传统的视觉-语言模型 (VLM) 在输入到 LLM 时,总是以刚性的光栅扫描顺序(从左上到右下)处理视觉 tokens,并采用固定的位置编码。然而,这与人类的视觉感知相悖,人类的视觉感知遵循灵活但语义连贯的扫描模式,这种模式由内在的逻辑结构驱动。特别是对于具有复杂布局的图像,人类视觉表现出因果相关的顺序处理。受这种认知机制的启发,DeepEncoder V2 的设计旨在赋予编码器因果推理能力,使其能够在基于 LLM 的内容解释之前智能地重新排序视觉 tokens。这项工作探索了一种新的范式:是否可以通过两个级联的 1D 因果推理结构有效地实现 2D 图像理解,从而提供一种新的架构方法,并有可能实现真正的 2D 推理。代码和模型权重可在 http://github.com/deepseek-ai/DeepSeek-OCR-2 公开访问
DeepSeek-OCR 2: Visual Causal Flow 论文大纲
I. 引言 (Introduction)
- 背景:
- 人类视觉系统遵循语义驱动的因果扫描模式,与传统VLM(Vision-Language Models)的固定栅格扫描顺序形成对比。
- 传统VLM将2D图像扁平化为1D序列,引入了不必要的归纳偏差,忽略了语义关系。
- 研究目标: 探索一种新型编码器------DeepEncoder V2,使其能够根据图像语义动态重排序视觉tokens,以实现更类人化的视觉编码。
- 主要贡献:
- 提出DeepEncoder V2: 用紧凑型LLM架构替代CLIP组件,引入可学习的因果流查询(causal flow tokens)和定制注意力掩码,实现视觉因果流。
- 发布DeepSeek-OCR 2: 在保持DeepSeek-OCR图像压缩比和解码效率的同时,显著提升性能,并作为研究探索和高质量训练数据生成工具。
- 验证LLM架构作为VLM编码器的潜力: 为统一全模态编码(omni-modal encoding)提供可行路径。
II. 相关工作 (Related Works)
- 解码器中的并行查询 (Parallelized Queries in Decoder):
- 以DETR为代表,通过预设并行可学习查询处理token,打破了传统检测范式中串行解码的效率限制。
- 投影器中的并行查询 (Parallelized Queries in Projector):
- 以BLIP-2中的Q-former为例,利用可学习查询进行视觉token压缩,将视觉token与LLM嵌入空间对齐。
- 基于LLM的多模态初始化 (LLM-based Multimodal Initialization):
- LLM预训练权重在多模态模型初始化中的有效性,例如Fuyu和Chameleon。
III. 方法论 (Methodology)
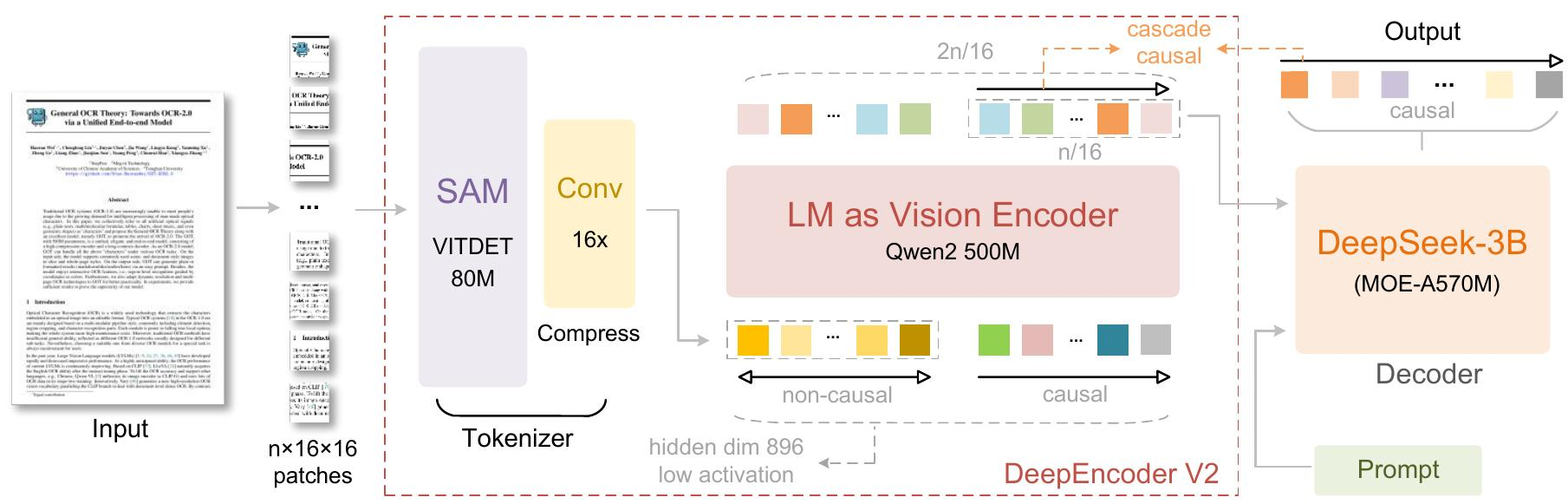
- 整体架构 (Architecture):
- DeepSeek-OCR 2继承DeepSeek-OCR的编码器-解码器架构。
- 核心区别: 编码器升级为DeepEncoder V2,引入因果推理能力。
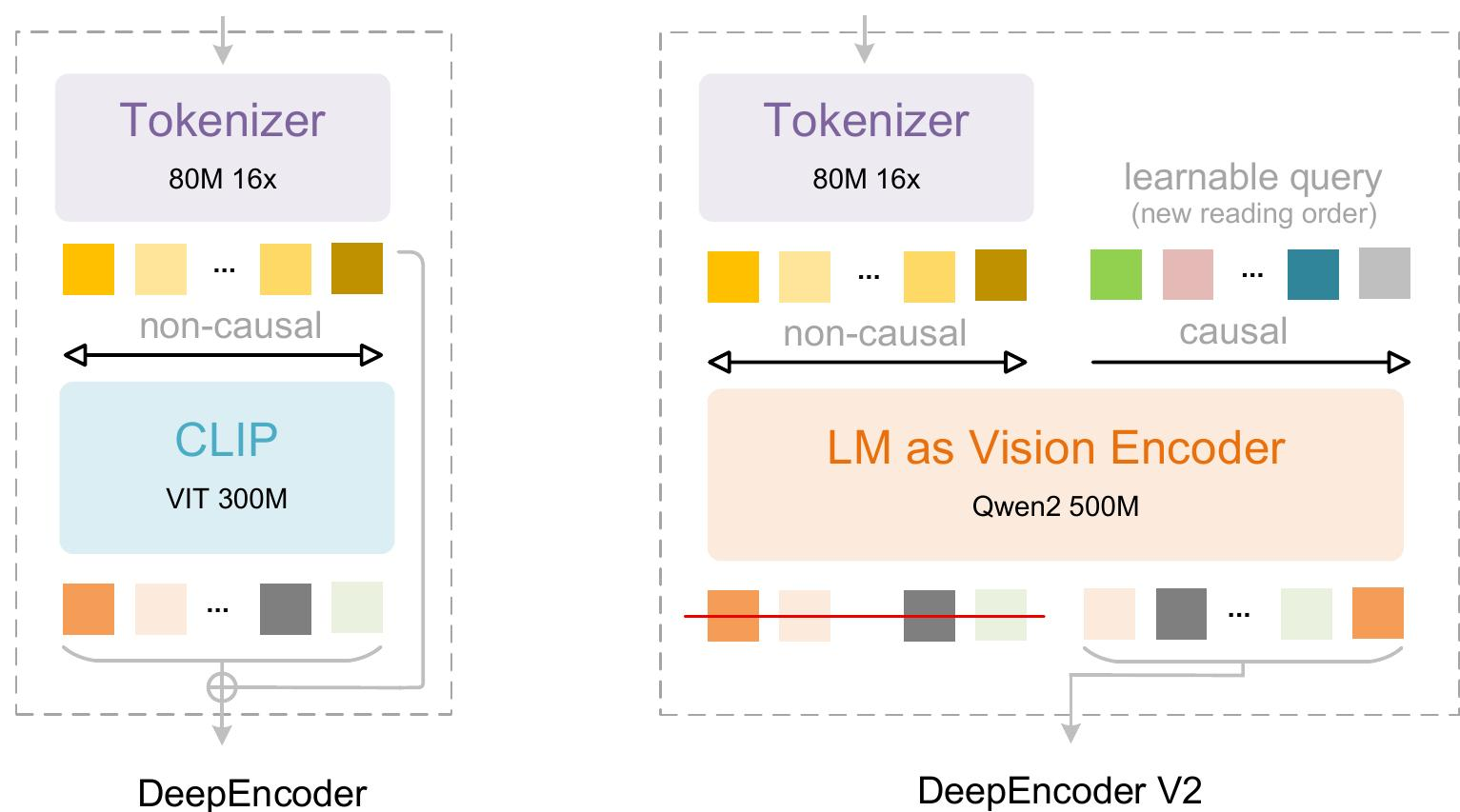
- DeepEncoder V2 详解:
- 愿景: 解决传统编码器将2D图像转换为1D序列时引入的僵硬排序偏差,该偏差与非线性视觉阅读模式不符。
- 视觉分词器 (Vision Tokenizer):
- 采用80M参数的SAM-base结合两个卷积层,将图像压缩为视觉tokens(16倍压缩)。
- 参数量与LLM中用于文本输入嵌入的参数量(~100M)相当。
- 语言模型作为视觉编码器 (Language model as vision encoder):
- DeepEncoder V2将DeepEncoder中的CLIP ViT替换为LLM风格架构 ,采用双流注意力机制。
