目录
[1. 概念](#1. 概念)
[2. 原理](#2. 原理)
[3. 代码实现(人脸+微笑检测)](#3. 代码实现(人脸+微笑检测))
[1. 概念](#1. 概念)
[2. 原理](#2. 原理)
[3. 代码实现(LBPH人脸识别)](#3. 代码实现(LBPH人脸识别))
三、Eigenfaces人脸识别器:基于PCA降维的经典方案
[1. 概念](#1. 概念)
[2. 原理](#2. 原理)
[3. 代码实现(Eigenfaces人脸识别)](#3. 代码实现(Eigenfaces人脸识别))
作为计算机视觉入门的核心方向,人脸检测与识别是最贴近生活、最易上手实战的场景之一。本文将结合OpenCV实战,系统拆解传统人脸检测与识别 的三大核心技术------Haar级联检测、LBPH人脸识别、Eigenfaces人脸识别,每一部分都从「概念理解→原理剖析→代码实战」三个维度展开。
一、Haar级联检测:快速实现人脸与微笑检测
1. 概念
Haar级联检测是一种基于「Haar灰度差分特征」和「级联分类器」的目标检测算法,在人脸检测、微笑检测、眼睛检测等场景中应用广泛。它的核心优势是轻量、快速,无需复杂算力,可通过OpenCV预训练模型直接调用 ,是传统人脸检测的入门首选,常用来完成"从图像/视频中找到人脸位置"等的前置任务。
2. 原理
Haar级联检测的核心逻辑是**「层层筛选、逐步求精」**,避免对图像中所有区域进行暴力检测,从而提升检测速度,具体可拆解为两个关键部分:
(1)Haar灰度差分特征:本质是描述图像局部的灰度变化规律,比如"人脸眼睛区域比脸颊暗""微笑时嘴角区域灰度变化更明显",通过这些特征可以初步区分目标(人脸/微笑)和背景。常见的Haar特征分为边缘特征、线特征、中心环绕特征三类,均通过"相邻区域灰度值之差"来表征。

(2)级联分类器:并非单一分类器,而是由多个「弱分类器」通过Adaboost算法组合成「强分类器」,再将多个强分类器按"简单→复杂"的顺序串联而成。检测时,先通过浅层简单强分类器,快速剔除图像中明显不是目标的区域(如背景、头发);再通过深层复杂强分类器,对疑似目标区域进行精准验证,最终确定目标位置。
补充说明:做一个不太恰当的比方,对一个区域线进行简单特征的判断,若有"眼睛",则进入下一层判断,没有则判定该区域不是人脸;若有"眼睛",继续判断有没有"鼻子",以此类推,当区域含有的特征超过我们设定的参数,则判定为人脸。
3. 代码实现(人脸+微笑检测)
本次实战使用OpenCV库的级联分类器,调用OpenCV预训练的.xml模型(人脸检测、微笑检测各对应一个模型),读取画面、检测人脸、识别微笑,并绘制检测框和提示文字的功能。
python
iimport cv2
faceCascade= cv2.CascadeClassifier(r'C:\Users\86139\AppData\Local\Programs\Python\Python37\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
