引言
- RAG(Retrieval Augmented Generation,检索增强生成)是一种将 LLM 与外部数据源(例如私有数据或最新数据)结合的方法,通过 RAG 可以实现问题结合外部数据来让 LLM生成输出,提高模型回答的准确率,降低模型"幻觉"。
- 注:token 是模型用来表示自然语言文本的基本单位,可以直观的理解为"字"或"词";在中文一般表示一个字,英文一般是 3-4 个字母
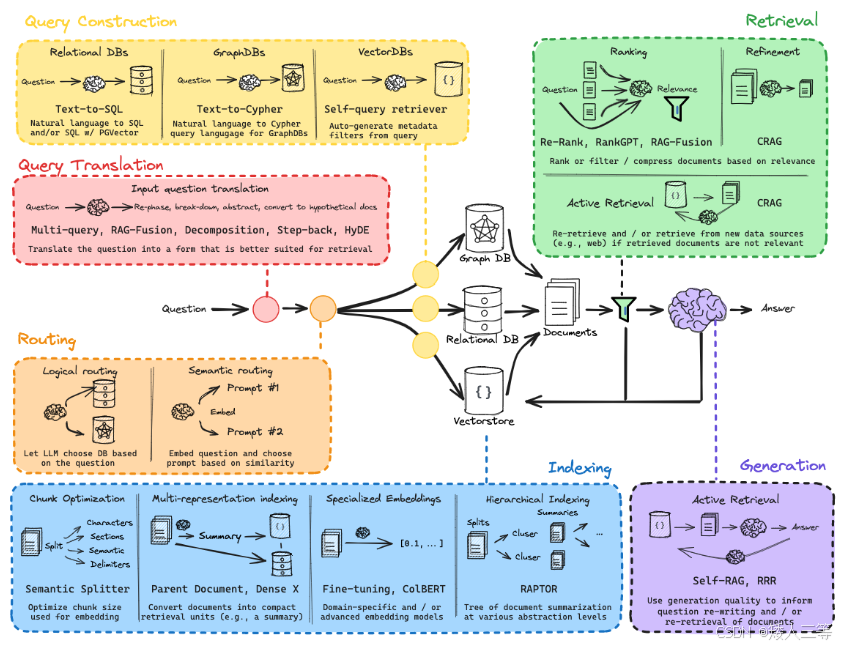
Rag流程都包含什么
-
简单来说:
-
首先我们对外部(数据)文档建立索引(Indexing);
-
根据用户的问题去检索(Retrieval)相关的文档;
-
将问题和检索处理得到的相关文档信息一起输入 LLM 生成(Generation )最终答案。
-
Question Translation
-
在问题层面,不是所有的用户都可以清楚准确地描述自己的 Query,如果用户写了一句模棱两可的 Query 或者是一个复杂的 Query,那么检索到的文档也将是模棱两可或者难以准确检索,进而导致 LLM 的回答就不准确,那么就需要在问题层面开始优化处理,常用方法如下:
-
Re-written:对原始查询进行语义重写,不改变核心语义,但调整语言表述,使得问题更易被知识库或检索系统处理。
-
Multi-Query:在检索阶段针对同一个问题让 LLM生成多个不同表述的问题,通过这些问题分别去检索知识库得到不同的知识内容,后续可选:综合结果排序或者直接输入LLM,本方法侧重于"检索增强"
-
RAG Fusion:可以看成是Multi-Query 的增强版,同样是需要生成多个问题,多个问题使用同一套检索方法进行检索处理生成多个结果列表,列表中所有结果汇总后使用 RRF 方法进行排序(侧重检索增强 + 融合的完整阶段),后续可以取 TOP 值再输入到 LLM。
- 检索融合方法组合推荐:
- 低成本、通用场景:RRF(向量 + BM25 多路召回 → RRF 融合 → top10 给 LLM)
- 高精度、中低并发:RRF + Cross-Encoder Reranker(多路召回 top100 → RRF 粗排 → Cross-Encoder 精排 top10)
- 高并发、中精度:Score Fusion + Bi-Encoder Reranker
- 无监督:RRF 最稳,Score Fusion 简单,CombMNZ 兼顾共识。
- 重排序:Cross-Encoder 精度王,Bi-Encoder 速度快。
- 学习型:(排序学习,训练排序模型)LTR 效果顶,但成本高。
