双塔异构神经网络:互补特征融合的实战探索
在深度学习模型设计中,经常面临一个核心矛盾:模型复杂度与泛化能力的平衡 。单一架构往往难以同时捕捉数据的不同模式------深层网络擅长提取抽象语义,而带有正则化的网络更关注鲁棒性特征。本文介绍一种双塔异构融合架构,通过两个结构差异显著的MLP分别提取特征,再通过交互层进行融合。
一、模型架构总览
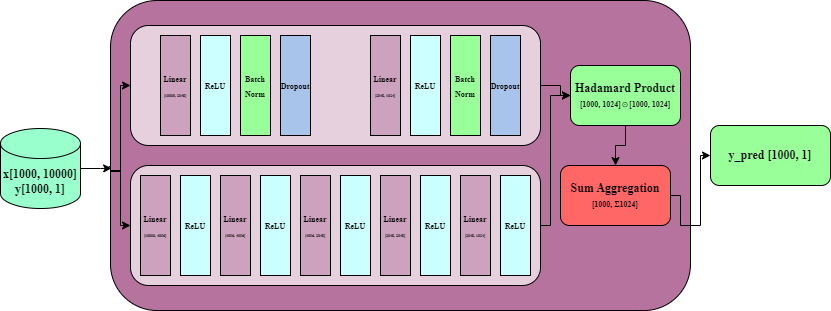
我们的模型包含三个核心组件:
- Tower A (MLP1):带正则化的浅层网络 ------ "稳健派"
- Tower B (MLP2):无正则化的深层网络 ------ "表达派"
- 融合层:逐元素相乘 + 全局池化 ------ "交互层"
python
class FusionModel(nn.Module):
def __init__(self, tower1, tower2):
super().__init__()
self.tower1 = tower1 # 正则化塔
self.tower2 = tower2 # 深度塔
def forward(self, x):
left_feat = self.tower1(x) # [B, 1024] 稳健特征
right_feat = self.tower2(x) # [B, 1024] 深度特征
fused = left_feat * right_feat # 特征交互
return fused.sum(dim=1, keepdim=True) # 压缩为预测值二、双塔设计的差异化策略
2.1 Tower A:正则化浅层网络 (MLP1)
python
self.fc1 = nn.Linear(10000, 2048)
self.bn1 = nn.BatchNorm1d(2048)
self.dp1 = nn.Dropout(0.1)
# ... 第二层同理设计哲学:
- BatchNorm:稳定隐藏层分布,加速收敛,提供轻微正则化
- Dropout(0.1):防止过拟合,强制网络学习冗余表示
- 瓶颈结构:10000 → 2048 → 1024,通过逐层降维压缩信息
适用场景:处理高维稀疏特征(如万维 one-hot 特征),抑制噪声干扰。
2.2 Tower B:深度无正则化网络 (MLP2)
python
self.fc1 = nn.Linear(10000, 4096)
# ... 连续5层全连接,无外置正则化设计哲学:
- 深度优势:5层堆叠具有更强的非线性表达能力,可学习复杂高阶特征组合
- 宽维度:4096维隐藏层保留更多信息容量,避免早期信息瓶颈
- 无Dropout/BN:保留原始梯度流,适合数据量充足、噪声较小的场景
关键观察: deeper network here acts as a "feature factory", generating rich hierarchical representations without the smoothing effect of normalization.
三、融合策略:Hadamard积 + 全局求和
不同于常见的特征拼接(concatenation)或注意力机制,本模型采用逐元素相乘(Hadamard Product):
python
fused = left_feat * right_feat # [batch, 1024]
output = fused.sum(dim=1, keepdim=True) # [batch, 1]为什么选择逐元素相乘?
-
特征交互:模拟逻辑"与"操作,只有当两个塔对某个维度都激活时,该特征才会被保留
- 例如: Tower A 检测到"关键词A存在" + Tower B 检测到"上下文B匹配" → 强相关信号
-
维度对齐压力 :强制两个塔学习语义对齐的表示空间。如果 Tower A 的第i维表示"情感极性",Tower B 的第i维也倾向学习互补的情感特征。
-
计算高效:相比双线性池化或注意力机制,O(n)复杂度适合实时推理。
求和池化的作用
将1024维交互特征压缩为标量,相当于可学习的加权投票机制 :
output = ∑ i = 1 1024 ( w 1 i ⋅ x ) × ( w 2 i ⋅ x ) \text{output} = \sum_{i=1}^{1024} (w_{1i} \cdot x) \times (w_{2i} \cdot x) output=i=1∑1024(w1i⋅x)×(w2i⋅x)
这等价于一个二阶特征交互的简化形式,类似Factorization Machines的核心思想。
四、应用场景与扩展
这种架构特别适合以下场景:
-
多视角特征学习
- Tower 1 处理手工特征(统计特征,需要BN稳定)
- Tower 2 处理原始嵌入(深度学习特征,需要深度提取)
-
知识蒸馏 precursor
- 先分别训练两个教师模型,再用融合层学习集成策略
-
多任务学习的骨干网络
- 在
fused层后添加多个投影头,分别处理不同任务
- 在
进阶融合技巧
若简单逐元素相乘效果不佳,可尝试:
python
# 门控融合(Gating Mechanism)
gate = torch.sigmoid(self.gate_layer(torch.cat([left, right], dim=1)))
fused = gate * left + (1 - gate) * right
# 双线性交互
fused = torch.bmm(left.unsqueeze(2), right.unsqueeze(1)).view(batch, -1)五、总结
本文的双塔架构通过结构异构性实现了特征提取的互补:
- MLP1 提供稳定、鲁棒的基准特征(Regularized Backbone)
- MLP2 提供丰富、复杂的高阶特征(Expressive Backbone)
- Hadamard融合 实现选择性注意(Selective Attention)
这种"宽+深"、"正则+原始"的组合策略,在实践中往往比单一路径的模型具有更好的泛化性能,尤其适合特征维度高且模式复杂的二分类任务(如CTR预测、欺诈检测等)。