重磅推荐专栏:
《大模型AIGC》
《课程大纲》
《知识星球》
本专栏系统介绍了大语言模型(LLM)及其相关技术的系列文章。第一章从LLM基础概念入手,涵盖文本向量化、ChatGPT应用、模型架构等基础知识,并针对Qwen3模型进行了6篇技术报告的深度解读。第二章聚焦RAG(检索增强生成)与Agent技术,包括RAG架构实践、知识图谱应用和多篇行业案例解析,同时包含17篇Dify框架核心源码的模块化解读。文章内容涵盖从基础理论到行业应用的全方位技术解析,为开发者提供了大语言模型技术落地的完整知识体系。
Github地址:https://github.com/xiaoyesoso/SlideFlow
SlideFlow 不仅仅是一个 PPT 生成器,它是一个基于 LangGraph 状态机编排、MCP (Model Context Protocol) 协议驱动、并具备 RAG (检索增强生成) 能力的端到端自动化引擎。它能够将模糊的创意或繁杂的文档,转化为具备专业排版、高保真图像和完全可编辑性的演示文稿。
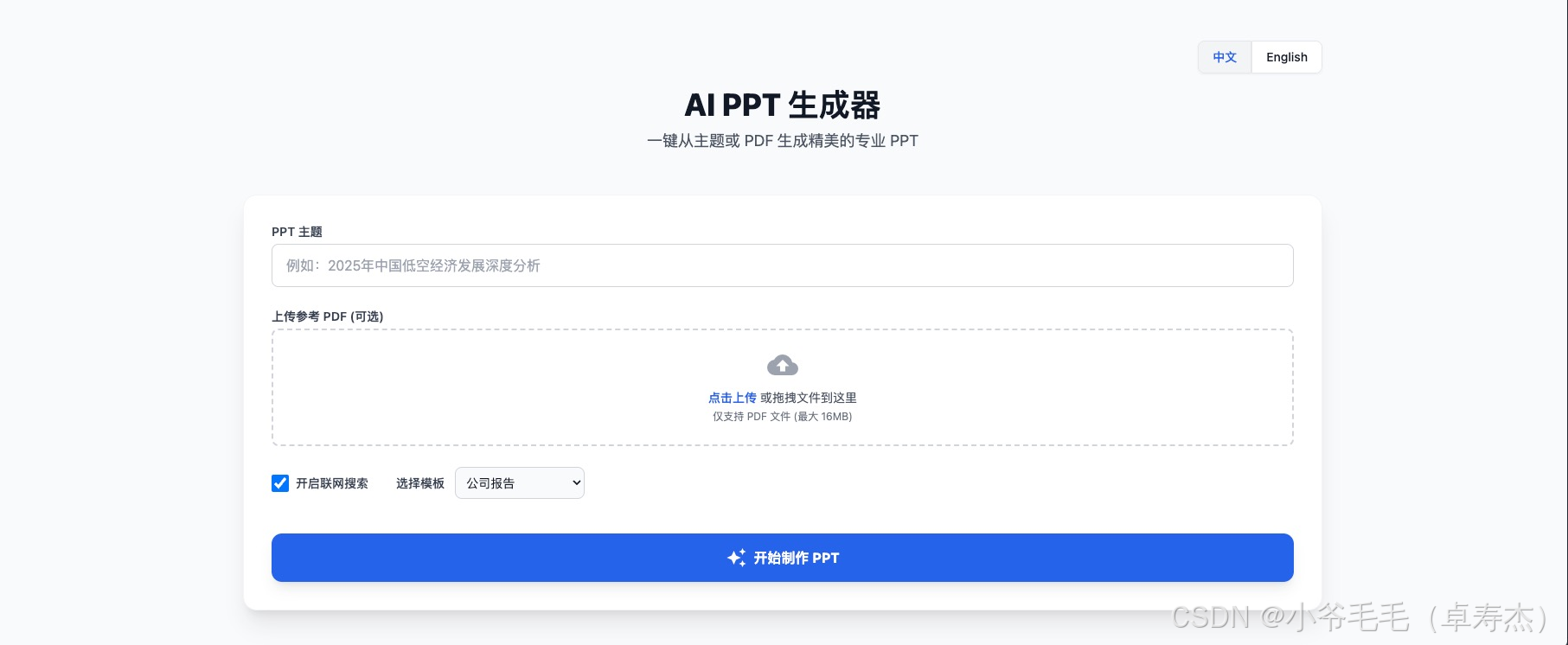
🏗️ 架构设计:高度解耦的生产力模型
SlideFlow 采用现代 AI 应用的四层架构设计,确保了在 Agent 交互、并发生成和基础设施扩展上的卓越表现。
1. 逻辑架构概览 (Mermaid)
- 执行与基础设施层 2. 接口与协议层 1. 交互层 工具调用
API 请求 - 逻辑编排层 - LangGraph 1. 联网搜索与大纲生成 2. 章节深度内容扩写 3. HTML 幻灯片原子生成 4. PDF 像素级合成 5. PPTX 矢量化转换 用户
AI Agent / Claude Desktop
响应式 Dashboard
FastMCP Server
Flask / Web API
SSE 流式推送引擎
Serper / DuckDuckGo
Milvus Lite / RAG
Jinja2 / Tailwind CSS
Playwright / Python-pptx
2. 核心组件职责表
| 层次 | 组件 | 关键技术 | 核心职责 |
|---|---|---|---|
| 交互层 | Web Dashboard | Vue 3 + Tailwind | 提供实时可视化反馈,展示生成进度与日志。 |
| 协议层 | MCP Server | FastMCP | 暴露 10 个原子工具,使 AI Agent 具备操作 SlideFlow 的"手"和"眼"。 |
| 编排层 | LangGraph | StateGraph | 管理复杂的有向无环图(DAG),实现内容的并行扩写与生成。 |
| 基础设施层 | 矢量 RAG 引擎 | Milvus Lite | 基于本地向量库提供私有文档检索能力,增强内容的专业深度。 |
| 基础设施层 | 转换引擎 | Playwright | 执行像素级捕获,将 HTML 模板精确映射到 PPTX 矢量元素。 |
🔬 技术深潜:核心工作流深度解析
1. LangGraph 状态机编排:精准的任务流控制
SlideFlow 的核心大脑是位于 ppt_graph.py 中的状态机。不同于传统的线性脚本,它支持复杂的并行处理和状态回溯。
python
# core/ppt_graph.py 核心逻辑片段
def create_ppt_graph():
# PPTState 存储了整个生成周期的所有上下文(大纲、页面、路径等)
workflow = StateGraph(PPTState)
# 注册 5 个核心工作节点
workflow.add_node("search_outline", search_outline_node) # 节点 1:生成结构化 JSON 大纲
workflow.add_node("chapter_content", chapter_content_node) # 节点 2:深度内容扩写(并行)
workflow.add_node("page_generation", page_generation_node) # 节点 3:原子 HTML 生成(并行)
workflow.add_node("pdf_synthesis", pdf_synthesis_node) # 节点 4:渲染为高保真 PDF
workflow.add_node("html_to_pptx", html_to_pptx_node) # 节点 5:重建为矢量 PPTX
