Ubuntu datasophon1.2.1 二开之四:解决YARN安装问题
- 背景
- 问题
-
-
- [Altermanager 报错:](#Altermanager 报错:)
- 重装zk时,机器节点安装不完整
- [YARN 安装后,总是启动失败](#YARN 安装后,总是启动失败)
- HDFS安装后,总是报警告
-
- 解决
- 最后
背景
上次安装完HDFS后,继续往下安装YARN,。安装YARN时,发现hdfs配置漏参数没写入到配置文件,修复后,重头安装,结果发现诸多问题,一个坑比一个坑深。我都跟客户说,datasophon太不稳定,我试试ambari.详细了解一下它的架构,看别人评价确实很稳定,但是扩展的话,需要花钱买文档。情况给客户说明之后,他不赞成,我只能回来捋一捋datasophon.
问题
每个组件安装失败,我一般都是清空数据库及目录,然后从头装。
结果这次遇到datashopon最大的坑:不稳定性。上次安装得好好,这次有可能失败。重新安装时,遇到下诸多问题:
Altermanager 报错:
javascript
level=info ts=2026-01-09T02:22:58.000Z caller=main.go:225 msg="Starting Alertmanager" version="(version=0.23.0, branch=HEAD, revision=61046b17771a57cfd4c4a51be370ab930a4d7d54)"
level=info ts=2026-01-09T02:22:58.000Z caller=main.go:226 build_context="(go=go1.16.7, user=root@e21a959be8d2, date=20210825-10:48:55)"
level=info ts=2026-01-09T02:22:58.001Z caller=cluster.go:671 component=cluster msg="Waiting for gossip to settle..." interval=2s
level=info ts=2026-01-09T02:22:58.044Z caller=coordinator.go:113 component=configuration msg="Loading configuration file" file=alertmanager.yml
level=error ts=2026-01-09T02:22:58.044Z caller=coordinator.go:118 component=configuration msg="Loading configuration file failed" file=alertmanager.yml err="missing host for URL"
level=info ts=2026-01-09T02:22:58.044Z caller=cluster.go:680 component=cluster msg="gossip not settled but continuing anyway" polls=0 elapsed=42.94763ms变量丢失,导致模板文件变量替换为空串
不是每次都出现,如果出现不想重装,需要手工修改文件:
修改/opt/datasophon/alertmanager/alertmanager.yml
javascript
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 5m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- send_resolved: true
url: 'http://ddp1:8080/ddh/cluster/alert/history/save'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
~ url这行原来是这样的:
url: 'http:///ddh/cluster/alert/history/save'
改成:
url: 'http://ddp1:8080/ddh/cluster/alert/history/save'
ddp1是你安装监控组件的机器名或ip
重装zk时,机器节点安装不完整
比如安装三台,就安装了两台。有一台压根没下载安装包。你说神奇不?
YARN 安装后,总是启动失败
这个问题,感觉就是代码问题,不知道其他os如何测试通过的,我1.2.1代码压根没创建NodeManager节点,后来我加上去了。还有一点,安装后,需要手工通过界面启动NodeManager节点。YARN才变成绿色。
HDFS安装后,总是报警告
刚开始我以为是稳定性问题,可是每次都失败。后来深入研究发现启动control_hadoop.sh(以前改的不够完善)检查进程是否存在有问题。
一句话,就是脚本检查进程是否存在有问题,不能简单检查pid文件
修改后的control_hadoop.sh内容如下:
javascript
#!/bin/bash
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
usage="Usage: start.sh (start|stop|restart) <command> "
# if no args specified, show usage
if [ $# -le 1 ]; then
echo $usage
exit 1
fi
startStop=$1
shift
command=$1
SH_DIR=`dirname $0`
echo $SH_DIR
ident=$SH_DIR/ident.id
export LOG_DIR=$SH_DIR/logs
export PID_DIR=$SH_DIR/pid
pid=$PID_DIR/hadoop-root-$command.pid
if [[ "$command" = "namenode" || "$command" = "datanode" || "$command" = "secondarynamenode" || "$command" = "journalnode" || "$command" = "zkfc" ]]; then
cmd=$SH_DIR/bin/hdfs
elif [[ "$command" = "resourcemanager" || "$command" = "nodemanager" ]]; then
cmd=$SH_DIR/bin/yarn
elif [[ "$command" = "historyserver" ]]; then
cmd=$SH_DIR/bin/mapred
else
echo "Error: No command named \'$command' was found."
