Mike Ranzinger∗^{*}∗ Greg Heinrich∗^{*}∗ Collin McCarthy Jan Kautz Andrew Tao
Bryan Catanzaro Pavlo Molchanov
通过利用多教师蒸馏,聚合式视觉骨干网络提供了一个统一的学生模型,该模型保留并改进了多个教师的不同能力。在本技术报告中,我们描述了C-RADIO模型系列的最新版本C-RADIOv4,它在设计上基于AM-RADIO/RADIOv2.5,在相同计算复杂度下,在关键下游任务上提供了显著的改进。我们发布了-SO400M(412M参数)和-H(631M参数)模型变体,两者均使用更新的教师集进行训练:SigLIP2、DINOv3和SAM3。除了核心指标的改进和模仿SAM3获得的新能力外,C-RADIOv4模型系列进一步改进了对任意分辨率的支持,重新引入了用于大幅提升高分辨率下效率的ViTDet选项,并附带宽松许可证。
链接:代码(GitHub):https://github.com/NVlabs/RADIO | 模型(Hugging Face):https://huggingface.co/collections/nvidia/radio-669f77f1dd6b153f007dd1c6
https://arxiv.org/pdf/2601.17237
1. 描述
AM-RADIO171717引入了聚合式基础模型的概念,这是一种通过从其他异构模型中蒸馏特征表示来创建新基础模型的方法。在最初的构想中,我们使用DFN CLIP111111、DINOv2888和 SAM131313作为核心教师集。我们还引入了多分辨率训练的概念,即DFN CLIP和DINOv2在一个分辨率下进行蒸馏,而SAM在更高的分辨率下进行蒸馏。我们发现了一种称为"模式切换"的现象,即学生模型学会根据分辨率改变其表示以最小化训练损失,这导致在推理时根据使用的分辨率会产生非常不一致的行为。在PHI-S161616中,我们确定了教师分布平衡是训练强大聚合模型的重要组成部分;在RADIOv2.5121212中,我们发现同时在两个分辨率下对所有教师进行训练足以克服模式切换问题;在FeatSharp181818中,我们提出了一种适用于某些固定分辨率模型(如DFN CLIP和SigLIP24,2124, 2124,21)的上采样方法,这比双线性重采样更优。AM-RADIO原始论文中的一个关键点是,改进的教师往往会产生改进的学生,这一趋势仍在持续。自先前工作以来,SigLIP2212121已成为前沿的文本-图像基础编码器,DINOv3191919推动了自监督学习(SSL)和密集表示的边界,产生了一个极其强大的密集感知模型,而SAM已升级到SAM3666,在解决计算机视觉问题上取得了重大进展。秉承我们最初的设想,我们将核心教师集升级为SigLIP2,DINOv3,SAM3SigLIP2, DINOv3, SAM3SigLIP2,DINOv3,SAM3,以升级我们的聚合式模型。我们继承了DINOv3改进的语义分割能力,以及SigLIP2增强的文本对齐能力。SAM3作为教师在选定的基准测试上并未显示出改进的指标,但将其作为教师纳入,可以实现替换SAM3的视觉编码器骨干,以及利用聚合式模型的创造性用例,例如RADSeg333中的案例。除了简单地更新我们的教师集,我们通过改进模型在任意分辨率下运行的能力,进一步致力于提升其通用性,并重新引入"ViTDet模式",允许大多数Transformer块在窗口模式下运行,这对高分辨率图像下的推理速度有显著影响(见图9)。
2. 方法更新
聚合式模型依赖于从多个视觉基础模型中进行蒸馏。对于RADIO系列模型,蒸馏在密集特征空间和汇总标记上同时进行。在本节中,我们描述了用于开发改进的C-RADIOv4模型相较于先前变体的新颖技术,形式为自我们在RADIOv2.5121212中完全描述方法以来所发生的变化。
2.1. 更新的教师集
对于C-RADIOv4,我们将教师集更新为:
• SigLIP2-g-384 21
• DINOv3-7B 19
• SAM3 6
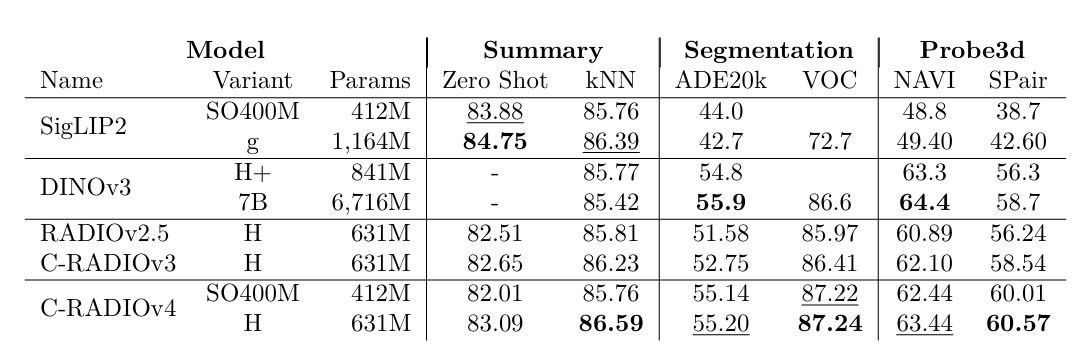
表 1 | 不同视觉编码器之间的比较。在密集任务上,C-RADIOv4以少得多的参数与DINOv3相竞争。

图 1 | PCA特征可视化,比较C-RADIOv3-H与C-RADIOv4-H。物体边界现在明显更清晰。