- 视觉tokens: 使用双向注意力,保持CLIP的全局建模能力。
- 因果流查询 (Causal flow query):
- 新增可学习查询,附加在视觉tokens之后,采用因果注意力。
- 每个查询可关注所有视觉tokens和其之前的查询。
- 通过维护查询与视觉tokens数量相等,实现语义排序和视觉特征提炼。
- 只有因果查询的输出被送入LLM解码器。
- 两阶段级联因果推理: 编码器通过可学习查询对视觉tokens进行语义重排序,LLM解码器对重排序后的序列执行自回归推理。
- 实例化: 使用Qwen2-0.5B(500M参数)。
- 注意力掩码 (Attention mask):
- 由两个独立区域组成:左侧对原始视觉tokens应用双向注意力 (ViT风格),右侧对因果流tokens应用因果注意力(LLM解码器风格的下三角掩码)。
- 数学表示:
M = [ [1mxm, 0mxn], [1nxm, LowerTri(n)] ]。
- DeepSeek-MoE 解码器 (DeepSeek-MoE Decoder):
- DeepSeek-OCR 2主要关注编码器改进,解码器沿用DeepSeek-OCR的3B参数MoE结构。
- 前向传播公式:
O = D(πo(T^L(Ɛ(I) ⊕ Q0; M)))
IV. 实验设置 (Experimental Settings)
- 数据引擎 (Data Engine):
- 沿用DeepSeek-OCR的数据源,OCR数据占80%。
- 两项修改:OCR 1.0数据采样策略更平衡,布局检测标签优化。
- 训练流程 (Training Pipelines):
- 阶段1:编码器预训练 - 视觉分词器和LLM风格编码器学习特征提取、token压缩和token重排序。
- 阶段2:查询增强 - 冻结视觉分词器,联合优化LLM编码器和解码器,增强查询表示和token重排序能力。
- 阶段3:LLM继续训练 - 冻结DeepEncoder V2所有参数,仅更新DeepSeek-LLM参数,加速训练并提升LLM对重排序视觉tokens的理解。
V. 评估 (Evaluation)
- 基准: OmniDocBench v1.5,包含1,355页文档,涵盖9大类别。
- 主要结果 (Main Results):
- DeepSeek-OCR 2在OmniDocBench v1.5上达到91.09%的先进性能,V-tokenmax最低(1120)。
- 相比DeepSeek-OCR基线,性能提升3.73%。
- 阅读顺序(R-order)的编辑距离(ED)显著下降(从0.085降至0.057),表明DeepEncoder V2能有效选择和排列视觉tokens。
- 在相同视觉token预算下,相比Gemini-3 Pro,DeepSeek-OCR 2在文档解析方面ED更低(0.100 vs 0.115)。
- 改进空间 (Improvement Headroom):
- DeepSeek-OCR 2在大多数情况下优于DeepSeek-OCR,但在某些文档类型(如报纸)上仍有提升空间。
- 主要原因:视觉token上限较低,报纸训练数据不足。
- 实际应用就绪度 (Practical Readiness):
- 重复率显著降低(在线用户日志图像从6.25%降至4.17%,PDF数据生产从3.69%降至2.88%),验证了其逻辑视觉理解能力。
VI. 讨论与未来工作 (Discussion and Future Works)
- 迈向真正的2D推理 (Towards Genuine 2D Reasoning):
- LLM风格编码器和LLM解码器的两阶段1D因果推理级联有望实现真正的2D推理。
- 编码器执行阅读逻辑推理(通过查询tokens重排序视觉信息),解码器执行视觉任务推理。
- 未来需要更长的因果流tokens以支持多次重检和多跳重排序。
