文章目录
- [一. 集群机制](#一. 集群机制)
- [二. 缓存机制](#二. 缓存机制)
-
- [1. 定期生成缓存](#1. 定期生成缓存)
- [2. 实时生成缓存](#2. 实时生成缓存)
- [3. 内存淘汰策略](#3. 内存淘汰策略)
-
- [(1) FIFO (First In First Out)](#(1) FIFO (First In First Out))
- [(2) LRU (Least Recently Used)](#(2) LRU (Least Recently Used))
- [(3) LFU (Least Frequently Used)](#(3) LFU (Least Frequently Used))
- [(4) Random](#(4) Random)
- [4. 缓存预热(Cache Preheating)](#4. 缓存预热(Cache Preheating))
-
- [(1) 问题原因](#(1) 问题原因)
- [(2) 解决方案](#(2) 解决方案)
- [5. 缓存穿透(Cache penetration)](#5. 缓存穿透(Cache penetration))
-
- [(1) 问题原因](#(1) 问题原因)
- [(2) 解决方案](#(2) 解决方案)
- [6. 缓存雪崩(Cache avalanche)](#6. 缓存雪崩(Cache avalanche))
-
- [(1) 问题原因](#(1) 问题原因)
- [(2) 解决方案](#(2) 解决方案)
- [7. 缓存击穿(Cache breakdown)](#7. 缓存击穿(Cache breakdown))
-
- [(1) 问题原因](#(1) 问题原因)
- [(2) 解决方案](#(2) 解决方案)
- [三. 分布式锁](#三. 分布式锁)
