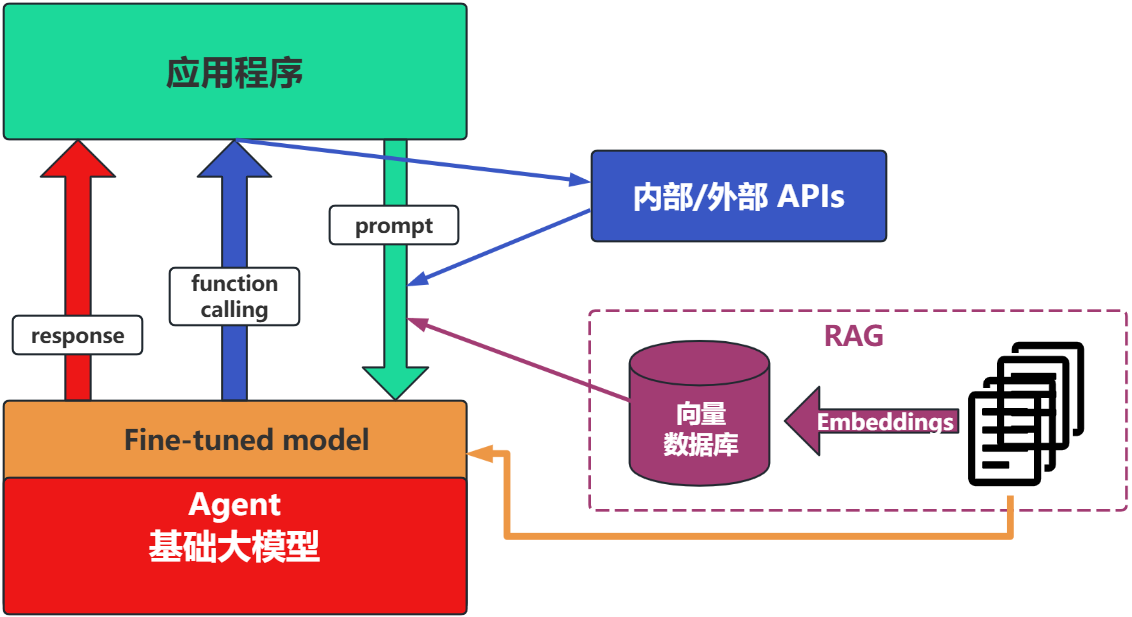
特点:成本最高;在前面的方式解决不了问题的情况下,再使用。
1.4.3.5 如何选择
面对一个需求,如何开始,如何选择技术方案?下面是个常用思路:
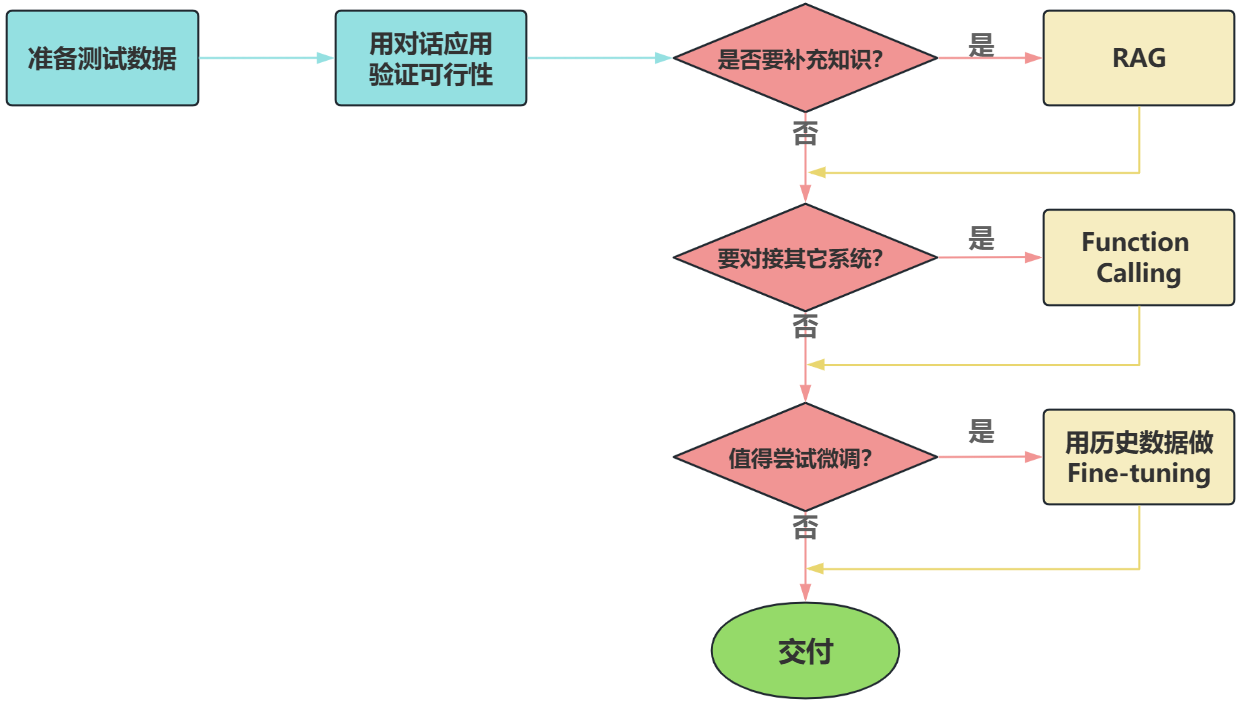
注意:其中最容易被忽略的,是准备测试数据。
后面我们重点介绍大模型应用的开发两类:基于RAG的架构,基于Agent的架构。
1.5 LangChain的核心组件
LangChain的核心组件主要涉及四个部分:Model I/O、Chains、RAG、Agents。
1.5.1 Model I/O
标准化大模型的输入和输出,包含提示模版,模型调用和格式化输出。
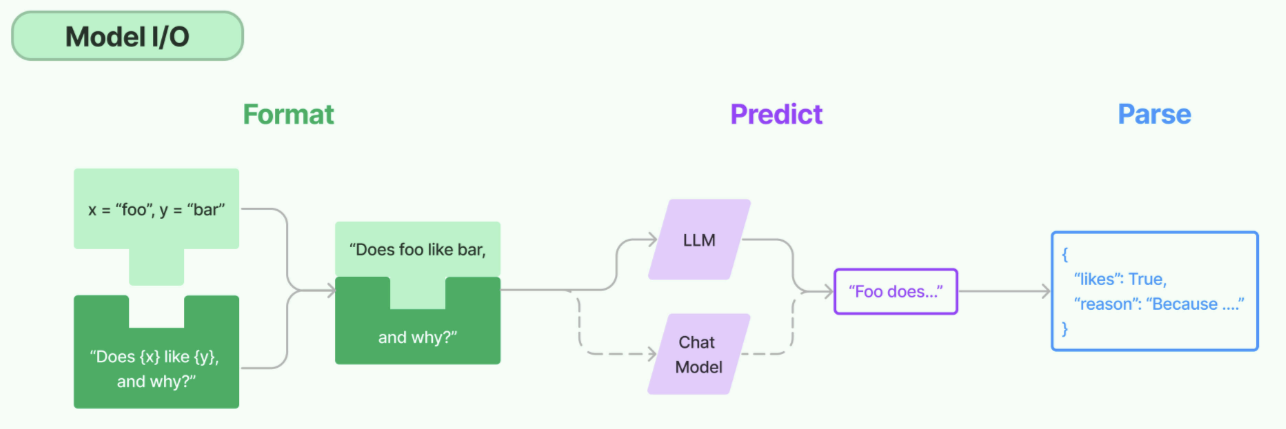
(1)Format(格式化):通过模板管理大模型的输入。将原始数据格式化成模型可以处理的形式,插入到一个模板中,然后送入模型进行处理。
(2)Predict(预测):调用LLM 接收输入,进行预测或生成回答。
(3)Parse(解析):规范化模型输出。比如将模型输出格式化为JSON。
1.5.2 Chains
"链条"用于将多个组件组合成一个完整的流程,方便链式调用。
1.5.3 Retrieval
对应RAG:检索外部数据,作为参考信息输入LLM辅助生成答案。
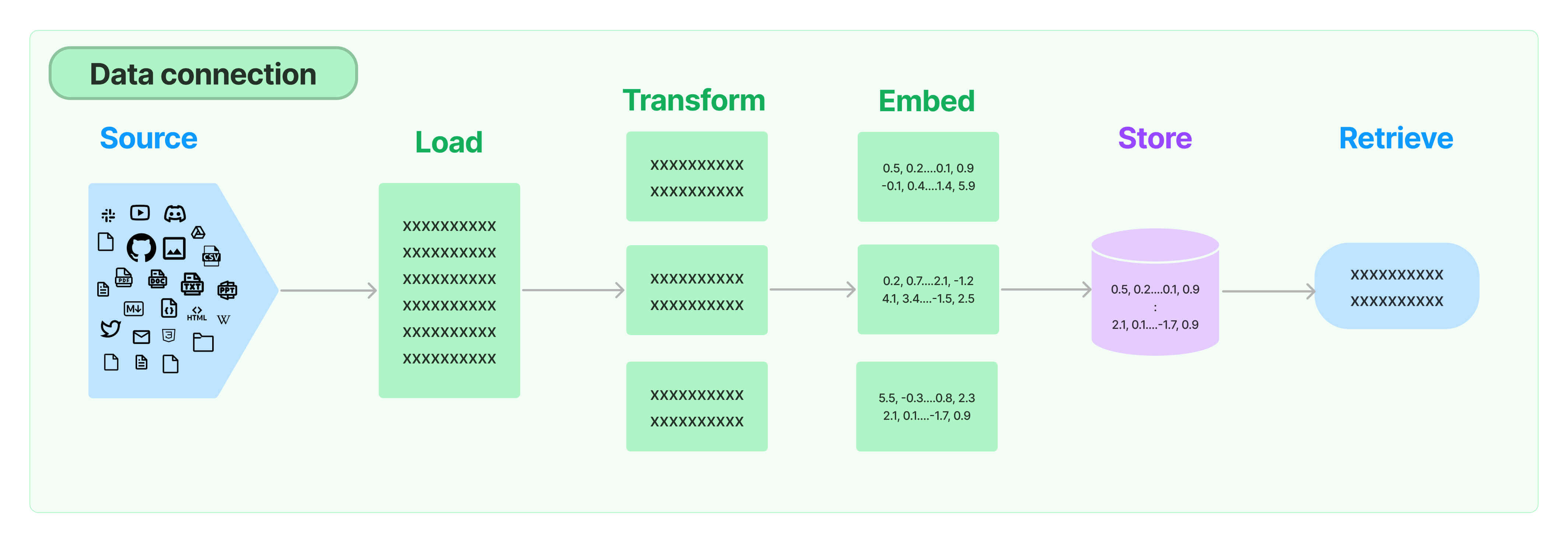
(1)Source:多种类型的数据源:视频、图片、文本、代码、文档等。
(2)Load:将多源异构数据统一加载为文档对象。
(3)Transform:对文档进行转换和处理,比如将文本切分为小块。
(4)Embed:将文本编码为向量。
(5)Store:将向量化后的数据存储起来。
(6)Retrieve:从文本库中检索相关的文本段落。
4) Agents
Agent 自主规划执行步骤并使用工具来完成任务。
第 2 章 Model I/O
2.1 Model I/O 介绍
Model I/O 部分是与语言模型进行交互的核心组件,包括输入提示(Prompt Template)、调用模型(Model)、输出解析(Output Parser)。简单来说,就是输入、处理、输出这三个步骤。
2.2 调用在线模型
2.2.1 大模型服务平台
LangChain作为一个"工具",依赖于第三方集成各种大模型。
有许多提供大模型API服务的平台,使用时只需要注册、充值并创建API-Key,之后即可使用API-Key与URL来调用平台提供的相应的模型的服务。
1) CloseAI : https://platform.closeai-asia.com/
API-Key管理:https://platform.closeai-asia.com/developer/api
API文档:https://doc.closeai-asia.com/tutorial/api/openai.html
模型:https://platform.closeai-asia.com/pricing
2) OpenRouter : https://openrouter.ai/
API-Key管理:https://openrouter.ai/settings/keys
API文档:https://openrouter.ai/docs/community/frameworks-and-integrations-overview
模型:https://openrouter.ai/models
3) 阿里云百炼: https://bailian.console.aliyun.com/
API-Key管理:https://bailian.console.aliyun.com/?tab=model#/api-key
API文档:https://bailian.console.aliyun.com/?tab=doc#/doc/?type=model
模型:https://bailian.console.aliyun.com/?tab=model#/model-market/all
4) 百度千帆: https://console.bce.baidu.com/qianfan/overview
API-Key管理:https://console.bce.baidu.com/qianfan/ais/console/apiKey
API文档:https://cloud.baidu.com/doc/qianfan-docs/s/Mm8r1mejk
模型:https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list
5) 硅基流动: https://www.siliconflow.cn/
API-Key管理:https://cloud.siliconflow.cn/me/account/ak
API文档:https://docs.siliconflow.cn/cn/userguide/capabilities/text-generation
模型:https://cloud.siliconflow.cn/me/models
2.2.2 OpenAI SDK 调用模型
OpenAI 的 GPT 系列模型影响了大模型技术发展的开发范式和标准。所以无论是 Qwen、ChatGLM 等模型,它们的使用方法和函数调用逻辑基本遵循 OpenAI 定义的规范,没有太大差异。这就使得能够通过一个较为通用的接口来接入和使用不同的模型。
python
# pip install langchain langchain-openai
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1", # 平台提供的 URL
api_key="sk-...", # 平台提供的 API-Key
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free", # 模型名称
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}], # 用户输入
)
print(completion.choices[0].message.content)2.2.3 API-Key 管理
通常有3种方式来管理API-Key:硬编码、写入.env文件、写入环境变量。
刚才我们就是将API-Key 硬编码仅代码中,这仅适用于临时测试,存在密钥泄露风险。
2.2.3.1 使用.env 配置文件
使用 python-dotenv 加载本地配置文件,支持多环境管理。该方式有以下优势:
-
配置文件可加入
.gitignore避免泄露 -
支持多环境配置(如
.env.prod和.env.dev) -
创建
.env文件(项目根目录):OPENAI_API_KEY="sk-..."
OPENAI_BASE_URL=" https://openrouter.ai/api/v1"
举例:显式读取.env中的环境变量
python
# pip install python-dotenv
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv() # 默认加载 .env
client = OpenAI(
base_url=os.getenv("OPENAI_BASE_URL"), # 平台提供的 URL
api_key=os.getenv("OPENAI_API_KEY"), # 平台提供的 API Key
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free",
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}],
)
print(completion.choices[0].message.content)举例:依靠OpenAI 的默认行为读取 .env 环境变量
OpenAI 在创建时,会自动到环境变量中找 OPENAI_API_KEY 以及OPENAI_BASE_URL。如果在.env 中配置的名字和上面的两个名字一样,无需再次赋值,只通过 dotenv.load_dotenv() 加载环境配置信息即可。
python
# pip install python-dotenv
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv() # 默认加载 .env
client = OpenAI()
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free",
messages=[{"role": "user", "content": "将'你好'翻译成意大利语"}],
)
print(completion.choices[0].message.content)2) 在环境变量中配置
通过系统环境变量存储API-Key,避免代码明文暴露。
终端设置变量(临时生效):
export OPENAI_API_KEY="sk-..." # Linux/Mac
set OPENAI_API_KEY="sk-..." # Windows CMD在代码中通过os.getenv() 读取API-Key:
python
import os
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENAI_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-20b:free",
messages=[{"role": "user", "content": "你好"}],
)
print(completion.choices[0].message.content)2.2.4 LangChain API 调用模型
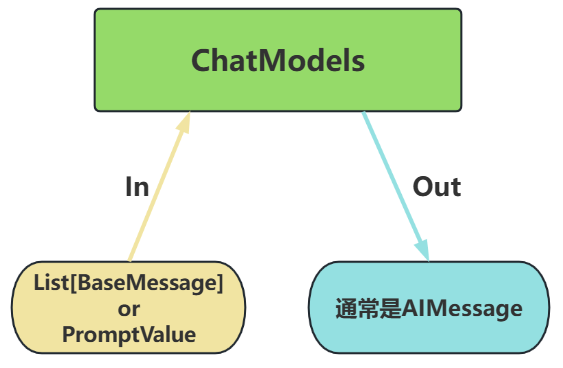
通常通过聊天模型接口访问LLM,该接口通常以消息列表作为输入并返回一条消息作为输出。
- 输入:接受文本PromptValue 或消息列表ListBaseMessage,每条消息需指定角色(如SystemMessage、HumanMessage、AIMessage)
- 输出:返回带角色的消息对象(BaseMessage 子类),通常是AIMessage
举例:
python
import os
from langchain.chat_models import init_chat_model
from langchain.messages import SystemMessage, HumanMessage, AIMessage
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
SystemMessage(content="你是一个诗人"),
HumanMessage(content="写一首关于春天的诗"),
]
resp = llm.invoke(messages)
print(type(resp)) # <class 'langchain_core.messages.ai.AIMessage'>
print(resp.content)2.2.5 模型初始化相关参数
初始化一个模型最简单的方法就是使用init_chat_model,并设置必要的参数,例如 API-Key 和模型名称。除此之外还有一些其他参数。
|-----------------|-----------------------------------|
| 参数 | 说明 |
| model | 模型名称或标识符 |
| base_url | 发送请求的 API 端点的 URL。常由模型的提供商提供 |
| api_key | 与模型提供商进行身份验证所需的 API 密钥 |
| temperature | 控制模型输出的随机性。数字越高,回答越有创意;数字越低,回答越确定 |
| timeout | 在取消请求之前,等待模型响应的最大时间(以秒为单位) |
| max_tokens | 限制响应中的总tokens 数量,控制输出长度 |
| max_retries | 请求失败时系统尝试重新发送请求的最大次数 |
🎯 Token是什么?