smileCascade= cv2.CascadeClassifier(r'C:\Users\86139\AppData\Local\Programs\Python\Python37\Lib\site-packages\cv2\data\haarcascade_smile.xml')
image = cv2.imread('img_1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(gray, 1.1, 15, minSize=(5, 5))
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
roi_color = image[y:y + h, x:x + w]
smiles = smileCascade.detectMultiScale(roi_gray, 1.5, 25, minSize=(50, 50))
for (sx, sy, sw, sh) in smiles:
# 计算原图微笑区域坐标
a = x + sx
b = sy + y
cv2.rectangle(image, (a, b), (a + sw, b + sh), (0, 255, 0), 2)
cv2.putText(image, "smile", (x, y), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 255, 255), thickness=2)
cv2.imshow('smile', image)
cv2.waitKey(0)
cv2.destroyAllWindows()注意事项:若运行时报"模型路径错误",请找到自己电脑中cv2\data文件夹的路径,替换代码中的.xml文件路径;检测速度过慢可适当增大缩放因子(如1.2),误检过多可增大邻域阈值(如20)。
运行结果:
图片中任务微笑不明显,因此没有检测到,大家可以自行传入微笑明显的图片,也可以尝试对摄像头有实时传入的视频进行检测。
二、LBPH人脸识别器:无需严格对齐的实用方案
1. 概念
LBPH(局部二值模式直方图)人脸识别器,是一种基于「局部特征提取」的传统人脸识别算法,核心优势是对人脸对齐要求低、计算量小、可解释性强,且支持增量训练(无需重新训练整个模型即可添加新样本)。它适合小型项目(如家庭人脸考勤),也是OpenCV中内置的三种人脸识别器(LBPH、Eigenfaces、Fisherfaces)中最常用的一种。
2. 原理
LBPH人脸识别的核心是"提取人脸局部特征、保留空间信息、通过特征匹配实现识别",完整原理可拆解为三步,纠正并补充大家学习中的细节偏差:
(1)生成LBPH图像( 核心步骤):首先对输入人脸图像进行预处理(灰度化、裁剪,去除背景干扰),然后对图像中每个像素,取其周围3×3的圆形邻域(OpenCV默认采用圆形邻域( 从3*3改进的),实现旋转不变性),将邻域内每个像素与中心像素比较------邻域像素≥中心像素记为1,否则记为0,得到8位二进制数(对应256种取值);将该二进制数顺时针旋转,取最小值作为该像素的LBPH值,确保人脸轻微旋转时,特征值不变: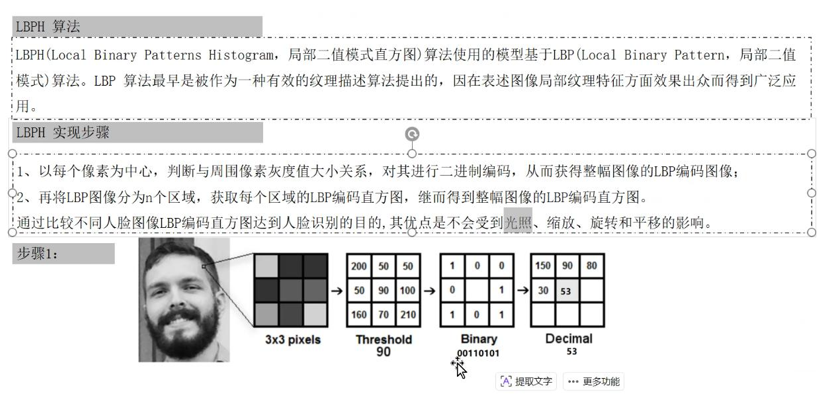
