LangGraph学习笔记(一)---快速入门与底层原理剖析及工作流搭建
文章目录
- LangGraph学习笔记(一)---快速入门与底层原理剖析及工作流搭建
- [一、LangGraph---- 以图的方式构建语言代理](#一、LangGraph---- 以图的方式构建语言代理)
- 二、安装
- 三、LangGraph快速构建Agent工作流应用
-
- [1. Agent工作流](#1. Agent工作流)
- [2. 设置](#2. 设置)
- [3. 完整代码](#3. 完整代码)
- 总结
一、LangGraph---- 以图的方式构建语言代理
官方文档地址:https://langchain-ai.github.io/langgraph/
1. 核心定义与定位
是什么:LangGraph 是一个专用于构建有状态、多角色应用程序的库。
- 面向场景:基于大语言模型(LLMs)的代理(Agent)与多代理工作流。
- 层级关系:是 LangChain 的高级库,为其增加了循环计算能力。
- 关键对比:区别于传统的线性工作流,支持带循环的、更复杂的任务处理流程。
2.核心优势
作用:相比其他LLM框架,LangGraph提供了三大关键优势:
① 循环(Cyclical)
- 允许定义带循环的流程,这是大多数代理架构的必需特性。
- 使工作流能够根据状态反馈重复或调整执行路径。
② 可控性(Controllability)
- 作为一种底层框架,提供对应用程序流程和状态的精细控制。
- 这对于构建可靠、可预测的代理至关重要。
③ 持久性(Persistence)
- 内置持久化机制。
- 作用:实现了高级的人机交互(Human-in-the-loop) 和内存(Memory) 功能,使状态在交互中得以保留和延续。
3. 核心架构组件
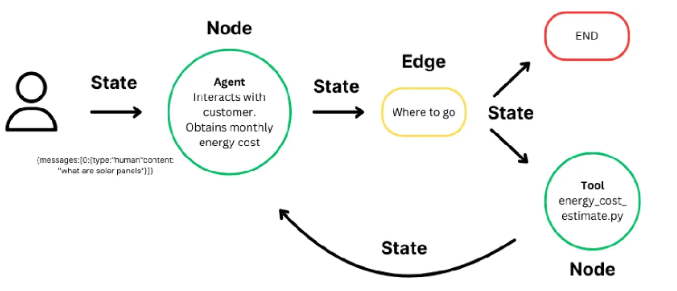
- 状态(State)
- 是什么:一个在计算过程中维护上下文的数据结构。
- 作用:实现基于累积数据的动态决策,是工作流在步骤间传递和更新信息的载体。
- 节点(Node)
- 是什么:代表工作流中的一个计算步骤或单元。
- 作用:执行特定的任务(如调用LLM、运行工具、处理数据)。节点可被定制以适应不同的工作流需求。
- 边(Edge)
- 是什么:连接各个节点的有向连线。
- 作用 :
- 定义计算流程:决定工作流中节点的执行顺序。
- 支持条件逻辑:可以根据当前状态的值,动态决定下一步执行哪个节点,从而实现分支、循环等复杂工作流。
4.主要功能
● 循环和分支:在您的应用程序中实现循环和条件语句。
● 持久性:在图中的每个步骤之后自动保存状态。在任何时候暂停和恢复图执行以支持错误恢复、"人机交互"工作流、时间旅行等等。
● "人机交互":中断图执行以批准或编辑代理计划的下一个动作。
● 流支持:在每个节点产生输出时流式传输输出(包括令牌流式传输)。
● 与 LangChain 集成:LangGraph 与 LangChain 和 LangSmith 无缝集成(但不需要它们)。
二、安装
python
pip install -U langgraph1.示例
LangGraph 的一个核心概念是状态。每次图执行都会创建一个状态,该状态在图中的节点执行时传递,每个节点在执行后使用其返回值更新此内部状态。图更新其内部状态的方式由所选图类型或自定义函数定义。
让我们看一个可以使用搜索工具的简单代理示例。
python
pip install langchain-openai
python
setx OPENAI_BASE_URL "https://api.openai.com/v1"
setx OPENAI_API_KEY "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"可以选择设置 LangSmith 以实现最佳的可观察性。
python
setx LANGSMITH_TRACING "true"
setx LANGSMITH_API_KEY "xxxxxxxxxxxxxxxx"
python
#示例:langgraph_hello.py
from typing import Literal
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# pip install langgraph
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, StateGraph, MessagesState
from langgraph.prebuilt import ToolNode
# 定义工具函数,用于代理调用外部工具
@tool
def search(query: str):
"""模拟一个搜索工具"""
if "上海" in query.lower() or "Shanghai" in query.lower():
return "现在30度,有雾."