- 迈向原生多模态 (Towards Native Multimodality):
- DeepEncoder V2架构有望发展为统一的全模态编码器,通过模态特定可学习查询处理多种模态(图像、音频、文本)。
- DeepSeek-OCR 2的LLM风格编码器架构是迈向原生多模态的关键一步。
VII. 结论 (Conclusion)
- DeepSeek-OCR 2是DeepSeek-OCR的重大升级,通过DeepEncoder V2引入双向和因果注意力机制,有效地建模了文档阅读中的因果视觉流,显著提升了视觉阅读逻辑。
- 光学文本阅读是LLM时代最实用的视觉任务之一,但仍是更广泛视觉理解领域的一小部分。
- 展望未来,将继续优化和调整该架构以适应更多样化的场景,旨在实现更全面的多模态智能。
细节学习

代码学习
1、deepseek_ocr2.py 文件核心介绍
(1)分割符
self.view_seperator = nn.Parameter(torch.randn(n_embed) * embed_std)
self.view_seperator = nn.Parameter(...):
nn.Parameter:将普通张量标记为模型可训练参数(会被 PyTorch 的优化器更新);torch.randn(n_embed):生成 1280 维的标准正态分布随机数;* embed_std:用之前计算的标准差缩放随机数,符合 Xavier 初始化规则。
该参数最终会在 _pixel_values_to_embedding 方法中被拼接进视觉特征序列(torch.cat([local_features, global_features, self.view_seperator[None, :]], dim=0)),是 "全局 + 局部" 多视图特征融合的关键标识。
(2)完整前向结构
DeepseekOCR2ForCausalLM,几个重要模块
self.sam_model = build_sam_vit_b()
self.qwen2_model = build_qwen2_decoder_as_encoder()
self.view_seperator = nn.Parameter(torch.randn(n_embed) * embed_std)
self.language_model = init_vllm_registered_model(
vllm_config=vllm_config,
hf_config=self.text_config,
prefix=maybe_prefix(prefix, "language"),
architectures=architectures,
)
对应的为大语言模型结构architectures = "DeepseekForCausalLM"可配置
self.projector = MlpProjector(Dict(projector_type="linear", input_dim=896, n_embed=n_embed)) #将qwen2_model 转为大语言模型的embedding
forward
def forward(self,
input_ids: torch.Tensor,
positions: torch.Tensor,
intermediate_tensors: Optional[IntermediateTensors] = None,
inputs_embeds: Optional[torch.Tensor] = None,
**kwargs: object):
if intermediate_tensors is not None:
inputs_embeds = None
