目的
为避免一学就会、一用就废,这里做下笔记
说明
- 本文内容紧承前文-模型微调1-基础理论,欲渐进,请循序
- 前面学完了微调基础理论,这里选择其中一种微调方法BitFit进行实战
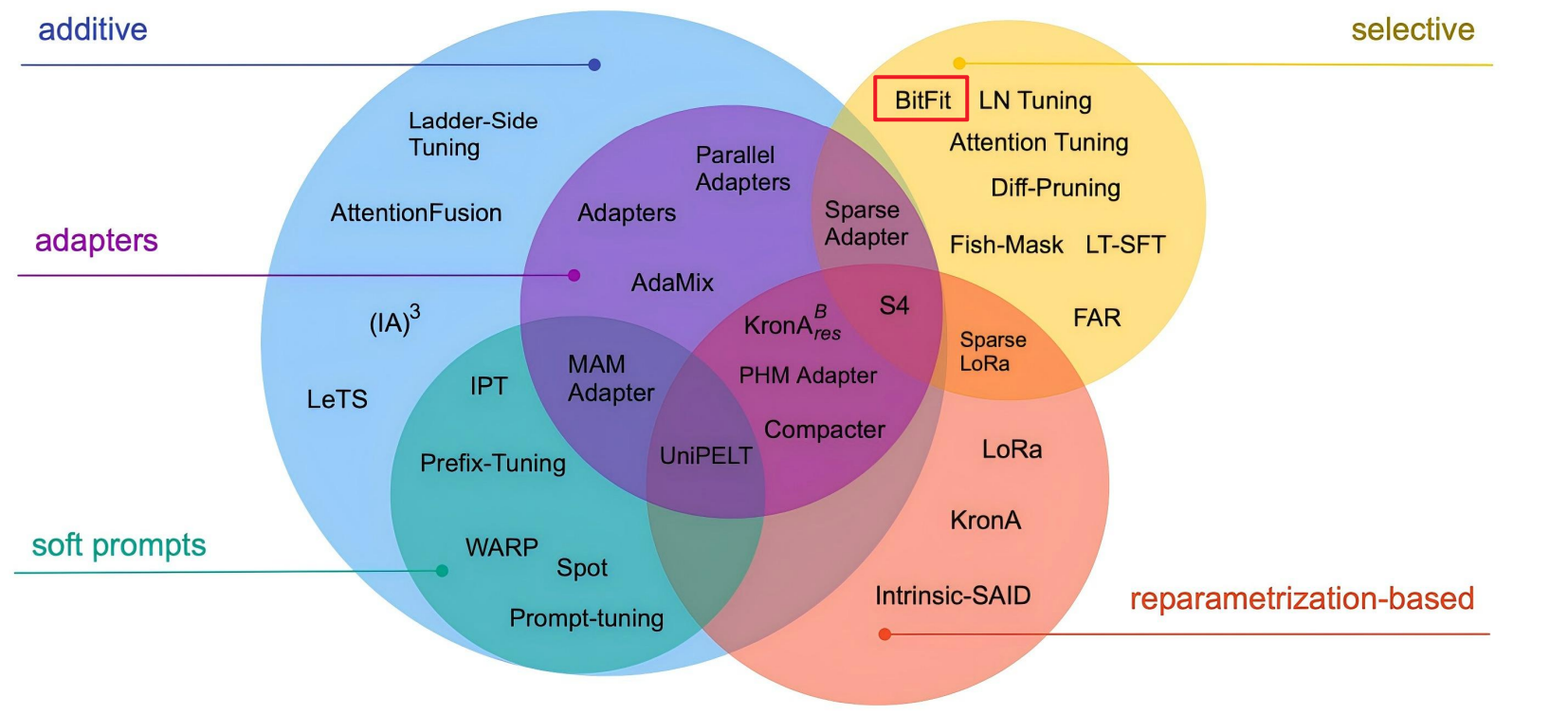
- BitFit微调只调偏置项,参数量远小于总参数(小3-4个数量级)
实战代码(Jupyter)
Step1 导入相关模块
python
from datasets import load_dataset
from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,TrainingArguments,Trainer
python
import datasets
datasets.__version__输出:
'4.5.0'
python
import transformers
transformers.__version__输出:
'4.56.2'Step2 加载数据集
python
ds=load_dataset("json",data_dir="./alpaca_data_zh/")
ds=ds['train']
# ds
ds[:3]输出:
{'instruction': ['保持健康的三个提示。', '三原色是什么?', '描述原子的结构。'],
'input': ['', '', ''],
'output': ['以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。',
'三原色通常指的是红色、绿色和蓝色(RGB)。它们是通过加色混合原理创建色彩的三种基础颜色。在以发光为基础的显示设备中(如电视、计算机显示器、智能手机和平板电脑显示屏), 三原色可混合产生大量色彩。其中红色和绿色可以混合生成黄色,红色和蓝色可以混合生成品红色,蓝色和绿色可以混合生成青色。当红色、绿色和蓝色按相等比例混合时,可以产生白色或灰色。\n\n此外,在印刷和绘画中,三原色指的是以颜料为基础的红、黄和蓝颜色(RYB)。这三种颜色用以通过减色混合原理来创建色彩。不过,三原色的具体定义并不唯一,不同的颜色系统可能会采用不同的三原色。',
'原子是物质的基本单位,它由三种基本粒子组成:质子、中子和电子。质子和中子形成原子核,位于原子中心,核外的电子围绕着原子核运动。\n\n原子结构具有层次性。原子核中,质子带正电,中子不带电(中性)。原子核非常小且致密,占据了原子总质量的绝大部分。电子带负电,通常围绕核运动,形成若干层次,称为壳层或电子层。电子数量与质子数量相等,使原子呈电中性。\n\n电子在每个壳层中都呈规律分布,并且不同壳层所能容纳的电子数也不同。在最里面的壳层一般只能容纳2个电子,其次一层最多可容纳8个电子,再往外的壳层可容纳的电子数逐层递增。\n\n原子核主要受到两种相互作用力的影响:强力和电磁力。强力的作用范围非常小,主要限制在原子核内,具有极强的吸引作用,使核子(质子和中子)紧密结合在一起。电磁力的作用范围较大,主要通过核外的电子与原子核相互作用,发挥作用。\n\n这就是原子的基本结构。原子内部结构复杂多样,不同元素的原子核中质子、中子数量不同,核外电子排布分布也不同,形成了丰富多彩的化学世界。']}Step3 数据预处理
python
# 加载tokenizer(小文件)
tokenizer=AutoTokenizer.from_pretrained("Langboat/bloom-1b4-zh")
tokenizer输出:
BloomTokenizerFast(name_or_path='Langboat/bloom-1b4-zh', vocab_size=46145, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='left', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '<unk>', 'pad_token': '<pad>'}, clean_up_tokenization_spaces=False, added_tokens_decoder={
0: AddedToken("<unk>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
1: AddedToken("<s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
2: AddedToken("</s>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
3: AddedToken("<pad>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
)
python
def process_func(example):
"""
用于对单个数据样本进行预处理,以便后续用于模型训练
:param example: 单个样本 {input:xxx,instruction:xxx,output:xxx}
:return:
"""
MAX_LENGTH=256
input_ids, attention_mask, labels=[],[],[]
instruction=tokenizer("\n".join(["Human: "+example["instruction"], example["input"]]).strip()+"\n\nAssistant: ")
response=tokenizer(example["output"]+tokenizer.eos_token)
input_ids=instruction["input_ids"]+response["input_ids"]
attention_mask=instruction["attention_mask"]+response["attention_mask"]