exit 1
fi
start(){
echo "execute $cmd --daemon start $command"
$cmd --daemon start $command
if [ $? -eq 0 ]
then
echo "$command start success"
if [ $command = "namenode" ]
then
echo "true" > $ident
fi
else
echo "$command start failed"
exit 1
fi
}
stop(){
$cmd --daemon stop $command
if [ $? -eq 0 ]
then
echo "$command stop success"
else
echo "$command stop failed"
exit 1
fi
}
status(){
if [ -f $pid ]; then
ARGET_PID=`cat $pid`
kill -0 $ARGET_PID
if [ $? -eq 0 ]
then
echo "$command is running "
else
echo "$command is not running"
exit 1
fi
else
echo "$command pid file is not exists"
exit 1
fi
}
restart(){
stop
sleep 10
start
}
case $startStop in
(start)
start
;;
(stop)
stop
;;
(status)
status
;;
(restart)
restart
;;
(*)
echo $usage
exit 1
;;
esac
echo "End $startStop $command."解决
第一个和第二个问题,都是偶尔发生的,暴露datasophon不稳定,为何不稳定?datasophon 依赖akka组件来通讯的,但是akka组件没有重试功能,万一遇到网络抖动,网络包丢失,worker没有收到server的命令。它就啥反应没有。为何会有网络抖动,因为高峰时,每个worker都从server下载安装包,就拿zk来说,假如有两台worker正在从server下载zk.tar.gz包,这时server出口网络带宽没剩多少了,如果这时又给第三台worker发出下载zk.tar.gz命令,有可能没收到。然后server没检查是否没收到,重试。没收到就不管了。
另外个问题是,datasophon-manager又充当文件服务器,供worker下载文件。使得本来不稳定情况,进一步加剧,雪上加霜。
针对文件服务器问题,我从ambari架构学了一招,使用nginx作为文件服务器,在nginx 配置一个端口,一个webroot 指向/opt/datasophon/DDP/packages ,然后原来下载url,改成nginx url。nginx经过多少人验证,稳定性大可以放心使用。并且只是静态文件,完全满足要求。
针对请求-应答 ,我也想很久,如何尽可能减少改动,又能解决检测应答,超时重试问题。刚开始想替换akka,我想替换工作量大,并且短时间不能完全稳定解决问题。后来我想到引入redis,这种轻量级组件,作为请求方,应答方的桥梁。下面简单画个框架图
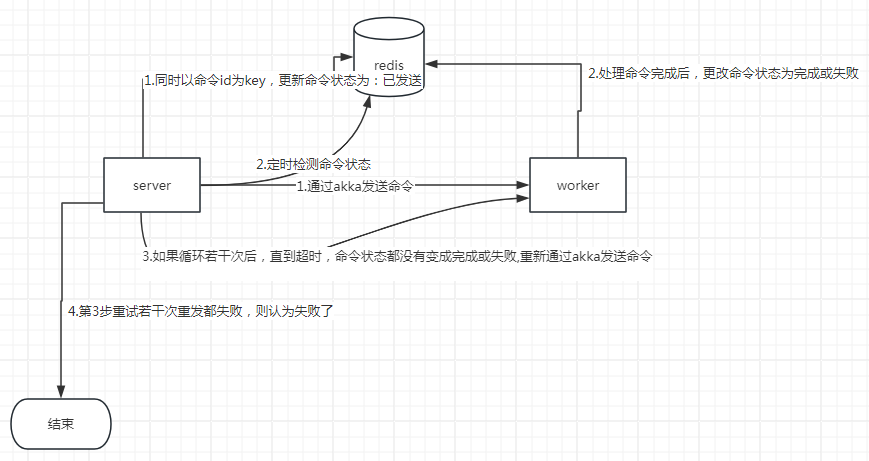
过程描述
1.server方:通过akka发送请求命令给worker后,同时设置redis命令状态,然后一直定时检查redis命令状态,直到收到命令状态变成已完成或已失败或者三次重试发送命令都失败(次数可以配置)
每次都是间隔一定时间检查命令状态是否变化,直到命令状态变成已完成或已失败或者超时,如果是超时,则重新发送akka命令。再循环检查处理
2.worker方:如果收到了命令,则立即修改redis命令状态为已收到,处理完成或者失败后,相应修改redis命令状态为已完成或已失败
最后
经过上面改造后,第一个,第二个目前没有重现,但是hdfs 有时还是需要重装缺失节点。比如namenode安装了两个节点,有个节点还是没装上,在管理界面上再勾选再安装。距离我理想中的稳定还是有些差距。各个大拿,如果有更好架构,不妨沟通沟通:lita2lz
原来我以为换成nginx,就高枕无忧了。没想到还那么多事。我没研究过ambari如何解决这个问题的。问ai,它答复通过http请求确认的