return "现在是35度,阳光明媚。"
# 将工具函数放入工具列表
tools = [search]
# 创建工具节点
tool_node = ToolNode(tools)
# 1.初始化模型和工具,定义并绑定工具到模型
model = ChatOpenAI(model="gpt-4o", temperature=0).bind_tools(tools)
# 定义函数,决定是否继续执行
def should_continue(state: MessagesState) -> Literal["tools", END]:
messages = state['messages']
last_message = messages[-1]
# 如果LLM调用了工具,则转到"tools"节点
if last_message.tool_calls:
return "tools"
# 否则,停止(回复用户)
return END
# 定义调用模型的函数
def call_model(state: MessagesState):
messages = state['messages']
response = model.invoke(messages)
# 返回列表,因为这将被添加到现有列表中
return {"messages": [response]}
# 2.用状态初始化图,定义一个新的状态图
workflow = StateGraph(MessagesState)
# 3.定义图节点,定义我们将循环的两个节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
# 4.定义入口点和图边
# 设置入口点为"agent"
# 这意味着这是第一个被调用的节点
workflow.set_entry_point("agent")
# 添加条件边
workflow.add_conditional_edges(
# 首先,定义起始节点。我们使用`agent`。
# 这意味着这些边是在调用`agent`节点后采取的。
"agent",
# 接下来,传递决定下一个调用节点的函数。
should_continue,
)
# 添加从`tools`到`agent`的普通边。
# 这意味着在调用`tools`后,接下来调用`agent`节点。
workflow.add_edge("tools", 'agent')
# 初始化内存以在图运行之间持久化状态
checkpointer = MemorySaver()
# 5.编译图
# 这将其编译成一个LangChain可运行对象,
# 这意味着你可以像使用其他可运行对象一样使用它。
# 注意,我们(可选地)在编译图时传递内存
app = workflow.compile(checkpointer=checkpointer)
# 6.执行图,使用可运行对象
final_state = app.invoke(
{"messages": [HumanMessage(content="上海的天气怎么样?")]},
config={"configurable": {"thread_id": 42}}
)
# 从 final_state 中获取最后一条消息的内容
result = final_state["messages"][-1].content
print(result)
final_state = app.invoke(
{"messages": [HumanMessage(content="我问的那个城市?")]},
config={"configurable": {"thread_id": 42}}
)
result = final_state["messages"][-1].content
print(result)
python
上海现在的天气是30度,有雾。现在,当我们传递相同的 "thread_id" 时,对话上下文将通过保存的状态(即存储的消息列表)保留下来。
python
final_state = app.invoke(
{"messages": [HumanMessage(content="我问的那个城市?")]},
config={"configurable": {"thread_id": 42}}
)
result = final_state["messages"][-1].content
print(result)
python
你问的是上海的天气。上海现在的天气是30度,有雾。2.逐步分解
① 初始化模型和工具
- 我们使用 ChatOpenAI 作为我们的 LLM。
注意:我们需要确保模型知道可以使用哪些工具。我们可以通过将 LangChain 工具转换为 OpenAI 工具调用格式来完成此操作,方法是使用 .bind_tools() 方法。 - 我们定义要使用的工具------在本例中是搜索工具。创建自己的工具非常容易------请参阅此处的文档了解如何操作 此处。
② 用状态初始化图
- 我们通过传递状态模式(在本例中为 MessagesState )来初始化图(StateGraph)。
- MessagesState 是一个预构建的状态模式,它具有一个属性,一个 LangChain Message 对象列表,以及将每个节点的更新合并到状态中的逻辑。
③ 定义图节点
我们需要两个主要节点
- agent 节点:负责决定采取什么(如果有)行动。
- 调用工具的 tools 节点:如果代理决定采取行动,此节点将执行该行动。
④ 定义入口点和图边
首先,我们需要设置图执行的入口点------agent 节点。
然后,我们定义一个普通边和一个条件边。条件边意味着目的地取决于图状态(MessageState)的内容。在本例中,目的地在代理(LLM)决定之前是未知的。
- 条件边:调用代理后,我们应该要么
a. 如果代理说要采取行动,则运行工具
b. 如果代理没有要求运行工具,则完成(回复用户)。 - 普通边:调用工具后,图应该始终返回到代理以决定下一步操作。
⑤ 编译图
- 当我们编译图时,我们将其转换为 LangChain Runnable,这会自动启用使用您的输入调用 .invoke() 、.stream() 和 .batch()。
