向量数据库实战:从"看起来能用"到"真的能用",中间隔着一堆坑
大多数向量数据库项目,不是"失败",而是"半死不活"
如果你问一个已经上线向量数据库的团队:
"你们的向量检索效果怎么样?"
得到的回答往往是:
- "还行吧,有时候挺准"
- "大部分时候能用,但偶尔很怪"
- "不好说,反正模型有时候答得不对"
这类系统,通常不是完全不能用,
但也很少让人真正放心。
原因并不在于向量数据库"不成熟",
而在于:从建库到稳定可用,中间有一整段工程空白,被严重低估了。
一个必须先说清楚的现实:向量数据库实战 ≠ 建库成功
很多教程,会把"向量数据库实战"理解成:
- 选一个向量库
- 把 embedding 存进去
- 调用 search 接口
但在真实项目里,这三步只是:
"系统刚刚有可能开始工作"
真正决定成败的,是后面这些问题:
- 数据怎么进来
- 文档怎么切
- 检索结果怎么用
- 出问题怎么排查
- 迭代时怎么不把系统搞崩
第一步:选向量数据库之前,你必须先搞清楚"你要它干嘛"
这是几乎所有实战翻车的起点。
很多人选向量数据库的理由是:
"RAG 不是都要用吗?"
但在工程上,这是一个非常危险的动机。
在真正选型前,你至少要回答清楚三件事:
- 你要解决的是模糊匹配 ,还是精确查询?
- 数据规模是几千、几十万,还是上千万?
- 查询是高并发在线 ,还是低频内部使用?
不同答案,对向量数据库的要求,完全不同。
第二步:Embedding 选型,往往比数据库本身更重要
这是一个非常容易被忽略的事实。
在向量数据库实战中,embedding 模型几乎定义了你整个系统的"世界观"。
因为一旦 embedding 选定:
- 什么算相似
- 什么算不相似
- 哪些差异会被忽略
这些判断,就已经被固化进向量空间了。
如果 embedding 本身就不适合你的领域,
那后面所有检索优化,基本都是在"补救"。
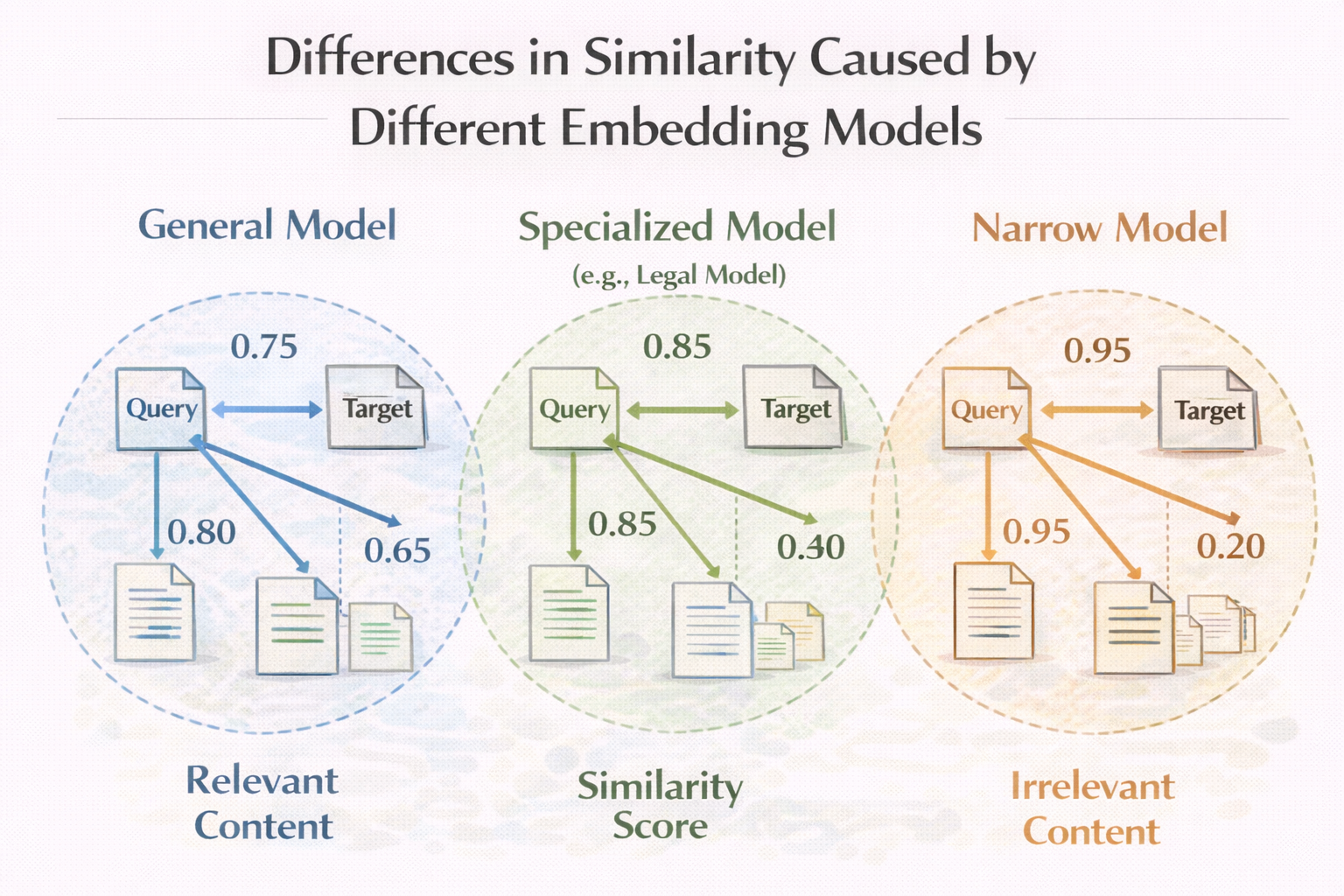
不同 embedding 模型导致的相似性差异示意图
一个真实工程现象:embedding 一换,系统像换了一个脑子
很多团队在系统上线一段时间后,会尝试升级 embedding。
然后你会看到:
- 原本很准的问题,突然不准了
- 原本答不出来的问题,突然能答了
- 整体行为变得难以预测
这是因为:
向量数据库不是"无状态组件",
它的行为强烈依赖 embedding 的语义空间。
所以在实战中,embedding 版本管理,是必须被认真对待的。