# NOTE: In v1, inputs_embeds is always generated at model runner, this
# condition is for v0 compatibility
elif inputs_embeds is None:
vision_embeddings = self.get_multimodal_embeddings(**kwargs)
inputs_embeds = self.get_input_embeddings(input_ids,
vision_embeddings)
input_ids = None
hidden_states = self.language_model(input_ids,
positions,
intermediate_tensors,
inputs_embeds=inputs_embeds)
return hidden_states(1)第一次推理使用inputs_emeds,否则使用input_ids(新生成的)和intermediate_tensors
(2)get_input_embeddings实现了文本和视觉embedding的合并,调用vllm的通用能力
get_multimodal_embeddings:重点调用了_pixel_values_to_embedding进行处理:
(1)大图需要分块,小图不需要。大图分块后需要融合全局特征和局部特征,sam_model和qwen2_model都执行了两次,最后进行拼接融合。小图直接使用全局特征
(2)拼接后使用project输出
# 初始化存储批次内所有图像视觉嵌入的列表
images_in_this_batch = []
# 推理阶段禁用梯度计算,提升效率+降低显存占用
with torch.no_grad():
# 遍历批次内的每张图像(jdx为图像索引)
for jdx in range(images_spatial_crop.size(0)):
# 提取当前图像的局部裁剪块(batch_size固定为1,取第0维),转bfloat16降低显存
patches = images_crop[jdx][0].to(torch.bfloat16)
# 提取当前图像的全局视图
image_ori = pixel_values[jdx]
# 提取当前图像的裁剪瓦片数量(宽/高方向)
crop_shape = images_spatial_crop[jdx][0]
# ========== 1. 有局部裁剪块(大图分块)的场景 ==========
if torch.sum(patches).item() != 0: # patches非空=存在局部裁剪
# 步骤1:SAM模型提取局部裁剪块的细节特征
local_features_1 = self.sam_model(patches)
# 步骤2:Qwen2解码器改造的编码器,增强局部特征的语义表征
local_features_2 = self.qwen2_model(local_features_1)
# 步骤3:投影层将视觉特征(896维)映射到语言模型维度(1280维)
local_features = self.projector(local_features_2)
# 同理处理全局视图:SAM→Qwen2→投影层,得到全局特征
global_features_1 = self.sam_model(image_ori)
global_features_2 = self.qwen2_model(global_features_1)
global_features = self.projector(global_features_2)
# 调试:打印特征维度(若PRINT_NUM_VIS_TOKENS=True)
if PRINT_NUM_VIS_TOKENS:
print('=====================')
print('BASE: ', global_features.shape) # 全局特征维度
