一、研究背景与核心问题
1. 推荐系统基础框架
工业级推荐系统通常分为匹配(Matching) 和排序(Ranking) 两阶段:
- 匹配阶段:从大规模候选池中快速召回数千个与用户兴趣相关的物品,核心要求是高效性 和扩展性(需处理海量数据);
- 排序阶段:精准预测用户与物品的交互概率,核心要求是预测精度。
2. 核心问题:用户冷启动(匹配阶段)
冷启动用户指交互行为稀疏(如新用户)的用户,现有方法存在明显局限:
- 传统协同过滤(CF)、深度学习模型(如强化学习、图网络、多兴趣网络)依赖丰富的用户行为序列,无法为冷启动用户学习高质量嵌入;
- 基于辅助信息的方法仅能惠及部分用户,且适配性有限;
- 元学习方法需计算二阶梯度,无法满足匹配阶段的扩展性需求;
- 现有研究多聚焦排序阶段的冷启动,匹配阶段的针对性解决方案极少。
论文目标:在匹配阶段高效建模冷启动用户,同时满足工业级推荐系统的扩展性要求。
二、核心贡献
论文提出的「Cold & Warm Net」针对上述问题,核心贡献有 3 点:
- 动态样本处理:通过冷启动专家(Cold-start Expert)和热身专家(Warm-up Expert)分别建模不同交互频率的用户,结合门网络(Gate Network)根据用户状态(如登录状态、活跃度)动态融合两专家结果,适配用户从冷启动到活跃的动态变化过程。
- 灵活教师选择器(动态知识蒸馏 DKD):设计动态知识蒸馏机制,根据预测精度为冷启动专家选择 "教师"(热身专家或标签),避免冷启动专家欠拟合,同时防止两专家训练后同化,确保冷启动用户信息充分学习。