- RAG 首选 :RRF + Cross-Encoder Reranker 是目前工业界最通用的黄金组合。
- 检索融合方法详解:
- Reciprocal Rank Fusion (RRF):最简单且兼容各种检索器,鲁棒性强,只关心根据分数得到的排名而不关心检索器的打分,RAG 首选,使用多种检索器方法
- Score Fusion(分数融合):与 RRF 不同的是其要使用检索器打分,根据打分来排名,没有 RRF 鲁棒性好,因为不同检索方法给的结果差异很大,适用于检索器都是同类型的情况
- CombSUM / CombMNZ:检索器的分数先归一化后,再进行求和,根据结果重排,对多个检索器有"共识"的结果加权更合理,多路召回快速融合,对精度要求不极致的场景。
- Cross-Encoder Reranker(交叉编码器重排):就是训练一个可以得到问题和索引的模型,只是需要的是模型对问题和索引匹配程度的得分,精度较高但是推理速度慢。
- Bi-Encoder Reranker(双塔重排):把问题和文档信息都向量化后,使用向量之间计算相似度的方法计算相似度,精度稍微低于4,但是速度快一些,精度和速度的一个平衡选择(更像向量检索的一个升级版)
- LambdaMART / ListMLE(排序学习 LTR):需要大量标注数据,成本最高,但是精度也最高
- 检索方法:
- 向量检索,就是使用编码后的问题和知识向量,通过余弦相似度或者点积来计算相似度进行检索
- BM25:把文档和问题分词 ,统计词频、逆文档频率(IDF),用 BM25 公式计算问题和文档的关键词匹配得分;
- 关键词检索(TF-IDF),text rank,pagerangk等
- 直接使用 faiss,有内置方法
- 检索融合方法组合推荐:
-
sub-question:将复杂的问题拆解为多个独立的子问题,每个子问题可以单独处理。最终通过聚合子问题的答案来生成完整的回答。
-
"递归求解"式:用前一个子问题答案结合下一个子问题进行检索,得到到的文档结合前面拿到的答案作为上下文,来生成下一个子问题的答案
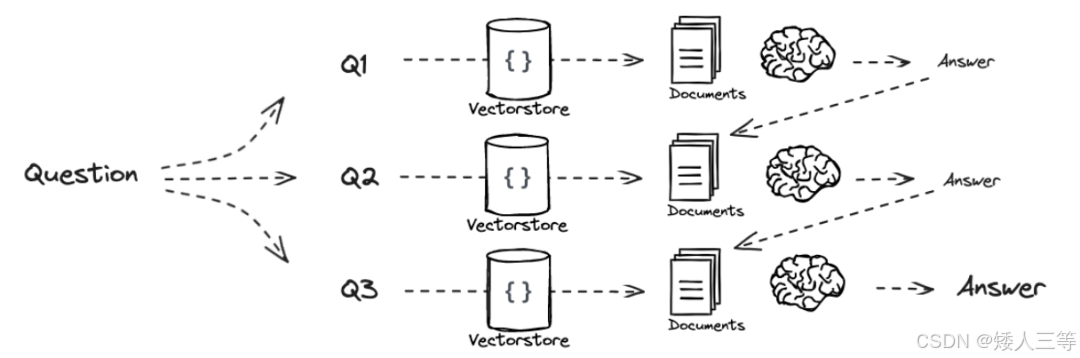
-
先得到每个子问题的答案,然后集中汇总得到最终答案。
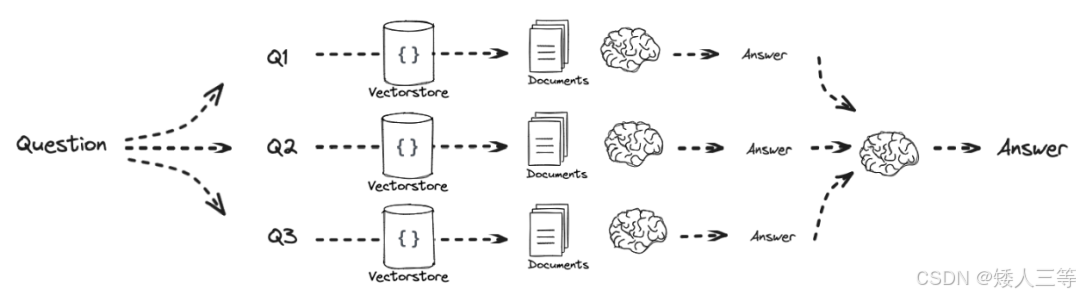
-
-
Step-back Question:在检索和回答过程中,当系统意识到当前的问题太具体或难以直接回答时,退一步改问一个更广泛、更概括性的问题,从而获取更大的上下文信息。
- 应用场景:
- 当前查询太具体,无法直接匹配知识库内容。
- 检索结果中没有足够的信息来回答原始问题。
- 注:如何"退一步"呢?