大模型处理的最小单位是token(相当于自然语言中的词或字),输出时逐个 token 依次生成。模型提供商通常也是以 token 的数量作为其计量或收费的依据。1个中文Token≈1-1.8个汉字,1个英文Token≈3-4字母。
Token与字符转化的可视化工具:
- OpenAI提供:https://platform.openai.com/tokenizer
- 百度智能云提供:https://console.bce.baidu.com/support/#/tokenizer
2.2.6 对话模型的 Message
对话模型的输入可以是文本提示、消息提示或是字典格式。
1) 文本提示
文本提示是字符串,适用于不需要保留对话历史的直接生成任务。
resp = llm.invoke("你好")2) 消息提示
将消息对象列表输入模型,方便管理对话历史,包含系统指令以及处理多模态数据。
messages = [
SystemMessage("你是个诗人"),
HumanMessage("写首关于春天的诗"),
]
resp = llm.invoke(messages)3) 字典格式
也可以按照OpenAI 聊天补全格式创建字典列表组成消息。一条消息通常包含 role(角色)、content(内容)、metadata(元数据)。
messages = [
{"role": "system", "content": "你是个诗人"},
{"role": "user", "content": "写首关于春天的诗"},
]
resp = llm.invoke(messages)4) 消息类型
|-------------------|-----------------------------------------------------|
| 消息类型 | 描述 |
| SystemMessage | 代表一组初始指令,用于引导模型的行为。可以使用系统消息来设定语气、定义模型的角色,并建立响应的指导方针 |
| HumanMessage | 表示用户输入 |
| AIMessage | 模型生成的响应,包括文本内容、工具调用和元数据 |
| ToolMessage | 表示工具调用的输出 |
- HumanMessage、AIMessage 和 SystemMessage 是常用的消息类型。
- ToolMessage 是在工具调用场景下才会使用的特殊消息类型。
2.2.7 调用方法
聊天模型提供了三种主要的调用方法:
|------------------|--------------|
| invoke / ainvoke | 将单个输入转换为输出 |
| batch / abatch | 批量将多个输入转换为输出 |
| stream / astream | 从单个输入生成流式输出 |
带有"a"前缀的方法是异步的,需要与 asyncio 和await 语法一起使用以实现并发。
2.2.7.1 非流式/流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出 与非流式输出。
- **非流式输出:**用户提出需求请编写一首诗,系统在静默数秒后突然弹出了完整的诗歌。如同一种"提交请求,等待结果"的流程,实现简单,但体验单调。
- **流式输出:**用户提问,请编写一首诗,当问题刚刚发送,系统就开始一字一句(逐个token)进行回复,更像是"实时对话",贴近人类交互的习惯。
1) 非流式输出:
这是LangChain 与 LLM 交互时的默认行为,是最简单、最稳定的语言模型调用方式。当用户发出请求后,系统在后台等待模型生成完整响应,然后一次性将全部结果返回。
举例:invoke() 调用
python
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一名数学家"},
{"role": "user", "content": "请证明以下黎曼猜想"},
]
resp = llm.invoke(messages)
print(resp.content)2) 流式输出
流式输出是一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token地实时返回内容。适合构建强调"实时反馈"的应用。
举例:stream() 流式输出
python
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一名数学家"},
{"role": "user", "content": "请证明以下黎曼猜想"},
]
# 使用 stream() 方法流式输出
for chunk in llm.stream(messages):
# 逐个打印内容块,并刷新缓冲区以即时显示内容
print(chunk.content, end="", flush=True)2.2.7.2 批量调用
将一组独立的请求批量发送给模型并行处理。
举例:batch() 批量调用
python
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
resp = llm.batch(messages) # 批量调用,返回一个消息列表
print(resp)batch 默认没有依赖底层 API 的原生批量接口,而是使用线程池并行执行多个 invoke()。所以它对 IO 密集型任务(如调用远程 LLM API)很有效。
如果底层 API 自身提供批量接口(一次请求多个 prompt),那么子类可以重写 batch 方法来直接使用批量接口,这样效率会更高。
2.2.7.3 同步/异步调用
1) 同步调用
每个操作依次执行,直到当前操作完成后才开始下一个操作,总的执行时间是各个操作时间的总和。
举例:使用invoke() 同步调用
python
import os
import time
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messagess = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
start_time = time.time()
resps = [llm.invoke(messages) for messages in messagess]
print(resps)
end_time = time.time()
print(f"Total time: {end_time - start_time}")
# Total time: 17.7894861698150632) 异步调用
异步调用,允许程序在等待某些操作完成时继续执行其他任务,而不是阻塞等待。这在处理I/O 操作(如网络请求、文件读写等)时特别有用,可以显著提高程序的效率和响应性。
举例:使用ainvoke() 异步调用
python
import os
import time
import asyncio
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messagess = [
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于春天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于夏天的诗"},
],
[
{"role": "system", "content": "你是一位诗人"},
{"role": "user", "content": "写一首关于秋天的诗"},
],
]
async def async_invoke():
tasks = [llm.ainvoke(messages) for messages in messagess]
return await asyncio.gather(*tasks)
start_time = time.time()
resps = asyncio.run(async_invoke())
print(resps)
end_time = time.time()
print(f"Total time: {end_time - start_time}")
# Total time: 8.280137062072754使用asyncio.gather() 并行执行时,因为多个任务几乎同时开始,它们的执行时间将重叠。理想情况下,如果多个任务的执行时间相同,那么总执行时间应该接近单个任务的执行时间。
2.3 调用本地模型
2.3.1 Ollama介绍
Ollama是一个开源项目,其项目定位是:一个本地运行大模型的集成框架。目前主要针对主流的LlaMA架构的开源大模型设计,可以实现如 Qwen、Deepseek 等主流大模型的下载、启动和本地运行的自动化部署及推理流程。
目前作为一个非常热门的大模型托管平台,已被包括LangChain、Taskweaver等在内的多个热门项目高度集成。
- Ollama官方地址:https://ollama.com
- Ollama Github开源地址:https://github.com/ollama/ollama
2.3.2 Ollama安装
Ollama项目支持跨平台部署,目前已兼容Mac、Linux和Windows操作系统。

无论使用哪个操作系统,Ollama项目的安装过程都设计得非常简单。
访问 https://ollama.com/download 下载对应系统的安装文件。
-
Windows 系统执行.exe文件安装
-
Linux 系统执行以下命令安装:
curl -fsSL https://ollama.com/install.sh | sh
这行命令的目的是从https://ollama.com/ 网站读取 install.sh脚本,并立即通过 sh 执行该脚本,在安装过程中会包含以下几个主要的操作:
检查当前服务器的基础环境,如系统版本等;
下载Ollama的二进制文件;
配置系统服务,包括创建用户和用户组,添加Ollama的配置信息;
启动Ollama服务;
2.3.3 模型下载
访问https://ollama.com/search可以查看Ollama支持的模型。使用命令行可以下载并运行模型,例如运行deepseek-r1:7b模型:
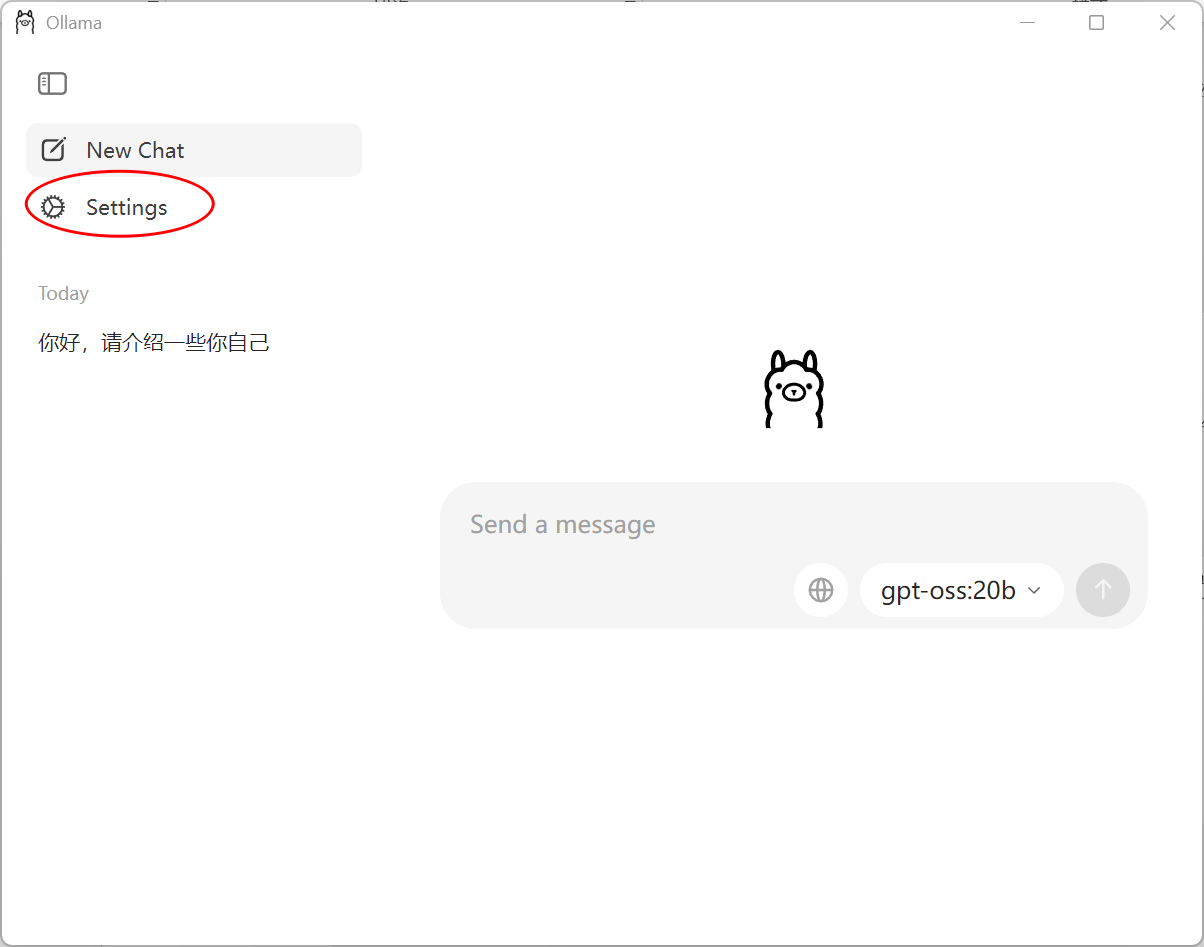
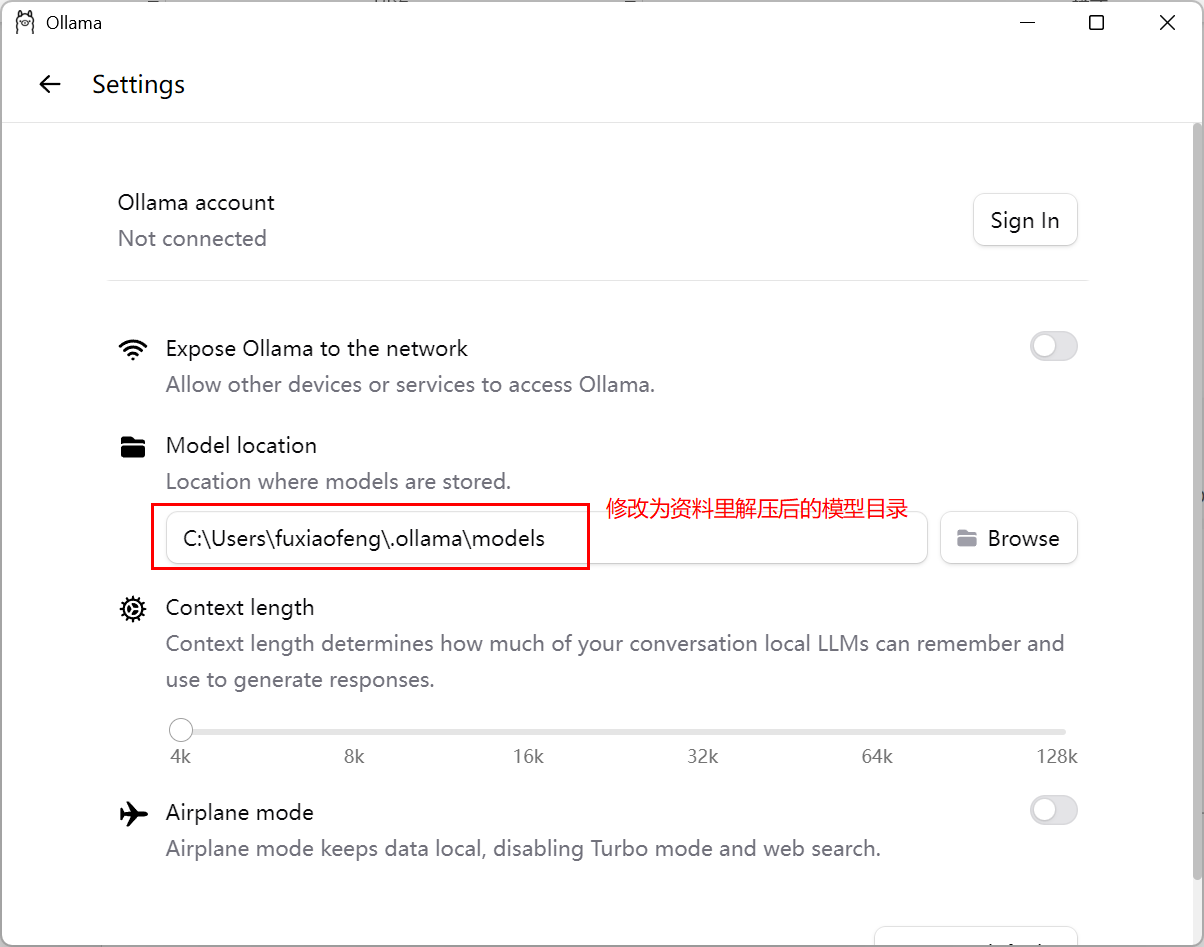
ollama run deepseek-r1:7b因为文件比较大,所以直接用我给大家提供的资料,需要做如下配置
1) 进入到 Settings
2) 切换模型目录
3) 运行模型 ollama run deepseek-r1:7b
ollama run deepseek-r1:7b2.3.4 调用本地模型
举例:
python
# pip install langchain-ollama
from langchain_ollama import ChatOllama
ollama_llm = ChatOllama(model="deepseek-r1:7b")
messages = {"role": "user", "content": "你好,请介绍一下你自己"}
resp = ollama_llm.invoke(messages)
print(resp.content)若 Ollama 不在本地默认端口运行,需指定 base_url,即:
python
# pip install langchain-ollama
from langchain_ollama import ChatOllama
ollama_llm = ChatOllama(
model="deepseek-r1:7b",
base_url="http://your-ip:port", # 自定义地址
)
messages = {"role": "user", "content": "你好,请介绍一下你自己"}
resp = ollama_llm.invoke(messages)
print(resp.content)2.4 Prompt Template
2.4.1 提示词模板介绍
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,Prompt Template 是一个模板化的字符串,我们可以将变量插入到模板中,从而创建出不同的提示。Prompt Template 接收用户输入,返回一个传递给LLM的信息(即提示词 prompt)。
提示模板以字典作为输入,其中每个键代表要填充的提示模板中的变量。并输出一个 PromptValue。这个 PromptValue 可以传递给聊天模型,也可以转换为字符串或消息列表。PromptValue 存在的目的是为了方便在字符串和消息之间切换。
有多种类型的提示模板,常用的有PromptTemplate(字符串提示模板)和ChatPromptTemplate(聊天提示模板)。
2.4.2 复习:str.format()
Python的str.format()方法是一种字符串格式化的手段,允许在字符串中插入变量。使用这种方法,可以创建包含占位符的字符串模板,占位符由花括号{}标识。
- 调用
format()方法时,可以传入一个或多个参数,这些参数将被顺序替换进占位符中。 str.format()提供了灵活的方式来构造字符串,支持多种格式化选项。- 在LangChain的默认设置下,
PromptTemplate使用Python的str.format()方法进行模板化。这样在模型接收输入前,可以根据需要对数据进行预处理和结构化。
基本用法
# 简单示例,直接替换
greeting = "Hello, {}!".format("Alice")
print(greeting)
# 输出: Hello, Alice!带有位置参数的用法
# 使用位置参数
info = "Name: {0}, Age: {1}".format("Jerry", 25)
print(info)
# 输出:Name: Jerry, Age: 25带有关键字参数的用法
# 使用关键字参数
info = "Name: {name}, Age: {age}".format(name="Tom", age=25)
print(info)
#输出: Name: Tom, Age: 25使用字典解包的方式
# 使用字典解包
person = {"name": "David", "age": 40}
info = "Name: {name}, Age: {age}".format(**person)
print(info)
#输出: Name: David, Age: 402.4.3 PromptTemplate
PromptTemplate 用于快速构建包含变量的提示词模板,并通过传入不同的参数值生成自定义的提示词。
|-----------------------|-----------------------------------------------|
| 参数 ||
| t emplate | 提示模板,包括变量占位符 |
| input_variables | 需要将其值作为提示输入的变量名称列表 |
| partial_variables | 提示模板携带的部分变量的字典。使用部分变量预先填充模板,无需后续在每次调用时再传递这些变量 |
| 方法 ||
| format() | 使用输入格式化提示 |
2.4.3.1 实例化
方式1:使用构造方法实例化提示词模板
python
from langchain_core.prompts import PromptTemplate
# 使用构造方法实例化提示词模板
template = PromptTemplate(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
input_variables=["product", "aspect1", "aspect2"],
)
# 使用模板生成提示词
prompt_1 = template.format(product="智能手机", aspect1="电池续航", aspect2="拍照质量")
prompt_2 = template.format(product="笔记本电脑", aspect1="处理速度", aspect2="便携性")
print(prompt_1) # 请评价智能手机的优缺点,包括电池续航和拍照质量。
print(prompt_2) # 请评价笔记本电脑的优缺点,包括处理速度和便携性。方式2:使用 from_template 方法实例化提示词模板
python
from langchain_core.prompts import PromptTemplate
# 使用 from_template 方法实例化提示词模板
template = PromptTemplate.from_template("请给我一个关于{topic}的{type}解释。")
# 使用模板生成提示
prompt = template.format(type="详细", topic="量子力学")
print(prompt) # 请给我一个关于量子力学的详细解释。2.4.3.2 部分提示模版
在生成提示之前可以赋予部分变量默认值。
- 方式1:实例化过程中指定 partial_variables 参数
python
from langchain_core.prompts import PromptTemplate
template = PromptTemplate(
template="{foo} {bar}",
input_variables=["foo", "bar"],
partial_variables={"foo": "hello"}, # 预先定义部分变量
)
prompt = template.format(bar="world")
print(prompt) # hello world- 方式2:使用 partial 方法指定默认值
python
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template("{foo} {bar}")
partial_template = template.partial(foo="hello") # 预先定义部分变量
prompt = partial_template.format(bar="world")
print(prompt) # hello world2.4.3.3 调用方式
除了format 方法,也可以使用 invoke 方法调用。
invoke 方法返回 PromptValue 对象,可以使用 to_string 方法将其转换为字符串。
举例:invoke 方法调用
python
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template("{foo} {bar}")
prompt = template.invoke({"foo": "hello", "bar": "world"})
print(prompt, type(prompt))
# text='hello world' <class 'langchain_core.prompt_values.StringPromptValue'>
prompt_str = prompt.to_string()
print(prompt_str, type(prompt_str))
# hello world <class 'str'>2.4.4 ChatPromptTemplate
ChatPromptTemplate是创建聊天消息列表的提示模板。相较于普通 PromptTemplate更适合处理多角色、多轮次的对话场景。支持 System/Human/AI 等不同角色的消息模板。
2.4.4.1 实例化
ChatPromptTemplate 可以通过构造方法或 from_messages 方法来实例化提示词模板。
实例化时需要传入messages 参数,messages 参数支持如下格式:
- tuple 构成的列表,格式为(role, content)
- dict 构成的列表,格式为{"role":... , "content":...}
- Message 类构成的列表
举例:
python
from langchain_core.prompts import ChatPromptTemplate
template = ChatPromptTemplate(
[
("system", "你是一个AI开发工程师,你的名字是{name}。"),
("human", "你能帮我做什么?"),
("ai", "我能开发很多{thing}。"),
("human", "{user_input}"),
]
)
prompt = template.format_messages(name="小谷AI", thing="AI", user_input="行")
print(prompt)
# [
# SystemMessage(content="你是一个AI开发工程师,你的名字是小谷AI。",...),
# HumanMessage(content="你能帮我做什么?", ...),
# AIMessage(content="我能开发很多AI。", ...),
# HumanMessage(content="行", ...),
# ]2.4.4.2 调用方式
推荐使用from_messages 方法或 invoke 方法调用。
举例:invoke 方法调用
python
from langchain_core.prompts import ChatPromptTemplate
template = ChatPromptTemplate(
[
("system", "你是一个AI开发工程师,你的名字是{name}。"),
("human", "你能帮我做什么?"),
("ai", "我能开发很多{thing}。"),
("human", "{user_input}"),
]
)
prompt = template.invoke({"name": "小谷AI", "thing": "AI", "user_input": "行"})
print(prompt)
# messages=[
# SystemMessage(content="你是一个AI开发工程师,你的名字是小谷AI。",...),
# HumanMessage(content="你能帮我做什么?", ...),
# AIMessage(content="我能开发很多AI。", ...),
# HumanMessage(content="行", ...),
# ]2.4.4.3 消息占位符
当希望在格式化过程中插入消息列表时,比如Agent 暂存中间步骤,需要使用 MessagesPlaceholder,负责在特定位置添加消息列表。
举例:
python
from langchain_core.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages(
[
("system", "你是一个助手。"),
("placeholder", "{conversation}"),
# 等同于 MessagesPlaceholder(variable_name="conversation", optional=True)
]
)
prompt = template.format_messages(
conversation=[
("human", "你好!"),
("ai", "想让我帮你做些什么?"),
("human", "能帮我做一个冰淇凌吗?"),
("ai", "不能"),
]
)
print(prompt)
# [
# SystemMessage(content="你是一个助手。", ...),
# HumanMessage(content="你好!", ...),
# AIMessage(content="想让我帮你做些什么?", ...),
# HumanMessage(content="能帮我做一个冰淇凌吗?", ...),
# AIMessage(content="不能", ...),
# ]2.4.4.4 多模态提示词
可以使用提示模板来格式化多模态输入,比如将图片链接作为输入。
举例:
python
import os
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
llm = init_chat_model(
model="google/gemini-2.0-flash-exp:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
template = ChatPromptTemplate(
[
{"role": "system", "content": "用中文简短描述图片内容"},
{"role": "user", "content": [{"image_url": "{image_url}"}]},
]
)
prompt = template.format_messages(
image_url="https://img2.baidu.com/it/u=2976763563,2523722948&fm=253&app=138&f=JPEG?w=800&h=1200"
)
resp = llm.invoke(prompt)
print(resp.content) # 图片中是...2.4.5 外部加载Prompt
可以将prompt 保存为 JSON 或者 YAML 等格式的文件,通过读取指定路径的格式化文件,获取相应的 prompt。这样方便对 prompt 进行管理和维护。
2.4.5.1 json格式提示词
prompts目录下创建json文件:prompt.json
python
{
"_type": "prompt",
"input_variables": ["name", "what"],
"template": "请{name}讲一个{what}的故事"
}代码:
python
from langchain_core.prompts import load_prompt
template = load_prompt("prompts/prompt.json", encoding="utf-8")
print(template.format(name="张三", what="搞笑的"))
# 请张三讲一个搞笑的的故事2.4.5.2 yaml格式提示词
prompts目录下创建yaml文件:prompt.yaml
_type: "prompt"
input_variables: ["name", "what"]
template: "请{name}讲一个{what}的故事"代码:
python
from langchain_core.prompts import load_prompt
template = load_prompt("prompts/prompt.yaml", encoding="utf-8")
print(template.format(name="年轻人", what="滑稽"))
# 请年轻人讲一个滑稽的故事2.5 Output Parsers
2.5.1 输出解析器介绍
在应用开发中,大模型的输出可能是下一步逻辑处理的关键输入。因此,在这种情况下,规范化输出是必须要做的任务,以确保应用能够顺利进行后续的逻辑处理。
语言模型返回的内容通常都是文本字符串,而实际AI 应用开发过程中有时希望模型可以返回更直观、更格式化的内容,LangChain 提供了输出解析器(Output Parser)将模型输出解析为结构化数据。
有多种类型的输出解析器,常用的有StrOutputParser(字符串解析器)与JsonOutputParser(JSON解析器)。
2.5.2 StrOutputParser
StrOutputParser 是一个简单的解析器,从结果中提取content 字段。
举例:将模型输出结果解析为字符串
python
import os
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
messages = [
{"role": "system", "content": "你是一个机器人"},
{"role": "user", "content": "你好"},
]
resp = llm.invoke(messages)
print(resp) # content='你好!有什么我可以帮忙的吗?' additional_kwargs=......