上图,我们相当于做了一次LBP编码,把binary中经过灰度值比较得到的0和1顺序排列,然后转化成十进制,得到53作为LBP编码,把每个像素值都进行这样的处理就得到了LBP图像。但是存在一个问题,比如图片中的人脸在拍照时稍微向右倾斜一点,那么我们得到的3*3邻域相当于做了顺时针旋转,这个时候我们把原来的binary中的0和1排列,结果是不一样的。为了避免这种旋转对算法的影响,我们使用以下方法: 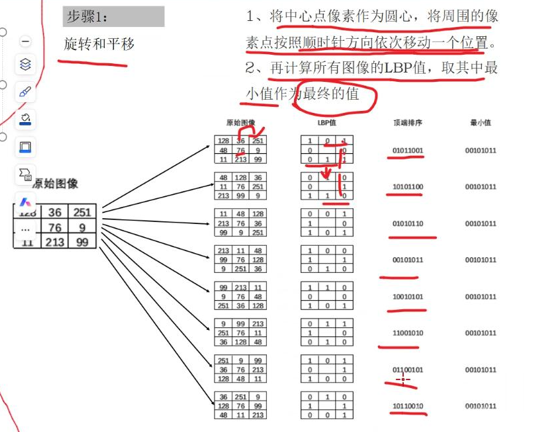
我们对原始图像的3*3邻域每次做一个单位顺时针旋转,取得到的所有LBP编码的最小值,这样我们无论输入的人脸有怎样的旋转,得到的编码都是相同的。
(2)提取全局特征向量:将生成的LBPH图像,均匀划分为若干个小方格(OpenCV默认8×8方格),计算每个方格的灰度直方图(每个方格得到256维特征,对应LBPH的256种取值),再将所有方格的直方图拼接起来,得到整个人脸的全局特征向量------这种分块方式的核心作用,是保留人脸的空间信息(比如"眼睛区域的LBPH特征的位置"),避免全局特征丢失局部细节: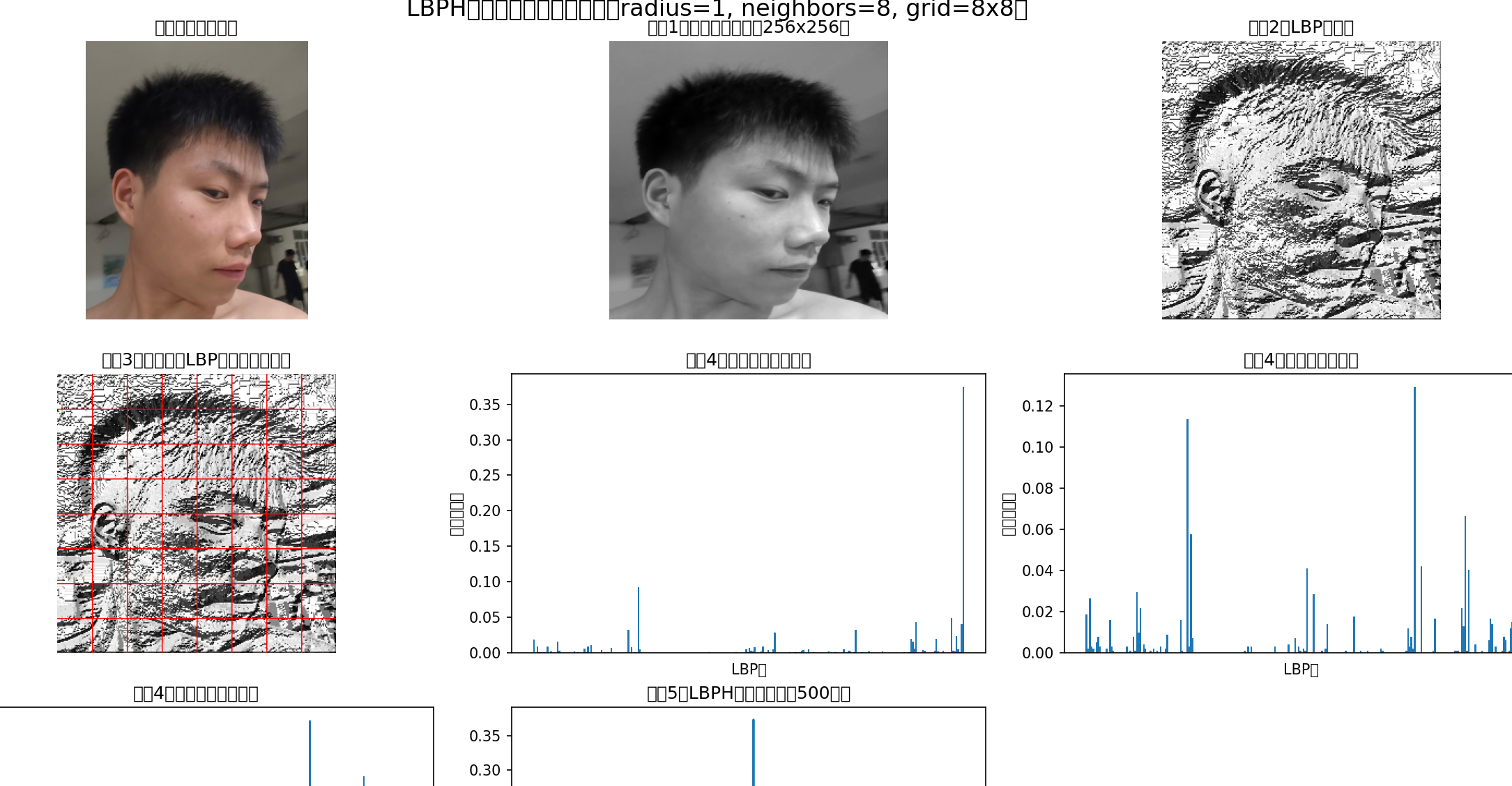
上图是我可视化了处理流程,我刚听plb图片的时候感觉这东西很难受,因为我看不到到底是什么样子,就让豆包把图片处理流程的结果都显示出来。
得到LBP图像后,这里我们把图像分成8*8的方格,然后绘制了每个方格的直方图,相当于把每个方格用256维度的向量表示,整张图片就可以用8*8*256维度的向量表示。
(3)特征匹配识别:用训练集人脸的特征向量,训练LBPH识别器;对待识别人脸,计算其特征向量与训练集所有特征向量的距离(默认欧氏距离或余弦距离),距离最小且小于设定阈值的,即为匹配结果;距离大于阈值,则判定为"无法识别"。
3. 代码实现(LBPH人脸识别)
本次实战使用4张训练人脸图片(2张侧脸、2张正脸),训练LBPH识别器,然后对待识别人脸进行预测,输出识别结果和置信度(置信度越低,匹配度越高)。
python
import cv2
import numpy as np
# 1. 准备训练数据(核心:训练图片需为灰度图,尽量裁剪纯人脸区域,减少背景干扰)
# 存储训练人脸图像的列表
images = []
# 读取训练图片,cv2.IMREAD_GRAYSCALE表示以灰度图方式读取
images.append(cv2.imread('img_2.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('img_3.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('img_4.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('img_5.png', cv2.IMREAD_GRAYSCALE))