- 应用场景:
-
HyDE:(Hypothetical Document Embedding) 是一种用于 Query Translation 的创新方法,特别适用于 RAG 系统中的复杂问题处理。HyDE 的核心思想是通过生成"假设文档"(Hypothetical Document),将查询从抽象的自然语言问题转化为检索系统能够高效处理的表示
- 通俗讲就是,先使用 LLM 模型生成一个对输入问题的结果,然后把这个结果作为输入,取向量数据库查询相关知识,再结合问题进行提问
- 注意语言问题,比如问问题是中文,知识库是英文,可以转化成语言一致的情况后再进行处理。
-
-
Routing
-
根据用户的查询内容,智能地选择最适合的检索路径或推理逻辑,以更高效地获取答案。这种动态选择的过程在多数据源、多检索器或多任务场景下尤为重要,能够显著提升系统的性能和准确性。
-
注:个人认为路由本质就是 RAG 的 "自动化优化 + 精细化管理",解决的就是 "多查询 / 多数据源 / 多检索器" 带来的效率和精度问题。
-
Logical Routing(逻辑路由):RAG 中基于规则 / LLM 逻辑推理,将用户查询动态分发到适配数据源、检索器或处理流程的机制,核心是 "按意图精准分流",提升效率与准确性。
-
适用于结构化问题或明确的数据源场景
-
举例:
text1 首先我们定义 python_docs、js_docs 和 golang_docs 这三个数据源,并定义一个查询路由函数 2 使用 with_structured_output 函数结合 1 中的查询路由函数,让 LLM 返回符合自定义格式的输出(也可以在此处使用 mcp) 3 定义了一个根据用户问题中的编程语言选择数据源的 prompt 4 结合 3 中的 prompt 和 2 中结构化输出,组成路由链 5 定义选择路由的逻辑,根据2 中结构化输出结果选择对应路由的检索方法 这样我们就实现了一个根据查询问题信息,进行路由分发,检索的过程。 -
典型应用场景:
场景 路由判断依据 目标组件 多语言 / 多技术文档 编程语言、框架关键词 Python/JS/Golang 文档库 多模态查询 内容类型(文本 / 图片 / 表格) 文本检索 / 视觉模型 / 表格解析 混合数据查询 数据结构(结构化 / 非结构化) 关系库 SQL 查询 / 向量库检索 多工具协同 任务类型(计算 / 搜索 / 翻译) 计算器 / 搜索引擎 / 翻译 API
-
-
Semantic Routing(语义路由):使用向量相似度把用户问题自动分到最匹配的 "意图 / 数据源 / 检索器",不用写规则,靠语义匹配分流。
-
适用于模糊查询或需要灵活响应的场景。
-
举例:
text1 首先定义两个用于回答不同领域(物理和数学)问题的 Prompt 2 对定义的两个 prompt 进行 Embedding 3 对用户的问题进行 Embedding,并比较用户问题和两个 prompt 的相似程度,选择相近的 prompt
-
Query Construction
-
把用户自然语言问题,自动转换成更适合检索的 "结构化 / 优化查询",让检索更准、召回更全,是 RAG 里提升检索质量的关键一步
-
通俗理解就是:自然语言 → 关键词组合、布尔查询(AND/OR/NOT)、过滤条件(时间、标签、分类)、向量检索的优化 query 表达
- 关键词提取:从问题里抽核心词 / 实体,使用这些词做 BM25 / 关键词检索,效果可能比整句更准
- 布尔查询生成:把问题转成
(A AND B) OR (C AND NOT D)格式,适合全文检索(Elasticsearch/Lucene),精确控制匹配逻辑 - 过滤条件生成:从问题里抽时间、分类、标签等,检索时先按条件过滤,再做相似度匹配,减少噪声
- 查询改写 / 扩展(Query Rewriting/Expansion):比如同义改写:"报销额度"→"报销标准 / 报销上限"; 补全缺失信息:"住宿报销"→"Q3 差旅住宿报销额度",尽可能在信息复杂的时候,让检索覆盖更多相关文档来提升检索质量
- 结构化查询生成(如 SQL/SPARQL):针对结构化数据(数据库 / 知识图谱),把自然语言转成可执行查询的语句,直接拉取精准数据
-
举例
text1 假设文档向量的元数据中包含文档元数据信息,并且可以进行非结构化索引 2 为结构化搜索查询,自定义一个架构,通俗讲就是把元数据信息写入到自定义的函数中,并增加 prompt 描述,类似上面例子中对模型输出进行格式化 3 让 LLM 可以将自然语言转成合适的结构化查询的 Prompt 4 结合 prompt 和 函数,让用户的自然语言描述转化成结构化查询
Index
-
我们需要使用文档加载器,从许多不同的来源抓取数据,然后进行 Indexing(比如使用:Qwen + BAAI + LangChain + Qdrant 来进行)
- Qwen 模型作为 LLM,BAAI 指的是北京智源人工智能研究院的简称,其开发了一系列的 bge-xx 系列模型,对中文适配度比较好
- Qdrant 是一个向量数据库,faiss 只能检索不能储存索引,langchain 把他们串联起来
-
RAG 很多方法侧重于将文档拆分成多个块,并在检索时返回一定数量的块给 LLM。但块的大小和块的数量参数对结果影响很大,因为可能选择的块没有完整的上下文,以下为一些优化储存和检索的方法:
-
Multi-representation(多表征索引):对文档 / 查询生成多种不同类型的向量 / 索引,多表征结合,兼顾不同匹配需求,减少漏召回,让检索能适配不同场景(语义匹配、关键词匹配、结构匹配等),提升召回率和鲁棒性。