str_resp = StrOutputParser().invoke(resp)
print(str_resp) # 你好!有什么我可以帮忙的吗?2.5.3 JsonOutputParser
JSON 解析器用于将大模型的自由文本输出转换为结构化JSON数据的工具。特别适用于需要严格结构化输出的场景,比如API 调用、数据存储或下游任务处理。
JsonOutputParser 能够结合Pydantic 模型进行数据验证,自动验证字段类型和内容(如字符串、数字、嵌套对象等)
使用get_format_instructions() 获取JSON解析的格式化指令:
python
from pydantic import BaseModel, Field
from langchain_core.output_parsers import JsonOutputParser
class Prime(BaseModel):
prime: list[int] = Field(description="素数")
count: list[int] = Field(description="小于该素数的素数个数")
json_parser = JsonOutputParser(pydantic_object=Prime)
print(json_parser.get_format_instructions())
# The output should be formatted as a JSON instance that conforms to the JSON schema below.
# ......举例:
python
import os
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import JsonOutputParser
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
class Prime(BaseModel):
prime: list[int] = Field(description="素数")
count: list[int] = Field(description="小于该素数的素数个数")
json_parser = JsonOutputParser(pydantic_object=Prime)
messages = [
{"role": "system", "content": json_parser.get_format_instructions()},
{
"role": "user",
"content": "任意生成5个1000-100000之间素数,并标出小于该素数的素数个数",
},
]
resp = llm.invoke(messages)
json_resp = json_parser.invoke(resp)
print(json_resp)
# {'prime': [1009, 2003, 3001, 4001, 5003], 'count': [168, 303, 430, 584, 669]}2.6 Structured Outputs
可以要求模型按照给定的模式格式提供其响应,这有助于确保输出可以被轻松解析并在后续处理中使用。LangChain 支持多种模式类型和强制结构化输出的方法。
2.6.1 TypedDict
TypedDict 提供了一个使用 Python 内置类型的简单方案,但是没有验证功能。
python
import os
from typing import TypedDict, Annotated
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
class Animal(TypedDict):
animal: Annotated[str, "动物"]
emoji: Annotated[str, "表情"]
class AnimalList(TypedDict):
animals: Annotated[list[Animal], "动物与表情列表"]
messages = [{"role": "user", "content": "任意生成三种动物,以及他们的 emoji 表情"}]
llm_with_structured_output = llm.with_structured_output(AnimalList)
resp = llm_with_structured_output.invoke(messages)
print(resp)
# {'animals': [{'animal': '猫', 'emoji': '🐱'}, {'animal': '老虎', 'emoji': '🐯'}, {'animal': '企鹅', 'emoji': '🐧'}]}2.6.2 Pydantic
Pydantic 模型提供了丰富的功能集,包括字段验证、描述和嵌套结构。
python
import os
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
class Animal(BaseModel):
animal: str = Field(description="动物")
emoji: str = Field(description="表情")
class AnimalList(BaseModel):
animals: list[Animal] = Field(description="动物与表情列表")
messages = [{"role": "user", "content": "任意生成三种动物,以及他们的 emoji 表情"}]
llm_with_structured_output = llm.with_structured_output(AnimalList)
resp = llm_with_structured_output.invoke(messages)
print(resp)
# animals=[Animal(animal='猫', emoji='🐱'), Animal(animal='乌龟', emoji='🐢'), Animal(animal='企鹅', emoji='🐧')]2.6.3 JSON Schema
若需最大程度的控制或互操作性,可以提供一个原始的JSON Schema。详情可参考 https://platform.openai.com/docs/guides/structured-outputs/json-schema#supported-schemas。
可以将原始响应与解析后的表示一起返回,可在调用with_structured_output 时设置 include_raw=True 来实现。
python
import os
from langchain.chat_models import init_chat_model
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
schema = {
"name": "animal_list",
"schema": {
"type": "array",
"items": {
"type": "object",
"properties": {
"animal": {"type": "string", "description": "动物名称"},
"emoji": {"type": "string", "description": "动物的emoji表情"},
},
"required": ["animal", "emoji"],
},
},
}
messages = [{"role": "user", "content": "任意生成三种动物,以及他们的 emoji 表情"}]
llm_with_structured_output = llm.with_structured_output(
schema, method="json_schema", include_raw=True
)
resp = llm_with_structured_output.invoke(messages)
print(resp)
print(resp["raw"])
print(resp["parsed"])
# [{'animal': '企鹅', 'emoji': '🐧'}, {'animal': '大象', 'emoji': '🐘'}, {'animal': '袋鼠', 'emoji': '🦘'}]第 3 章 Chains
3.1 Runnable与LCEL
3.1.1 Runnable
Runnable 是 LangChain 中可以调用、批处理、流式传输、转换和组合的工作单元。
Runnable 接口是使用 LangChain 组件的基础,它在许多组件中实现,例如语言模型、输出解析器、检索器、编译的 LangGraph 图等。
Runnable 接口强制要求所有LCEL 组件实现一组标准方法:
|------------------|--------------|
| invoke / ainvoke | 将单个输入转换为输出 |
| batch / abatch | 批量将多个输入转换为输出 |
| stream / astream | 从单个输入生成流式输出 |
| ... ||
为什么需要统一调用方式?
假设没有统一调用方式,每个组件调用方式不同,组合时需要手动适配**:**
- 提示词渲染用.format()
- 模型调用用.generate()
- 解析器解析用.parse()
- 工具调用用.run()
代码会变成:
prompt_text = prompt.format(topic="猫") # 方法1
model_out = model.generate(prompt_text) # 方法2
result = parser.parse(model_out) # 方法3Runnable统一调用方式:
python
# 分步调用
prompt_text = prompt.invoke({"topic": "猫"}) # 方法1
model_out = model.invoke(prompt_text) # 方法2
result = parser.invoke(model_out) # 方法3
# LCEL管道式
chain = prompt | model | parser # 用管道符组合
result = chain.invoke({"topic": "猫"}) # 所有组件统一用invoke无论组件的功能多复杂(模型/提示词/工具),调用方式完全相同。并且可以通过管道符 | 组合,自动处理类型匹配和中间结果传递。
3.1.2 LCEL
LangChain 表达式语言(LCEL,LangChain Expression Language)是一种从现有的Runnable 构建新的 Runnable 的声明式方法,用于声明、组合和执行各种组件(模型、提示、工具、函数等)。
我们称使用 LCEL 创建的 Runnable 为"链","链"本身就是 Runnable。
LCEL 两个主要的组合原语是RunnableSequence 和 RunnableParallel。许多其他组合原语可以被认为是这两个原语的变体。
3.2 RunnableSequence 可运行序列
RunnableSequence 按顺序"链接"多个可运行对象,其中一个对象的输出作为下一个对象的输入。
LCEL重载了 | 运算符,以便从两个 Runnables 创建 RunnableSequence。
chain = runnable1 | runnable2
# 等同于
chain = RunnableSequence([runnable1, runnable2])举例:提示模板➡️模型➡️输出解析器
python
import os
from langchain.chat_models import init_chat_model
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt_template = PromptTemplate(
template="讲一个关于{topic}的笑话",
input_variables=["topic"],
)
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
parser = StrOutputParser()
chain = prompt_template | llm | parser
resp = chain.invoke({"topic": "人工智能"})
print(resp)3.3 RunnableParallel 可运行并行
RunnableParallel 同时运行多个可运行对象,并为每个对象提供相同的输入。
-
- 对于同步执行,RunnableParallel 使用 ThreadPoolExecutor 来同时运行可运行对象。
- 对于异步执行,RunnableParallel 使用 asyncio.gather 来同时运行可运行对象。
在LCEL 表达式中,字典会自动转换为 RunnableParallel。
举例:
python
import os
from langchain.chat_models import init_chat_model
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableParallel
from langchain_core.output_parsers import StrOutputParser
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
joke_chain = (
PromptTemplate.from_template("讲一个关于{topic}的笑话") | llm | StrOutputParser()
)
poem_chain = (
PromptTemplate.from_template("写一首关于{topic}的诗歌") | llm | StrOutputParser()
)
map_chain = RunnableParallel(joke=joke_chain, poem=poem_chain)
resp = map_chain.invoke({"topic": "人工智能"})
print(resp)3.4 RunnableLambda 可运行λ
RunnableLambda 将 Python 可调用函数转换为 Runnable,使得函数可以在同步或异步上下文中使用。
举例:
python
from langchain_core.runnables import RunnableLambda
chain = {
"text1": lambda x: x + " world",
"text2": lambda x: x + ", how are you",
} | RunnableLambda(lambda x: len(x["text1"]) + len(x["text2"]))
result = chain.invoke("hello")
print(result) # 29也可以通过装饰器来使用:
python
from langchain_core.runnables import RunnableLambda
@RunnableLambda
def total_len(x):
return len(x["text1"]) + len(x["text2"])
chain = {
"text1": lambda x: x + " world",
"text2": lambda x: x + ", how are you",
} | total_len
result = chain.invoke("hello")
print(result) # 293.5 RunnablePassthrough 可运行透传
RunnablePassthrough 接收输入并将其原样输出。RunnablePassthrough 是 LangChain LCEL 体系中的"无操作节点",用于在流水线中透传输入或保留上下文,也可以用于向输出中添加键。
举例:保留中间结果
python
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
chain = RunnableParallel(
original=RunnablePassthrough(), # 保留中间结果
word_count=lambda x: len(x),
)
result = chain.invoke("hello world")
print(result) # {'original': 'hello world', 'word_count': 11}举例:使用assign() 向输出中添加键
python
from langchain_core.runnables import RunnablePassthrough
chain = {
"text1": lambda x: x + " world",
"text2": lambda x: x + ", how are you",
} | RunnablePassthrough.assign(word_count=lambda x: len(x["text1"] + x["text2"]))
result = chain.invoke("hello")
print(result)
# {'text1': 'hello world', 'text2': 'hello, how are you', 'word_count': 29}3.6 RunnableBranch 可运行分支
RunnableBranch 使用 (条件,Runnable) 对列表和默认分支进行初始化。对输入进行操作时,选择第一个计算结果为 True 的条件,并在输入上运行相应的 Runnable。如果没有条件为 True,则在输入上运行默认分支。
举例:
python
from langchain_core.runnables import RunnableBranch
branch = RunnableBranch(
(lambda x: isinstance(x, str), lambda x: x.upper()),
(lambda x: isinstance(x, int), lambda x: x + 1),