-
- [1. setnx](#1. setnx)
- [2. set key value nx ex seconds](#2. set key value nx ex seconds)
- [3. 校验服务器id](#3. 校验服务器id)
- [4. 引入lua脚本](#4. 引入lua脚本)
- [5. 看门狗(watch dog)](#5. 看门狗(watch dog))
- [6. redlock算法](#6. redlock算法)
一. 集群机制
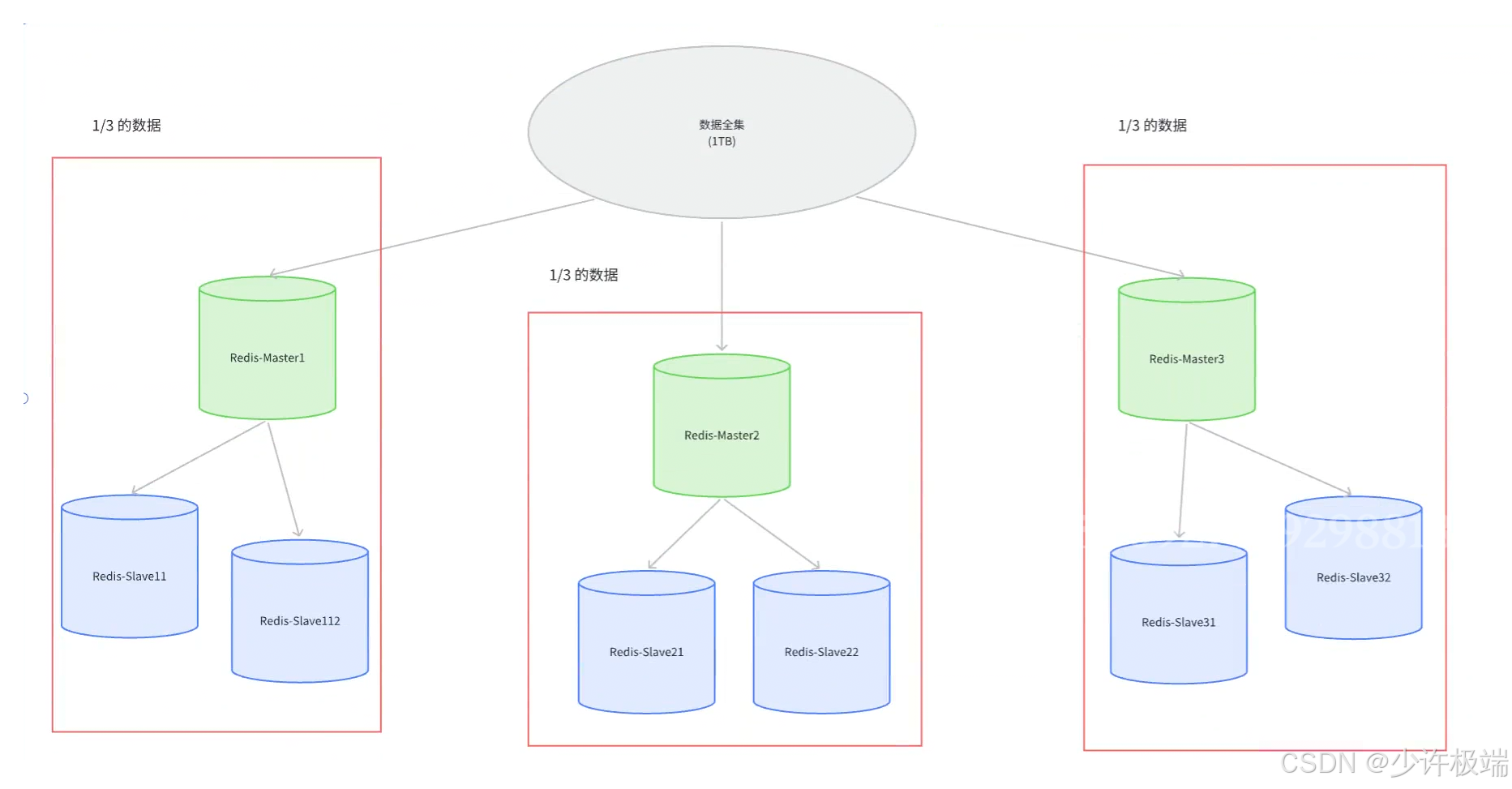
1. 我们这里说的Redis集群指的不是多个主机之间构成的那种集群模式, 而是为了解决集群模式下储存空间不足的问题而引入的机制
2. 在前面的主从结构和哨兵模式的讲解中, 都是一个主节点负责存储所有数据然后同步给从节点, 时间长了之后势必会导致主节点上内存不足, 因此拓展储存空间就是必须的, 解决方式是引入多个主节点, 每个主节点存储总数据的一部分, 主节点下同时增加从节点来备份数据, 将存储压力分摊开
1. 分片算法
为了将数据更均匀分布到分片上, 分摊整体的存储压力, 好的分片算法必不可少~
(1) 哈希求余
1) 算法原理
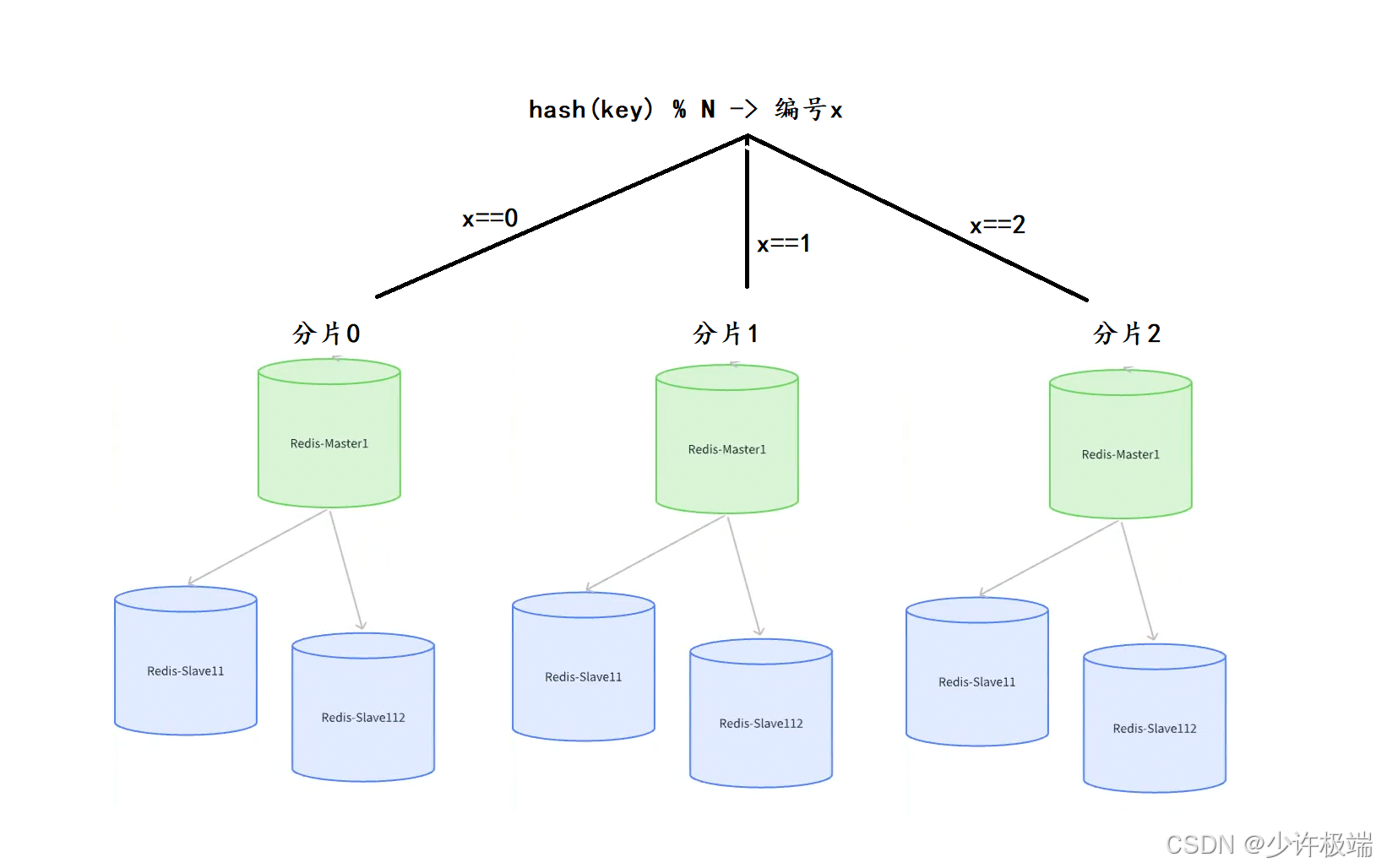
看到哈希两个字我们可能会联想到哈希表, 哈希求余也确实运用了哈希表的一些思想: 用哈希函数将 key 映射到具体的分片上(每个分片是一个主从节点集群)
具体流程为: 将 key 通过哈希函数算出一个整数数值(哈希值), 然后将算出的数值对切片的数量求余得到数值x, x的数值就是要存入的坐标
2) 存在的问题
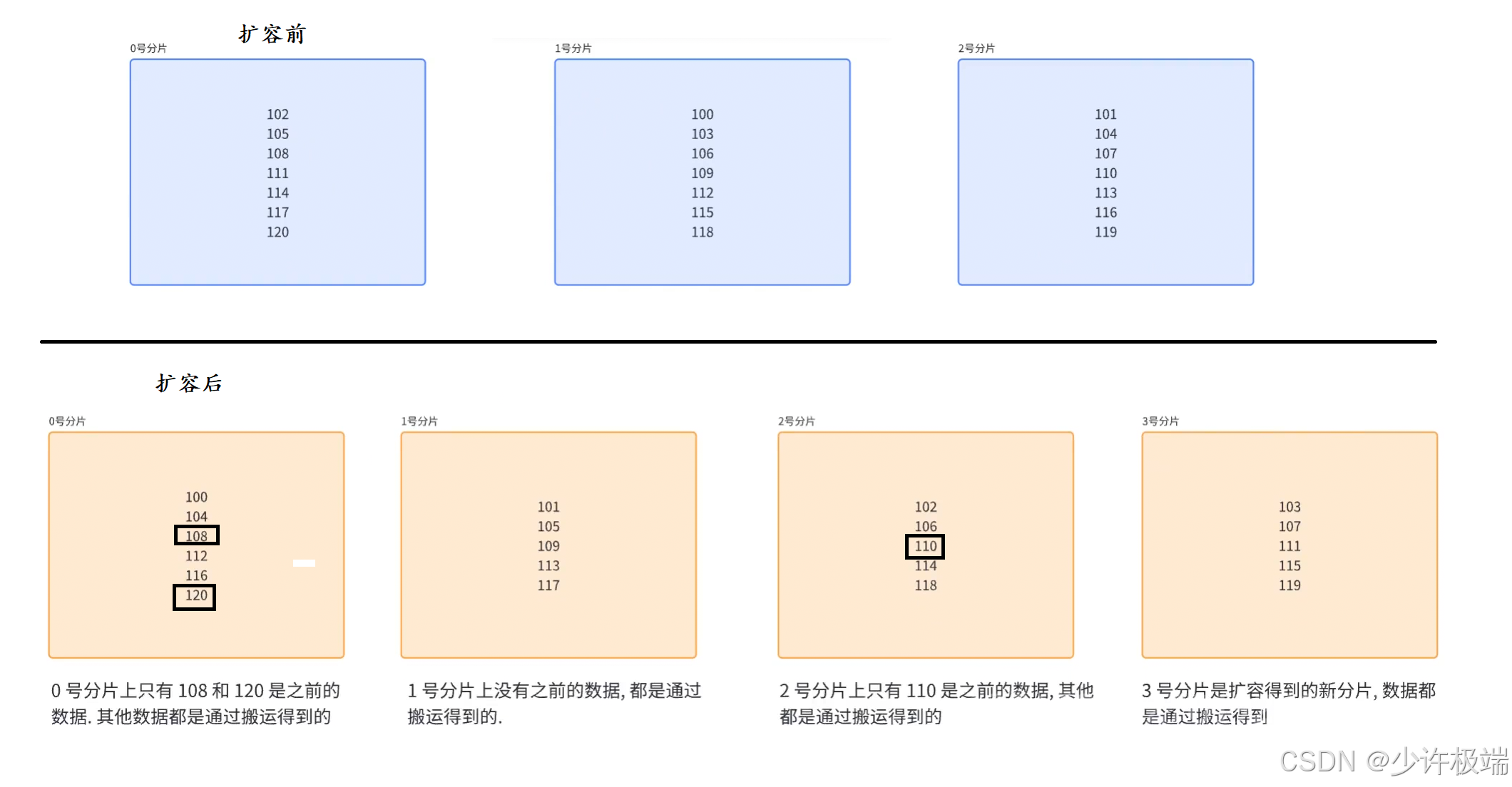
