视频讲解1:Bilibili视频讲解
论文下载:https://arxiv.org/abs/1909.07083
代码下载:https://github.com/mrlibw/ControlGAN
论文GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis详解(代码详解)
论文Generative Adversarial Text to Image Synthesis详解
论文DF-GAN: ASimple and Effective Baseline for Text-to-Image Synthesis详解
论文StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks详解
论文HDGAN(Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network)详解
论文AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks详解
论文MirrorGAN: Learning Text-to-image Generation by Redescription详解
基于GAN的文生图(DM-GAN:Dynamic MemoryGenerative Adversarial Networks for Text-to-Image Synthesis)
基于监督对比学习的统一图像生成框架(A Framework For Image Synthesis Using Supervised Contrastive Learning)
基于GAN的文生图算法详解(Text to Image Generation with Semantic-Spatial Aware GAN)
本文综述了多项文本生成图像(Text-to-Image)的GAN模型研究,重点分析了现有方法在生成可控性和细粒度控制方面的局限性。针对StackGAN++、AttnGAN等模型存在的生成不可控、属性耦合等问题,提出了一种改进方案:通过引入通道注意力机制和词级判别器,增强语义部位聚焦能力;采用感知损失减少随机性,保持未修改内容的一致性。实验表明,该方法能实现更精准的文本-图像对齐,在修改特定属性时保持其他视觉内容稳定。研究为提升文生图模型的可控性和生成质量提供了新思路。
目录

