新闻文本分类识别系统
技术栈:前端Vue3+Element Plus,后端Flask,算法:TensorFlow+textCNN
项目介绍
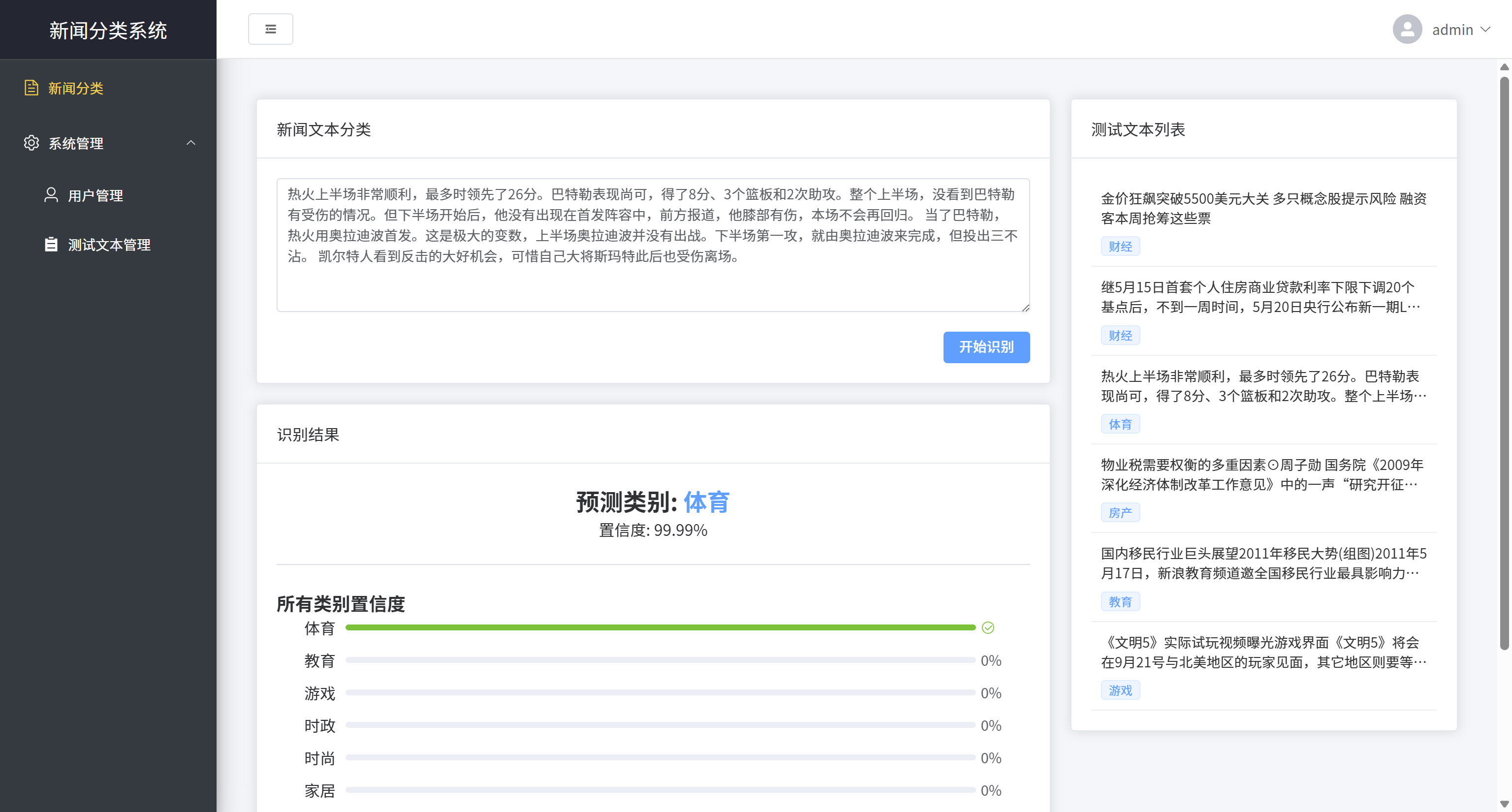
本新闻文本分类识别系统是一个基于深度学习的智能文本分类Web应用平台。系统采用前后端分离架构,后端使用Python Flask框架提供RESTful API服务,前端采用Vue3框架结合Element Plus组件库构建现代化用户界面。核心算法基于TensorFlow深度学习框架,采用textCNN(卷积神经网络)模型对中文新闻文本进行自动分类,可识别体育、财经、房产、家居、教育、科技、时尚、时政、游戏、娱乐等十大类别。
选题背景与意义
随着互联网技术的飞速发展,网络新闻信息呈爆炸式增长,每天产生海量的新闻文本数据。传统的人工分类方式效率低下、成本高昂,已无法满足大数据时代的信息处理需求。自动文本分类技术作为自然语言处理的重要应用领域,能够快速准确地实现新闻内容的自动化归类,对于提高信息检索效率、实现个性化推荐、辅助内容监管具有重要意义。