- 我们还可以选择传递检查点对象以在图运行之间持久化状态,并启用内存、"人机交互"工作流、时间旅行等等。在本例中,我们使用 MemorySaver------一个简单的内存中检查点。
⑤ 执行图
a. LangGraph 将输入消息添加到内部状态,然后将状态传递给入口点节点 "agent"。
b. "agent" 节点执行,调用聊天模型。
c. 聊天模型返回 AIMessage。LangGraph 将其添加到状态中。
d. 图循环以下步骤,直到 AIMessage 上不再有 tool_calls。
- 如果 AIMessage 具有 tool_calls,则 "tools" 节点执行。
- "agent" 节点再次执行并返回 AIMessage。
e. 执行进度到特殊的 END 值,并输出最终状态。因此,我们得到所有聊天消息的列表作为输出。
三、LangGraph快速构建Agent工作流应用
1. Agent工作流
下面展示了如何创建一个"计划并执行"风格的代理。这在很大程度上借鉴了计划和解决论文以及Baby-AGI项目。
核心思想是先制定一个多步骤计划,然后逐项执行。完成一项特定任务后,您可以重新审视计划并根据需要进行修改。
一般的计算图如下所示
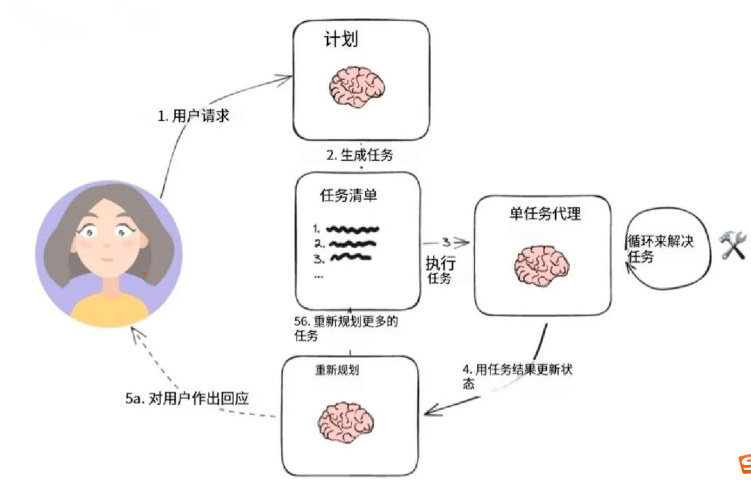
这与典型的 ReAct 风格的代理进行了比较,在该代理中,您一次思考一步。这种"计划并执行"风格代理的优势在于
-
明确的长期规划(即使是真正强大的 LLM 也可能难以做到)
-
能够使用更小/更弱的模型来执行步骤,仅在规划步骤中使用更大/更好的模型
以下演练演示了如何在 LangGraph 中实现这一点。生成的代理将留下类似以下示例的轨迹:(链接)
2. 设置
首先,我们需要安装所需的软件包。
python
%pip install --quiet -U langgraph langchain-community langchain-openai tavi-ly-python接下来,我们需要为 OpenAI(我们将使用的 LLM)和 TaviLy(我们将使用的搜索工具)设置 API 密钥。
可以选择设置 LangSmith 跟踪的 API 密钥,这将为我们提供一流的可观察性。
python
setx TAVILY_API_KEY ""
# Optional, add tracing in LangSmith
setx LANGCHAIN_TRACING_V2 "true"
setx LANGCHAIN_API_KEY ""3. 完整代码
python
# 导入tavily搜索api库
from langchain_community.tools.tavily_search import TavilySearchResults
# 创建TavilySearchResults工具,设置最大结果数为1
tools = [TavilySearchResults(max_results=1)]
# 导入langchain的hub库和ChatOpenAI类,以及asyncio库和create_react------agent函数
from langchain import hub
from langchain_openai import ChatOpenAI
# 导入执行异步调用所需的库
import asyncio
from langgraph.prebuilt import create_react_agent
# 从LangChain的Hub中获取prompt模板,可以进行修改
prompt = hub.pull("wfh/react-agent-executor")
prompt.pretty_print()
# 选择驱动代理的LLM,使用OpenAI的ChatGPT-4o模型
llm = ChatOpenAI(model="gpt-4o")
# 创建一个REACT代理执行器,使用指定的LLM和工具,并应用从Hub中获取的prompt
agent_executor = create_react_agent(llm, tools, messages_modifier=prompt)
# 调用代理执行器,询问"谁是美国公开赛的冠军"
#agent_executor.invoke({"messages": [{"user", "谁是美国公开赛的获胜者"}]})
import operator
from typing import Annotated, List, Tuple, TypedDict
# 定义一个TypedDict类PLInExecute,用于存储输入、计划、过去的步骤和响应
class PlanExecute(TypedDict):
input: str
plan: List[str]
past_steps: Annotated[List[Tuple], operator.add]
response: str
from pydantic import BaseModel, Field
# 定义一个Plan模型类,用于描述未来要执行的计划
2 usages
class Plan(BaseModel):
"""未来要执行的计划"""
steps: List[str] = Field(
description="需要执行的不同步骤,应该按顺序排列"
)
from langchain_core.prompts import ChatPromptTemplate
# 创建一个计划生成的提示模板
planner_prompt = ChatPromptTemplate.from_messages([
[
("system",
"对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案。不要添加任何多余的步骤。最后一步的结果应该是最终答案。确保每一步都有所有必要的信息 - 不要跳过步骤。",
),
("placeholder", "{messages}")
]
])
# 使用指定的提示模板创建一个计划生成器,使用OpenAI的ChatGPT-4o模型
planner = planner_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Plan)