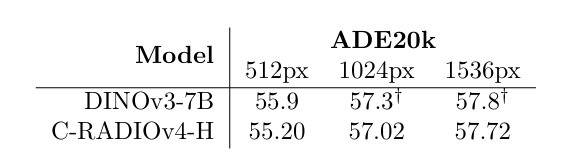
表 2 | DINOv3-7B和C-RADIOv4-H在ADE20k252525线性探测任务上的分辨率缩放比较。两个模型都表现出强大的分辨率缩放特性。†\dagger†DINOv3-7B的指标来自191919中的图11,其中小数点后的值是近似值。
为了减少计算需求,我们在此版本中放弃了DFN CLIP111111的支持,转而采用更普遍的SigLIP2212121,因为后者正在更多地方部署(例如Qwen3 VL444),并且两个模型具有相似的表征和应用领域。
2.2. 随机分辨率
与RADIOv2.5121212中在两个不同分辨率下训练不同,我们在低分辨率分区中从{128,192,224,256,384,432}\{128, 192, 224, 256, 384, 432\}{128,192,224,256,384,432}采样,在高分辨率分区中从{512,768,1024,1152}\{512, 768, 1024, 1152\}{512,768,1024,1152}采样,从而实现更平滑的分辨率缩放曲线,同时在低分辨率下获得显著的质量提升。对于SigLIP2212121,我们使用FeatSharp181818在高分辨率训练分区中将图像从384像素上采样3倍至1152像素。低分辨率分区使用原始输出。最后,对于SAM3,我们使用RADIOv2.5121212中提出的马赛克增强,因为它仅支持1152×11521152 \times 11521152×1152大小的输入。图3和图4展示了多分辨率支持随时间的变化,其中图4显示了RADIO模型与同样支持多分辨率的DINOv2/3的比较。在表2中,我们展示了C-RADIOv4在提高语义分割分辨率方面具有很强的鲁棒性,包括在高于训练分辨率的条件下。考虑到C-RADIOv4-H的参数数量比DINOv3-7B少一个数量级,它的表现非常有竞争力。
2.3. 平移等变性
自PHI-S 16以来,特征损失的公式一直是1Z∑i(x−y^)2\frac{1}{Z}\sum_{i}(x-\hat{y})^{2}Z1∑i(x−y^)2,其中y^\hat{y}y^是经PHI-S归一化的教师特征,x是学生预测,Z是归一化常数。这种方法的一个缺点是,学生不仅在学习教师的有用特征,还在学习固定的模式噪声。在DVT 23中,作者发现所有这些视觉基础模型都有这种噪声,他们将模型的输出解耦为ViT(x)≈f(x)+g(Epos)+h(x,Epos)ViT(x) \approx f(x) + g(E_{pos}) + h(x, E_{pos})ViT(x)≈f(x)+g(Epos)+h(x,Epos),其中f是依赖于输入的语义,g是数据不变的偏差,h是纠缠的残差。我们在FeatSharp 18工作中也识别出了相同的噪声模式,尤其是SigLIP2模型,它们的输出特征图边界上有这些"空洞"。SAM 13在ViTDet 14窗口的边界上有强烈的伪影。DINOv3-H+则偶尔会有大范围的噪声斑块。在所有情况下,如果不加以缓解,模型将学会在MLP适配器中模仿这种噪声,并且它会泄漏到骨干特征中。我们通过损失公式中的两种不同形式的平移等变性来对抗这一点,这两种形式都使学生无法知道学生和教师之间匹配的补丁的确切位置。我们在图2中可视化了这些伪影,其中高能量的表征出现在原本大致均匀的图像区域中。
2.3.1. 平移等变损失
为了防止学生匹配那些不是明确依赖于输入的语义232323的密集教师特征,对于特定图像,我们随机移动学生看到的裁剪区域,以及每个教师看到的裁剪区域。教师之间以及相对于学生都获得独立的平移。我们跟踪一个映射FS→TF_{S\rightarrow T}FS→T,该映射将学生产生的特征变换为与教师在空间上对齐。采样的平移增量是补丁大小的整数倍,这尽可能消除了插值效应。因此,我们采用以下新的损失公式:
Lspatial(x,y^)=1∣Ω∣∑u∈Ω(FS→Txu−y^u)2.L_{\mathrm{s p a t i a l}}(\mathbf{x},\hat{\mathbf{y}})=\frac{1}{|\Omega|}\sum_{u\in\Omega}\left(\mathcal{F}{S\rightarrow T}\\mathbf{x}{u}-\hat{\mathbf{y}}_{u}\right)^{2}.Lspatial(x,y^)=∣Ω∣1u∈Ω∑(FS→Txu−y^u)2.