- 显式行为偏差建模:通过偏置网络(Bias Net)显式建模冷启动用户的行为偏差(如冷启动用户与活跃用户的点击率差异),利用互信息(Mutual Information)筛选与用户行为高度相关的特征,提升预测的全面性。
三、模型架构与方法细节
Cold & Warm Net 整体由「原始冷温网络(Original Cold & Warm Net)」和「偏置网络(Bias Net)」两部分组成,最终输出为两部分分数的融合结果。其核心架构与关键模块的细节如下,结合图表可直观理解各组件的连接关系与数据流向:
1. 核心输入特征

2. 原始冷温网络(核心模块)
负责学习用户与物品的基础相似度分数,核心是「用户冷温嵌入层」,整体架构如图 1 所示:
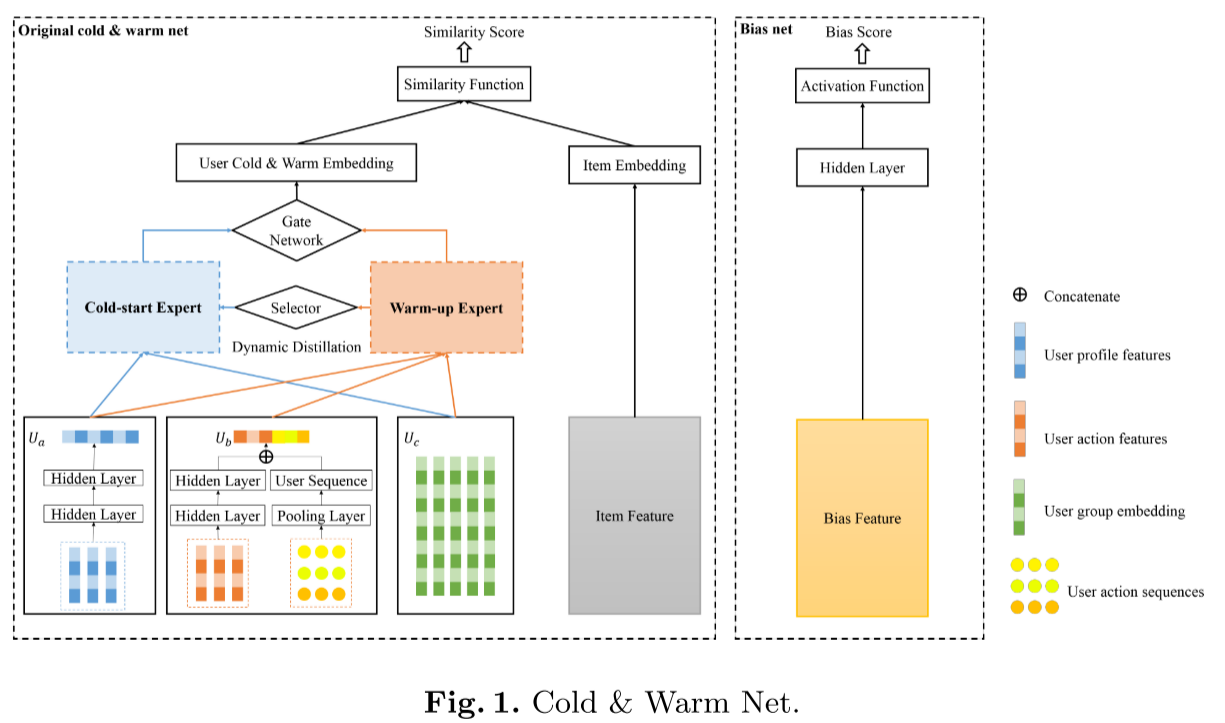

(注:图表展示了模型的整体流程:用户特征(画像 + 行为)与物品特征输入原始冷温网络,偏置特征输入偏置网络,经用户冷温嵌入层、物品嵌入层处理后,融合相似度分数与偏置分数得到最终输出。)

(1)用户冷温嵌入层(核心子模块)
该层是原始冷温网络的核心,主要由两个专家网络、门网络和动态知识蒸馏模块组成,细节如图 2 所示:
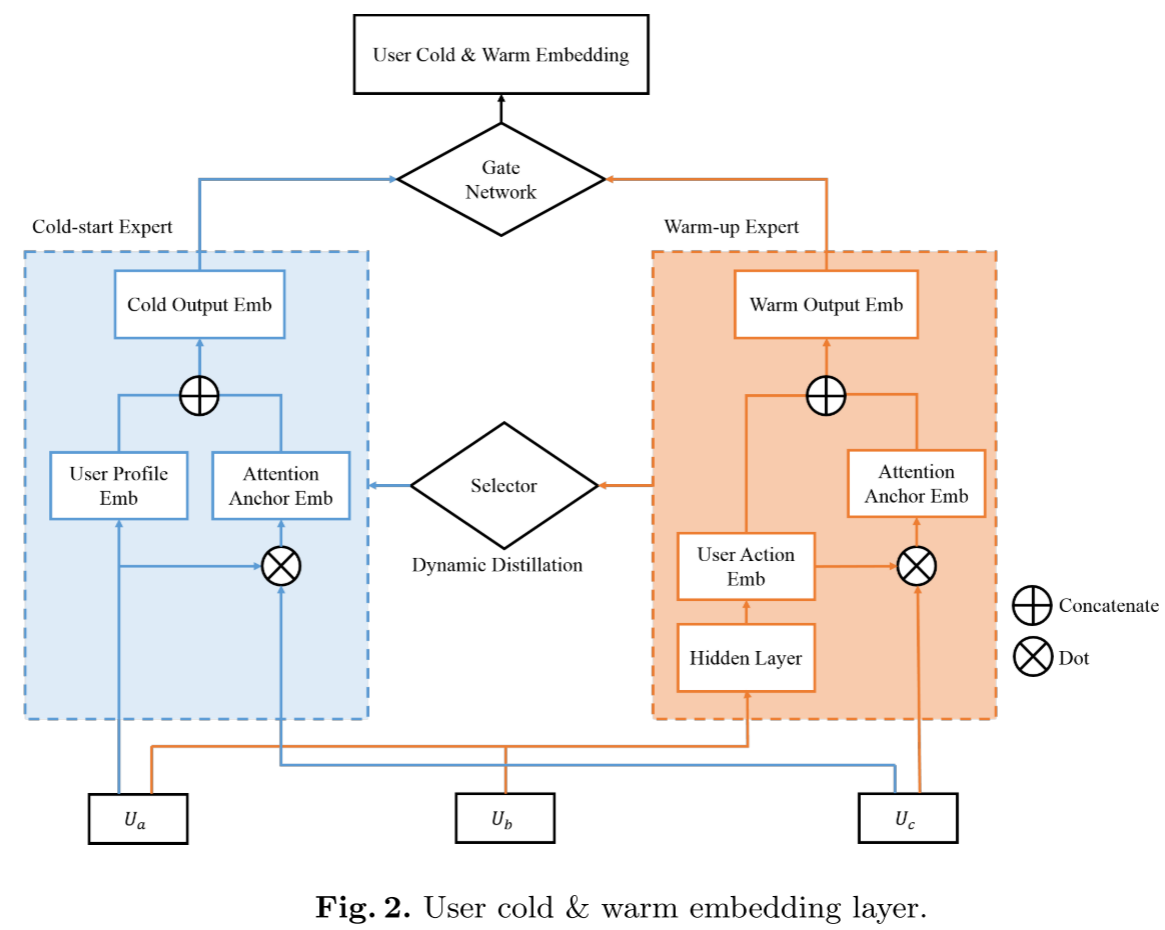


(注:图表展示了子模块的内部结构:用户画像嵌入、行为嵌入与用户组嵌入分别输入冷启动专家和热身专家,经注意力机制提取先验信息后,通过门网络动态融合输出,动态知识蒸馏模块实现两专家间的信息传递。)