# 2. 准备训练标签(标签与训练图片一一对应,相同人脸对应相同标签)
labels = [0, 0, 1, 1] # 0对应侧脸,1对应正脸
# 3. 定义标签映射字典(将数字标签转为易懂的文字)
label_dict = {0: '侧脸', 1: '正脸', -1: '无法识别'}
# 4. 准备待识别人脸图片(同样需为灰度图)
predict_image = cv2.imread('img_6.png', cv2.IMREAD_GRAYSCALE)
# 5. 创建LBPH人脸识别器并设置参数
# LBPHFaceRecognizer_create参数说明:
# radius:圆形LBPH的半径,默认1
# neighbors:圆形邻域的采样点数量,默认8
# grid_x:水平方向方格数,默认8
# grid_y:垂直方向方格数,默认8
# threshold:识别阈值,超过该值则判定为无法识别,此处设为80(值越小越严格)
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold=80)
# 6. 训练识别器(核心函数train)
# train参数说明:
# images:训练人脸图像列表(灰度图)
# np.array(labels):训练标签(需转为numpy数组格式)
recognizer.train(images, np.array(labels))
# 7. 对待识别人脸进行预测(核心函数predict)
# predict返回值:
# label:预测的标签(-1表示无法识别)
# confidence:置信度,值越小,匹配度越高(<50为高匹配,>100基本不匹配)
label, confidence = recognizer.predict(predict_image)
# 8. 输出识别结果
print('识别结果:', label_dict[label])
print('置信度(匹配度,越小越好):', confidence)运行结果:
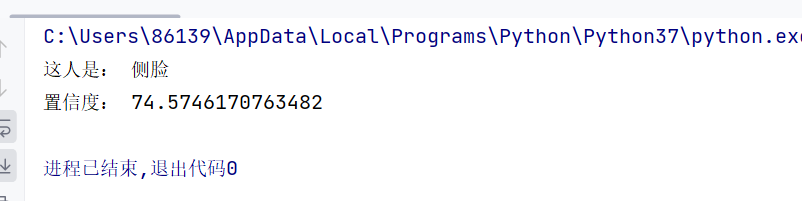
这里我没去网上找人脸图片,用了我的正脸和侧脸做的训练和预测。
三、Eigenfaces人脸识别器:基于PCA降维的经典方案
1. 概念
Eigenfaces(特征脸)人脸识别器,是基于「PCA(主成分分析)」的经典人脸识别算法,核心思路是"通过降维提取人脸的共性特征(特征脸),用低维特征向量表示人脸,实现高效匹配"。它的优势是在大样本、人脸对齐良好的场景下,匹配速度快;缺点是对人脸对齐、光照变化、表情变化敏感,工程上单独使用较少,但作为PCA降维的实战案例,非常适合入门学习。
补充纠正:很多同学会误以为"Eigenfaces的核心是PCA降维",其实不然------PCA降维是手段,目的是去除人脸特征的冗余信息,提取最具区分度的共性特征(特征脸),降维是为了提升匹配效率,而非核心目标。
2. 原理
Eigenfaces的原理核心是"用特征脸空间表示人脸",完整步骤可拆解为5步,兼顾理论和工程实践:(这个算法老师也没细讲原理)