其中Ω\OmegaΩ是学生和教师共同看到的空间位置集合,x是学生输出,y^\hat{y}y^是PHI-S 16 归一化的教师输出。
2.3.2. 平移等变MESA
MESA999是训练分类模型不可或缺的工具,它试图将权重收敛到平坦区域,其中输入的扰动不会导致输出的混沌变化,从而改进泛化能力。为了进一步防止固定模式噪声出现在我们的学生模型中,我们应用了MESA公式来匹配学生模型的指数移动平均(EMA),但增加了一个新技巧:为学生及其EMA引入不同的裁剪,并通过FS→SˉF_{S\rightarrow\bar{S}}FS→Sˉ变换关联它们,然后使用以下公式:

图 2 | DINOv3和C-RADIOv4(适配器)预测的可视化。注意DINOv3产生的不合时宜的斑点。
第1列:输入图像
第2列:DINOv3 PCA可视化。
第3列:C-RADIOv4适配器PCA可视化。
第4列:学生适配器预测与DINOv3教师之间的误差热图。
Lmesa(x,x~)=1∣Ω∣∑u∈Ω(FS→S~LN(x)u−LN(x~)u)2L_{m e s a}(\mathbf{x},\tilde{\mathbf{x}})=\frac{1}{|\Omega|}\sum_{u\in\Omega}\left(\mathcal{F}{S\rightarrow\tilde{S}}\leftL N(\\mathbf{x})\\right{u}-L N(\tilde{\mathbf{x}})_{u}\right)^{2}Lmesa(x,x~)=∣Ω∣1u∈Ω∑(FS→S~LN(x)u−LN(x~)u)2
其中LN是层归一化,不包含可学习的仿射投影,S~,x~\tilde{S}, \tilde{x}S~,x~分别是EMA学生模型的裁剪和输出。
2.4. DAMP
为了进一步增强我们模型的鲁棒性,我们采用了DAMP 20,它在训练期间对模型的权重施加乘性噪声。

表 3 | 关键教师的汇总标记的角度离散度。
2.5. 平衡的汇总损失
在PHI-S161616中,整个研究围绕对每个教师的空间特征分布进行归一化展开,这样大的激活就不会主导损失。然而,对汇总特征没有给予关注。原因是汇总特征是使用余弦相似度进行匹配的,它本质上是归一化的。然而,我们后来注意到,虽然汇总特征的大小被归一化到单位超球面上,但它们的方向方差却没有。如果教师产生的特征在单位超球面上呈均匀分布,这并不重要,但我们发现特征往往落在一个锥体内,而这个锥体的半径对于每个教师是不同的。其影响是,半径较大的锥体将产生较大的损失,而半径较小的锥体损失则较小。此外,重要的不是学生和教师之间的角度,而是该角度相对于所有其他嵌入的角度。为了缓解这个问题,我们不再使用余弦距离作为汇总损失,而是采用以下公式:
cos(x,y)=x⊺y∥x∥∥y∥\cos(\mathbf{x},\mathbf{y})=\frac{\mathbf{x}^{\intercal}\mathbf{y}}{\|\mathbf{x}\|\|\mathbf{y}\|}cos(x,y)=∥x∥∥y∥x⊺y
Θ(x,y)=arccos(cos(x,y))\Theta(\mathbf{x},\mathbf{y})=\operatorname{arccos}(\cos(\mathbf{x},\mathbf{y}))Θ(x,y)=arccos(cos(x,y))