现有方法的局限性
生成过程不可控:现有文本到图像生成方法(如StackGAN++、AttnGAN)在生成图像后,若对文本描述进行局部修改(如改变颜色或形状),模型会重新生成完全不同的图像,无法保持未修改部分的视觉内容。例如,修改鸟的羽毛颜色时,背景、姿态等无关属性也可能被改变。
**缺乏细粒度属性解耦:**传统方法依赖于全局文本特征,无法将不同视觉属性(如纹理、部位细节)与文本中的特定单词对齐,导致修改文本时难以精准控制对应区域。
判别器反馈不够精细:现有判别器(如文本自适应判别器)使用全局池化层提取图像特征,丢失了空间信息,无法为生成器提供单词与图像子区域之间的细粒度关联反馈。
生成结果随机性高:在没有约束的情况下,模型对文本无关区域(如背景)的生成具有高度随机性,难以保持语义一致性。
提出的方法
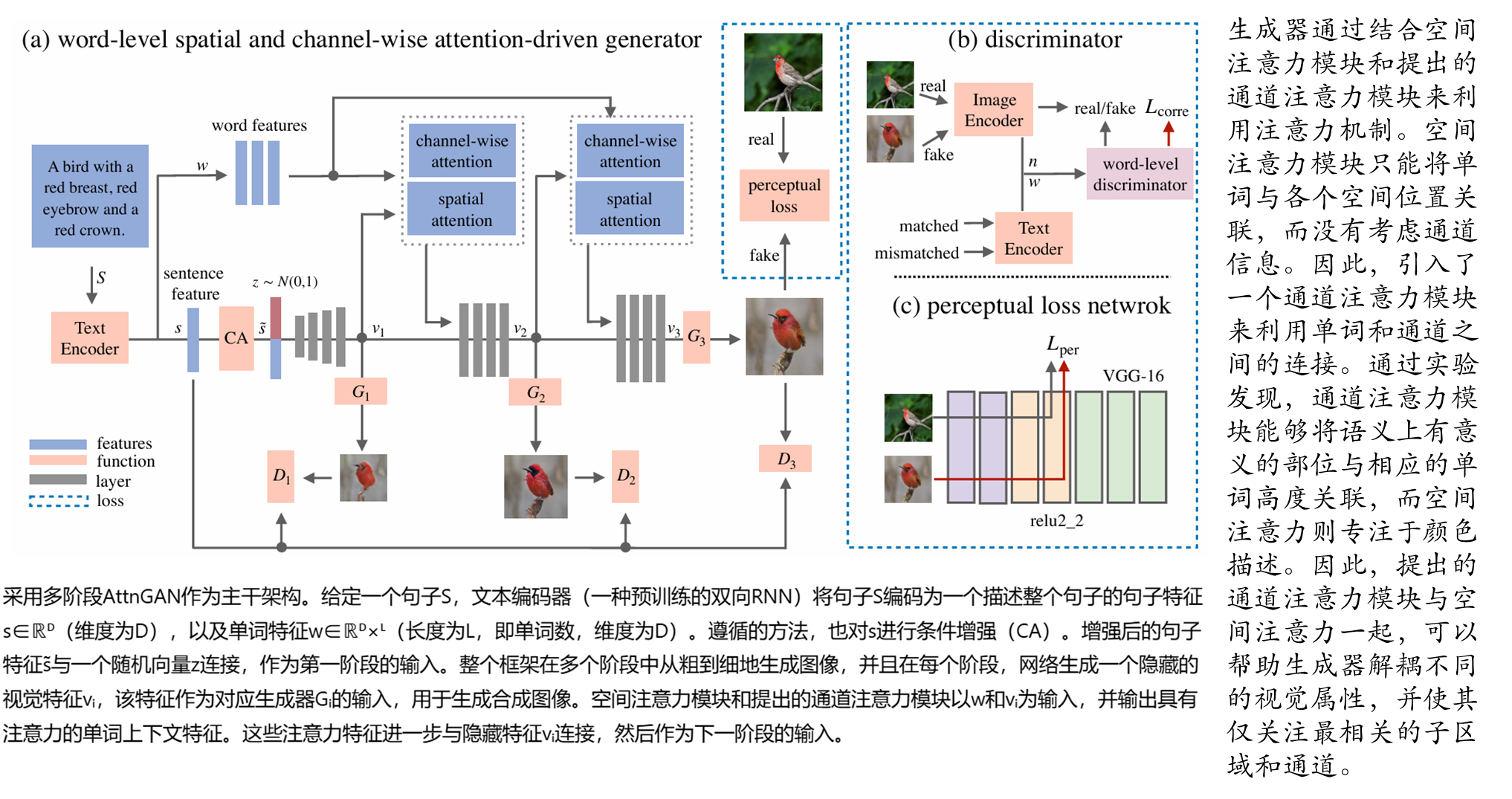
词级空间与通道注意力驱动的生成器**:**在AttnGAN多阶段架构基础上,引入通道注意力机制,计算单词与特征图通道之间的相关性,增强对语义部位(如鸟喙、翅膀)的聚焦。结合空间注意力,使生成器能解耦不同视觉属性,仅修改与文本变化相关的区域。
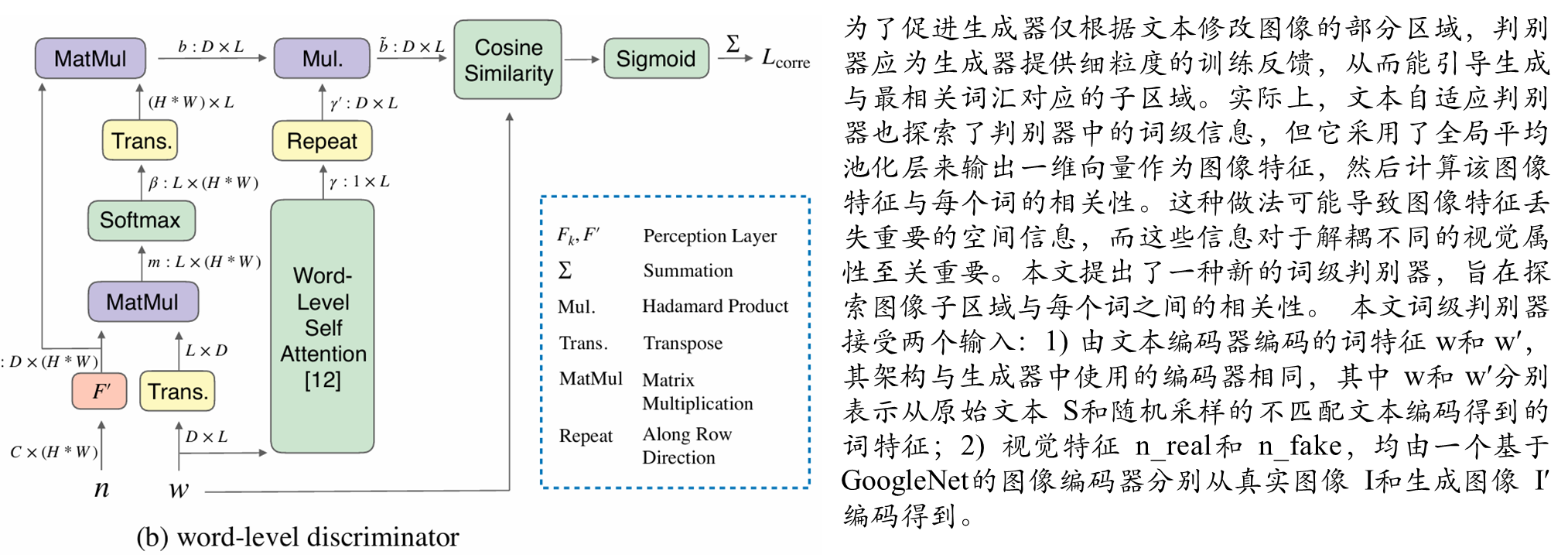
词级判别器**:**通过计算单词与图像子区域的关联矩阵,提供细粒度监督信号,确保每个单词仅影响对应视觉属性。
相比传统方法,保留空间信息,避免全局池化造成的细节丢失.
感知损失的应用**:**首次在可控文本到图像生成中引入VGG网络提取的感知损失,通过匹配真实图像与生成图像的特征空间,减少随机性,保留未修改文本对应的内容.