(lambda x: isinstance(x, float), lambda x: x * 2),
lambda x: "goodbye",
)
result = branch.invoke("hello")
print(result) # HELLO
result = branch.invoke(None)
print(result) # goodbye3.7 RunnableWithFallbacks 可运行带回退
RunnableWithFallbacks 使得Runnable 失败后可以回退到其他 Runnable。可以直接在Runnable 上使用 with_fallbacks 方法。
举例:
python
import os
from langchain.chat_models import init_chat_model
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
chain = PromptTemplate.from_template("hello") | llm
chain_with_fallback = chain.with_fallbacks([RunnableLambda(lambda x: "sorry")])
result = chain_with_fallback.invoke("1") # 提示词模板中没有需要填充的变量,会报错
print(result) # sorry第 4 章 Retrieval
4.1 RAG介绍
4.1.1 大模型的局限
1) 知识滞后
LLM 因其具有海量参数,需要花费相当的物力与时间成本进行预训练和微调,同时商用 LLM 还需要进行各种安全测试与风险评估等。因此 LLM 会存在知识滞后的问题。
2) 知识缺失
在专有领域,LLM 无法学习到所有的专业知识细节,因此在面向专业领域知识的提问时,无法给出可靠准确的回答。
3) 幻觉
LLM 在生成回答时,可能会"胡言乱语",这种现象称之为 LLM 的"幻觉"。"幻觉"可以体现为错误陈述、编造事实、错误的复杂推理或者复杂语境下理解能力不足等。
"幻觉"产生的原因:
训练知识存在偏差,这些错误信息被LLM 学习后在输出中复现
- LLM 训练时过度泛化,将普通的模式应用在特定场合导致不准确输出
- LLM 本身没有真正学习到训练数据中深层次的含义,导致在一些需要深入理解或复杂推理的任务中出错
- LLM 缺乏某些领域的相关知识,在面临这些领域的相关问题时编造不存在的信息
- 大模型生成内容的不可控,尤其是在金融和医疗领域等领域,一次金额评估的错误,一次医疗诊断的失误,哪怕只出现一次都是致命的。但这些错误对于非专业人士来说难以辨识。目前还没有能够百分之百解决这种情况的方案。
4.1.2 什么是RAG
为了改善大模型在时效性、可靠性与准确性方面的不足,各种针对LLM 优化的方法应运而生。RAG(Retrieval-Augmented Generation,检索增强生成)就是其中一种被广泛研究和应用的优化架构。
RAG 的基本思想为:将传统的生成式大模型和实时信息检索技术相结合,为大模型补充来自外部的相关数据和上下文,来帮助大模型生成更加准确可靠的内容。这使得大模型在生成内容时可以依赖实时与个性化的数据和知识,而非仅仅依赖训练知识。就相当于在大模型回答时给它一本参考书。
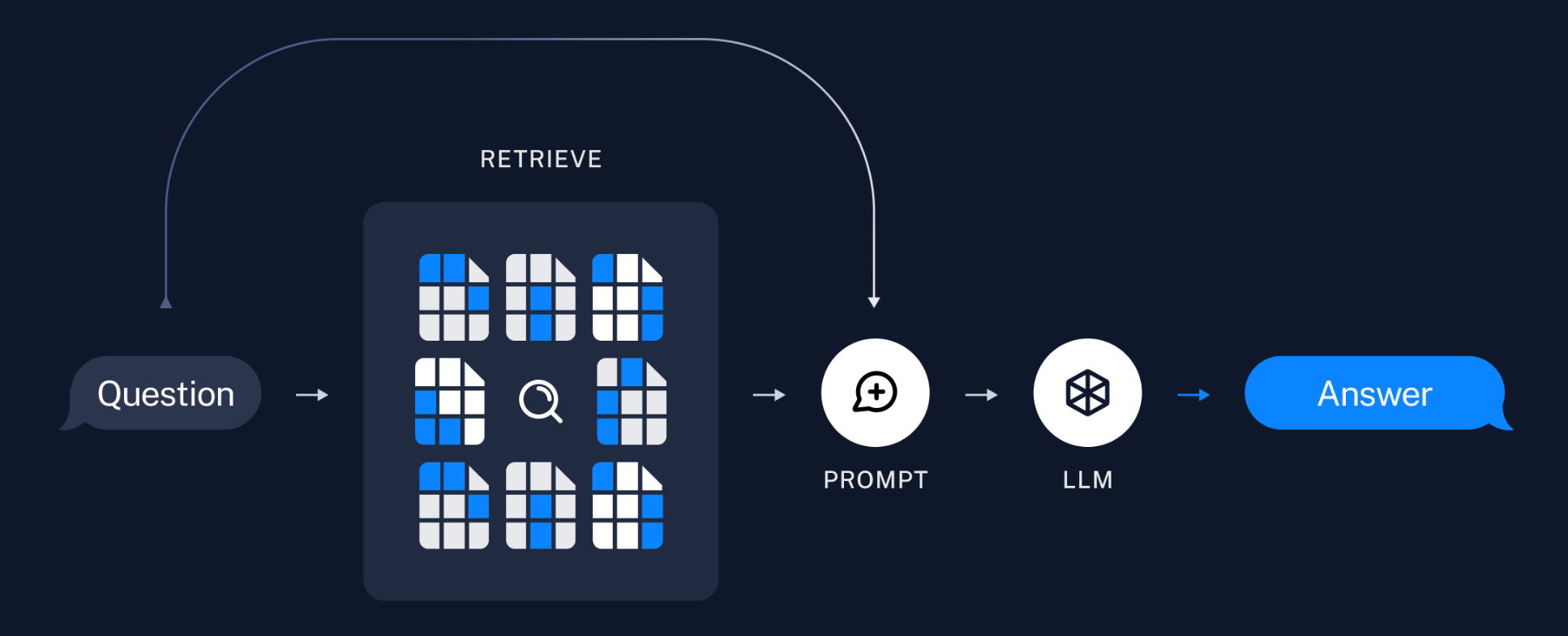
可以说,当应用需求集中在利用大模型去回答特定私有领域的知识,且知识库足够大时,那么除了微调大模型外,RAG 就是非常有效的一种解决方案。LangChain 对这一流程提供了解决方案。
4.1.3 RAG优缺点
1) RAG 的优点
- 相比提示词工程,RAG 有更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,就能生成比较符合用户预期的答案。
- 相比于模型微调,RAG 可以提升问答内容的时效性和可靠性。
- 在一定程度上保护了业务数据的隐私性。
2) RAG 的缺点
- 由于每次问答都涉及外部系统数据检索,因此RAG 的响应时延相对较高。
- 引用的外部知识数据会消耗大量的模型Token 资源。
4.1.4 RAG流程
典型的RAG有两个主要流程:
- 索引:从数据源提取数据,构建索引。
- 检索生成:接受用户查询并从索引中检索相关数据,然后将其传递给模型。。
索引阶段:
- 从各种数据源加载数据➡️
- 将文档切分为小块➡️
- 对文本块进行嵌入➡️
- 存储嵌入向量。
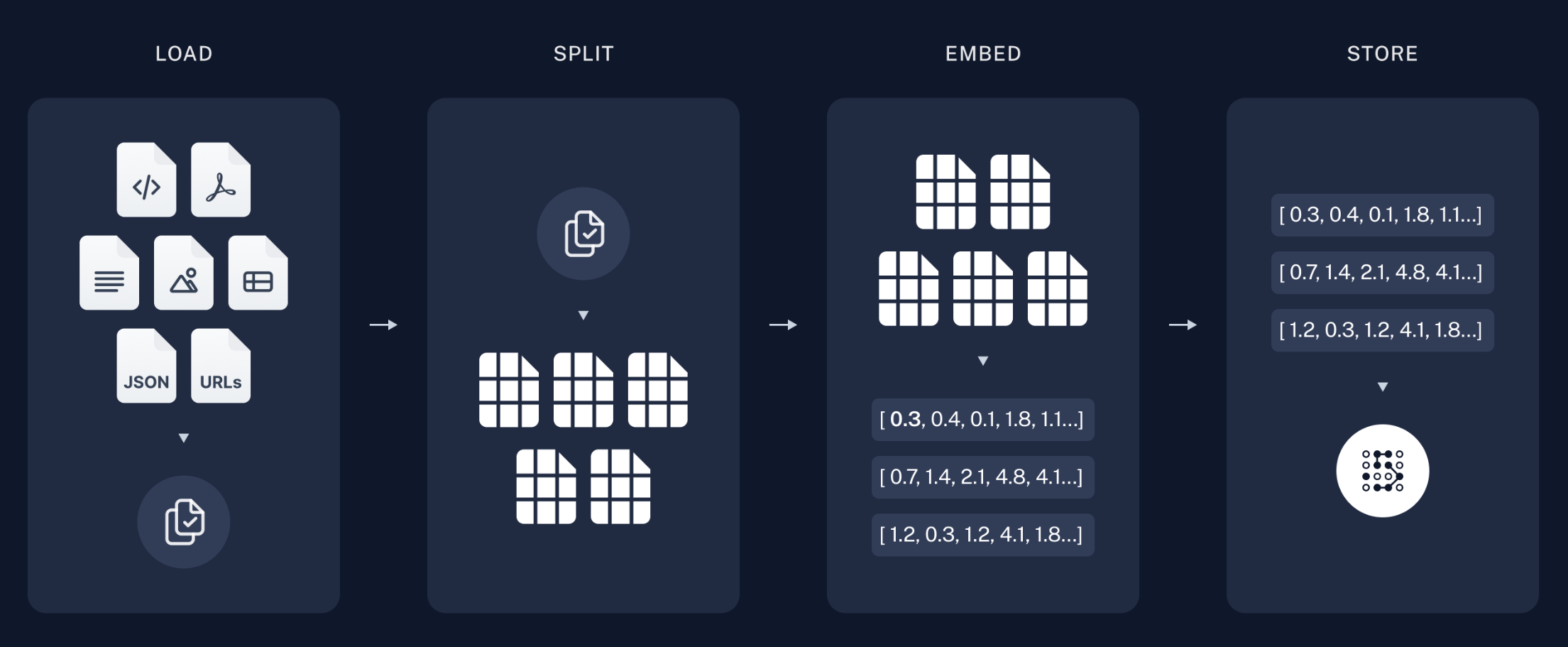
检索生成阶段:
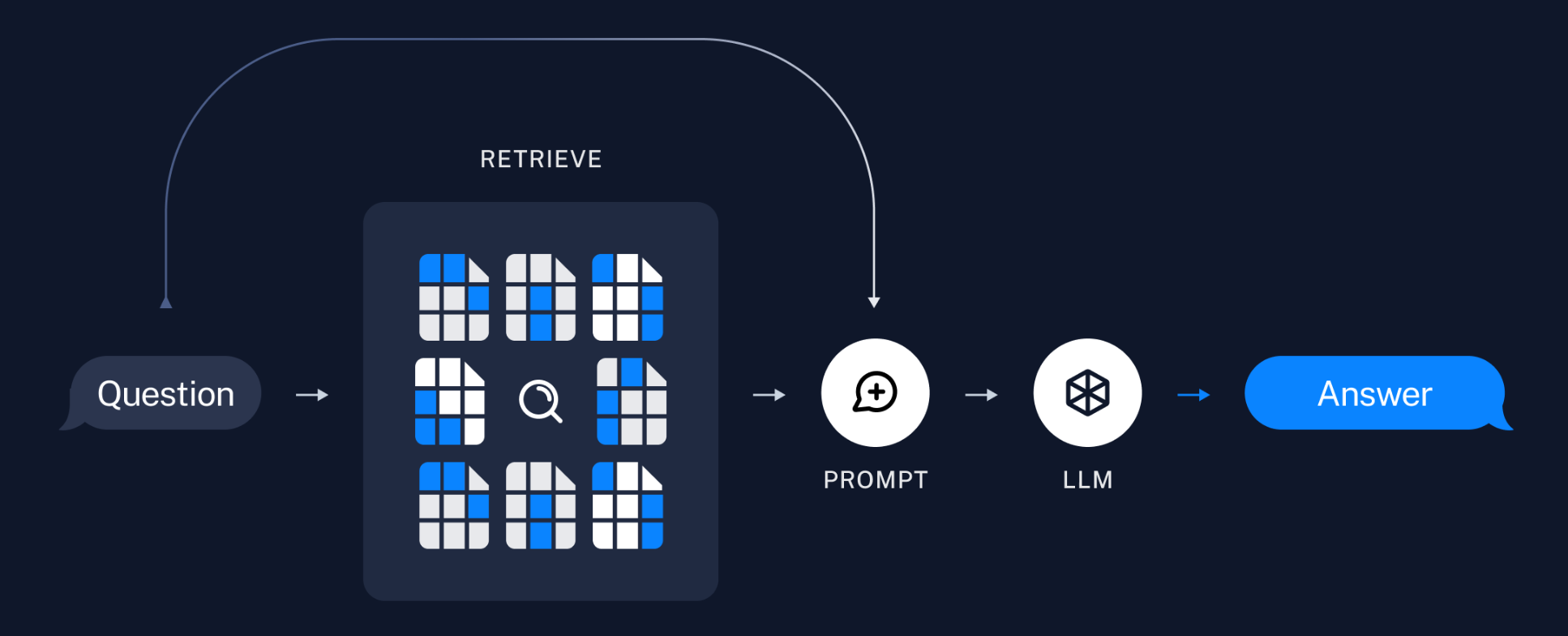
- 根据用户输入,使用检索器从存储中检索相关文本块➡️
- 大模型使用包含问题和检索结果的提示生成回答。
4.2 文档加载
数据源可能包含多种格式的文件,如文本文档、Markdown,PDF 等。因此我们首先需要对各种格式的文件进行处理。LangChain 实现和集成了众多文档加载器,方便从不同格式的文件中加载数据。可在 https://docs.langchain.com/oss/python/integrations/document_loaders 查看所有集成的文档加载器。
LangChain 所有文档加载器都实现了BaseLoader 接口,接口提供了通用的 load(一次加载所有文档) 与 lazy_load(以延迟方式加载文档)方法,用于从数据源加载数据并处理为Document 对象。
LangChain 实现了 Document 抽象,用于表示文本单元及其元数据,它包含三个属性:
- page_content:文本内容字符串。
- metadata:包含元数据的字典,如文档的来源等。
- id:可选,文档标识符。
4.2.1 加载TXT
python
# pip install langchain_community
from langchain_community.document_loaders import TextLoader
docs = TextLoader(
file_path="assets/sample.txt", # 文件路径
encoding="utf-8", # 文件编码方式
).load() # 返回List[Document]
print(docs)
# [Document(metadata={'source': 'asset/sample.txt'}, page_content='...')]4.2.2 加载CSV
python
# pip install langchain_community
from langchain_community.document_loaders.csv_loader import CSVLoader
# 加载所有列
docs = CSVLoader(
file_path="assets/sample.csv", # 文件路径
).load() # 返回List[Document]
print(docs)
# 加载部分列
docs = CSVLoader(
file_path="assets/sample.csv", # 文件路径
metadata_columns=["title", "author"], # 将指定列作为元数据
content_columns=["content"], # 将指定列作为内容
).load() # 返回List[Document]
print(docs)4.2.3 加载JSON
LangChain 实现了 JSONLoader,用来将 JSON 和 JSONL 数据转换为 LangChain 文档对象。它使用指定的 jq 模式来解析 JSON 文件,从而将特定字段提取到 LangChain 文档的内容和元数据中。
如果要从JSON Lines 文件加载文档,需传递 json_lines=True。
常见jq schema参考:
python
JSON -> [{"text": ...}, {"text": ...}, {"text": ...}]
jq_schema -> ".[].text"
JSON -> {"key": [{"text": ...}, {"text": ...}, {"text": ...}]}
jq_schema -> ".key[].text"
JSON -> ["...", "...", "..."]
jq_schema -> ".[]"详细用法可参考 https://jqlang.org/manual/#basic-filters
举例:提取所有字段
python
# pip install langchain_community jq
from langchain_community.document_loaders import JSONLoader
# 提取所有字段
docs = JSONLoader(
file_path="assets/sample.json", # 文件路径
jq_schema=".", # 提取所有字段
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)举例:提取指定字段中的内容
python
# pip install langchain_community jq
from langchain_community.document_loaders import JSONLoader
# 提取指定字段中的内容
docs = JSONLoader(
file_path="assets/sample.json", # 文件路径
jq_schema=".data.items[]", # 提取data.items中的数据
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)
docs = JSONLoader(
file_path="assets/sample.json", # 文件路径
jq_schema=".data.items[].content", # 提取data.items[].content中的数据
).load()
print(docs)
docs = JSONLoader(
file_path="assets/sample.json", # 文件路径
jq_schema="""
.data.items[] | {
author,
created_at,
content: (.title + "\n" + .content)
}
""", # 提取data.items中指定字段的数据
text_content=False, # 提取内容是否为字符串格式
).load()
print(docs)4.2.4 加载HTML 网页
python
# pip install langchain_community beautifulsoup4
import bs4
from langchain_community.document_loaders import WebBaseLoader
docs = WebBaseLoader(
# 网址序列
web_paths=("https://baike.baidu.com/item/%E5%BE%AE%E6%B3%A2%E7%82%89/84186",),
# 传给 BeautifulSoup 的解析参数,parse_only 表示只提取指定标签的元素
bs_kwargs={"parse_only": bs4.SoupStrainer(class_="J-lemma-content")},
).load()
print(docs)4.2.5 加载Markdown
可以使用Unstructured 文档加载器来加载多种类型的文件,关于如何在 LangChain 中使用 unstructured 生态系统,可参考这里。
可使用UnstructuredMarkdownLoader 加载 Markdown 文件,需要 unstructured 包。
python
# pip install langchain_community unstructured[md]
from langchain_community.document_loaders import UnstructuredMarkdownLoader
docs = UnstructuredMarkdownLoader(
# 文件路径
file_path="assets/sample.md",
# 加载模式:
# single 返回单个Document对象
# elements 按标题等元素切分文档
mode="elements",
).load()
print(docs)4.2.6 加载Doc/Docx
python
# pip install langchain_community unstructured[docx]
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
docs = UnstructuredWordDocumentLoader(
# 文件路径
file_path="assets/sample.docx",
# 加载模式:
# single 返回单个Document对象
# elements 按标题等元素切分文档
mode="single",
).load()
print(docs)4.2.7 加载PDF
PDF 存在多种来源格式,包括扫描版(图片 PDF)、电子文本版、混合版。并且布局格式也多种多样,包括单列布局、双列布局甚至竖排文本布局。并且包含段落、标题、页眉页脚、表格、数学公式、化学式、特殊符号、图片等各种元素。
因此,PDF 解析存在很多挑战。对于复杂 PDF,需要进行文本提取、布局检测、表格解析、公式识别等处理
1) PyPDFLoader
python
# pip install langchain_community
from langchain_community.document_loaders import PyPDFLoader
docs = PyPDFLoader(
# 文件路径,支持本地文件和在线文件链接,如"https://arxiv.org/pdf/alg-geom/9202012"
file_path="assets/sample.pdf",
# 提取模式:
# plain 提取文本
# layout 按布局提取
extraction_mode="plain",
).load()
print(docs)2) UnstructuredPDFLoader
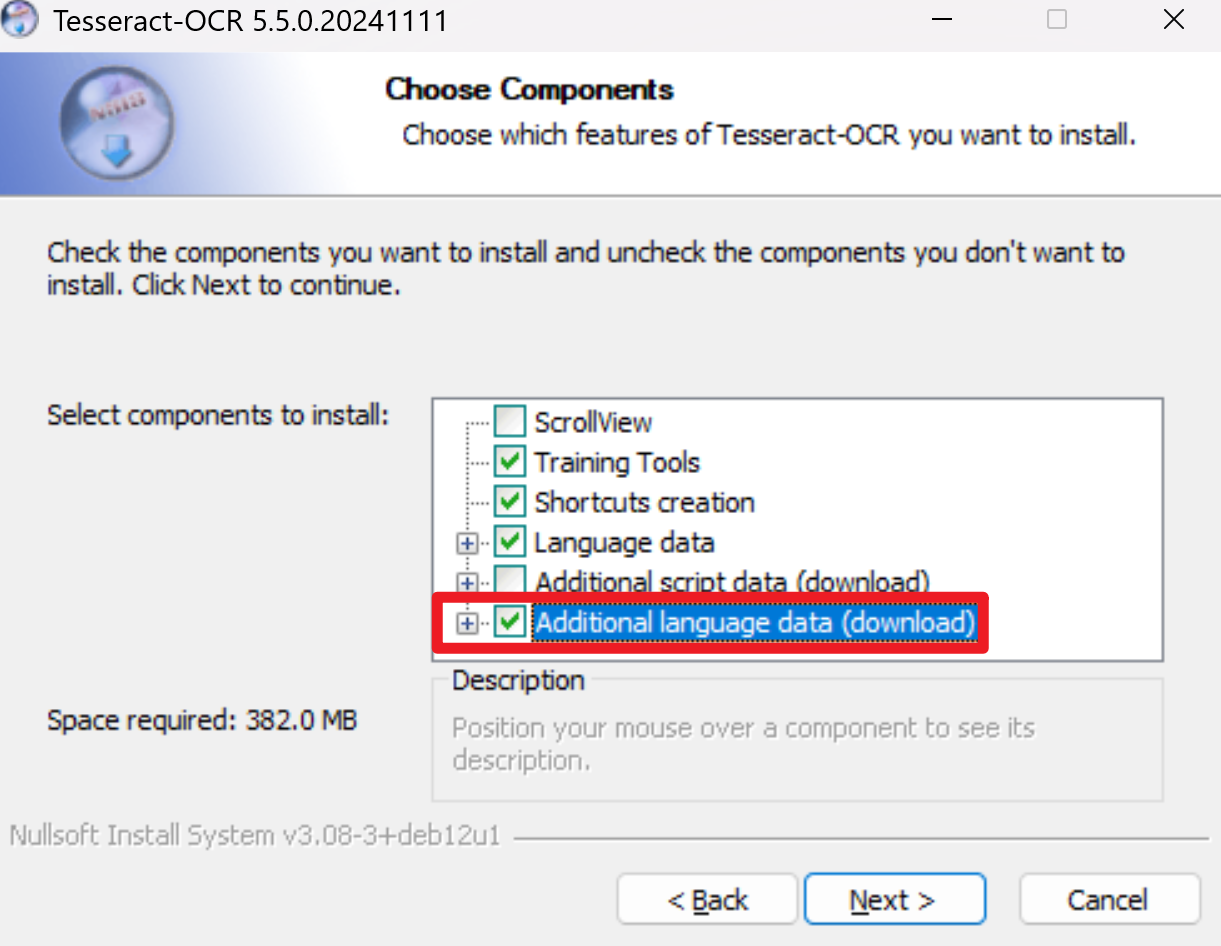
UnstructuredPDFLoader是对 unstructured 库的封装。支持布局识别与 OCR 提取文字。
使用UnstructuredPDFLoader,需要先下载Poppler 和Tesseract OCR。
Poppler 是一个开源的 PDF 文档处理库,用于渲染、解析和操作 PDF 文件。下载解压后将 .../poppler-24.08.0/Library/bin 添加到环境变量 Path 中即可。
Tesseract OCR 用于提取图片中的文字,在安装时需要选择Additional language data(download) 来添加中文语言包。
安装后,将安装时设置的安装目录添加到环境变量Path 中。
举例:
python
# pip install unstructured[local-inference]
from langchain_community.document_loaders import UnstructuredPDFLoader
docs = UnstructuredPDFLoader(
file_path="assets/sample.pdf", # 文件路径
# 加载模式:
# single: 返回单个Document对象
# elements: 按标题等元素切分文档
mode="elements",
# 加载策略:
# fast: pdfminer 提取并处理文本
# ocr_only: 转换为图片并进行 OCR
# hi_res: 识别文档布局,将OCR 输出与 pdfminer 输出融合
strategy="hi_res",
# 推断表格结构:仅 hi_res 下起效,如果为 True 则会在表格元素的元数据中添加 text_as_html
infer_table_structure=True,
# OCR 使用的语言: eng 英文,chi_sim 中文简体。语言列表参考 https://github.com/tesseract-ocr/langdata
languages=["eng", "chi_sim"],
# 更多参数详见 https://github.com/Unstructured-IO/unstructured/blob/main/unstructured/partition/pdf.py
).load()
print(docs)3) MinerU
MinerU 提供了PDF、Word、PPT、图片等文件的解析,支持图像提取、OCR、公式、表格解析等功能。
调用在线服务:https://mineru.net/apiManage/docs。可以从本地批量上传文件进行解析,并接收解析结果
python
import os
import requests
def upload_files(file_paths: list[str]) -> str:
"""批量上传文件"""
url = "https://mineru.net/api/v4/file-urls/batch"
api_key = os.getenv("MINERU_API_KEY")
header = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
files_info = [
{
"name": os.path.basename(file_path), # 文件名
"is_ocr": True, # 是否启用 ocr
"data_id": f"file_{i}", # 文件对应唯一标识 id
}
for i, file_path in enumerate(file_paths)
] # 动态生成文件信息
data = {
"enable_formula": True, # 是否开启公式识别