- 聚焦 "文档该用什么形式存"------ 给同一文档生成多种向量(语义 / 关键词 / 结构),解决 "一种向量只能适配一种匹配场景" 的问题。
text举例: 1 给同一篇文档 "贴多个不同维度的标签",比如: 1.1 标签 1:语义向量(使用 BGE 生成,获取整体意思); 1.2 标签 2:稀疏向量(使用SPLADE 生成,获取关键词权重); 1.3 标签 3:结构向量(按文档层级 / 段落关系生成,获取逻辑结构); 1.4 入库时:将上面不同纬度的标签存入到支持多向量的向量数据库中 2 检索查询时:用同样的多个模型生成查询问题的多种表征 3 检索融合:每种表征单独召回 top-K,再用 RRF / 分数融合合并结果(类比上面的RAG Fusion)。-
Proposition Indexing:把文档拆解成最小的 "语义命题单元"(非段落 / 句子,而是一个能表达完整含义的单元),对每个命题单独建索引,除去冗余信息只精准匹配"事实",让 LLM 的上下文更干净,生成答案更准。
text举例:文档不是整段存,而是拆成 "一个个独立的事实陈述",每个陈述就是一个 "命题": 原文档段落:"2025Q3 差旅报销政策:一线城市住宿每日 500 元,二线城市 400 元,需提供发票和行程单。" 拆解后的命题: 命题 1:2025Q3 差旅报销的一线城市住宿额度为每日 500 元; 命题 2:2025Q3 差旅报销的二线城市住宿额度为每日 400 元; 命题 3:2025Q3 差旅报销需提供发票; 命题 4:2025Q3 差旅报销需提供行程单。 每个命题单独生成向量、存索引,检索时直接召回和查询最相关的 "命题",而非整段文档(这样还具有可解释性)。
-
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval):一种针对长文档检索的 RAG 优化方案,通过递归抽象的方式构建层次化树形索引,解决传统 RAG 仅检索短文本块、难以把握长文档整体语境的问题,还能减少 Token 使用量,提升检索效率与精准度:
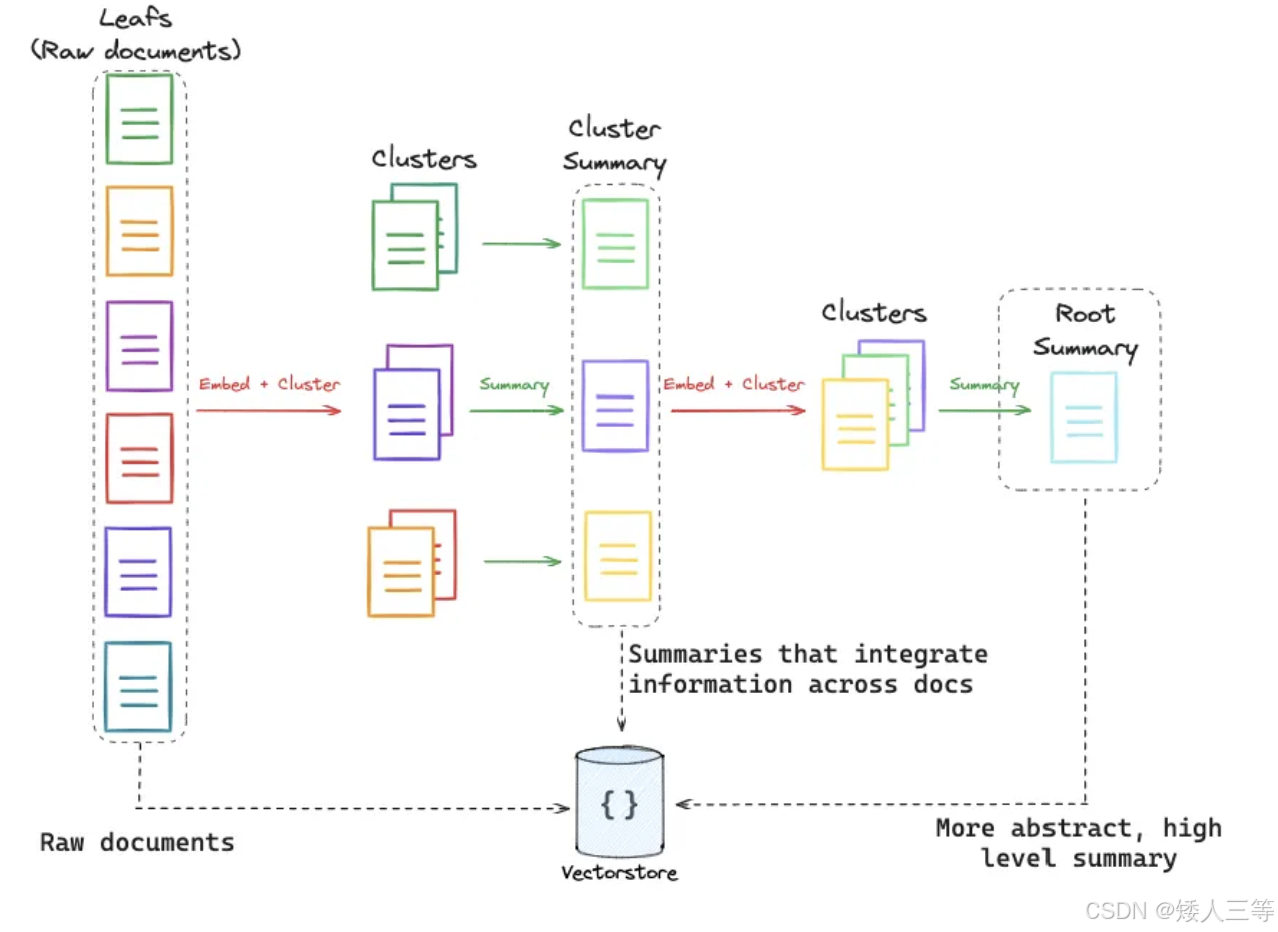
- 聚焦 "长文档怎么存、怎么查"------ 把长文档拆成树形结构,既存细节又存全局摘要,解决 "长文档查细节漏全局、查全局漏细节" 的问题;
- 优点:
- 高效的层次化信息检索:通过分层组织,用户可以快速定位到感兴趣的层级(从概览到细节)。
- 灵活的扩展性:可以处理不同粒度的数据(从段落到文档再到更大的集合)。
- 适配 LLM:尤其是上下文窗口更大的模型(如 GPT-4 或 Claude)可以进一步增强其性能。
- 实现流程:
- 叶子节点初始化:将原始长文档切分成多个详细的小文本块,这些文本块是知识的基础单元,作为树的 "叶子",和传统 RAG 中的文档分块类似
- 逐层递归抽象:对语义相关的叶节点做聚类分组,再用大语言模型为每个聚类生成摘要,这些摘要成为树的下一层 "分支";之后重复聚类与摘要步骤,对新生成的摘要再聚类、再总结。
- 形成树形结构:持续递归向上构建,直到生成一个能代表整个文档库核心概念的 "根节点"。最后将所有原始文本块和各层级摘要都纳入向量数据库建立索引。
- 聚类方法:高斯混合模型,UMAP降维,多尺度聚类(Local and Global Clustering)
-
ColBERT(Contextualized Late Interaction over BERT):一种检索排序模型,核心是 "上下文化延迟交互" 机制,兼顾 BERT 的语义精准性与双编码器的检索效率,在 RAG 等长文档检索场景中广泛落地
- 注:bert 本身是单编码器,但是ColBERT把编码器拆成 "查询编码器" 和 "文档编码器"(可共享权重),查询和文档独立输入编码器,分别生成向量,结构上形成 "双编码器"
- 聚焦 "怎么算相似度更准、更快"------ 在检索阶段用 Token 级细粒度匹配,解决 "粗匹配不准、细匹配太慢" 的问题;
- 实现流程:
- token 级别的相似度计算:分别把问题和文档输入到对应编码器中,得到对应的向量后让问题中的每个 token 向量与文档中每个token 向量求相似度(一般是余弦相似度来衡量),构成一个相似度矩阵
- token 的上下文向量获取:把文档输入到 bert 中后,经过 bert 的注意力后,去掉标签向量等无关信息,就是包含 token 上下文的输出向量了
- MaxSim(最大池化)操作:在文档 token 中找到每个查询 token 的最大相似度token,汇总所有文档中与查询最相似的 token 的和,作为整个文档与查询的整体相似度
- 对所有输入的文档依次做 1,2 操作,通过 2 中结果取 TOP值,得到问题最相关的文档
- token 级别的相似度计算:分别把问题和文档输入到对应编码器中,得到对应的向量后让问题中的每个 token 向量与文档中每个token 向量求相似度(一般是余弦相似度来衡量),构成一个相似度矩阵
- 工业使用一般是在长文本情况下,组合使用:RAPTOR(树形存储长文档)
→Multi-representation(每个节点生成多类向量)→ColBERT(Token级细粒度检索)
-
Retrieval
-
Retrieval:根据我们提出的问题转换成的的向量,使用某种度量方法在向量数据库中去匹配检索相近的index
-
为了提升 RAG 系统的准确性,我们还可以从 retrieval 方面进行优化