结合图 2,该层的核心逻辑的是通过差异化专家建模与动态融合,适配不同状态用户的需求:



(2)动态知识蒸馏(DKD)


3. 偏置网络(Bias Net)

四、实验结果与分析
1. 实验设置
(1)数据集
| 数据集 | 用户数 | 物品数 | 交互数 | 场景说明 |
|---|---|---|---|---|
| MovieLens 1M | 6,040 | 3,706 | 1,000,209 | 公开推荐数据集(电影评分) |
| Little-World | 433,549 | 406,140 | 15,200,286 | 腾讯 QQ 短视频平台真实数据(脱敏) |
(2)对比模型
选取工业界匹配阶段常用模型:FM、YouTubeDNN、DSSM、Mind(多兴趣网络)、UMI(用户感知多兴趣模型)。
(3)评价指标
- 离线指标:Hit Rate(HR@K,召回率)、Normalized Discounted Cumulative Gain(NDCG@K,排序质量);
- 在线指标:APP 停留时间(APT)、用户留存率(URR)、视频完播率(VPI)、视频跳过率(VSR)。
2. 核心实验结果
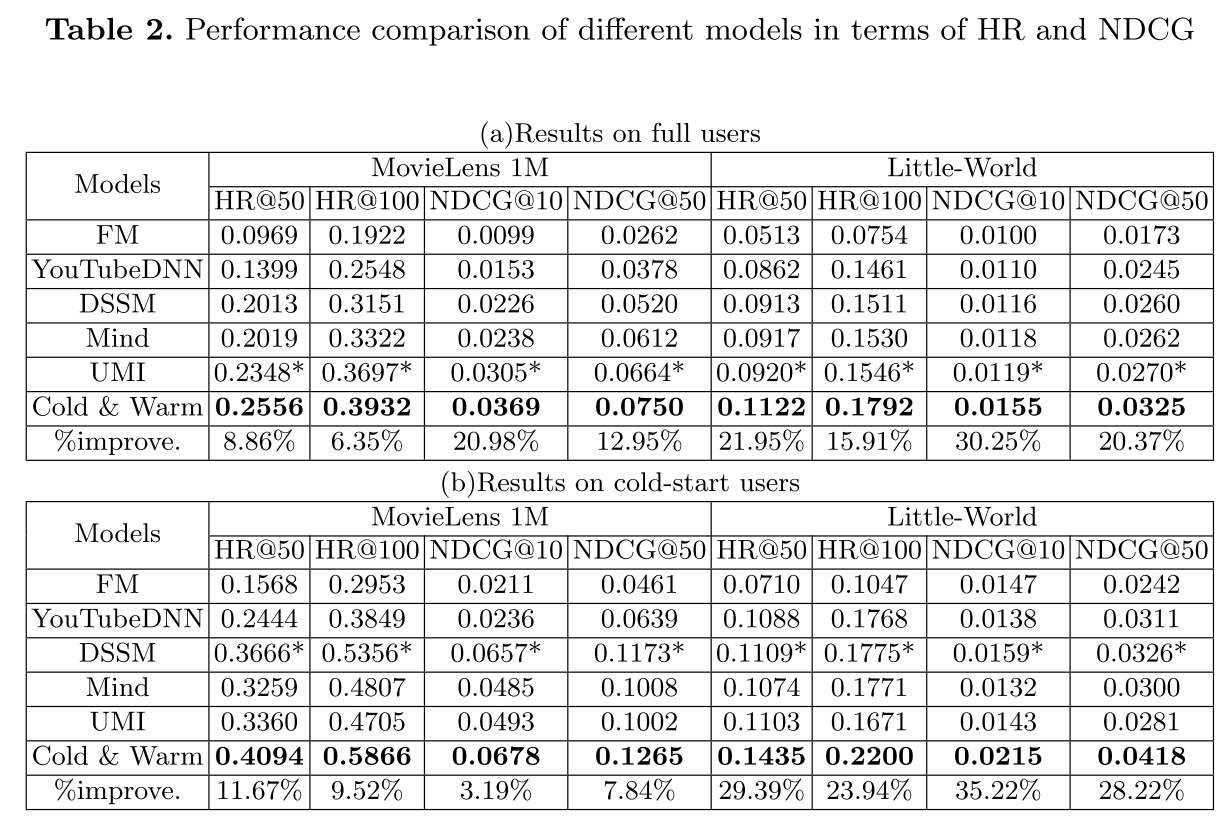
(1)离线性能(表 2)
- 全用户场景:Cold & Warm Net 在所有指标上最优,Little-World 数据集上 HR@50 提升 21.95%、NDCG@50 提升 20.37%(对比最优基线 UMI);