labels=[-100]*len(instruction["input_ids"])+response["input_ids"]
if len(input_ids)>MAX_LENGTH:
input_ids=input_ids[:MAX_LENGTH]
attention_mask=attention_mask[:MAX_LENGTH]
labels=labels[:MAX_LENGTH]
return {
"input_ids":input_ids,
"attention_mask":attention_mask,
"labels":labels
}
python
# 数据处理
tokenized_ds = ds.map(process_func, remove_columns=ds.column_names)
tokenized_ds输出:
Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 48818
})
python
# 解码看下input_ids中的数据
tokenizer.decode(tokenized_ds[0]["input_ids"])输出:
'Human: 保持健康的三个提示。\n\nAssistant: 以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。</s>'
python
# 解码看下labels中的数据
tokenizer.decode(list(filter(lambda x:x!=-100,tokenized_ds[0]["labels"])))输出:
'以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。</s>'Step4 模型创建
python
# 加载模型文件(大文件,以Gb为单位)
model = AutoModelForCausalLM.from_pretrained("Langboat/bloom-1b4-zh",low_cpu_mem_usage=True)
python
# 模型结构
model输出:
BloomForCausalLM(
(transformer): BloomModel(
(word_embeddings): Embedding(46145, 2048)
(word_embeddings_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(h): ModuleList(
(0-23): 24 x BloomBlock(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(self_attention): BloomAttention(
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(mlp): BloomMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(gelu_impl): BloomGelu()
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
)
)
)
(ln_f): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2048, out_features=46145, bias=False)
)
python
# 模型参数量,numel是number of elements的缩写
sum(p.numel() for p in model.parameters())输出:
1303111680全量调参的资源占用(耗不起)
### float32存储需要4个字节
model size: 1.3G *4 =5.2G
### 如果进行全量调参,需要占用更多的显存
SGD gradient: 1.3G *4 =5.2G
with Momentum Optimizer: 1.3G *4 =5.2G
with AdamW Optimizer: 1.3G *4 =5.2G
## 合计
5.2G * 4 = 20.8GBitFit调参(重点,这里用来标记待调整的参数)
python
# Selective 选择模型参数中所有 bias 偏置项进行微调
num_param=0
for name,param in model.named_parameters():
if "bias" not in name:
# 冻结非bias项(标识为不计算梯度,该操作会影响model的状态)
param.requires_grad=False
else:
param.requires_grad=True # 默认为True,可不写
num_param+=param.numel()
num_param # BitFit待训练参数量仅544768输出:
544768
参数量很小,为总参数量的万分之4Step5 配置训练参数
python
args = TrainingArguments(
output_dir="./chatbot", # 模型保存路径和预测结果输出路径
per_device_train_batch_size=1, # 训练时一次训练的样本数量,默认为8
gradient_accumulation_steps=8, # 梯度累积,每8个step更新一次参数
logging_steps=10, # 训练时每10个step保存一次日志
num_train_epochs=1 # 训练轮数
)Step6 创建训练器
python
trainer=Trainer(
model=model,
args=args,
train_dataset=tokenized_ds,
# 构建一个个批次数据所需要的
data_collator=DataCollatorForSeq2Seq(tokenizer,padding=True)
)
python
# 启动训练
trainer.train()