- 开篇先介绍自己的开源项目vibe-blog, 一个基于多 Agent 架构的 "长文专业博客"的创作助手,支持深度调研、智能配图、Mermaid 图表、代码集成等写作能力,简化写作的重复劳动, 让写作更有趣.
- 我基于它已经创作了一个面向大模型应用开发者的微调(Fine-tuning)技术全栈教程Hello-LLM-FineTuning, 40 万字,100+章配图.
- Vibe-Blog开源项目地址: https://github.com/datawhalechina/vibe-blog
- 感兴趣的同学可以了解下,如果该项目对你有用, 欢迎 star🌟 & fork🍴
前文: cola-DDD-skill让 AI 自动帮你遵循 COLA 架构规范来组织代码的技能包,支持 Python 和 Java。
🤔 你是否也有这样的困惑?
"新建了一个代码文件,应该放在哪个目录下呢?"
"整个项目的代码结构如何设计呢?"
"为什么我的项目越写越乱,最后自己都看不懂了?"
如果你在项目开发中------尤其是 Vibe Coding 时------没有建立起一套代码组织的最佳规范,很容易就会陷入:
- 📁 目录杂乱不堪,毫无结构可言
- 📦 代码堆积繁杂,想找个文件都费劲
- 🔧 难以维护,改一处崩十处
- 👥 协作困难,每个人都有自己的"风格"
💡 解决方案:COLA + cola-skill
如何将代码组织得井井有条呢? 优秀的前辈们已经设计好了一套通用的规范------COLA。
COLA (Clean Object-Oriented and Layered Architecture)是阿里巴巴出品的项目架构规范,在专业度上没得说。但实际怎么使用呢?
对于喜欢 Vibe Coding 的同学来说,其实无需感知复杂的架构设计细节。我将整个 COLA 架构规范转换成了 cola-skill 技能包 ,分成 Python 版 和 Java 版。
只需在支持 Skill 的 IDE(如 Claude Code、Windsurf)中加载该技能包,AI 就会自动帮你遵循 COLA 规范来组织代码!
| Skill | 描述 | 适用场景 |
|---|---|---|
| python-cola-skill | Python 版 COLA 架构指南 | Flask、FastAPI 项目 |
| java-cola-skill | Java 版 COLA 架构指南 | Spring Boot 项目 |
🎯 实践案例:vibe-blog 项目重构
以下是我基于 vibe-blog 的真实重构案例。
为什么要重构?
vibe-blog 前期开发处于探索阶段,90% 的代码都是通过 Vibe Coding 完成。由于模型生成代码的天性使然------只会新增和堆积,不会自己做重构和优化(没有项目的记忆, 上下文有限等等因素)。
迭代一段时间后,整个代码库越来越混乱,导致:
- 模型需要加载的无效上下文越来越多,速度慢
- 大量无效 Token 是一笔较大的开销
- 无意义的代码充斥上下文,导致生成的代码质量也很差
- 项目可维护性差, 作为一个项目的开发者我有时候对一些功能的实现也很困惑, 代码放哪儿了这是? 找到代码后, 尼玛,怎么放在这个模块下了.
为了扭转这一局面,我使用 python-cola-skill 对整个 vibe-blog 进行重构。
重构前:混乱的代码库
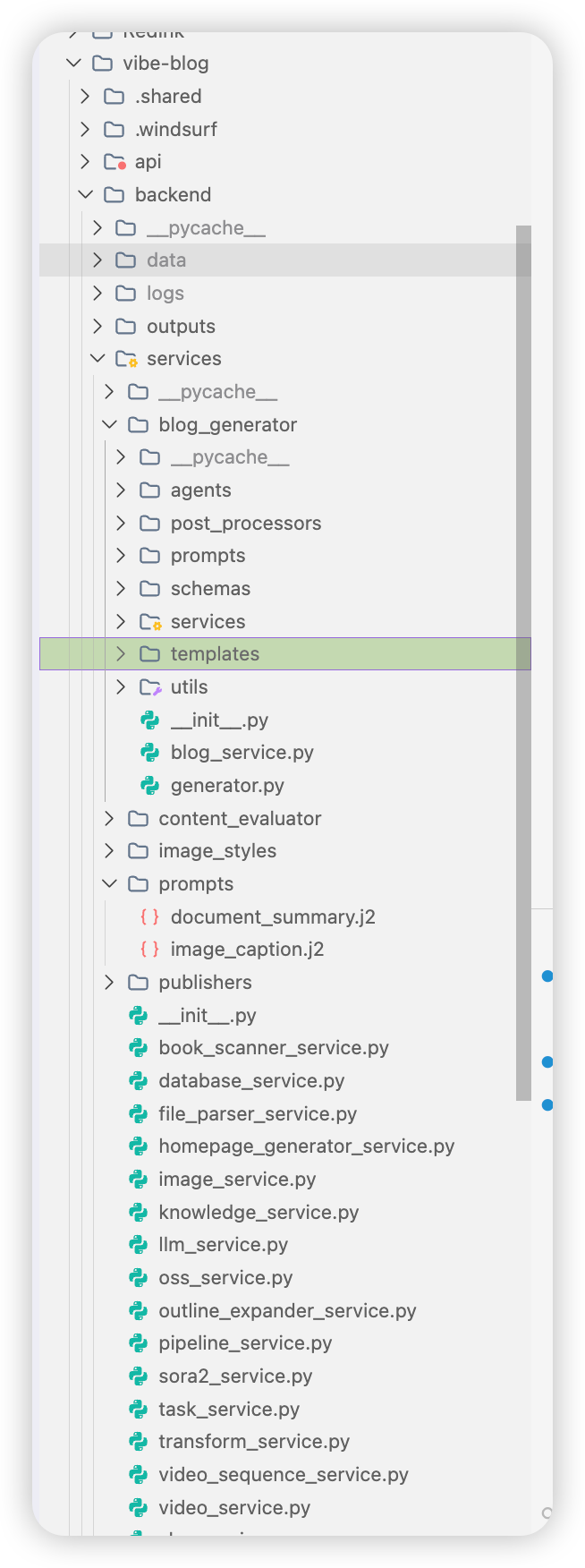
backend/
├── app.py # 😱 108KB 巨型文件(2695行)- 50+ 个路由全在这里
├── config.py # 7KB 配置文件
│
├── services/ # 扁平化服务层(15+ 个服务文件混在一起)
│ ├── blog_generator/ # 博客生成子模块
│ │ ├── agents/ # 9 个 Agent(planner, writer, artist...)
│ │ ├── templates/ # 36 个 Jinja2 模板(第1处模板目录)
│ │ ├── prompts/ # 第2处模板目录(重复)
│ │ ├── blog_service.py # 47KB
│ │ └── generator.py # 21KB