上述求余算法中, 连续数据是交替存储的(即1, 2, 3三个连续哈希值连续的key分别存在不同的分片中), 当需要扩容时, 例如3个分片扩容成4个分片, 需要搬运大部分数据, 如果数据总量庞大到用亿为单位, 搬运数据所需要消耗的资源是十分巨大的, 这也是该算法最大的问题
(2) 一致性哈希算法
1) 算法原理
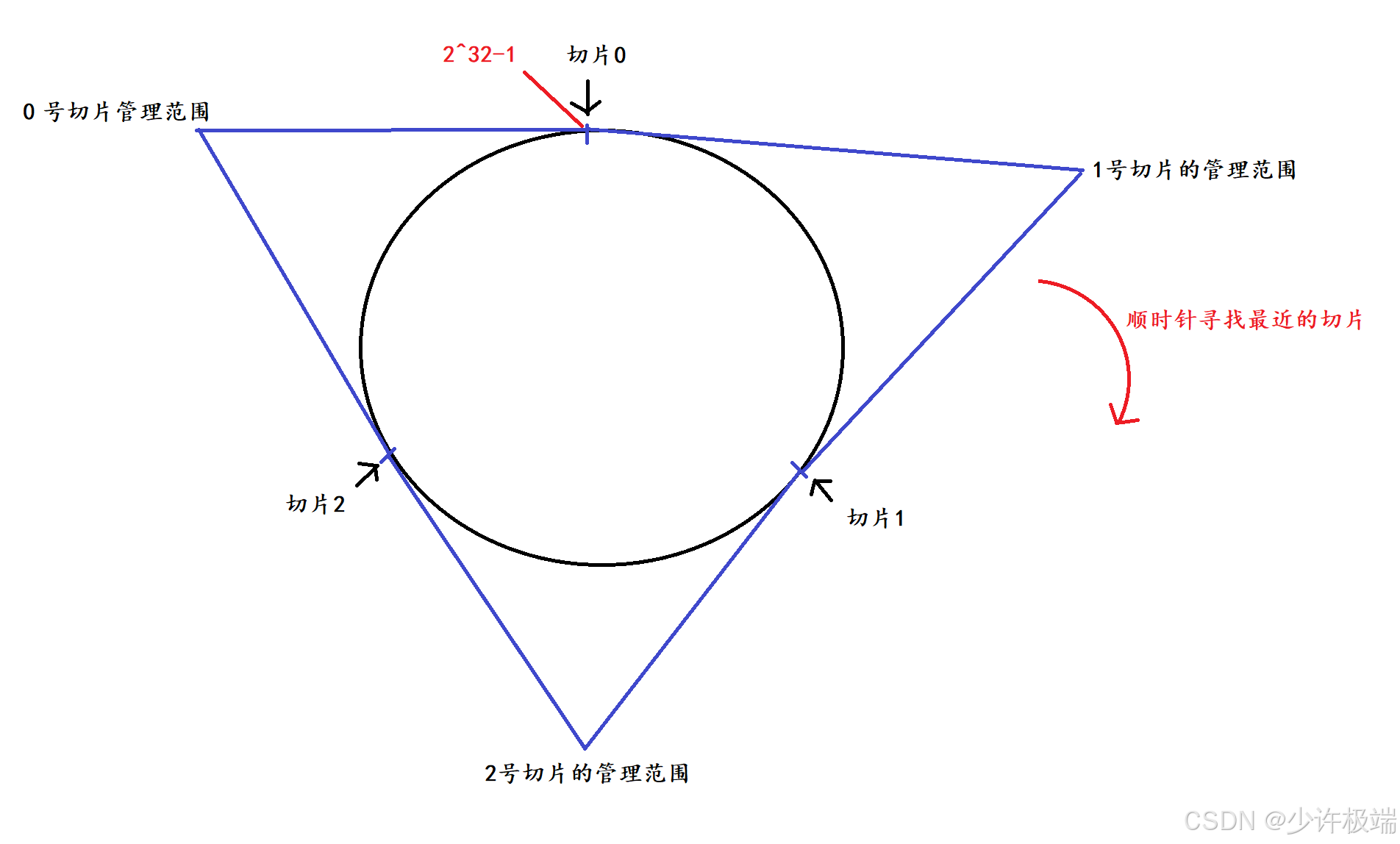
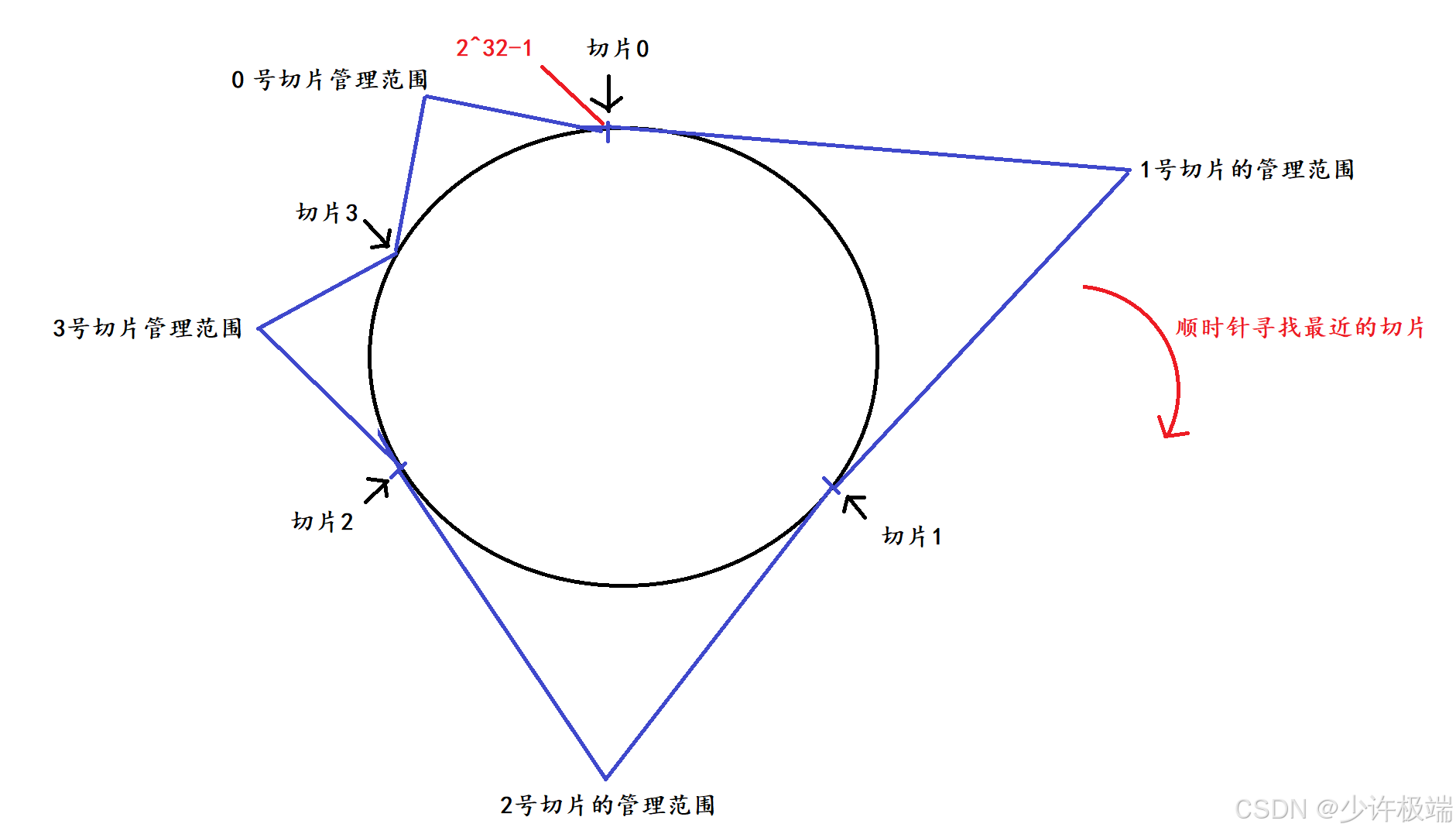
通过哈希算法算出来的数值最大为2^32-1, 因此当切片数量为3时, 将数值划分为3个部分, 每个切片管理的范围差不多大, 将key通过哈希算法算出哈希值, 算出的哈希值通过增大的方式(顺时针)来寻找最近的切片
2) 解决的问题
增加一个切片3时, 只需要将0号切片管理的范围再划分为两半, 一半继续由0号切片管理, 一半交给新的切片3, 这期间只需要将这交给切片3的这些数据进行搬运即可, 减少了搬运所花费的开销
3) 存在的问题
上方增加切片后会出现数据切斜问题, 即1, 2 号切片会存储大部分数据, 存储压力较大, 而3, 0 号切片只会存储小部分数据, 压力较小, 导致资源利用不充分
(3) 哈希槽分区算法
1) 算法原理
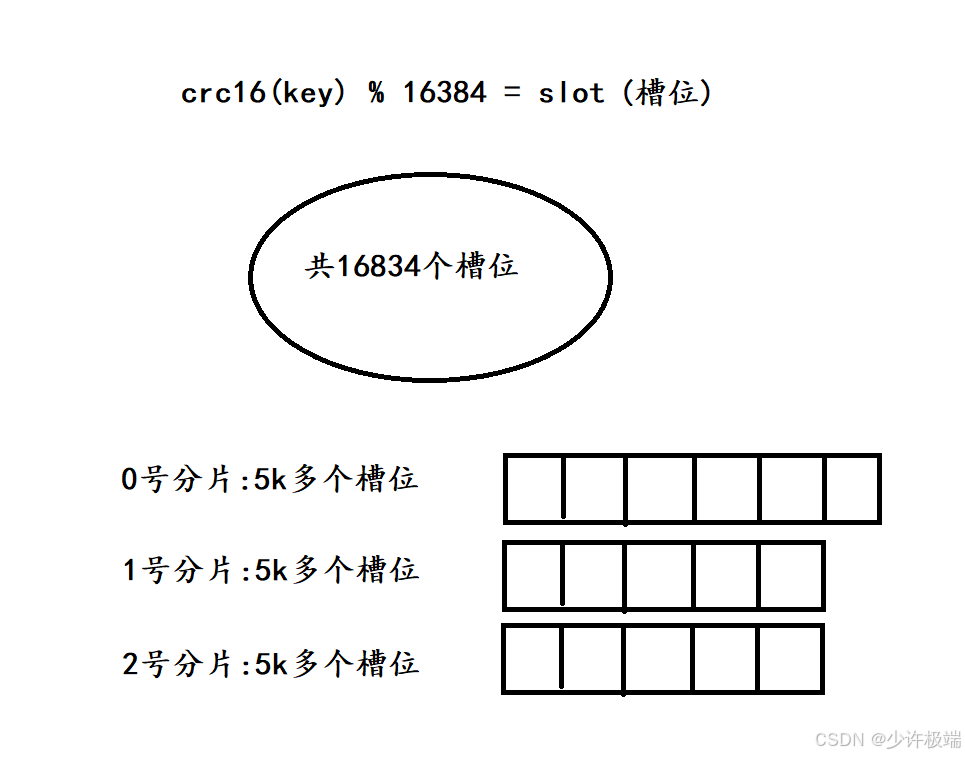
默认有16384个槽位, 假如当前有3个切片, 将槽位尽量均匀地分布到这几个切片中, 有key需要存储时, 先计算出哈希值, 接着对16384取余, 得出的结果就是所属的槽位, 根据槽位去寻找对应的切片
2) 解决的问题
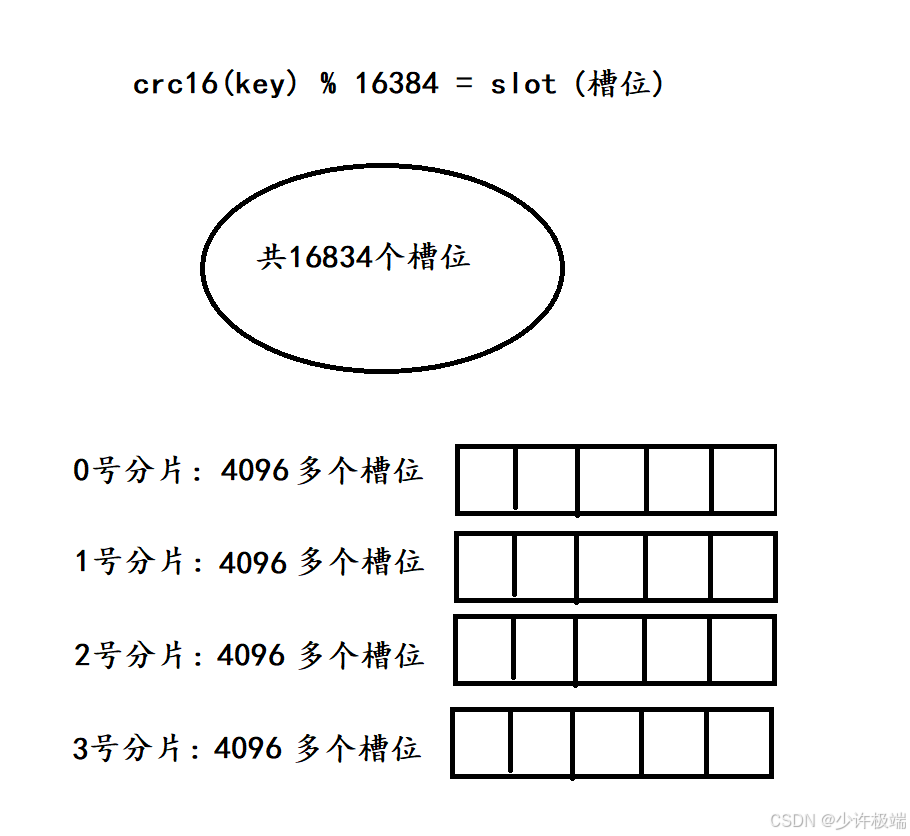
1. 当有新切片3假如时, 会从之前的切片中挑出一部分槽位交给切片3管理, 然后将挑出的槽位中的数据转移到新的切片上, 这里挑出槽位后每个切片的槽位数量基本相同