(1)数据标准化(关键前置步骤):将所有训练人脸图片统一尺寸、转为灰度图,并严格对齐(如对齐双眼连线、嘴巴中心)------这是Eigenfaces效果的关键,轻微偏移就会导致特征失真;然后将每张人脸图片展平为一维向量(如120×180的图片,展平为21600维向量)。
(2)计算平均脸与偏差向量:计算所有训练人脸向量的平均值,得到"平均脸"(代表所有人脸的共性特征);将每张训练人脸向量减去平均脸,得到"人脸偏差向量"------目的是去除共性特征,保留每个人脸的个性差异(比如脸型、五官细节)。
(3)PCA降维提取特征脸:对"人脸偏差向量矩阵"计算协方差矩阵,提取协方差矩阵的特征向量(取方差最大的前N个特征向量),这些特征向量对应的图像,就是"特征脸"(最具区分度的人脸共性特征);所有特征脸构成"特征脸空间"。
(4)生成低维特征投影向量:将每张训练人脸的偏差向量,投影到特征脸空间,得到低维的特征投影向量(维度远低于原始向量)------该向量就是人脸的最终特征表示,保留了最具区分度的信息。
(5)特征匹配识别:待识别人脸经过相同的标准化处理后,投影到特征脸空间,得到其特征投影向量;计算该向量与训练集所有特征向量的距离,距离最小且小于阈值的,即为匹配结果;否则判定为"无法识别"。
3. 代码实现(Eigenfaces人脸识别)
本次实战与LBPH采用相同的训练数据,但需先统一图片尺寸(Eigenfaces对尺寸敏感),训练完成后预测待识别人脸,绘制识别结果并显示。
python
import cv2
import numpy as np
# 1. 准备训练数据(核心:Eigenfaces对尺寸敏感,需统一所有训练图片尺寸)
images = [] # 存储训练人脸图像(灰度图,尺寸统一)
# 读取训练图片,以灰度图方式读取(0等价于cv2.IMREAD_GRAYSCALE),并统一缩放到120×180
a = cv2.imread('img_2.png', 0)
a = cv2.resize(a, (120, 180))
b = cv2.imread('img_3.png', 0)
b = cv2.resize(b, (120, 180))
c = cv2.imread('img_4.png', 0)
c = cv2.resize(c, (120, 180))
d = cv2.imread('img_5.png', 0)
d = cv2.resize(d, (120, 180))
# 将处理好的训练图片加入列表
images.append(a)
images.append(b)
images.append(c)
images.append(d)
# 2. 准备训练标签(与LBPH一致,相同人脸对应相同标签)
labels = [0, 0, 1, 1]
# 3. 准备待识别人脸(统一尺寸、灰度图)
pre_image = cv2.imread('img_6.png', 0)
pre_image = cv2.resize(pre_image, (120, 180))