-
Ranking:对检索到的候选文档进行重新排序的过程。这个步骤通常是为了提高生成模型的质量,确保生成的答案或内容更相关、更精确,重新排序的方法通常有:
- 基于相似度的排序:可以使用基于查询和文档之间相似度的度量方法,如余弦相似度、点积等。
- 基于深度学习的排序模型:一些更复杂的 Re-Rank 方法会利用深度学习模型,比如使用 BERT 或 T5 等预训练语言模型,进一步评估候选文档和查询之间的相关性。
- 使用回归模型:有时可以将候选文档的特征(如长度、相似度、标题等)输入回归模型,预测每个文档的重要性得分,最终根据得分对文档排序
-
Self-reflection RAG:在 RAG 系统中,结合自我反思的机制来改进生成结果。这个过程会在生成步骤中加入自我审视,帮助模型更好地理解和修正之前的生成结果,以提高最终的输出质量,具体实践有:
-
CRAG(Corrective Retrieval Augmented Generation)是一种为 RAG 设计的策略,它将自我反思/自我评分机制应用于检索到的文档。
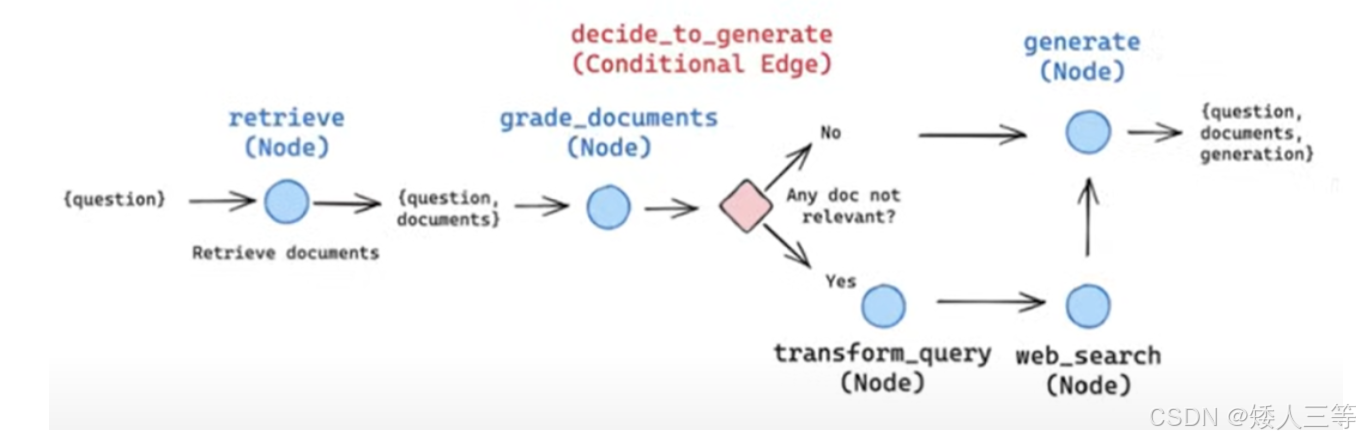
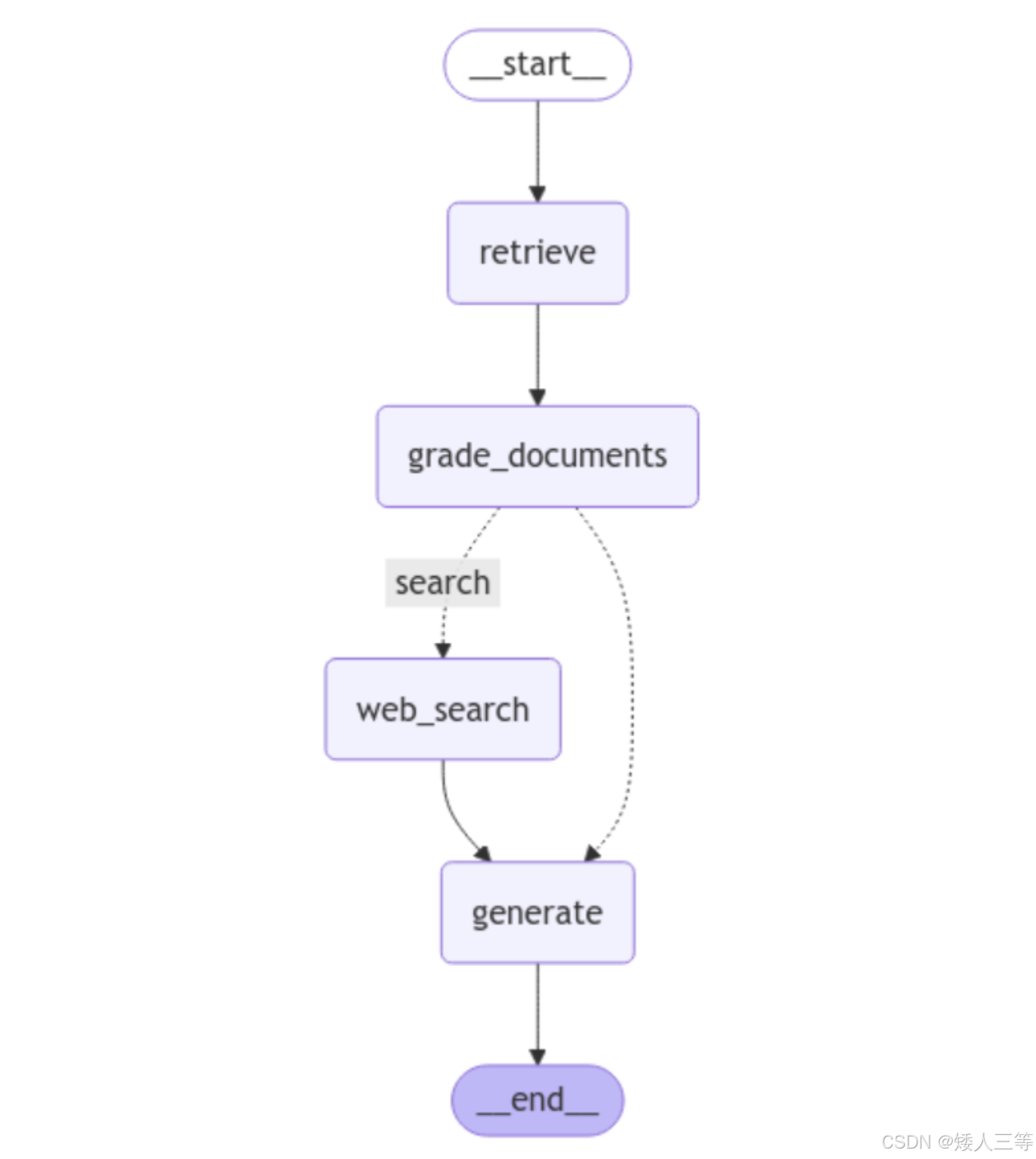
- 核心:引入 "检索质量评估 + 动态纠错" 机制,在检索结果质量不佳时通过网络搜索等外部源补充,提升生成的事实一致性与知识覆盖,尤其适合静态知识库不足或长尾问题场景。
- 注:Refinement:在检索文档阶段进行更细致的筛选和优化,确保用于生成的文档更加精准。目标是优化检索结果,并在生成之前提升生成的基础质量,CRAG 是检索端前置纠错的实现,Refinement 是其知识精炼模块
- 给基础 RAG 加了「检索结果的前置审核 + 联网补漏」,生成环节无思考、无回头
- 适用场景:静态知识库更新慢(实时)、长尾问题多、事实一致性要求高的场景(如客服、问答、内容创作)
- 实现流程:
- 基于传统检索:从本地知识库获取 Top-K 相关文档。
- 检索评估:评估器打分,按阈值判定三类置信度。
- 正确(高相关):知识精炼后直接喂给 LLM 生成。
- 错误(低相关):舍弃本地结果,调用 Web Search 获取补充信息。
- 不确定(中等相关):本地精炼 + Web Search 结果融合后生成。
- Web Search 联网搜索是纠错功能的核心
- 生成输出:基于筛选 / 融合后的知识生成最终答案。
-
-
Self-RAG(Self-Reflective Retrieval-Augmented Generation):是一种结合了自我反思或自我评估的 RAG 策略,用于提升从检索到生成的整个流程的质量。它在传统 RAG 框架的基础上,引入了额外的"自我检查"步骤,以更高效地评估和改进检索和生成结果。