│ │
│ ├── prompts/ # 第3处模板目录(又重复)
│ ├── publishers/ # 发布器
│ ├── image_styles/ # 图片风格(第4处模板目录)
│ │
│ ├── database_service.py # 数据库操作
│ ├── xhs_service.py # 小红书服务
│ ├── book_scanner_service.py # 书籍扫描
│ ├── video_service.py # 视频服务
│ ├── llm_service.py # LLM 调用
│ └── ...其他服务
│
└── vibe_reviewer/ # 独立模块(第5处模板目录)核心痛点:
| 问题 | 描述 |
|---|---|
| 🔴 巨型 app.py | 2695 行,50+ 个路由全部堆在一个文件 |
| 🔴 扁平化服务层 | 所有服务平铺,职责不清、依赖混乱 |
| 🔴 模板目录分散 | templates/prompts 分散在 5 个不同位置 |
| 🔴 无分层架构 | 路由、业务逻辑、数据访问混在一起 |
重构后:清晰的 COLA 架构
backend/
├── api/ # 接口层(Controller)
│ ├── routes/
│ │ ├── blog_routes.py # 博客生成路由
│ │ ├── xhs_routes.py # 小红书路由
│ │ ├── book_routes.py # 书籍管理路由
│ │ └── ...(12 个路由模块)
│ └── middlewares/
│ └── error_handler.py # 统一错误处理
│
├── application/ # 应用层(用例编排)
│ ├── blog_application.py # 博客生成用例
│ ├── xhs_application.py # 小红书用例
│ └── ...(5 个用例服务)
│
├── domain/ # 领域层(核心业务)
│ ├── blog/
│ │ ├── entities.py # Blog, Section 实体
│ │ ├── value_objects.py # ArticleType 值对象
│ │ └── agents/ # 领域服务
│ ├── xhs/
│ └── book/
│
├── infrastructure/ # 基础设施层
│ ├── persistence/ # 持久化
│ ├── external/ # 外部服务(LLM、OSS)
│ └── prompts/ # 统一管理所有模板
│
└── app.py # 只做初始化和路由注册(~50行)重构效果
| 指标 | 重构前 | 重构后 |
|---|---|---|
| app.py 行数 | 2695 行 | ~50 行 |
| 路由模块 | 1 个巨型文件 | 12 个独立模块 |
| 模板目录 | 分散 5 处 | 统一 1 处 |
| 可测试性 | 难以单测 | 领域层可独立测试 |
🚀 快速开始
安装
方法一:Git 克隆(推荐)
bash
# 克隆整个仓库到 skills 目录
git clone https://github.com/lailoo/cola-DDD-skill.git ~/.claude/skills/cola-DDD-skill方法二:手动安装
- 下载本项目的 ZIP 文件
- 将 skill 文件夹复制到 Claude Code 的 skills 目录:
- macOS/Linux :
~/.claude/skills/
- macOS/Linux :
使用
当你提到以下关键词时,Skill 会被自动激活:
- 通用:COLA、DDD、分层架构、整洁架构、六边形架构、Gateway 模式
- Python:Python DDD、Flask 架构、FastAPI 架构
- Java:Java DDD、Spring Boot 架构、Maven 多模块
使用示例:
- 请帮我用 COLA 架构创建一个 Flask 用户管理系统
- 我有一个 Spring Boot 单体应用,请帮我按 COLA 架构重构📚 COLA 架构详解
如果你想深入了解 COLA 架构的设计思想,请继续阅读。
为什么需要分层?