"enable_table": True, # 是否开启表格识别
"language": "ch", # 文档语言
"files": files_info,
}
try:
response = requests.post(url, headers=header, json=data)
if response.status_code == 200:
result = response.json()
print("response success. result:{}".format(result))
if result["code"] == 0:
batch_id = result["data"]["batch_id"]
urls = result["data"]["file_urls"]
print("batch_id:{}\nurls:{}".format(batch_id, urls))
for i in range(0, len(urls)):
with open(file_paths[i], "rb") as f:
res_upload = requests.put(urls[i], data=f)
if res_upload.status_code == 200:
print(f"{urls[i]} upload success")
else:
print(f"{urls[i]} upload failed")
return batch_id
else:
print("apply upload url failed,reason:{}".format(result.msg))
else:
print(
"response not success. status:{} ,result:{}".format(
response.status_code, response
)
)
except Exception as err:
print(err)
def download_files(batch_id):
"""批量获取任务结果"""
os.makedirs("parsed_files", exist_ok=True)
url = f"https://mineru.net/api/v4/extract-results/batch/{batch_id}"
api_key = os.getenv("MINERU_API_KEY")
header = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
res = requests.get(url, headers=header)
extract_results = res.json()["data"]["extract_result"]
failed_files = set() # 失败文件集合
done_files = set() # 完成文件集合
while True:
for result in extract_results:
if result["state"] == "failed":
failed_files.add(str(result))
elif result["state"] == "done":
done_files.add(str(result))
full_zip_url = result["full_zip_url"]
res_download = requests.get(full_zip_url, stream=True)
with open(
f"parsed_files/{result['file_name']}_{result['data_id']}.zip", "wb"
) as f:
for chunk in res_download.iter_content(chunk_size=1024):
f.write(chunk)
if len(failed_files) + len(done_files) == len(extract_results):
break
for i in failed_files:
print(i)
for i in done_files:
print(i)
file_paths = ["assets/sample.pdf"]
batch_id = upload_files(file_paths)
download_files(batch_id)4.3 文档切分
4.3.1 为什么切分
获取Document 对象后,需要将其切分成 Chunk。之所以要进行切分是出于以下考虑:
- 后续需要根据提问检索出相关的内容放入Prompt,如果答案出现在某一个 Document 对象中,那么将检索到的整个 Document 对象直接放入 Prompt 中并不是最优的选择,因为Document 可能包含非常多无关的信息,这些无效信息会干扰大模型的生成。
有研究发现,尽管大模型能够处理长文本输入,但它们在利用长上下文方面存在显著不足。尤其是在多文档问答和键值检索等任务中,当相关信息位于输入文本的中间时,模型的性能显著下降。这种现象表明,当前的语言模型在长输入上下文中未能充分利用信息,尤其是位于中间部分的信息。
- 大模型存在最大输入的Token 限制,如果一个Document 非常大,在输入大模型时会被截断,导致信息缺失。
基于此,一个方法是将完整的Document 进行分块处理(Chunking),将 Document 切分为一个个小块(Chunk)。无论是在存储还是检索过程中,都将以这些块为基本单位,这样能有效地避免内容噪声干扰和超出最大Token 的问题。
4.3.2 切分策略
- 按照固定字符数或Token 数来切分,但可能会在不适当的位置切断句子。
- 递归使用多个分隔符切分,同时尽量保证字符数或Token 数不超出限制。能保证不切断完整的句子。
- 语义切分:根据文本的语义内容切分,旨在保持相关信息的集中和完整,适用于需要高度语义保持的场景。但处理速度较慢,且可能出现不同块之间长度极不均衡的情况。具体切分过程为:将相邻的几个句子拼成一个句组。对所有句组进行嵌入,并比较嵌入向量的距离,找到语义变化大的位置,根据阈值确定切分点(比如计算相邻句子嵌入向量的余弦距离,取距离分布的第N 百分位值作为阈值,高于此值则切分)。按照切分点切分出若干个语义段,并合并某些长度很短的语义段。
4.3.3 RecursiveCharacterTextSplitter
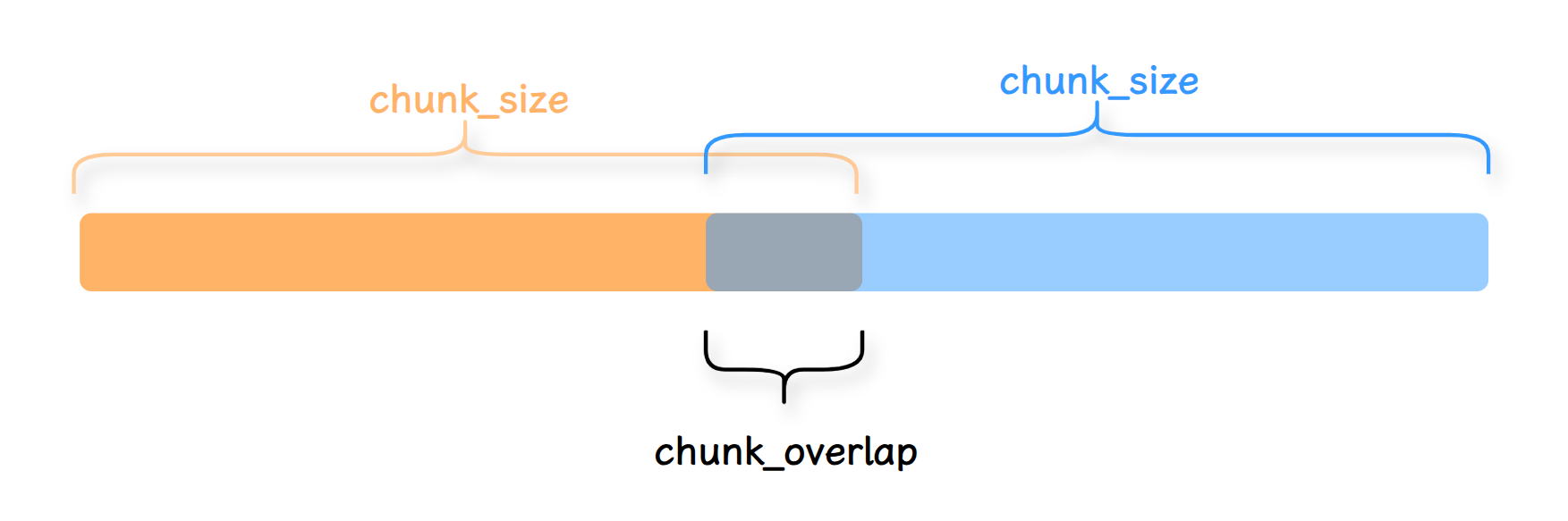
RecursiveCharacterTextSplitte(递归字符文本切分器)是最常用的切分器,它由一个字符列表作为参数,默认列表为 "\\n\\n", "\\n", " ", "",并且会尝试按顺序使用这些字符进行切分,直到块足够小。由此尽可能地将所有段落(然后是句子,最后是词)保持在一起,因为这些段落通常看起来是语义上最相关的文本片段。
同时为了保证段之间语义完整,可以设置每个块之间有一部分重叠。
举例:
python
# pip install langchain-text-splitters
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 加载文档
docs = UnstructuredWordDocumentLoader(
file_path="assets/sample.docx", mode="single"
).load()
# 切分为文本块
chunks = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", "......", ",", ""], # 分隔符列表
chunk_size=400, # 每个块的最大长度
chunk_overlap=50, # 每个块重叠的长度
length_function=len, # 可选:计算文本长度的函数,默认为字符串长度,可自定义函数来实现按 token 数切分
add_start_index=True, # 可选:块的元数据中添加此块起始索引
).split_documents(docs)
print(chunks)4.4 文档嵌入
使用嵌入模型生成文档的嵌入向量,后续检索时用于与查询的嵌入向量进行相似度计算。
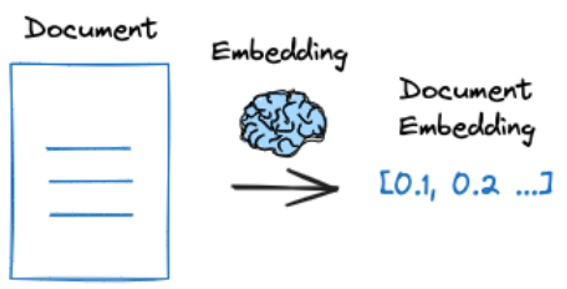
2018年谷歌推出的 BERT 能够将文本嵌入为简单的向量表示,但是 BERT 并未针对有效生成句子嵌入进行优化,由此促使了 Sentence-BERT 的诞生。Sentence-BERT 调整了 BERT 的架构以及预训练任务以生成包含语义的句子嵌入向量,这些嵌入向量可以通过余弦相似度等相似性指标轻松进行比较,大大降低了查找相似句子等任务的计算开销。
常用嵌入模型:
|---------------------------------|---------------|--------------------------|
| 模型 | 机构 | 描述 |
| bge-large-zh | 北京智源研究院(BAAI) | 开源,向量维度1024,序列长度512 |
| bge-base-zh | BAAI | 开源,向量维度768,序列长度512 |
| bge-small-zh | BAAI | 开源,向量维度512,序列长度512 |
| bge-m3 | BAAI | 开源,多语言,向量维度1024,序列长度8192 |
| text-embedding-3-small | OpenAI | 多语言,向量维度1536,序列长度8192 |
| text-embedding-3- large | OpenAI | 多语言,向量维度3072,序列长度8192 |
举例:
python
# pip install sentence-transformers langchain_huggingface
import os
from langchain_huggingface import HuggingFaceEmbeddings
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# 单文本嵌入
query = "你好,世界"
print(embed_model.embed_query(query))
# 多文本嵌入
docs = ["你好,世界", "你好,世界"]
print(embed_model.embed_documents(docs))4.5 向量存储
4.5.1 向量数据库的理解
假设你是一名摄影师,拍了大量的照片。为了方便管理和查找,你决定将这些照片存储到一个数据库中。传统的关系型数据库(如 MySQL、PostgreSQL 等)可以帮助你存储照片的元数据,比如拍摄时间、地点、相机型号等。
但是,当你想要根据照片的内容(如颜色、纹理、物体等)进行搜索时,传统数据库可能无法满足你的需求,因为它们通常以数据表的形式存储数据,并使用查询语句进行精确搜索。那么此时,向量数据库就可以派上用场。
我们可以构建一个多维的空间使得每张照片特征都存在于这个空间内,并用已有的维度进行表示,比如时间、地点、相机型号、颜色....此照片的信息将作为一个点,存储于其中。以此类推,即可在该空间中构建出无数的点,而后我们将这些点与空间坐标轴的原点相连接,就成为了一条条向量,当这些点变为向量之后,即可利用向量的计算进一步获取更多的信息。当要进行照片的检索时,也会变得更容易更快捷。
注意,在向量数据库中进行检索时,并不是检索唯一的匹配结果,而是查询和目标向量最为相似的一些向量,具有模糊性。
延伸思考一下,只要对图片、视频、商品等素材进行向量化,就可以实现以图搜图、视频相关推荐、相似商品推荐等功能。
4.5.2 常用的向量数据库
LangChain提供了众多向量存储的集成,包括开源的本地向量存储与云托管的私有向量存储。并公开了一个标准接口,可以轻松地在向量存储之间进行交换。
常用向量数据库:
|-------------------|-------------------------------------------------------|
| 向量数据库 | 描述 |
| FAISS | 一个用于高效相似性搜索和密集向量聚类的库 |
| Chroma | 开源的轻量级向量数据库,有极简的API |
| Milvus | 开源的专为向量搜索设计的云原生数据库。性能强悍,功能丰富。覆盖轻量级的原型开发到十亿级向量的大规模生产系统 |
| Pgvector | 开源关系型数据库PostgreSQL 的扩展,为PostgreSQL增加了向量数据类型和相似性搜索功能 |
| Redis | 开源内存数据结构存储,现已原生支持向量相似性搜索功能 |
| Elasticsearch | 开源分布式搜索和分析引擎,提供了一个基于文档的数据库,结构化、非结构化和向量数据通过高效的列式存储统一管理 |
这里我们使用Milvus 作为向量存储。
4.5.3 Milvus 介绍
Milvus 通过 数据库---Collections---实体 的结构管理数据。Collections 和实体就类似关系型数据库中的表和记录。具体来说,Collection 是一个二维表,具有固定的列和变化的行。每列代表一个字段,每行代表一个实体。

Collection 通过 Collection Schema 来定义有哪些字段以及字段的类型、索引等。一个Collection Schema 有一个主键、最多四个向量字段和若干标量字段。
主键用于唯一标识一个实体,只接受 Int64 或 VarChar 值。插入实体时,默认情况下应包含主键值。但是,如果在创建Collections 时启用了 AutoId,Milvus 将在插入数据时生成主键值,此时插入的实体中不应包含主键值。
向量字段用于存储文本、图像和音频等非结构化数据类型的嵌入,可以是密集向量、稀疏向量或二进制向量。通常,密集向量用于语义搜索,而稀疏向量则更适合全文或词性匹配。
标量字段通常用来存储一些元数据,并可以在搜索时通过元数据进行过滤,以提高搜索结果的正确性。
|----------|-------|---------------------|---------------------------------|
| 字段类型 || 字段 | 描述 |
| 向量字段 | 密集向量 | FLOAT_VECTOR | 32位浮点数列表 |
| 向量字段 | 密集向量 | FLOAT16_VECTOR | 16位半精度浮点数列表 |
| 向量字段 | 密集向量 | BFLOAT16_VECTOR | 16位浮点数列表,精度稍低,但指数范围与 Float32 相同 |
| 向量字段 | 密集向量 | INT8_VECTOR | 8位有符号整数向量 |
| 向量字段 | 稀疏向量 | SPARSE_FLOAT_VECTOR | 非零数字及其序列号列表 |
| 向量字段 | 二进制向量 | BINARY_VECTOR | 一个0和1的列表 |
| 标量字段 || VARCHAR | 字符串 |
| 标量字段 || BOOL | 存储true或false |
| 标量字段 || INT | INT8、INT16、INT32、INT64 |
| 标量字段 || FLOAT | 32位浮点数 |
| 标量字段 || DOUBLE | 64位双精度浮点数 |
| 标量字段 || ARRAY | 相同数据类型元素的有序集合 |
| 标量字段 || JSON | 结构化的键值数据 |
索引是建立在数据之上的附加结构,可以加快搜索速度。不同字段数据类型适用不同的索引类型。比如FLOAT_VECTOR 可使用HNSW(分层导航小世界)索引,VARCHAR 可使用 INVERTED(反转)索引 。详见https://milvus.io/docs/index-explained.md。
Milvus 提供了多个版本以在不同场景下选择合适的使用方式:
- Milvus Lite:本地轻量化运行,通过
pip install pymilvus[milvus-lite]即可安装。但Milvus Lite 有一些限制,比如 Milvus Lite 仅支持 FLAT 索引类型。无论在 Collections 中指定了哪种索引类型,它都使用 FLAT 类型。 - Milvus Standalone:单点部署,支持通过Docker 部署。
- Milvus Distributed:分布式部署,支持在 Kubernetes 集群上部署。
4.5.4 创建Collection
python
# pip install pymilvus[milvus_lite]
from pprint import pprint
from pymilvus import MilvusClient, DataType
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 创建 schema
def build_schema():
return (
MilvusClient.create_schema(
# 自动分配主键
auto_id=True,
# 启用动态字段,未在 Schema 中声明的字段会以键值对的形式存储在这个动态字段
enable_dynamic_field=True,
)
# 添加 id 字段,类型为整数,设置为主键
.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
# 添加 vector 字段,类型为浮点数向量,维度为 768
.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=768)
# 添加 text 字段,类型为字符串,最大长度为 1024
.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1024)
# 添加 metadata 字段,类型为 JSON
.add_field(field_name="metadata", datatype=DataType.JSON)
)
# 创建 index
def build_index():
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="vector", # 建立索引的字段
index_type="AUTOINDEX", # 索引类型
metric_type="L2", # 向量相似度度量方式
)
return index_params