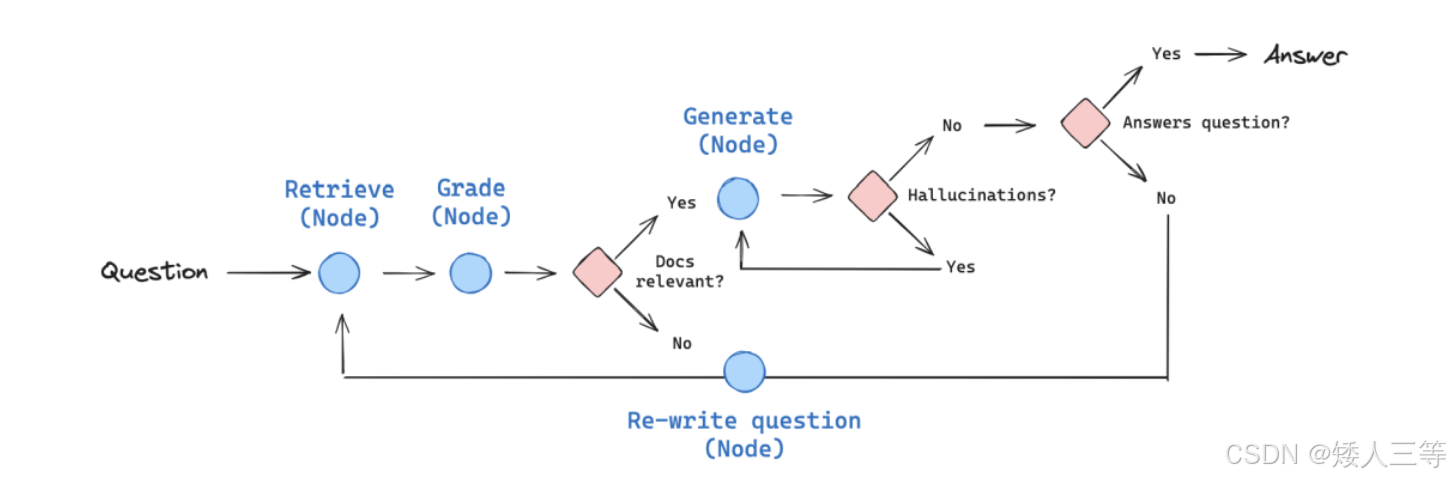
- 核心:让模型在生成中按需检索 + 自我评估 + 动态调整,解决传统 RAG"盲目检索、无归因、静态流程" 三大痛点,实现生成与检索的自适应协同
- 给基础 RAG 加了「生成中的自我思考能力」,用思考决定什么时候检索、用什么检索结果、怎么继续生成,无默认联网补漏。
- 实现流程:
- 输入查询,生成器初始生成并判断是否需检索,输出检索令牌触发检索。
- 检索器返回文档,生成器输出批评令牌评估相关性与支持度。
- 采纳有效证据、拒绝无效内容,继续生成;必要时多轮检索 / 反思。
- 最终生成带证据归因的输出,提升事实一致性与可靠性。
- 生成器:基础 LLM,生成时输出反思令牌(Reflection Tokens),决定是否检索、如何评估、是否采纳证据。
- 检索器(Retriever):接收到检索令牌后,从知识库按需获取相关文档,支持多轮触发。
- 反思器(Reflector/Critic):通过四类反思令牌评估检索相关性、生成一致性、证据支持度、答案实用性,指导生成决策。
- 检索令牌(Retrieve):触发检索。
- 批评令牌(Critic):评估检索 / 生成质量。
- 采纳令牌(Adopt):标记可用证据。
- 拒绝令牌(Reject):标记无效证据。
- 两阶段训练:先训评判模型(Critic)学习反思令牌标注;再训生成器(Generator)学习按需检索与反思,端到端优化决策与生成。
-
与 CRAG 互补:Self-RAG 做生成决策,CRAG 做检索评估与联网补充,可组合成 "反思 + 纠错" 双保险流程
特性 CRAG 传统 RAG Self-RAG 检索评估 前置评估,动态纠错 无评估,直接用检索结果 生成中反思,触发检索 纠错源 外部 Web Search 等 无外部纠错,依赖本地库 以本地库为主,反思后再检索 核心目标 提升检索鲁棒性,扩展知识覆盖 基础幻觉抑制 生成中动态补全信息
-
文档分块
- 固定大小分块:按预定义的字符数、单词数或 Token 数量对文本进行切分,同时保留一定的重叠部分。
- 缺点:按预定义的字符数、单词数或 Token 数量对文本进行切分,同时保留一定的重叠部分。
- 语义分块:根据有意义的单元对文档进行分段,持续将单元添加到现有块中,直到余弦相似度显著下降。一旦下降明显,就开始新的分块。
- 递归分块:基于内在分隔符(如段落或章节)进行分块。如果某个块的大小超过限制,则将其进一步分割为更小的块。
- 基于文档结构分块:利用文档的内在结构(如标题、章节或段落)进行分块。
- 基于 LLM 分块:使用提示引导 LLM 生成有意义的分块。
- 计算成本较高,并受限于 LLM 的上下文长度。