Torch-TensorRT 相关
-
Torch-TensorRT 是 NVIDIA 开发的一个高性能 PyTorch 推理编译器,旨在利用 NVIDIA 的 TensorRT 优化引擎,在不离开 PyTorch 生态的情况下,为深度学习模型提供极致的 GPU 加速。
-
简单来说,它就像是给你的 PyTorch 模型装了一个"涡轮增压器"。
核心架构与工作原理
-
Torch-TensorRT 的核心价值在于其**混合执行(Hybrid Execution)**能力。它不会强迫模型的所有部分都进入 TensorRT,而是智能地进行"手术":
-
分块(Partitioning):扫描 PyTorch 的计算图(通常是 TorchScript 或 FX 图),识别出 TensorRT 支持的操作子集。
-
转换(Conversion):将这些支持的子图转换为 TensorRT 引擎(Engine)。
-
回退机制(Fallback):对于 TensorRT 不支持的操作(如某些复杂的自定义算子或动态逻辑),自动保留在原生的 PyTorch 运行时(LibTorch)中执行。
-
集成执行:最终生成一个包含 TensorRT 引擎和 PyTorch 算子的混合模块,对用户来说,调用方式依然是 model(input)。
2026 年的关键特性
- 在当前的 AI 生态(2026年)中,Torch-TensorRT 已经高度成熟,其核心优势包括:
1. 极简的集成方式 (torch.compile)
自 PyTorch 2.x 时代引入 torch.compile 以来,Torch-TensorRT 已经成为其官方支持的最佳后端之一。你只需一行代码即可开启加速:
python
Python
import torch_tensorrt
import torch
model = MyModel().cuda().eval()
# 使用 TensorRT 作为后端进行即时编译 (JIT)
optimized_model = torch.compile(model, backend="tensorrt")2. 多样化的精度支持 (FP8, INT8, FP16)
除了传统的 FP16,Torch-TensorRT 在最新的架构(如 Blackwell/Hopper)上对 FP8 提供了原生支持,大幅提升了 LLM(大语言模型)的推理吞吐量,同时保持精度几乎无损。
- PTQ (Post-Training Quantization):通过校准集自动将模型压缩至 INT8。
- QAT (Quantization Aware Training):支持在 PyTorch 中训练好的量化模型直接部署。3. 动态形状 (Dynamic Shapes)
它完美解决了 TensorRT 早期版本对输入尺寸(Batch Size, Sequence Length)敏感的问题。通过预设优化范围(Min/Opt/Max),模型可以灵活处理变长输入。
4. 强大的工具链支持
-
NVIDIA Model Optimizer:配合使用,可进行更高级的稀疏化(Sparsity)和蒸馏优化。
-
C++ 部署:支持将优化后的模型序列化为 .ts (TorchScript) 或 .ep (Exported Program),无需 Python 环境即可在生产环境部署。
性能对比参考

核心版本对应表 (2024-2026)
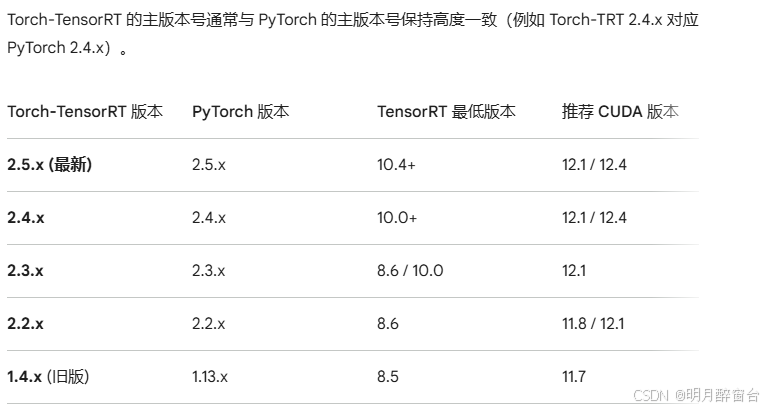
-
关键依赖链,要让 Torch-TensorRT 跑通,你需要确保以下这条"链路"从底层到顶层全部兼容:
-
NVIDIA Driver (驱动):必须支持你选定的 CUDA 版本。
-
CUDA Toolkit:PyTorch 编译时使用的 CUDA 版本必须与 TensorRT 编译时使用的版本一致(或二进制兼容)。
-
cuDNN:TensorRT 运行所需的底层加速库。
-
TensorRT:建议安装官方指定的版本,尤其是 TensorRT 10.x 引入了大量架构变化。
-
PyTorch:Torch-TensorRT 对 PyTorch 的版本依赖极强,建议通过 pip 或 conda 安装时严格指定。
-