# 编排逻辑:Search 结束后,同时启动内容扩写与页面生成
workflow.set_entry_point("search_outline")
workflow.add_edge("search_outline", "chapter_content")
workflow.add_edge("search_outline", "page_generation")
# 两个分支完成后汇聚到合成节点
workflow.add_edge("chapter_content", "pdf_synthesis")
workflow.add_edge("page_generation", "pdf_synthesis")
workflow.add_edge("pdf_synthesis", "html_to_pptx")
workflow.add_edge("html_to_pptx", END)
return workflow.compile()2. 高保真 HTML-to-PPTX:从 DOM 到矢量的桥梁
这是 SlideFlow 的核心"黑科技"。通过 html_to_ppt.py,我们避免了简单的"截图粘贴",而是实现了真正的元素重建。
- 坐标捕获 :使用 Playwright 执行自定义 JS 脚本,获取每个字符、图像、形状的
getBoundingClientRect()。 - 样式还原 :提取计算后的 CSS 样式(如 RGB 颜色、字体大小、对齐方式),并映射到
python-pptx的对应属性。 - 分层策略:背景图片 -> 装饰性元素 -> 文本内容 -> 图标。
javascript
// html_to_ppt.py 中的核心坐标捕获逻辑
async () => {
const elements = [];
// 遍历所有非脚本和样式的可见元素
const allElements = document.querySelectorAll('body *:not(script):not(style)');
allElements.forEach(el => {
const rect = el.getBoundingClientRect();
const style = window.getComputedStyle(el);
// 精确处理 TextNode 及其换行情况
if (hasDirectText(el)) {
elements.push({
type: 'text',
text: el.textContent.trim(),
x: rect.left, y: rect.top, // 像素级坐标
fontSize: parseFloat(style.fontSize),
fontFamily: style.fontFamily,
color: parseRGB(style.color), // 将 'rgb(r,g,b)' 转为数组
textAlign: style.textAlign
});
}
});
return elements;
}3. RAG 引擎:基于 Milvus Lite 的知识增强
在 vector_utils.py 中,我们集成了 Milvus Lite,为 PPT 提供垂直领域的知识支撑。
- 本地索引 :无需部署庞大的向量数据库集群,
milvus_demo.db即可满足本地 Agent 的低延迟检索需求。 - 自动切片 :使用
tiktoken进行精准的 Token 计数和重叠切片(Chunking),确保上下文完整。
python
# vector_utils.py 核心 RAG 逻辑
class VectorSearchManager:
def __init__(self, db_path: str = "milvus_demo.db"):
# 初始化 Milvus Lite 客户端
self.milvus_client = MilvusClient(db_path)
self.collection_name = "pdf_chunks"
async def add_pdf(self, pdf_path: str):
"""将 PDF 内容向量化并存入 Milvus"""
text = self.extract_text_from_pdf(pdf_path)