# 创建 collection
if client.has_collection(collection_name="demo_collection"):
# 删除 collection
# 在 Milvus 中删除数据后,存储空间不会立即释放。虽然删除数据会将实体标记为 "逻辑删除",但实际空间可能不会立即释放。
# Milvus 会在后台自动压缩数据。这个过程会将较小的数据段合并为较大的数据段,并删除"逻辑删除"的数据或已超过有效时间的数据。
# 一个名为 Garbage Collection (GC) 的独立进程会定期删除这些 "已删除 "的数据段,从而释放它们占用的存储空间。
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection", # collection 名称
schema=build_schema(), # collection 的 schema
index_params=build_index(), # collection 的 index
)
# 查看 collection
print(client.list_collections())
# 查看 collection 描述
pprint(client.describe_collection(collection_name="demo_collection"))4.5.5 操作实体
4.5.5.1 插入实体
python
import os
from pymilvus import MilvusClient
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 加载文档
docs = UnstructuredWordDocumentLoader(
file_path="assets/sample.docx",
mode="single",
).load()
# 文档切分
chunks = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", "......", ",", ""],
chunk_size=400,
chunk_overlap=50,
).split_documents(docs)
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# 计算嵌入向量
embeddings = embed_model.embed_documents([chunk.page_content for chunk in chunks])
# 转换数据格式
data = [
{
"vector": embedding,
"text": chunk.page_content,
"metadata": chunk.metadata,
}
for chunk, embedding in zip(chunks, embeddings)
]
# 插入实体
res = client.insert(collection_name="demo_collection", data=data)
print(res)4.5.5.2 查询实体
python
from pymilvus import MilvusClient
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 通过主键查询实体
res = client.get(
collection_name="demo_collection",
ids=[461484610130804912, 461484610130804913],
output_fields=["text", "metadata"],
)
print(res)
# 通过过滤条件(https://milvus.io/docs/zh/boolean.md)查询实体
res = client.query(
collection_name="demo_collection",
filter='metadata["source"] == "assets/sample.docx"', # 使用 metadata["source"] 进行过滤
output_fields=["text", "metadata"],
limit=1,
)
print(res)4.5.5.3 删除实体
python
from pymilvus import MilvusClient
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 通过主键删除实体
res = client.delete(
collection_name="demo_collection",
ids=[461484610130804912, 461484610130804913],
)
print(res)
# 通过过滤条件(https://milvus.io/docs/zh/boolean.md)删除实体
res = client.delete(
collection_name="demo_collection",
filter='text LIKE "第%"', # 使用 text 前缀过滤
)
print(res)4.6 检索与生成
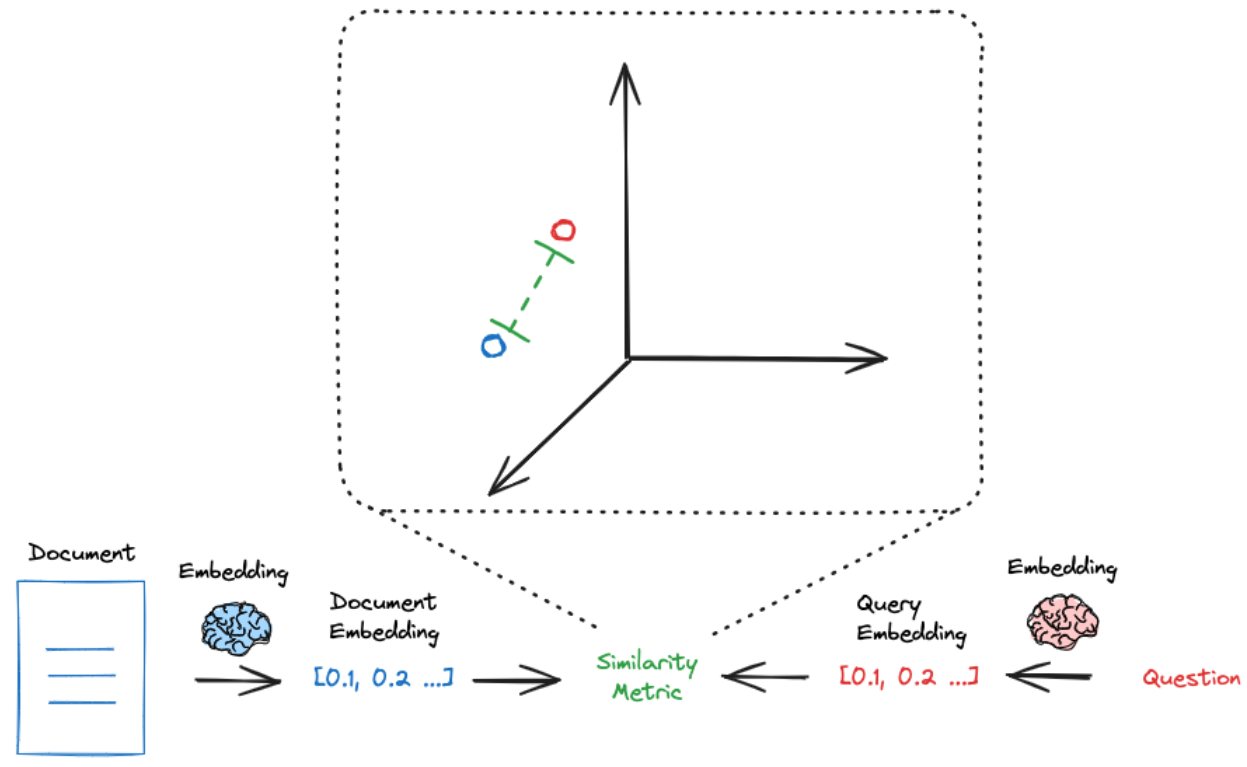
4.6.1 检索
检索阶段:用户输入查询➡️计算嵌入向量➡️在向量存储中检索相似向量➡️返回相似向量对应的内容。
举例:检索过程
python
import os
from pymilvus import MilvusClient, DataType
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# ========== 构建索引 ==========
# 创建 schema
def build_schema():
return (
MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=768)
.add_field(field_name="text", datatype=DataType.VARCHAR, max_length=1024)
.add_field(field_name="metadata", datatype=DataType.JSON)
)
# 创建 index
def build_index():
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="vector", # 建立索引的字段
index_type="AUTOINDEX", # 索引类型
metric_type="L2", # 向量相似度度量方式
)
return index_params
# 创建 collection
if client.has_collection(collection_name="demo_collection"):
client.drop_collection(collection_name="demo_collection")
client.create_collection(
collection_name="demo_collection", # collection 名称
schema=build_schema(), # collection 的 schema
index_params=build_index(), # collection 的 index
)
# 加载文档
docs = UnstructuredWordDocumentLoader(
file_path="assets/sample.docx",
mode="single",
).load()
# 文档切分
chunks = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", "!", "?", "......", ",", ""],
chunk_size=400,
chunk_overlap=50,
).split_documents(docs)
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# 计算嵌入向量
embeddings = embed_model.embed_documents([chunk.page_content for chunk in chunks])
# 转换数据格式
data = [
{
"vector": embedding,
"text": chunk.page_content,
"metadata": chunk.metadata,
}
for chunk, embedding in zip(chunks, embeddings)
]
# 插入实体
res = client.insert(collection_name="demo_collection", data=data)
# ========== 检索 ==========
def retrieval(query, embed_model, client):
"""检索并返回上下文"""
query_embedding = embed_model.embed_query(query) # 查询嵌入
context = client.search(
collection_name="demo_collection", # collection 名称
data=[query_embedding], # 搜索的向量
anns_field="vector", # 进行向量搜索的字段
# 度量方式:L2 欧氏距离/IP 内积/COSINE 余弦相似度
search_params={"metric_type": "L2"},
output_fields=["text", "metadata"], # 输出字段
limit=3, # 搜索结果数量
)
return context
context = retrieval("不动产被占有了怎么办?", embed_model, client)
print(context)向量相似性搜索算法:
ANN(近似近邻)和KNN(最近邻)搜索是向量相似性搜索的常用方法。
在 KNN 搜索中,必须将向量空间中的所有向量与搜索请求中携带的查询向量进行比较,然后找出最相似的向量,费时费力。
而ANN 搜索算法要求提供一个索引文件,记录向量 Embeddings 的排序顺序。当收到搜索请求时,使用索引文件作为参考,找到可能包含与查询向量最相似的向量嵌入的子组,根据指定的度量类型来测量查询向量与子组中的向量之间的相似度,根据与查询向量的相似度对组成员进行排序,并返回前 K 个成员。不过 ANN 搜索依赖于预建索引,搜索吞吐量、内存使用量和搜索正确性可能会因选择的索引类型而不同。
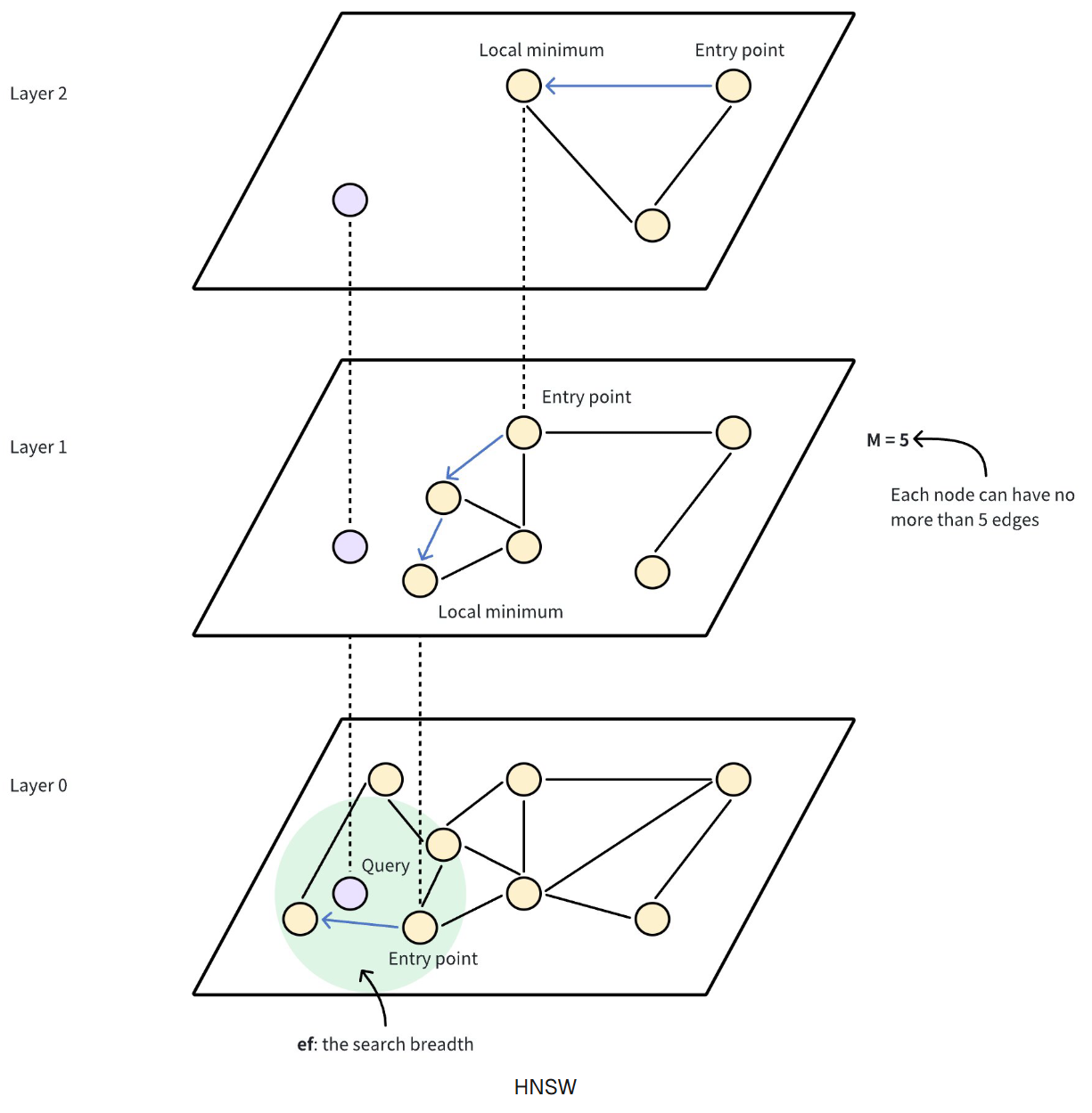
HNSW (分层导航小世界)是当下常用的一种基于图的索引算法,可以提高搜索高维浮点数向量时的性能。它具有出色的搜索精度和低延迟,但需要较高的内存开销来维护其分层图结构。该算法构建了一个多层图(类似不同缩放级别的地图),底层包含所有数据点,而上层则由从底层采样的数据点子集组成。在这种层次结构中,每一层都包含代表数据点的节点,节点之间由表示其接近程度的边连接。上层提供远距离跳转,以快速接近目标,而下层则进行细粒度搜索,以获得最准确的结果。其工作原理如下:
- 入口点:搜索从顶层的一个固定入口点开始,该入口点是图中的一个预定节点。
- 贪婪搜索:算法贪婪地移动到当前层的近邻,直到无法再接近查询向量为止。上层起到导航作用,作为粗过滤器,为下层的精细搜索找到潜在的入口点。
- 层层下降:一旦当前层达到局部最小值,算法就会利用预先建立的连接跳转到下层,并重复贪婪搜索。
- 最后细化:这一过程一直持续到最底层,在最底层进行最后的细化步骤,找出最近的邻居。
4.6.2 生成
python
import os
from pymilvus import MilvusClient
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# 实例化向量数据库客户端
client = MilvusClient(
uri="./milvus_demo.db", # 数据存储在本地当前目录下
)
# 加载嵌入模型
embed_model = HuggingFaceEmbeddings(
model_name=os.path.expanduser("~/models/bge-base-zh-v1.5")
)
# ========== 检索 ==========
def retrieval(query, embed_model, client):
"""检索并返回上下文"""
query_embedding = embed_model.embed_query(query) # 查询嵌入
context = client.search(
collection_name="demo_collection", # collection 名称
data=[query_embedding], # 搜索的向量
anns_field="vector", # 进行向量搜索的字段
# 度量方式:L2 欧氏距离/IP 内积/COSINE 余弦相似度
search_params={"metric_type": "L2"},
output_fields=["text", "metadata"], # 输出字段
limit=3, # 搜索结果数量
)
return context
# ========== 生成 ==========
llm = init_chat_model(
model="openai/gpt-oss-20b:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
template = ChatPromptTemplate.from_messages(
[
(
"system",
"# 任务\n\n根据上下文参考,回答用户的问题。\n\n# 上下文参考\n\n{context}",
),
("human", "{query}"),
]
)
rag_chain = (
{
"query": RunnablePassthrough(),
"context": lambda x: retrieval(query=x, embed_model=embed_model, client=client),
}
| RunnableLambda(lambda x: print(x) or x) # 打印中间结果
| template
| llm
| StrOutputParser()
)
res_chunks = rag_chain.stream(input="不动产被占有了怎么办?")
for chunk in res_chunks:
print(chunk, end="", flush=True)第 5 章 Agents
5.1 Agent 介绍
通用人工智能(AGI)将是 AI 的终极形态,几乎已成为业界共识。同样,构建 Agent则是 AI 工程应用当下的"终极形态"。
将 AI 和人类协作的程度类比自动驾驶的不同阶段:
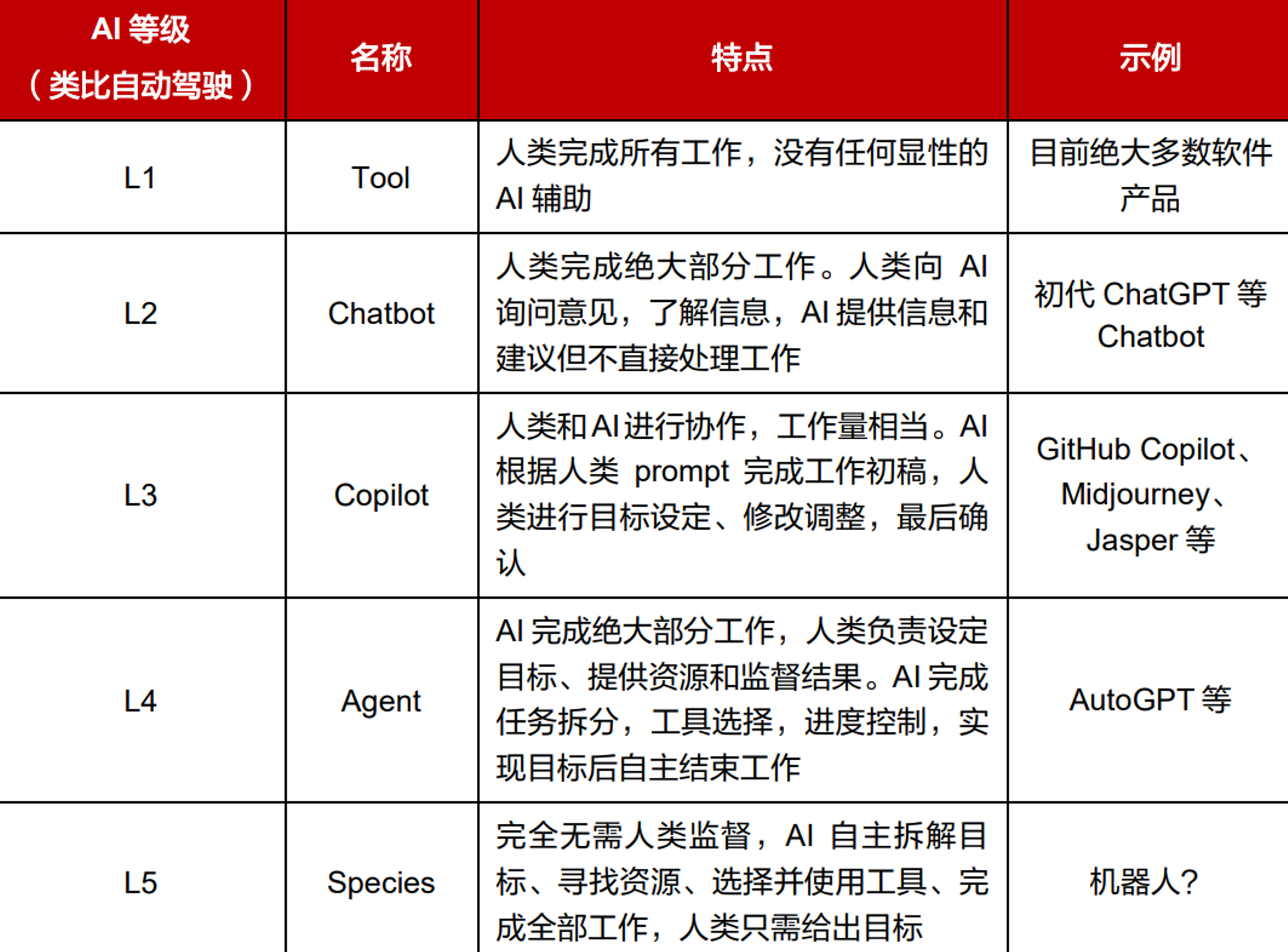
语言模型本身无法采取行动------它们只是输出文本。LangChain 的一个重要功能是创建Agent。Agent 是一种使用 LLM 作为推理引擎的系统,它决定要采取哪些行动以及这些行动的输入应该是什么。这些行动的结果可以反馈给 Agent,由 Agent 决定是否需要采取更多行动,或者是否可以完成。
与传统的固定流程链不同,Agent 具备一定的自主决策能力,更适合处理开放式、多步骤的问题。它可以拆解任务,根据任务动态决定调用哪些工具,并利用中间结果推进任务。
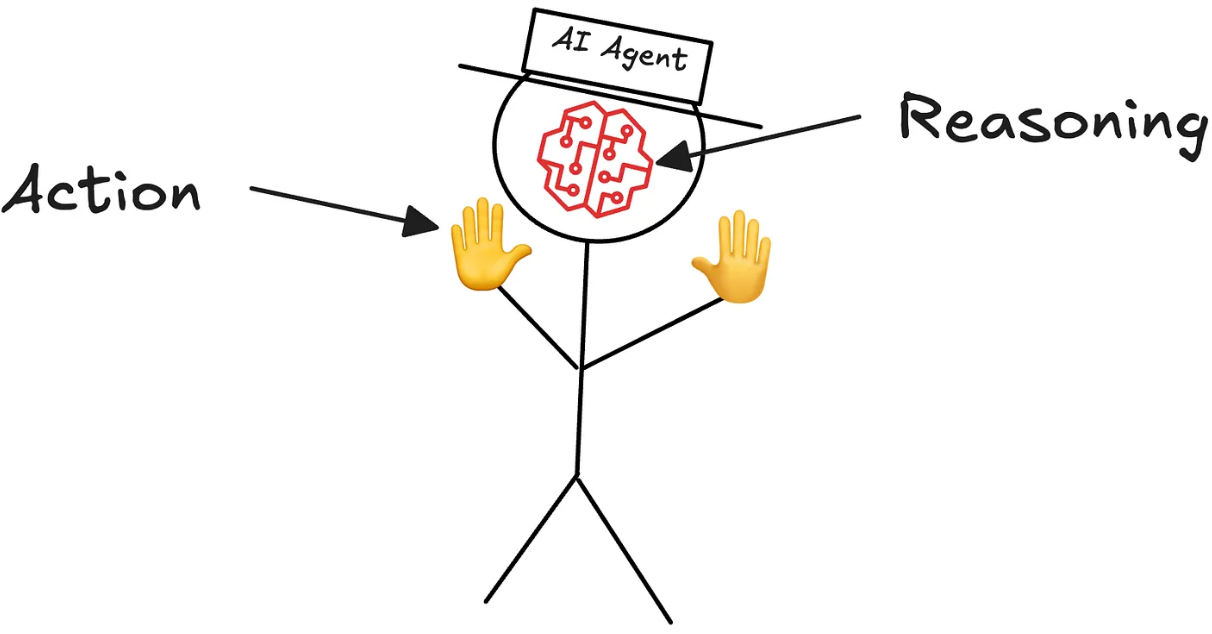
Agent 的核心能力/组件:
(1)大模型(LLM):作为大脑,提供推理、规划和知识理解能力。
(2)记忆(Memory):具备短期记忆和长期记忆,支持快速知识检索。
(3)工具(Tools):调用外部工具(如API、数据库)的执行单元。
(4)规划(Planning):任务分解、反思与自省框架实现复杂任务处理。
(5)行动(Action):实际执行决策的能力。
(6)协作:通过与其他Agent 交互合作,完成更复杂的任务目标。
5.2 Tools
5.2.1 Tools 介绍
要构建更强大的AI 工程应用,只有生成文本这样的"纸上谈兵"能力自然是不够的,借助工具,才能让 AI 应用的能力真正具备无限的可能。
工具封装了一个可调用函数及其输入模式。这些参数可以传递给兼容的聊天模型,从而允许模型决定是否调用工具以及调用哪些参数。在这种情况下,工具调用使模型能够生成符合指定输入模式的请求。
5.2.2 创建工具
一个Tool 通常包括工具名称,工具描述,以及工具参数的类型注解。
可以通过@tool 装饰器来创建工具。
举例:通过@tool 创建工具
python
from langchain.tools import tool
@tool
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b
print(f"{add_number.name=}\n{add_number.description=}\n{add_number.args=}")
# add_number.name='add_number'
# add_number.description='两个整数相加'
# add_number.args={'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}举例:通过@tool 的参数修改属性
python
from langchain.tools import tool
from pydantic import BaseModel, Field
class FieldInfo(BaseModel):
a: int = Field(description="第1个参数")
b: int = Field(description="第2个参数")
@tool(
name_or_callable="add_2_number",
description="计算两整数之和",
args_schema=FieldInfo, # 定义参数模式
)