μy=Ey∥Ey∥\boldsymbol{\mu}_{\mathbf{y}}=\frac{\mathbb{E}\\mathbf{y}}{\|\mathbb{E}\\mathbf{y}\|}μy=∥Ey∥Ey
Disp(Θy)=EΘ(y,μy)2\mathrm{D i s p}(\Theta_{\mathbf{y}})=\mathbb{E}\left\\Theta\\left(\\mathbf{y},\\boldsymbol{\\mu}_{\\mathbf{y}}\\right)\^{2}\\rightDisp(Θy)=EΘ(y,μy)2
Langle(x,y)=Θ(x,y)2Disp(Θy)L_{angle}(\mathbf{x},\mathbf{y})=\frac{\Theta(\mathbf{x},\mathbf{y})^{2}}{Disp(\Theta_{\mathbf{y}})}Langle(x,y)=Disp(Θy)Θ(x,y)2
其中x是学生预测,y是教师预测,μy\mu_{y}μy是y的期望方向,Disp(Θy)\text{Disp}(\Theta_{y})Disp(Θy)是y的角度离散度,我们用它来归一化教师之间的锥体半径,使学生能够专注于相对角度,并防止一个教师主导另一个教师。我们在表3中报告了发现的角度离散度,显示SigLIP2和DINOv3之间存在显著差异。如果不加以缓解,DINOv3将主导损失项,使学生偏向于匹配它,而牺牲对SigLIP2的匹配。
3. 结果
3.1. 指标
在图3中,我们展示了RADIOv2.5和各个版本的C-RADIO的零样本准确率。我们注意到RADIOv2.5和C-RADIOv2没有SigLIP2对齐头,因此我们使用它们的DFN CLIP头报告准确率。一般来说,DFN CLIP对学生模型来说更容易匹配,因此,直到C-RADIOv4之前,我们都无法达到先前RADIOv2.5模型的零样本准确率。所有显示的模型都表现出强大的分辨率缩放能力,然而,C-RADIOv4相对于之前的模型代际,显著改进了低分辨率下的分类。我们使用保持长宽比的尺寸调整,在1024像素分辨率下达到了最大零样本分数。
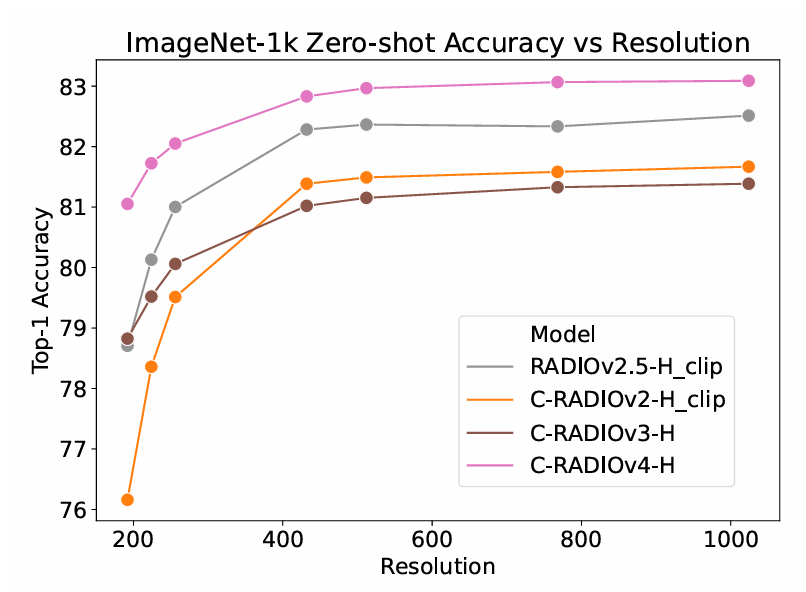
图 3 | ImageNet-1K零样本准确率随输入分辨率的变化。
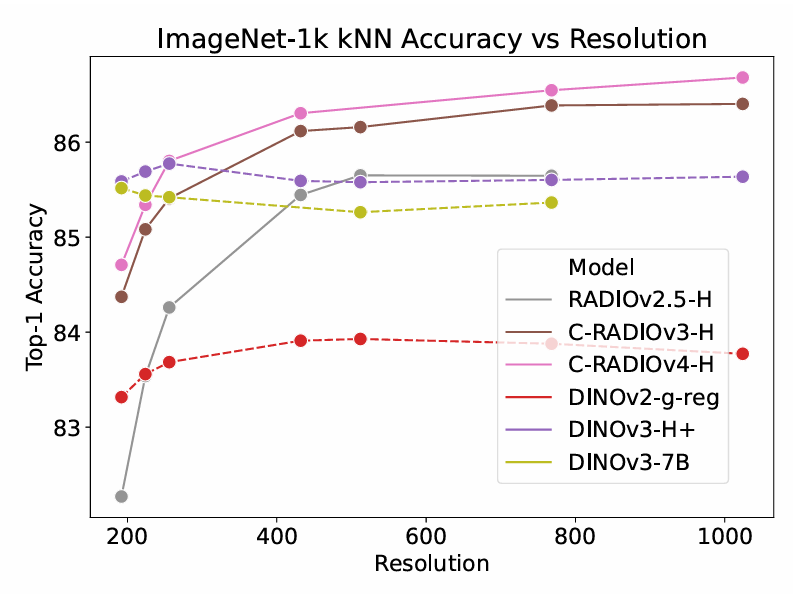
图 4 | ImageNet-1K kNN准确率随输入分辨率的变化。
我们能够通过k-近邻(k-Nearest Neighbors)分类直接与DINOv2/3模型进行比较,如DINOv2和先前RADIO工作所用。我们在图4中展示了这些结果,可以看到DINOv3在k-NN分类上相比DINOv2有了巨大改进,然而,分辨率缩放能力主要集中在192-256像素附近,更高分辨率会下降。对于RADIO,C-RADIO模型相对于RADIOv2.5有显著改进,C-RADIOv4总体上比C-RADIOv3略好。这表明C-RADIOv3在零样本方面的问题更可能源于匹配SigLIP2的具体问题,而不是缺乏良好的整体表征。尽管如此,C-RADIOv4对两个任务仍然是一个改进。有趣的是,DINOv3的H+模型在kNN分类上优于7B模型。从256像素开始,C-RADIOv4-H能够匹配或超过DINOv3。