# 4. 创建Eigenfaces人脸识别器并设置参数
# EigenFaceRecognizer_create参数说明:
# threshold:识别阈值,Eigenfaces的置信度范围为0~20000,<5000为可靠结果
recognizer = cv2.face.EigenFaceRecognizer_create(threshold=5000)
# 5. 训练识别器
recognizer.train(images, np.array(labels))
# 6. 对待识别人脸进行预测
label, confidence = recognizer.predict(pre_image)
# 7. 定义标签映射字典(根据实际需求修改,此处示例为0:hg,1:pyy)
label_dict = {0: 'hg', 1: 'pyy', -1: '无法识别'}
# 8. 输出识别结果
print('识别结果:', label_dict[label])
print('置信度(<5000可靠):', confidence)
# 9. 绘制识别结果并显示(将识别结果写在待识别人脸图片上)
# 读取待识别人脸的彩色图(用于绘制文字,灰度图无法显示彩色文字)
show_image = cv2.imread('img_6.png').copy()
# 绘制文字:参数依次为(图像、文字、坐标、字体、字体大小、颜色、线宽)
show_image = cv2.putText(show_image, label_dict[label], (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 2)
# 显示图片
cv2.imshow('Eigenfaces Recognition', show_image)
# 等待键盘输入(0表示无限等待,按下任意键关闭窗口)
cv2.waitKey(0)
# 释放窗口资源(避免程序残留)
cv2.destroyAllWindows()注意事项:Eigenfaces的核心坑是「图片尺寸统一+严格对齐」,若训练图片尺寸不一致或未对齐,会导致模型训练失败或识别准确率极低;置信度超过5000时,识别结果不可靠,可适当调整threshold阈值,但需权衡误检概率。
运行结果: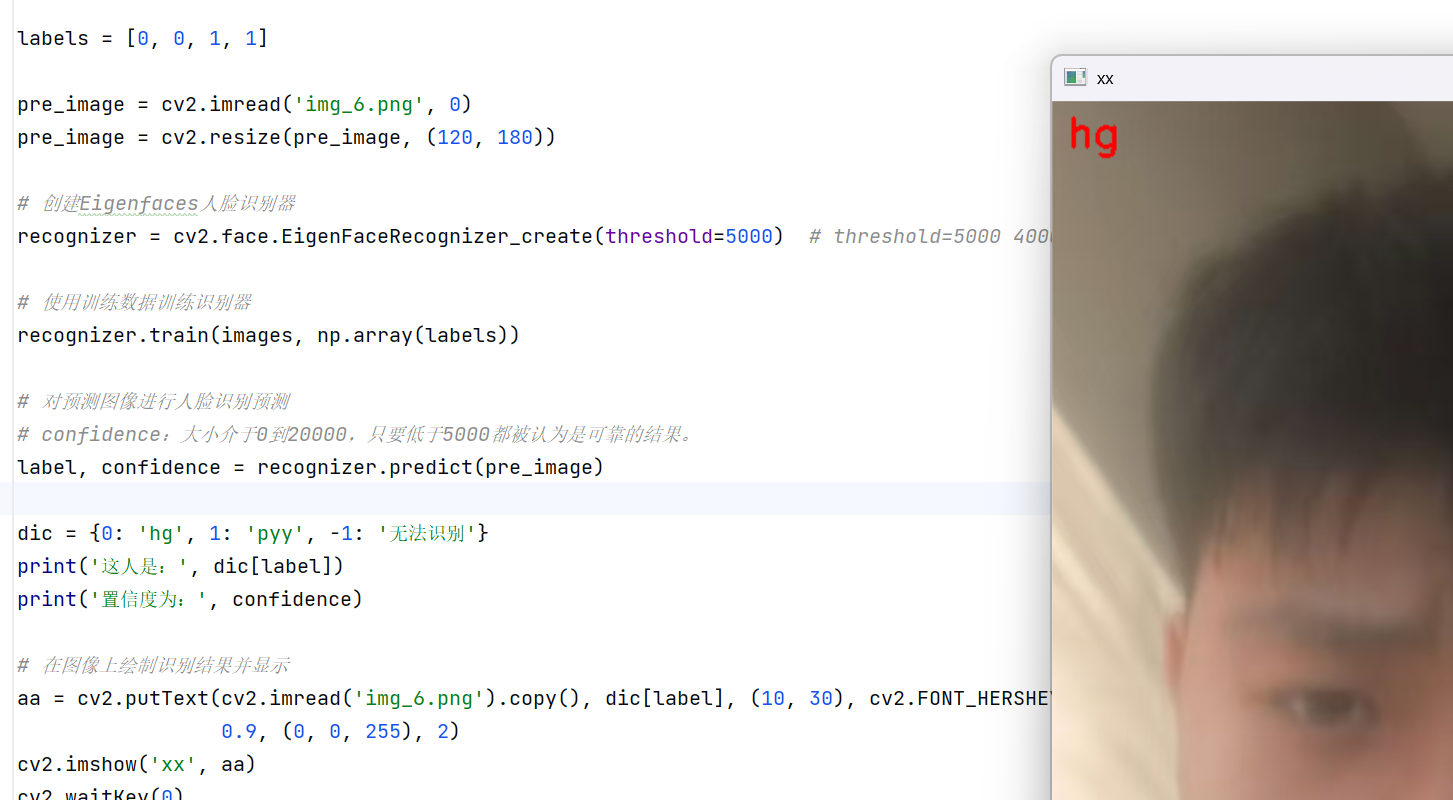
四、总结与学习心得
本文拆解的三大技术,构成了传统人脸检测与识别的完整链路:Haar级联检测负责"找到人脸"(前置检测),LBPH/Eigenfaces负责"认出人脸"(核心识别)或者说进行人脸匹配,三者各有优劣,工程选型需结合场景:
-
若需轻量、快速检测(如嵌入式设备):优先选「Haar级联检测」;
-
若为小型项目、人脸对齐困难:优先选「LBPH人脸识别器」;
-
若为大样本、人脸对齐良好,追求匹配速度:可尝试「Eigenfaces人脸识别器」。
作为入门学习,重点掌握"检测→特征提取→匹配"的核心逻辑,理解每一步代码的作用和参数含义,多动手修改参数(如threshold、缩放因子),观察结果变化,才能真正吃透这些知识点。后续可尝试将三者结合(Haar检测人脸→LBPH/Eigenfaces识别),实现完整的人脸检测与识别系统,为后续学习深度学习人脸识别(如MTCNN+ArcFace)打下基础。