关键技术栈:textCNN算法
textCNN(Text Convolutional Neural Network)是Yoon Kim于2014年提出的用于文本分类的卷积神经网络模型,其核心思想是利用一维卷积提取文本的局部特征。与传统CNN应用于图像处理不同,textCNN将词向量序列作为输入,通过不同尺寸的卷积核捕捉不同范围的语义特征(如词组、短语等)。
系统中的textCNN模型包含嵌入层、卷积层、池化层和全连接层。首先将文本转换为词向量矩阵表示,然后使用多个不同窗口大小的卷积核进行特征提取,通过最大池化操作保留最重要的特征信息,最后经Softmax激活函数输出各类别的概率分布。该模型在预训练的词向量基础上进行微调,相比RNN和LSTM等序列模型,textCNN具有训练速度快、参数量少、并行计算友好等优势。
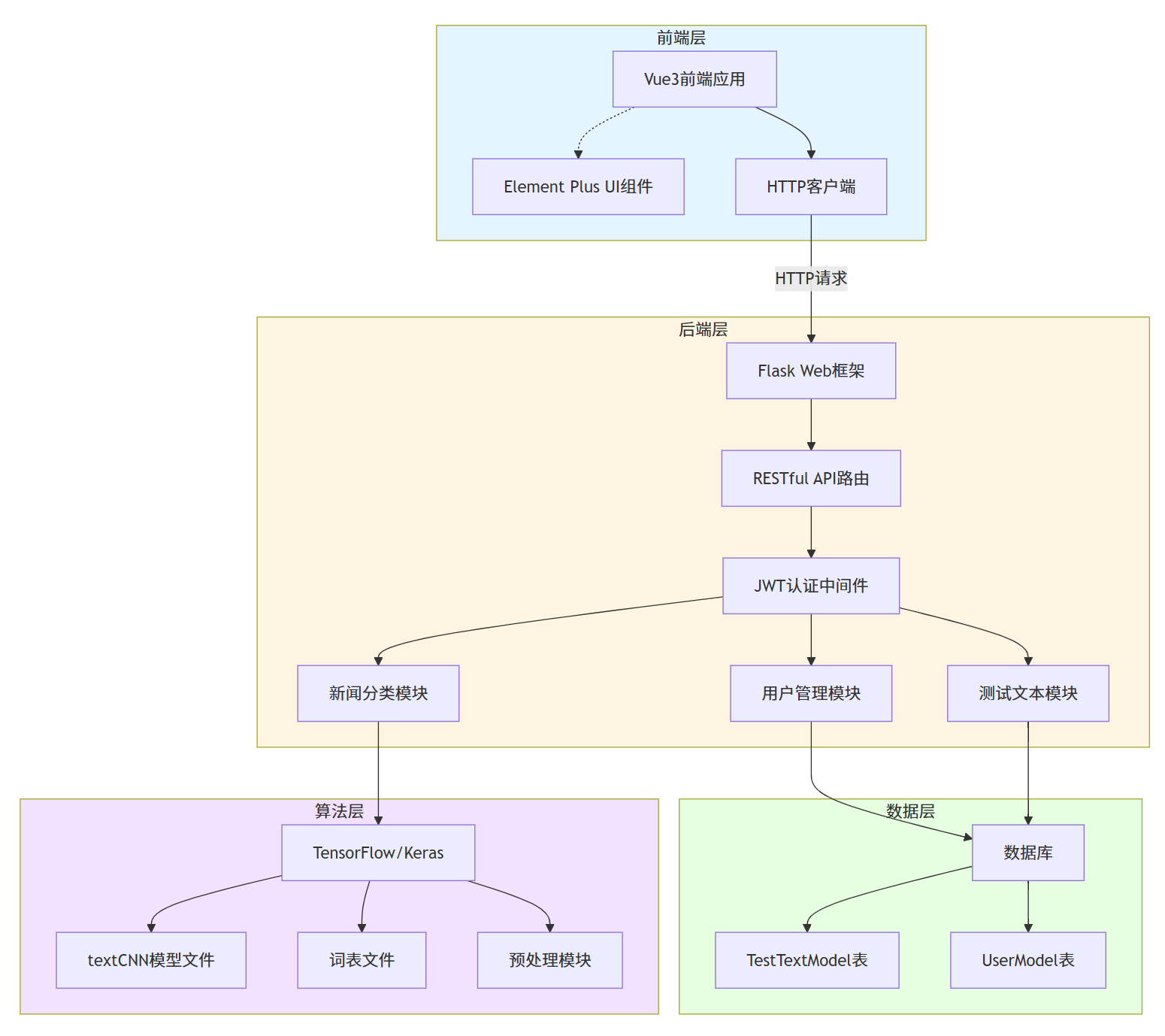
系统架构图
系统功能模块图