print('PATCHES: ', local_features.shape) # 局部特征维度
print('=====================')
# 维度重塑:将二维特征展平为一维序列(适配语言模型输入格式)
global_features = global_features.view(-1, self.projector.n_embed)
local_features = local_features.view(-1, self.projector.n_embed)
# 拼接:局部特征 → 全局特征 → 视图分隔符(可学习的特殊嵌入)
global_local_features = torch.cat([
local_features,
global_features,
self.view_seperator[None, :] # 分隔符token,区分全局/局部视图
], dim=0)
# ========== 2. 无局部裁剪块(小图,无需分块)的场景 ==========
else:
# 仅处理全局视图:SAM→Qwen2→投影层
global_features_1 = self.sam_model(image_ori)
global_features_2 = self.qwen2_model(global_features_1)
global_features = self.projector(global_features_2)
if PRINT_NUM_VIS_TOKENS:
print('=====================')
print('BASE: ', global_features.shape)
print('NO PATCHES')
print('=====================')
# 维度重塑+拼接:全局特征 → 视图分隔符
global_features = global_features.view(-1, self.projector.n_embed)
global_local_features = torch.cat([
global_features,
self.view_seperator[None, :]
], dim=0)
# 将当前图像的融合特征加入批次列表
images_in_this_batch.append(global_local_features)
# 返回批次内所有图像的视觉嵌入列表
return images_in_this_batch(3)sam_vary_sdpa.py# 文件整体介绍
- SDPA 适配:使用 PyTorch 原生缩放点积注意力,兼顾效率与稳定性,适合批量 OCR 推理;
- 动态位置编码:绝对 / 相对位置编码均支持插值缩放,适配不同分辨率的输入图像;
- 分层特征处理:neck 层融合 + 逐步下采样,既保留字符细节,又提升特征维度适配语言模型;
- 轻量化设计:窗口注意力将注意力计算复杂度从 O (N²) 降至 O (N²/W)(W 为窗口尺寸),降低显存占用。
通过改造 SAM 的 ViT 编码器,既保留了 SAM 对图像细节的捕捉能力
- 核心目标:将 1024×1024 输入图像通过 ViT 提取特征,经卷积下采样和特征融合后输出 896 维视觉特征,兼顾字符细节(SAM 优势)和语义表征(适配语言模型);
- 技术基底:基于 SAM 的 ViT-B 架构改造,优化了注意力机制、位置编码和特征维度,专门适配 OCR 任务对字符位置 / 细节的敏感性;
- 输入输出 :
- 输入:
[B, 3, 1024, 1024]维度的 3 通道图像张量; - 输出:
[B, 896, 64, 64]维度的视觉特征张量(经两次下采样后),展平后可直接输入 Qwen2 模型增强。
- 输入:
(4)qwen2_d2e.py# 文件整体介绍。因果和非因果是如何设计的,是否有自定义注意力?