def add_number(a: int, b: int) -> int:
"""两个整数相加"""
return a + b
print(f"{add_number.name=}\n{add_number.description=}\n{add_number.args=}")
# add_number.name='add_2_number'
# add_number.description='计算两整数之和'
# add_number.args={'a': {'description': '第1个参数', 'title': 'A', 'type': 'integer'}, 'b': {'description': '第2个参数', 'title': 'B', 'type': 'integer'}}5.2.3 绑定工具
要想让大模型能够使用工具,首先需要将工具给到大模型。
创建模型实例,并通过bind_tools 方法将工具绑定到大模型。
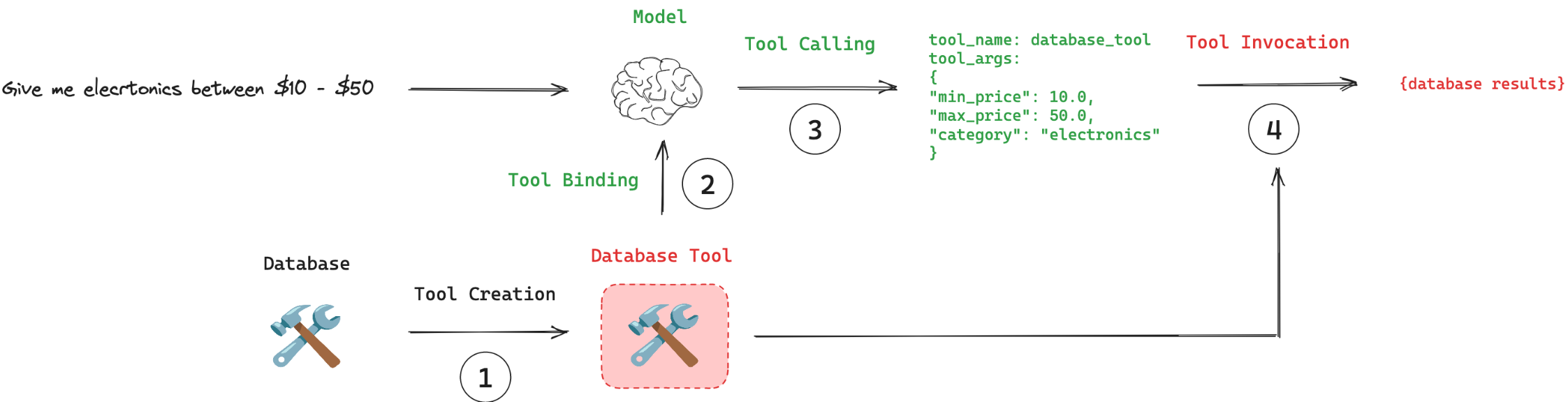
(1)大模型通过分析用户需求,判断是否需要调用工具。
(2)如果需要则在响应的additional_kwargs 参数中包含工具调用的详细信息。
(3)使用模型提供的参数执行工具。
python
import os
from langchain.tools import tool
from langchain.chat_models import init_chat_model
@tool
def query_user_info(user_id: int) -> str:
"""查询用户信息"""
return {1001: "Jack", 1002: "Tom", 1003: "Alice"}[user_id]
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 为模型提供工具
tools = [query_user_info]
llm_with_tools = llm.bind_tools(tools)
resp = llm_with_tools.invoke("帮我查下1001用户的信息")
print(resp)
# content='\n\n我来帮您查询1001用户的信息。\n'
# additional_kwargs={'tool_calls': [{'id': '...', 'function': {'arguments': '{"user_id": 1001}', 'name': 'query_user_info'}
# 返回的响应中 additional_kwargs 参数中包括了工具调用的信息,此时还没有调用工具,只是返回了要调用的工具及参数
# 手动执行工具
for tool_call in resp.tool_calls:
tool_name = tool_call["name"] # 获取工具名称
tool_args = tool_call["args"] # 获取工具参数
tool_result = globals()[tool_name].invoke(tool_args) # 执行工具
print(tool_name, tool_args, tool_result)5.3 构建Agent
使用create_agent 来创建 Agent,create_agent 使用 LangGraph 构建基于图的 Agent运行时。此 Agent 会在一个循环中反复调用模型和工具,直到某次模型输出中不再包含工具调用则结束。
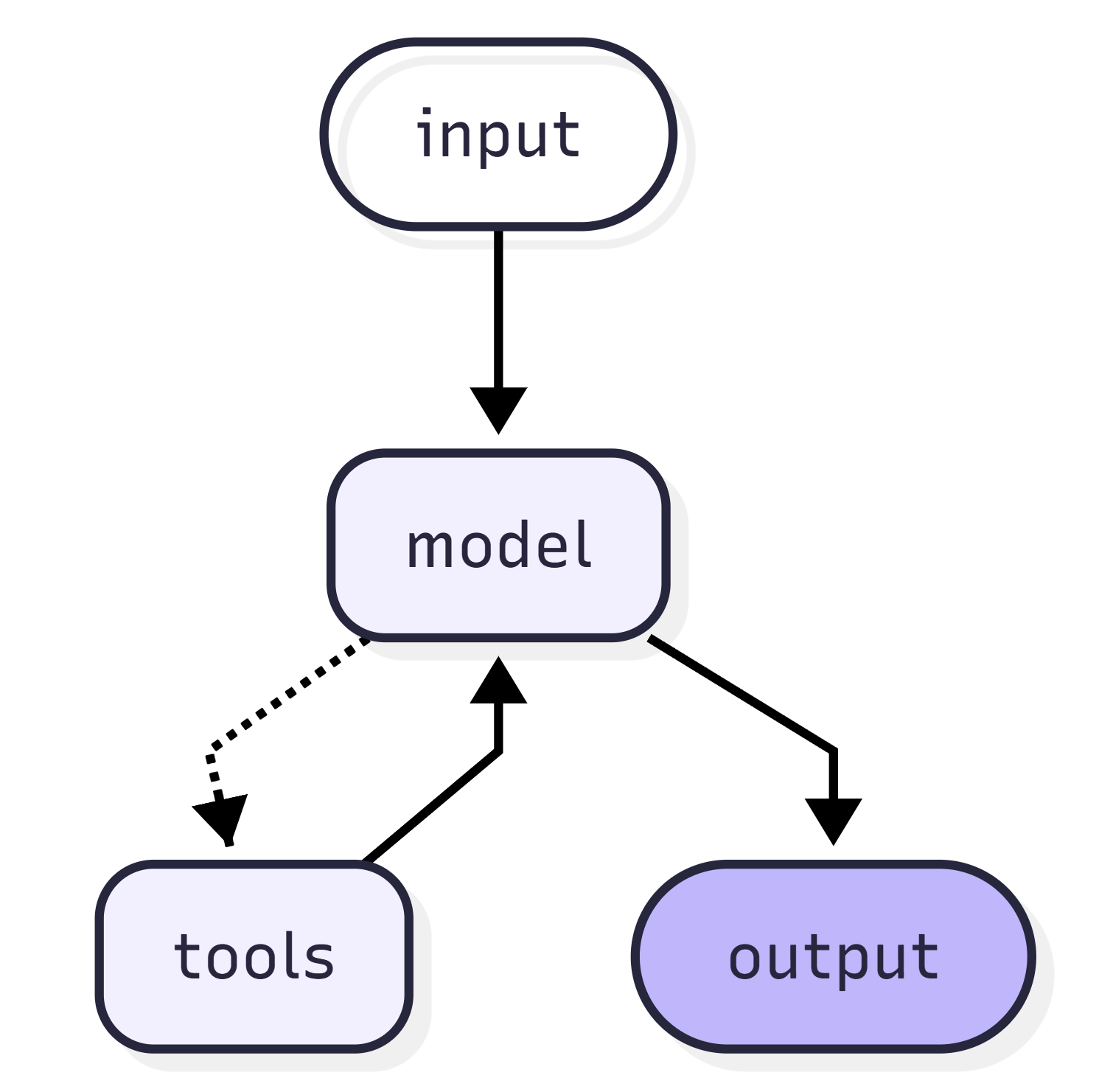
使用create_agent 创建 Agent 时,需传入模型和工具、可选地也可以传入系统提示词。
这里使用Tavily (搜索引擎)作为工具,需要先获取它的API-Key 并添加到环境变量。
python
# pip install langchain-tavily
import os
from langchain_tavily import TavilySearch
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
# 定义模型
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 定义 Tavily 搜索工具
search = TavilySearch(max_results=5)
tools = [search]
# 创建 Agent
agent = create_agent(
model=llm, # 模型
tools=tools, # 工具
system_prompt="你是位助手,需要调用工具来帮助用户。", # 系统提示词
)
# 调用 Agent
res = agent.invoke(
{"messages": [{"role": "user", "content": "今天北京的天气怎么样?"}]}
)
print(res)如果Agent 执行多个步骤,这可能需要一些时间。为了显示中间进度,我们可以使用 stream 流式返回消息。
python
# pip install langchain-tavily
import os
from langchain_tavily import TavilySearch
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
# 定义模型
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 定义 Tavily 搜索工具
search = TavilySearch(max_results=5)
tools = [search]
# 创建 Agent
agent = create_agent(model=llm, tools=tools)
# 调用 Agent
for chunk in agent.stream(
{
"messages": [
{"role": "system", "content": "你是位助手,需要调用工具来帮助用户。"},
{"role": "user", "content": "今天北京的天气怎么样?"},
]
}
):
print(chunk, end="\n\n")5.4 LangSmith
使用LangChain 构建的许多应用程序都包含多个步骤,需要多次调用 LLM。随着这些应用程序变得越来越复杂,能够检查链或 Agent 内部的具体情况变得至关重要。最好的方法是使用 LangSmith。
注册 LangSmith,在Settings ➡️ API Keys 下创建 API-Key 并复制。之后在环境变量中添加以开始记录跟踪:
LANGSMITH_TRACING="true"
LANGSMITH_API_KEY="..."配置好环境变量之后,可在LangSmith 的 Tracing Projects 中查看跟踪记录。
LangSmith 默认将跟踪记录到 default 项目,可通过 LANGSMITH_PROJECT 环境变量设置 LangSmith 跟踪记录保存到哪个项目,如果该项目不存在则会创建。
5.5 记忆
为了给代理添加短期记忆(线程级持久化),在创建代理时需要指定一个checkpointer,并在调用代理时指定线程 ID。这个短期记忆的能力是借助 LangGraph 的状态和检查点实现的。
python
import os
import datetime
from langchain_tavily import TavilySearch
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
os.environ["LANGSMITH_PROJECT"] = "agent-with-memory"
# 定义 Tavily 搜索工具
search = TavilySearch(max_results=5)
tools = [search]
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 创建 Agent
agent = create_agent(
model=llm,
tools=tools,
checkpointer=InMemorySaver(),
)
# 调用
for chunk in agent.stream(
input={
"messages": [
{
"role": "system",
"content": f"当前时间:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}",
},
{"role": "user", "content": "今天北京天气怎么样?"},
]
},
config={"configurable": {"thread_id": "1"}},
):
print(chunk, end="\n\n")
for chunk in agent.stream(
input={
"messages": [
{
"role": "system",
"content": f"当前时间:{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}",
},
{"role": "user", "content": "上海呢?"},
]
},
config={"configurable": {"thread_id": "1"}},
):
print(chunk, end="\n\n")5.6 MCP
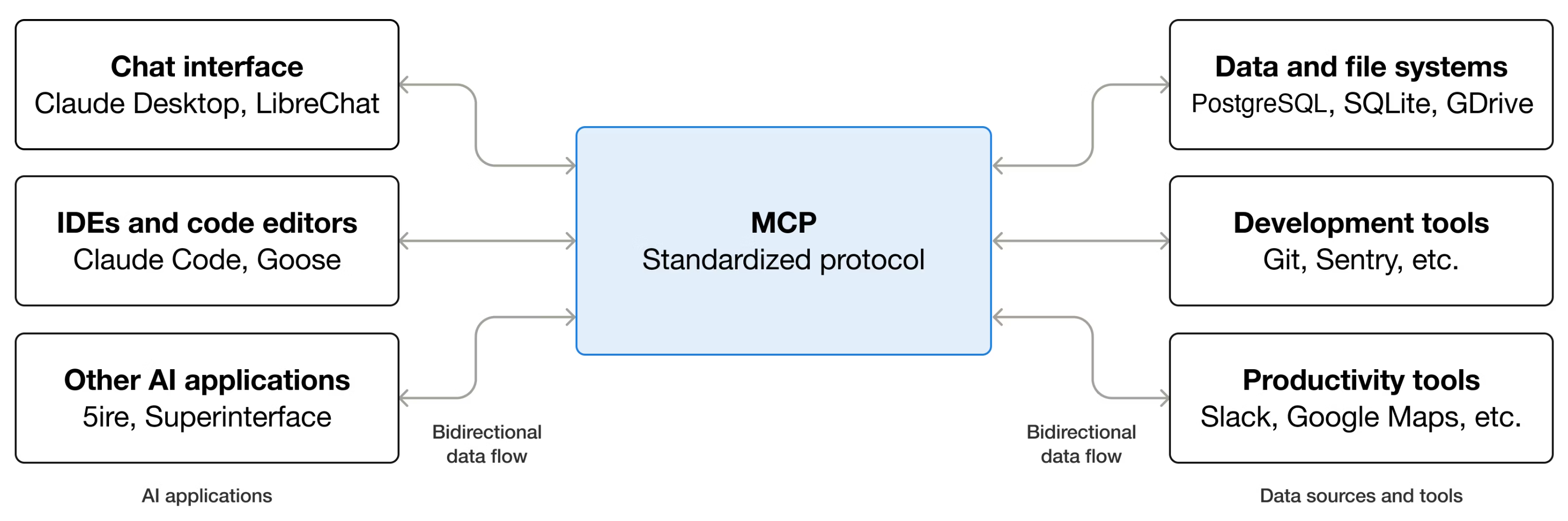
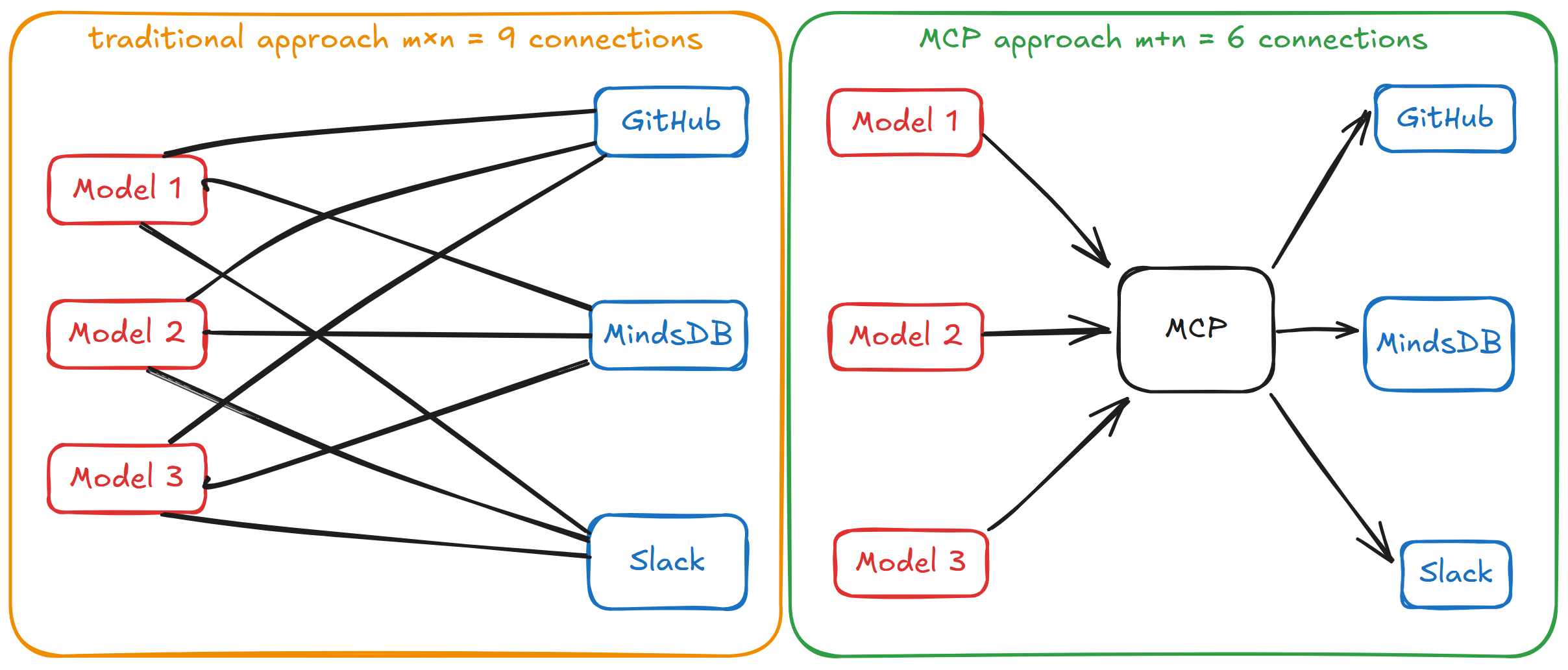
5.6.1 MCP 介绍
Model Context Protocol(MCP,模型上下文协议)是一个开源协议,它标准化了大语言模型与外部工具和数据源通信的方式,允许开发者和工具提供商只需集成一次,就能与任何兼容MCP 的系统交互。MCP 就像 USB-C 标准:不需要为每个设备使用不同的连接器,而是使用一个端口来处理多种类型的连接。
5.6.2 MCP 架构
MCP 遵循客户端-服务器架构,架构中包括:
|---------|------------------------------------------------------------------|
| MCP 主机 | 协调和管理一个或多个 MCP 客户端的 AI 应用 |
| MCP 客户端 | 一个保持与 MCP 服务器连接的组件,通过MCP 定义的消息处理通信,从服务器查找并请求资源和工具,并管理与服务器的连接生命周期 |
| MCP 服务器 | 一个向 MCP 客户端提供服务的程序,通过协议暴露工具、资源和提示模板功能 |
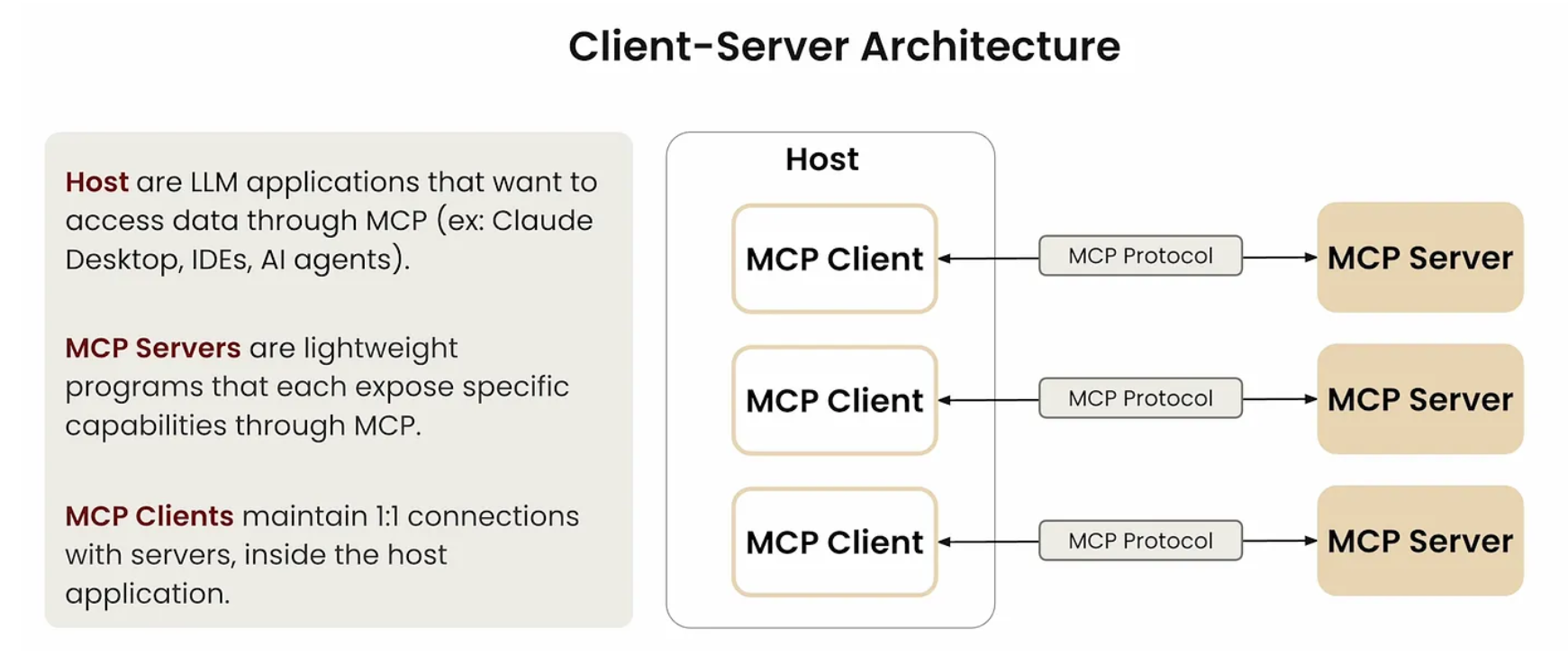
5.6.3 MCP 层级
MCP 分为两个层级:
(1)数据层
数据层实现了一个基于JSON-RPC 2.0 的交换协议,该协议定义了消息结构和语义。
数据层包括生命周期管理(连接初始化、能力协商、连接终止)、服务器功能(提供工具、资源和提示模板)、客户端功能(调用LLM、获取输入、记录消息)、其他功能(实时更新通知、长时运行操作跟踪)。
(2)传输层
传输层定义了客户端与服务器之间数据交换的通信机制和通道,包括特定传输方式的连接建立、消息帧定界和授权。
MCP 支持多种传输机制,包括 Stdio、Streamable HTTP、SSE。
|-----------------|----------------------------------------------------------------------------------------------------------|
| Stdio | 使用标准输入和输出流,与在终端输入命令并看到响应时使用的机制相同。适用于本地开发 |
| Streamable HTTP | 该传输使用HTTP POST 和 GET 请求,服务器可以选择使用SSE来流式传输多个服务器消息。支持流式传输和服务器到客户端通知,并支持标准 HTTP 身份验证方法,包括授权令牌、API 密钥和自定义头信息 |
| SSE | 带有SSE(Server-Sent Events 服务器发送事件)的HTTP,MCP早期传输机制,现逐渐被 Streamable HTTP 取代 |
5.6.4 MCP 工作流程
(1)初始化
在初始化过程中,AI 应用程序的 MCP 客户端管理器连接到配置的服务器,并将它们的能力存储起来以供后续使用。应用程序使用这些信息来确定哪些服务器可以提供特定类型的功能(工具、资源、提示),以及它们是否支持实时更新。
初始化有几个重要的作用:
|--------|----------------------------------------------|
| 协议版本协商 | 确保客户端和服务器使用兼容的协议版本,避免因版本不一致导致的通信问题 |
| 能力发现 | 声明各自支持的功能,包括他们能够处理的基元类型(工具、资源、提示)以及是否支持通知等特性 |
| 身份交换 | 交换客户端与服务器的身份及版本信息,便于后续的调试与兼容性管理 |
(2)工具发现
AI 应用程序从所有连接的 MCP 服务器中获取可用工具,并将它们组合成一个语言模型可以访问的统一工具注册表。这使得 LLM 能够理解它可以执行哪些操作,并在对话期间自动生成相应的工具调用。
连接建立之后,客户端可以通过发送tools/list 请求来发现可用的工具。这个请求是 MCP 工具发现机制的基础---它允许客户端在尝试使用工具之前了解服务器上有哪些可用的工具。响应包含一个 tools 数组,该数组提供了关于每个可用工具的全面元数据。这种基于数组的结构允许服务器同时展示多个工具,同时保持不同功能之间的清晰界限。响应中的每个工具包括几个关键字段:
|-------------|------------------------------------------------|
| name | 工具标识符 |
| title | 工具的易读显示名称 |
| description | 工具描述 |
| inputSchema | 一个定义预期输入参数的JSON Schema,支持类型验证并提供关于必需和可选参数的清晰文档 |
(3)工具执行
当语言模型在对话中决定使用工具时,AI 应用程序会拦截工具调用,将其路由到合适的 MCP 服务器,执行该工具,并将结果作为对话流程的一部分返回给 LLM。这使 LLM 能够访问实时数据并在外部世界中执行操作。
客户端使用tools/call 方法执行一个工具。tools/call 请求遵循结构化格式,确保客户端和服务器之间的类型安全和清晰通信。请求结构包括几个重要组件:
|-----------|--------------------------|
| name | 工具标识符 |
| arguments | 包含工具的inputSchema 定义的输入参数 |
响应返回一个内容对象数组,允许进行丰富、多格式的响应(文本、图片、资源等)。每个内容对象都有一个type 字段。
(4)实时更新
MCP 支持实时通知,使服务器能够在未经明确请求的情况下通知客户端有关变更。当 AI 应用程序收到关于工具变更的通知时,它会立即刷新其工具注册表并更新 LLM 的可用功能。这确保了正在进行的对话始终能够访问最新的一组工具,并且 LLM 可以随着新功能的可用而动态适应。
5.6.5 MCP SDK
5.6.5.1 Stdio 服务端与客户端
可通过mcp 包来简单创建 Stdio 服务器。
服务端mcp_server_stdio.py:
python
# pip add mcp
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
mcp = FastMCP("Demo")
# 为 MCP 实例添加工具
@mcp.tool()
def add(a: int, b: int) -> int:
return a + b
# 为 MCP 实例添加资源
@mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
# 为 MCP 实例添加提示词
@mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
if __name__ == "__main__":
mcp.run(transport="stdio")客户端:
python
# pip install mcp
import asyncio
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
async def stdio_run():
server_params = StdioServerParameters(
command="python",
args=["mcp_server_stdio.py"],
)
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# 初始化连接
await session.initialize()
# 获取可用工具
tools = await session.list_tools()
print(tools)
print()
# 调用工具
call_res = await session.call_tool("add", {"a": 1, "b": 2})
print(call_res)
print()
# 获取可用资源
resources = await session.list_resources()
print(resources)
print()
# 调用资源
read_res = await session.read_resource("greeting://default")
print(read_res)
print()
# 获取可用提示
prompts = await session.list_prompts()
print(prompts)
print()
# 调用提示
get_res = await session.get_prompt("greet_user", {"name": "Jack"})
print(get_res)
print()
asyncio.run(stdio_run())5.6.5.2 Streamable HTTP 服务端与客户端