具体方法
逐通道注意力

词层面的判别器

感知损失

生成和判别损失


实验结果
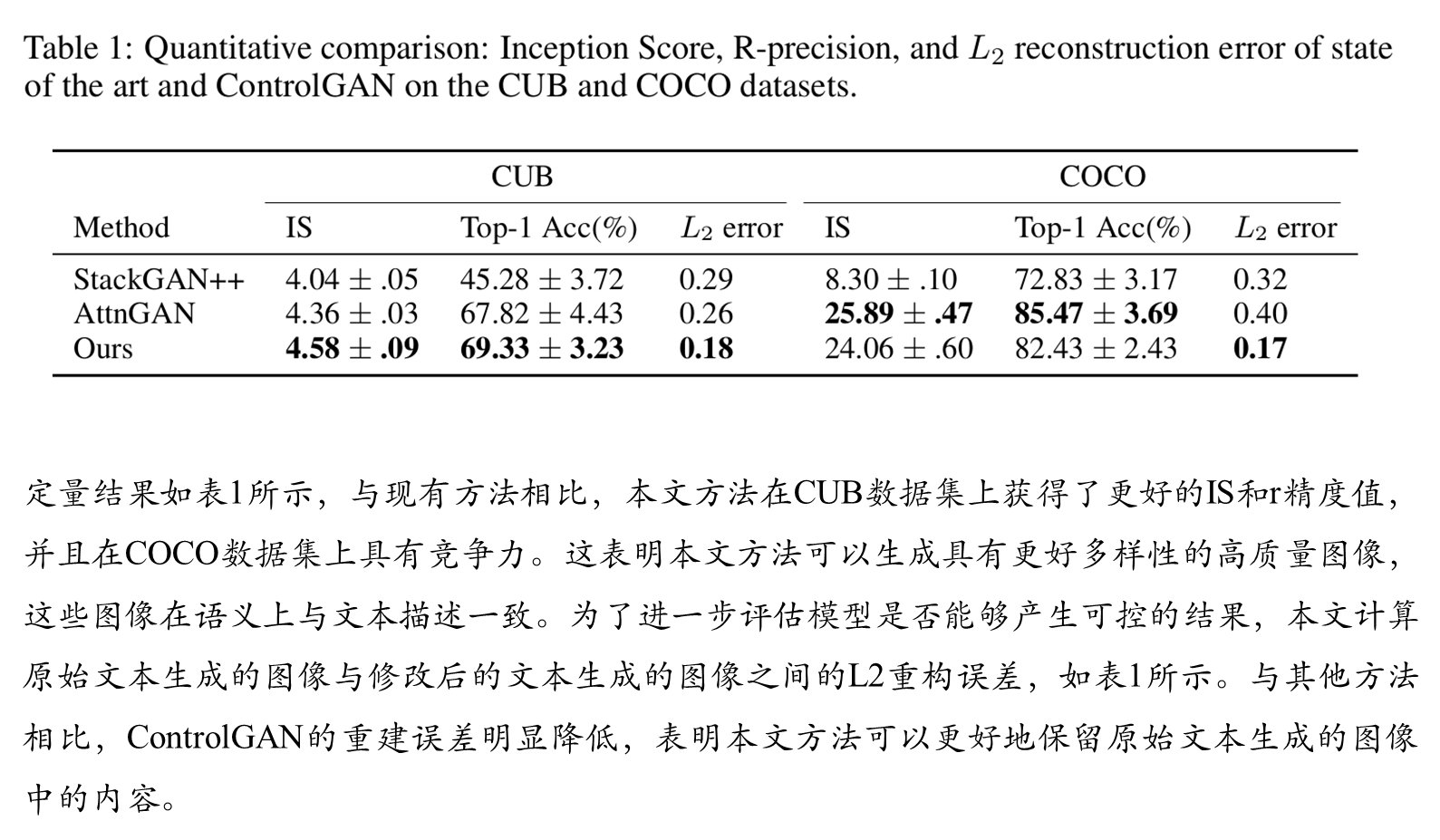
综合比较
可视化结果