该文件 qwen2_d2e.py 是 DeepSeek-OCR-2 项目 中核心的跨模态编码模块,核心目标是将 Qwen2 大语言模型的解码器改造为「适配 OCR 任务的编码器」------ 通过定制化注意力掩码逻辑,实现「视觉特征非因果注意力 + 文本 / 查询特征因果注意力」的混合机制,兼顾 OCR 中视觉特征的全局交互需求和语言特征的自回归生成约束。
文件整体围绕 "解码器转编码器" 展开,核心包含 3 个关键组件,层级关系为:build_qwen2_decoder_as_encoder(工程化构建)→ Qwen2Decoder2Encoder(编码器封装)→ CustomQwen2Decoder(核心改造的 Qwen2 解码器)。
一、核心类与功能拆解
| 类 / 函数 | 核心作用 |
|---|---|
CustomQwen2Decoder |
核心改造类:封装 Qwen2 原生模型,重写注意力掩码逻辑,实现因果 / 非因果混合注意力 |
Qwen2Decoder2Encoder |
编码器封装:新增视觉查询嵌入层,拼接视觉特征与查询特征,适配 OCR 输入格式 |
build_qwen2_decoder_as_encoder |
工程化构建函数:支持加载预训练权重,对外提供统一的编码器构建接口 |
二、因果(Causal)与非因果(Non-Causal)注意力的设计逻辑
核心设计依托 token_type_ids 区分 token 类型(0=非因果视觉token、1=因果文本/查询token),通过重写注意力掩码生成逻辑实现混合注意力,具体步骤如下:
1. 核心约定:token_type_ids 定义
| token_type_ids 值 | 对应 token 类型 | 注意力规则 |
|---|---|---|
| 0 | 视觉特征 token | 非因果:全局互相可见 |
| 1 | 文本 / 查询特征 token | 因果:仅可见自身及之前的 token |
2. 关键实现步骤(从输入到掩码生成)
步骤 1:传递 token_type_ids(暂存)
在 CustomQwen2ModelInner(自定义 Qwen2 模型子类)的 forward 方法中,将输入的 token_type_ids 暂存为实例变量 _current_token_type_ids,供后续掩码生成时调用:
python
运行
self._current_token_type_ids = token_type_ids # 暂存token类型标识步骤 2:重写掩码更新入口
重写 Qwen2 原生的 _update_causal_mask 方法(原生仅生成纯因果掩码),替换为调用自定义的 _create_custom_4d_mask 生成混合掩码:
步骤 3:核心:自定义 4D 掩码生成(_create_custom_4d_mask)
这是因果 / 非因果的核心实现,逐 batch 构建掩码矩阵(seq_len × seq_len),核心逻辑:
# 初始化全负无穷掩码(负无穷表示该位置注意力被屏蔽)
mask = torch.full((seq_len, seq_len), fill_value=min_dtype, dtype=dtype, device=device)
# 分离视觉/文本token位置
image_positions = (type_ids == 0).nonzero(as_tuple=True)[0] # 非因果token位置
text_positions = (type_ids == 1).nonzero(as_tuple=True)[0] # 因果token位置
# 1. 非因果:视觉token之间互相可见(全局注意力)
if len(image_positions) > 0:
mask[image_positions[:, None], image_positions] = 0.0 # 0表示允许注意力
# 2. 因果:文本token的注意力约束
for i, text_pos in enumerate(text_positions):
# 文本token可看到所有视觉token(跨模态关注)
if len(image_positions) > 0:
mask[text_pos, image_positions] = 0.0
# 文本token仅能看到自身及之前的文本token(时序因果)
mask[text_pos, text_positions[:i+1]] = 0.0- 非因果逻辑:视觉 token 所在的行和列全部置 0,意味着每个视觉 token 能关注到所有其他视觉 token(全局交互,适配图像特征的空间关联性);