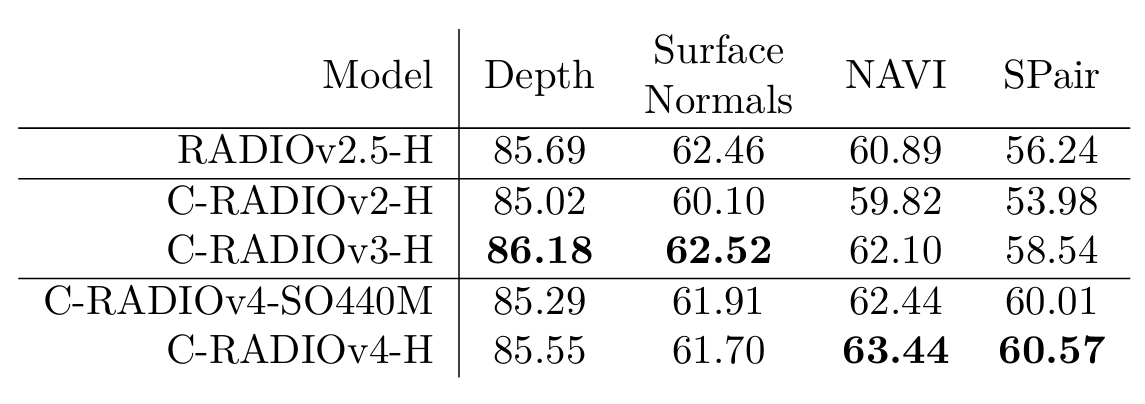
表 4 | 各种RADIO模型的完整Probe3d\[10\]评估。所有指标越高越好。
3.2. SAM3
旧版本的RADIO支持SAM131313适配器,允许RADIO替换SAM的视觉编码器,同时使用其解码和记忆堆栈来执行分割。这种能力在RADSeg333等工作中找到了巧妙的用途,该工作使用SAM头来细化分割掩码,并为开放词汇语义分割设定了新的最先进水平。C-RADIOv4将我们的SAM支持升级到SAM3666,再次允许替换核心视觉模型。我们在 https://github.com/mranzinger/sam3-radio 上有一个SAM3代码库的分支,演示了如何进行这种替换。在图6和图7中,我们展示了RADIO替换视觉编码器的能力,首先是SAM3提供的图像演示,第二是我们自己的图像,带有不同的查询。从质量上看,RADIO在代替SAM3的Perception Encoder555骨干时没有任何问题。在表5中,我们展示了在SA-Co/Gold666实例分割上的基准测试结果。C-RADIOv4成为第二好的模型,尽管,在替换SAM3视觉编码器的能力上存在不均。在由自然图像主导的"metaclip_nps"和"sa1b_nps"上,RADIO表现得相当好,与SAM3的差距较小,然而,在"fg_sports_equipment"和"wiki_common"上,差距变得更大。改进我们更好地匹配SAM3的能力是一个开放的研究方向。
C-RADIOv4支持"ViTDet模式"14^{14}14,该模式允许模型要么以完全全局注意力运行(例如,禁用ViTDet模式),要么以大部分窗口注意力以及少数几层全局注意力运行。这可以通过构造模型时的"vitdet_window_size"标志来控制。SAM3使用ViT-L+架构,具有4个全局层,其余层使用24×2424 \times 2424×24标记的窗口。为了提高效率,C-RADIOv4支持6×66 \times 66×6到32×3232 \times 3232×32标记之间的任何窗口大小,唯一的限制是窗口大小乘以补丁大小需要能够整除输入图像分辨率。较小的窗口可能更快,因为它减少了自注意力222222的二次惩罚,然而,硬件可能会减少/消
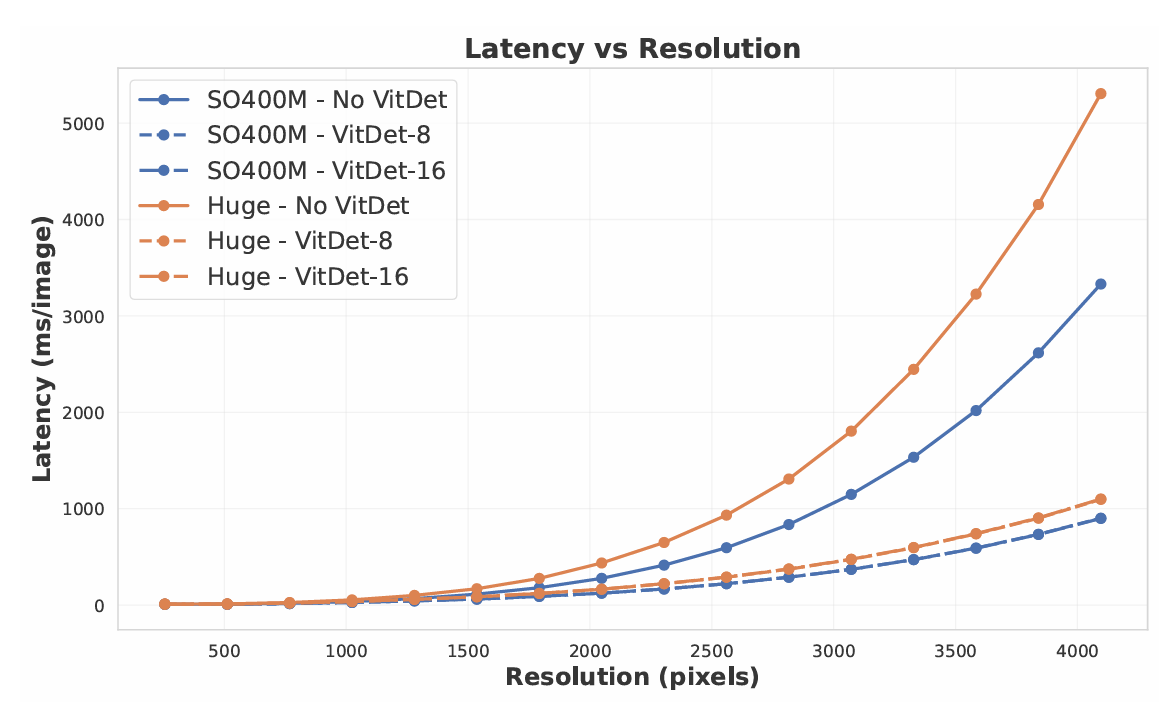
图 5 | 在A100上对两个版本的C-RADIOv4(有和没有指定窗口大小的ViTDet)进行延迟分析。窗口大小为8和16的ViTDet模式之间的延迟差异可以忽略不计。
除相似窗口大小之间的差距,并且较小的窗口可能会带来轻微的质量下降。我们在图9中展示了在A100 GPU上单图像推理的时间。对于SO400M模型,窗口大小≤12\leq12≤12比SAM3的编码器更快。ViT-H RADIO的窗口大小为8时几乎一样快。我们还在图5中展示了两个C-RADIOv4模型在256像素到4096像素分辨率下,有和没有ViTDet的延迟。虽然ViTDet并没有将模型的复杂度从O(T2)O(T^{2})O(T2)改变(T是标记数量),但由于4层仍然使用全局注意力,它确实显著降低了增长因子。