2. 需要注意: 切片管理的槽位范围并不一定是连续的, 而是可能分散的, 因此Redis采用位图这种数据结构来表示切片对应的槽位
3) 槽位数量的解答
1. 在上面我们看到一个数字16384, 这时槽位的总数量, 但这不意味着最多可以有16384个切片, 因为一个切片就是一个主从结构的小集群, 我们上面三个算法要做的事情就是平摊存储压力, 当一个节点只对应一个槽位时, 数据均匀是难以保证的, 这就意味着切片的分摊压力难以达到平衡, 违背了最开始的初心, 因此官方建议集群切片数不超过1k
2. 在各个节点之间是通过心跳包来交流的, 其中就包含了槽位slot, Redis使用位图来存储切片管理的槽位, 也就是16384个bit位(2kb), 这个数量能够满足绝大部分场景, 同时也不会太占用网络带宽
2. 故障处理
集群中的主从节点发生故障时, 处理方式和哨兵模式有点不同
(1) 故障判定
1. 在集群中, 每个节点每秒钟会给随机的一些节点发送ping包, 来验证其他节点的健康状态, 注意这里不是给所有节点发送ping, 因为集群中可能有很多节点, 给每个节点都发送一遍的话, 网络带宽消耗较大
2. 如果A向B发送ping, 而B没有在超时时间内回应pong包, A会先重置与B的TCP连接, 检查能否连接成功, 如果仍然失败会将B设置为PFAIL(类似于主观下线)
3. 判断B主观下线后, A接着通过Redis的Gosssip协议向其他节点确认B的健康状态
4. 当认为B下线的节点数超过集群个数的一般是, A会把B标记为FAIL(类似于客观下线), 并同步给其他节点, 其他节点也会将B设置为FAIL
(2) 故障转移
如果判定故障的节点B为从节点, 那么不用故障转移, 如果B为主节点, 需要B的从节点来进行故障转移
1. 先投票竞选, B的所有从节点会检查自身是否有竞选资格, 如果与主节点间太久没通信超过了设定的时间阈值, 会判定为没有竞选资格