第三步:建库之前,先把"切分策略"当成核心工程
这一点前面那篇《RAG 文档切分》已经讲过很多,但在实战里,还是值得再强调一次。
在向量数据库里:
- 你检索的不是"文档"
- 而是 chunk
而 chunk 的质量,直接决定:
- 检索是否命中
- 命中的内容是否可用
如果你在建库时,随意切分、一次性切完所有文档,
那后面你几乎一定会后悔。
切分策略在向量库中的位置示意图
第四步:建库成功,只是"第一天不报错"
很多人第一次看到:
python
vector_db.insert(embeddings)不报错,
查询能返回结果,
就会产生一种错觉:
"向量数据库这块,应该没问题了。"
但从工程经验来看,这只是:
第一天不报错而已
真正的问题,往往在:
- 数据量上来之后
- 查询变复杂之后
- 业务开始依赖结果之后
一个非常真实的场景:TopK 一开始看起来很准,后来越来越怪
在向量数据库实战中,你几乎一定会遇到这个阶段。
初期:
- 数据少
- 文档干净
- TopK=3 很准
后期:
- 数据越来越多
- 文档类型混杂
- TopK=3 开始频繁命中"看起来相关,但没用"的内容
这不是数据库退化了,
而是数据分布变了,而你的策略没变。
第五步:你迟早要面对"相似但不可用"的检索结果
这是向量数据库实战中最头疼、但无法回避的问题。
你会看到很多这样的结果:
- embedding 分数很高
- 关键词命中
- 但内容缺条件、缺结论、缺上下文
在这一刻,你会意识到:
向量数据库只负责"找像的",
不负责"找对的"。
这也是为什么,单纯的向量检索,在真实系统里,几乎一定不够。
Rerank:向量数据库从"能用"到"好用"的分水岭
在很多真实项目中,向量数据库效果的质变,发生在引入 rerank 的那一刻。
向量检索解决的是:
- 快速召回
- 模糊匹配
Rerank 解决的是:
- 精细排序
- 可用性判断
如果你只用向量数据库,不做 rerank,
那系统迟早会被噪声淹没。
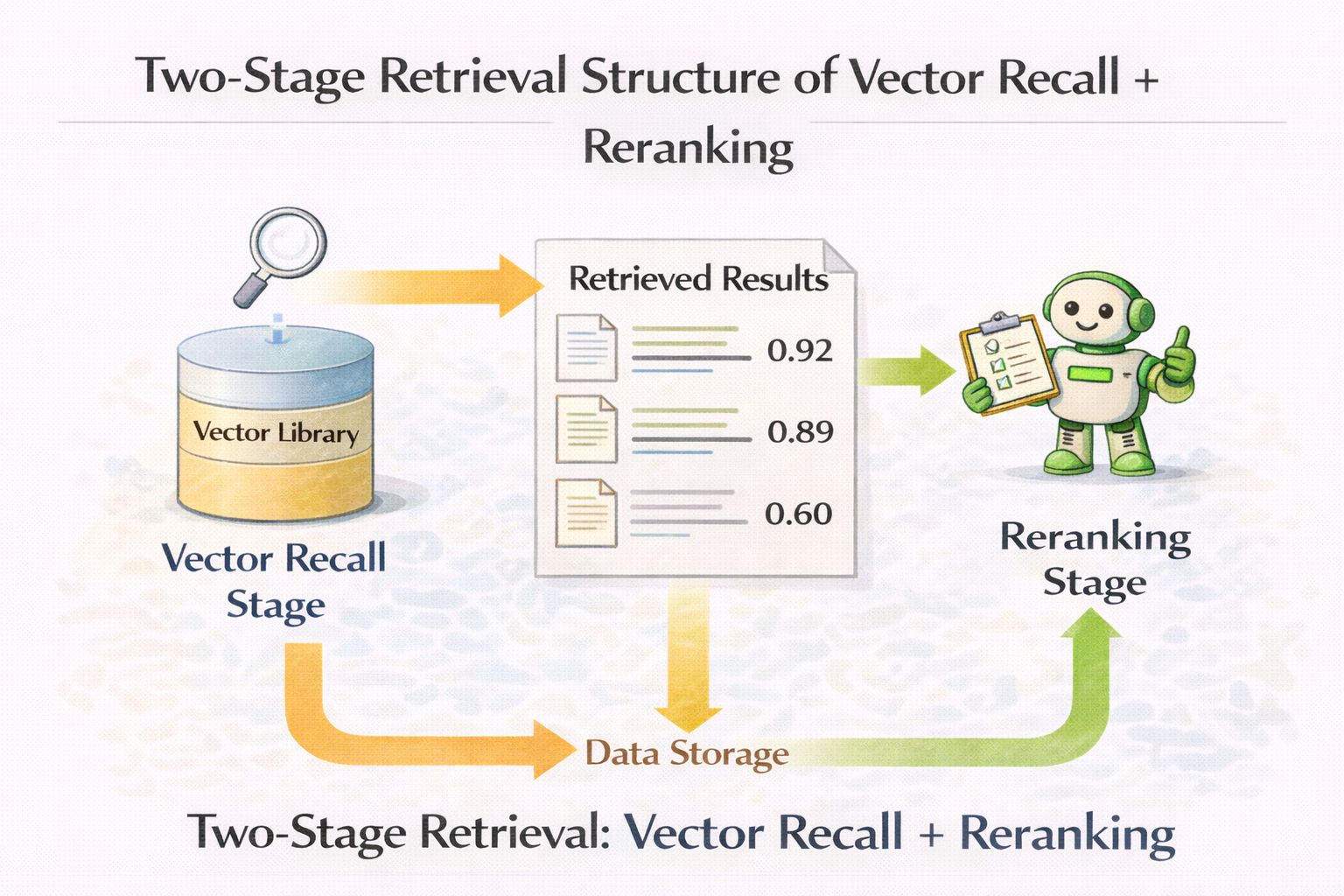
向量召回 + rerank 的两阶段检索结构图
一个简化但真实的两阶段检索示例
python
candidates = vector_db.search(query, top_k=20)
reranked = rerank_model.rank(query, candidates)
final = reranked[:3]这段代码看起来很简单,
但它背后表达的是一个非常重要的工程认知:
向量数据库适合做"第一轮筛选",
而不是最终裁决。
第六步:你需要为"坏结果"设计排查路径
这是很多团队在实战中才意识到的事。
当用户反馈:
"这个问题答错了。"
你必须能回答:
- 是没检索到?
- 还是检索到了但没用?
- 是切分问题?
- embedding 问题?
- 还是模型生成问题?
如果你回答不上来,
那系统就不可维护。
一个实用但朴素的排查顺序
在实战中,我非常推荐下面这个顺序:
- 固定模型,不动生成
- 只看检索结果本身
- 人工判断是否"可用"
- 再考虑 rerank / prompt
这个顺序,能帮你避免 80% 的误判。
第七步:向量数据库不是"一次性工程",而是长期系统
这是很多团队在后期最痛的地方。
向量数据库一旦成为系统依赖,你就必须考虑:
- 数据更新策略
- 向量重建成本
- embedding 升级影响
- 历史版本回滚
这时候你会发现:
向量数据库,已经不是一个"组件",
而是系统的一部分。
一个常被忽略的问题:向量数据库的评估方式
很多团队在评估向量数据库效果时,只看最终答案。
但在实战中,更合理的评估应该拆成:
- 是否命中正确 chunk
- 命中的 chunk 是否可用
- 模型是否正确使用了 chunk
如果第一步就失败了,
后面讨论模型没有意义。
什么时候你应该停下来,重新考虑向量数据库
这是一个很重要、但很多人不愿面对的问题。
如果你发现:
- 数据规模其实不大
- 问题类型高度集中
- 规则能解决大部分问题
那向量数据库,很可能已经变成负资产。
一个更健康的实战策略:先小规模跑通,再放大
在真实工程中,一个更稳妥的路径往往是:
- 少量核心文档
- 多种切分方式
- 不同 embedding 对比
- 人工强介入评估
而不是一开始就:
- 全量建库
- 高并发上线
在向量数据库实战的早期阶段,如果你还在反复验证"向量检索到底是不是适合当前业务",用LLaMA-Factory online先快速搭一套 RAG + 向量检索原型、对比不同 embedding 和切分策略下的真实输出效果,会比直接投入完整向量库工程更容易看清问题本质,也更容易止损。
总结:向量数据库实战,难的从来不是"用",而是"用对"
如果要用一句话总结向量数据库实战,那应该是:
向量数据库不是"装上就行"的基础设施,
而是一个会深度影响系统行为的核心组件。
真正成熟的实战,不是问:
- "这个向量库性能够不够?"
而是问:
- "这个问题,本质上是不是一个相似性问题?"
当你能清楚地回答这个问题时,
向量数据库,才会成为资产,而不是拖累。