- 因果逻辑:文本 token 仅能关注「所有视觉 token + 自身及之前的文本 token」,符合语言模型自回归生成的时序约束;
- 掩码维度 :最终拼接为 4D 掩码(
batch_size × 1 × seq_len × seq_len),适配 Qwen2 多头注意力的输入格式。
3. 设计意图
OCR 任务中:
- 视觉特征(图像 token)需要全局交互(非因果)才能完整捕捉字符的空间位置、笔画关联等信息;
- 文本 / 查询特征(语言 token)需要因果约束,保证生成文本的时序合理性(符合自回归语言模型的特性)。
四、补充:编码器封装层(Qwen2Decoder2Encoder)的适配逻辑
为了让改造后的解码器适配 OCR 视觉特征输入,Qwen2Decoder2Encoder 新增了关键适配逻辑:
- 视觉查询嵌入 :定义
query_768/query_1024两个嵌入层,适配 144/256 两种数量的视觉查询 token; - 特征拼接 :将输入的视觉特征
x与查询嵌入拼接,生成x_combined(视觉 token + 查询 token); - token_type_ids 自动生成:拼接后的序列前半部分为 0(视觉,非因果)、后半部分为 1(查询,因果);
- 输出裁剪 :仅保留查询 token 对应的输出(
y[:, n_query:, :]),作为编码器的最终输出(因果流查询特征)。
(5)查询嵌入的概念和实现
介绍下这里面的因果和非因果注意力,这两部分的输入分别是什么,调用这个模型的时候需多次forward得到结果吗?
# 非因果输入:图像特征展平(token_type_ids=0)
x = x.flatten(2).transpose(1, 2) # [bs, hidden_dim, H, W] → [bs, n_query, 896]
# 因果输入:查询嵌入(token_type_ids=1)
batch_query_imgs = param_img.unsqueeze(0).expand(bs, -1, -1)
# 拼接为完整输入
x_combined = torch.cat([x, batch_query_imgs], dim=1) # [bs, 2*n_query, 896]
# 对应token_type_ids:前半段0(非因果)、后半段1(因果)
token_type_ids = torch.cat([torch.zeros(bs, n_query), torch.ones(bs, n_query)], dim=1)常规场景下无需多次调用 forward,单次 forward 即可完成推理,核心依据:
1. 代码设计层面
- 模型是端到端一体化设计 :
Qwen2Decoder2Encoder.forward接收图像特征后,内部完成 "特征展平→查询嵌入拼接→token_type_ids 生成→注意力计算→结果输出" 的全流程;
划线位置,这个作用是什么,为什么把它叫做查询嵌入,有什么意义
self.query_768 = nn.Embedding(144, hidden_dimension)
self.query_1024 = nn.Embedding(256, hidden_dimension)先明确命名来源,再拆解作用和意义:
二、"查询嵌入(Query Embedding)" 的命名原因
-
注意力机制的底层逻辑:Transformer 的核心是「Query(查询)-Key(键)-Value(值)」注意力范式:
- Query:"我要找什么"(主动查询的向量);
- Key/Value:"我有什么"(被查询的向量)。这里的
query_768/1024是为视觉特征生成 "主动查询向量",用于和视觉特征做注意力交互,因此命名为 "查询嵌入"。
-
后缀 768/1024 的含义 :后缀对应 OCR 场景中常见的图像输入分辨率(如 768×768、1024×1024);而
nn.Embedding的第一个参数(144=12×12、256=16×16)是分辨率下视觉特征展平后的 token 数量(H×W)------ 本质是 "适配不同分辨率的查询向量",因此用分辨率作为后缀区分。
三、查询嵌入的核心作用(结合代码逻辑拆解)
先梳理Qwen2Decoder2Encoder的 forward 流程,再看查询嵌入的核心作用:
预览
查看代码
生成失败,请重试
graph TD