2. 有资格的节点会先休眠, 休眠时间为: 500ms(基础休眠时间) + 0, 500随机休眠时间 + 排名 ✖️ 1000ms(offset越大, 排名越靠前, 值越小)
3. 先结束休眠的从节点会进行拉票操作, 期间只有主节点可以投票, 且只有一票
4. 如果从节点X的票数超过了主节点数的一半, X晋升为主节点(自己执行 slaveof no one), 并且让其他从节点执行slaveof C
5. X晋升后会将自身成为主节点的信息同步给其他节点, 其他节点会更新存储的信息
6. X成为主节点后, 如果节点B重连了上来, 会自动成为X的从节点
二. 缓存机制
缓存这个概念我们在第一篇提到过, Redis在实际业务中主要有两个作用: 一是存储所有数据, 作为内存数据库; 二是只存储频繁查询的热点数据, 作为MySQL这种关系型数据库的缓存, 替MySQL负重前行, 这里我们只讨论作为缓存的场景
1. 定期生成缓存
将近期(一天/一周/一月)访问的数据情况通过日志保留下来, 然后针对日志进行大数据统计, 将查询的关系词按频率降序排列, 然后取前20%的数据作为关键词, 这20%的数据基本能满足80%的请求
2. 实时生成缓存
在Redis作为缓存使用过程中, 客户端发送一个请求如果在Redis没有查到, 会从数据库中查询, 返回结果的时候也写入Redis
3. 内存淘汰策略
内存空间是有限的, 不可能只写不删, 因此Redis提供了几种淘汰策略来删除数据
(1) FIFO (First In First Out)
先进先出策略, 将缓存中存在时间最久的数据(最先写入的)淘汰掉
配置项:⬇️
volatile-ttl: 对所有设置了过期时间的key进行排列, 越早过期的优先淘汰
(2) LRU (Least Recently Used)
将最近数据中最老的那一个淘汰