"人"的奇特案例 在SAM3的GitHub上(截至2026年1月14日),有一个GitHub issue 253指出,SAM3的GitHub示例在使用"人"查询时不能正常工作。我们能够复现这种行为。然而,当使用C-RADIOv4作为视觉骨干时,查询按预期工作。我们在图8中展示了这种行为。RADIO变体在全局注意力模式以及ViTDet窗口大小为8的情况下都能工作(其他窗口大小可能也能工作,我们只测试了这两种)。这似乎表明两个视觉编码器之间表征的细微差异对这个特定查询产生了阈值效应。
4. 结论
得益于基础基础模型的改进,特别是DINOv3 19,以及我们蒸馏算法的改进,C-RADIOv4比其前代模型有了巨大提升。与之前的发布不同,我们包含了一个SO400M 1版本,它通常能够与ViT-H竞争,同时成本更低。我们展示了如何将C-RADIOv4用于替换SAM3666中的视觉编码器,并且使用ViTDet窗口大小≤12\leq 12≤12的SO400M变体,它甚至比SAM3使用的ViT-L+ Perception Encoder555更快。过去的RADIO模型已被广泛使用,包括在Nemotron Nano V2 VL151515视觉语言模型、自动驾驶汽车、机器人、OCR文档解析777、开放词汇语义分割3,23, 23,2等众多应用中。鉴于其商业上宽松的许可证,我们希望学术界和工业界都能利用这个基础模型来构建伟大的产品。

图 6 | SAM3图像演示的掩码结果,要么使用常规SAM3,要么将视觉编码器替换为RADIO。RADIO能够复现SAM3的结果。
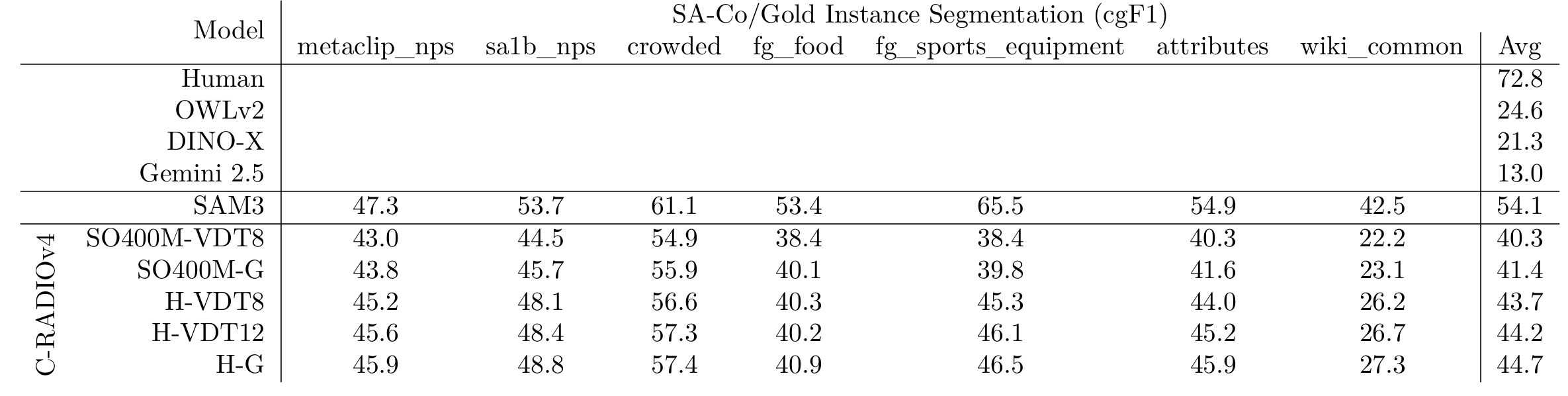
表 5 | SA-Co/Gold\[6\]实例分割上的结果。"VDT"指ViTDet窗口大小W,而"G"指全程全局注意力。

图 7 | 用RADIO替换SAM3视觉编码器,同时保持解码器不变的文本查询结果。
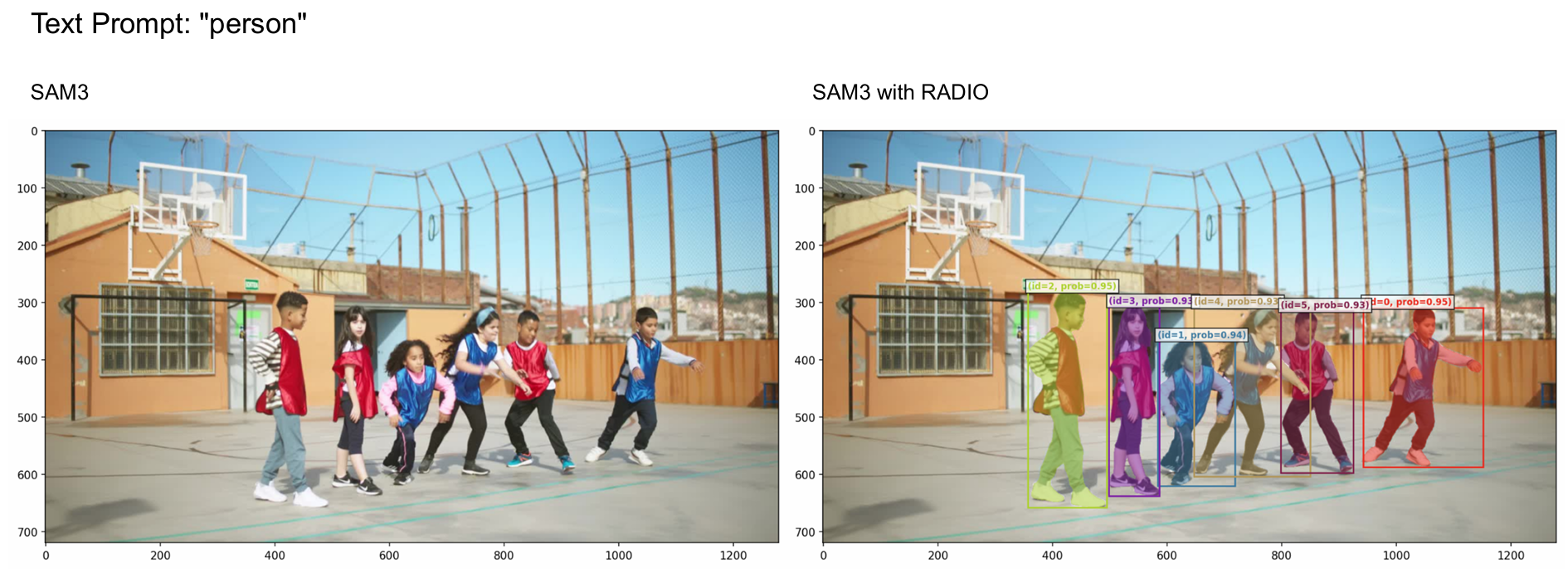
图 8 | SAM3演示(GitHub问题)无法使用"person"查询进行掩码,而C-RADIOv4-SO400M,H却工作得很好。
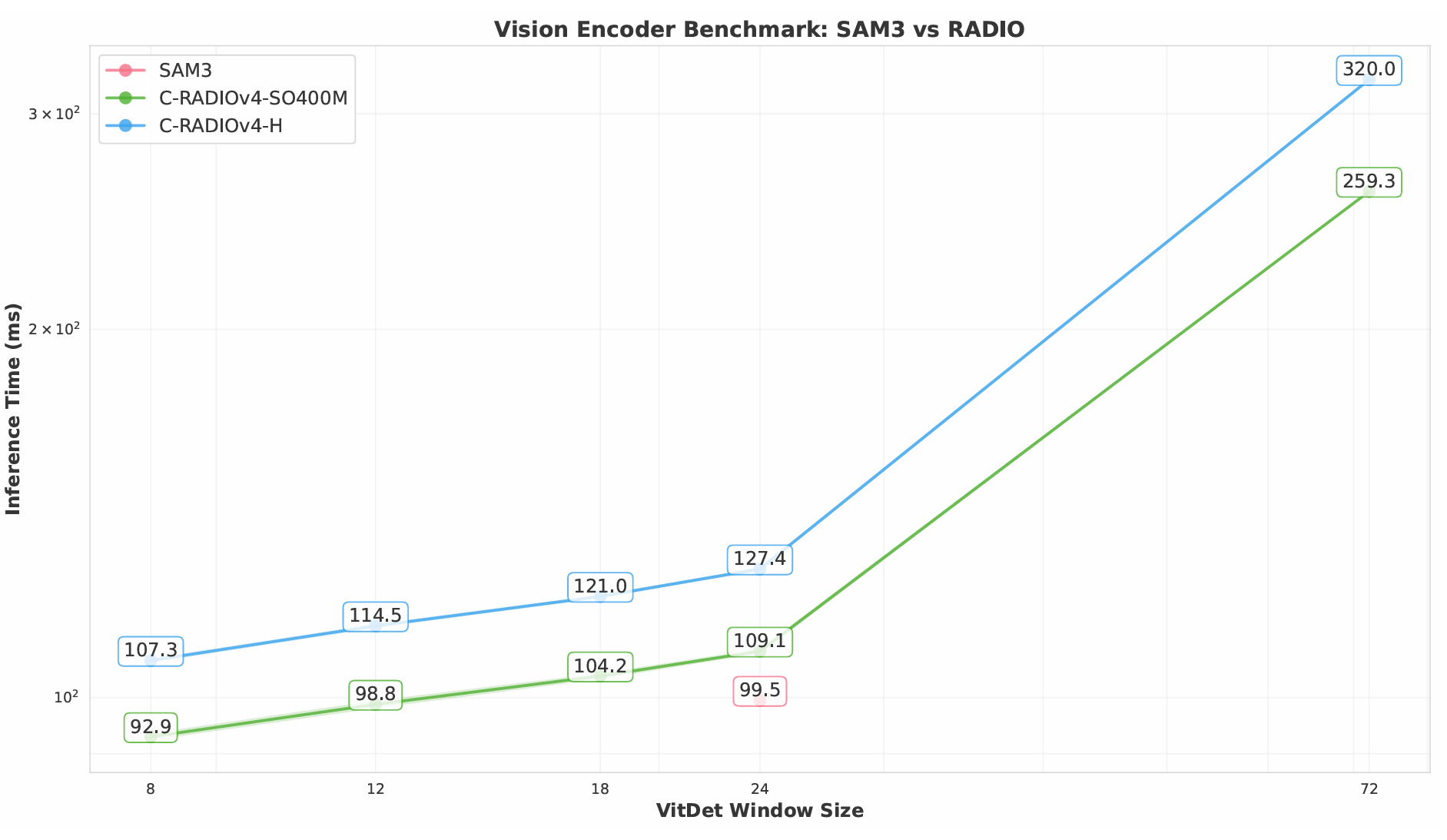
图 9 | SAM3与RADIO视觉编码器在A100上的单图像基准测试结果,包括SO400M和Huge两种尺寸。SAM3使用窗口大小为24的ViT-L+架构。窗口大小为72等同于完全全局注意力。
参考文献
1 Ibrahim Alabdulmohsin, Xiaohua Zhai, Alexander Kolesnikov, and Lucas Beyer. Getting vit in shape: Scaling laws for compute-optimal model design. In Thirty-seventh Conference on Neural Information Processing Systems, 2023.
2 Omar Alama, Avigyan Bhattacharya, Haoyang He, Seungchan Kim, Yuheng Qiu, Wenshan Wang, Cherie Ho, Nikhil Keetha, and Sebastian Scherer. Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5930--5937, 2025.