你有没有见过那种"上帝类"?一个 XXXService.java 几千行代码,从接收请求、校验参数、调用数据库、发送消息、返回结果全都塞在一起。改一个小功能,得把整个文件翻一遍,生怕改错了哪里。
分层的本质是"分而治之"。
就像你不会让前端工程师去写 SQL,也不会让 DBA 去调 CSS 一样------每个人专注自己擅长的事情,效率最高。代码也是如此:
- 接口层专注于接收请求、返回响应
- 业务层专注于核心逻辑计算
- 数据层专注于存取数据
各司其职,互不干扰。改数据库不影响业务逻辑,换前端框架不用动后端代码。这背后体现了几个重要的设计原则:
- 封装:下层对上层屏蔽实现细节,上层不需要知道数据是存在 MySQL 还是 Redis
- 单一职责:每一层只做一件事,职责边界清晰
- 高内聚低耦合:相关代码聚在一起,不相关的代码彼此隔离
最终目的:从而避免不断堆出来大一统的屎山代码文件, 比如某个几千行的 service类.。
为什么需要 COLA?
分层架构的思想大家都懂,六边形、洋葱圈、整洁架构......概念一大堆。但问题是:具体怎么落地?
- 这个类应该放在哪个包下?
- Gateway 和 Repository 有什么区别?
- Command 和 Query 要不要分开?
- DTO、VO、DO、Entity 到底怎么转换?
很多架构文章讲完思想就结束了,留下一脸懵逼的你。
COLA 不一样。 它不仅告诉你"应该分层",还告诉你:
- 每一层叫什么名字
- 每一层放什么代码
- 类应该怎么命名
- 甚至提供了脚手架,一键生成标准目录结构
这就是 COLA 的价值------从理论到实践的最后一公里。
| 问题 | COLA 的解决方案 |
|---|---|
| 🔴 业务逻辑散落各处 | 领域层集中管理核心业务逻辑 |
| 🔴 技术实现与业务耦合 | 分层架构解耦,Infrastructure 实现 Domain 接口 |
| 🔴 代码难以测试 | 依赖倒置,Domain 层无外部依赖,易于单测 |
| 🔴 新人上手困难 | 标准化目录结构和命名规范 |
| 🔴 重构成本高 | 清晰的边界,改动影响范围可控 |
分层结构
COLA 将应用分为四层,每一层都有明确的职责定义:
| 层级 | 职责 | 大白话解释 |
|---|---|---|
| Adapter 层(适配层) | 负责对前端展示(web、wireless、wap)的路由和适配 | 就是 MVC 中的 Controller,接收请求、返回响应 |
| App 层(应用层) | 获取输入、组装上下文、参数校验、调用领域层做业务处理 | 编排调度员,不干活,只负责协调各方 |
| Domain 层(领域层) | 封装核心业务逻辑,提供业务实体和业务逻辑计算 | 真正干活的地方,不依赖任何其他层 |
| Infrastructure 层(基础设施层) | 处理技术细节(数据库 CRUD、搜索引擎、RPC 等) | 脏活累活都在这里,外部依赖通过 Gateway 转义后才能被上层使用 |
┌─────────────────────────────────────┐
Driving Adapter: │ 浏览器 │ 定时器 │ 消息队列 │
└─────────────────────────────────────┘
↓
VO ←─────────────── ┌─────────────────────────────────────┐
(View Object) │ Adapter 层 │
│ controller │ scheduler │ consumer │
└─────────────────────────────────────┘
↓
DTO ←────────────── ┌─────────────────────────────────────┐
(Data Transfer │ App 层 │
Object) │ service │ executor │
└─────────────────────────────────────┘
↓
Entity ←─────────── ┌─────────────────────────────────────┐
│ Domain 层 │
│ gateway │ model │ ability │
└─────────────────────────────────────┘
↑
DO ←─────────────── ┌─────────────────────────────────────┐
(Data Object) │ Infrastructure 层 │
│ gatewayImpl │ mapper │ config │
└─────────────────────────────────────┘
↓
Driven Adapter: │ DB │ Search │ RPC │💡 参考来源 :COLA 4.0:应用架构的最佳实践
依赖方向:为什么 Domain 层最特殊?