配置项: ⬇️
volatile-lru: 对有过期时间的key用LRU算法淘汰
allkeys-lru: 对所有key用LRU算法淘汰
(3) LFU (Least Frequently Used)
记录key最近一段时间的访问次数, 最小的淘汰
配置项: ⬇️
volatile-lfu: 对有过期时间的key用LFU算法淘汰
allkeys-lfu: 对所有key用LFU算法淘汰
(4) Random
从所有key中随机淘汰掉
配置项: ⬇️
volatile-random: 对有过期时间的key随机淘汰
allkeys-random: 对所有key随机淘汰
4. 缓存预热(Cache Preheating)
(1) 问题原因
这种情况主要发生在缓存的实时生成阶段, 当Redis服务器重启或者首次介入时, 服务器可能并没有任何热点数据, 这时首次的所有请求都会先打到数据库上, 数据库压力暴大, 可能会宕机, 这就是缓存预热不足的问题
(2) 解决方案
核心就是将缓存预热, 现将之前定期生成的日志或者其他途径来找到一批旧的热点数据, 先写入到Redis服务器中, 帮数据库承担一些压力, 之后随时间推移新的热点数据会替代旧数据
5. 缓存穿透(Cache penetration)
(1) 问题原因
因为业务的设计不合理或者一些特殊原因, 导致客户端在查询某个key时, Redis和数据库中都没有存在该信息, 该请求就会反复打到MySQL上处理, 这时如果这种请求大量且频繁, 会对数据库造成巨大压力
(2) 解决方案
1. 如果Redis和数据库上都不存在, 依旧写入Redis, value这只为空值
2. 把所有的key写入到布隆过滤器上, 每次查询缓存和数据库的时候先判断在布隆过滤器上是否存在, 存在就放行
6. 缓存雪崩(Cache avalanche)
(1) 问题原因