chunks = self.chunk_text(text, chunk_size=500, chunk_overlap=50)
# 获取 Embedding 并存入向量库
for chunk in chunks:
embedding = await self.get_embedding(chunk)
self.milvus_client.insert(
collection_name=self.collection_name,
data=[{"vector": embedding, "text": chunk, "source": pdf_path}]
)🔌 MCP 模式:将 SlideFlow 挂载到您的 Agent
1. 核心工具列表 (10 个原子工具)
| 工具名称 | 作用阶段 | 功能描述 |
|---|---|---|
initialize_task_workspace |
初始化 | 为新任务创建独立的工作目录,隔离 HTML、PDF 和 PPTX。 |
search_web |
调研 | 调用 Serper 或 DuckDuckGo 获取互联网实时信息。 |
search_vector_db |
调研 | 在本地 PDF 向量库中检索专业知识。 |
get_generation_guidelines |
规划 | 核心工具:获取各类型页面的 System Prompt 和生成规则。 |
list_available_templates |
设计 | 返回系统内置的视觉模板列表(如 company_report)。 |
get_template_reference |
设计 | 获取特定模板页面的参考 HTML/CSS 结构。 |
search_images |
设计 | 搜索高清背景图片以增强幻灯片视觉效果。 |
save_html_to_workspace |
设计 | 将 Agent 生成的 HTML 代码保存到磁盘。 |
list_workspace_files |
验证 | 列出当前任务已保存的所有 HTML 幻灯片。 |
synthesize_final_documents |
合成 | 最终步骤:触发 Playwright 和 PPTX 转换引擎生成产物。 |
2. 配置 Claude Desktop
将 SlideFlow 挂载为 Claude 的"外部技能":
json
{
"mcpServers": {
"slideflow": {
"command": "python",
"args": ["/Users/your_path/SlideFlow/mcp_server.py"],
"env": {
"OPENAI_API_KEY": "sk-xxxx",
"SERPER_API_KEY": "xxxx"
}
}
}
}🚀 快速开始
1. 环境依赖
bash
# 推荐 Python 3.10+
pip install -r requirements.txt
# 安装 Playwright 驱动(用于 HTML 渲染)
playwright install chromium2. 运行模式
- Web 交互模式 :运行
python main.py,访问http://localhost:5001。 - Agent 模式 :通过 Claude Desktop 或其他 MCP 客户端连接
mcp_server.py。
🔮 未来展望
- 多模态图表识别:直接识别用户上传图片中的图表并转化为 PPT 内部原生图表。
- 多 Agent 协作流:引入"设计 Agent"和"文案 Agent"进行多轮博弈优化。
- 矢量资产库扩展:支持更多样化的 SVG 图标和动态背景模板。
📂 项目结构
text
SlideFlow/
├── core/
│ ├── nodes/ # LangGraph 节点实现(大纲、内容、合成等)
│ ├── utils/ # 核心工具类(RAG、转换引擎、搜索)
│ ├── ppt_graph.py # 工作流状态机定义
│ └── state.py # 共享状态 PPTState 定义
├── web/ # 基于 Flask 的可视化看板
├── mcp_server.py # MCP 协议入口
├── main.py # Web 服务入口
└── assets/ # 模板与静态资源📄 开源协议
本项目采用 MIT License。
💡 提示 :为了获得最佳生成质量,建议使用 Claude 3.5 Sonnet 或 GPT-4o 作为底层模型。