目录
前言
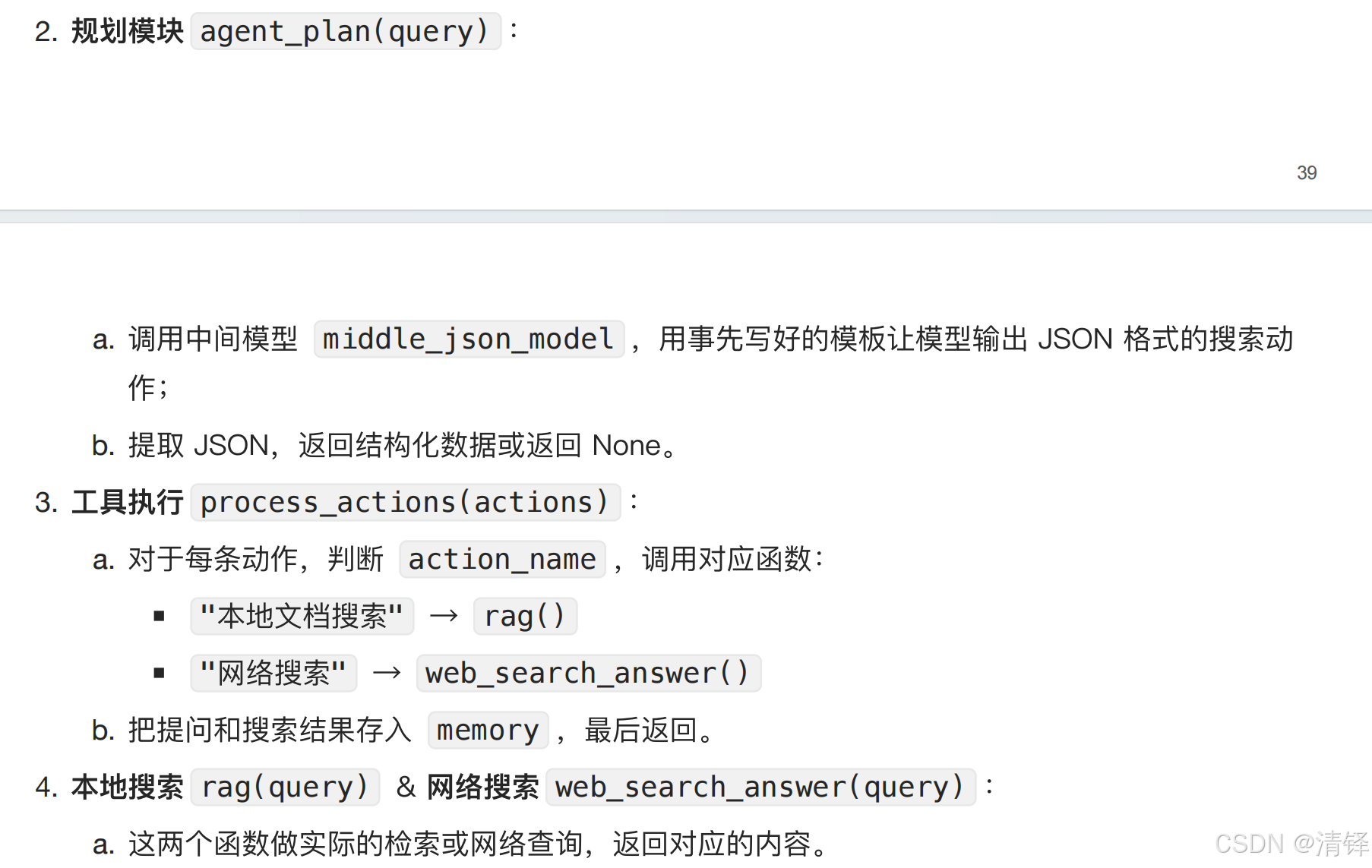
vibecoding 框架
python
目录结构~
config/:配置文件目录
• __init__.py
• model_config.yaml(模型配置)
• prompt_templates.yaml(提示模板)
• logging_config.yaml(日志配置)
src/:源代码目录
llm/:大语言模型客户端
• __init__.py
• base.py(基础客户端)
• claude_client.py (Claude支持)
• gpt_client.py(OpenAI GPT支持)
• utils.py(工具函数)
prompt_engineering/:提示工程模块
• __init__.py
• templates.py
• few_shot.py(少样本提示)
• chainer.py(链式提示)
utils/:通用工具
• __init__.py
• rate_limiter.py(速率限制)
• token_counter.py(令牌计数)
• cache.py(缓存机制)
• logger.py(日志器)
handlers/:处理器
• __init__.py
• error_handler.py(错误处理)
data/:数据目录
• cache/(缓存数据)
• prompts/(提示存储)
• outputs/(输出)
• embeddings/(嵌入)
examples/:示例代码
• basic_completion.py(基础补全)
• chat_session.py(聊天会话)
• chain_prompts.py(链式提示示例)
notebooks/:Jupyter笔记本,用于实验和测试
• prompt_testing.ipynb
• response_analysis.ipynb
• model_experimentation.ipynb
根目录其他文件:
• requirements.txt(依赖)
• setup.py
• README.md
• Dockerfile规划机制
plan and think
实际系统中常常 先在人为代码中固定主干流程,再在需要模型能力的节点中,通过prompts来让模型在做局部规划中执行。 有点像我在user端事先规定的ruler一样
API
一个程序和另一个程序之间一套规则和接口 地址或者说是链接URL,参数API key
COT
chain of thought 即推理 只写reasoning不执行行动,thought 思考过程,action 需要执行的动作和调用的工具,observation 得到返回的信息
"规划机制"在当前最⽕的 Agent 框架⾥,⼏乎都是通过 Prompt + ⼀些⼿写逻辑 实现的, LLM 在这些框架⾥扮演"执⾏规划"或"辅助⽣成规划"的⻆⾊,但很少有框架能让 LLM 完全靠⾃⼰从 0 到 1 做所有⼤规模规划。
snippets列表中每一个元素就是一个字典,包含title网络标题,url网页链接,content网页内容摘要,用于存入chromadb做向量相似度排序
目的意义
通过调用检索知识库和联网搜索的知识库生成prompts,再调用大模型进行回答,还有一个规划模块预判用户query的动机和未来决策,最终大模型流式输出给前端。做的这些都是为了agent可以给出有来源且高质量的回复
get_chat_completion
get_chat_completion 流式响应生成器函数
def get_chat_completion(
session_id, # 会话 ID
question, # ⽤户问题
retrieved_content, # 知识库检索内容
user_id, # ⽤户 ID
final_prompt, # 最终提示词
related_questions, # 相关问题
snippets # Web搜索⽚段
调用大模型进行对话
处理流式响应
返回知识库检索结果
返回网络搜索结果
生成推荐问题
处理图片和视频搜索结果
总结


碎碎念:我在一个朋友身上学习到了:无论被如何打压、不被尊重、不被正视依旧可以笑脸相迎像没发生过这件事一样,此等胸襟是我曾没有的。