3 Omar Alma, Darshil Jariwala, Avigyan Bhattacharya, Seungchan Kim, Wenshan Wang, and Sebastian Scherer. Radseg: Unleashing parameter and compute efficient zero-shot open-vocabulary segmentation using agglomerative models, 2025.
4 Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan Liu, Dunjie Lu, Ruilin Luo, Chenxu Lv, Rui Men, Lingchen Meng, Xuancheng Ren, Xingzhang Ren, Sibo Song, Yuchong Sun, Jun Tang, Jianhong Tu, Jianqiang Wan, Peng Wang, Pengfei Wang, Qiuyue Wang, Yuxuan Wang, Tianbao Xie, Yiheng Xu, Haiyang Xu, Jin Xu, Zhibo Yang, Mingkun Yang, Jianxin Yang, An Yang, Bowen Yu, Fei Zhang, Hang Zhang, Xi Zhang, Bo Zheng, Humen Zhong, Jingren Zhou, Fan Zhou, Jing Zhou, Yuanzhi Zhu, and Ke Zhu. Qwen3-vl technical report, 2025.
5 Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Abdul Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Shang-Wen Li, Piotr Dollar, and Christoph Feichtenhofer. Perception encoder: The best visual embeddings are not at the output of
the network. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025.
6 Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane Momeni, Rishi Hazra, Shuangrui Ding, Sagar Vaze, Francois Porcher, Feng Li, Siyuan Li, Aishwarya Kamath, Ho Kei Cheng, Piotr Dollár, Nikhila Ravi, Kate Saenko, Pengchuan Zhang, and Christoph Feichtenhofer. SAM 3: Segment anything with concepts, 2025.