短时间内缓存的大量key(包含热点数据和普通数据)失效, 导致数据库的压力迅速上升, 甚至宕机, 一般是Redis服务挂机或者Redis集群大量节点挂机, 还有种情况是之前短时间内设置了大量的key, 且这些key的过期时间设置的一样
(2) 解决方案
1. 设置监控报警, 加强Redis集群可用性
2. 设置key的过期时间的时候, 添加随机因子
7. 缓存击穿(Cache breakdown)
(1) 问题原因
这时缓存雪崩的一种特殊情况, 指的是热点key突然过期导致的大量请求打到数据库上
(2) 解决方案
1. 进行大数据统计来发现热点key, 设置为永不过期
2. 进行服务降级, 限制服务器的功能, 只保留核心业务
三. 分布式锁
在多线程(六) ~ 定时器与锁这篇博客中我们谈到过多线程模式下如何加锁和使用的场景, 那在分布式系统中, 每个节点都相当于一个单独的进程, 那么如何在多进程间实现加锁效果呢? 下面我们基于Redis来实现分布式系统中的互斥锁
1. setnx
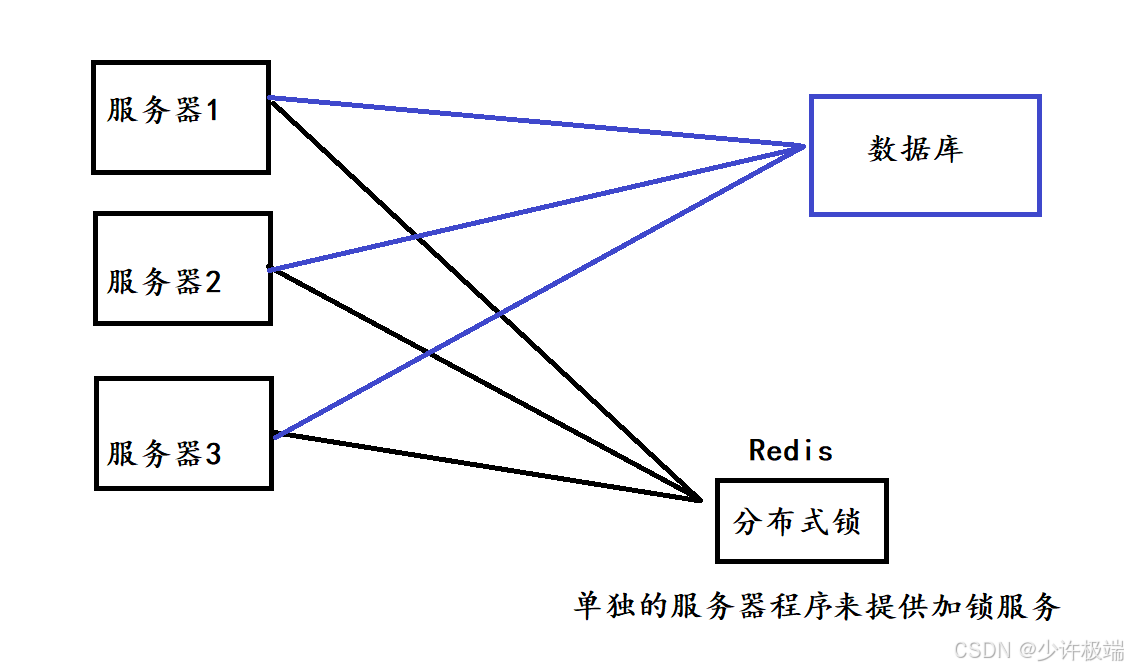
我们想要实现一个服务器加锁之后, 在未解锁期间, 另一个服务器想要获取到锁必须判定失败, 在Redis入门指南(二):从零到分布式缓存-string类型这篇博客中, 曾提到过setnx恰好可以实现这种效果, del就可以视为解锁操作
2. set key value nx ex seconds
使用上面命令给锁设置过期时间, 来解决极端情况下(例如服务器断电)导致的无法正常解锁
3. 校验服务器id
当服务器加锁之后, 如果另一个服务器意外执行了解锁操作, 会导致锁的丢失, 因此引入校验id机制, 将加锁者的id记录到value中, 解锁之前先与锁的value值对比, 确保由加锁者亲自解锁
4. 引入lua脚本