Adapter → App → Domain ← Infrastructure
↘ ↙
Client注意看箭头方向:
| 规则 | 解释 |
|---|---|
| Domain 层不依赖任何层 | 纯业务逻辑,可以独立测试,不需要启动数据库 |
| Infrastructure 依赖 Domain | Infrastructure 实现 Domain 定义的 Gateway 接口(依赖倒置) |
| Client 被所有层依赖 | Client 层定义了 DTO(数据传输对象),大家都要用 |
为什么这样设计?
假设有一天你要把 MySQL 换成 PostgreSQL:
- ❌ 传统做法:Domain 层直接调用 MySQL,换数据库要改业务代码
- ✅ COLA 做法:Domain 层只调用 Gateway 接口,换数据库只需要改 Infrastructure 层的实现
这就是依赖倒置的威力------核心业务不受技术选型的影响。
COLA 组件(可选增强)
COLA 还提供了一些开箱即用的组件,按需引入:
| 组件 | 用途 | 使用场景 |
|---|---|---|
| DTO | 统一的 Response、Command、Query 基类 | 所有项目 |
| Exception | 统一异常处理 | 所有项目 |
| Extension | 扩展点机制 | 多业务线、多租户 |
| StateMachine | 状态机 | 订单状态流转、审批流程 |
| CatchLog | 异常捕获和日志 | 简化 try-catch |
| RuleEngine | 规则引擎 | 复杂业务规则 |
COLA Archetypes(项目脚手架)
不想手动创建目录?COLA 提供了两种脚手架,一键生成标准项目结构:
| Archetype | 用途 | 包含模块 |
|---|---|---|
cola-archetype-web |
Web 应用(有前端接口) | adapter, app, client, domain, infrastructure, start |
cola-archetype-service |
纯后端服务(RPC/Dubbo) | app, client, domain, infrastructure, start |
bash
# 创建 Web 应用
mvn archetype:generate \
-DarchetypeGroupId=com.alibaba.cola \
-DarchetypeArtifactId=cola-framework-archetype-web \
-DarchetypeVersion=4.3.1💡 参考来源 :COLA 4.0:应用架构的最佳实践
命名规范
| 类型 | Python 后缀 | Java 后缀 |
|---|---|---|
| 命令 | _cmd |
Cmd |
| 查询 | _qry |
Qry |
| 命令执行器 | _cmd_exe |
CmdExe |
| 查询执行器 | _qry_exe |
QryExe |
| 客户端对象 | _co |
CO |
| 服务接口 | _service_i |
ServiceI |
| 服务实现 | _service |
ServiceImpl |
| 网关接口 | _gateway |
Gateway |
| 网关实现 | _gateway_impl |
GatewayImpl |
| 转换器 | _convertor |
Convertor |
📁 文件说明
cola-DDD-skill/
├── README.md # 本说明文档
├── python-cola-skill/
│ ├── SKILL.md # Python COLA 技能定义
│ └── references/
│ ├── dto.md # Response、Command、Query、CO 模板
│ ├── service.md # Service 和执行器模板
│ ├── gateway.md # Gateway 模式模板
│ └── example.md # 完整用户管理示例
└── java-cola-skill/
├── SKILL.md # Java COLA 技能定义
└── references/
├── dto.md # Response、Command、Query、CO 模板
├── service.md # Service 和执行器模板
├── gateway.md # Gateway 模式模板
└── example.md # 完整示例 + Maven 配置🔗 参考资源
- COLA GitHub - 阿里巴巴 COLA 官方仓库
- COLA 4.0:应用架构的最佳实践
- vibe-blog - 本文实践案例的开源项目
提示: 这些 Skills 旨在提供架构指导,而非强制规范。根据项目实际情况灵活调整,保持代码整洁和可维护性才是最终目标。