A[输入视觉特征x: [batch, 896, 16, 16]] --> B[展平为: [batch, 256, 896]]
B --> C{判断n_query长度}
C -->|144| D[用query_768生成查询向量]
C -->|256| E[用query_1024生成查询向量]
D/E --> F[扩展为batch维度: [batch, 256, 896]]
F --> G[拼接视觉特征+查询向量: [batch, 512, 896]]
G --> H[token_type_ids标记: 视觉=0(非因果),查询=1(因果)]
H --> I[送入改造后的Qwen2解码器]
I --> J[提取查询部分输出作为最终编码结果]具体作用分 4 点:
1. 视觉特征的 "空间锚点"
视觉特征是二维空间特征(如 16×16),展平后是无序的一维序列;查询嵌入为每个空间位置的视觉 token 提供可学习的固定查询向量,作为注意力交互的 "锚点",让模型能精准对齐图像的空间位置特征(比如区分 "第一行第一个字" 和 "第二行第二个字")。
2. 实现 "非因果 + 因果" 注意力的核心桥梁
DeepSeek-OCR2 改造 Qwen2 解码器的核心是「视觉非因果注意力 + 文本因果注意力」:
- 视觉特征部分(token_type_ids=0):做非因果注意力 (全可见,对应代码中
mask[image_positions[:, None], image_positions] = 0.0),让模型全局看图像; - 查询嵌入部分(token_type_ids=1):做因果注意力 (只能看前面的 token,对应
mask[text_pos, text_positions[:i+1]] = 0.0),同时能关注所有视觉特征(mask[text_pos, image_positions] = 0.0)。查询嵌入是 "因果查询端",连接 "全局视觉特征" 和 "顺序文本理解",模拟人类 "先看全图、再按顺序读文字" 的视觉逻辑。
3. 适配不同分辨率的视觉输入
OCR 场景中图像分辨率多样(如 768×768、1024×1024),对应的视觉特征展平长度不同(12×12=144、16×16=256);query_768/1024分别适配这两种长度,保证不同分辨率输入下都有匹配的查询向量,提升模型的多分辨率鲁棒性。
4. 维度对齐与解码器兼容
查询嵌入的维度(hidden_dimension)和视觉特征、Qwen2 解码器的隐藏层维度完全一致,拼接后能无缝送入解码器做注意力计算,避免维度不匹配问题,是 "视觉特征→解码器" 的关键适配层。
四、查询嵌入的设计意义(结合 DeepSeek-OCR2 的核心理念)
1. 实现 "Decoder→Encoder" 的改造(适配 OCR 场景)
Qwen2 原生是解码器(Decoder) ,天然做因果注意力(文本生成);但 OCR 需要编码器(Encoder) 做视觉特征的全局建模。查询嵌入是核心改造点:通过 "视觉非因果 + 查询因果" 的组合,把 Decoder 改造成适配 OCR 的 Encoder,既保留 Qwen2 的文本建模能力,又具备视觉全局编码能力。
2. 落地 "视觉因果流(Visual Causal Flow)" 核心设计
DeepSeek-OCR2 的核心卖点是「类人视觉编码」------ 人类阅读时先全局看图像(非因果),再按顺序理解文本(因果);查询嵌入模拟 "按顺序查询图像特征" 的过程,贴合人类阅读的因果逻辑,大幅提升复杂排版(多行、倾斜、图文混排)的 OCR 识别准确率。
3. 可学习的位置编码(替代传统静态编码)
相比 RoPE、Sinusoidal 等静态位置编码 ,查询嵌入是可学习的,能自适应不同图像的特征分布(比如模糊、低对比度、异形字体),提升模型对复杂场景的适配能力。
4. 提升推理效率
查询嵌入是预定义的可学习参数(仅 144/256 个 token),而非动态生成,能减少推理时的计算量;同时结合 vLLM 的高性能推理框架,进一步提升 OCR 的处理速度(尤其是 PDF / 长文本场景)。
总结
"查询嵌入" 命名源于 Transformer 的 QKV 注意力范式,核心作用是为视觉特征提供 "因果查询锚点",实现 "非因果视觉编码 + 因果文本理解" 的融合,是 DeepSeek-OCR2 将 Qwen2 解码器改造成适配 OCR 的编码器、落地 "视觉因果流" 核心设计的关键组件;后缀 768/1024 则是为了适配不同分辨率的图像输入,保证多场景的鲁棒性。