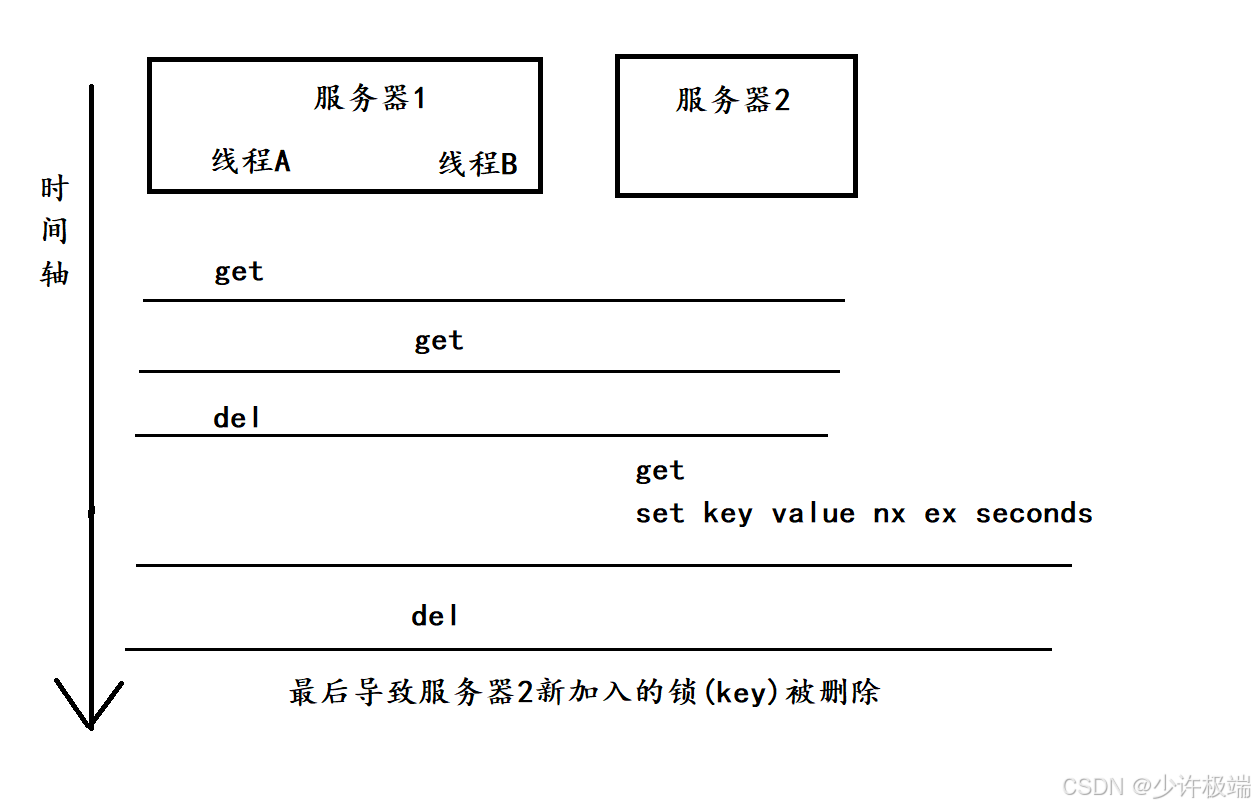
按时间轴顺序执行命令,线程A,B在同一个服务器上, 服务器1加锁后, 线程A和B都可以正常获取到锁来进行操作, 线程A执行完任务后, 校验id通过正常解锁, 线程B校验id通过也想要解锁, 在执行del的前一刻, 服务器2插入了两条命令, 分别是获取锁和加锁, 但服务器2加完锁之后, 服务器1的线程B执行了del, 这样会导致服务器2新加的锁丢失
解决问题的本质是为了在执行get和del之间不能被其他操作插入, 即将get和del打包成原子性操作, 可以借助Redis内嵌的lua解释器来达到事务的效果(官方推荐)
5. 看门狗(watch dog)
前面我们提到过要给锁设置过期时间包防止不能解锁的情况, 但这里过期时间的大小又是个问题, 不同任务花费的时间不同, 需要锁的过期时间也不一样, 因此采取动态续约的形式来不断调整过期时间, 当锁剩余的时间到达设定阈值时, 如果还没有主动解锁, 这时就会续约一段过期时间, 这就需要在需要加锁的服务器专门提供一个线程来负责续约服务, 又被称为看门狗
6. redlock算法
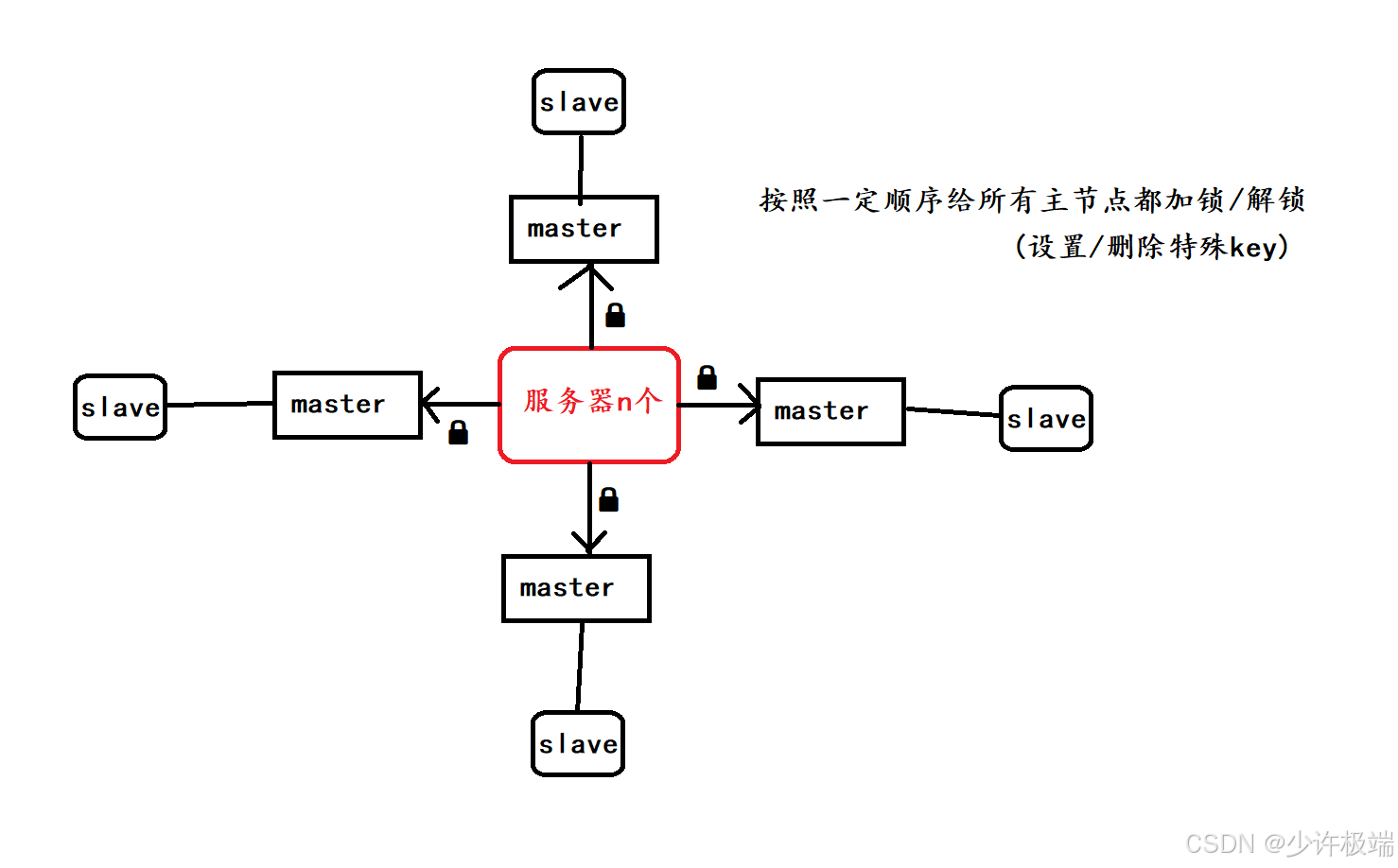
我们使用Redis提供加锁服务, 如果只提供一组主从节点集群的话, 当有服务器加锁后, Redis主节点出现宕机, 这时在从节点晋升为主节点过程中, 因为备份延迟的问题, 可能会存在从节点并没有保存锁的信息, 这就会导致锁的丢失
Redis官方给出解决方案是设置多组Redis(包含主从节点), 当有服务器加锁时, 按顺序给所有的主节点都加锁, 就算期间有主节点因为宕机或者其他原因导致加锁失败, 也不停下, 只要加锁的主节点数超过总数的一半, 就认为加锁成功, 解锁时同时也需要给所有主节点进行解锁, 这样就可以解决单组主从节点因为备份延迟而导致锁丢失的问题了!