- 冷启动用户场景:提升更显著,Little-World 数据集上 HR@50 提升 29.39%、NDCG@50 提升 28.22%(对比最优基线 DSSM),验证了模型对冷启动用户的建模能力。
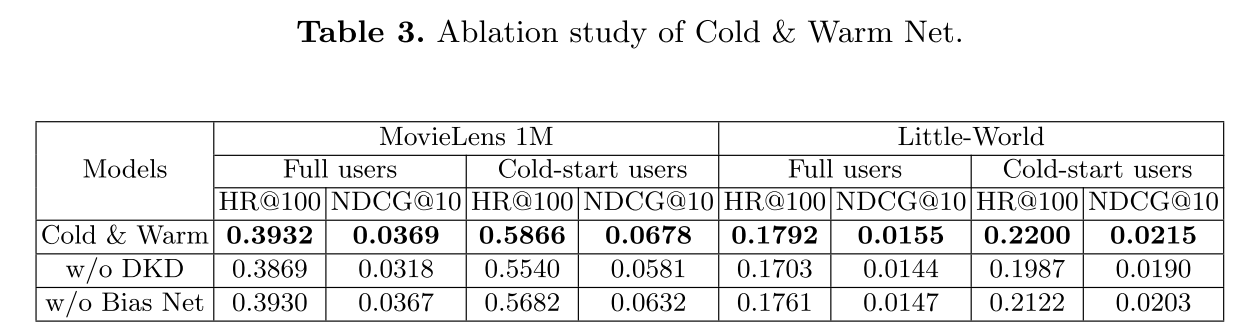
(2)消融实验(表 3)
验证 DKD 和偏置网络的有效性(冷启动用户场景):
- 移除 DKD(w/o DKD):HR@100 在两数据集分别下降 5.88% 和 10.72%,说明 DKD 是解决冷启动专家欠拟合的关键;
- 移除偏置网络(w/o Bias Net):HR@100 分别下降 3.24% 和 3.68%,说明显式建模行为偏差能补充关键信息。
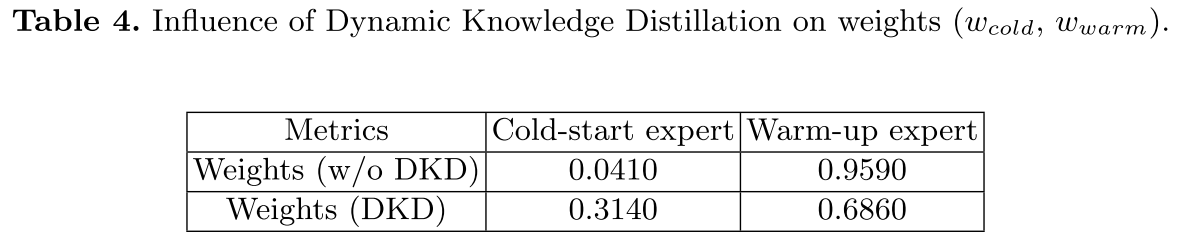
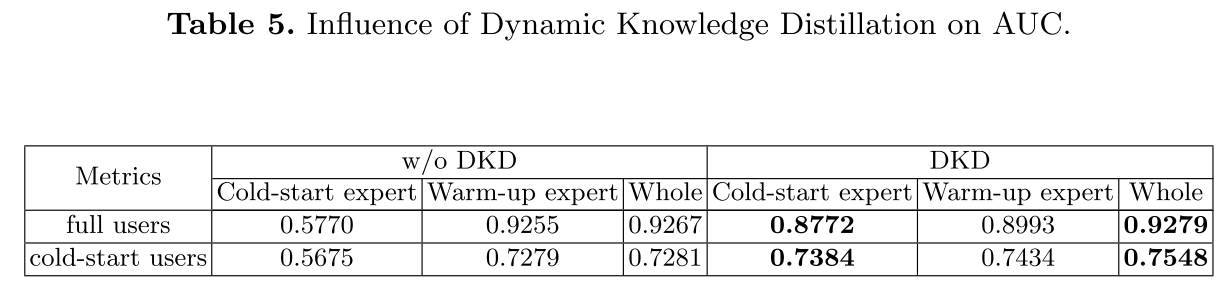
(3)DKD 机制分析(表 4、表 5)
- 权重变化:DKD 使冷启动专家权重从 0.0410 提升至 0.3140,避免其被热身专家 "压制";
- AUC 提升:冷启动专家 AUC 显著提升,全模型测试集 AUC 提升,验证 DKD 能促进冷启动专家充分学习。
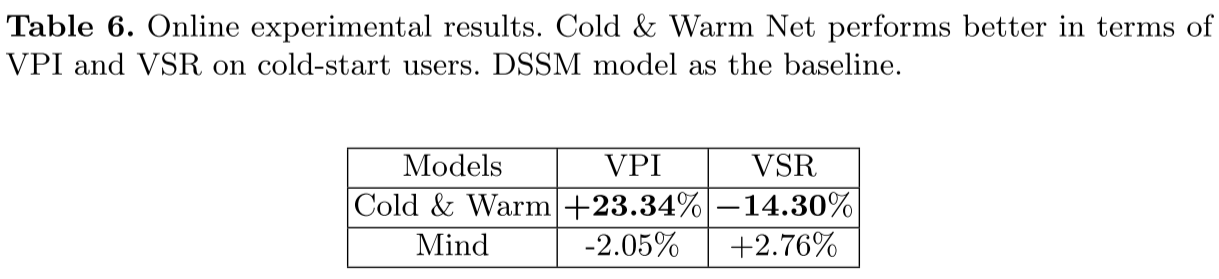
(4)在线实验(表 6)
部署于 Little-World 平台后的 A/B 测试结果(冷启动用户):