7 Kateryna Chumachenko, Amala Sanjay Deshmukh, Jarno Seppanen, Ilia Karmanov, Chia-Chih Chen, Lukas Voegtle, Philipp Fischer, Marek Wawrzos, Saeid Motiian, Roman Ageev, Kedi Wu, Alexandre Milesi, Maryam Moosaei, Krzysztof Pawelec, Padmavathy Subramanian, Mehrzad Samadi, Xin Yu, Celina Dear, Sarah Stoddard, Jenna Diamond, Jesse Oliver, Leanna Chraghchian, Patrick Skelly, Tom Balough, Yao Xu, Jane Polak Scowcroft, Daniel Korzekwa, Darragh Hanley, Sandip Bhaskar, Timo Roman, Karan Sapra, Andrew Tao, and Bryan Catanzaro. Nvidia nemotron parse 1.1, 2025.
8 Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. In Proceedings of the 12th International Conference on Learning Representations (ICLR), 2024.
9 Jiawei Du, Zhou Daquan, Jiashi Feng, Vincent Tan, and Joey Tianyi Zhou. Sharpness-aware training for free. In Advances in Neural Information Processing Systems, 2022.
10 Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, and Varun Jampani. Probing the 3D Awareness of Visual Foundation Models. In CVPR, 2024.
11 Alex Fang, Albin Madappally Jose, Amit Jain, Ludwig Schmidt, Alexander Toshev, and Vaishaal Shankar. Data filtering networks, 2023.
12 Greg Heinrich, Mike Ranzinger, Hongxu Yin, Yao Lu, Jan Kautz, Andrew Tao, Bryan Catanzaro, and Pavlo Molchanov. Radiov2.5: Improved baselines for agglomerative vision foundation models. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 22487--22497, 2025.
13 Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloé Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross B. Girshick. Segment anything. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3992--4003, 2023.
14 Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. In Computer Vision -- ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23--27, 2022, Proceedings, Part IX, page 280--296, Berlin, Heidelberg, 2022. Springer-Verlag.
15 NVIDIA, :, Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Guo Chen, Karan Sapra, Zhiding Yu, Adi Renduchintala, Charles Wang, Peter Jin, Arushi Goel, Mike Ranzinger, Lukas Voegtle, Philipp Fischer, Timo Roman, Wei Ping, Boxin Wang, Zhuolin Yang, Nayeon Lee, Shaokun Zhang, Fuxiao Liu, Zhiqi Li, Di Zhang, Greg Heinrich, Hongxu Yin, Song Han, Pavlo Molchanov, Parth Mannan, Yao Xu, Jane Polak Scowcroft, Tom Balough, Subhashree Radhakrishnan, Paris Zhang, Sean Cha, Ratnesh Kumar, Zaid Pervaiz Bhat, Jian Zhang, Darragh Hanley, Pritam Biswas, Jesse Oliver, Kevin Vasques, Roger Waleffe, Duncan Riach, Oluwatobi Olabiyi, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Pritam Gundecha, Khanh Nguyen, Alexandre Milesi, Eugene Khvedchenia, Ran Zilberstein, Ofri Masad, Natan Bagrov, Nave Assaf, Tomer Asida, Daniel Afrimi, Amit Zuker, Netanel Haber, Zhiyu Cheng, Jingyu Xin, Di Wu, Nik Spirin, Maryam Moosaei, Roman Ageev, Vanshil Atul Shah, Yuting Wu, Daniel Korzekwa, Unnikrishnan Kizhakkemadam Sreekumar, Wanli Jiang, Padmavathy Subramanian, Alejandra Rico, Sandip Bhaskar, Saeid Motiian, Kedi Wu, Annie Surla, Chia-Chih Chen, Hayden Wolff, Matthew Feinberg, Melissa Corpuz, Marek Wawrzos, Eileen Long, Aastha Jhunjhunwala, Paul Hendricks, Farzan Memarian, Benika Hall, Xin-Yu Wang, David Mosallanezhad, Soumye Singhal, Luis Vega, Katherine Cheung, Krzysztof Pawelec, Michael Evans, Katherine Luna, Jie Lou, Erick Galinkin, Akshay Hazare, Kaustubh Purandare, Ann Guan, Anna Warno, Chen Cui, Yoshi Suhara, Shibani Likhite, Seph Mard, Meredith Price, Laya Sleiman, Saori Kaji, Udi Karpas, Kari Briski, Joey Conway, Michael Lightstone, Jan Kautz, Mohammad Shoeybi, Mostofa Patwary, Jonathan Cohen, Oleksii Kuchaiev, Andrew Tao, and Bryan Catanzaro. Nvidia nemotron nano v2 vl, 2025.
16 Mike Ranzinger, Jon Barker, Greg Heinrich, Pavlo Molchanov, Bryan Catanzaro, and Andrew Tao. Phis: Distribution balancing for label-free multi-teacher distillation, 2024.
17 Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Am-radio: Agglomerative vision foundation model reduce all domains into one. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12490--12500, 2024.
18 Mike Ranzinger, Greg Heinrich, Pavlo Molchanov, Bryan Catanzaro, and Andrew Tao. Featsharp: Your vision model features, sharper. In Forty-second International Conference on Machine Learning, 2025.
19 Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien Mairal, Hervé Jégou, Patrick Labatut, and Piotr Bojanowski. DINOv3, 2025.
20 Trung Trinh, Markus Heinonen, Luigi Acerbi, and Samuel Kaski. Improving robustness to corruptions with multiplicative weight perturbations. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024.
21 Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features, 2025.
22 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, page 6000--6010, Red Hook, NY, USA, 2017. Curran Associates Inc.
23 Jiawei Yang, Katie Z Luo, Jiefeng Li, Congyue Deng, Leonidas J. Guibas, Dilip Krishnan, Kilian Q Weinberger, Yonglong Tian, and Yue Wang. Dvt: Denoising vision transformers. 2024.
24 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pretraining. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 11941--11952, 2023.
25 Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127:302--321, 2016.