# 调用计划生成器,询问"当前澳大利亚公开赛冠军的家乡是哪里?"
#planner.invoke({"messages": [{"user", "现任澳网冠军的家乡是哪里?"}]})
from typing import Union
# 定义一个响应模型类,用于描述用户的响应
2 usages
class Response(BaseModel):
"""用户响应"""
response: str
# 定义一个行为模型类,用于描述要执行的行为。该类继承自 BaseModel
# 类中有一个属性 action,类型为 Union[Response, Plan],表示可以是 Response 或 Plan 类型。
# action 属性的描述为:要执行的行为。如果要回应用户,使用 Response;如果需要进一步使用工具获取答案,使用 Plan。
class Act(BaseModel):
"""要执行的行为"""
action: Union[Response, Plan] = Field(
description="要执行的行为。如果要回应用户,使用Response。如果需要进一步使用工具获取答案,使用Plan。"
# 创建一个重新计划的提示模板
replanner_prompt = ChatGPTemplate.from_template(
"""对于给定的目标,提出一个简单的逐步计划。这个计划应该包含独立的任务,如果正确执行将得出正确的答案。不要添加任何多余的步骤。最后一步是:
你的目标是:
{input}
你的原计划是:
{plan}
你目前已经完成的步骤是:
{past_steps}
相应地更新你的计划。如果不需要更多步骤并且可以返回给用户,那么就这样回应。如果需要,填写计划。只添加仍然需要完成的步骤。不要返回已完成的步
}
""")
# 使用指定的提示模板创建一个重新计划生成器,使用OpenAI的ChatGPT-4o模型
replanner = replanner_prompt | ChatGPTAI(
model="gpt-4o", temperature=0
).with_structured_output(Act)
from typing import Literal
# 定义一个异步主函数
async def main():
# 定义一个异步函数,用于生成计划步骤
async def plan_step(state: PlanExecute):
plan = await planner.ainvoke({"messages": [("user", state["input"])]})
return {"plan": plan.steps}
# 定义一个异步函数,用于执行步骤
async def execute_step(state: PlanExecute):
plan = state["plan"]
plan_str = "\n".join(f"{i + 1}. {step}" for i, step in enumerate(plan))
task = plan[0]
task_formatted = f"""对于以下计划:
{plan_str}\n\n你的任务是执行第1步,{task}。"""
agent_response = await agent_executor.ainvoke(
{"messages": [("user", task_formatted)]}
)
return {
"past_steps": state["past_steps"] + [(task, agent_response["messages"][-1].content)],
}
# 定义一个异步函数,用于重新计划步骤
async def replan_step(state: PlanExecute):
output = await replanner.ainvoke(state)
if isinstance(output.action, Response):
return {"response": output.action.response}
else:
return {"plan": output.action.steps}
# 定义一个函数,用于判断是否结束
def should_end(state: PlanExecute) -> Literal["agent", "_end_"]:
if "response" in state and state["response"]:
return "_end_"
else:
return "agent"
from langgraph.graph import StateGraph, START
# 创建一个状态图,初始化PlanExecute
workflow = StateGraph(PlanExecute)
# 添加计划节点
workflow.add_node("planner", plan_step)
# 添加执行步骤节点
workflow.add_node("agent", execute_step)
# 添加重新计划节点
workflow.add_node("replan", replan_step)
# 设置从开始到计划节点的边
workflow.add_edge(start_key="agent", end_key="replan")
# 添加条件边,用于判断下一步操作
workflow.add_conditional_edges(
source="replan",
# 传入判断函数,确定下一个节点
path_map=should_end,
)
# 编译状态图,生成LangChain可运行对象
app = workflow.compile()
# 将生成的图片保存到文件
graph_png = app.get_graph().draw_mermaid_png()
with open("agent_workflow.png", "wb") as f:
f.write(graph_png)
# 设置配置,递归限制为50
config = {"recursion_limit": 50}
# 输入数据
inputs = {"input": "2024年巴黎奥运会100米自由泳决赛冠军的家乡是哪里?请用中文答复"}
# 异步执行状态图,输出结果
async for event in app.astream(inputs, config=config):
for k, v in event.items():
if k != "_end__":
print(v)
# 运行异步函数
asyncio.run(main())总结
参考:B站