- 核心业务指标:APT (App Dwell Time应用停留时间)提升 3.27%,URR (User Retention Rate用户留存率)提升 1.01%;
- 用户满意度:VPI 提升 23.34%,VSR 下降 14.30%,显著优于基线 DSSM 和对比模型 Mind。
五、结论与展望
1. 核心结论
论文提出的 Cold & Warm Net 首次针对推荐系统匹配阶段的用户冷启动问题,通过 "双专家 + 门网络 + 动态知识蒸馏 + 偏置网络" 的设计,在保证扩展性的同时,高效建模冷启动用户,离线与在线实验均验证了其优越性,且已成功部署于工业级短视频平台。
2. 创新点总结
- 聚焦匹配阶段冷启动:填补了现有研究空白,满足工业级扩展性需求;
- 动态自适应架构:门网络与两专家适配用户状态动态变化,无需强制划分用户类型;
- 灵活蒸馏机制:DKD 根据预测精度动态选择教师,平衡欠拟合与专家同化问题;
- 显式偏差建模:通过互信息选特征,针对性解决冷启动用户的行为偏差。
3. 潜在方向
- 进一步优化用户组嵌入的生成方式(如用更精细的聚类或生成模型);
- 扩展至物品冷启动场景,构建统一的冷启动建模框架;
- 探索更高效的特征选择方法,提升偏置网络的适配性。
总结
该论文围绕推荐系统匹配阶段的用户冷启动痛点,提出了一套兼顾有效性 与扩展性的工业级解决方案。通过模块化设计(双专家、DKD、偏置网络),既解决了冷启动用户嵌入学习不足的问题,又满足了大规模候选池召回的效率要求,最终在真实场景中实现了业务指标与用户满意度的双重提升,具有重要的学术价值与工程实践意义。