服务端:
python
# pip add mcp
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
mcp = FastMCP("Demo")
# 为 MCP 实例添加工具
@mcp.tool()
def add(a: int, b: int) -> int:
return a + b
# 为 MCP 实例添加资源
@mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
# 为 MCP 实例添加提示词
@mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
if __name__ == "__main__":
# mcp.settings.host = "0.0.0.0"
# mcp.settings.port = 8888
mcp.run(transport="streamable-http") # 默认启动在 127.0.0.1:8000客户端:
python
# pip install mcp
import asyncio
from mcp import ClientSession
from mcp.client.streamable_http import streamablehttp_client
async def streamablehttp_run():
url = "http://127.0.0.1:8000/mcp"
headers = {"Authorization": "Bearer sk-atguigu"}
async with streamablehttp_client(url, headers) as (read, write, _):
async with ClientSession(read, write) as session:
# 初始化连接
await session.initialize()
# 获取可用工具
tools = await session.list_tools()
print(tools)
print()
# 调用工具
call_res = await session.call_tool("add", {"a": 1, "b": 2})
print(call_res)
print()
# 获取可用资源
resources = await session.list_resources()
print(resources)
print()
# 调用资源
read_res = await session.read_resource("greeting://default")
print(read_res)
print()
# 获取可用提示
prompts = await session.list_prompts()
print(prompts)
print()
# 调用提示
get_res = await session.get_prompt("greet_user", {"name": "Jack"})
print(get_res)
print()
asyncio.run(streamablehttp_run())5.6.5.3 将多个Streamable HTTP 服务器挂载到 ASGI 服务器
**ASGI(Asynchronous Server Gateway Interface)**是Python 的 异步 Web 服务器接口标准,定义了服务器与应用之间的通信协议,支持异步调用,能够处理高并发和长连接。
可以使用streamable_http_app 方法将 StreamableHTTP 服务器挂载到现有的 ASGI 服务器。这允许将 StreamableHTTP 服务器与其他 ASGI 应用程序集成。
python
# pip add mcp fastapi
import uvicorn
import contextlib
from fastapi import FastAPI
from mcp.server.fastmcp import FastMCP
# 创建 MCP 实例
tool_mcp = FastMCP("tool server")
resource_mcp = FastMCP("resource server")
prompt_mcp = FastMCP("prompt server")
# 为 tool_mcp 实例添加工具
@tool_mcp.tool()
def add(a: int, b: int) -> int:
return a + b
# 为 resource_mcp 实例添加资源
@resource_mcp.resource("greeting://default")
def get_greeting() -> str:
return "Hello from static resource!"
# 为 prompt_mcp 实例添加提示词
@prompt_mcp.prompt()
def greet_user(name: str, style: str = "friendly") -> str:
styles = {
"friendly": "写一句友善的问候",
"formal": "写一句正式的问候",
"casual": "写一句轻松的问候",
}
return f"为{name}{styles.get(style, styles['friendly'])}"
# 设置 MCP 的 HTTP 根路径
tool_mcp.settings.streamable_http_path = "/"
resource_mcp.settings.streamable_http_path = "/"
prompt_mcp.settings.streamable_http_path = "/"
# 创建一个组合生命周期来管理会话管理器
@contextlib.asynccontextmanager
async def lifespan(app: FastAPI):
async with contextlib.AsyncExitStack() as stack:
await stack.enter_async_context(tool_mcp.session_manager.run())
await stack.enter_async_context(resource_mcp.session_manager.run())
await stack.enter_async_context(prompt_mcp.session_manager.run())
yield
app = FastAPI(lifespan=lifespan)
# 挂载 MCP 服务器
app.mount("/tool", tool_mcp.streamable_http_app())
app.mount("/resource", resource_mcp.streamable_http_app())
app.mount("/prompt", prompt_mcp.streamable_http_app())
if __name__ == "__main__":
uvicorn.run(app)客户端代码和之前一致,注意修改URL 路径。
5.6.6 LangChain 使用 MCP
LangChain Agent 可以通过 langchain-mcp-adapters 包使用 MCP 服务器上定义的工具。
这里使用了如下工具,需要先在相关平台创建API-Key 并添加到环境变量:
- 阿里云百炼:https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
- Smithery:https://smithery.ai/server/@DeniseLewis200081/rail
python
# pip install langchain_mcp_adapters
import os
import asyncio
from urllib.parse import urlencode
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_mcp_adapters.client import MultiServerMCPClient
# 配置 MCP 客户端
mcp_client = MultiServerMCPClient(
{
"WebSearch": {
"transport": "sse",
"url": "https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/sse",
"headers": {"Authorization": f"Bearer {os.getenv('DASHSCOPE_API_KEY')}"},
}, # https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
"RailService": {
"transport": "streamable_http",
"url": f"{'https://server.smithery.ai/@DeniseLewis200081/rail/mcp'}?{urlencode({'api_key': os.getenv('SMITHERY_API_KEY')})}",
}, # https://smithery.ai/server/@DeniseLewis200081/rail
}
)
# 获取工具
tools = asyncio.run(mcp_client.get_tools())
# 定义模型
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# 创建 Agent
agent = create_agent(model=llm, tools=tools)
# 调用 Agent
async def main():
async for chunk in agent.astream(
{
"messages": [
{"role": "system", "content": "你是位助手,需要调用工具来帮助用户。"},
{
"role": "user",
"content": "北京今天天气怎么样,要是还不错的话,帮我看看今天上海到北京的车票",
},
]
}
):
print(chunk, end="\n\n")
asyncio.run(main())5.7 监督者模式多Agnet 架构
监督者(主管)模式是一种多Agnet 架构,其中中央主管 Agnet 负责协调各专业工作 Agnet 。当任务需要不同类型的专业知识时,这种方法非常有效。与其构建一个管理跨领域工具选择的 Agnet ,不如创建由了解整体工作流程的主管协调的、专注的专家。
在LangChain 中可以将 Agent 封装为工具,将工具绑定到主管 Agent 来实现主管多代理模式。
举例:创建两个子Agent,分别带有搜索功能和发送邮件功能,并通过主管 Agent 调用子 Agent。
python
import os
import asyncio
import smtplib
from langchain.tools import tool
from urllib.parse import urlencode
from email.mime.text import MIMEText
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
from langchain_mcp_adapters.client import MultiServerMCPClient
llm = init_chat_model(
model="z-ai/glm-4.5-air:free",
model_provider="openai",
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
# ========== 创建一个有搜索功能的子Agent ==========
class SearchSubAgent:
"""带搜索功能的子Agent"""
def __init__(self):
self.tools = asyncio.run(
MultiServerMCPClient(
{
"WebSearch": {
"transport": "sse", # 服务器发送事件 (SSE):针对实时流通信进行优化的可流式 HTTP 的变体。
"url": "https://dashscope.aliyuncs.com/api/v1/mcps/WebSearch/sse",
"headers": {
"Authorization": f"Bearer {os.getenv('DASHSCOPE_API_KEY')}"
},
}, # https://bailian.console.aliyun.com/?tab=mcp#/mcp-market/detail/WebSearch
"RailService": {
"transport": "streamable_http", # 流式 HTTP:服务器作为独立进程运行,处理 HTTP 请求。支持远程连接和多客户端。
"url": f"{'https://server.smithery.ai/@DeniseLewis200081/rail/mcp'}?{urlencode({'api_key': os.getenv('SMITHERY_API_KEY')})}",
}, # https://smithery.ai/server/@DeniseLewis200081/rail
}
).get_tools()
)
self.agent = create_agent(model=llm, tools=self.tools)
async def __call__(self, input: str) -> str:
return await self.agent.ainvoke(
{"messages": [{"role": "user", "content": input}]}
)
# ========== 创建一个能发送邮件的子Agent ==========
@tool
async def send_email(to: list[str], subject: str, body: str) -> str:
"""
发送邮件。需要自动生成邮件主题。
Args:
to: 收件人
subject: 邮件主题
body: 邮件正文
"""
SMTP_HOST = "smtp.qq.com"
SMTP_USER = os.getenv("SMTP_USER")
SMTP_PASS = os.getenv("SMTP_PASS") # 需要在邮箱中开启 SMTP 并生成授权码
msg = MIMEText(body, "plain", "utf-8")
msg["From"] = SMTP_USER
msg["Subject"] = subject
try:
server = smtplib.SMTP_SSL(SMTP_HOST, 465, timeout=10)
server.login(SMTP_USER, SMTP_PASS)
server.sendmail(SMTP_USER, to, msg.as_string())
try:
server.quit()
except smtplib.SMTPResponseException as e:
if e.smtp_code == -1 and e.smtp_error == b"\x00\x00\x00":
pass # 忽略无害的关闭异常
else:
raise
return "success"
except Exception as e:
return f"Send failed: {type(e).__name__} - {e}"
class EmailSubAgent:
"""带发送邮件功能的子代理"""
def __init__(self):
self.tools = [send_email]
self.agent = create_agent(model=llm, tools=self.tools)
async def __call__(self, input: str) -> str:
return await self.agent.ainvoke(
{"messages": [{"role": "user", "content": input}]}
)
search_subagent = SearchSubAgent()
email_subagent = EmailSubAgent()
# ========== 将子 Agent 包装为工具 ==========
@tool
async def search(input: str) -> str:
"""
一个具有搜索功能的子Agent,功能包括:
- 搜索网页
- 搜索火车票相关信息
"""
return await search_subagent(input)
@tool
async def email(input: str) -> str:
"""
一个具有发送邮件功能的子Agent
"""
return await email_subagent(input)
# ========== 创建主管 Agent ==========
supervisor_agent = create_agent(
model=llm,
tools=[search, email],
system_prompt="你是一个主管,需要调用子Agent来帮助用户",
)
async def main():
async for chunk in supervisor_agent.astream(
{
"messages": [
{
"role": "user",
"content": "北京明天天气怎么样,要是还不错的话,帮我看看明天上海到北京的车票。如果天气好的话,发送邮件给xxxxxx@qq.com告诉他我明天去北京。如果天气不好的话就告诉他我明天不去北京了。",
}
]
}
):
print(chunk, end="\n\n")
asyncio.run(main())更多推荐
-
工··信··部 · A··I·G··C·证··书
-
AI 工具集导航:
-
AI 学习知识库